结合文本与隐反馈信息的学术论文推荐方法
2023-11-10陈雨民李东喜闫一帆吕传建陈泽华
陈雨民,李东喜,闫一帆,吕传建,陈泽华
1(太原理工大学 大数据学院,太原 030024)
2(山东亿云信息技术有限公司,济南 250000)
1 引 言
互联网时代,学术论文的爆炸性增长使得研究者很难在海量的文章中迅速找到自己感兴趣的文章,为了缓解科研人员的信息迷航与信息过载问题,学术论文推荐技术受到广泛关注.协同过滤是推荐系统领域广泛采用的一种方法[1-6],然而,在学术论文推荐场景,基于协同过滤的推荐方法面临严重的数据稀疏问题,因此,许多学者引入辅助信息以提升学术论文推荐模型的性能[7-9].
辅助信息分为结构信息和文本信息两种类型.结构信息主要指论文的引用关系,Mohammadi等[10]基于参考文献构建论文引用关系图,通过随机游走算法生成论文推荐列表.王勤洁等[11]基于异构信息网络理论提出一种可以融合多种信息的学术论文推荐方法.结构信息能有效缓解数据稀疏问题,但存在一些不可靠因素.Hassan等[12]指出,新论文无法被旧论文引用,一些有价值的参考文献可能由于研究者的不了解而被遗漏,所以使用结构信息作为辅助信息的学术论文推荐方法存在一些局限性.文本信息主要指论文的标题和摘要,wang等[13]提出协同主题回归模型,通过隐含狄利克雷分布学习论文主题分布,结合概率矩阵分解生成论文推荐.李冉等[14]考虑到用户在选择论文时对研究热点的偏好问题,进一步提出一种基于频繁主题集偏好的协同主题回归模型.本文认为相比于结构信息,文本信息对于论文推荐起着更为关键的作用,研究者喜欢某篇论文归根结底是喜欢其内容而非其它.
然而,现有的结合文本信息的学术论文推荐方法,仅仅简单连接标题摘要得到段落文本,然后将其传入主题模型或简单神经网络获得论文向量表示,没有充分利用学术论文的结构化特点去捕捉标题摘要之间的语义关系.本文认为,学术论文是一种典型的结构化文本,其中,标题是对整篇文章内容的凝练,充分反映论文核心主旨,摘要含正文等量的主要信息,但不可避免的包含一些噪声信息.可以通过注意力机制捕捉标题摘要间的语义关系,获得更好的论文表示以提升推荐质量.以图1学术论文为例进行具体解释,首先可以看到,标题是该文章主旨的核心凝练,标题中的划线单词Reinforcement learning、Web recommendations则更能反映论文核心主旨,在构造论文向量表示时,应当给予标题更大权重,给予标题中的核心单词更大权重.其次,标题是整篇文章的核心凝练,将标题单词看作蕴含重要信息的单词,如果摘要句子中的某些单词与标题单词更相关,应该在构造摘要句子向量表示时给予这些单词更大权重,以便更好捕捉摘要句子语义信息.例如,摘要句子3中的划线单词architecture、recommendation、system与标题单词更相关,也对揭示文章主旨有更大帮助.最后,摘要中不同句子揭示文章主旨的能力各不相同,以句子3和句子5作比较,句子3极为重要,它阐述了论文的中心工作,应给予更大权重,而句子5是可以出现在很多论文中的一般性陈述,对于捕捉论文主旨几乎没有贡献,应给予较小权重.
基于以上分析,本文提出一种结合文本与隐反馈信息的学术论文推荐方法(RAP-WTIF,Recommending Academic Papers With Text and Implicit Feedback).通过预训练BERT模型获得标题摘要中单词的向量表示,提出标题摘要注意力机制捕捉标题摘要语义关系以获得更好的论文向量表示,最后结合改进的神经协同过滤模型实现学术论文推荐.本文主要贡献可以总结为以下3点:
1.利用学术论文结构化特点,提出标题摘要注意力机制捕捉标题摘要之间语义关系,获得更好的论文向量表示.
2.增加论文文本信息作为辅助信息改进原始的神经协同过滤模型,缓解原始神经协同过滤模型存在的局限性.
3.集成预训练BERT模型,标题摘要注意力机制,改进的神经协同过滤模型提出RAP-WTIF方法,并在CiteULike-a、CiteULike-t数据集上验证了该方法提升学术论文推荐质量的有效性.
2 相关工作
2.1 隐反馈信息
推荐系统领域的用户-物品交互行为分为显式反馈和隐式反馈两种,显式反馈指能明显表达用户喜好的行为,例如评分,隐式反馈指不能明显表达用户喜好的行为,例如浏览,点击,收藏.学术论文推荐领域显反馈信息不易获取,许多研究使用隐反馈信息进行推荐.本文以论文收藏为例展开介绍,但本文方法同样适用于处理其它类型的隐反馈信息.
常用的处理隐反馈信息的损失函数为:
(1)
其中,yij为1指用户ui收藏了论文pj,表示用户ui对论文pj感兴趣,yij为0指用户ui没有收藏论文pj,表示用户ui对论文pj不感兴趣或者用户ui根本没见过论文pj.γ表示正样本集,γ-表示负样本集.负例选取数目N(γ-)参照科研人员收藏数目进行选取,科研人员收藏数目越多,其看过的论文越多,其没有收藏的论文更多是看见但不喜欢:
N(γ-)=αN(γ)
(2)
α为负例选取比例.
2.2 结合评论文本的商品推荐方法
为了缓解商品推荐领域评分数据稀疏性的问题,近年来的研究热点是通过挖掘评论文本语义信息来对用户和商品建模,从而提高推荐质量[15].Jakob等[16]发现用户对商品的评论是宝贵的资源,认为评论文本中关于价格、服务、正负情感的叙述能够对推荐产生重要帮助.李琳[17]等将评论主题与矩阵分解隐因子融合,添加潜在主题分布作为预测评分引导项.Kim等[18]提出卷积矩阵分解(ConvMF,Convolution Matrix Factorization)模型,考虑文本的局部词序信息,利用卷积神经网络(CNN,Convolution Neural Network)从商品描述文本中提取重要信息辅助推荐.Zheng等[19]提出深度协作神经网络(DeepCoNN,Deep Cooperative Neural Network)模型同时考虑用户文本信息与商品文本信息,使用两个并行的CNN网络分别处理用户评论集和商品评论集辅助推荐.本文认为结合评论文本的商品推荐方法与结合文本信息的学术论文推荐方法有许多相似之处,本文RAP-WTIF方法借鉴了DeepCoNN模型的基本思想.
3 方 法
为了方便阐述,首先进行符号定义,假设给定数据集D,其中每条数据(ui,pj,t,s)表示用户ui收藏了论文pj,t=(t1,t2,…,tn)和s=(a1,a2,…,am)为论文pj的标题和摘要,n为标题中单词个数,m为摘要中句子个数,ay=(wy,1,wy,2,…,wy,r)表示摘要第y个句子由r个单词组成.
本文方法RAP-WTIF整体结构如图2所示,首先,使用预训练BERT模型[20]获取标题摘要中单词的向量表示.其次,通过本文提出的标题摘要注意力机制(TAAM,Title-Abstract Attentive Mechanism)捕捉标题摘要语义关系,获得论文向量表示.最后,结合改进的神经协同过滤(NCF,Neural Collaborative Filtering)[21]模型处理隐反馈信息实现推荐.

图2 整体结构Fig.2 Overall structure
3.1 预训练BERT模型
现有的结合文本信息的学术论文推荐方法在获取单词向量表示时仍采用传统的word2vec[22]或glove[23]预训练词向量模型,这些模型属于静态编码,不能很好的联系单词的上下文信息,以至于对语义的理解存在偏差.例如“I stole money from a bank vault”与“I′m fishing on the Mississippi river bank”,前一句中的bank意为银行,后一句中的bank意为岸边,而word2vec与glove模型对不同语句中的bank仅会给出相同的向量表示,没有很好的联系单词的上下文信息.谷歌公司提出双向Transformer结构的BERT模型[20],并在大规模语料库上对其进行了预训练,可以很好的解决这一问题,每个单词的向量表示会根据不同的上下文信息而动态变化.本文使用预训练BERT模型获取标题摘要中单词的向量表示:
(3)
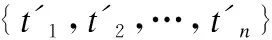
3.2 标题摘要注意力机制
标题摘要注意力机制利用学术论文结构化特点,捕捉标题摘要之间语义关系获得论文向量表示,结构如图3所示,主要分为标题注意力(Title attention),摘要注意力(Abstract Attention),句级注意力(Sentence Attention)3个模块.

图3 标题摘要注意力机制结构Fig.3 Structure of title-abstract attentive mechanism
3.2.1 标题注意力
标题注意力赋予标题中核心单词更大权重.首先,使用一层双向门控循环单元(GRU,Gated Recurrent Unit)神经网络对标题中单词的向量表示进行编码,以捕捉标题单词间的语义关系,此处GRU网络称作词级GRU(Word GRU)网络,
(4)
hi=[hfi;hbi]
(5)
接着,通过自注意力机制获取标题中每个单词的重要性权重αi,

(6)
其中,W1、W2、b1、b2为模型自主学习的参数.
最后,加权得到标题向量表示t′,
t′=αihi
(7)
3.2.2 摘要注意力
摘要注意力通过比较摘要句子中的单词与标题中单词的相关性,赋予摘要中重要单词更大权重,以便更好捕捉摘要句子语义信息.首先,计算摘要句子中每个单词与标题中单词的相关性分数sim(wy,x,t),
(8)
WK与WQ为模型自主学习的权重参数.
对相关性分数进行归一化,得到摘要句子中每个单词的重要性权重αx,
(9)
接着,同样使用一层双向GRU网络对摘要句子中单词的向量表示进行编码,以捕捉摘要句子中单词之间的语义关系,得到每个单词的隐藏状态hy,x,此处GRU网络与标题注意力中的词级GRU网络共享参数.
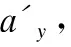
(10)
3.2.3 句级注意力
句级注意力赋予标题更大权重,赋予摘要中重要句子更大权重.首先,通过比较摘要中每个句子与标题的相关性,赋予摘要中重要句子更大权重.计算摘要中每个句子与标题的相关性分数sim(t,ay)以及每个句子的重要性权重βy,
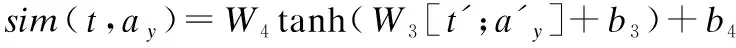
(11)
其中,W3、W4、b3、b4为模型自主学习的参数.
接着,可以将标题看作摘要的总结句,使用标题向量表示t′初始化一层双向GRU网络的全局记忆,将摘要句子向量表示依次输入该GRU网络,获得每个摘要句子的隐藏状态hy,这样,不仅可以捕捉摘要句子之间的语义关系,也可以通过标题来辅助摘要句子向量表示的构建,使其更倾向于文章的核心主旨.此处GRU网络称作句级GRU(Sentence GRU)网络,不与前面词级GRU网络共享参数.
然后,加权聚集每个摘要句子的隐藏状态,获得摘要向量表示s′,
(12)
最后,连接标题向量表示t′和摘要向量表示s′获得论文向量表示p′,
p′=W5[t′;s′]+b5
(13)
其中,W5,b5为模型自主学习的参数.
这里,将标题向量表示与摘要向量表示连接以及使用标题向量表示t′初始化GRU网络的全局记忆,都间接给予了标题在构造论文向量表示时的更大权重.
3.3 改进的神经协同过滤模型
现有的学术论文推荐方法在处理用户-论文交互信息时仍采用矩阵分解模型或其简单变体,不能很好的捕捉用户-论文交互信息.He等[21]提出神经协同过滤(NCF,Neural Collaborative Filtering)模型,将传统矩阵分解中的内积操作与神经网络结合,可以进一步捕获非线性特征和更多特征组合,极大提升了推荐效果.其结构如图4所示,核心为广义矩阵分解(GMF,Generalized Matrix Factorization)模块和多层感知机(MLP,Multi-Layer Perceptron)模块.然而,原始的NCF模型仅仅使用用户物品编号信息,存在一定的局限性,本文改进原始的NCF模型,增加论文文本信息作为辅助信息来进一步提升推荐效果.

图4 神经协同过滤模型结构Fig.4 Structure of neural collaborative filtering model
首先,去掉原始NCF模型的项目嵌入(Item Embeding)模块,将标题摘要注意力机制获得的论文向量表示p′分别赋值给广义矩阵分解模块的项目向量表示(GMF Item Vec)和多层感知机模块的项目向量表示(MLP Item Vec).因为本文主要目的是捕捉标题摘要语义关系获得更好的论文表示提升论文推荐质量,所以对于用户向量表示的两个模块(GMF User Vec和MLP User Vec),仍使用NCF模型原始的用户嵌入模块(User Embeding)进行随机初始化.
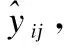

(14)
其中,pG和pM分别为论文GMF向量表示与MLP向量表示,qG和qM分别为用户GMF向量表示与MLP向量表示.
最后,使用公式(1)作为损失函数,采用Adam作为优化器学习模型.
4 实 验
4.1 实验数据
CiteULike网站为用户提供管理学术论文和发现学术论文的服务,用户可以在网站上收藏感兴趣的论文.本文实验数据CiteULike-a[13]和CiteULike-t[24]均来自CiteULike网站公开提供的真实数据,对两个数据集进行数据预处理后相关信息如表1所示.

表1 数据集相关信息Table 1 Information about dataset
4.2 对比实验
实验选取以下方法进行对比,方法实现均来自原论文提供的代码并在实际实验中调优,
—NCF[21]:仅使用NCF模型处理隐反馈信息进行推荐,未使用论文文本信息.
—DeepCoNN[19]:使用glove预训练词向量模型获得标题摘要中单词的向量表示,通过CNN网络提取论文文本特征.
—DeepCoNN++[25]:用GRU网络取代 DeepCoNN模型中的CNN网络来提取文本特征.
—RAP-WTIF-base:论文标题摘要简单连接得到段落文本,使用预训练BERT模型获得单词向量表示,通过GRU网络捕捉文本特征.
—RAP-WTIF-t:RAP-WTIF模型变体,仅包含标题注意力.
—RAP-WTIF-a:RAP-WTIF模型变体,包含标题注意力和摘要注意力.
4.3 实验方法
实验使用leave-one-out方法进行验证,对每个用户取出最后一个交互作为测试集,剩余交互作为训练集.由于对每个用户都进行所有论文的预测和排序十分耗时,本文采取一个简化做法,随机选取99篇不在用户收藏库中的论文,与测试论文一起排序,选取top10作为推荐列表,通过命中率(HR)和归一化折损累计增益(NDCG)评判推荐表现[21],
(15)
N表示用户总数量,hits(i)表示第i个用户的真实值是否在推荐列表中,是则为1,否则为0.HR值越大,模型推荐准确率越高.
(16)
N表示用户总数量,pi表示第i个用户真实值在推荐列表的位置,若推荐列表不存在该值,则pi→∞.NDCG值越大,模型推荐效果越好.
对每个用户随机选取一个交互进行超参数调节,用高斯分布初始化模型参数.综合考虑实验效果和时间耗费,本文选定NCF模块MLP层数layers=3,负例抽取比例α=5,学习率lr=0.0005.考虑论文向量表示的维度对模型效果有较大影响,实验中对论文向量表示的不同维度factors=[8,16,32,64]进行了分析.
4.4 实验结果与分析
根据上述实验设计,对实验结果进行统计,CiteULike-a数据集实验结果如表2所示,分析实验结果得出如下结论,

表2 CiteULike-a实验结果Table 2 Experimental results of CiteULike-a
1)RAP-WTIF方法在HR,NDCG评价指标下均优于其它方法,比经典方法DeepCoNN分别提高5.8,6.2个百分点,证明该方法提升学术论文推荐质量的有效性.
2)考虑论文文本信息的模型(DeepCoNN,DeepCoNN++,RAP-WTIF)相比仅考虑隐反馈信息的模型(NCF)效果显著提升,表明论文文本信息对于科研人员具有重要作用.
3)使用循环神经网络的模型(DeepCoNN++)比使用卷积神经网络的模型(DeepCoNN)效果更好,表明循环神经网络可以更好地捕捉文本语义信息.
4)将本文方法RAP-WTIF与其变体RAP-WTIF-base,RAP-WTIF-t,RAP-WTIF-a比较可以看出,标题摘要注意力机制的3个模块均对获取更好论文表示,提升推荐效果产生有益作用.
CiteULike-t数据集实验结果显示同样情况,限于篇幅问题省略了CiteULike-t数据集实验结果表.
图5、图6为论文向量表示维度发生变化的实验结果,可以看出,本文所提RAP-WTIF方法在不同论文向量表示维度下皆取得最优表现,进一步验证本文所提RAP-WTIF方法提升学术论文推荐质量的有效性.另外,随着维度升高,各方法效果皆有提升,表明提升维度可以更好的捕捉学术论文主旨信息,但考虑过大的维度也可能引起过拟合导致效果变差.CiteULike-t数据集上的实验也显示出相同趋势,同样限于篇幅问题省略了CiteULike-t数据集的实验结果图.

图5 不同factor维度下的HRFig.5 HR under different factor dimension

图6 不同factor维度下的NDCGFig.6 NDCG under different factor dimension
5 总 结
本文针对学术论文推荐领域存在的数据稀疏问题,提出一种结合文本与隐反馈信息的学术论文推荐方法.该方法充分利用了学术论文的结构化特点,首先,使用预训练BERT模型获得标题摘要中单词的向量表示.其次,提出标题摘要注意力机制捕捉标题摘要之间的语义关系获得更好论文表示.最后,结合改进的NCF模型处理用户-论文隐反馈信息实现推荐.在CiteULike-a与CiteULike-t数据集上进行实验,证明本方法可以明显提升学术论文推荐质量.在今后的研究中,我们将进一步考虑时序信息,并考虑构建多语种的学术论文推荐服务.
