面向在线学习情境的认知情绪面部表情识别
2023-11-14陈子健段春红
陈子健,段春红
(贵州财经大学信息学院,贵州 贵阳 550025)
0 引 言
认知情绪是学习者在处理新的、非常规的任务时由认知问题引发的情绪。不同于日常生活情境中发生频率最高的6 种基本情绪,学习情境中最常产生的认知情绪是困惑、厌倦、沮丧、兴趣等[1-2]。随着认知加工活动的进行,认知情绪的类别也发生动态变化。赋予在线学习系统识别认知情绪的能力,可以发挥认知情绪监测在学习中的价值潜能,有助于全面、科学地评估学习者的学习状态,也有助于实现人机情感交互,推动智适应教学系统的发展。
情绪作为一种内隐的心理状态,无法直接测量,一般通过对情绪体验、外显表情和生理唤醒3 个情绪构成要素的调查或测量,间接实现对情绪的识别或测量。在线学习情境中的认知情绪识别不仅需要提高识别的准确率,还需考虑识别方式的适切性,降低监测过程中对学习者的侵入性,避免干扰学习者的学习。面部表情是情绪的主要表现形式[3],并且人类的面部表情也是不学而能的,新生儿就会因饥饿呈现哭闹表情,因舒适呈现微笑表情,因惊吓呈现恐惧表情[4]。由于进化中适应生存的需要,人类各种具体情绪的适应功能各不相同,情绪的功能差异又通过各种不同的面部表情实现[5],即情绪和面部表情之间存在先天的一致性。虽然由于社会规范、道德、价值标准的约束,人类在后天生活过程中,可能学会抑制或修饰自身情绪的面部表情,但是在线学习情境中,学习者是单独处在一个虚拟学习空间中进行自主学习,不存在对情绪的面部表情进行抑制或修饰的需求。
目前,面部表情识别领域的研究人员普遍将6 类基本情绪面部表情作为研究对象,利用实验室环境下收集得到的受控面部表情库开展研究,如JAFFE、CK、CK+、MMI、Oulu-CASIA 等,并取得了较好的识别率,但是实验室中采集的受控面部表情大部分是故意摆拍,无法反映现实生活中的复杂场景[6],针对真实世界中面部表情的识别研究是推进面部表情识别发展和应用的重点。收集和创建真实世界中的面部表情数据库,又是推进真实世界中面部表情识别研究的首要环节。针对此问题,本文设计认知情绪诱发实验,创建认知情绪面部表情库,用于认知情绪面部表情识别算法的开发和评估。
有效提取具有判别能力的特征是面部表情识别的核心问题。自从Kahou 等人[7]构建由多种不同类别网络组成的混合深度神经网络,实现面部表情特征的自动提取和分类,并取得EmotiW2013 情感识别大赛冠军,越来越多的研究者采用深度学习的方法进行面部表情特征的提取。相关研究主要是对已有的网络结构进行优化,如增加Inception 模块[8],引入残差结构[9-10],引入对抗生成网络[11],将局部块注意力机制引入深度网络中,对面部表情分区进行学习[12-13],以增加网络的特征学习能力,或者设计新的网络损失层辅助网络模型的训练,以进一步降低面部表情类内差异[14-15]。对于视频序列形式的面部表情,则将面部表情的空间域特征和时间域特征相结合来提高识别的性能[16-18]。真实学习情境中的认知情绪面部表情具有短暂性、局部性、细微性的特点,为了针对性地学习到具有表情判别性的特征,本文设计混合深度神经网络实现面部表情在空间域和时间域中的几何特征和表观特征,融合2种特征识别认知情绪面部表情。
1 方法介绍
面向在线学习情境的认知情绪面部表情识别,首先需要解决的是学习者监测画面中的人脸检测问题,然后在提取面部表情特征的基础上识别面部表情。面部表情是一个动态的过程,既有空间域的特征,又有时间域的特征。空间域特征既包括眉毛、眼睛、鼻子、嘴唇等单个或多个面部器官的几何特征,也包括由于面部肌肉运动产生的皱纹、沟纹、纹理等表观特征。实现面部表情的本质特征提取是提升识别准确率的重要途径,因此本文提出基于双模态空时域特征的面部表情识别方法,通过设计混合深度神经网络,实现面部表情的空时域几何特征和空时域表观特征的自动提取,融合2 种模态的特征识别图像序列形式的面部表情。将提出的方法应用于认知情绪面部表情识别,创建认知情绪面部表情库,训练认知情绪面部表情识别的网络模型,并对模型的性能进行测评。
图像序列形式的面部表情从起始到结束的持续时间是一个变化量,而神经网络自身的特点决定了输入数据的维度是一个恒定值。也就是说,不能直接将图像序列形式的面部表情输入神经网络,因为每个表情包含的图像帧数量不一致。为了解决这个问题,本文参考相关研究[18-19],从面部表情的图像序列中选取固定数量的代表帧作为神经网络的输入。代表帧选择的计算公式如下:
式中,F'表示选取的面部表情代表帧集合;ft表示代表帧,下标t是代表帧的时间码;ton和tapex分别表示面部表情图像序列中起始帧和峰值帧的时间码;n表示要选取的代表帧的数量。
设计的混合深度神经网络由全连接神经网络(FCN)、卷积神经网络(CNN)和长短时记忆网络(LSTM)这3 个子网络构成。认知情绪面部表情的识别流程如图1 所示:1)在面部表情图序列的起始帧和峰值帧之间选取统一数量的代表帧;2)检测所有代表帧中人脸,并对图像进行裁剪,只保留人脸区域图像;3)对所有代表帧中的人脸特征点进行定位,特征点坐标值组成的向量,用于表征面部表情的空间域几何特征;4)所有代表帧的空间域几何特征输入FCN 子网络,进一步提取空时域几何特征;5)第2 步中,裁剪后的代表帧输入CNN 子网络,提取代表帧在空间域的表观特征;6)所有代表帧的空间域表观特征输入LSTM子网络,进一步提取空时域表观特征;7)融合后的空时域几何特征和空时域表观特征,通过全连接层输入分类器,分类器输出面部表情在各个类别上的概率分布。
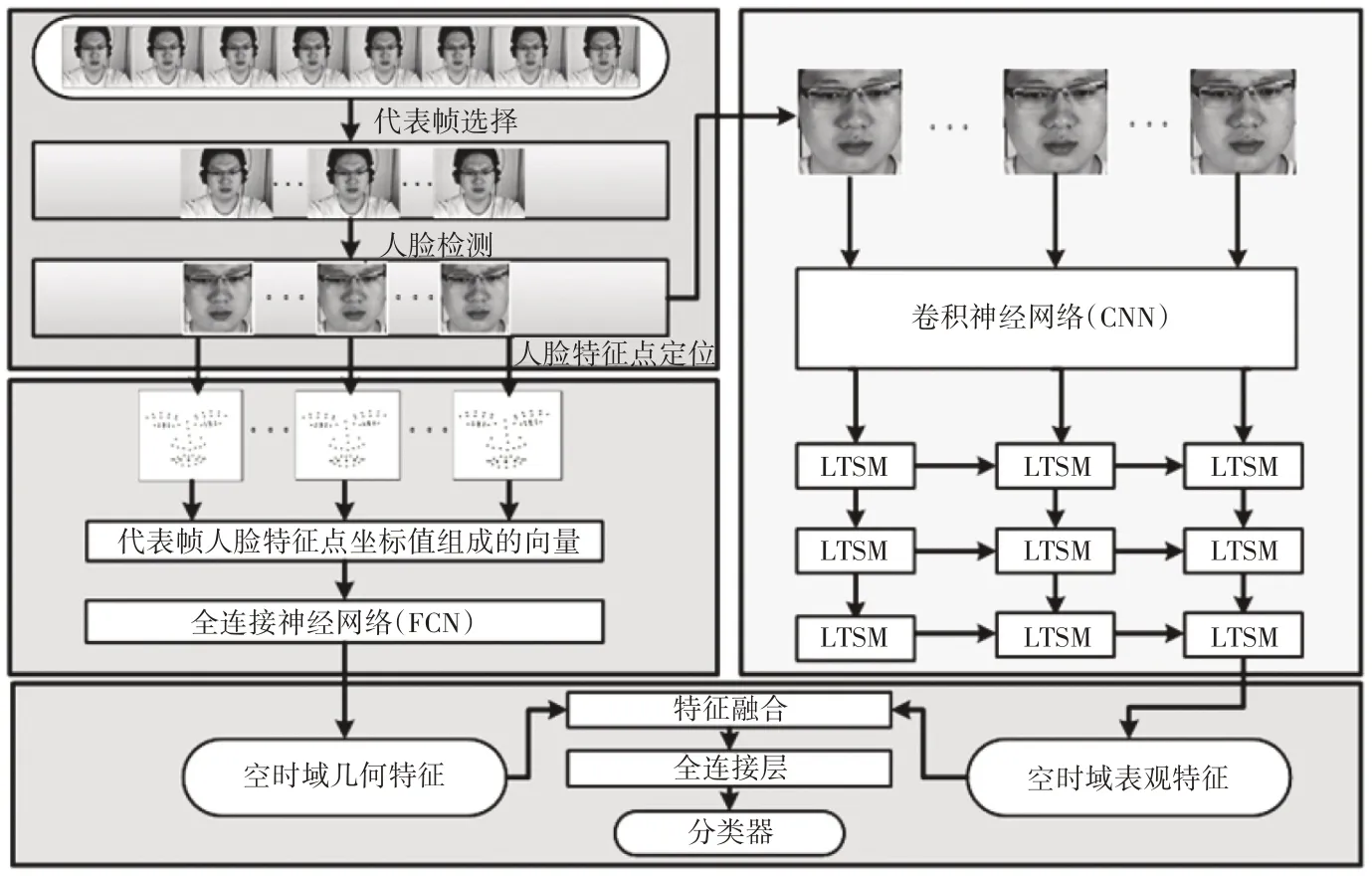
图1 认知情绪面部表情识别流程(表情实例来自CASME Ⅱ[19]数据库)
1.1 人脸检测
人脸检测属于目标检测的范畴,就是判断给定的图像上是否存在人脸,如果存在,则输出人脸所处的位置及其边框信息。传统的VJ[20]人脸检测算法提升了人脸检测的速度,推动了人脸检测的发展,但是仍然采用的是暴力穷举式的滑窗法,并且只提取窗口图像的底层特征,检测的精度还有待提升。随着目标检测的迅速发展,新的检测算法层出不穷,代表性的算法有Faster R-CNN[21-22]、SSD[23-25]、YOLO[26-28]等。本文构建基于Faster R-CNN 框架的人脸检测器,其网络结构如图2所示。其中,CNN 输出检测图像的卷积特征图,RPN在卷积特征图的基础上生成人脸候选区域,候选区域的图像特征图经过RoI 池化后,分别输入分类器和回归器,分类器判断人脸候选框是不是人脸,回归器对人脸候选框的坐标位置进行调整,以获取更高精度人脸检测框。

图2 人脸检测器网络结构
利用Wider-Face[29]中的人脸样本训练人脸检测器,利用FDDB[30]中的人脸样本测试人脸检测器的性能。其中,CNN 采用Incetption ResNet V2网络结构,并使用预训练模型对权值参数进行初始化,以加速人脸检测网络的训练。构建均值为0、标准差为0.01 的高斯分布,对人脸检测网络中其它层的权值参数进行随机初始化。在人脸检测测试实验中,AP 值为0.9049,误检数为500 时,TPR 值为0.93。图3 呈现了人脸检测器的一个测试实例。从图中可以发现人脸检测器对图像中不同位置、不同大小、不同方向的人脸都具有较好的检测效果。

图3 人脸检测器的测试实例
1.2 面部表情几何特征提取
为了提取面部表情产生时眉毛、眼睛、鼻子、嘴唇等单个或多个面部器官的几何形变信息,本文首先构建训练人脸特征点定位模型,对人脸的68 个特征点(如图4 所示)进行定位,用归一化的特征点坐标值表征面部表情在空间域的几何特征,然后设计全连接神经网络,从多个表情图像帧的空间域几何特征中进一步提取面部表情的空时域几何特征。

图4 68个人脸特征点
构建的人脸特征点定位模型中,为了降低头部姿态的影响,先对眼角和嘴角4 个特征点进行定位,计算头部的倾斜角度,在此基础上旋转图像,纠正头部倾斜。然后,采用分治法和由粗到精的定位方式,先将特征点划分为人脸轮廓和五官2 个部分,进行初次定位。再在初次定位的基础上,将五官划分为左眉毛和眼睛、右眉毛和眼睛、鼻子、嘴唇共4 个部分,进行第二次定位。构建的人脸特征点模型由7 个级联的CNN 组成,使用300-W Challenge 数据集训练和测试网络模型。测试过程中,采用MNE 评估人脸特征点定位的误差,计算公式如下如示:
其中,N表示人脸特征点的数量,表示第i个特征点模型定位的坐标值表示第i个特征点标注的坐标值,dio表示两眼外眼角间的距离。测试样本的MNE均值为0.04709。
单个的面部表情图像帧输入人脸特征点定位模型,输出68 个特征点的坐标值,然后所有特征点坐标值减去鼻尖(图4 中黑色圆点)的坐标值,再将所有特征点的X 和Y 坐标值分别进行Z-score 标准化处理,用于表征面部表情图像帧在空间域的几何特征。面部表情所有图像帧的空间域几何特征输入设计的全连接神经网络,进一步提取面部表情在空时域的几何特征。设计的全连接神经网络由1 个输入层、3 个隐藏层和1 个输出层组成,3 个隐藏层中分别包含256、128 和64 个神经元,采用线性整流函数(ReLU)作为神经元的激活函数。
1.3 面部表情表观特征提取
针对面部表情图像帧在空间域的表观特征提取问题,通过构建CNN 实现特征的自动提取。由于真实的在线学习情境中,认知情绪面部表情的面部变化比较细微,特征提取难度大,因此采用增加网络深度的方式,提升网络的非线性表达能力,进而提升网络学习特征的能力。同时,在网络中采用小型卷积核,从而有助于网络学习认知情绪面部表情的细微特征,也有助于降低网络的参数量。CNN 的网络结构设计参考VGG-16[31],将整个CNN 分为5段,每段内有2~3个卷积层,每段段尾连接一个池化层用于数据降维。卷积层统一采用3×3大小的卷积核,池化层统一采用2×2大小的最大池化。通过一系列的卷积和池化操作,CNN最终输出面部表情图像帧在空间域的表观特征。
为了进一步提取面部表情在时间域的表观特征,设计构建长短时记忆网络(LSTM),以面部表情所有图像帧的空间域表观特征作为LSTM 的输入,在图像帧的空间域表观特征的基础上,继续学习面部表情在时间域的表观特征,输出面部表情在空时域的表观特征,整个流程如图5 所示。设计构建的LSTM 由3 层组成,每层分别包含512、256、128 个LSTM 单元。为了提取面部表情在时间域的变化特征,将LSTM 前2层设置为输出时序数据,最后一个LSTM 层则设置为输出静态数据,输出结果用于表征面部表情的空时域表观特征。
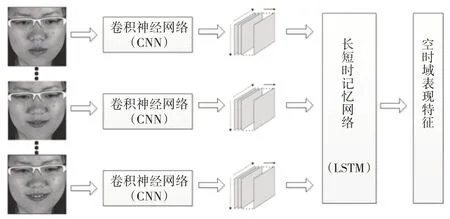
图5 面部表情的空时域表观特征提取
1.4 网络训练优化
在分类网络模型训练过程中,训练数据的类别分布不均会致使网络偏重对数量多的样本特征的学习,而对数量少的样本特征学习不充分,从而导致意外错误,甚至造成严重后果。因此,在网络模型的训练过程中,本文为不同类别的样本设置不同的权重,确保网络模型对不同类别的面部表情样本进行同等程度的特征学习。样本类别的权重按如下公式进行计算:
其中,Wi表示第i个类别的权重,Nall是所有样本的数量,NCi是第i个类别中样本的数量。在网络模型训练阶段,将样本类别的权重传递给损失函数。模型训练过程中在计算模型的损失时,损失函数根据类别权重计算不同类别样本的损失。
在视觉分类任务中,通常采用交叉熵作为损失函数,使用Softmax 函数作为分类器[32]。通过交叉熵衡量网络输出的概率分布(Softmax 输出值)和期望的概率分布(样本标签)之间的误差。网络训练的目标就是调节网络参数,使得输出值和期望值之间误差最小,即网络的损失(loss)最小。假定网络当前输出的概率分布为(v1,v2,v3,v4),而期望的输出概率分布为(1,0,0,0),依据交叉熵的公式:
当前网络的loss可以表示为:
其中,V=v1+v2+v3+v4。通过训练不断降低网络的loss,使得网络的输出(v1,v2,v3,v4)趋近于或等于(1,0,0,0),其实质是训练网络模型拟合样本数据的one-hot分布。利用交叉熵作为损失函数训练网络容易实现,付出的代价也小。在网络训练过程中,如果v1已经是(v1,v2,v3,v4)中的最大值,只需增大训练参数,从而增大向量(v1,v2,v3,v4)的模长,就可以使得ev1V接近1(loss 接近0)。但采用的Softmax 分类器即使输入噪音,分类的结果也是非1即0,使用交叉熵作为损失函数易导致网络模型训练的过拟合,也会使得在实际应用中难以确定置信区间、设置阈值。因此,本文为交叉熵损失函数添加约束项,使得网络模型训练时以拟合one-hot 分布为主,同时也按设定的权重拟合均匀分布。改进后的损失函数如下:
其中,ε是属于区间(0,0.5)的可调节系数,n是分类的类别数。相应地,上述实例的loss为:
在网络模型训练时,单纯地增大向量(v1,v2,v3,v4)的模长,使得ev1V接近于1,已经不是最优解。改进交叉熵损失函数,有助于降低网络模型训练过程中的过拟合风险。
1.5 方法有效性测试
为了测试方法的有效性,本文先利用CASME Ⅱ微表情数据库[19]进行微表情识别测试,并与其它方法进行比较。选择难度更大的微表情识别任务能更好地测试方法的有效性,并且在测试中训练的微表情识别网络模型可以作为预训练模型,应用于后续的认知情绪面部表情识别网络模型的训练中,可以加快模型收敛的速度,同时也能在训练样本数据有限的情况下,提升模型的识别性能。
CASME Ⅱ由中国科学院心理研究所创建,包括高兴、厌恶、惊讶、忧郁、其它5种类别的微表情,并且已经标注微表情的类别、微表情的起始帧、峰值帧和结束帧等相关信息。采用数据增强和随机取样的方法,将所有的微表情样本分成训练集、验证集和测试集。训练集用于训练网络模型,验证集用于训练阶段的测试,测试集则用于训练结束后对网络模型进行测试。
本文使用以TensorFlow 为后端的Keras 搭建网络,并训练网络模型。网络参数进行随机初始化,通过BP算法传递网络误差,采用Adam方法优化网络参数,初始学习率lr 设置为0.00008。为防止模型训练过程中出过拟合现象,采用了Dropout 机制(参数为0.3)。其它训练设置为:batch_size=20,epoch=1000。测试结果显示在测试集上平均识别准确率为83.90%,与其它方法在CASME Ⅱ上的识别准确率的对比结果如表1 所示。对比结果显示,本文提出的方法能有效提升微表情识别的准确率。
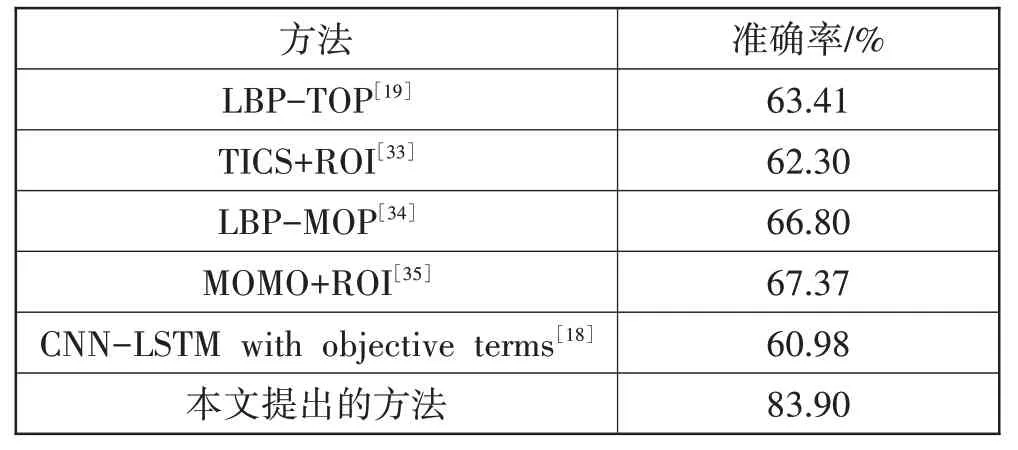
表1 与其它方法在CASME Ⅱ上的识别准确率比较
2 认知情绪面部表情识别实验与分析
2.1 数据集创建与数据预处理
设计认知情绪诱发实验,设置数学测试和智力挑战游戏2 种实验任务,模拟真实的在线学习情境,通过打破认知平衡的方式诱发被试者的认知情绪,并利用摄像头全程记录被试者的面部影像。从大学生中共招募59 名被试者参与实验,对被试者的年龄、性别、专业等不做任何限定。实验开始前,主试随机决定被试者具体的实验任务(数学测试或智力挑战游戏),随机选择实验材料(数学测试随机抽取试卷,智力挑战游戏则随机决定从第几关开始),并对实验任务进行说明和操作演示。实验正式开始后,被试者独自一人在实验室内完成实验,实验时长为40 min。
实验结束后,首先对所有被试者的面部影像中出现的专注、愉悦、困惑、沮丧和厌倦5 类认知情绪面部表情进行标注,包括面部表情的起始帧位置、峰值帧位置、对应的认知情绪类别。然后,从面部影像文件中分离出所有的认知情绪面部表情样本,每个样本由面部表情起始帧到峰值帧之间的图像序列组成,如图6 所示。最终,创建了包含5 个类别,共计772 个样本的认知情绪面部表情库,并且后续会公开该面部表情库,供相关人员开展科学研究使用。从理论上讲,样本数据越多,训练的网络模型的泛化能力越强。因此通过图像翻转、旋转和缩放等数据增强方法对样本进行扩充,得到5 个类别的认知情绪面部表情样本共计3119 个。采用随机取样的方法,将所有的样本分成3个部分:训练集、验证集和测试集。

图6 认知情绪面部表情库中的样本实例
2.2 基于迁移学习的模型训练
通过迁移学习,将已经训练好的微表情识别网络模型通过微调(Fine-tune)的方式迁移到认知情绪面部表情识别模型的训练中。根据源域和目标域中数据的相似度、目标域中训练数据量,微调在深度神经网络模型训练中又存在不同的具体实现方式。由于微表情识别和认知情绪面部表情识别具有较大相似性,面部肌肉运动幅度都相对较小,并且本文构建的认知情绪面部表情库的数据量大于CASME Ⅱ微表情数据库的数据量,所以将微表情识别模型作为预训练模型,保持其网络结构和权值参数不变,利用创建的认知情绪面部表情库继续训练网络,进一步优化网络的权值参数,使得训练的网络模型能够实现认知情绪面部表情双模态空时域特征的自动学习和分类识别。
网络的搭建和训练同样采用以TensorFlow 为后端的Keras。为避免网络训练过程中出现过拟合,采用了Dropout机制(参数为0.3)。采用Adam 方法优化网络的权值参数,初始学习率lr 设置为0.00004,其它参数设置为batch_size=9,epoch=1000。图7 和图8分别呈现了网络训练过程中的损失曲线和正确率曲线。从图中可以发现,由于采用了微调的方式训练网络模型,利用预训练的微表情识别模型对网络权值参数进行初始化,使得网络在刚开始训练时已经具有一定的特征学习能力,只是在原来的基础上进一步优化权值参数,所以在训练前期网络损失快速下降,准确率快速提升。随着迭代次数的继续增加,网络的损失降低和准确度上升的速度逐渐放缓,然后趋于平稳,表明网络收敛较好。
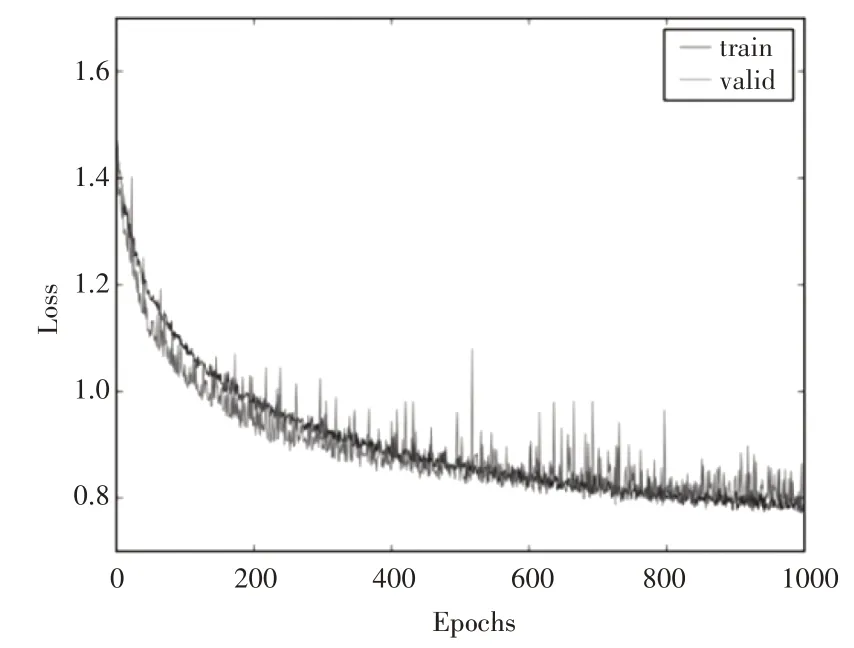
图7 误差曲线
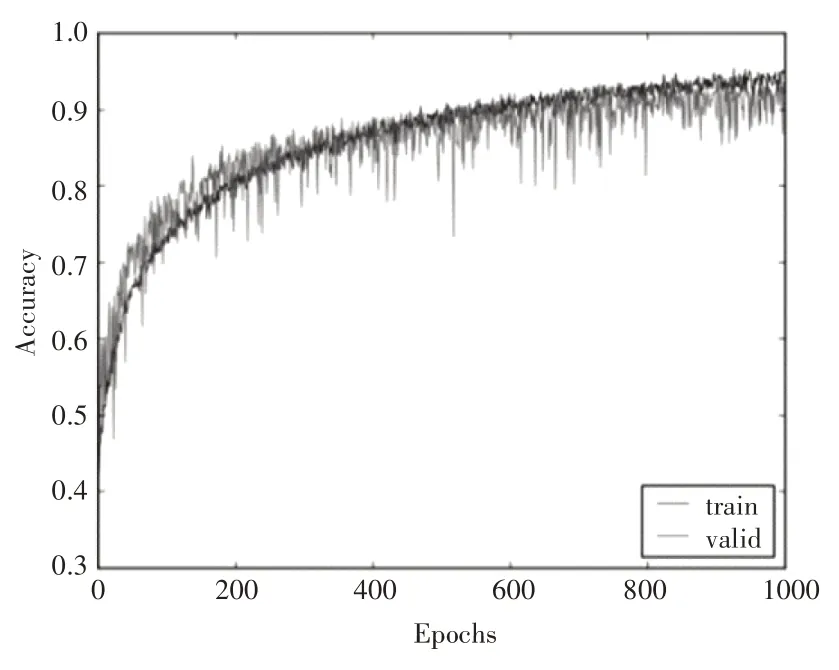
图8 准确率曲线
2.3 模型测试与结果分析
网络训练完成后,利用测试集对得到的认知情绪面部表情识别模型进行测试,并采用多个指标评价模型的性能。测试集共包含468 个样本,其中“厌倦”样本85 个、“专注”样本85 个、“困惑”样本120 个、“沮丧”样本95个、“愉悦”样本83个。先采用分类算法评价指标中常用的准确率(Accuracy,ACC)对模型进行初步评价,计算公式如下:
式中的TP、TN、FP 和FN 分别代表真正例、真负例、假正例和假负例。但是仅仅使用ACC 并不能全面、准确地评价网络模型的性能,特别是在测试样本类别分布不均时,所以进一步采用混淆矩阵和多类别ROC(Receiver Operating Characteristic)曲线评价网络模型。混淆矩阵的行是测试样本的真实类别分布,混淆矩阵的列是网络模型输出的测试样本的类别分布,分类正确的测试样本都位于混淆矩阵的对角线上。ROC 曲线是以FPR(FP/(TN+FP))为横轴、TPR(TP/(TP+FN))为纵轴的一条曲线。通过ROC 曲线与横轴围成的面积(Area Under Curve,AUC)评价网络模型的性能。AUC值的范围为0.5~1,大于0.9表示性能极好,0.8~0.9 表示性能较好,0.7~0.8 表示性能一般,0.6~0.7表示性能较差,0.5~0.6表示性能极差。
网络模型对认知情绪面部表情测试集中468 个样本分类识别的平均准确率为92.94%。图9 所示的多类别ROC 曲线显示,厌倦(class 0)、专注(class 1)、困惑(class 2)、沮丧(class 3)、愉悦(class 4)的ROC 曲线的AUC 值分别为0.95、0.95、0.96、0.90、0.96,表明网络模型对5 个类别的样本的分类识别都达到了“极好”的级别。从图10 的混淆矩阵可以发现,427 个样本分类正确,41 个样本分类错误。其中,83个愉悦(happy)样本中只有1个被误判,120个困惑(confusion)样本中有4 个被误判,85 个专注(concentrated)样本中有6 个被误判,85 个厌倦(boredom)样本中有14 个被误判,95 个沮丧(depressed)样本中有16个被误判。厌倦和沮丧2个类别的误判样本中,沮丧的误判样本分布比较均匀,而厌倦的误判样本主要是被误判为沮丧。相对于沮丧,厌倦的识别难度更大。后续需要研究如何进一步提升网络模型对这2类认知情绪面部表情进行分类识别的准确性。
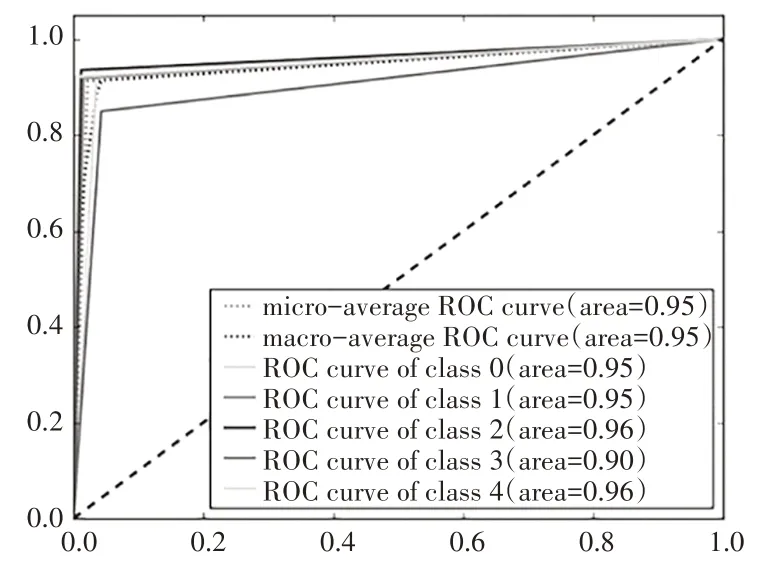
图9 多类别ROC曲线
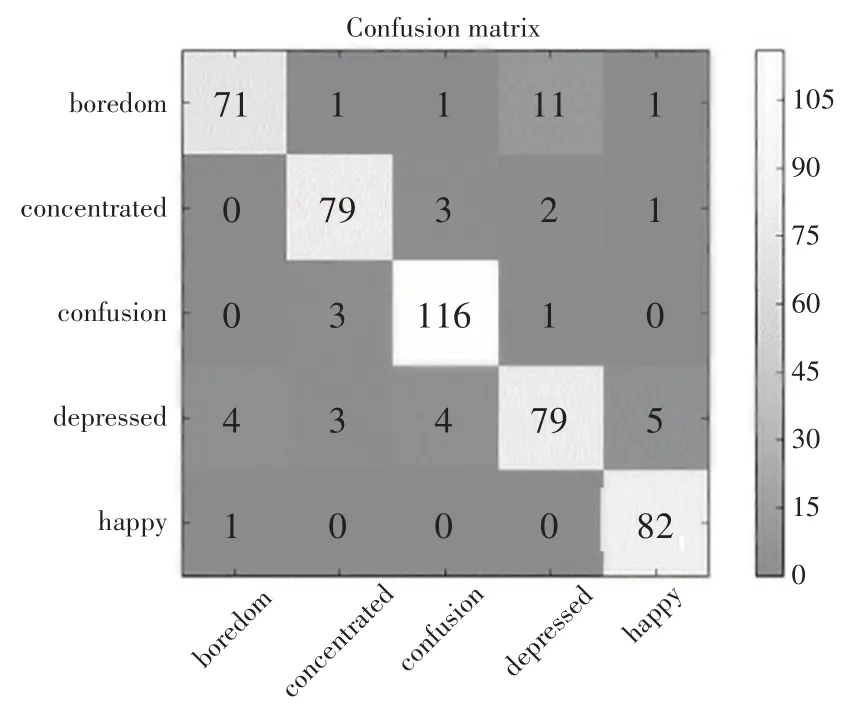
图10 混淆矩阵
总体而言,测试结果显示网络模型对5 个类别的认知情绪面部表情都具有较好的分类识别性能,表明本文提出的方法可以有效地识别认知情绪面部表情,从而通过面部表情识别获取学习者内隐的认知情绪。
3 结束语
人工智能时代的教育呼唤教学环境更具感知性、交互性和情境性。利用人工智能技术实现在线学习系统的情感智能,是构建智能化在线学习环境的重要组成部分。在线学习环境下认知情绪自动识别是实现个性化、精准化教学及评价的必然选择,也是实现在线学习系统的情感智能的起点。赋予在线学习环境下的计算机识别认知情绪面部表情的能力,通过对学习者外显的面部表情的识别,实现对学习者内隐的、动态变化的认知情绪的监测识别,具有侵入性低、实用性强的优点。针对认知情绪面部表情存在的特征不明显、持续时间短的问题,本文提出了通过设计混合深度神经网络,实现面部表情在空间域和时间域2 种模态特征的自动提取,融合2 种模态特征识别面部表情的方法,并开展了综合性实验。实验结果表明本文提出的方法能有效提升面部表情识别的准确率,训练的认知情绪面部表情识别网络模型具有较好的分类识别性能。
本文的研究是促进人工智能与在线学习深度融合的一次尝试。认知情绪面部表情自动识别应用的落地还存在一些有待解决的问题,比如有学者、家长和学生担忧人脸识别、面部表情识别等技术在教学中的应用是否会侵犯学生的隐私。虽然,任何技术都具有价值负荷功能,具有善恶兼具的两面性[36],可以先发展后规范,但还是需要通过法律、法规为认知情绪面部表情识别技术的应用注入更多安全基因,凸显技术的善,避免技术的恶。同时,也需要通过对认知情绪面部表情识别技术的继续完善,使技术的应用朝着安全、可靠、可控的方向发展。
