基于多尺度特征融合网络的路面裂缝分割方法研究
2023-11-22李朝勇张成韦海丹
李朝勇,张成,韦海丹
广西防城港核电有限公司,防城港 538001
1 引 言
道路安全问题至关重要,路面裂缝是威胁道路安全的重要因素之一(翁飘等,2019)。传统的路面裂缝检测方法主要采用人工目视,这会耗费大量的人力物力,检测的精度也相对较低。近年来,随着影像技术的发展,使用路面裂缝采集设备采集路面影像,并使用计算机视觉算法从影像中提取裂缝的方法逐渐成为研究热点(Guan 等,2021;Chen等,2023)。在诸多计算机视觉算法中,主要有数字图像处理和深度学习两种方法(Cao 等,2020)。基于数字图像处理的方法主要为边缘检测、形态学等针对裂缝低级特征而设计的提取方法。如Chanda等(1998)提出了基于多尺度结构元素的形态学边缘检测,具有较强的抗噪性。Abdel-Qader 等(2003)将快速傅里叶变换、快速哈尔变换、坎尼算子、Sobel算子应用于裂缝检测中,结果表明快速哈尔变换对裂缝的检测效果最好,但该类算法对噪声仍很敏感。Yamaguchi 和Hashimoto(2007)提出了基于渗流模型的裂缝检测算法,该算法将各像素点在其对应的局部窗口内进行区域生长,根据生长的结果判断该像素点是否为裂缝点。此类研究多针对某一特定数据集的方法,模型的泛化能力较弱。
随着深度学习技术在图像处理领域的广泛应用,卷积神经网络在图像分类和目标检测领域取得了很大的进展。基于深度学习语义分割的裂缝分割方法因具有速度快、精度高、泛化能力强等特点,已成为路面裂缝分割任务中应用最为广泛的方法之一(Ali 等,2022)。语义分割是深度学习中广泛使用的目标检测技术之一,其中,广泛应用于裂缝分割的模型主要为编解码结构,该结构通过对图像中的每一个像素进行分类实现了目标的分割。基于此结构提出的模型有很多,如全卷积神经网络(fully convolutional network,FCN)、SegNet、U-Net(u-shaped network)等。FCN 由Long 等(2015)提出,使用反卷积结构及特征图相加的融合方式,实现了对物体的像素级分割。Yang 等(2018)使用FCN 进行裂缝的检测,达到了像素级别的分割效果。SegNet 由Badrinarayanan 等(2017)提出,该方法的特点在于不用保存整个解码部分的特征图,只需保存池化索引,节省了内存空间。Nguyen 等(2022)将该方法应用在混凝土裂缝分割任务中,实现了自动化、快速的裂缝分割。U-Net 由Ronneberger 等(2015)提出并应用于细胞分割的模型,率先使用了U 型结构的编解码结构的网络。Ju等(2020)在此基础上提出将U-Net 中的卷积层中加入填充,使卷积后的特征图像保持与卷积前的分辨率一样,更适用于细小尺寸的裂缝分割。Zhang等(2021)设计了拥有不同下采样和上采样层数的U-Net,并进行对比实验,分析了模型深度对裂缝分割效果的影响。
虽然基于深度学习的路面裂缝分割方法已经得到了广泛的应用,但现有的算法中仍存在一些问题。由于路面裂缝通常比较细小,所以在整幅路面影像中,裂缝的像素数相对全图像素数的占比通常较小,并且裂缝的形态通常为细长的,其宽度相对于全图宽度的占比也十分小。此外,编解码结构网络中频繁的下采样,导致其精度难以提升。鉴于此,本文提出了一种基于改进U-Net的编解码结构语义分割网络模型,通过建立编码结构和解码结构中多尺度特征图之间的联系,以及选用能平衡正负样本数量的损失函数,来提高路面影像中裂缝的分割精度。
2 研究方法
2.1 U-Net 模型
U-Net 最初是为了解决生物医学图像分割问题而提出的,但由于其出色的分割性能,后来也被广泛应用在其他物体的分割上,如卫星图像分割、工业缺陷检测等(吕书强等,2022)。U-Net 的编解码结构,如图1 所示。编码结构负责特征提取,主要用到的是卷积神经网络中常用的卷积层和池化层;解码结构负责将特征图恢复至原始分辨率并对图像中的每个像素点进行分类,主要用到的是上采样和跳跃连接。上采样是将图像的分辨率提高,使经过下采样后的特征图恢复至原始分辨率;常用的上采样方式有反卷积和插值两种。跳跃连接是将编码结构和解码结构的特征图进行融合,融合采用将两个特征图沿着特征维度的方向进行拼接的方式,这种设计可以帮助网络更好地保留图像中的原始信息,从而提高分割精度。
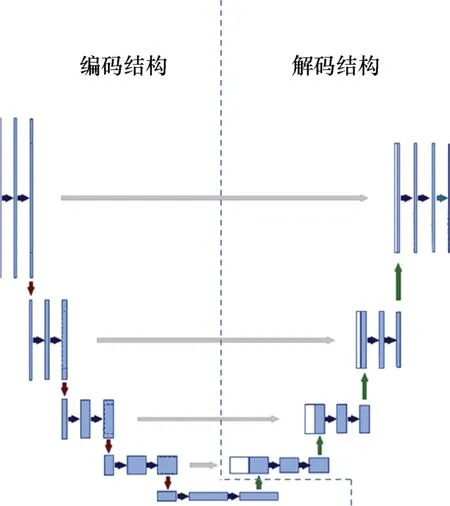
图1 U-Net 模型结构(Ronneberger 等,2015)Fig.1 Structure of the U-Net model
2.2 改进的U-Net 模型
基于编解码结构的U-Net 网络在特征融合时仅考虑了同一尺度的特征,这导致随着编码结构下采样次数的逐渐增多,低级别的特征信息逐渐丢失,而只保留了高级别特征信息。这使得最终的分割结果中,由低级别信息组成的边界等特征被弱化,导致分割精度的下降。研究基于U-Net 模型,将编码结构中的原始特征图按照不同的比例下采样,得到不同尺度的特征图;之后分别与解码结构中相对应的特征图进行融合,实现了融合多尺度特征图、保留多尺度特征信息,原理如图2 所示。与U-Net 模型最大的不同点在于增加了多尺度特征融合层:①结构将原始分辨率的特征图C1 分别按照1/2、1/4、1/8 的下采样比例进行最大池化,分别得到P1、P2、P3 三个特征图;②将这些包含了裂缝边界等低级别特征信息的特征图分别与编码结构、解码结构的特征图进行融合,即P1 与C2、U3 融合,P2 与C3、U2 融合,P3 与C4、U1 融合。融合的方式与U-Net模型的一致,采用沿特征维度拼接的方式:

图2 本文方法的结构Fig.2 Structure of the proposed method
式中, Featurefusion为融合后的特征图; Feature1、Feature2为待融合的两个特征图,形状分别为{C1,W,H}、{C2,W,H};Ci为特征图的维度;W、H分别为特征图的长和高。由此可知,使用拼接的特征融合方式需保证特征图的长和高一致,这也是为何在多尺度特征融合层中采用三种不同下采样比例的原因。
此外,为了使模型在误差反向传播时,更注重于对裂缝分类准确度的优化,本文使用了Focal Loss 作为网络的损失函数。Focal Loss 是一个专门为正负类别数量不均衡而设计、适用于小目标物体分割的损失函数(Lin 等,2017):
式中,γ>0 时,可以使易分类样本的损失大幅减少,使模型更加关注不易分类的样本;α为平衡因子,用于平衡正负样本的重要性。研究中,易分类的样本是占有大量像素的背景;不易分类的样本是仅占少量像素的裂缝。
3 实验与分析
为了验证本文方法的有效性和泛化性,选用CrackForest 数据集作为训练和测试的数据集(Shi等,2016)。CrackForest 数据集是一个常用的道路裂缝图像数据库,包含155 幅分辨率为480 像素×320 像素的道路裂缝图像,可以大致反映城市的路面状况。图3 是该数据集的图像和标签示例。

图3 CrackForest 数据集的图像和标签示例Fig.3 Examples of images and labels from the CrackForest dataset
为了量化评估模型的分割性能,本文利用交并比(intersection over union,IoU)、F1 分数这两个常用的综合评价指标对最终的分割结果进行评价。
式中,TP 为将正类预测为正类的像素数量,即将裂缝像素分类为裂缝的个数;FP 为将负类预测为正类的像素数量,即将背景像素分类为裂缝的个数;FN为将正类预测为负类的像素数量,即将裂缝像素分类为背景的个数;Precision 为模型判定是正的所有样本中有多少是真正的正样本;Recall 为所有正样本中有多少被模型判定为正。
3.1 模型训练
为了使模型的泛化能力更强,研究对CrackForest 数据集进行了数据增强处理。对所有图像和标签分别进行了90°、180°、270°的旋转,以及以竖边为轴线的左右翻转,从而将数据集扩充至原来的8 倍,即1240 幅图像。通过这种方式,使模型能够具有平移和旋转不变性,提升模型的分割精度。
训练过程中,先将上述数据集里所有的图像和标签按照6∶2∶2 的比例随机分为训练集、验证集和测试集。其中,训练集用于训练模型与确定参数;验证集用于确定网络结构及调整模型的超参数;测试集用于检验模型的泛化能力,即分割能力。除此之外,其他超参数设置如下:优化器选用Adam,初始学习率设为0.001;一阶、二阶矩估计的指数衰减率设为0.9、0.99;模糊因子epsilon 设为1×10-8;批量大小设为32;epoch 次数设为30;Focal Loss 中的α和γ分别设为0.25、2。
3.2 结果与分析
为了验证本文方法对小裂缝分割的有效性,研究分别使用本文方法和经典模型FCN-8s、U-Net、Segnet,以及一种专门为路面裂缝分割设计的模型CrackU-net,对经过预处理后的CrackForest 数据集进行训练和测试。其中,CrackU-net 是在U-Net 基础上改进的,通过分析路面裂缝的形态特点,将原始网络中的池化方式改为最大池化、卷积中的填充方式改为不变,显著提升了路面裂缝的分割精度,是一种非常具有代表性的路面裂缝分割网络。
首先将训练集和验证集放入模型中进行训练,其次统一保存验证集精度最高的模型参数,最后分别使用这些模型参数对测试集进行测试。图4 是五种模型在测试集上的部分测试结果,测试图像按照简单到复杂的情况分为单条裂缝、多条裂缝和极细裂缝。其中,由红框标的位置可以看出,本文方法相比三种经典模型无论在单条裂缝还是多条裂缝的情况下,在边缘细节上的分割效果要更好,同时,噪点数即误识别的区域也更少;CrackU-net 虽然分割情况稍好但仍与本文方法有差距。在对极细裂缝进行分割时,其他四种模型的分割效果明显不如本文方法,出现了不同程度的漏检情况。这证明本文方法中的多尺度特征融合层,以及Focal Loss 的使用在分割路面裂缝这种小目标物体时,相比已有方法具有更好的性能,更能还原细小裂缝本身的细节。

图4 五种模型的分割结果示例Fig.4 Examples of segmentation results from five models
为了进一步量化五种模型的分割性能,利用IoU、F1 分数指标对五种模型在测试集上的分割结果进行统计,结果如表1 所示。本文方法有效地提升了路面裂缝的分割精度,相对于其他四种方法,IoU、F1 分数指标的提升幅度分别为2.9%~9.9%、2.0%~7.2%。

表1 五种模型分割结果的IoU、F1 分数指标Tab.1 IoU and F1 metrics for segmentation results of five models%
为了验证本文方法中多尺度特征融合层和Focal Loss 损失函数对模型分割效果的影响,使用消融实验进行了分析,分别测试单独使用特征融合层和单独使用Focal Loss 损失函数对模型分割效果的影响,以及两者都使用和都不使用对模型分割结果的影响。其中,两者均不使用为基本的U-Net 模型,两者均使用为本文方法,结果如表2 所示。可以看出,多尺度特征融合层和Focal Loss 均起到了提升路面裂缝分割精度的作用,且多尺度特征层对分割效果的提升更为明显。这表明本文方法的两项改进均有效。

表2 消融实验测试结果Tab.2 Results of the ablation experiments%
4 结 论
针对路面影像中裂缝像素数占比较小,分割精度有待提升的问题,本文提出了一种改进U-Net 的编解码结构语义分割模型。通过将编码结构中不同层级的特征图分别与解码结构中的特征图越级融合,并在网络的反向传播过程中使用了适用于小目标物体分割的Focal Loss 损失函数,提高路面裂缝的分割精度。本文方法在路面裂缝数据集CrackForest中进行了训练和测试,与四种常用的语义分割模型进行了对比分析,并通过消融实验分析了改进模型的有效性。从实验结果中发现,改进的U-Net 模型在IoU、F1 分数指标上的表现均要优于其他模型,且在细小裂缝的分割结果上提升更为明显。这表明本文方法可以有效提升影像中细小物体的分割精度,在路面裂缝分割任务中具有实用价值。
