基于优化YOLO算法的多约束条件下视觉伺服系统目标的精准定位*
2023-11-13李石朋
李石朋,方 赟
(1.中国国际海运集装箱(集团)股份有限公司,广东深圳 518067;2.浙江大学机械工程学院,杭州 310058)
0 引言
近年来,在机器人视觉控制领域中被研究最多的是视觉伺服技术。视觉伺服技术是一种利用图像信息的实时闭环反馈完成机器人姿态动态调整的技术。该技术在完成系统的硬件部署后,首要任务就是获取机器人视觉系统的操作对象,因此对具有目标特征的图像有效识别是视觉伺服系统面临的第一个关键问题。对视觉伺服的理解,可以形象地比喻为人类基于眼睛视野信息进行电脑鼠标寻找的过程,当视野中出现具有类似鼠标外在基本特征的物体时,即使目标被部分遮挡,大脑也可以根据经验判断出此物体是否为所要搜寻的目标,并完成对该目标的定位。在此过程中即使面对光照、遮挡等因素,人脑也能够克服约束影响,所依赖的正是目标在大脑计算单元中所形成的印象深刻的特征形象。
与人类大脑的搜索和计算相比,机器人视觉处理系统并没有此能力,但过程类似:首先,对目标的搜寻主要是匹配处理系统已有的有限目标模型,较大姿态的改变会导致匹配失败,对于发生严重遮挡或非刚体目标形状变化造成的目标信息约束无能为力,这也是机器人视觉控制系统严重依赖标准工作环境,系统鲁棒性差的原因。在本文所关注的复杂工业生产环境中存在大量的非结构性因素,如目标特征的非标准化,其他机械设备运行产生的各种噪声,相机视野范围出现的遮挡,环境光线强度的变化等因素均会造成视觉目标识别失败。因此,需要研究一种能够适应各种非结构化环境信息影响的图像识别和目标匹配算法,以完成系统任务的关键一步。
1 相关工作
基于YOLO 的深度学习算法的主要目的在于提高目标图像检测速度,在个别的工作中已实现了对整幅图像和视频的实时检测[1]。在检测算法实施的过程中,最关键的是如何提高网络的运行效率,使得模型在计算能力较低的嵌入式设备上也能够高效运行。从已有的研究成果来看[2],考虑到通过提升现有上位机计算能力的方法提升网络运行效率的效果有限,一般通过采用降低模型复杂度的手段,以牺牲目标模型完整度和精度的代价换取计算速度的提升,这种以删减网络结构,调整分辨率为主要手段的方法显然不能从根本上解决问题。
ROI-Pooling是Pooling算法的一种,在传统的卷积神经网络中主要有以下作用[3]:首先是特征不变性,该算法更关注模型是否存在某种特征而非特征的具体位置,同时对目标图像位置具有较强的旋转和平移不变性,这是对机器人视觉伺服任务非常重要的一个性质;其次该算法还可以通过特征降维的方式使模型抽取更广范围的特征,减少各层输入大小,减少特征计算量和计算个数,这也完美符合视觉伺服研究以简单特征为目标降低系统计算负载而提高实时性的任务诉求;另外还可以在一定程度上防止过拟合,更方便优化。
基于上述ROI-Pooling 的特点,本文着重研究在目标图像完全信息受到干扰或缺失的情况下,提高图像检测成功率以及对目标缺失信息进行预测的目标检测算法。
YOLO 算法将目标物体的检测转换为一种回归问题[4],通过对边界框和对应类的概率进行空间分离,其边框和对应类的检测只需在单一的神经网络评估中就可以完成,该网络通过将图像分割成更细粒度的区域网格,实现任意区域边框的检测并计算出检测概率,最后通过检测概率来确定这些检测边框的权重。这种检测通道为单一卷积神经网络的方式,也为其检测性能上完成端到端的优化提供了可能,这个特点也是其优于基于区域生成方法的地方,大量研究结果证实了其具有快速且精确的检测效果(如实时图像检测传输帧率最高可达50帧),但该检测方法也存在定位错误的缺点[5]。
YOLO 目前已经发展出了多个版本,相对于初代版本,最新的版本主要是针对以下几个方面的改进[6]:首先是不同尺度的目标检测,以13× 13、26 × 26 和52 ×52 作为3 个尺度预测选取值;其次是对网络结构方面的优化,使用了Res-Net 的设计方法,通过加入残差块的方法来降低梯度消失的概率,不同的特征图尺度负责检测不同尺寸的物体,如大尺度特征图来完成最小目标的检出[7-8]。这种引入残差块的方法一方面降低了卷积的参数冗余,另一方面使梯度爆炸和梯度消失的情况也有所减少,从结构上优化了该网络主体。
YOLO-V3网络总体架构以Darknet-53为主干进行设计,具有置信度高、定位准确的特点,图1 所示为其典型的网络结构。基于以上YOLO 网络结构的研究基础,结合本文研究目标,对本文采用的复杂环境检测算法进行介绍。

图1 YOLOv3总体采样网络结构示意
2 基于YOLO的目标检测框架
本文主要结合视觉伺服系统在复杂环境中目标检测的特点,利用基于YOLO 的目标检测和特征提取一体化网络结构,提出一种将上一帧目标位置与卡尔曼滤波得到的目标在当前帧的预测位置做关键点匹配,从而判断预测位置是否存在目标的方法。该方法能够有效提高图像目标特征的检测效率,目的在于克服现有技术在检测速度和成功率上的不足,设计适合本文总体目标的检测框架,其主要步骤可描述如下。
步骤1:通过图像传感器获取视频流;
步骤2:使用目标检测网络检测输入视频,在这一步骤中如果检测到目标则使用目标的检测位置信息初始化卡尔曼滤波器,用目标在图像中的外接矩形框表示目标的位置信息;如果未能检测到目标,则持续使用YOLO网络检测输入视频;
步骤3:通过本文YOLO 检测网络获取当前图像帧,如果检测到目标则计算当前帧图像目标的检测位置与预测位置的交并比,如果交并比大于预设阈值,则用目标的检测位置作为目标在当前帧的位置,否则将目标在上一帧的位置与目标在当前帧的预测位置做关键点匹配,如果匹配对大于预设阈值,得到目标在当前帧的位置,否则重复执行步骤2;
步骤4:检查视频是否检测结束,若是则结束跟踪,否则执行步骤3。在这一步的执行过程中需要首先设置交并比阈值,计算当前图像目标的检测位置与预测位置的交并比,该比值的计算方法如下:
式中:IIoU为检测位置与预测位置的交并比;Sdetection为目标检测位置的外接矩形框的面积;Sprediction为目标预测位置的外接矩形框的面积。
当IIoU小于检测算法中的预设阈值时,系统选择目标检测位置的值[9],否则需要重新检测输入图像流,即执行步骤2相关流程。更直观的流程可见图2。
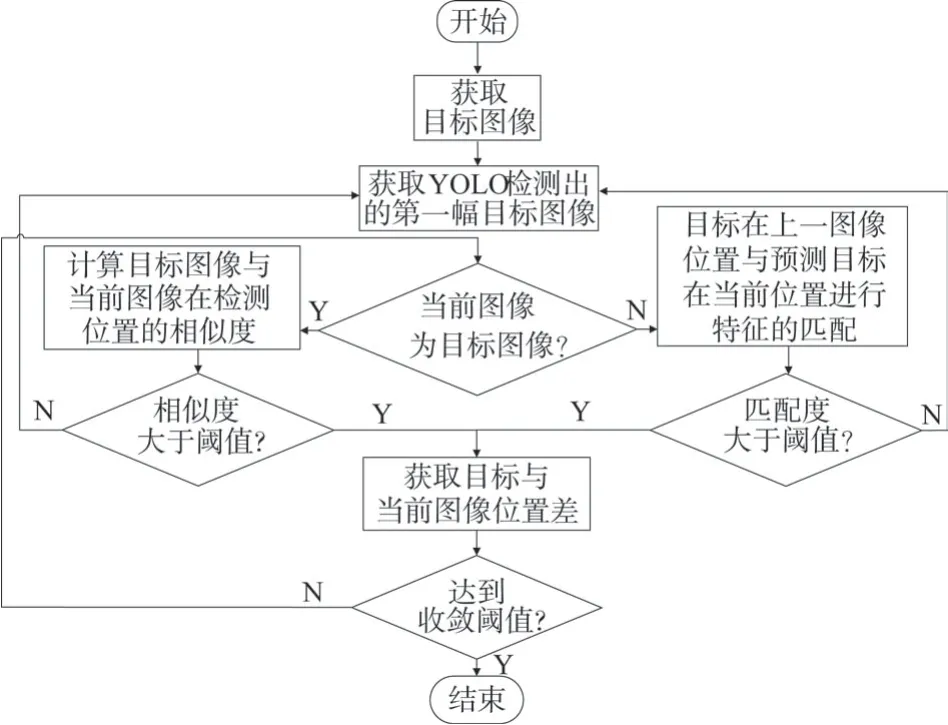
图2 目标图像特征位置预测流程
需要指出的是,在实现进行上述图像预测关键点匹配过程中,如SHIF 关键点检测、RANSAC 的计算、放射矩阵的变换、卡尔曼滤波器的更新等步骤较为复杂,本文通过以下伪代码进行主要算法实现流程的说明,作为上文如步骤3的补充。
其主要算法实现如下:
Input:image setI={I1,I2,…,Im,…,IM} ,image attributeIm=(Cm,Tm,max).
Threshold detection setT={T1,T2,…Tn,…TN,}
YOLO target detection network intercepts the current frame imageI1
Obtain intersection ratio of detection position and the predicted position of the target in the current frame.
Match key points according to the thresholdTn.Output:Φ
Begin
Computing SIFT Key Points of Prediction Position
P={P1,P2,…Pn} ;
Extract feature vectorsVpcorresponding to each key point Calculated euclidean distancedeof feature vector;Get thedminanddsecmindistance;
for
judge whetherdmin <0.6·dsec min;If true,consider the SIFT point matching,Complete the matching task of all key points;
Determine whether the key point matching pairs are greater than 10;
Calculation of affine transformation matrix
by RANSAC algorithm;
for
Randomly selecting 4 pairs of key matching points;Gets four verticesV1,V2,V3,V4of the target bounding rectangle and calculates the widthwand height ℎ of the rectangleR;
Prediction of rectangular center coordinatesCo;
end for
Update Kalman Filter through Current Position;
end for
Get the final matching result Φ;
Return Φ;
End Begin
在上述算法中,涉及仿射矩阵的参数表示意义如下:ℎ′0、ℎ′、1ℎ′0和ℎ′0为缩放旋转因子,Δx和Δy分别为目标在上一帧的检测位置相对目标在当前帧的预测位置在X方向和Y方向上的偏移量,[x′,y′,1]T和[x,y,1]T分别为任一对SIFT 关键点在目标在上一帧的检测位置与目标在当前帧的预测位置的齐次坐标。
根据上一节和绪论中的研究可知,无论从推断过程或是训练的角度考虑,回归的方法都要优于候选框的方法。基于回归的检测方法虽能够满足视觉伺服对系统实时性的要求,但在视觉伺服研究中精度方面的检出效果却无法与基于候选框的方法相比,研究认为这种差距的存在归结于卷积层在完成位置回归和类别预测时造成的高分辨率丢失[10]。鉴于此,本文在YOLO 回归概念的基础上结合ROI目标检测算法,通过将跨层的ROI结构池在回归的过程中实现,利用高分辨率的方法对系统的检测效果进行优化,这也有助于视觉伺服鲁棒动态特性的提升。
图3 所示为以木块的特征检测为例的YOLO 模型网络结构。图3(a)表示通过YOLO 框架完成目标图像在C×C个网格中的输入,若目标物体或其他物体的中心位置出现在某个网格(图3(b)),那么就由该网格完成该目标的检出工作(图3(c)),最终检测结果如图3(d)。滑动窗口由T(x,y,w,ℎ,Cconfidence)等信息组表示,其中,预测目标的置信度中心坐标为(x,y),此外宽度、高度、置信度依次由w、ℎ、Cconfidence表示,这些数值可以客观地说明检测对象与滑动窗口的相对位置,同时做出准确性预测,计算方法为:
式中:P( object )为检测对象出现在T(x,y,w,ℎ,Cconfidence)中的概率,图3 中表示的真实目标检测区域与滑动窗口的重叠面积通过表示。若检测目标存在于单元格中,则P( object )为1,此时置信度Cconfidence为,否则P( object )为0,置信度为0。这里候选框中某一类别的置信度可以通过下式计算。
式中:P(classi)为某目标图像在候选框中的概率,通过与的乘积来计算目标物体匹配度。在YOLO 中引入锚机制、归一化处理、维度聚类、高分辨率分类器、直接位置预测等技巧措施来提高检测精度[11],也可结合词向量树法扩大YOLO检测目标的种类[12]。
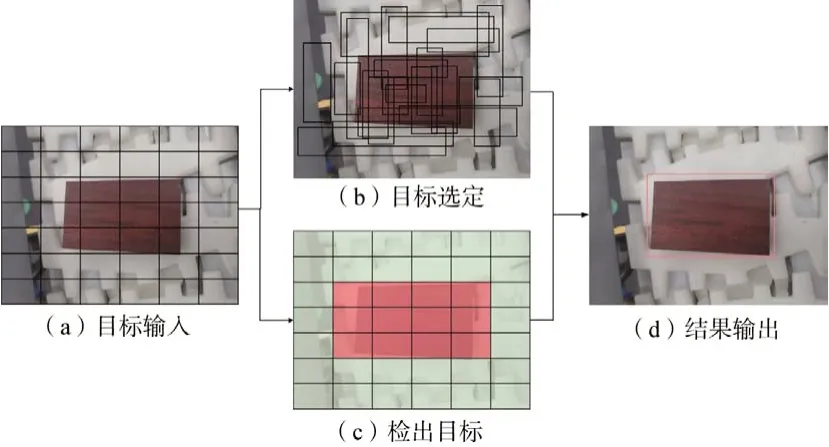
图3 本文优化算法检测模型
3 优化融合路径
为改善YOLO 的目标检测精度,本文在图像检测过程中采取融合ROI的处理技术。
如图4所示,经过卷积运算,特征图像1中的ROI大于输入图像中的ROI,这是因为卷积操作会导致输入图像中的单个像素影响输出图像中的9 个像素(3像素× 3像素)的值。在图4中,特征图像2的ROI大于前一层的ROI。随着卷积操作持续到网络末端,ROI会变得越来越大,最终会和输入图像一样。这意味着输入图像中的所有数据都将被视为感兴趣的区域,将导致减少了最终ROI 的计算。因此,在进行卷积运算后,有必要推导出合适的ROI选择方法。

图4 未抽样ROI变化情况示意
图5 所示为在卷积层中确定的ROI 示例。每个方框对应一个像素N、I 代表RONI(Region of Non Interest)数据和ROI 数据,内核大小为3× 3。当内核窗口中的ROI 数据数为大于预定阈值,则输出是ROI。在图5(a)中,输入图像右下角的粗方块指示当前卷积的滑动窗口操作,该卷积运算的输出被视为ROI 数据,卷积后的输出取决于输入窗口中的ROI数据量,图中3个数据在ROI中,其余6 个在RONI 中的预定义的阈值用于确定输出层。当数据值为0、1 或2 时,将其输出为ROI 区域,超过2的区域作为RONI区域输出;在图5(b)中,当阈值为0 时,表示当内核窗口至少包含一个ROI 数据,输出为投资回报率。图5(b)显示了该条件何时为TH0,与ROI 边界相邻的数据变为ROI 数据,因此卷积层输出的ROI 大小为大于输入的ROI;图5(c)显示了条件是TH3时,阈值为3,则ROI不会增加。一旦输出了ROI区域,避免了在RONI 区域生成数据的操作,在成功检出目标的同时可以减少计算量,不会对系统计算负载造成影响。每一层只处理ROI 数据生成的操作,并将结果传递给下一层。
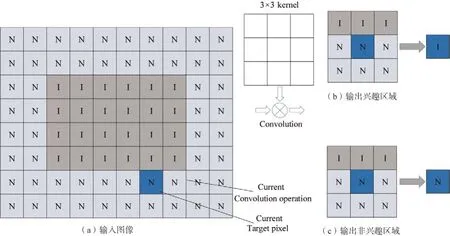
图5 ROI的示意
一些说明:根据视觉伺服系统的特点,在比较了常用的卷积模型后可以发现,VGG 网络在众多的研究中都有出色的ROI 提取效果,在Image-Net 图像分类工作的Top-5 的错误率稳定在7.1%,比Google-Net、Res-Net 等形式的卷积模型在特征提取中的精度虽无明显优势[13-14],但在多个网络中表现却更稳定[15],这对视觉伺服系统的鲁棒性优化很重要,也是本文选取VGG-16 模型作为编码器进行输入图像提取的原因。
有关本文检测模型的效果将在实验部分,视觉伺服系统在不同约束条件下目标图像识别情况的对比中给出。
4 实验验证及结果分析
本文主要结合优化YOLO 图像快速检测与ROI Pooling候选框算法高检测精度的特点,针对在工业环境下常见的约束条件下,研究目标特征图像高效的检测识别算法,并对部分信息缺失情况下目标的识别问题进行测试。
4.1 算法测试实验系统的建立
如图6 所示,实验平台包括一个七轴协作机器人Franka Panda、相机Realsense SR300 和Basler acA720-520uc(能够自由设置相机频率);上位机操作系统Ubantu 16.04 LTS,配备英特尔I350-T2 V2网卡(需有较高配置,保证数据处理的实时性),开源图像处理库OpenCV 4.1,TensorFlow 2.0,LabelImg,Caffe,标注工具Labelme等。

图6 视觉伺服算法测试实验平台
4.2 工业环境下本文图像处理架构有效性验证与分析
针对工业环境常见的约束条件,本文设计了复杂背景、强光照、阴暗空间、遮挡、形变等约束项,并在不同的姿态下对目标图像进行10 000次左右的训练,图7所示为部分位置训练结果。由图可知,在不同条件下,本文基于YOLO-ROI 的图像优化识别算法均能有效从非结构化环境中检测出目标图像,各约束条件下检测效率较高,尤其在视觉伺服系统中影响大的遮挡和反光情况下也有理想的识别效果。在识别目标后进行系列增强、锐化等步骤。

图7 不同条件下图像训练后识别情况
在实际工业环境中,目标图像的位置和姿态不可能完全匹配ROI 池的目标特征,对于非训练样本空间的目标图像的有效识别更有实际意义。如表1 所示,分别改变上述5 种约束条件,并在每种条件下进行10 000 次左右不同姿态的目标识别,并对非训练样本空间目标图像进行识别率测试,其识别效率如表1所示。
在表1 中,反光和阴影条件的不同可以分别通过改变相机帧率进行数据设置,背景改变通过增加和减少干扰项数量实现(不对目标进行遮挡),遮挡情况中ROI训练数据最大遮挡面积占总面积为50%,目标形变项以未发生形变目标图像为基准进行改变,在不易量化的情况下以实验人员经验为参考。由表可知,除复杂背景一项外,在稍微增加环境约束量的情况下,系统有较高的概率正确识别目标,只有在目标受遮挡的情况下识别效率较差;而当增加环境约束权重,目标识别率则出现严重下降,但仍然可以在一定程度上识别图像,显示了本文算法良好的预测能力和对环境的鲁棒性,可以有效提高视觉伺服系统环境适应性。

表1 非训练样本空间目标图像识别率
5 结束语
本文主要研究在视觉伺服过程中图像处理阶段如何克服系统鲁棒性因素带来的影响,包括有效实现工业环境约束条件下(如光照、阴影、遮挡等情况)对目标特征图像的识别和具有较强鲁棒性和精度的目标模型匹配算法。在分析工业环境中所面临的主要约束任务后,提出了以YOLO 算法为基础的复杂工业环境目标检测算法,利用端到端的规划思路,将物体检测转换为单一的回归问题。该方法避免了基于R-CNN 方法对每个模块都单独训练,通过多个步骤来完成对目标物体检测的必要过程,融合定位与分类任务后同时进行,在完成对图片的单次扫描后利用CNN 网络进行特征提取和定位,提高目标检测的实时性,降低大规模计算带来的影响,此外也能在一定程度上克服动态约束因素的干扰。
