融合掩码机制的图卷积文本分类模型
2023-12-06黄雪阳徐广辉陆欣荣任丽博
孙 红,黄雪阳,徐广辉,2,陆欣荣,任丽博
(1.上海理工大学 光电与计算机工程学院,上海 200093;2.同济大学附属上海市第四人民医院 脊柱外科,上海 200434)
0 引言
随着互联网的发展和网络文本数据的迅速增长,文本分类已成为自然语言处理领域中最重要和最具有挑战性的分支之一。文本分类是利用文本处理技术对一段文本内容进行分类,其在文档主题分类[1]、过滤垃圾邮件[2]和新闻主题分类[3]应用场景得到广泛应用。文本特征提取是文本分类的关键步骤之一,其关键在于在保留语义信息的前提下对文本进行向量化表示。早期的文本分类问题常用机器学习方法解决,其中包括支持向量机[4]、朴素贝叶斯算法[5]和K近邻算法[6]等。尽管上述方法能达到不错的分类效果,但存在时间成本和人力资源成本高的问题。
相较于机器学习难以对文本进行有效的特征提取的问题,深度学习可以利用其神经网络结构进行特征工程和自动学习数据的特征表示,因此广泛运用于自然语言处理领域。Liu等[7]使用长短时记忆网络LSTM(Long Short-Term Memory)模型引入遗忘门、输入门与输出门的概念,通过控制信息的量来捕捉文本信息。双向长短时记忆网络BiLSTM(Bidirectional Long Short-Term Memory)在LSTM的基础上,通过捕捉上下文信息和长距离的双向语义依赖能更好解决文本分类的任务。此外,为了解决句子级别的分类任务,Kim等[8]提出的TextCNN(Text Convolutional Neural Network)模型将多个词向量构成的特征矩阵作为句子表示,并使用不同尺寸的卷积核对特征进行一维卷积,最后通过池化层提取每个文本的特征信息。Yang等[9]提出HAN(Hierarchical Attention Networks)模型采用”单词-句子-文档”的层次化结构表示文本,并对单词级别和句子级别使用不同的注意力机制,从而具有不同程度的表达能力。
近年来,图卷积神经网络因其在文本分类领域的出色表现而在众多自然语言处理领域得到广泛应用。Yao等[10]提出TextGCN模型构建整个语料库的文本图,利用点互信息[11]和TF-IDF[12]计算节点依赖关系,并作为边的权重进行文本分类。除了词共现关系外,Liu等[13]提出的TensorGCN模型引入了长短时记忆网络和单词间的句法依赖,用于表达单词间的语义与句法关系,并构建了三种异质图,然后采用图内和图间两种信息传播方式,分别用于单图中节点的信息聚合以及协调各图之间的异构信息。但上述方法忽略了图卷积神经网络存在过平滑的问题[14],即节点随着网络层数和迭代次数的增加表征会趋向于收敛到同一个值的现象,导致模型性能下降而无法学习图结构中丰富的文本语义。
为缓解上述的过平滑现象,本文提出了一种融合掩码机制的图卷积神经网络模型MaskGCN(Mask Graph Convolution Network)并应用于文本分类任务。Rong等[15]提出的Dropedge通过丢弃文本图的边以达到缓解过平滑的目的,而本文的掩码机制同样是对文本图的边进行操作,在提高模型分类性能的同时,本文也探索了掩码机制对缓解过平滑的作用。不同于现有的图网络研究,MaskGCN为每个文本构建不同粒度的文本图,将余弦相似度作为边的权重,并使用全局共享矩阵动态更新文本图矩阵。这样可以有效节约内存资源和计算时间,并且全局共享矩阵可以捕捉节点的全局信息。在构建完文本图后,按照融合规则将随机掩码矩阵和文本图矩阵进行融合,生成文本图掩码矩阵。不同粒度的文本图是基于全局共享矩阵在训练时动态生成的,并生成文本图掩码矩阵,输入到MaskGCN中学习文本表示,最后通过BiLSTM网络和分类器获得分类结果。
本文的主要贡献有:
(1) 针对图卷积神经网络在模型学习过程中存在过平滑的问题,即节点更新过程中特征收敛至相似值的现象,同时为探索图结构上的掩码机制,提出了融合掩码机制的图卷积神经网络,能够在一定程度上有效抑制过平滑问题,并提高文本分类效果。
(2) 基于全局共享矩阵为每一个文本动态构建单词级文本图、短语级文本图和句法文本图的多粒度文本图,以词向量之间的余弦相似度为文本图的边的权重,有效捕捉文本全局信息和潜在的依赖关系。
(3) 在三个公开数据集上的大量实验验证了本文模型的有效性,以及掩码机制对抑制过平滑现象的作用。同时通过实验探索不同掩码比例下的文本分类效果。
1 相关研究
文本是非欧几里德数据,这是一类不具有平移不变性的数据,所以神经网络的表达能力往往会被这种复杂结构限制。而图神经网络以图的形式对词与词之间以及词与文档之间的关系进行建模,可以直观地表达出文本的丰富关系,并且利用节点间的连接关系保留全局的图信息。近年来,大量研究利用该特点将图卷积神经网络应用在文本分类任务上,以表达文本中的语义关系,并且在图像分割[16]和语义角色标签[17]等任务上得到广泛应用。Kipf等[18]提出了GCN(Graph Convolutional Networks)模型,通过利用切比雪夫多项式的一阶截断展开式来拟合卷积核,简化了节点信息的传播规则,并通过减少参数来缓解过拟合以及简化卷积层的运算。同时,Gao等[19]提出了一种通过结合GCN图卷积与CNN一维卷积获取上下文关系的混合卷积操作,该操作不仅能快速增大感受野,还能提取文本的语序信息。
为整个语料库构建文本图的研究方法存在计算成本高、忽略了文本内的单词交互和难以扩展的问题。为此,Huang等[20]提出的Text-level GCN模型构建文本级别的有向图,设计了节点特征矩阵和边权矩阵,并在训练过程中使用消息传递机制动态更新节点表示和边权,更好地捕捉全局特征和降低计算成本,且对新样本具有较好的泛化能力。Wang等[21]提出的GeniePath是可扩展和自适应感受路径的图神经网络,具有排列不变性的图数据的函数空间和具有适应广度和深度函数的路径层。而Wu等[22]提出的SGC模型消除了隐藏层之间的激活操作,将中间过程转换为简单的线性变换,以减少模型的复杂度和冗余计算。Kenta等[23]使用归一化拉普拉斯算子的谱分布将权重标准化的图神经网络和底层图的拓扑信息联系起来。Wang等[24]提出MAGNN(Multi-hop Attention Graph Neural Network)将注意力和多跳上下文信息结合,在节点间进行远程交互,并消除噪声信息。
掩码机制作为预训练模型BERT[25]的核心任务之一,在预训练过程中能有效提高BERT模型性能,受到广泛关注。掩码机制将单词作为掩码对象的基本单位,从训练文本中选取15%作为参与掩码的对象,其中,80%的单词被掩盖,10%的单词被随机替换,剩下10%保持不变,通过该掩码机制使得BERT模型快速学习文本单词的上下文语义。不同于BERT的掩码机制,Sun等[26]提出的ERNIE模型设计了随机掩盖实体的掩码机制,通过整合额外知识信息和文本信息,将实体的异构信息表征在统一的特征空间,如“我想去北京”,在BERT中掩盖后为“我想去[Mask]京”,在ERNIE中掩盖后为“我想去[Mask]”,将“北京”视作一个实体能更好挖掘文本语义信息。但上述研究都是基于文本结构进行掩码,并不完全适用于基于图卷积神经网络的文本分类任务。
为了有效抑制图网络存在的过平滑问题和探索图结构上的掩码机制,本文提出了融合掩码机制的图卷积神经网络,基于全局共享矩阵动态构建不同粒度的文本图,以提高模型学习不同层次文本语义的能力。通过实验表明,抑制过平滑的有效性和较优的分类效果,并探索了掩码比例对于文本分类效果的影响。
2 模型概述
本文提出的融合掩码机制的图卷积文本分类模型主要包含全局共享矩阵、构建文本图、掩码机制的融合规则和融合掩码机制的图卷积神经网络四个部分。本节将介绍各部分的结构和实现细节。
2.1 全局共享矩阵
在Text-level GCN[20]中的研究基础上,本文根据词表集合构建一张包含不同粒度的全局共享矩阵,即包含单词级别和短语级别两种粒度的全局共享矩阵。
首先,将语料库的文本进行数据清洗和去除重复词等预处理操作,并且用分词工具获取短语级别的语料和以单词为基本单位进行分割获得单词级别的语料。然后,通过统计两种语料中所有不重复的单词,以保留两种语料中没有重复的词表。最后,使用预训练词向量[27]初始化全局共享矩阵,其中预训练词向量中不存在的单词使用服从0~1均匀分布的随机样本值进行初始化。全局共享矩阵构建流程如图1所示。
其中,d是词向量的维度。词表包含n个单词级别和短语级别的单词,且是经过统计后得到的不重复的单词。全局共享矩阵将作为模型的嵌入层在模型训练过程中动态更新嵌入层的参数,由于余弦相似度每一个批次都会计算一次,因此实现了文本图的动态更新。
2.2 构建文本图
给定一个包含m个节点的文本,在模型训练过程中动态构建文本图矩阵,将节点间的余弦相似度作为节点间的边的权重。其构建流程如图2所示。
文本图矩阵是在模型训练过程中动态构建的,其边的权重是节点间的余弦相似度。具体实现过程是将全局共享矩阵作为模型的嵌入层,在训练时获取文本图对应的词向量,再计算余弦相似度得到文本图矩阵。余弦相似度其定义如式(1)所示。
(1)
其中,Ai和Bi代表节点的词向量分量,n是词向量的维度。
为了探索在图结构上的掩码机制,为每一个文档构建的三张不同粒度的文本级别文本图,分别是单词级文本图、短语级文本图、句法文本图。其目的是引入不同粒度的图卷积中包含的语义信息和句法结构信息,提高模型拟合学习的能力。三种文本图的邻接矩阵构建流程如图2所示,其边的权重的构建如式(1)所示。
单词级文本图将预处理后的文本以单词为基本单位进行分割,并以单词作为图节点构建文本图。本文舍弃了以往论文中采用的PMI和TF-IDF的构图方法,因为这种方案需要统计全局信息,存在不易扩展新文本的缺点。单词级文本图的邻接矩阵是以单词作为节点构建的,并将节点间的余弦相似度作为边的权重。
短语级文本图短语是一组词或实体,中文语境中单个汉字并不能完整表达语义,如“北京”是一组短语,但拆开后则是完全不同的含义,因此短语级文本图能更好地表达语义。短语级文本图的邻接矩阵是以短语作为节点构建的,其边的权重是节点间的余弦相似度。
句法文本图句法是用来表达句子结构的。不同于以往研究仅仅表示是否存在句法关系,本文使用哈工大LTP工具生成文本的句法结构并且为边赋予了权重。句法文本图在以短语为基本单位生成句法结构的基础上,将余弦相似度作为边的权重,并用邻接矩阵描述这种图节点间的关系。
2.3 掩码机制的融合规则
不同于文本结构对词或实体掩码的研究[26],本文将掩码机制引入图神经网络。由于文本是非欧几里德数据,可以直接在文本上进行掩码操作,而图结构的掩码机制更为复杂。不同于现有研究,本文并不是简单借鉴其方法,而是利用其思想并针对图结构的特点,提出了掩码机制的融合规则,在图结构上对文本间的关系进行掩码,使模型去学习文本节点关系并提高了模型的分类性能。
在每次训练过程中,按照一定掩码比例生成一张与文本图矩阵大小相同的随机掩码矩阵,按照掩码机制的融合规则生成文本图掩码矩阵。融合掩码机制的构建流程如图3所示。
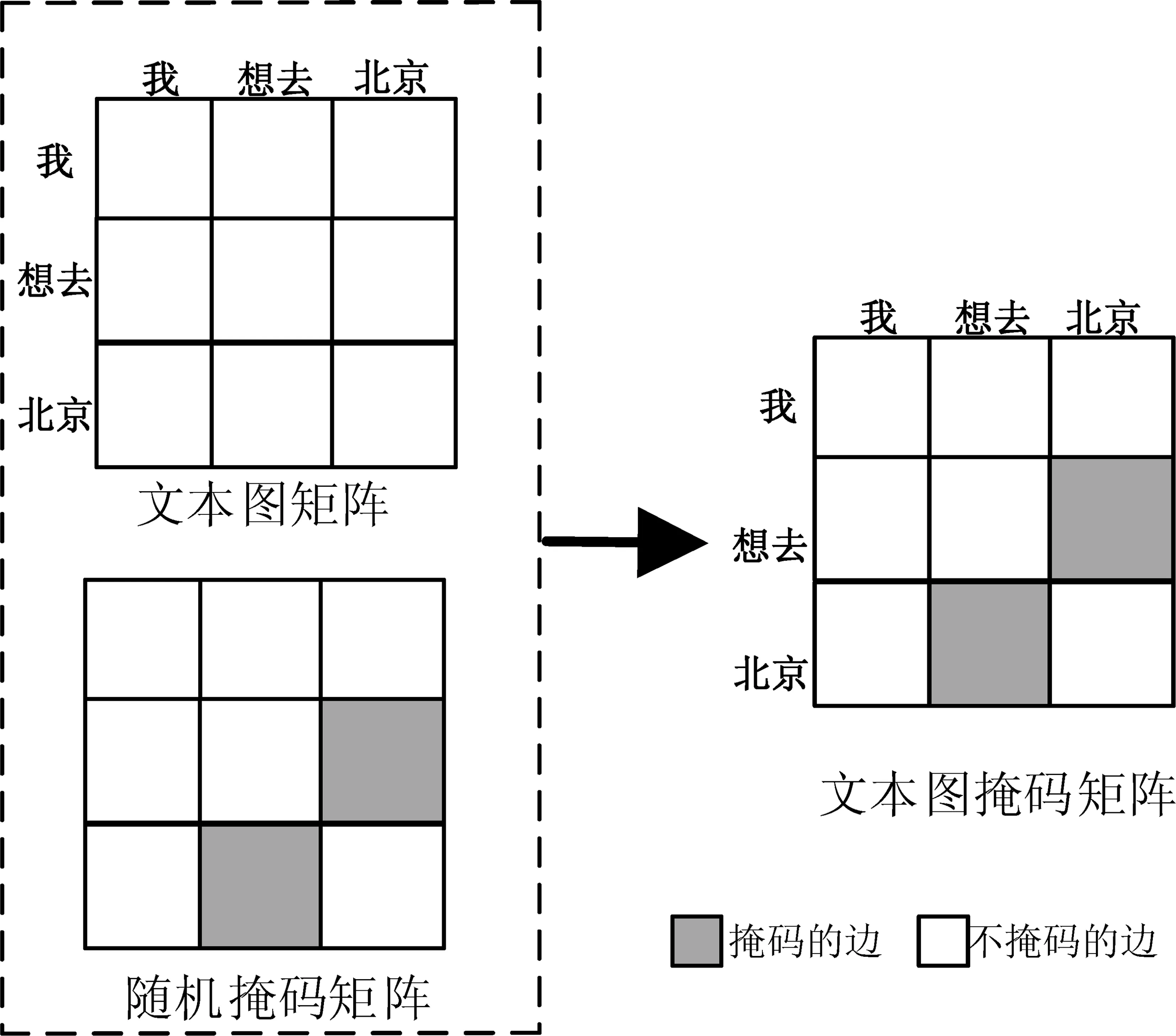
图3 融合掩码机制的构建流程
给定一个大小为m×n的文本图矩阵,和大小同样为m×n的随机掩码矩阵,随机掩码矩阵的生成规则如式(2)所示。
(2)
其中,当节点的边被掩码时,Mask(i,j)=0,否则Mask(i,j)=0。Mask表示随机掩码矩阵,Mask(i,j)表示随机掩码矩阵的i行j列的值,即图节点i和节点j之间的边权重。
文本图矩阵和随机掩码矩阵的融合规则如式(3)所示。
(3)
其中,∘表示逐元素点乘,adj和Mask分别是文本图矩阵和随机掩码矩阵,a和b是矩阵元素。随机掩码矩阵元素由1和0组成,根据融合公式将文本图矩阵和随机掩码矩阵融合,生成文本图掩码矩阵,因此通过矩阵逐元素点乘实现图结构上的掩码机制。另外,随机掩码矩阵是动态生成的,以实现在训练过程中的动态更新。
融合掩码机制的单词级文本图、短语级文本图和句法文本图在图结构上的呈现分别如图4~图6所示。按照融合规则将随机掩码矩阵融合三种不同粒度的文本图,实现了动态随机掩码。

图4 融合掩码的单词级文本图
2.4 融合掩码机制的图卷积神经网络
在按照融合规则生成文本图掩码矩阵的基础上,本文提出了一种融合掩码机制的图卷积神经网络MaskGCN,其中主要包括残差结构和自注意力机制,而上文中生成的文本图掩码矩阵则作为图网络的输入。
MaskGCN构建流程如图7所示,将文本图掩码矩阵和文本向量作为图卷积神经网络的输入,同时残差结构有效缓解图卷积网络的过平滑的问题。最后,自注意力层关注图结构中的不同粒度的文本。
图卷积神经网络更新节点如式(4)、式(5)所示。
(4)
(5)
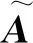
为了解决同一句话的不同粒度导致特征向量的长度不相同的问题,本文将不同粒度的文本长度对齐一致,并在较短的文本后面增加空格以保持不同粒度文本长度一致。如“我想去北京”,在单词级别的长度为5,而短语则分割为“我”“想去”“北京”,长度为3。通过增加空格来保持不同粒度文本长度一致,解决了在模型训练过程中输入大小不一致的问题。由于空格不含有具体文本语义信息而造成模型性能下降,MaskGCN模型引入自注意力机制来弥补该缺陷,用自注意力机制去关注文本自身的长度。
2.5 BiLSTM
双向长短时记忆模型BiLSTM是一种双向递归神经网络,其将整个句子的所有单词作为输入,充分考虑了文本的上下文信息。BiLSTM模型能记忆上下文信息和学习文本特征,可以很好地处理多条短文本语料,结构如图8所示。
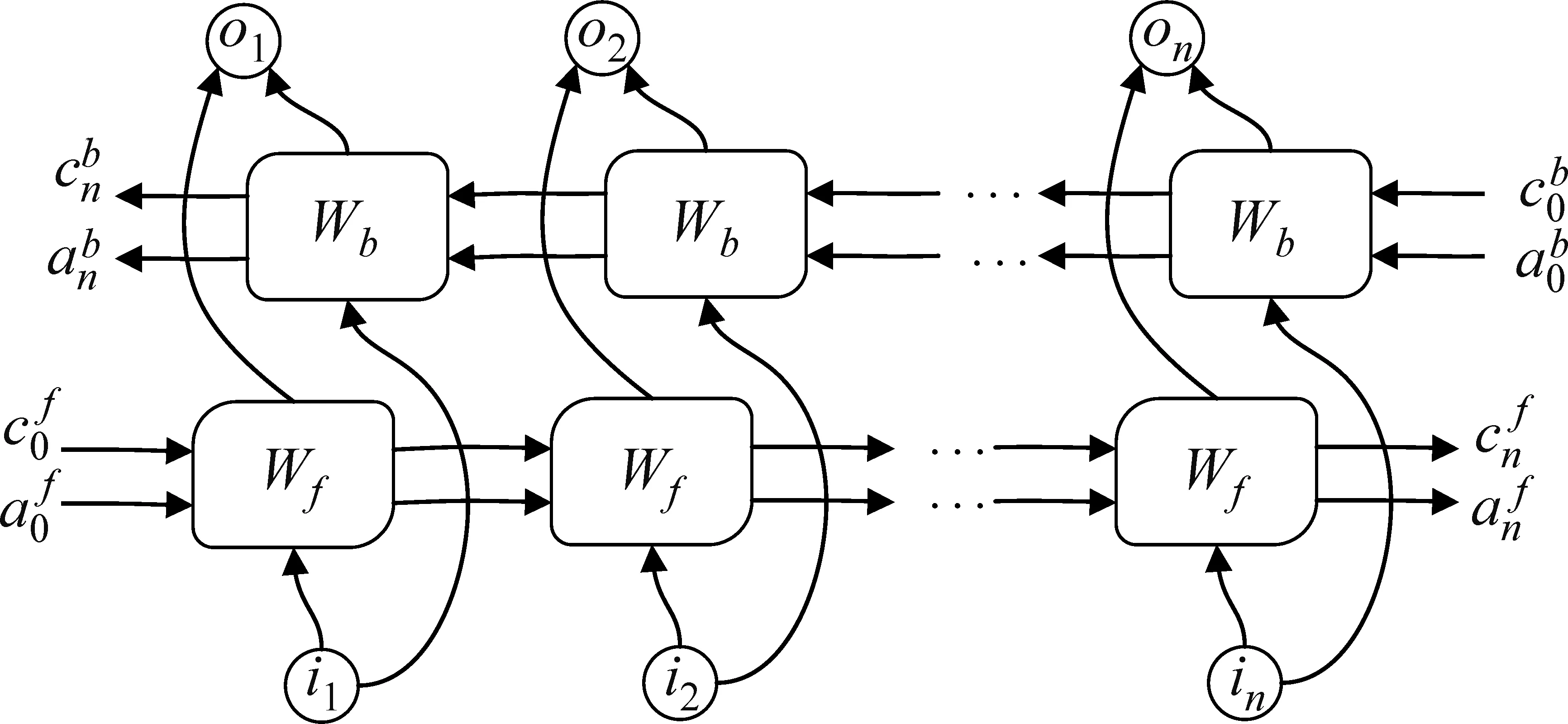
图8 双向长短期记忆网络的结构
2.6 模型框架
图9展示了文本分类模型的整体框架,主干部分包括MaskGCN网络,以及基于掩码机制的融合规则生成不同粒度的文本图掩码矩阵。
从图9可以看到,全局共享矩阵为每一个文本构造三张不同粒度的文本图,并且在训练过程中动态构建文本图矩阵。然后,利用掩码机制的融合规则将随机掩码矩阵和文本图矩阵生成文本图掩码矩阵作为图卷积神经网络的输入。全局共享矩阵的词向量和单词级文本图掩码矩阵输入第一个MaskGCN网络,其输出作为第二个MaskGCN网络的输入,而第三个MaskGCN的输出作为BiLSTM的输入。三个MaskGCN堆叠的模型结构能融合三种不同粒度的文本特征,有助于缓解图网络过平滑的问题。BiLSTM接收来自MaskGCN的输出,最后输入到Softmax分类器进行分类。
此外,本文使用交叉熵损失作为模型的分类损失函数,如式(6)所示。
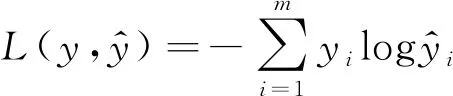
(6)
3 实验及结果分析
3.1 数据集和实验环境
为了检验本文提出的文本分类模型的分类效果,选取了三个广泛使用的文本分类数据集进行实验,数据集介绍如下:
THUCNews数据集包含教育、科学、经济、房产、股票、社会、时政、体育、游戏和娱乐共10个不同主题类别的新闻文本分类数据集。
今日头条数据集来源于今日头条客户端,分别包括教育、科技、国际、证券、农业、房产、军事、旅游、民生、文化、娱乐、体育、财经、汽车、电竞共 15个类别。
SogouCS数据集包含来自搜狐新闻共18个类别的文本数据,本实验选取其中10个类别。
各数据集分类统计信息如表1所示。
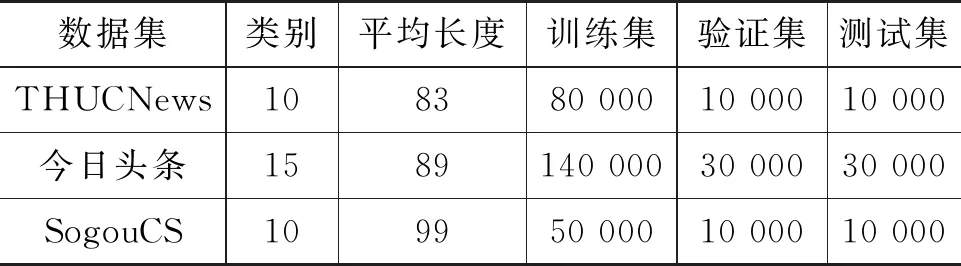
表1 数据集分类信息
词向量的维度是300,Dropout值为0.2,学习率为1e-3,并使用Adam优化器训练。实验平台的GPU配置为Quadro RTX 6000,并使用64位Windows操作系统。
3.2 对比模型
实验将提出的融合掩码机制的图卷积文本分类模型与多种具有代表性的基于传统神经网络的或基于图卷积的文本分类方法进行了比较,相关方法介绍如下:
TextCNN[8]将CNN引入文本分类领域,利用一维卷积核对文本中的词序列特征向量进行整行的卷积操作以提取文本的局部特征,利用池化得到文本的向量表示并用于分类。
BiLSTM双向LSTM模型能捕捉文本的双向信息和长距离语义依赖。
Text-LevelGCN[20]文本级图卷积网络为每个文本构建一张文本图,并使用全局共享矩阵动态更新图权重。
TextGCN[10]文本图卷积分类模型将整个语料库作为节点构建文本图,并使用图卷积神经网络对文本节点进行分类。
TensorGCN[13]分别使用词共现关系、语义相似关系和语法依存关系作为边权重以建立三通道文本图,然后进行文本分类。
TextINGZhang等[28]提出的TextING模型为每篇文档构建独有的图结构,并通过图门控网络更新自身状态,从而捕捉上下文的细粒度关系和单词的交互。
BertGCNLin等[29]提出的模型,将预训练模型Bert和GCN相结合,采用记忆存储、预测插值和小学习率的方法训练模型。
ME-GCNWang等[30]提出的ME-GCN模型,首次尝试在图网络上应用多维度边进行文本分类,通过多维词向量和文档向量构造文本图,从而捕捉丰富的语义信息。
3.3 实验结果
实验将本文提出的MaskGCN模型与各模型在实验数据集上进行对比,其实验结果如表2所示。
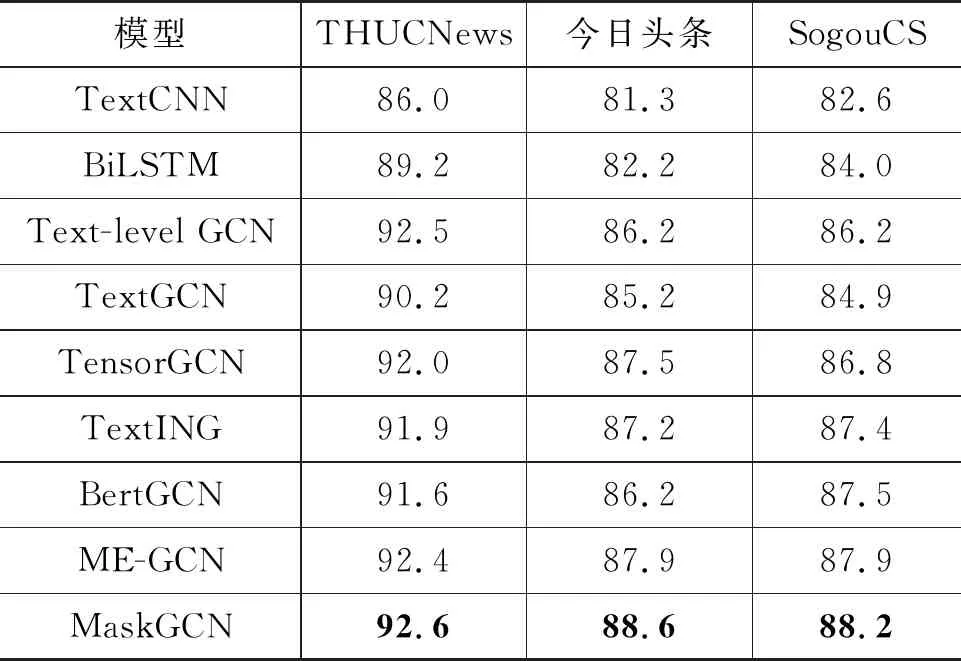
表2 模型分类准确率 (单位: %)
通过表2发现,相比于CNN、BiLSTM等传统神经网络模型,基于图卷积网络的文本分类模型都表现出良好的效果,说明图结构在非欧几里德数据的文本分类任务的有效性。MaskGCN在THUCNews数据集上相比于各对比模型至少有0.2%的提升,在今日头条数据集上则有至少0.7%的提升,而在SogouCS数据集上至少有0.3%的提升。以上结果表明,本文提出的融合掩码机制的图卷积网络模型有力提高了文本分类性能。
3.4 消融实验
为了进一步验证融合掩码机制对抑制过平滑的有效性,本文设计了两个用于消融实验的对比模型,分别记为MaskGCNnone和MaskGCN,其中MaskGCNnone是不含掩码机制的模型。
本文采用Chen等人[31]提出的衡量图表示的平滑度的计算方法,其方法如式(7)~式(11)所示。
(7)
Dtgt=D∘Mtgt
(8)
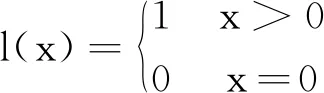
(9)
(10)
(11)
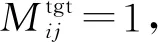
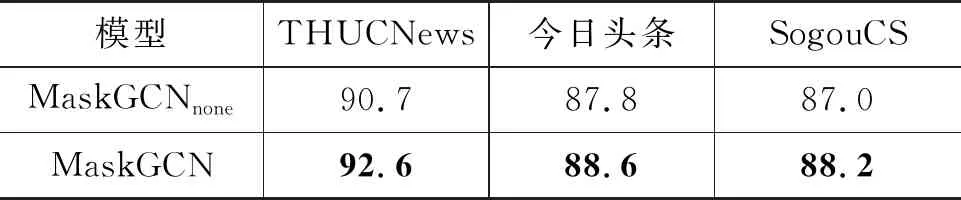
表3 掩码机制抑制过平滑实验的准确率 (单位: %)
从表3可以发现,相比于无掩码机制的MaskGCNnone,MaskGCN在三个数据集上的模型性能更优,说明掩码机制对于分类准确率的有效性。此外,为了进一步说明掩码机制对过平滑问题的抑制效果,本文观察了THUCNews数据集上的样本的平滑度衡量值MAD随模型层数的变化曲线(图10)。
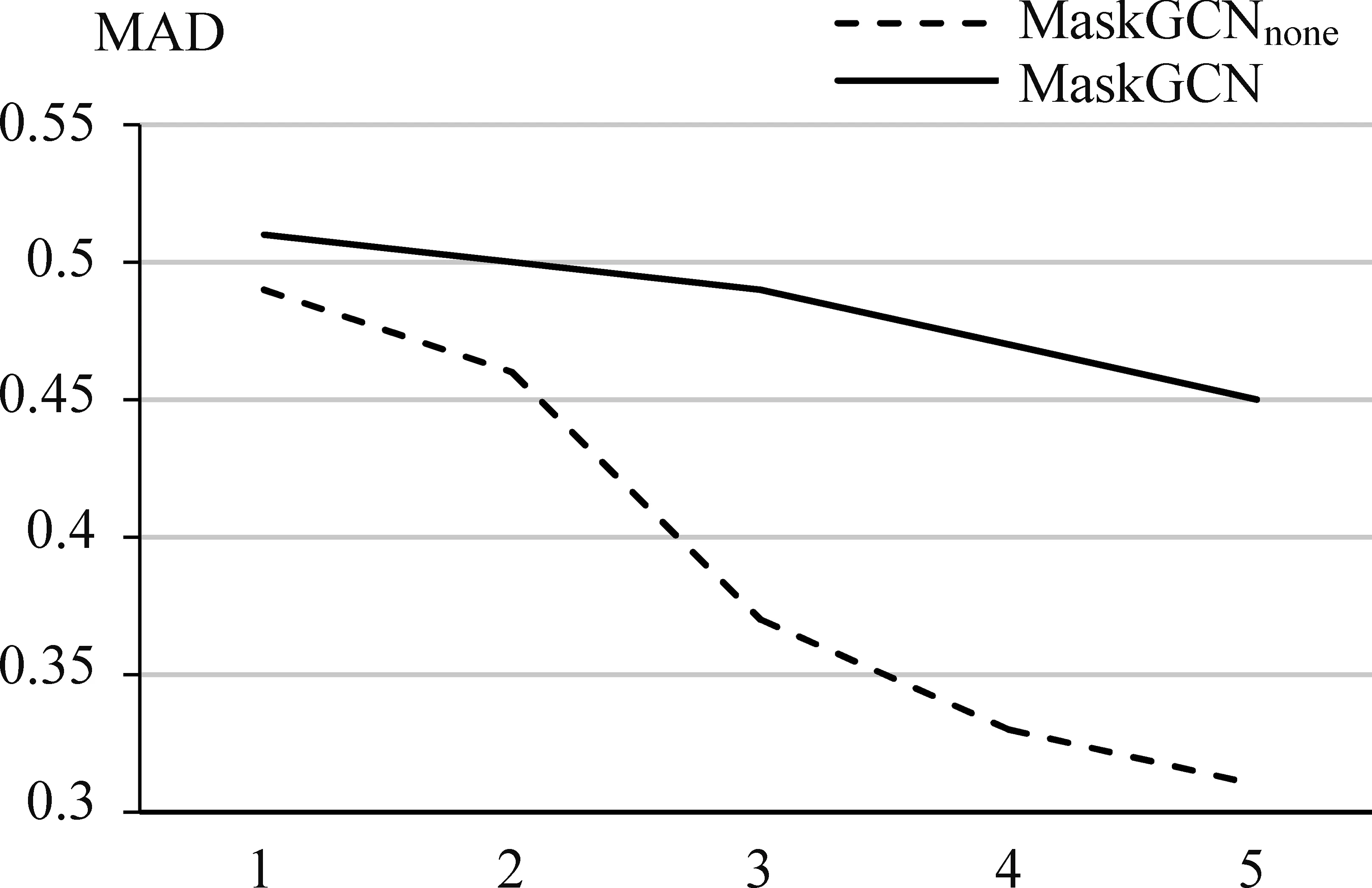
图10 平滑度MAD值随模型层数变化
从图10中可以发现,随着图卷积网络的层数增加,模型MaskGCNnone的MAD值逐渐下降,说明逐渐出现了过平滑的现象。相比于MaskGCNnone,虽然MaskGCN模型的MAD值整体呈下降趋势,但下降趋势较缓且值大于MaskGCNnone,说明融合掩码机制的图卷积神经网络能够提升模型分类性能和抑制过平滑现象。
3.5 掩码比例研究
为了探究掩码比例对分类结果的影响,本文采用不同比例对文本图矩阵进行掩码。首先,从训练集中选取一定比例的文本图,其比例记为x1。然后,对于每一张被选中的文本图,对文本图中的一定比例的节点进行掩码操作,其比例记为x2。结果如表4所示。
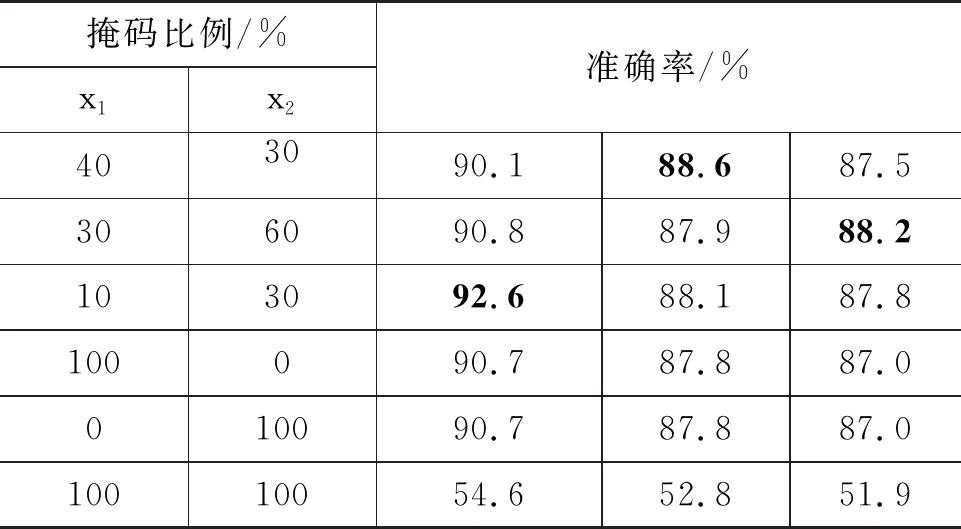
表4 掩码比例的实验结果
从表4可以发现,在三个数据集上分别当x1=10%且x2=30%、x1=40%且x2=30%和x1=30%且x2=60%时,在三个数据集上的准确率分别为92.6%、88.6%和88.2%,其模型准确率最高,说明不同的数据集的最佳掩码比例不同,且整体准确率相差不大。
当x1=0%或者x2=0%时,模型性能和无掩码机制的MaskGCNnone是相同的。由此,当x1=100%且x2=0%,或者x1=0%且x2=100%时,可以发现这两种掩码比例下的准确率相同。当x1=100%且x2=100%时,实验结果准确率分别为52.6%、52.8%和51.9%,在三个数据集上的模型性能都非常差,本文认为过高的掩码比例会破坏图文本表示的信息,造成了模型性能的下降。
结合表1和表4可以发现,不同数据集的最佳掩码比例是不同的,本文认为不同数据集最佳掩码比例的不同和样本量、文本平均长度有关。在数据集样本量方面,今日头条的样本量最大,而SougoCS数量最少。在文本平均长度方面, SougoCS平均长度最大,THUCNews平均长度最短。其原因如下: 当文本平均长度越小时,文本图中被掩码的节点越多,反而会破坏图结构所包含的信息,造成孤立的图节点,导致模型无法捕捉到节点间关系,因此模型性能会有所下降。而当样本量大时,被选中掩码的样本比例上升可以缓解过平滑并提高模型的拟合能力。综上所述,不同的样本量以及文本平均长度会影响不同数据集的最佳掩码比例。
实验结果表明,当掩码比例过高或者过低时,分类准确率都会有所下降,不同程度的掩码比例会抑制图卷积网络的过平滑现象,从而影响模型分类效果。
3.6 文本图研究
为了探究本文设计的三种文本图对文本分类准确率的影响,本文在MaskGCN模型的基础上,保留其中的部分文本图模块在三个数据集上进行了消融实验,结果如表5所示。

表5 文本图对分类准确率的影响 (单位: %)
从表5可以发现,单张文本图在MaskGCN模型上基本能保持较好的文本分类效果,而句法文本图、单词文本图和短语文本图的结合可以捕捉到多粒度的语义信息,从而获得更好的模型分类性能。
4 总结
针对卷积网络过平滑的问题,本文提出了一种融合掩码机制的图卷积文本分类模型,将掩码机制引入图结构,并通过实验证明掩码机制能有效提高模型性能和抑制过平滑问题。此外,本文构建了三种不同粒度的文本图来获取多层次的文本信息,并使用全局共享矩阵动态更新文本图,从而使模型捕捉更深层次的文本图信息。
通过在三个中文数据集上的实验,本文证明了本文模型对于文本分类任务的有效性。同时,实验也证明融合掩码机制的图卷积网络能有效抑制过平滑现象,并且探索了不同掩码比例下的分类效果。
