融合CatBoost和SHAP的乳腺癌预测及特征分析
2023-11-14贾潇瑶
贾潇瑶
(1.昌吉学院数学与数据科学学院,新疆 昌吉 831100;2.新疆财经大学统计与数据科学学院,新疆 乌鲁木齐 830012)
0 引 言
随着互联网和人工智能技术的不断发展、医疗数据库的不断扩大,基于人工智能的疾病预测已成为研究热点。其中,机器学习作为人工智能的主要工具,已成功应用于糖尿病预测[1-3]、冠心病预测[4-5]和双高疾病预测[6-7]等方面[8-9]。
乳腺癌作为女性中最常见的癌症,是所有癌症中最具侵略性的癌症之一[10]。根据2020年的一项全球癌症统计发现,中国乳腺癌新发病例数为42 万例,为中国女性恶性肿瘤新发病例之首,占整体女性恶性肿瘤的19.9%,且乳腺癌已正式取代肺癌成为世界第一大癌症[11]。此外,由于经济增长带来的生活方式、社会文化和建设环境的巨大变化,以及女性在工业劳动中比例的增加,导致女性推迟生育、少子化、超重和缺乏运动,从而加速了乳腺癌发病率的上升。鉴于此,基于机器学习的低成本乳腺癌的可解释预测研究具有现实意义。
现阶段,大部分的乳腺癌预测主要基于KNN[12-13]、WAUCE[14]、ABCoDT[15]、SVM[16]、Gradient Boosting Classifier[17]和神经网络方法[18-21],分别作用到Breast Cancer Wisconsin(Diagnostic)[22]、Wisconsin Original Breast Cancer[23]和Breast Cancer Coimbra Dataset[24]这3 个数据集上进行探索。虽然乳腺癌预测模型在不断发展,但是这些模型不能同时满足临床应用的高性能和可解释的需求。在此背景下,为了提高乳腺癌预测模型的性能,并增强其可解释性,本文在威斯康星大学的Breast Cancer Wisconsin(Diagnostic)数据集上分别进行数据预处理、CatBoost模型的建立、泛化能力分析和可解释处理等内容,以满足临床应用的需求。总的来说,本文的主要工作分为以下3个部分:
1)基于CatBoost 算法构建乳腺癌预测模型,并将其Accuracy、Precision、Recall和F1值指标结果与现有文献以及主流机器学习模型结果进行对比,以此验证本文的优越性。
2)在保障第1 个部分的高性能同时,本文进行泛化能力分析,分别与主流机器学习模型中性能较好的进行对比,以突显本文方法出色的泛化能力。
3)为了缓解CatBoost 的“黑盒”机制引起的可解释差的问题,本文将使用SHAP 值进行事后可解释分析,以提高医生的决策质量。
1 相关研究
本章将简要回顾基于机器学习[12-17]和基于深度学习[18-21]的乳腺癌预测相关工作,如表1所示。

表1 已有相关工作综合比较
基于机器学习,Zhang 等人[12]首次将BSO 算法应用到特征选择,并结合KNN 算法进行乳腺癌的分类预测,在Breast Cancer Wisconsin 数据集上实验得到Accuracy 值为98.18%。Wang 等人[14]提出了一种基于SVM 的加权AUC 集成学习模型用于乳腺癌诊断。该模型利用具有6 个内核函数的C-SVM 和vSVM 来增加基模型集的多样性,还定义了5 种融合策略,以聚合来自不同基础模型的决策。使用Breast Cancer Wisconsin 数据集作用到该模型,发现Accuracy 值为97.68%,Recall值为94.75%,以此验证模型的可行性。Rao 等人[15]基于蜂群和梯度提升决策树提出一种特征选择算法,旨在解决乳腺癌数据的特征效率和信息质量等问题,并在此基础上使用Breast Cancer Wisconsin 进行实验,得到Accuracy 值为97.18%。Abdel-Basset 等人[13]为了解决基于包装方法的乳腺癌分类预测的特征选择问题,提出了一种集成2 相突变的灰狼优化算法,并融合KNN 算法作用到Wisconsin Original Breast Cancer 数据集,实验表明Accuracy 值为73.63%,这较已有文献性能较差,未达到应用的要求。El Filali等人[16]在Breast Cancer Wisconsin 数据集上应用了支持向量机、随机森林、逻辑回归、决策树和K 近邻这5 种机器学习算法进行乳腺癌预测,经过对比实验发现支持向量机的性能最好,其Accuracy、Precision、Recall 和F1 值分别为97.20%、97.50%、99.00%和98.00%。Mishra等人[17]提出了一种基于二元粒子群优化(BPSO)的特征选择方法,可用于提高乳腺癌自动预测CDSS 的性能,并引入Gradient Boosting Classifier 算法对乳腺癌进行分类,实验发现在Breast Cancer Coimbra Dataset 数据集上Accuracy和Recall值分别为76.67%、80.54%。
基于深度学习,Agarap[18]使用整流线性单位(ReLU)作为深度神经网络DNN中的分类函数,并使用Breast Cancer Wisconsin(Diagnostic)数据集进行性能评估,得出Accuracy、Precision、Recall和F1值分别为92.40%、92.00%、92.00%和92.00%,该性能略低于机器学习算法的性能。Liu等人[19]提出了一种新型的智能分类模型用于乳腺癌的智能诊断。该模型首先采用IG 进行特征排名,然后根据重要性排名,再引入SAGAW 混合方法进行特征选择,并利用BP作为底层分类器用于乳腺癌诊断。结果表明,所提出的智能分类模型在Breast Cancer Wisconsin(Diagnostic)数据集上不仅能有效评价误分类成本,还能提高乳腺癌诊断性能,降低计算复杂度。Singh等人[20]提出了一种利用Ant Lion优化算法的包装方法用于乳腺癌预测,该方法同时搜索多层神经网络的最佳特征权重和参数值,并将隐藏神经元和反向传播训练作为神经网络的参数。在Breast Cancer Coimbra Dataset 数据集上实验得到Accuracy值为82.79%。甘丹[21]采用GA算法对多属性医疗数据的属性权重进行优化,将归一化的属性特征与权重组合,作为多层感知机输入层的新输入数据,并寻找多层感知机网络层数、神经元个数、激活函数和优化器的最优参数组合进行乳腺癌分类。同样在Breast Cancer Coimbra Dataset 数据集上,获得的Accuracy值仅为66.42%,较已有研究性能不佳。
总的来说,已有文献的乳腺癌预测差异集中在数据集和方法这2 个方面。虽然现有文献在机器学习方法上性能相对较好,但是在预测的各指标性能上仍有提升空间。此外,现有模型只保障了模型的性能,忽略了模型的可解释性,这不能很好地帮助医生诊断。鉴于此,本文提出一种融合CatBoost 和SHAP 的乳腺癌预测及特征分析模型,在提高乳腺癌预测性能的同时,增强模型的可解释性,为临床医生提供原理性的支撑。由此,本文较已有研究的特色在于:
1)模型的不同:区别于现有文献基于KNN、SVM和Gradient Boosting Classifier 等的预测模型作用到Breast Cancer Wisconsin(Diagnostic)数据集,本文使用集成学习CatBoost算法作用在同样的数据集上,结果显示Accuracy 指标提升了1.12~6.90个百分点,Precision指标提升了2.00~7.50 个百分点,Recall 指标提升了2.41~6.91个百分点,F1值提升了2.19~7.19个百分点。
2)可解释性的增强:现有文献中的乳腺癌预测模型均为“黑盒”模型,无法对预测结果做进一步的可解释。而本文引入SHAP,能够对乳腺癌的风险因素进行分析,为临床医生诊断提供原理性的支撑。
2 模型构建
本文提出一种融合CatBoost和SHAP的乳腺癌预测及特征分析模型,其流程如图1所示。

图1 融合CatBoost和SHAP的乳腺癌预测及特征分析模型的流程图
2.1 乳腺癌预测模型的构建
本文方法CatBoost[25-26]作为一种对称树结构的算法,是在GBDT[27]的基础上,采用一种改进的标准TS(目标统计)以避免训练集和测试集的数据结构和分布不一致时产生的条件偏移,再使用Ordered boosting 的算法减少梯度估计偏差,进而避免模型的过拟合。具体步骤如算法1所示。
算法1Prediction model training algorithm。


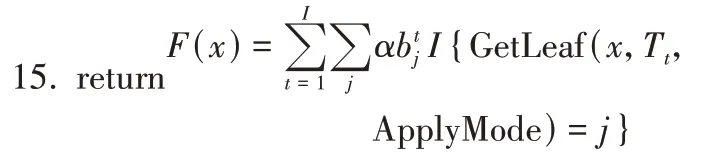
算法1 第1 行对数据集随机采样一个序列。第2行是第0个序列每个样本模型的初始化,共n个模型。第3~7 行,在2 个boosting 模型中进行选择,其中Plain模型为内置有序TS 的标准GBDT 算法,Ordered 模型为改进算法;然后分别计算目标变量的一阶梯度和二阶梯度,即模型初始预测与实际目标变量之间的差别和模型对目标变量的置信程度。第8~15行迭代生成T棵树,在初始化T的基础上,运用贪婪算法,找出全部的分割方式,假设共K种;在K中选出一种分割法建成树Tk,并计算树的叶子结点、前k个叶子结点的梯度均值和第k种分割法的损失,随后挑选最小损失对应的T,使其作为输出值;最后不断地重复直到达到规定的迭代次数K为止,从而训练出预测模型。
2.2 SHAP可解释模型
基于CatBoost 算法的乳腺癌预测可以得到相对较高性能的模型。然而,高性能的同时,触发了Cat-Boost 的“黑盒”机制,造成可解释性差的问题。鉴于此,本文结合SHAP 模型,以增强模型的可解释性。SHAP 是由Lundberg 等[28]提出的一种用于解释“黑盒”模型的解释框架,其核心是计算每个特征的Shap Values,以此来反映特征对于整个模型的预测能力的贡献程度。具体来说,SHAP 将模型的预测值解释为每个输入特征的归因值(Shap Values)之和,即:
其中,f()为的SHAP值。直观上看,f()就是第k个样本中第1 个特征对最终预测值yk的贡献值,当f()>0,说明该特征提升了预测值,起正向作用。反之,说明该特征使得预测值降低,起反作用。
3 实验及结果分析
3.1 实验环境及评价指标
本文在Pycharm2021.1 编译环境下使用Python3.7 和scikit-learn0.24.2 进行实验。在此基础上,乳腺癌预测的结果由混淆矩阵呈现,该矩阵提供每个类别中被正确/错误分类的实例数量,其中正确分类的实例数量,即真阳性(TP)和真阴性(TN)的数量;错误分类的实例数量,即假阳性(FP)和假阴性(FN)的数量。但是由于混淆矩阵不能直接明确得出结论,在实际场景中只是辅助其他方法进行应用。故本文将使用Accuracy、Precision、Recall 和F1 值作为评价指标,其详细信息如表2所示。
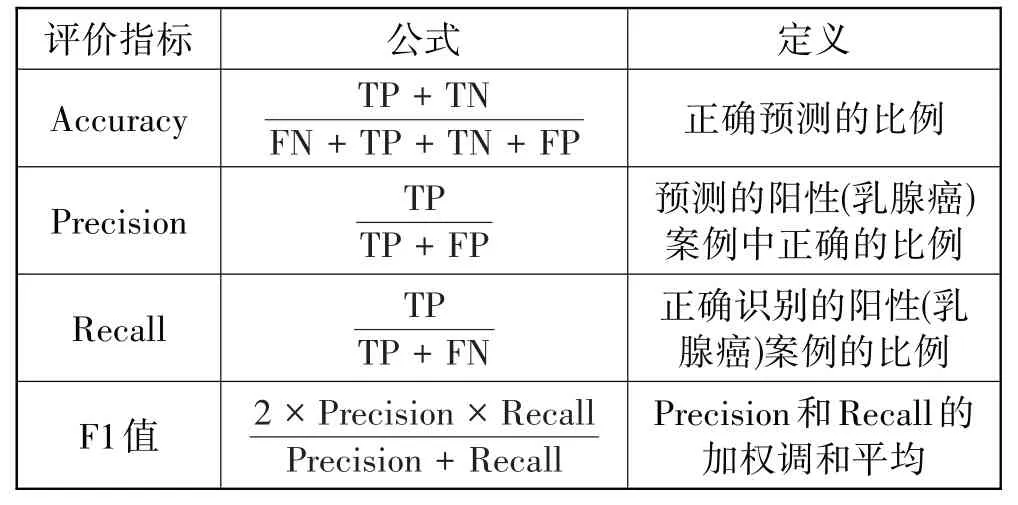
表2 评价指标
表2 中,Accuracy、Precision、Recall 和F1 值越大,说明模型的性能越出色。
3.2 特征工程
数据集来源于威斯康星大学的Breast Cancer Wisconsin(Diagnostic)数据集(本文数据集及代码实现URL: https://gitee.com/jia-xiaoyao/icsbc)。该数据集包含357个良性乳腺肿瘤实例和212个恶性乳腺肿瘤实例,且特征变量分别由乳腺组织细胞核的半径、纹理、周长、面积等10 个变量计算得到,共计30 个。其中,mean 结尾的特征表示计算得到的平均值,se 结尾的特征表示计算得到的标准误差,worst 结尾的特征表示计算得到的极值。由于本数据集没有空值和重复值,故不作处理。
1)异常值处理。
通常,原始乳腺癌数据集会存在部分不合理值的问题。为了解决这个问题,本文使用IQR计算出数据集的四分位数间距,并将其可视化,如图2 所示。实验发现有24 个实例有异常值,本文将异常值使用极值(最大值或最小值)代替。

图2 各特征变量的箱线图
2)数据标准化。
由于各特征变量的量纲不同,使得各特征变量间的可比性困难,大大影响到后续建模的性能。故本文采用MinMax 法对数据进行标准化处理,其详细公式如下:
其中,xj为原始向量x的第j个分量,max(x)和min(x)是相应向量x的最大分量和最小分量,xj_norm为归一化映射后的向量的第j个分量。
3.3 对比实验分析
将本文CatBoost 模型的性能与已有研究提出的KNN[12]、WAUCE[14]、ABCoDT[15]、SVM[16]、DNN[18]、IGSAGAW+BP[19]模型的性能进行比较,如表3所示。

表3 CatBoost的结果与现有研究对比
由表3 可以发现,本文方法得到的Accuracy 值为99.30%,Precision 值为99.50%,Recall 值为98.91%和F1 值为99.19%,均优于现有文献。其中Accuracy 指标提升了1.12~6.90 个百分点,Precision 指标提升了2.00~7.50 个百分点,Recall 指标提升了2.41~6.91 个百分点,F1 值提升了2.19~7.19 个百分点。这表明好的数据预处理过程是提升模型性能的有效手段,从而验证了本文方法的有效性及优越性。此外,为了突出本文方法的性能,将CatBoost 模型的性能与其它8 种主流机器学习方法进行对比,结果如图3所示。
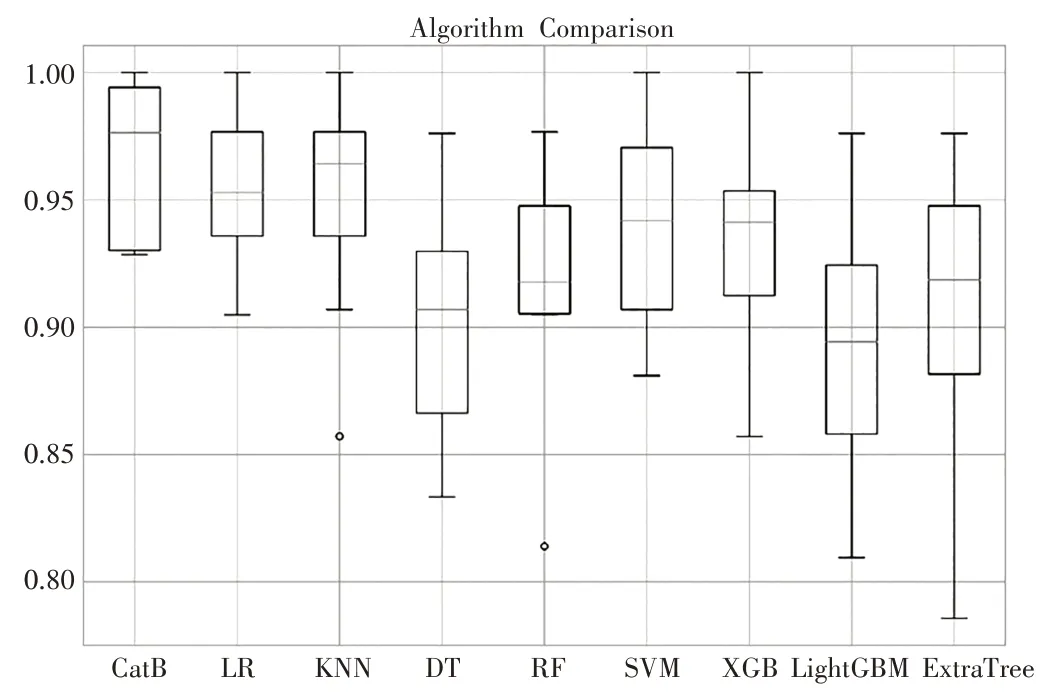
图3 以Accuracy为评价指标的10折交叉验证箱线图
本文采用以Accuracy 为评价指标的10 折交叉验证箱线图进行初步的性能对比。不难发现,CatBoost(CatB)的精度分布最好。为了详细查看各模型性能,本文进行AUC 曲线和Precision-Recall 曲线展示,如图4所示。
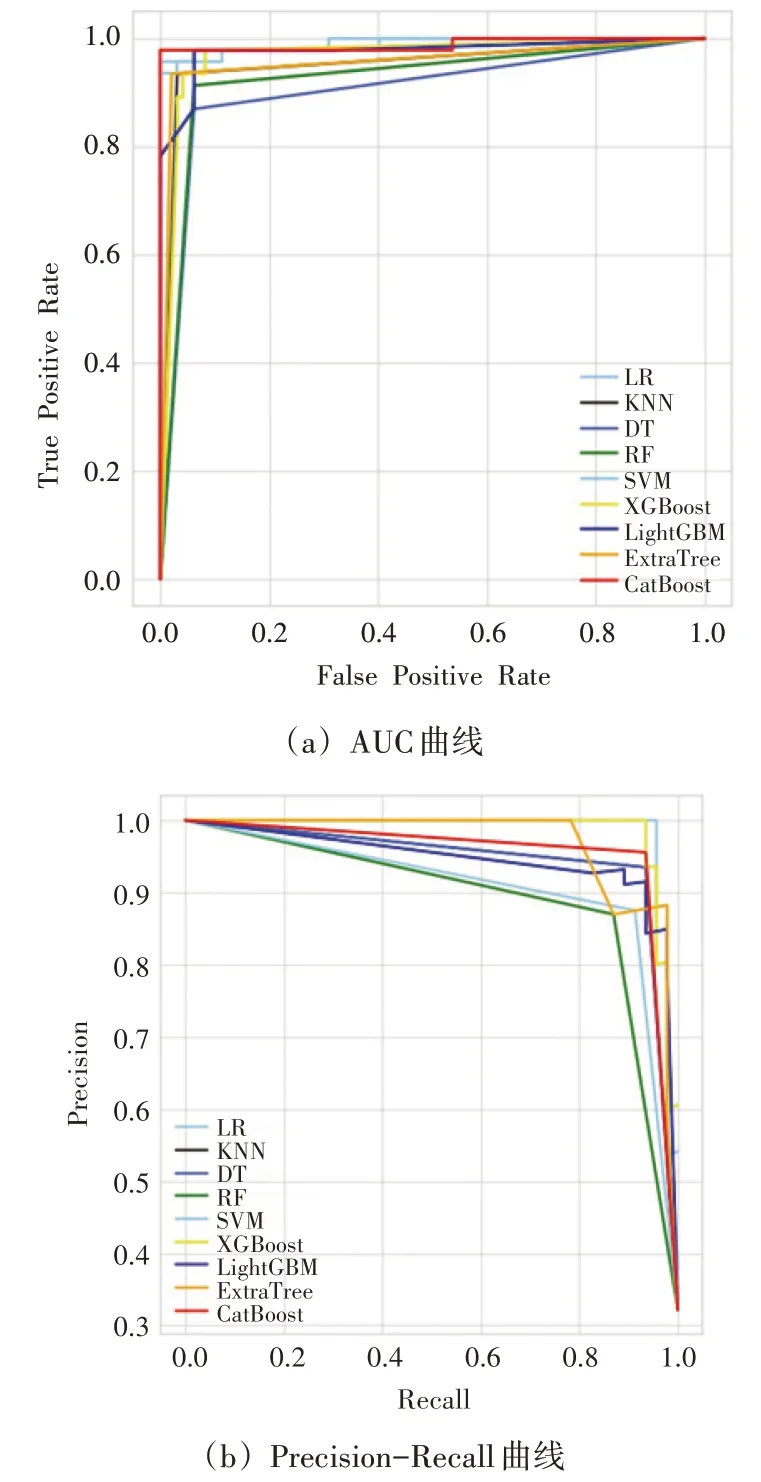
图4 CatBoost与主流机器学习性能比较图
由图4(a)可知,在Logistic Regression (LR)、KNN、Decision Tree (DT)、Random Forest (RF)、SVM、XGBoost (XGB)、LightGBM、ExtraTree 和Cat-Boost 这9 种算法中,CatBoost 的预测模型最好,其AUC 值为98.83%。其次分别是Logistic Regression(LR)、SVM、LightGBM、XGBoost (XGB)、ExtraTree、KNN、Random Forest(RF)和Decision Tree(DT),且AUC 值分别为98.79%、98.78%、97.62%、96.76%、95.71%、95.19%、92.56%和90.39%。而在图4(b)中,本文方法在Precision和Recall这2个性能指标上的值为99.49%和98.91%,这较Logistic Regression(LR)模型分别提升了0.99个百分点和2.17个百分点,以此凸显了本文方法出色的性能。
3.4 泛化能力分析
判断乳腺癌预测算法的好坏,除了上述的性能优势分析外,还需要查看乳腺癌预测算法的泛化能力,即该模型在新数据上的表现。故本文进行学习曲线分析,以探索模型的泛化能力。
图5 显示了部分主流模型与CatBoost模型的学习曲线图,其中横坐标代表训练数据集的样本个数,纵坐标是训练数据集和交叉验证的评分结果,即Accuracy。可以发现Logistic Regression(LR)模型的学习曲线处于高偏差状态,致使模型学习的能力不足。而CatBoost、ExtraTree 和SVM 模型的学习能力相对较好,但CatBoost模型在测试集上的鲁棒性更为优越。
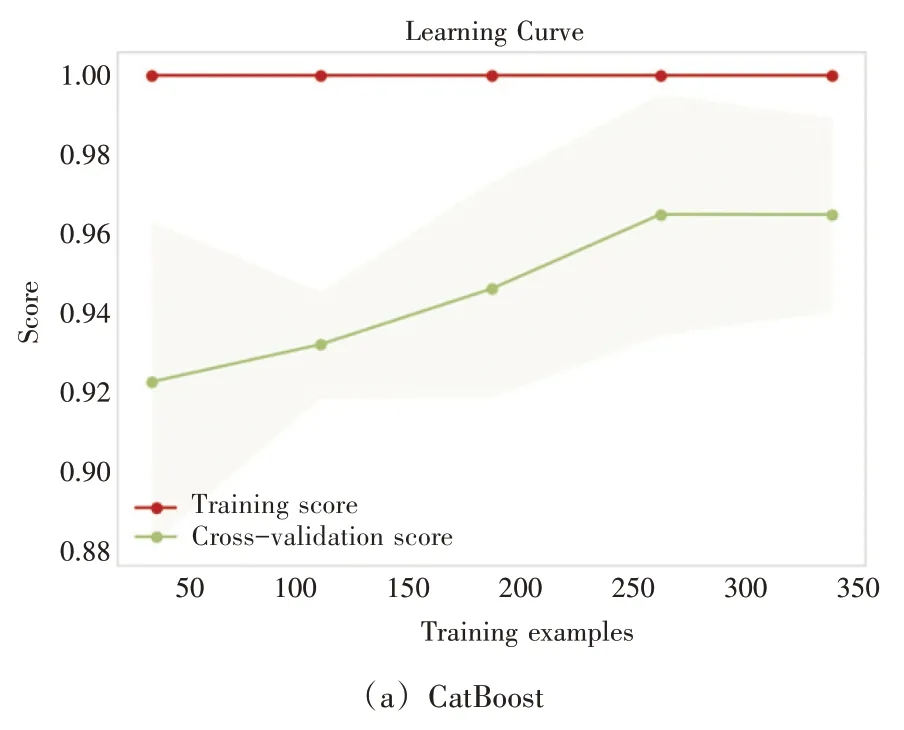
图5 学习曲线
3.5 乳腺癌预测的可解释分析
图6 显示了基于CatBoost 的SHAP 摘要图以及模型自带的特征重要性的排序图,其中从图6(a)可以看出:concave points_worst(乳腺组织细胞核凹点极值)、perimeter_worst(乳腺组织细胞核周长极值)、area_worst(乳腺组织细胞核面积极值)、concave points_mean(乳腺组织细胞核凹点平均值)和texture_worst(乳腺组织细胞核质感极值)特征对是否患有乳腺癌有关键影响,并且这些关键特征对乳腺癌有着正向作用。随着值的增长,乳腺癌的风险增加。而从图6(b)可以看出concave points_worst、texture_worst 和texture_mean(乳腺组织细胞核质感平均值)对是否患有乳腺癌具有重要意义。
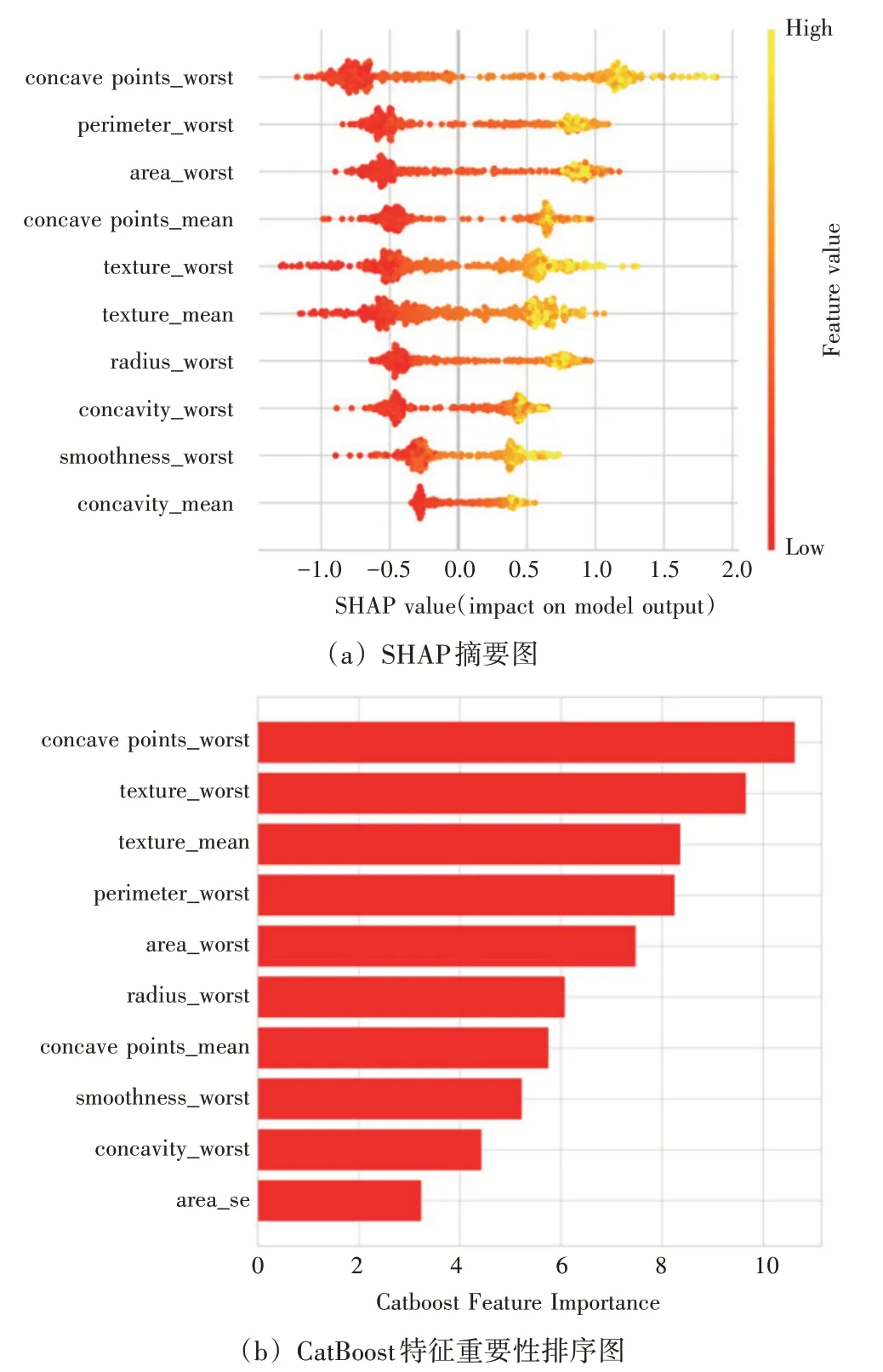
图6 模型的可解释图
此外,本文还选取了concave points_worst、perimeter_worst和area_worst这3个重要的特征进行特征依赖分析,如图7 所示。其中,横坐标为该特征的值,纵坐标为该特征的SHAP 值。不难看出,这3 个核心风险因素都随着特征值的增加,SHAP 值也增加,表明这3 个核心风险因素都对促成乳腺癌具有正向作用。显然,area_se(乳腺组织细胞核面积标准误差)对concave points_worst 有驱动作用,而compactness_mean(乳腺组织细胞核紧凑度平均值)对perimeter_worst和area_worst有驱动作用。

图7 concave points_worst、perimeter_worst和area_worst的特征依赖图
4 结束语
本文对乳腺癌进行可解释预测研究,提出了一种融合CatBoost 和SHAP 的乳腺癌预测及特征分析模型。该模型分别由数据预处理、模型预测分析和可解释分析这3个部分构成。
首先,该模型的数据预处理将不规范、不准确和不完整的原始数据进行清洗,以得到质量较高的数据。其次,该模型的预测是基于CatBoost 算法所构建,并进行了泛化能力分析。最后,采用SHAP 值,以解决CatBoost 预测模型的“黑盒”问题,这有效兼顾了高性能和可解释。与已有研究相比,本文提出的方法在Accuracy 指标上提升了1.12~6.90 个百分点,而且弥补了已有研究的可解释性差的问题,以此验证了本文的优越性。在下一步工作中,将对特征工程、模型训练和泛化能力等方面进一步优化。
