一种基于学习型特征的多模态影像匹配方法
2023-11-22王迎春
王迎春
安徽省基础测绘信息中心,合肥 230031
1 引 言
随着对地观测技术的快速发展,多种平台传感器获取的影像日趋丰富,为遥感信息的解译和分析提供了重要的数据来源(杨威等,2022)。复杂环境目标区域的探测,经常受到云雾遮挡、成像质量等因素的影响,往往难以通过单一类型的影像获取目标区域的全局信息(赵怡涛,2020)。通过结合多种类型影像的观测优势,能够得到更为准确的分析结果。由于不同模态影像的辐射特征和几何特征差异显著,实际应用中它们之间高精度匹配一直是影像分析处理的难点(钱学飞等,2021;韦春桃等,2022;姚永祥等,2022)。
基于图像特征点的影像匹配方法当前研究较为广泛,利用特征提取器在图像上检测特征点,构建特征点描述符,并计算特征描述符之间的相似性,获取同名特征点(张传辉等,2021)。其中最重要的是如何实现图像特征稳健的提取、描述与匹配,对此,国内外研究提出了多种多模态图像匹配的方法(梁建国和马红,2014;Ma 等,2018;Ye 等,2019)。总体来说,图像特征匹配方法经历了由手工设计的浅层特征匹配到深度学习特征匹配的演化过程。手工设计的浅层特征中最著名的是尺度不变特征转换(scale invariant feature transform,SIFT)特征描述符,但由于多模态影像之间的波段、成像模式、时相等差异显著(陈钟鸿,2020;崔学荣等,2022),直接利用SIFT 算法检测的特征对比度变化较大,难以获得高度可重复性的同名特征,且SIFT算法检测的特征点具有分布不均匀性,使得影像匹配效果通常较差(Fan 等,2018)。近年来,深度学习被广泛应用于计算机视觉、图像处理、大数据处理等方面(段芸杉等,2022),深度卷积神经网络通过对图像信息从低层到高层进行非线性学习,显著提升了特征表达能力,有着很强的泛化性能(Yang 等,2018),理论上能够抵抗由于辐射差异、几何形变及非线性畸变等带来的干扰,提升多模态影像匹配的稳健性(蓝朝桢等,2021)。早期的深度学习特征提取方法很好地解决了特征向量的描述问题,如Simo-Serra 等(2015)提出的一种与SIFT 特征描述符维度等价的深度学习描述符,直接替代SIFT 特征之后取得了更优的效果。但由于多模态影像的匹配,需要特征具有较强的泛化能力和像素精确定位能力。卷积神经网络(convolutional neural network,CNN)特征进行匹配经常出现特征描述与泛化能力相矛盾,以及特征描述缺乏精确的像素定位等问题(姚永祥等,2021)。因此,Noh等(2017)针对大规模地标图像检索,在提出的深度局部特征中引入了注意力机制进行特征点选择和匹配,取得了很好的效果。此外,多模态遥感影像的训练样本缺乏,限制了深度学习技术在遥感影像处理中的广泛应用(廖明哲等,2020;郑权和刘亮,2020)。为了解决遥感影像小样本量的问题,Wang 等(2018)提出了一种端到端的遥感影像匹配的深度学习框架,通过学习待匹配图像和参考图像之间的特征块和对应标签进行匹配;从多模态遥感影像匹配精度和稳健性的角度考虑,Ma 等(2019)基于CNN 提取的深度特征引入一种由粗到精的策略,完成了邻近空间关系和局部精确特征匹配的遥感影像匹配方法。这些基于深度学习特征的影像匹配方法有效地增加了特征匹配的稳健性。然而,这些方法训练需要大量的影像对,且处理过程相对烦琐,难以实现直接端到端的匹配(杨根新等,2022)。
综上可知,基于深度学习方法提取的学习型特征显著提升了图像匹配性能,但是由于深度学习是一种基于数据驱动的技术,当训练样本不足时,难以得到完备的特征表达。因此,如何利用已有的训练模型,通过迁移学习来有效表征图像的学习型特征,以提高其在图像匹配应用中的稳健性,是研究重点。本研究通过深度残差神经网络结构自主训练影像的学习型特征,得到多模态图像之间更为丰富和更为准确的同名特征点对;并选取可靠且可重复的检测器和描述符(reliable and repeatable detector and descriptor,R2D2)、辐射变化不敏感特征变换(radiation-variation insensitive feature transform,RIFT)方法与本文方法进行对比分析。
2 基本原理
2.1 影像学习型特征提取
通过增加卷积神经网络层数,利用深层卷积神经网络提取更加稳健的图像深度学习特征是有效提升学习型特征匹配性能的方法(范大昭等,2018)。研究基于Google 的Landmarks 大规模数据集(Weyand 等,2020),利用预训练ResNet50 模型,构造尺度因子为倍的图像金字塔,获取不同尺度图像学习型特征;特征表示方式通过卷积层、激活层和池化层非线性映射之后得到,特征点位置使用卷积之后对应输入图上区域(感受野)中心的像素点坐标表示。
由于ResNet50 网络输出的特征图是密集型特征,直接匹配会带来计算量大、效率低下等问题,为此,研究利用带有自注意力机制的编码器学习图像局部稀疏特征,特征描述符的相关性则通过特征得分函数进行度量,得分函数表达为α(f n;θ),其中,θ是得分函数α(·) 的参数,fn为用于与得分模型一同学习的影像特征量,网络训练是通过不断迭代权重文件,输出结果是对特征向量的加权求和:
式中,W∈RM×d为CNN 全连接层的权重。
网络中的损失函数为交叉熵损失函数,可以表达为
式中,y*为多模态影像特征的真值。其参数能够通过反向传播算法学习得到,网络模型目标是求解交叉熵损失函数最小时的反向传播参数θ,损失函数对θ的梯度计算如下:
式中,αn=α(fn;θ)为输出函数。训练后的模型提取多模态影像特征流程,如图1 所示。
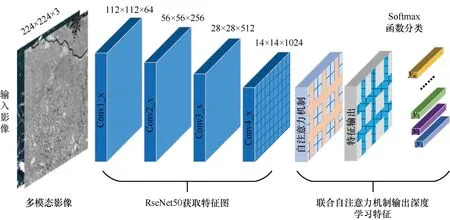
图1 多模态影像深度学习特征提取流程Fig.1 Deep learning feature extraction process for multimodal images
2.2 图像多尺度特征融合
由于不同卷积神经网络学习到的特征不同,通过融合多种包含丰富组合信息的网络深层特征(简称高层特征)能够有效综合不同特征的优点(高莎等,2022)。因此,本文先组合不同的高层特征,将特征维度升高,再使用最大池化方法对组合的特征进行聚合,来降低特征维度。具体操作如下。
假设组合k个高层特征{f1,… ,fj,…,fk},则最大的特征维度表示为
式中,Cj为第j个高层特征fj的特征维度。
为了能够把所有特征图对齐统一,通过补充0值的方式将所有特征图都扩充到Cmax:
式中,xij为第i个高层特征fi中的第j个特征图:
将所有高层特征对应的特征图采用分块对角矩阵的形式进行合并,得到特征为
所有特征合并后的特征图尺寸为W×H×Cmax,W和H的计算原理如下:
式中,wi为第i个特征图的宽度;hi为第i个特征图的高度。
为了将融合后的特征维度和直接提取的高层特征维度一致,可通过池化的方法将组合特征的维度降低到1 × 1 ×C维,得到一个C维的特征向量,以保持维度的一致性。
2.3 网络模型训练
多模态影像网络模型训练基于微调方式,训练和测试数据来源于Landmarks 大规模数据集中的多模态影像匹配数据集(https://github.com/StaRainJ/)。网络模型是基于ResNet50 预训练模型的微调,训练时输入图像随机裁剪为224 像素×224 像素,训练优化器选用 Adam,学习率设置为 0.0005,BatchSize 设置为8,迭代次数为200。
3 实验结果与分析
3.1 数据来源
实验数据来自多模态影像匹配数据集的测试集,选取了具有代表性的多模态遥感影像作为实验数据,包含不同的纹理、地物类型、季节变化、尺度、成像方式的多模态影像,可较好地应用于测试算法验证。
3.2 深度学习特征多尺度融合
为测试多尺度特征融合对提纯稳健学习型特征的影响,实验设置了尺度范围为0.25~2.0,构建尺度因子为倍的图像金字塔,得到0.25、0.356、0.5、0.707、1、1.414、2 共7 种不同的尺度因子,并提取每一尺度下的学习型特征。并对这7 种不同的尺度分别进行逐层叠加,目的是明晰每一尺度层的作用机理,同时记录多尺度的学习型特征检测数量和提纯后稳健特征数量,具体结果如表1 所示。
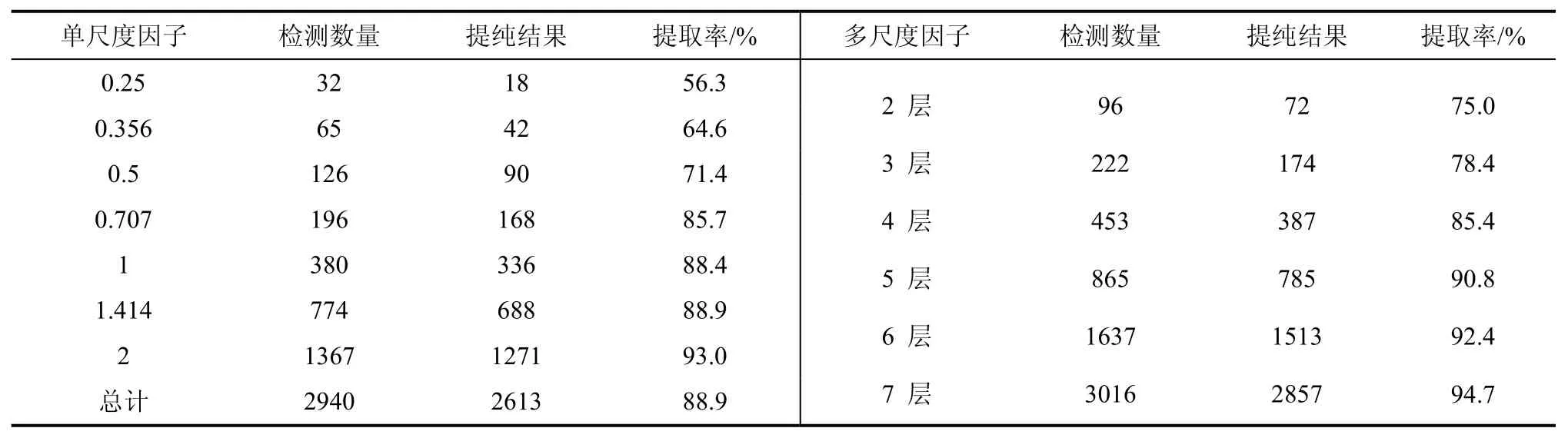
表1 不同尺度系数的稳健特征提取率Tab.1 Robust feature extraction rate of different scale coefficients
单尺度逐层特征提取和多尺度特征提取实验表明,随尺度系数的增加,特征检测数量和提纯后的特征数量呈现不断增长趋势。当单尺度因子为0.25 时稳健特征提取率仅为56.2%,当单尺度因子为2 时,稳健特征提取率增长至93.0%,增幅为36.8%,单尺度因子平均提取率为88.9%;融合多尺度因子的特征提取跟单尺度因子具有近似的特性,即随着特征金字塔层数的增加,特征检测数量和特征提纯数量都会随之增长,当多尺度因子为前2 层时,提取率为75.0%;当多尺度因子为全部的7 层时,提取率上升至94.7%,增幅为19.7%。相比于单尺度因子,融合多尺度层的特征检测数量、稳健特征提纯结果和稳健特征提取率均具有更好的稳健性,表明了通过融合图像多尺度特征之后,能够得到更好的匹配效果。
进一步分析表1 可知,对于单尺度下的稳健特征提取率来说,当尺度系数为0.25 和0.356 时,特征提取率低于65%;而在0.356~1 尺度空间快速上升,当尺度因子为1 时,提取率接近90%;尺度系数再往后增加时,增长幅度较小,从1 增加到2,提取率仅增长4.5%。对于多尺度因子的特征提取率,呈现出持续上升趋势。从融合前2 层的尺度因子到融合前5 层的尺度因子,提取率增加15.8%,显著上升至90.8%;再从融合前5 层尺度到融合全部的7 层的尺度因子时,提取率缓慢增加至94.7%,增幅为3.9%。由此可知:单尺度因子小于1 时对学习型特征提取的数量具有较大影响;单尺度因子大于1 时影响呈现不断下降趋势。
3.3 结果与分析
利用本文方法、基于深度学习特征的R2D2 方法和基于手工设计特征的RIFT 方法在多模态影像数据集进行多组不同影像对匹配实验,最终匹配结果,如图2 所示。

图2 三种方法下多模态影像与光学影像匹配结果Fig.2 Matching results of multimodal images with optical images under three methods
通过匹配实验结果可知,本文提出的多模态遥感影像匹配算法在6 组不同多模态影像匹配结果中均获取了较为丰富且分布均匀的匹配点对,其他两种对比方法则无法完全适应所有场景,出现了无法匹配或匹配点对较少的情况,表明了算法对多模态影像匹配具有很强的适应性和稳健性,能够为多模态遥感影像的高精度配准提供了可靠的算法支撑。
3.4 匹配精度分析
基于前述6 组实验,详细统计了不同情形下的粗匹配数量、精匹配数量、正确匹配率(精匹配数量/粗匹配数量)、匹配耗时和匹配均方根误差(root mean square error,RMSE),如表2 所示。可知,对于影像粗匹配而言,不同模态影像粗匹配数量相差不明显,这跟实验所用影像大小、影像质量和匹配参数设置相关。对于提纯后的影像精匹配而言,每种情形表现不同,越多的精匹配点对说明匹配效果越好,实验中精匹配数量差异较大,精匹配数量最高的是507 对,最低仅为192 对,差距高达315对,表明不同模态之间影像匹配存在一定的不稳定性;对于正确匹配率而言,最高的匹配率是夜光影像和光学影像匹配率,高达75.0%;最低是电子影像和光学影像的匹配,仅有36.9%的匹配率。就匹配时间效率而言,整体差异不大,差值不超过2 s,同时RMSE 均较好地控制在1 像素左右,表明本文方法具有较好的匹配精度。
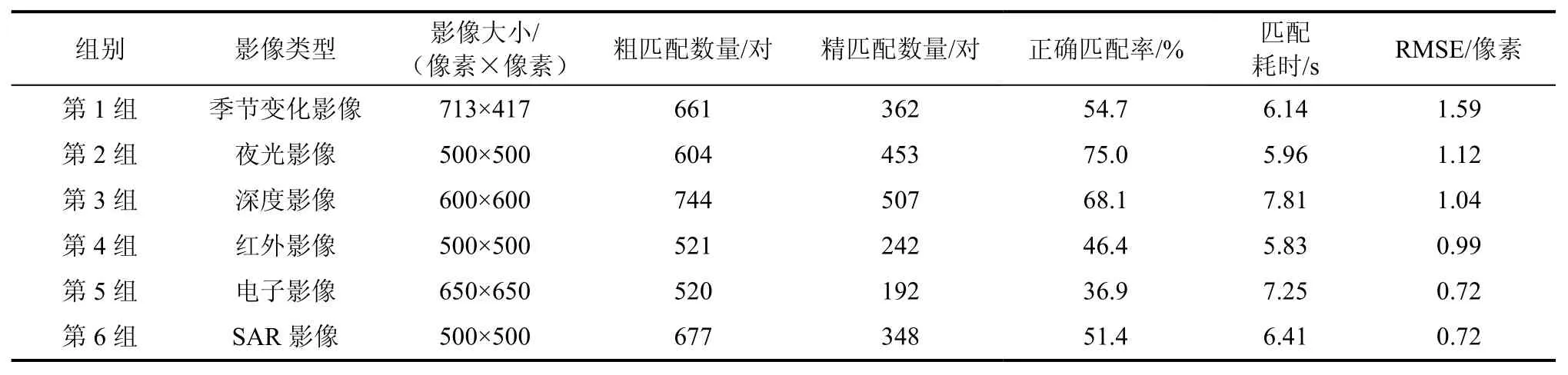
表2 不同情形匹配结果统计Tab.2 Statistical analysis of matching results in different scenarios
图3 分析了三种方法在特征粗匹配数量、精匹配数量、正确匹配率和匹配耗时四个方面的差异。可以发现,本文方法在粗匹配数量方面具有相对较低的结果,但对于精匹配数量和匹配正确率具有显著优势,说明了本文方法对多模态图像匹配的稳健性。对于匹配耗时,本文方法和其他两种方法相差不大,表明了在匹配耗时方面的稳健性。
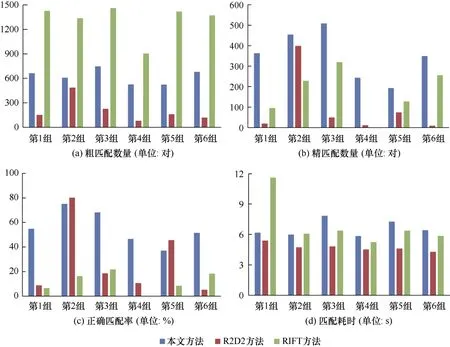
图3 三种方法结果对比Fig.3 Comparison of results among three methods
4 结 论
为解决多模态影像的高精度匹配问题,基于在大型数据集上预训练的ResNet50 网络模型,本文提出了一种融合多尺度深度学习特征的多模态影像匹配方法,通过深度残差神经网络结构自主训练学习影像的学习型特征,得到多模态图像之间更为丰富和更为准确的同名特征点对,并在差异显著的多模态影像中进行了匹配实验。结果表明,本文方法在多组不同环境下的多模态影像匹配中均得到了较好的匹配结果,具有一定的实际应用价值,这在一定程度上为多模态遥感影像自动配准提供了基础和参考。
然而,由于深度学习特征匹配算法性能对训练数据数量和质量依赖较大,面对实际问题时常常难以有效获取高质量、大规模的训练数据。因此,对于数据训练数据规模不足时如何高效完成多模态遥感图像匹配是未来研究的一项重要任务。
