基于FPGA 的Winograd 算法卷积神经网络加速器设计与实现
2023-11-18牛朝旭孙海江
牛朝旭,孙海江*
(1.中国科学院 长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100049)
1 引 言
卷积神经网络被广泛应用于许多深度学习系统中,并在全息图像重建[1]、光学计量[2]和自动驾驶[3]等多种计算机视觉任务中取得了显著的成效。为了达到更高的精度,一些研究引入了多尺度特征增强[4]、弱光照图像增强[5]以及RGB-D 特征融合[6]等更为复杂的算法,使得网络计算复杂度和模型规模也更为庞大,进而导致了计算功耗的提升[7]。在一些低功耗的应用场景中,如星上AI 计算、遥感图像在轨处理等,常规的硬件平台部署卷积神经网络十分困难[8]:通用的中央处理器(Central Processing Unit,CPU)无法满足卷积神经网络的计算需求;图形处理器(Graphic Processing Units,GPU)功耗太高,无法应用于嵌入式环境;专用集成电路(Application Specific Integrated Circuit,ASIC)成本高昂且通用性差。与之相比,计算并行度高、功耗低、可重复编程的现场可编程门阵列(Field Programmable Gate Array,FPGA)更适合应用于星上智能计算、在轨目标识别等低功耗环境下的卷积神经网络的硬件加速中。
传统的空间卷积算法通过循环展开、并行计算的方法进行加速计算,在早期被人们广泛使用,如脉动阵列[9]、层集群并行映射方法[10]等加速方法被先后提出。随着卷积神经网络的层次变深、卷积核尺寸变小,传统的卷积方法在卷积效率上已经逐渐落后,快速卷积算法显现出它的优势。文献[11]将快速傅里叶变换FFT 算法应用于卷积中以加速计算,但此方法只对大尺寸卷积核具有良好的加速效果,否则其转换过程会引入大量补零操作,得不偿失。文献[12]提出在卷积计算中使用Winograd 算法降低计算复杂度。Winograd 算法是通过对输入特征矩阵和权重矩阵做线性变换后再求哈达玛积,减少了乘法次数,实现了硬件上计算效率的提升。文献[13]提出在FPGA 上使用行缓存结构提高Winograd 算法切片之间的行数据重用。文献[14]提出双缓冲区5×5 流水线卷积方法。但是上述文献并没有充分复用重叠数据,也没有在目前使用广泛的小卷积核网络上充分发挥FPGA 低功耗的特性。
本文设计了一种Winograd 算法卷积神经网络加速器。首先设计了输入数据缓存复用模块,结合行缓存和列缓存重叠数据,最大化重用了片上数据,减少了频繁数据搬运的开销。针对FPGA并行运算特性,设计多通道并行Winograd 卷积运算阵列,并将卷积过程分解为六级流水线,提高了运算效率和吞吐量。为了提升计算速度和数据传输速度,使用权重8 位定点数(INT8)量化的方式来压缩模型,数据量减少到1/4。最后针对遥感图像分类数据集修改VGG16 网络,将加速器部署至ZCU104 平台进行实验验证。实验结果表明,本设计相比其他FPGA 设计方案在功耗和计算效率上都有一定的提升。
2 Winograd 算法
文献[15]提出的Winograd 算法可以用于减少有限脉冲响应(Finite Impulse Response,FIR)滤波器的乘法次数,之后被应用于卷积神经网络加速中以减少乘法数量的方式来提升计算速度。在一维Winograd 卷积计算中,设卷积核尺寸为r,卷积结果输出长度为m,则一维Winograd 卷积计算公式F(m,r)需要的乘法数量为m+r-1,而传统卷积为m×r。可以看出,当r和m都大于1时,Winograd 卷积乘法数量更少。
以F(2,3)为例,用d=[d0d1d2d3]T表示输入向量,g=[g0g1g2]T表示卷积核,r=[r0r1]T表示输出向量,其计算过程可以表示为:
因此可知,普通卷积需要6 次乘法和4 次加法,即:
而F(2,3)的Winograd 卷积可写成如下矩阵乘法形式:
其中m0、m1、m2、m3计算如下:
其中,输入信号d的变换需要4 次加法。而对于卷积神经网络推理阶段的卷积核g,其数值是固定的,其变换可以预先计算好进行存储,同时其中的除2 操作可以用位移代替,所以计算需求可以忽略。输出项r还需要中间项m进行4 次乘法和4 次加法,所以F(2,3)的Winograd 乘法数量为4 次、加法数量为8 次。相较于传统卷积,以加法为代价,节省了33%的乘法数,考虑到在硬件实现的乘法的实现成本远高于加法。因此使用Winograd 算法能够提升运算速度。
上述计算可以整理为如下的矩阵形式:
一维Winograd 卷积推广到二维Winograd 卷积,可得到如下矩阵形式:
其中W和In 是输入数据,Out 是输出结果。AT、G、BT都是常数矩阵,在F(22,32)时为:
Winograd 卷积计算F(22,32)的过程如图1 所示。一次F(22,32)卷积计算可以将乘法数从36次降低为16 次,计算效率提升了2.25 倍。
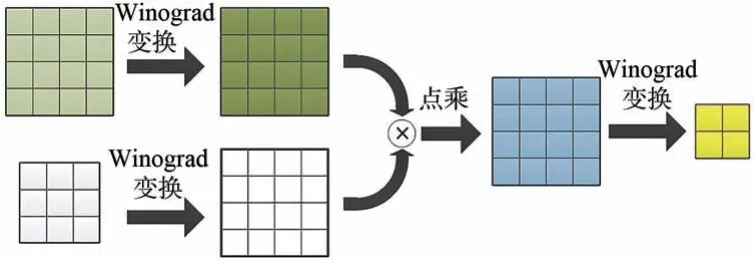
图1 Winograd 卷积过程示意图Fig.1 Schematic diagram of Winograd convolution process
3 卷积神经网络加速器的构成
卷积神经网络加速器的整体架构如图2 所示。因为基于ZYNQ 平台,所以分为可编程逻辑(Progarmmable Logic,PL)端和处 理系统(Processing System,PS)端两部分。PL 端负责计算卷积神经网络的卷积、池化、全连接等相关层,PS 端负责控制PL 端的运行以及传输数据。两部分主要通过AXI-DMA 进行数据交互,并使用AXI-FIFO起到对数据流缓冲的作用,防止数据接收不及时造成的数据丢失。

图2 卷积神经网络加速器硬件架构图Fig.2 Hardware architecture diagram of convolutional neural network accelerator
PS 端读取SD 卡中的权重数据和特征数据到DDR 内存,通过写寄存器控制当前PL 端运行网络的层数。之后开始计算,通过AXI-DMA 使用AXI-Stream 总线向PL 端写入DDR 上的数据,缓存至特征数据缓存模块或权重数据缓存模块。在卷积层中,将卷积计算按照并行计算方式循环展开,之后根据计算窗口位置的不同,输出数据到六级流水线卷积层,得到中间计算结果后累加缓存,完成整幅输出通道的计算后经AXI-DMA输出数据到DDR 上,作为下一层特征数据存储。依此类推,直至完成网络全部层的计算,得到输出结果。
4 卷积神经网络加速器设计
4.1 硬件8 位定点数量化
32 位浮点数在FPGA 上进行乘加运算时会消耗更多的片上资源,占用更多的位宽。为了提高数据吞吐速率和加速器计算效率,可以使用量化后的8 位定点数,在精度损失不大的情况下达到压缩模型的目的。为了更适合FPGA 硬件电路实现,本文选择了线性对称且逐层的量化方式。
量化的过程就是放缩的过程。将32 位浮点数的数值范围线性缩小到8 位定点数的数值范围,就得到了INT8 的权重数据。其量化公式如式(11)所示:其中:x表示32 位浮点数据,scale 表示缩放比例,zero_point 表示映射零点偏移,round 表示四舍五入的取整操作。因为采用对称式量化,所以zero_point 为0。通过KL 散度校准训练可以得到最优缩放比例,提升量化后精度。VGG16 网络逐层量化后的部分结果如表1 所示,可以看到量化后结果全部为整数,且缩放比例均为2 的整数幂,可以通过移位实现缩放,易于在硬件上实现8 位定点数量化。
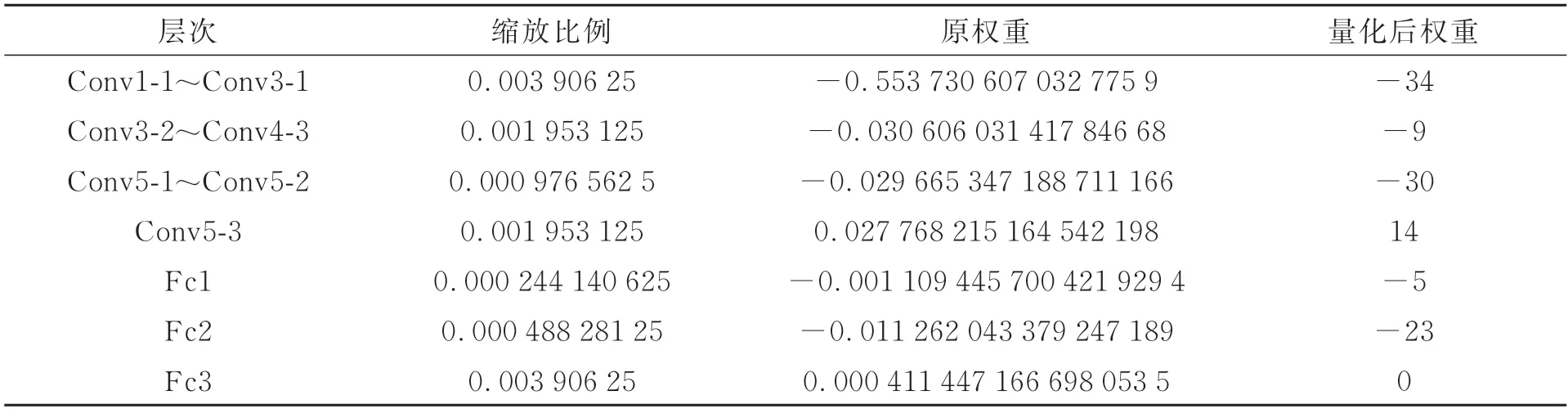
表1 VGG-16 网络量化后的部分结果Tab.1 Partial results after quantification of VGG-16 network
硬件量化流程如图3 所示。将32 位浮点数权重经过训练后量化,可以得到8 位定点权重,与8 位定点特征数据卷积后,扩展位宽到16 位。经过多通道累加,输出数据位宽扩展到32 位。之后累加上偏置,利用移位量化得到下一层计算所需的8 位定点特征数据。为减小误差,移位量化时对需要舍去的小数位采用向偶数进位的模式。

图3 硬件量化流程图Fig.3 Diagram of hardware quantification flow
4.2 输入数据缓存复用模块
FPGA 的存储资源可以分为片上存储和片外存储两种。片上存储主要是Block RAM,它存储和读取的速度快,但是容量小,无法将网络权重数据全部保存在片上,只能够将其存于片外存储DDR 中,再分批输入到片上进行计算。
卷积计算时一个输出通道的结果需要累加全部输入通道的中间计算结果。为了减少片上缓存的占用,采用输入通道切片的方式处理特征数据。计算完成一组输出通道对应的全部输入通道切片后,再切换到下一组输出通道。
切片卷积的整体流程如图4 所示。开始某一卷积层计算后,循环完成部分卷积核的切片卷积计算。待部分卷积核的全部层卷积完成后,更换卷积核继续进行循环卷积,直至全部卷积核都已运算完成,结束当前卷积层运算。
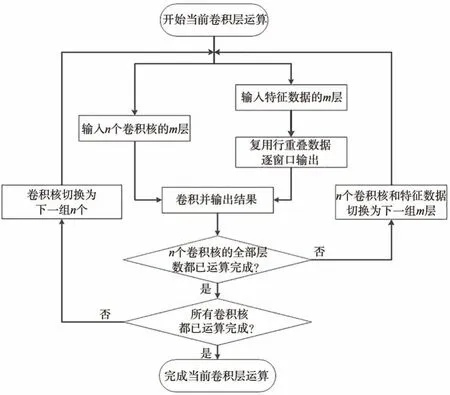
图4 切片卷积流程图Fig.4 Slice convolution flow chart
为了便于不同输入通道同时计算,使用特征数据融合设计。原输入顺序是输入第一通道后再输入下一通道,这种方式需要将全部数据输入完成后才可开始计算,占用较多的存储空间。而经过数据融合,可以将同一位置的4 个输入通道数据组合传输,如图5 所示。这种设计可以充分利用输入数据位宽,在得到中间结果后,不需要暂存中间数据就可以完成结果累加,减少了片上缓存的占用。

图5 特征数据融合设计图Fig.5 Design drawing of feature data fusion
在输入数据缓存复用模块中,因为Winograd卷积的特殊性,输出窗口大小为4×4,步长为2。这就导致相邻窗口间有步长为2 的数据重叠。为了复用行重叠数据,本文设计了循环复用的输入数据缓存模块,如图6 所示。设置6 个Block RAM,每个存储一行特征数据。数据以128 bit 位宽顺序写入,当写入完成前4 个Block RAM 后,在写入第5 个Block RAM 的同时,并行输出前4 个Block RAM。当Block RAM 数据全部输出后,第5、6 个Block RAM 也完成写入,此时在写入第1 个Block RAM 的同时,复用第3、4 个Block RAM 数据,并行输出后4 个Block RAM。依此交替,3 个状态构成循环的一个周期。在降低片上存储占用的同时,实现了串并转换和行数据复用。

图6 输入数据缓存复用模块示意图Fig.6 Schematic diagram of input data buffer reuse module
4.3 Winograd 流水线卷积模块
卷积计算存在内部的并行性,分别是行并行、列并行、输入通道并行、输出通道并行和核内并行。从算法层面看,这5 种并行方式可以任意组合先后顺序。但从硬件实现的角度,合理的并行计算方式可以节省片上资源,提高计算效率。经分析,本文选择使用4 输入通道并行、8 输出通道并行、核内16 并行度的方式进行卷积计算。
Winograd 卷积需要逐步计算完成,采用流水线的设计方式可以提高计算效率。卷积模块共分为六级流水线,其结构如图7 所示。
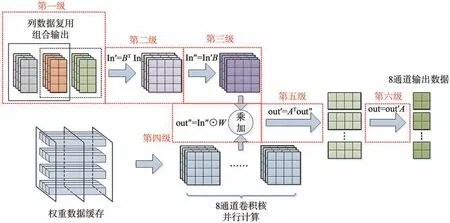
图7 六级流水线卷积设计图Fig.7 Convolution design drawing of six stage assembly line
第一级是列数据复用组合输出。模块接收并暂存输入数据缓存模块输出的4×2 数据,即图中的灰色数据块。等下一周期橙色数据块输入后,组合为4×4 窗口大小输出到第二级,便于下一级进行Winograd 矩阵变换。暂存数据也替换为橙色数据块。下一周期绿色数据块输入后再次组合输出,如此循环往复。缓存的4 行2 列数据每周期切换,实现了相邻窗口之间的列重叠数据复用,提高了数据利用效率。
第二级和第三级是矩阵变换。特征矩阵和权重矩阵都需要进行变换。由于权重是预先训练完成的,可以提前变换后保存在DDR 上直接输入,降低片上资源的占用。因此只需要对特征矩阵乘上常数矩阵进行变换。
第四级是多通道并行乘加。多输入通道和多输出通道可以并行相乘,这也是计算最为集中的环节。不同输入通道的中间结果累加后才可以得到输出数据,为了优化时序,使用加法树的方式进行累加。
最后经过第五级和第六级矩阵变换之后,就可以得到8 个输出通道的2×2 输出数据。作为中间结果输出到缓存模块暂存。
以VGG-16 网络的第一层卷积为例,当输入图像为图8 时,可以得到输出前8 个输出通道结果以灰度图展示如图9。

图8 河流图的遥感图像Fig.8 Remote sensing image of river map

图9 卷积输出灰度图Fig.9 Grayscale image of convolution output
4.4 数据累加输出模块
数据累加输出模块(图10)获取到卷积模块的输出数据后,按照输出通道不同,暂存在缓存A 的不同Block RAM 中。当存储完一组卷积核的一组输出结果后,在下一组结果输入前依次读出,一起输入加法树累加后再次存入Block RAM,覆盖之前的结果。当这组卷积核的全部结果计算完成后,切换缓存,使缓存B 继续存储结果,缓存A 则输出所有计算结果到DDR 中。这种设计可以在不中断数据输入和计算的同时输出结果,减少了数据输出时的阻塞时间。
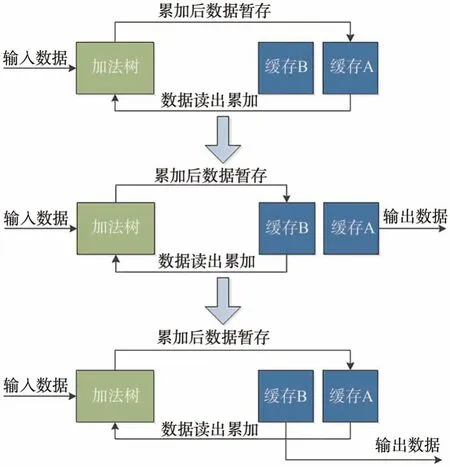
图10 数据累加输出模块状态图Fig.10 Status diagram of data accumulation output module
在卷积计算之后,裁剪了边缘处的数据,输出特征图像的尺寸会减小。随着网络层数的加深,如果不做处理,特征图像尺寸会越来越小,造成信息的丢失。为了防止这一现象,在一层数据输出时进行padding 填充,即对特征图像周围补0。为了减少数据传输时间、节省存储资源,在设计中省略了第一行和最后一行全部数据为0 的值,只在中间行的首尾列补0,在特征数据窗口读取时再补首末行的0。
5 实验结果及分析
5.1 实验环境
本文的实验平台为Xilinx 公司的ZCU104 开发板,芯片型号为XCZU7EV-2FFVC1156。PS 端片外存储为2 GB 大小的DDR4,PL 端片上存储为38 Mb 的Block RAM 和Ultra RAM,可以满足实验需求。在RTL 代码编写完成后,使用Vivado 2018.3 进行仿真测试。在综合实现完成后,编写SDK 程序,烧录上板进行实验。
本文基于经典的VGG-16 网络进行了改进。VGG-16 网络具有提取特征能力强,结构清晰简单、易于修改的特点,且其卷积核尺寸小,全部为3×3,更便于Winograd 算法的应用。但是VGG-16 网络主 要针对ImageNet ILSVRC2012 数据集进行1 000 种标签的分类,为了将其适用于遥感图像分类的任务中,使用NWPU-RESISC45 数据集对其进行迁移学习,并修改最后的全连接层输出为45,对应数据集的飞机、机场、棒球场、篮球场、沙滩等45 种标签。修改后的VGG-16 网络结构如表2 所示。

表2 修改后的VGG-16 的网络结构Tab.2 Revised VGG-16 network structure table
5.2 性能分析
设定加速器时钟频率为200 MHz,经综合实现后硬件资源占用情况如表3 所示。其中LUT表示片上所有查找表;LUTRAM 表示作为存储资源使用的查找表;BRAM 和URAM 表示片上的专用块RAM 存储器;DSP 则表示片上运算单元,主要用于乘法运算当中。
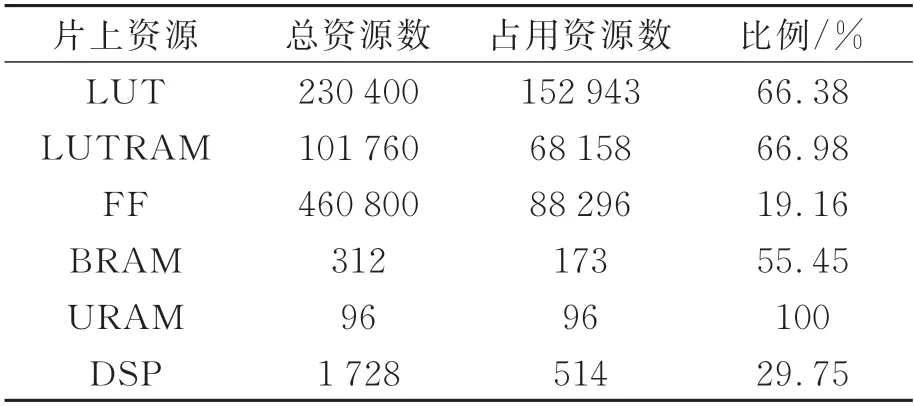
表3 硬件资源占用情况Tab.3 Hardware resource usage
可以看出,加速器使用DSP 资源比例相较LUT 和BRAM 等资源比例较低,原因在于数据带宽限制了数据传输速度。如果通过提高DSP 使用量的方式继续提升加速效果,可以更换硬件资源更丰富、带宽更大的开发板平台或者使用PL 端的DDR 存储图像和权重数据。在时序稳定的前提下,也可以通过提高时钟频率来获得更快的加速效果。
实验时,首先读取SD 卡中的权重数据和图像数据到DDR 内存上,读取后的图像数据如图11所示,位于DDR内存的0×1 000 000地址处。

图11 图像数据存入DDR 内存展示图Fig.11 Display diagram of image data stored in DDR memory
硬件实验平台如图12 所示。读取图8 所示图像后完成计算,通过串口输出到上位机得到图像分类的标签与分类概率,如图13 所示。

图12 ZCU104 硬件平台测试图Fig.12 ZCU104 hardware platform test diagram
在NWPU-RESISC45 数据集上验证后得到FPGA 实现遥感图像分类的TOP-1 准确率,与GPU 实现的准确率对比如表4 所示。在精度损失不超过1%的情况下,将网络大小压缩为原大小的28.6%,效果显著。

表4 硬件实现后网络精度对比Tab.4 Comparison of network accuracy after hardware implementation
将加速器与其他方案的实验结果进行对比,如表5 所示。由于不同的设计方案采用的FPGA平台不同,因此将计算效率和能效作为主要性能指标进行分析。本文提出的加速器与文献[16]的Caffeine 结构、文献[17]的Angel-Eye 结构相比,使用了更少的硬件DSP 资源,实现了更高的计算吞吐量。与文献[18]中提出的将乘加树与脉动阵列相结合的乘加阵列相比,虽然由于硬件规模不同,在卷积层计算性能方面存在差距,但是本设计在能效比上较为接近,且DSP 计算效率提升为1.635 倍。
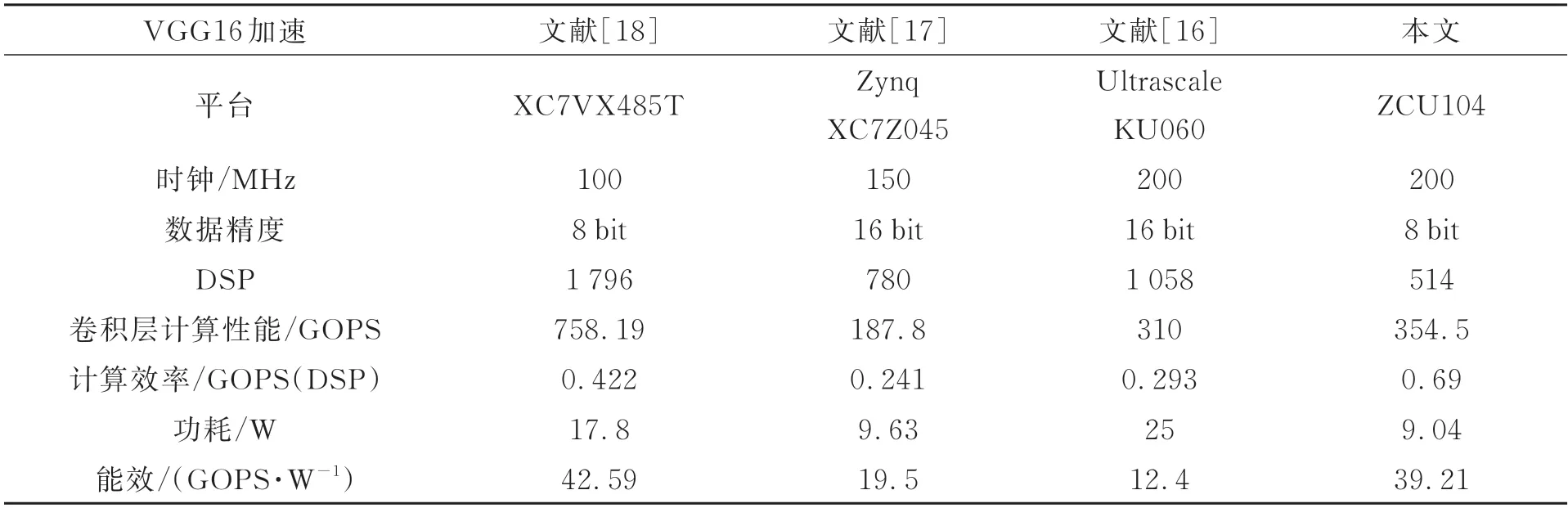
表5 与现有FPGA 加速方案的对比Tab.5 Comparison with existing FPGA acceleration schemes
6 结 论
本文提出了一种基于FPGA 的Winograd 算法卷积神经网络加速器。在卷积算法方面,采用Winograd算法减少乘法运算量,并设计了输入数据缓存复用和流水线相结合的方式,充分复用了行列间的重叠数据,提高了传输效率。使用8 位定点数对权重和数据量化,提高数据吞吐速率和加速器计算效率。经过六级流水线并行卷积计算之后,得到的数据分组循环累加,降低了片上缓存的占用。在ZCU104开发板上的实验表明,加速器卷积层计算性能达到了354.5 GOPS,片上DSP 计算效率达到0.69,与相关研究相比,实现了1.6 倍以上的提升。本设计在计算效率上优于其他FPGA加速器设计方案,能够以较高能效完成遥感图像分类任务中的硬件加速计算。
