面向多智能体协作的注意力意图与交流学习方法
2023-11-28俞文武杨晓亚李海昌胡晓惠
俞文武 杨晓亚 李海昌 王 瑞 胡晓惠
多智能体强化学习技术在现实世界中有着广泛的应用,例如踢球机器人团队[1]、游戏智能[2]、自动驾驶等.随着深度学习在语音识别[3]、文本翻译和目标检测[4]等领域的发展,多智能体强化学习同这些领域技术融合,已取得了许多成果[5].然而,多智能体强化学习领域仍存在许多开放问题,比如训练过程非平稳性、维度爆炸和信用分配问题等[6].
本文针对部分可观测的多智能体合作任务,采用基于值函数的强化学习方法进行研究.独立Q学习(IndependentQ-learning,IQL)[7-8]是将单智能体强化学习方法直接应用到多智能体问题上的典型代表,虽然具有很好的扩展性,但是由于其他智能体的策略在训练过程中不断发生变化,对单个智能体而言,所处环境是非平稳的,在复杂任务上的表现往往不佳.值函数分解方法在一定程度上能缓解智能体间信用分配和懒惰智能体的问题,同时每个智能体学习到自身最优的局部值函数,仅仅利用自身的局部值函数进行决策,具有很好的扩展性.因此,本文基于值函数分解系列方法[9-11],采用集中式训练和分布式执行训练模式[12].在这种模式下,所有智能体在训练时被统一集中控制,执行过程中各个智能体被单独控制.
本文在值分解框架的基础上进行改进,对于维度爆炸问题,本文训练的所有智能体网络参数共享.而对于其他智能体的存在,会导致训练不稳定现象.本文的应对方案是对其他智能体的策略进行建模,利用这部分信息可以让智能体处在相对稳定的环境下进行训练.
本文为每个智能体增加额外的公共网络,将历史表现最优的策略网络保存下来.在智能体网络参数共享的情况下,历史性能最优的网络即代表最优的策略,可以预示智能体将来所要达成的目标.智能体网络训练最终目的为获取最优策略,因此历史最优网络能够推测出其他智能体的未来信息.本文将历史最优网络命名为意图网络,从意图网络得到的信息称为意图信息.因此整合这些意图信息作为交流信息,可以让交流信息包含不同时间段最优网络对当前状态的指导信息,智能体也可以在最初时,有更多的基础信息筛选.而历史最优网络是通过测试过程中智能体每一局平均得分的高低来筛选.本文将这部分意图信息和观测信息整合起来,并基于注意力机制进行信息提取,继而利用整合提取后的信息进行决策,加速智能体之间的合作学习.对于历史最优网络是否可以代替意图网络,本文在小规模的修改版捕食者游戏上,从内在奖励方面来验证意图网络的可行性.
本文为每个智能体之间增加了交流通道,通过沟通,帮助智能体学会更好地合作.传统的交流方法有直接固定交流信息、交流离散信息或对于连续交流信息做一个简单的加和,这些方式过于简单,不适用于复杂的合作任务.智能体收到的交流消息会随着智能体数目的增加而增加,过多的消息反而会引入一些干扰信息,不利于智能体的决策.因此本文提出为每个智能体增加一个交流通道,智能体间的交流信息采用多头注意力机制进行提取.这种基于注意力的交流模式可以更好地处理智能体数目的变化,具有良好的可扩展性,智能体的交流网络结构采用门控循环单元(Gated recurrent unit,GRU)[13]神经网络.
本文采用集中式训练、分布式执行的训练框架,提出面向部分可观测合作问题的多智能体注意力意图交流学习算法(Multi-agent attentional intention and communication,MAAIC).在训练过程中,利用额外的意图信息使训练更加高效,同时改善了智能体间的交流信息结构.本文算法的主要贡献有:
1)增加额外的公共网络,保存其他智能体的历史时刻最优策略,为智能体决策提供了额外的信息来源;
2)采用注意力机制,对意图信息和交流信息进行处理,从而能够提取到更为有效的信息;
3)验证增加意图网络的可行性,从内在意图奖励角度,对智能体意图信息的可靠性提供理论依据.
本文结构安排如下: 第1 节介绍相关工作;第2 节介绍背景知识;第3 节详细介绍本文算法的结构,包括组成成分与训练过程;第4 节为具体实验分析;第5 节总结研究结果.
1 相关工作
继单智能体领域取得卓越的性能后[14],研究人员转而朝向更有难度的多智能体环境上[15-16].最简单的多智能体学习方法是每个智能体独立训练学习,早期的尝试是IQL[17],但一般在实际应用中表现不好,由于其实现简单而且随着智能体数目的增加仍然具有很好的扩展性,因此很多问题都是用独立智能体学习作为基线来进行实验对比.
对于多智能体合作任务[18-19]的研究算法,2017年,Lowe 等[20]提出多智能体深度确定性策略梯度,将深度确定性策略梯度扩展和应用到多智能体领域,每个智能体都有自己的动作和评论者网络.在训练阶段,评论者能够拿到所有智能体的动作,因此能够用于混合环境下每个智能体都有自己局部奖励的问题.在多智能体深度确定性策略梯度基础上,基于存储的多智能体深度确定性策略梯度[21]算法提出了共享内存作为一种交流模式,比另一种受到信息丢弃启发的多智能体深度确定性策略梯度[22]算法,具有更好的鲁棒性.
另外一种处理全局奖励信用分配问题的方法是值函数分解,2017 年,Sunehag 等[9]提出值函数分解网络(Value-decomposition networks,VDN)算法,将一个全局的Q函数分解成智能体的局部Q函数之和.Q混合网络(Qmixing network,QMIX)[10]在VDN 的基础上,添加了一个混合网络,为分解添加了非线性部分,并且保证全局Q函数对于局部Q函数是单调的.反事实多智能体[23]算法利用反事实基线,去衡量智能体在全局奖励中所做的贡献.然后,为适用于QMIX 中满足了分解条件且不满足单调性的任务,Q因式分解(Q-transformation,QTRAN)[24]算法弱化了QMIX 的结构约束,从而能够处理更加通用的任务.Q注意力算法[25]从理论上给出一种通用的值函数分解方式,基于多头注意力显式建模智能体对整体的影响,并将这种影响引入混合网络中,实现了一种更精确的值函数表示.Q路径分解算法[26]提出一种利用积分梯度技巧,沿轨迹路径分解全局Q值的新的值分解方法,通过积分梯度衡量每个智能体对于全局Q值的贡献,将这部分贡献作为局部Q值进行监督学习.
在多智能体交流方面,2016 年,Foerster 等[27]提出离散和连续的智能体间交流两种方法,是最早在深度强化学习中引入交流信息,旨在缓解离散交流通道的问题,是深度Q网络(DeepQ-network,DQN)和IQL 的结合应用到多智能体问题上.同年,Sukhbaatar 等[28]提出简洁的交流网络(Communication neural net,CommNet),使用了一个连续的交流通道,智能体接受从其他智能体传来的信息之和,算法允许多步交流,梯度能够通过连续交流通道回传给各个智能体.双向协作网络[29]提出双向循环网络构建每个智能体,智能体之间并不显示交流信息,而是发生在隐藏空间.2018 年,Singh 等[30]提出的独立控制连续通信模型,为每个智能体添加一个门控,决定是否同其他智能体进行交流,从而让智能体学会更好地交流.
在筛选有效信息方面,注意力模型作为一种成功的方法,被广泛应用于计算机视觉[31]、自然语言处理[32]和强化学习.2018 年,Jiang 等[33]提出的注意力协作算法,可以让智能体选择是否进行通信和同哪些智能体进行通信.有目标的多智能体交流(Targeted multi-agent communication,TarMAC)[34]通过基于签名的软注意力机制来衡量消息的相关性,并进行多轮的交流.两步注意力图网络[35]算法使用两阶段注意力网络模型,分别利用硬注意力机制、确定交互的智能体和软注意力机制,确定交互的权重,自动学习大规模复杂游戏中不断变换的智能体间关系.
在多智能体建模领域,以前的研究多是通过观测学习其他智能体的模型.2018 年,Raileanu 等[36]提出的自身模仿其他智能体算法,利用自身策略,去预测对手的动作,从而推断其他智能体的目标信息,再利用这部分目标信息做决策.对于那些共享目标任务,自身模仿其他智能体算法具有很好的表现.社会性影响方法[37]是通过一种统一的方法,去实现多智能体的协调和沟通,即给予智能体对其他智能体的行为产生因果影响的内在奖励.但这两种方法都需要额外地使用监督学习方法,去训练这个预测网络.
这些交流算法大多局限于当前时刻策略网络的隐藏层信息.本文算法通过增加意图网络,扩大了交流信息的来源,且选择经典值分解系列的算法流程作为基础框架,从意图信息模块和交流模块两个角度进行改善,提取出有效的交流信息,使智能体更好地协作.相比于自身模仿其他智能体算法,本文的意图网络是直接从历史上挑选出最优策略网络,不需要额外训练网络.
2 背景知识
多智能体强化学习涉及多个智能体和多个状态,是马尔科夫决策过程和矩阵博弈的结合,其中马尔科夫决策过程包含一个智能体和多个状态,矩阵博弈包含多个智能体和一个状态.多智能体强化学习的发展与博弈论[38]是分不开的,部分可观测的多智能体合作问题可被定义如下:<N,S,A,R,P,O,γ>,其中N是智能体的数目,S代表全局状态空间,A={A1,···,AN}是所有智能体的动作空间,R是奖励函数,P:S×A1×···×AN→S是环境状态转移函数,O={O1,···,ON}代表所有智能体的观测空间,γ是折扣因子.智能体i的策略:Oi×Ai→[0,1],智能体πi执行在时刻t动作后,会从环境中获得奖励本文在纯合作任务上进行研究,此时所有智能体获得的奖励相同即整个任务目标为智能体学到最优合作策略,从而最大化累计回报G=
VDN 算法是基于深度循环Q网络提出的值分解结构,能够在仅有全局收益情况下,去学习不同智能体的动作价值函数,从而缓解由于部分可观测导致的伪收益和懒惰智能体问题.VDN 的值分解函数如下:
QMIX 是在VDN 基础上进行的改进版本,采用一个混合网络,对局部智能体函数进行合并,并且在训练过程中,利用全局状态信息为混合网络提供正向权重.本文对于联合动作值取arg max 等价于对于每个局部动作值函数求arg max:
QMIX 将上式转换成为一种单调性的约束,这种约束通过混合网络实现,其中约束如下:
3 多智能体注意力意图交流算法
为了更好地处理多智能体交流合作问题,保证交流信息的充分性和有效性,本文提出MAAIC 算法,为每个智能体增加能够表示其他智能体意图的网络信息输入,同时使用注意力机制对意图信息和交流信息进行处理.本节首先对算法思想和算法整体框架进行详细阐述;然后,介绍多个意图网络注意力单元、多头注意力的交流结构和算法的整体训练流程;最后,进一步探究意图网络的影响.
3.1 MAAIC 算法框架
在多智能体合作问题中,在已知其他智能体状态与动作以及自身策略的信息基础上,若能够知道其他智能体的目标,就能更好地推测出其他智能体的意图.基于此,本文选取智能体历史上表现最好的网络结构,这些网络中间层信息能够表示智能体的意图目标,通过对这些意图进行注意力机制提取,从而得到更加有效的信息.将这部分信息加入到自身的决策中,能够提升智能体的决策能力.
本文提出的多智能体注意力意图交流学习算法框架见图1,共分为3 个阶段.第1 阶段是对信息特征的处理.提出为智能体增加公共意图网络,这些意图网络是由近阶段表现最好的网络复制而来.首先将观测输入到全连接(Fully connected,FC)层得到初步的特征,然后通过GRU 循环神经网络,对智能体的局部观测和动作进行处理,得到包含历史的状态动作信息,将这部分信息与通过意图网络得到其他智能体的意图信息进行注意力机制提取,得到包含意图信息的状态信息.第2 阶段是交流模块.智能体之间增加多头注意力机制的交流通道,每个智能体将交流信息广播出去,智能体根据自身信息和接收到其他智能体传来的交流信息进行多头注意力信息的提取,从而得到对自身决策有效的信息输入给GRU 单元.为了让交流信息更加充分,智能体作出决策前,会同其他智能体进行多次迭代交流.第3 阶段将经过意图和交流提取到的高层信息,经过一个全连接层,得到智能体当前状态下的局部Q值函数,进行一个简单的加和操作,得到整体Qsum值求和函数.
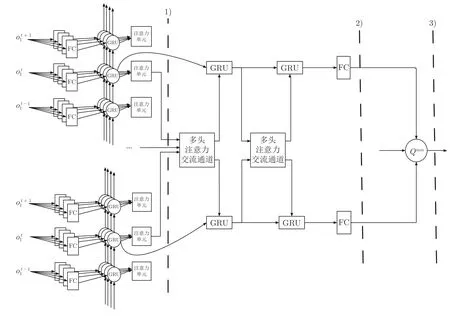
图1 MAAIC 算法框架Fig.1 Overall framework of MAAIC algorithm
在上述算法框架中,所有智能体都共享同一套网络参数,根据不同时刻的观测输入和智能体编号的不同,能够得到不同的信息.本文每个智能体的网络参数共享,主要有两个原因: 1)大部分多智能体问题是一个开放的系统,智能体进入或退出都有可能发生,那么此时如果用独立的网络去训练智能体,训练出来的网络容易对环境中智能体数目过拟合,很难泛化;2)对多智能体环境,如果采用独立的智能体网络,需要很大精力去训练出一个好模型,随着智能体数目的增加,甚至有可能训练不出一个好模型.为了缓和部分可观测带来的问题,同时也会将智能体的动作和交流信息传入下一时刻的智能体信息中.第2 阶段交流模块所要经过的2 个GRU 循环神经网络也可以共享参数.因此,本文使用1 个GRU 循环神经网络来循环迭代交流.
整个网络的流程运行过程为: 智能体当前时刻得到观测后,首先,经过全连接层提取信息;然后,经过GRU 循环神经网络,得到包含过往历史的观测信息,这部分历史观测信息在和过往的意图网络信息先做一个注意力机制信息提取后,再同其他智能体进行一个多头注意力机制的信息交流;在信息交流后,经过一个全连接层,从而得到智能体的状态动作值函数;最后,将这些状态动作值函数相加,利用DQN 的训练模式来学习策略.
3.2 意图网络的注意力机制
为了缓和多智能体环境不稳定的问题,可以采取许多办法,其中对其他智能体的行为进行建模,推测出其他智能体的意图,相比于简单地将其他智能体当作环境的一部分,更有帮助.认知科学研究发现,人类使用与他们相交互的其他群体的目标、信念和喜好来帮助他们更好地做决策.其中,人类会从对他人的观测中模拟他人行为,这种脑部过程能够帮助他们更好地知道他人的意图和行为,从而在社会环境中作出正确行为.
式中,σ和tanh 代表要训练的权重矩阵和偏置.r和z代表重置门和更新记忆门,从而更好地利用历史信息,缓和局部观测问题.
在训练过程当中,有些历史阶段的网络能有好的表现,也就是从一定程度上说明网络能够表示出智能体更好的意图,因此将这些网络结构的参数保存下来,再利用这些网络对当前时刻智能体的观测做进一步的信息补充,从而让智能体能够更好地利用以往经验进行学习.本文提出的多智能体注意力意图交流学习算法为每个智能体增加三个意图网络,如图2 第1 阶段,其中线性层Linear(Q)表示Q为一个线性层,Linear(K)和Linear(V)也是线性层.这样对当前时刻智能体的观测就得到一个信息向量其中代表当前网络的信息,代表历史网络的信息,该向量能够在一定程度上表示出对其他智能体的意图理解信息.
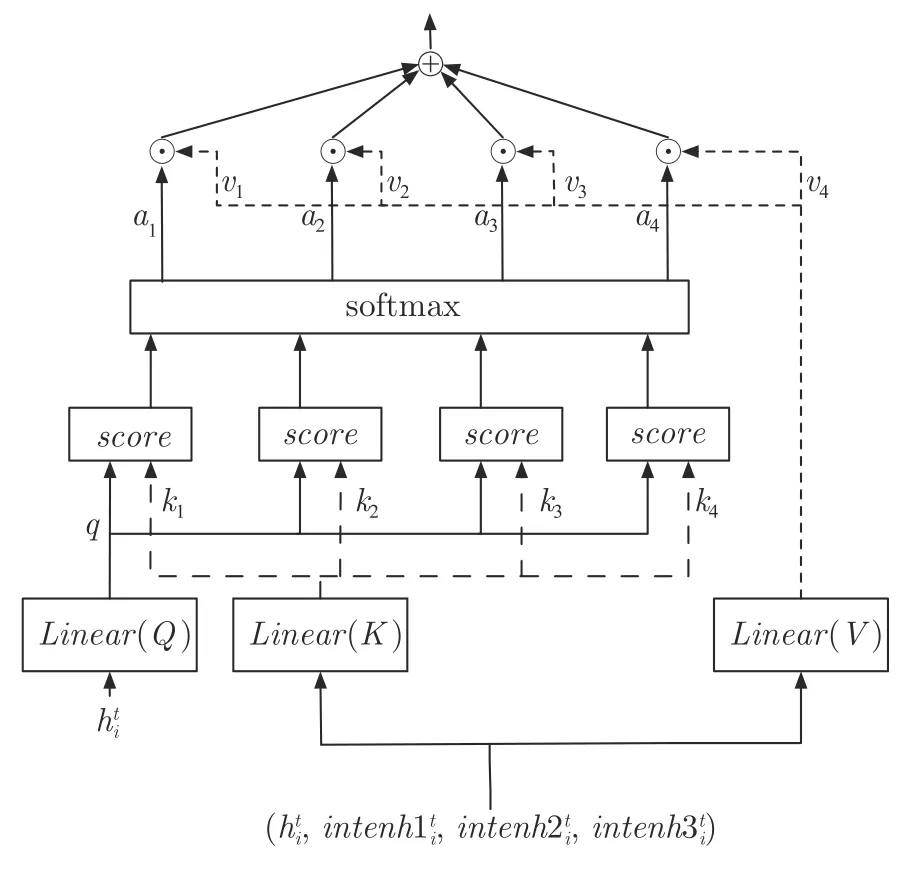
图2 对意图网络进行自注意力信息的提取Fig.2 Extracting self attention information from intention network
3.3 交流信息的注意力机制
交流是一种重要的获得信息方式,作为智能体的一种必要手段,能够帮助从其他智能体的经验中学习,在部分可观测环境中,交流能够帮助传递其他智能体的观测信息,从而能够去缓和多智能体环境不稳定问题.本文研究致力于为星际争霸这样复杂的环境,寻找更好的处理方案,让交流发生在隐藏空间,进而让高层次信息能够传递到各个智能体中,以及让每个智能体得到的策略梯度能够回传到整个网络中.
在多智能体合作环境下,智能体agent0接受环境的观测通过自身的网络输出相应动作根据当前状态执行完动作后,环境给出一个集体奖励.集中式训练分布式执行的多智能体同环境交互见图3,智能体间可以选择是否利用有限通道进行交流信息.本文从另一个角度出发,为了更好地利用交流信息,考虑到在不同时刻,当前智能体策略对于其他智能体的关注点是不一样的,因此在交流信息上选择使用注意力模型,通过给其他智能体的交流信息分配不同权重,提取出有效的交流信息.
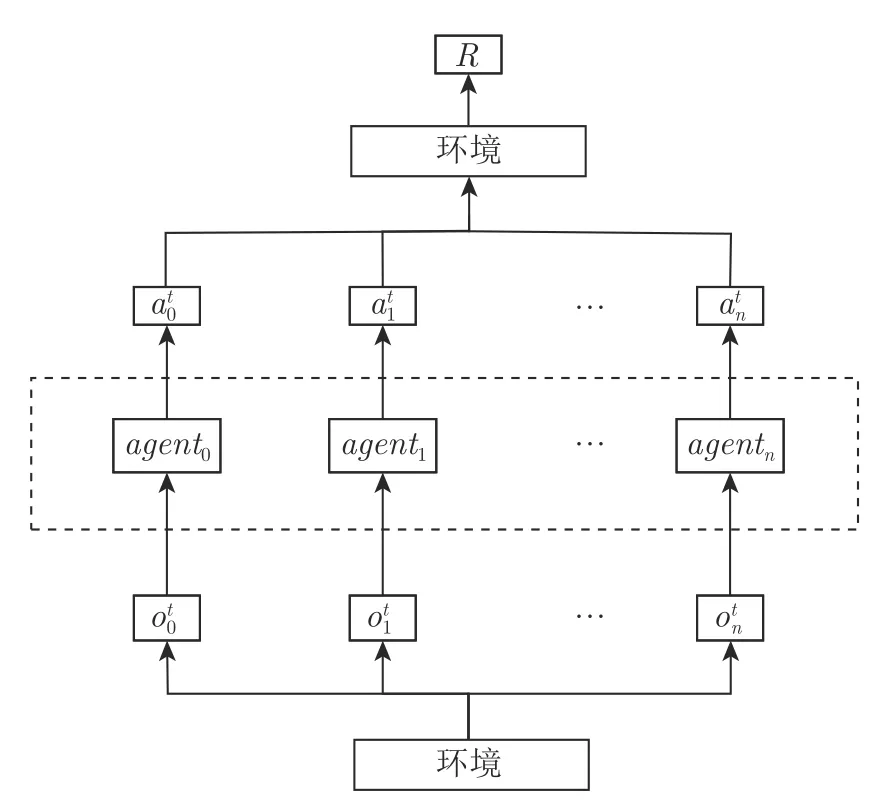
图3 基于集中式训练分布式执行的多智能体同环境交互Fig.3 Multi-agent interaction with environment under centralized training and decentralized execution
本文智能体间交流信息计算采用多头注意力模型,相比于单头注意力模型,多头注意力模型本身为多个注意力的计算,彼此之间相互独立,起到一个集成的作用,防止出现过拟合.本文选择GRU 神经网络处理智能体交流,智能体间的交流可循环迭代k个时间步,GRU 网络隐藏层状态来自前一阶段GRU 隐藏层状态输出.考虑到智能体在实际问题中发送交流信息是需要一定时间的,如果同步处理交流信息,每次需要等到所有信息都发送过来,决策效率必然不高.因此实现交流信息时,一般采用异步处理即当前时刻接受前一时刻的交流信息进行处理,并且输出下一时刻的交流信息.交流通道使用的多头注意力模型见图4.交流信息c的计算公式见式(6),其中Q、K、V根据交流时刻以及决策时刻存在不同的情况,本文采用8头注意力模型,映射权重矩阵为其中dmodel为智能体意图融合向量的维度,dk为每个注意力头部的维度.
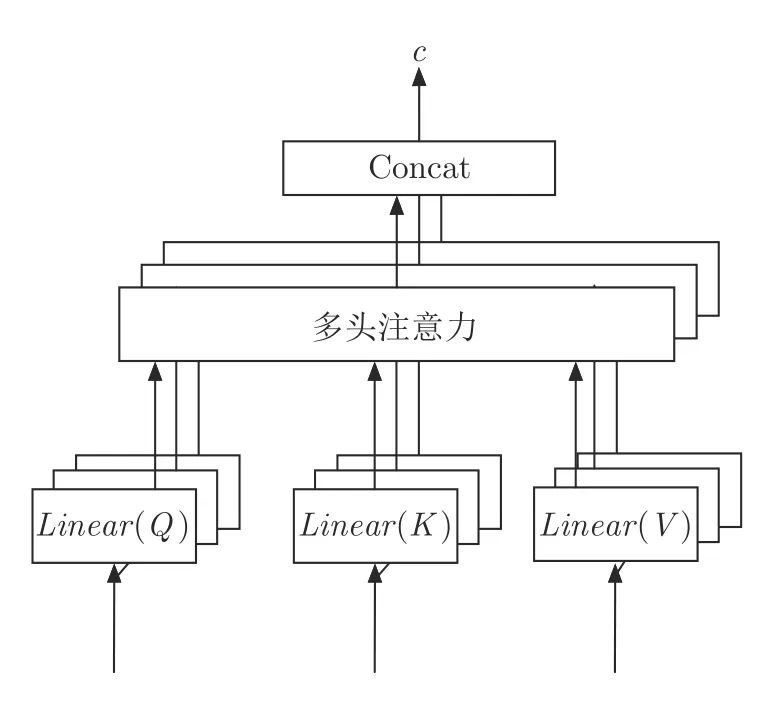
图4 交流通道使用的多头注意力模型Fig.4 Multihead attention model used in communication channels
本文在每个决策时刻,智能体之间可以交流k时间步,每次交流的计算流程如下:
式中,t表示当前决策时刻,k代表交流时间步,智能体之间最多进行k步交流.矩阵A由每个智能体经过意图网络注意力模型的输出构成,矩阵H由每个智能体经过GRU 得到的隐藏层状态构成.在本文提出的智能体交流结构中,智能体会将上一时刻经过交流单元GRU 后,得到的隐藏层信息加入当前时刻,进行一个注意力的提取,从而使整个智能体的决策与过去的信息更加紧密地结合起来.交流信息c的计算共分为3 种情况: 1)智能体第1 次同环境进行交互做决策,在t=0 且k=0时刻,此时智能体没有前一时刻的交流信息,输入给多头注意力交流通道的信息为 (At,At,At).2)智能体在t>0 且k=0 时,此时智能体的交流信息是由上一决策时刻的隐藏层向量给出.在k=0 时刻,智能体需要利用意图观测信息进行注意力的提取,此时多头注意力单元的输入为3)当交流时间步k>0,此时输入由当前时刻上一交流时间步的隐藏层信息构成.
3.4 网络结构更新
本文算法采用离线更新方式,将多个智能体同环境进行交互的状态、动作、奖励、终止状态等数据放到经验池中,每次从经验池中选取批量完整的每局游戏过程进行学习.算法同DQN 一样,构建一个目标网络,每隔固定周期,将当前网络参数复制,用于计算下一时刻状态值,用自举方式对状态值进行更新,能够加速收敛并且有助于算法的稳定.算法的损失函数loss为:
多智能体注意力意图交流学习算法的流程见附录A 中算法1.该算法是基于Q值算法,在算法训练过程中,通过对损失函数最小化,找到最优价值函数估计,最优策略来自对动作空间遍历后的最大Q值动作.在智能体学习过程中,会不断根据评估时刻智能体的表现,将性能更好的网络替换过往的意图网络.
3.5 内在意图奖励
针对本文的一个最主要的假设,意图网络是可以短暂地作为最优策略网络,本文从内在奖励方面研究意图网络的影响,为意图信息的有效性提供理论依据.修改智能体i做出动作后得到的即时奖励:
计算内在意图奖励需要知道智能体当前策略网络与意图网络在环境状态下作出的行为,一种直观的奖励方式可以是当两者的行为a一致时,给出正向奖励然后,它可以奖励自己采取它认为最具影响力的行动.这是一种自然而然的方式,因为它类似于人类思考自己对他人的影响方式.
本文设置了多个意图网络且多个智能体是共享网络,得到的反馈是团队奖励,因此只有当所有智能体行为都与意图网络行为一致时(多个意图网络只要有一个满足要求即可),才会有内在意图奖励.在t时刻得到的奖励为:
式中,o和a是所有智能体的观察和动作,QIntention代指多个意图网络中的一个.
4 实验
4.1 环境简介
在经过精心设计的SMAC 游戏场景中,智能体必须学会一种或多种微管理技术,才能击败敌人.每个场景都是两支部队之间的对抗,每个部队的初始位置、数量、类型都随着场景的不同而发生变化.其中第1 支部队是由本文算法所控制的智能体构成,第2 支部队是内置游戏人工智能控制的敌方构成.本文算法所使用的SMAC 实验场景如表1 所示.SMAC 环境下具体算法参数设置见附录B.

表1 SMAC 实验场景Table 1 Experimental scenarios under SMAC
在每个时间步长,每个智能体都会获得其视野范围内的局部观测结果,其中包含了每个单元圆形区域内的地图信息.具体地,每个智能体得到的特征向量包含视野范围内的友军和敌军的属性(如距离、相对x、相对y、健康、盾牌、unit_type),其中盾牌是能够抵消伤害并可以在一段时间后重新生成的.同时,特征向量也包含周围地形特征以及可观测到友军的最后行动.在本文的局部观测中,智能体的观测无法区分其余智能体是不是在视野范围,还是已经死亡.
4.2 实验结果分析
首先,给出本文的多智能体注意力意图交流学习算法在SMAC 五个实验场景下,同基准算法的对比实验结果(见图5),其中MAAIC-VDN 是本文的多智能体注意力意图交流学习算法;然后,对这些实验结果进行分析.
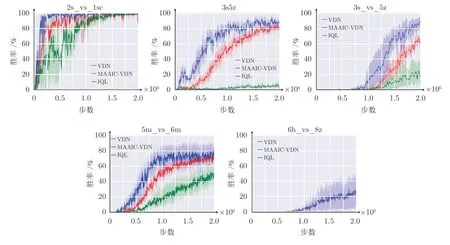
图5 MAAIC-VDN 算法在SMAC 上的实验结果Fig.5 Experimental results of MAAIC-VDN algorithm on SMAC
实验场景任务目标是要学会让我方单位战胜敌方单位,因此本文选取游戏胜率作为最终评估目标.在算法训练过程中,每间隔evaluate_cycle次,算法会对智能体学习到的策略进行评估.智能体会在相应场景游戏下进行evaluate_epoch轮的游戏测试,通过统计胜利次数给出我方的游戏胜率.为了不失一般性,算法采用不同的随机种子,进行4 次重复实验,且使用95%的置信区间.每次完整训练进行n_epoch次数,训练结束后会得到n_epoch/evaluate_cycle个游戏胜率数据用于绘制实验结果图.
图5 给出了5 个场景下,本文多智能体注意力意图交流学习算法MAAIC-VDN 的对比结果,其中2s_vs_1sc 和3s5z 是简单场景,算法能够获得比较高的胜率;5m_vs_6m 和3s_vs_5z 为困难场景,算法需要学到更好的合作策略才能够取得胜利;6h_vs_8z 是超级困难场景,需要更长的训练时间以及需要学会更好的获胜技巧.由图5 可以看出,本文算法MAAIC-VDN 在所有场景下的收敛速度明显优于其他基线算法,并且性能表现是最好的.本文算法在场景3s5z 和3s_vs_5z 上,相比于VDN 获得了一定的性能提升,特别是在超级困难场景6h_vs_8z 中,在其他算法都已经失效的情况下,仍然获得了25%左右的胜率.IQL 除了在简单的场景2s_vs_1sc 上,能够最终获得和其他算法同样的性能,在其他的场景下的结果,都远远不如VDN 和MAAIC-VDN,说明独立学习的智能体在复杂环境不能够表现出好的合作策略.VDN 算法在2s_vs_1sc、3s5z、3s_vs_5z、5m_vs_6m 上,都能获得不错的性能,但是在复杂场景6h_vs_8z 中,基本没有学到任何策略.
同样在QMIX 算法上修改,图6 给出了在5 个场景下,本文多智能体注意力意图交流学习算法MAAIC-QMIX 算法与QMIX 和IQL 算法在SMAC 上的实验结果,其中在简单场景3s5z 和困难场景3s_vs_5z 下,MAAIC-QMIX 算法相较于其他算法收敛更快,最终结果也更好.在超级困难场景6h_vs_8z 中,其他算法结果都接近零,而本文算法获得了20%左右的胜率.图7 给出了5 个场景下,基于QTRAN 算法的多智能体注意力意图交流学习MAAIC-QTRAN 算法在SMAC 上的实验结果,可以看出,相较于其他基线算法,MAAICQTRAN 算法性能都有显著提升.其中,所有算法在简单场景2s_vs_1sc 最终都能取得百分百胜率,而本文MAAIC-QTRAN 算法收敛更快.值得注意的是,在场景3s_vs_5z 下,QTRAN 算法由于其对约束条件的放松,性能不佳,而本文MAAIC 方法可以让智能体快速地找到最优策略.
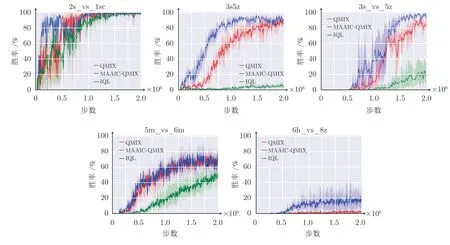
图6 MAAIC-QMIX 算法在SMAC 上的实验结果Fig.6 Experimental results of MAAIC-QMIX algorithm on SMAC
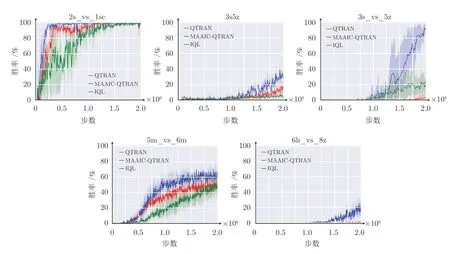
图7 MAAIC-QTRAN 算法在SMAC 上的实验结果Fig.7 Experimental results of MAAIC-QTRAN algorithm on SMAC
表2 给出了测试算法的最大中值实验结果,最大中值为训练过程最后 2 50k步得到的所有测试结果.实验结果表明,启发式(Heuristic)算法即攻击最近敌方单位策略算法,性能是最低的.而在基础算法框架上应用本文MAAIC 方法,智能体之间能更好地协作,获取更高性能.除了2s_vs_1sc 外,IQL 的胜率很低,这是因为直接使用全局奖励更新策略会带来非平稳性,当智能体数量增加时,这种非平稳性会变得更严重.QTRAN 算法的表现也不是很好,是因为实际场景下的宽松约束可能会阻碍其更新的准确性[25].

表2 测试算法的最大中值实验结果 (%)Table 2 Maximum median performance of the algorithms tested (%)
在两个基线算法上加入本文的多智能体注意力意图交流模型,其最终实验结果和收敛速度在大多数场景中都有明显的提升,显示了本文算法能够从意图信息中学习到更多知识.
乔瞧也把藕挑起来了,不过,她挑起来的藕都是断的。踩藕人见了,就说:“乔瞧你不要踩了,你踩出来的藕都断了,卖不出好价钱。”
4.3 消融实验
本文进行三个方面消融实验分析: 1)对交流结构的消融实验.对比算法为去掉意图网络结构,保留本文的多头注意力多步交流模块的VDN with Tar-MAC 算法和去掉本文的交流信息的网络结构,换成CommNet 的交流结构的VDN with CommNet算法;2)对意图网络数目的消融性实验.对比了1、3、5 个意图网络的MAAIC 算法;3)对比历史最优网络[40]与历史最近邻网络[41],哪个作为意图网络更好,本文采用的是历史最优网络作为意图网络.
首先,验证本文交流结构消融性的实验结果见图8.由图8 可以看出,在6 个场景下,VDN with CommNet 性能是最差的,说明本文多头注意力交流结构能够在复杂环境中提取到有效信息,智能体如果只是简单地拿到所有智能体信息,简单求和反而会让策略变差.算法VDN with TarMAC 除了在场景3s5z 性能与本文算法相当,在其他场景下,MAAIC-VDN 算法性能表现最好.由场景2s_vs_1sc 可以看出,含注意力交流模块的VDN with TarMAC 算法收敛速度和多智能体注意力意图算法是一样的,相比CommNet 交流结构,收敛速度更快,说明本文多头注意力交流模块对于提升收敛速度很有效.由场景5m_vs_6m 和场景3m 可以看出,多智能体注意力意图相比于没有意图的VDN 算法,性能要好一些,从而说明本文提出的意图网络结构与注意力交流结构结合,能够帮助改善算法性能.在3s_vs_5z 和6h_vs_8z 场景下,本文算法无论是收敛速度还是性能,都比其他的交流结构要好.这表明,从额外的意图网络中提取意图信息作为交流信息,比只在当前内部网络提取交流信息,更具有价值,验证了本文的多个意图网络和注意力交流模型的有效性.
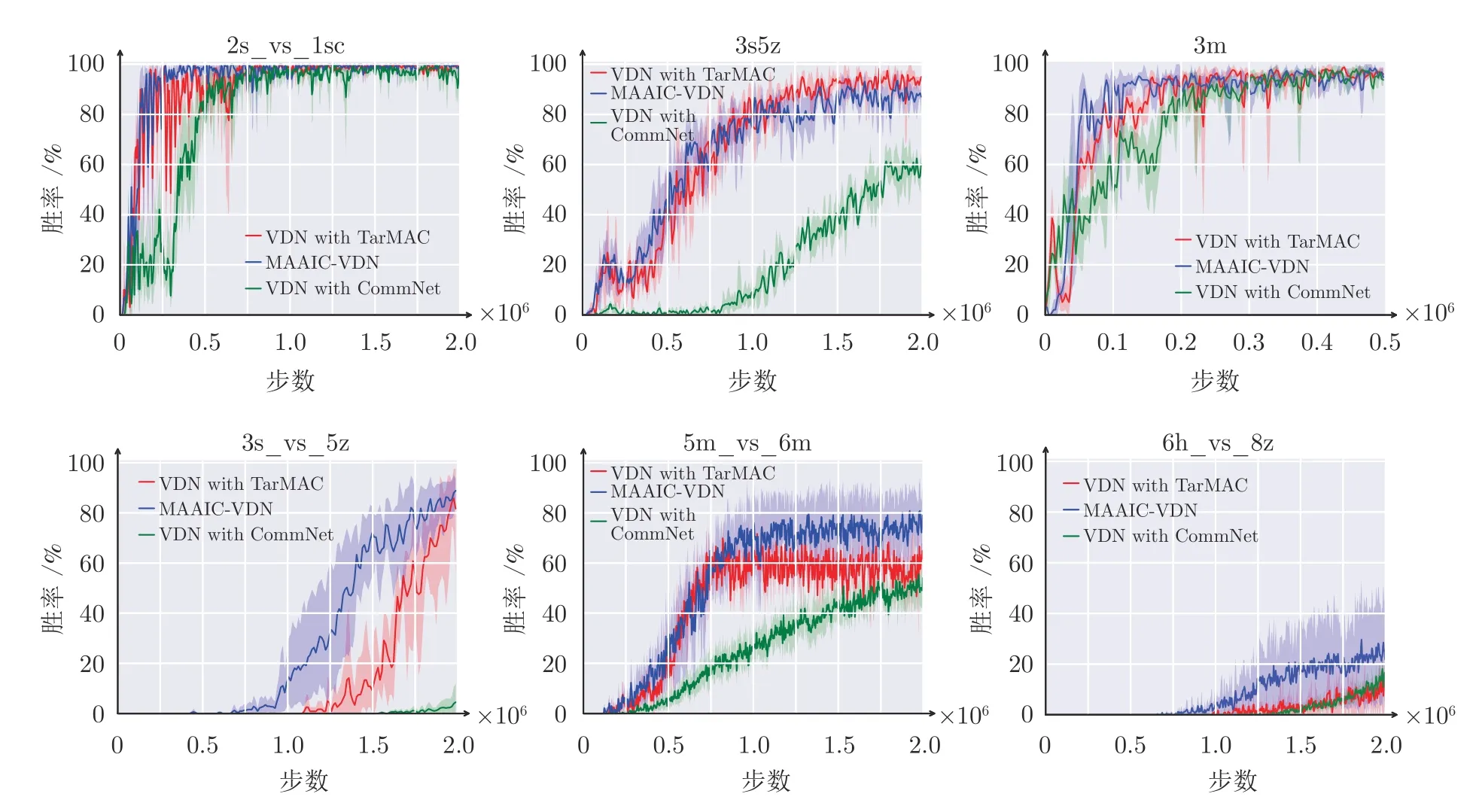
图8 交流结构消融性实验结果Fig.8 Experimental ablation results of the communication structure
接着,验证意图网络数目对于性能的影响,在SMAC 的3 个实验场景下,图9 给出了1 个意图网络、3 个意图网络和5 个意图网络的消融性实验结果.由图9 可以看出,在简单场景2s_vs_1sc中,意图网络数并不影响最终性能,算法都能很快地收敛到最好结果.由场景3s_vs_5z 可以看出,5 个意图网络的性能大于1 个意图网络和3 个意图网络性能.在场景5m_vs_6m 中,3 个意图网络性能最优.在3 个场景下,有意图网络算法性能收敛都是比基线VDN 算法要快且大多数最终结果也更好.由实验结果可以看出,意图网络对算法性能有明显提升,能够处理应对复杂问题且多个意图网络性能优于1个意图网络.
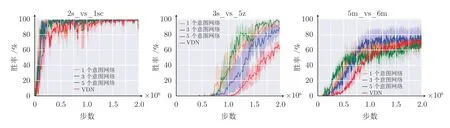
图9 意图网络数的消融性实验结果Fig.9 Experimental ablation results of the number of intention networks
表3 为本文训练1 000 轮后,MAAIC-VDN 算法在不同意图网络数的GPU 上内存开销,表3 中数值为运行多次求平均值且去掉个位数得到的结果.图10 为MAAIC-VDN 算法在不同意图网络数的时间开销,纵坐标是平均每局所消耗的时间,本文选择在场景2s_vs_1sc 下测量,这是由于所有算法都可以快速找到最优策略.为了减少其他变量干扰,本文只在1 个GPU 运行且只运行单个程序.VDN 算法内存开销和时间开销都是最小的,而添加注意力机制的交流模块且无意图网络VDN with TarMAC算法的内存和时间开销大幅度增加.随着意图网络数量的增加,MAAIC-VDN 算法的内存和时间花费也越来越大,总体上呈现线性增长.其中注意力机制交流模块是必不可少的,因此,本文在衡量算法性能与消耗情况下,选择使用3 个意图网络.

表3 MAAIC-VDN 算法在不同意图网络数的GPU 内存开销 (MB)Table 3 GPU memory cost for different numbers of intention networks based on MAAIC-VDN algorithm (MB)
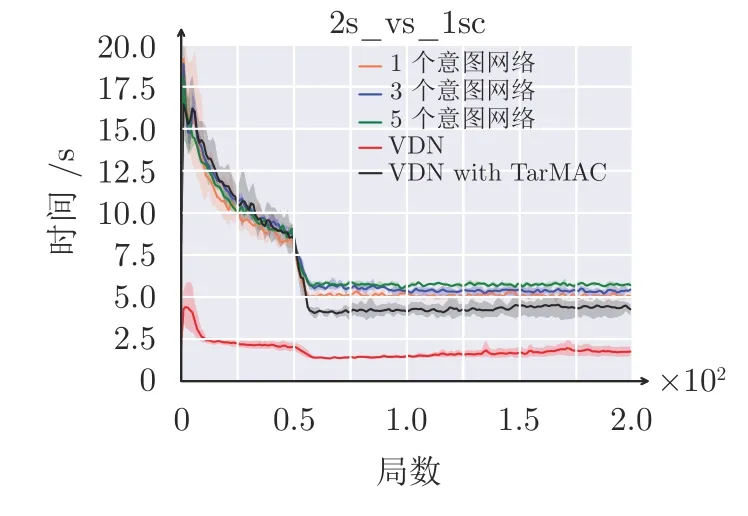
图10 MAAIC-VDN 算法在不同意图网络数的时间开销Fig.10 Time cost for different numbers of intention units based on MAAIC-VDN algorithm
图11 给出了历史最优网络作为意图网络和历史最近邻网络作为意图网络2 个算法的消融性对比实验.可以看出,在3 个场景下,2 个算法相比于算法VDN,其收敛速度和最终性能结果更好.本文采用的历史最优网络作为意图网络算法,在3 个场景中性能表现最优,这表明了使用历史最优网络作为意图网络,得到的意图信息更为有效.
4.4 内在意图奖励实验
为了更好地探究意图网络的作用,本文单独在小规模的球形环境(即修改版捕食者(Modified predator-prey,MPP)游戏)验证意图网络的性能,实验参数见附录C.修改的捕食者游戏比经典的捕食者游戏更复杂.两者状态空间和行动空间的构造是相同的,捕获猎物就相当于将猎物置于代理人的观察视界内.修改的捕食者游戏将经典的捕食者游戏扩展到只有当多个捕食者同时捕获猎物时,才会给予积极奖励,这需要更高程度的合作.如果两个或两个以上捕食者同时捕获猎物,捕食者将获得+1的团队奖励,但如果只有一个捕食者捕获猎物,捕食者将获得负奖励P.
图12 给出了2 个智能体、不同惩罚值P下VDN与本文VDN-Intention 的内在意图奖励实验结果,其中意图网络数为3.图12 中,每个算法都绘制了5 次测试的平均奖励和95%的置信区间.可以看出,基线算法VDN 随着惩罚值P的增大,训练难度增大,得到的奖励减少.而本文VDN-Intention 算法是在VDN 基础上,只增加了内在意图奖励,没有额外添加注意力机制和交流结构,可以看出,与基线算法VDN 相比,有较大的性能提升.即使惩罚值P很大,VDN-Intention 算法中智能体还是能很好地合作捕捉猎物.这充分表明本文最主要假设的可行性,即意图网络是可以短暂地作为最优策略.因此,在大型复杂环境下,可以从意图网络中抽取意图信息,帮助智能体更好地决策.
5 结束语
本文提出一种意图存储机制,引入额外的公共网络保存历史表现最好的策略网络,以此建模其他智能体的意图信息.同时引入交流模块,采用多头注意力机制提高整个网络的表示能力.本文的多智能体意图交流算法可以充分利用过往局部最优网络信息,扩大了信息的来源渠道.最后,将本文的多智能体注意力意图交流学习算法分别在开源的星际争霸任务场景上和捕食者环境上进行验证和分析,并同领域内的经典算法进行对比,验证了本文算法的有效性.通过在星际争霸环境上的消融性实验分析,验证了本文提出的多智能体注意力意图结构和多头注意力交流结构的可行性,并通过内在意图奖励方式,验证了意图网络提供意图信息的可靠性.
附录AMAAIC 算法
算法1.多智能体注意力意图交流学习算法
附录BSMAC 环境下算法参数设置
为了能够更好地分析本文提出的多智能体注意力意图交流学习算法的性能,本文在SMAC 多个不同复杂度场景下进行实验.本文的多智能体注意力意图学习算法的网络结构参数见表B1.
首先,环境初始化后会构建N个智能体的控制器,其中对于本文算法,N个控制器的网络参数是共享的,区别只是在于自身的观测输入和编号信息是不一样的.在控制器网络中,每个智能体将自身的观测输入和过往的动作信息等经过1 个FC 层的编码和ReLU 函数激活,然后经过GRU 循环神经网络的编码,得到当前对于观测的信息输出,其中在增加了3 个意图网络后的维度输出为(4,N,rnn_hidden_dim),这部分包括现实信息和三部分意图信息,对这部分信息进行注意力提取,最后得到(N,attention_dim1)信息,代表每个智能体各自针对观测和意图信息的融合所生成的更高层次特征.
接着,进行多智能体间的交流,其中本文采用8 头注意力机制处理交流结构信息.交流的信息经过多头注意力的提取为 (N,attention_dim2),通过GRU 循环神经网络经过k时间步交流,得到最终信息为 (N,rnn_hidden_dim).最后,这部分信息经过全连接层,输入动作空间维度大小的q值,大小为 (N,n_actions).
本文算法训练参数设置见表B2.智能体策略从控制器选取最大Q值对应的动作.多个智能体利用自身策略同环境进行交互,收集每集游戏的样本数据放到内存池中,从而通过从内存池当中选取一批数据,利用这些数据来训练智能体.在每段游戏中,智能体生成n_episodes样本数据,放入内存池中.根据DQN 的模式计算的当前Q值和下一时刻的目标Q值,首先,对所有的智能体将两个Q值分别求和;然后,求得损失l=(Q-(r+maxa Qtarget))2,将所有时刻、所有游戏集数的损失求和,得到总损失;最后,按照均方根传递(Root mean square prop,RMSProp)优化方法对损失进行优化求解.
附录C修改版追捕者环境下的算法参数设置
表C1 给出了修改版追捕者环境下训练的参数设置.每个独立的策略网络包含3 个隐藏层.所有隐藏层维度为64,激活函数为ReLU.其中智能体探索策略是保证游戏开始阶段,智能体更多地进行探索,随着训练持续进行,智能体学到了更多知识,智能体的探索会逐渐减少,最后维持在一个最小的探测概率ϵ∈[0.1,1],从而更有效地利用已学到的知识保证训练的稳定性和速度.最后,实验使用前馈策略且使用Adam 优化器进行训练.

表B1 MAAIC 算法网络参数Table B1 Network parameters of MAAIC algorithm
