未知二进制协议的报文分割方法
2023-11-22李晓辉朱承才
徐 魁,海 洋,李晓辉,朱承才,陶 军,3
(1.宝鸡市公安局通信处,陕西 宝鸡 721014;2.东南大学 网络空间安全学院,江苏 南京 211189;3.计算机网络和信息集成教育部重点实验室(东南大学),江苏 南京 211189)
0 引 言
随着互联网技术的不断发展,保障通信网络的安全愈发重要。二进制协议因其非侵入性的特点以及在网络中的广泛应用成为了当前研究的热点。
协议逆向工程的关键在于对协议报文如何分段。对未知规范的通信需要通过监控网络流量等方法对其进行逆向工程[1]。静态流量逆向工程的应用包括僵尸网络分析[2]、蜜罐设置[2-3]、模糊漏洞测试[4]和网络自动建模[5]。2004年,Beddoe[6]和Rauch提出了首个解决方案:序列比对。此后ProDecoder[7]和PRISMA[2]发现自然语言处理在使用ASCII编码关键字来构造消息的协议上运行良好。推断消息格式往往需要大量消息,然而多序列比对会导致指数复杂性[8],当数据量巨大时性能变差。另一方面,长可变消息可能出现对齐偏差,从而导致字段边界误判。因此,为了聚类消息类型或对齐字段序列,就需要进行消息字段划分。ScriptGen[3]、Discoverer[9]和Netzob使用序列对齐来推断消息格式。FieldHunter[10-11]使用字段类型的特征化等方法进行格式推断。张蔚瑶等人使用协议特征库对未知协议进行逆向分析[12]。此外,研究人员提出了三类创新性的协议报文分段方法:基于信息论投票的报文分段、基于决策模型的报文分段[13]与基于报文内部结构的报文分段。Zhang等人[14]提出协议关键词提取方法ProWord,首次将无监督专家投票算法应用于流量分析。Sun等人[15]引入统计信息,从信息论的角度提出协议报文分段算法ProSeg。IPART[16]在专家投票算法基础上又加入语义识别,对报文分段点进行二次确认。Jiang等人[17]提出基于相邻字节距离的报文分段算法ABInfer,采用最近邻聚类算法迭代将相邻字节进行合并,然后对字段进行划分。
协议字段划分的过程可以抽象为报文字节序列中字段边界的决策问题。黎敏等人[18]将字段划分过程看成马尔可夫过程,在此基础上使用隐半马尔可夫模型(Hidden Semi-Markov Models,HSMM)[19]进行字段划分。Cai等人[20]同样使用隐半马尔可夫模型进行求解,对黎敏的工作进行了优化。Tao等人[21]使用贝叶斯决策模型进行协议逆向分析,提出了对二进制协议进行字段划分的方法PRE-Bin。
协议报文的部分研究以比特为粒度,挖掘比特间的表征关系。Kleber等人[22]研究协议报文的内部结构,提出了一种新颖的报文分段方法NEMESYS。Marchetti等人[23]通过幅度序列和位翻转频率寻找报文分段点,提出汽车通信数据帧分段方法READ。
基于上述情况,该文提出了一种用于未知二进制协议逆向工程的协议字段划分方案HV。主要工作如下所述:
首先,提出字节翻转率的概念并将其应用到消息分析。从垂直分析的角度,通过对比相邻消息的结构,找到该二进制协议在消息结构上的共性。其次,从水平分析的角度探究单条消息的内部结构。基于第一数字定律等方法初步找到消息边界;使用路径搜索等算法找到更多候选边界点,从而优化消息字段划分的结果。接着,创新性地联合水平以及垂直分析进行消息字段的划分,设计用于未知二进制协议字段划分方案HV。对从上述得到的消息分段点进行评估、投票等决策,得到最终结果。最后,引入格式匹配分数(Format Match Score,FMS)用于量化特定消息的格式推断质量。
1 算法思路
1.1 基于垂直分析的报文分段
此阶段探究的是消息之间所呈现出的结构信息。对相邻的消息进行比较,得出相关的统计信息。
1.1.1 字节翻转率与位翻转率
一般工业协议粒度为字节,将消息载荷以字节形式展开,使用字节翻转率进行评估。字节翻转率定义如下:
(1)
其中,BFi表示第i个字节的翻转率,M是所有消息集合,mj是M集合中第j条消息,mj(i)是第j条消息的第i个字节。⊕是异或操作。|M|是消息集合中的消息数量。这一步得到一个含有n个元素的数组,每个元素代表某一字节处的翻转率,n是消息载荷字节的长度。字节翻转率独立于同一消息中邻近的字节,只与邻近的消息有关。过程如算法1所描述。
同理,可以将消息载荷以比特形式展开,得到位翻转率。定义如下:
(2)
位翻转率处理的粒度是比特位。
1.1.2 字段划分
对消息进行翻转率的计算后可以得到字节翻转率数组BF以及位翻转率数组bF。接着进行字段划分。首先遍历字节翻转率数组,查找符合如下条件之一的字节位置:
(1)该位置字节的翻转率为局部极值点,即满足:BFi≥BFi-1and BFi≥BFi+1。
(2)该位置字节与相邻的位置字节都具有一个较高的翻转率,即满足:
BFi≥Φ and (BFi-1≥Φ or BFi+1≥Φ)。
(3)该位置字节的翻转率为0,即BFi=0。
将符合条件的字节位置标记为字段边界可疑点。经过上述处理得到一个边界列表b。将字节翻转率为0的字节位标记为边界。根据翻转率的定义,经常变化的字段翻转率会偏大,反之则偏小。
位翻转率数组是一个辅助数组。对于计数字段,翻转率会较大。计数字段低位的字节翻转率为1,相应的最低比特位翻转率也为1。并且计数字段从最低位到最高位翻转率应是递减的,每一位的翻转率是下一位的两倍。当字节翻转率为1后可利用位翻转率数组进行确认。当认定某一字节为计数字段时,需要查看该字节的后一字节以及前一字节。这一过程如算法2所描述。

算法2:字段划分阶段二1:function divide2(BF, bF, b) :2: BLen len(BF);3: bLen len(bF);4: For i In range(0, BLen) :5: IF BFi = 1 :6: IF detectLeftMatch(bF, i) :7: b.append((i-2, BFi-2));8: b.erase(i-1);9: ELIF detectRightMatch(bF, i) :10: b.append((i+1, BFi+1));11: b.erase(i);12: return b;
通过算法2可以得到垂直分析的边界列表b。该阶段是在寻找同一种协议的所有消息中共有部分的统计特性。在进行消息分段时需要取一个固定的长度进行消息间比对。具体如何取值下文有所说明。
1.2 基于水平分析的报文分段
协议字段划分的过程可以抽象为报文字节序列中字段边界的决策问题。因此可以使用路径搜索算法从水平分析的角度对消息的内部结构进行分段。在此之前需要进行分支度量以及约束条件的定义。
1.2.1 分支度量的定义及第一数字定律扩展
第一数字定律,指所有自然随机变量只要样本空间足够大,每一样本首位数字为1至9,各数字的概率在一定范围内具有稳定性。以1为首位数字的数的出现概率约为总数的三成。总结而言,越大的数以它为首几位的数出现的概率就越低。
在十进制中,以n开头的数出现的几率为:
(3)
然而二进制协议中对以“0”开头的字节也会保留,因此可以扩展为:
(4)
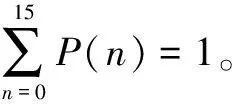
分支度量在定义时主要基于第一数字定律,边界评估指标如式(5)所示:
(5)
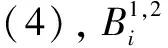
1.2.2 约束条件
约束条件控制节点之间是否可达。构造约束条件时:首先字段长度是有限的,一般不超过4个字节,个别字段会达到8字节,多数情况下为偶数或“1”。其次,字段是单向的,即字段是从左往右,不存在从右往左的。评估指标如式(6)(7)所示:
(6)
(7)
式(6)中,di,j表示第i个候选边界和第j个候选边界之间的距离。根据最短路径搜索的思想,为使最佳路径的路径权值和最小,该式使用score的倒数作为分支度量。式(7)中,wk是一个距离权重,其中k是整数,表示两个候选边界之间相隔的字节数。当k=1,2,4时,表示j>i并且字段长度合理,使用平方增量;当k≤0(从右往左)或者k=3(3个字节长度的字段一般不常见)或者k>4(字段长度太长)时,权重为负无穷,即不可达。
1.2.3 最佳路径搜索算法
根据分支度量和约束条件生成候选边界有向图,利用最佳路径搜索算法从有向图中找到与真实格式关键词边界最接近的一条路径作为最终格式关键词的边界推断结果。目标函数如式(8)所示:
(8)
其中,Trace是所有可能的路径集合,tracek是集合的第k条路径。
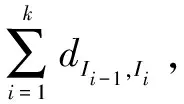
最佳路径搜索算法应用于关键词边界选择,最终目标是寻找一条从第一个候选边界点到最后一个候选边界点权值之和最小或最大的路径。
1.3 联合垂直分析和水平分析的消息分段
1.3.1 划分方案
消息的水平分析通过消息内部所蕴含的信息对字段进行了划分。消息的垂直分析通过消息序列之间所蕴含的信息对字段进行了划分。这两种方案各自的特点如表1所示。

表1 水平与垂直分析优缺点
该文将这两种方式进行结合,设计了一种创新性的消息字段划分方案HV。
对于水平分析,分析的是单条消息;结合垂直分析时要将分析对象由单条消息转为消息集合。
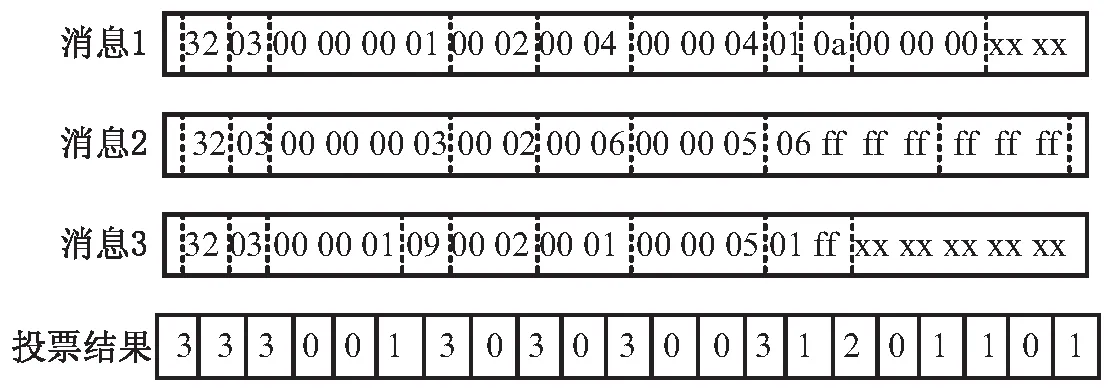
图1 投票机制执行过程
接下来,结合垂直分析与水平分析的结果。设水平分析的字段边界划分结果为Ih={ih,1,ih,2,…},垂直分析的字段边界划分结果为Iv={iv,1,iv,2,…},最终的结果取两者的并集,即I=Ih∪Iv。
1.3.2 方案优化
为避免在data字段进行消息字段划分对结果产生干扰,需要对消息进行截尾处理。这里使用平均类内距离作为评估指标,如式(9)所示:
(9)
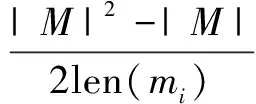
接着对消息作截尾处理,取不同长度的消息计算平均类内距离,取平均类内距离骤增时的消息长度lenavg作为截尾点候选点。同时考虑所有消息中最短的消息长度lenmin。将lenavg的初始值设为所有消息的长度最小值,再设一个下限lenlow,在该文中设为10。最终的截尾长度lenfinal取值如下:
lenfinal=min{lenmin,max{lenavg,lenlow}}
(10)
1.4 格式匹配分数FMS
引入格式匹配分数FMS作为字段划分质量的度量。该测度主要考虑三个方面:(1)正确识别字段的比率;(2)区分移位字段边界和完全错误字段;(3)量化不同字段边界推断的递减效用。
FMS为消息的每一个真实边界rk定义了范围,一个边界的范围起始点为前一个边界rk-1和前一边界rk的中间点,范围结束点为当前边界rk和后一边界rk+1的中间点。消息开始处r0和消息结束处r|R|不分配边界范围。因此,当推断边界il满足式(11)时,就表明il属于rk的范围。
(11)
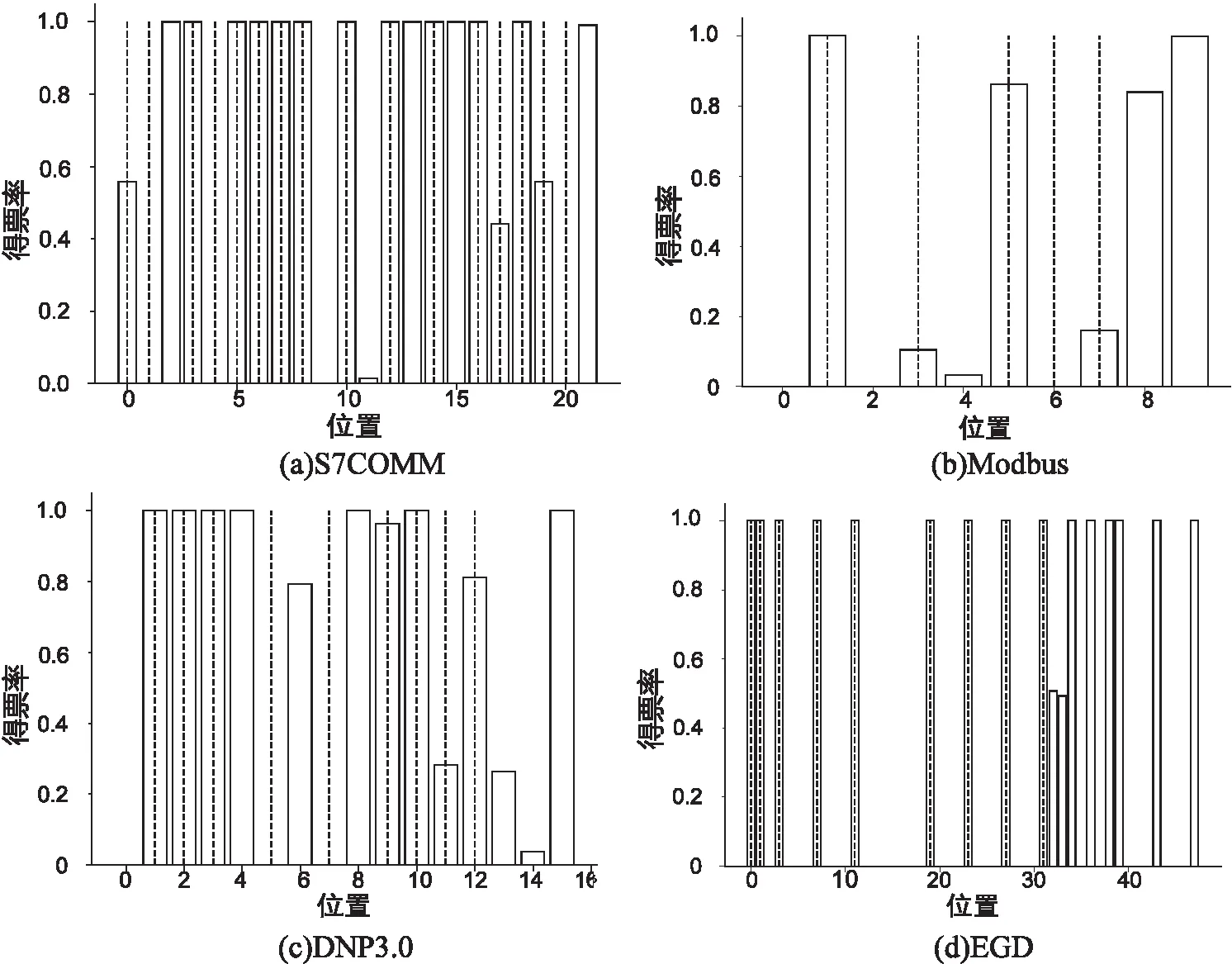
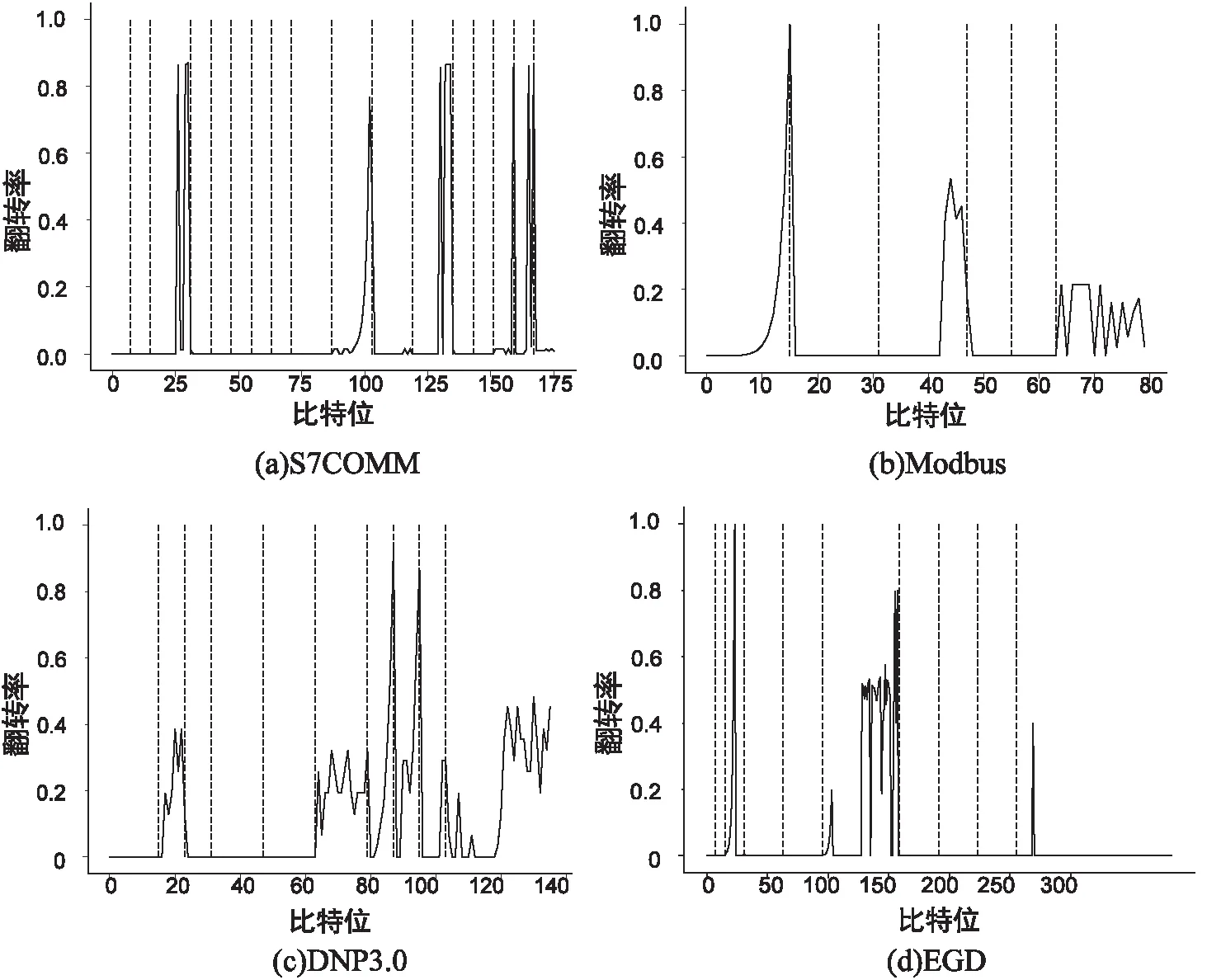
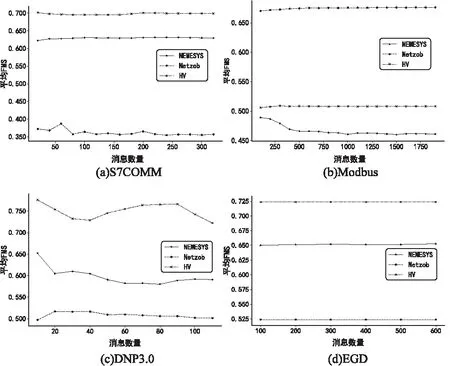
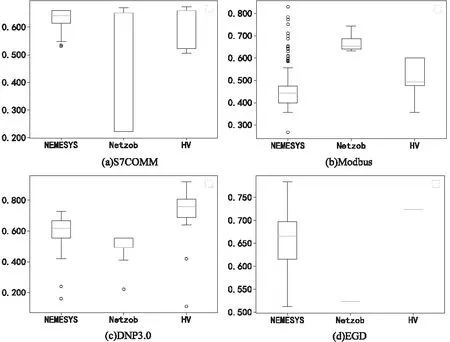
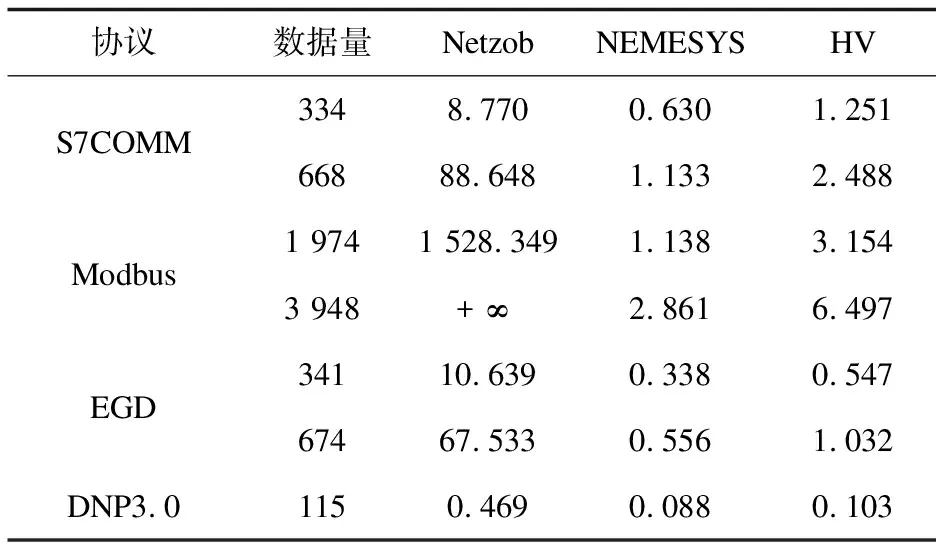
式中,il表示第l个推断的字段边界的下标索引,0 δr=argmin{|i-r|}-r (12) 将空集上的min运算符定义为minφ=-∞。可知δr有四种情况:①δr=-∞:对于真实边界r,没有与之匹配的推断结果。②δr=0:推断边界与真实边界完全吻合。③-∞<δr<0:推断边界在真实边界的左边,偏移量为δr字节。④δr>0:推断边界在真实边界的右边,偏移量为δr字节。 模式匹配分数的定义如式(13)所示。 (13) 最后,对整个式子进行标准化,使得FMS的值在0到1之间。推断质量越高,FMS越大。 实验样本为668条S7COMM协议数据、115条DNP3.0协议数据、3 948条Modbus协议数据和674条EGD协议数据。S7COMM协议使用TPKT和COPT封装PDU,DNP3.0协议较复杂,Modbus协议较简单,EGD协议含有时间戳等字段。 由于实验无需对不同协议的字段划分结果进行横向比较,因此并未保持协议数据的数据量一致。实验中投票时的Θ设置为0.8,FMS的γ设置为2,使用tshark对消息解析出的信息作为基准。 图2展示了四种协议截尾后的投票结果。可见划分结果的有效字段较多,侧面印证截尾的必要性。 该阶段对字段边界的推导初具成效,尤其是EGD协议。这是因为EGD协议主要由IP地址和时间戳字段等常见字段组成。这些字段在投票前已经被事先定义的字段识别方法识别了。 图2 投票结果 在垂直分析时需要计算位翻转率,图3展示了这四种协议的位翻转率。可见字段边界左边的比特位的翻转率普遍偏高,所以翻转率高的位置附近或者翻转率骤降点可以判定为字段边界。 图3 位翻转率 实验使用Netzob以及NEMESYS作为对比方法,如图4所示。(a)描述的是S7COMM协议的字段划分的质量,可见随着数据量的增加三者的质量变化都较小。(b)描述的是Modbus字段划分的质量,其中Netzob推测的质量最高。(c)描述的是DNP3.0字段划分的质量。可见Netzob的质量较差。因为实验中DNP3.0协议的数据量太少,Netzob可挖掘的统计信息太少。且NEMESYS和HV都有较大起伏,这是因为NEMESYS只考虑单条消息,依赖于每条消息的取值,所以不受样本数增加的影响;但是HV在考虑单条消息的同时也会考虑多条消息之间的比较,因此随着相似样本的增加会提高推测质量。(d)描述的是EGD字段的划分质量,清晰地观察到HV的推导质量极高且稳定,达到了0.725,这是因为EGD协议中有几个字段的语义被HV事先定义了。 图4 FMS测度下的字段划分质量 图5展示了HV与Netzob和NEMESYS在所有消息上的推导质量的分布情况。从图中可以看出HV除了在Modbus协议上的推测质量不如Netzob,其余情况下的推测质量均高于Netzob和NEMESYS,而且较为稳定。HV整体上是优于Netzob以及NEMESYS的。 图5 FMS分布情况 表2列出了三种方法的运行时间。其中+∞表示在30分钟内无法求解。可以看出,三种方法中Netzob的运行时间最长,甚至当数据集到达一定数量时,可能无法求解。这是由于Netzob和大多数协议逆向算法相同,使用了全局序列比对算法,导致具有指数级别的时间复杂度。当对最大长度为l的k条消息进行比对时,复杂度为O(lk)。从中还可以看出,NEMESYS运行时间最短,这是因为NEMESYS不需要将数据集中的消息进行任何比较,它只与消息的长度以及数量相关,导致它具有极低的线性复杂度。同样,HV运行时间也较短,并且运行时间也几乎是线性的。以Modbus为例,在分析1 974条消息时,NEMESYS与HV都是在几秒内完成,而Netzob使用的时间是HV的500倍。 表2 执行时间 s 图5说明边界推断的质量只有在Modbus协议上是Netzob>HV>NEMESYS;而S7COMM,DNP3.0和EGD协议上均为HV>NEMESYS>Netzob。从表2可知,Netzob的执行时间远远大于HV以及NEMESYS。而后两者的执行时间相差无几。因此,综合字段划分质量和划分时间,HV总体上是优于Netzob以及NEMESYS的,它有着较稳定的推断质量。HV的执行时间几乎是线性的,当数据量较大时也能快速处理,而Netzob中的序列比对的复杂度是指数级别,当数据到达一定量就无法求解。 推断二进制协议的格式结构对于二进制协议分析十分重要。目前的协议逆向分析对于文本协议的研究较深,针对二进制协议进行逆向分析仍存在难点。字段划分是协议逆向过程中的前置步骤,协议逆向的准确度很大程度依赖于字段划分的质量。为解决上述问题,该文提出了一种新颖的较简单的未知二进制协议字段划分方法HV。HV首先单独分析每一条消息的内部结构;接着通过计算相邻消息之间的字节以及位翻转率进行字段划分;最后结合两次分段得到最终的字段划分结果。其他需要成对比较消息的方法复杂度在指数级别,HV几乎只需要线性复杂度。并且与其它方案相比,此方案在推断字段边界的质量上也有着不错的表现。该文还定义了格式匹配分数来衡量字段划分的质量,相比传统的衡量指标,格式匹配分数更加适用于字段划分。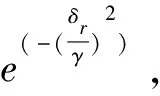
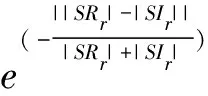
2 实 验
2.1 实验设置
2.2 实验结果及性能分析
3 结束语
