一种局部信息增强与对话结构感知的多轮对话模型
2023-11-10陈泽林陈羽中
廖 彬,陈泽林,陈羽中
1(福州大学 网络安全与信息化办公室,福州 350108)
2(福州大学 计算机与大数据学院,福州 350108)
3(福建省网络计算与智能信息处理重点实验室,福州 350108)
1 引 言
对话技术能够在理解用户问题的前提下为用户返回合适的回复,直观的模拟人类的智能,其研究对于人工智能的发展具有重大的意义.目前的对话模型可分为生成式对话模型和检索式对话模型[1],其中,生成式对话模型在推理阶段不依赖任何语料库就能根据一个问题逐字生成一个答案,其生成的答案具有多样性的优点,但获取的答案往往逻辑性不强,有时还会陷入安全回复的陷阱中.而检索式对话模型是让算法根据特定的一个问题到语料库中找到一个最合适的答案进行回复,能够从问题中提取出与正确回复相关联的信息,依据这些信息推理出合适的答案.相较于生成式对话模型,检索式对话模型更加可靠且具有更好的实用性.
检索式对话模型分为单轮对话模型和多轮对话模型,早期的检索式对话模型受限于其对文本的理解能力,只能对单条的短文本进行处理,无法处理对话历史信息.在实践当中,用户可能会分多句话来表达其意图,单轮对话在实际场景下缺乏实用性.检索式多轮对话模型需要根据对话历史和问题从知识库中选择出合适的回复,对话历史中的冗余信息以及话题的转换使得选择合适的回复十分困难.因此,本文重点针对多轮对话回复选择任务开展研究.
由于对话是一种具有时序性的数据,因此早期的多轮对话模型主要使用能够建模时序依赖关系的循环神经网络或特征提取能力强的注意力机制来学习多轮对话中的上下文语义[2-10].近年来,由于预训练语言模型在学习语义信息上的巨大优势,研究人员引入了预训练语言模型进行上下文语义学习[11-16].一些研究工作[17-19]则进一步将多任务学习引入到多轮对话回复选择任务中,针对对话数据连贯性、一致性等特点设计了多个子任务.这些子任务与主任务一起共享预训练语言模型的参数,设计额外的损失函数来有针对性的优化预训练语言模型.预训练语言模型与多任务学习相结合的方法在多轮对话回复选择任务中展现了显著的效果.一方面进一步挖掘了预训练语言模型的潜力,减少了模型的参数数量;另一方面能够更高效地学习对话数据中的潜在特征,大幅提升了预训练语言模型对于对话数据的理解能力.但是,现有模型还存在以下问题:1)设计的多个子任务需要在训练的时候对预训练语言模型做多次微调,训练代价较高.同时,子任务的优化目标与主任务的优化目标有一定差异,例如插入,删除话语后预测其位置的子任务,可能会为主任务带来噪声;2)现有模型对关键语义信息的筛选不够充分;3)现有模型的预训练语言模型是在文本较长的百科类数据集上学习得到,应用于短文本多轮对话数据上可能出现语义理解错误.针对上述问题,本文提出了一种局部信息增强与对话结构感知的多轮对话模型SAFL,主要贡献如下:
1)针对现有模型的子任务不够高效的问题,SAFL提出了一个名为随机滑动窗口回复预测(RPRSW,Response Prediction in Random Sliding Windows)的辅助任务.该任务在多轮对话上下文中的不同位置、大小的窗口内进行回复预测,充分学习不同对话阶段、对话长度的语言特点,显著增强了预训练语言模型对不同位置的对话数据的理解能力.
2)针对现有模型对重点信息的筛选不够充分的问题,SAFL提出了一种重点局部信息蒸馏(Key Local Information Distillation,KLID)机制.该机制借助多门控融合方法从全局和局部信息之中蒸馏出重点信息,进一步提升了模型融合层的效果.
3)SAFL提出了一种阶段信息学习(Phase Information Learning,PIL)策略,在微调前加强预训练语言模型对短对话数据的领域学习,增强模型对短文本多轮对话数据的学习能力.
4)SAFL提出了对话结构感知(DSA,Dialogue Structure-aware Task)辅助任务.该任务根据对话人说话的先后顺序构造图结构,并使用GCN进行编码,促使预训练语言模型学习正确的对话结构信息,进一步加强了模型对多轮对话数据的语义理解能力.
2 相关工作
早期的检索式对话模型主要针对单轮对话,传统的算法采用统计机器学习的方法,将LDA(Latent Dirichlet Allocation),LSA(Latent Semantic Analysis)等主题分析算法与余弦相似度等短文本匹配算法相结合来解决单轮对话任务.Lowe等人[20]在2015年提出使用RNN(Recurrent Neural Networks)来处理时序依赖,模型拼接对话上下文拼接后输入RNN编码时序信息.但是该方法直接使用RNN编码整段上下文,难以过滤掉上下文中不相关的语义信息.
Zhou等人[3]提出了一个双视图的检索式对话模型,能够从两种粒度更加精确的提取上下文信息.第1个视图在词粒度上使用门控循环单元GRU(Gated Recurrent Unit)[19]编码整个上下文和回复,第2个视图生成每个句子的表示,在句粒度上使用GRU进行编码,最终使用两个视图得到的表示分别进行匹配.但是,该模型分别从上下文和回复中提取特征,难以根据回复有针对性的提取相关信息.Wu等人[4]对不同的话语和回复分别进行编码,并且基于词嵌入和GRU构建两种粒度的语义表示.在匹配阶段,该模型对每一个话语和回复在两种粒度表示上分别进行语义匹配.Zhang等人[5]将多轮对话中的最后一个话语视为对话问题,同时将其与回复拼接起来,作为一个整体与上下文进行匹配,并在RNN编码后进一步使用自注意力机制提取对话中的语义信息.
2017年,Vaswani等人[22]提出了Transformer模型.Transformer模型具有强大的语义理解能力,模型通过在词粒度上使用多头自注意力机制来将所有的单词联系在一起,能够保证远距离依赖信息的提取.由于Transformer架构的优势,衍生出了一系列将Transformer应用于多轮对话回复选择任务的研究工作.Zhou等人[6]提出了一种混合注意力机制模型DAM(Deep Attention Matching Network),对每一个话语和回复都使用基于Transformer编码器改进的注意力模块来编码,并借助多层注意力机制获得多粒度的信息,能够更好地提取语义信息.Tao等人[7]在DAM的基础上,重点研究了在不同时期进行多粒度信息融合对模型的影响.Yuan等人[10]提出MSN(Multi-hop Selector Network)模型,该模型结合DUA(Deep Utterance Aggregation)模型[5]和DAM模型各自的优势,设计了一个多跳选择器来过滤与问题不相关的上下文.上述模型借助Transformer强大的语义理解能力,大幅提升了回复选择模型的性能,但对每个话语和回复分别编码的方法难以从全局角度理解对话信息,同时这些工作主要使用Word2vec[23]等静态词向量,难以解决一词多义的问题.
近几年,许多研究工作将BERT[24],RoBERTa[25],ELECTRA[26]等预训练语言模型应用于多轮对话回复选择任务.预训练语言模型的语义表示能力能够让模型在训练过程中学习到更加合理的对话语义特征.Whang等人[11]提出了BERT-VFT模型,率先将BERT运用于回复选择任务中.Gu等人[12]提出了SA-BERT模型,在预训练语言模型的输入中加入对话人信息来学习对话人嵌入表示,加强模型对于不同对话参与者的语言风格的理解能力.Li等人[13]提出了DCM(Deep Context Modeling)模型,在BERT编码后进一步对上下文和回复进行语义匹配,有针对性地提取上下文和回复中的相关语义特征.上述模型进一步提升了多轮对话回复选择任务的性能,但仍然无法学习到对话数据中的一些潜在特征,无法充分挖掘预训练语言模型的潜力.
近来,在预训练语言模型上添加辅助训练任务的方法获得了广泛关注.Whang等人[18]提出了UMS(Utterance Manipulation Strategies)模型.该模型设计了3个子任务来辅助优化预训练语言模型,分别是插入话语,删除话语,搜索话语,通过让模型恢复扰乱的对话数据,从而学习对话数据的特点.Xu等人[19]提出了BERT-SL模型.该模型设计了4个子任务,分别是下一会话预测,话语恢复,不连贯检测,一致性鉴别,其根本思想也是通过构建一些不同种类的不合理样本来让模型学习到对话数据应该具有的特点.辅助任务的引入,进一步挖掘了预训练语言模型的潜力,减小了模型的参数数量,但由于在训练中同时优化多个任务,仍可能导致模型训练的计算资源与时间成本大幅增加.
3 模 型
3.1 问题定义
多轮对话回复选择任务定义如下:给定对话数据集,内部的每一条数据形式都为(c,r,y).c={u1,u2,…,um}代表着包含m个话语的对话上下文,对话上下文中的第t个话语表示为ut={wt,1,wt,2,…,wt,lt},其中lt代表第t个话语中词的个数,回复候选为r={r1,r2,…,rlr},lr代表回复中词的个数.y∈{0,1}代表着数据的标签,y=1表示候选回复是当前上下文的合理回复,y=0则表示不合理.任务目标是在数据集D中学习得到能够准确计算上下文与回复相关度的模型g(c,r).
3.2 模型概述
图1为SAFL模型的整体架构.针对多轮对话回复选择设计微调任务.为了与SA-BERT[12]、UMS-BERT[18]、BERT-SL[19]等优秀的检索式多轮对话模型进行公平对比,SAFL模型选择BERT作为预训练语言模型,并采用重点局部信息蒸馏(Key local information distillation,KLID)机制提取融合预训练语言模型的输出.总体上说,微调的过程可以分解为四个部分,分别是输入层、编码层、特征融合层与预测层.各部分方法如下:
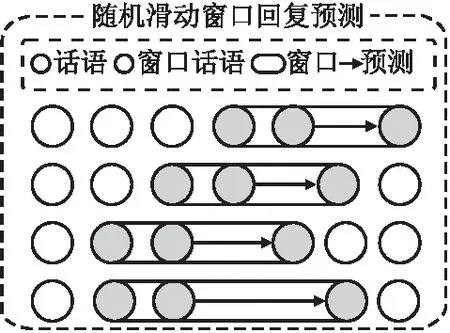
图2 滑动窗口回复预测RPRSW方法示意图Fig.2 Schematic diagram of the RPRSW
1)输入层
预训练语言模型的输入是由上下文和回复拼接而成,在输入的最前面插入[CLS],并在回复前后插入[SEP]来断开上下文和回复.特别的,SAFL模型在每一个话语的后面插入特殊的标记[EOT]来断开不同的话语,则输入为:
x={[CLS],u1,[EOT],u2,[EOT],…,
[EOT],um,[SEP],r,[SEP]}
(1)
其中u代表上下文中的话语,r代表着回复,m代表着话语的个数.
2)编码层
SAFL模型在编码层将整段对话数据输入预训练语言模型进行编码,将其在词粒度上映射为连续高维向量:
E=BERT(x)
(2)
3)特征融合层
预训练语言模型通过多层Transformer编码器能够学习到丰富的语义信息.输出中首部位置的[CLS]标签就包含了丰富的全局语义表示,其他位置标签也包含了每个词的多粒度上下文语义信息.为了充分利用预训练语言模型的输出,SAFL模型提出了重点局部信息蒸馏机制,该机制能够促进预训练语言模型生成多粒度的局部语义表征,还能够在多种粒度上筛选全局信息之中重要的部分,蒸馏出对于分类任务最重要的信息,具体将在3.4节详细论述.
4)预测层
预测层将局部信息感知模块得到的融合表征输入分类层计算得分g(c,r):
g(c,r)=σ(WTEensemble+b)
(3)
其中W是可训练的参数,σ(·)代表sigmoid激活函数.SAFL使用交叉熵作为主任务的损失函数:
(4)
在微调的同时,SAFL模型采用自监督学习策略,将预训练语言模型的参数导出,在两个辅助任务优化的过程中学习不同的语义特点.具体来说,SAFL的自监督学习策略中采用随机滑动窗口回复预测任务以学习局部的对话表示.该任务将在3.3节详细论述.此外,SAFL模型提出了能够学习对话结构信息的对话结构感知任务.该任务采用多层次的GCN编码预训练语言模型中的局部语义表征,在加强预训练语言模型理解对话结构的能力的同时,还赋予局部语义表征根据对话结构感知远距离话语的能力.该任务将在3.5节详细论述.SAFL在微调的过程中同时优化两个辅助任务与一个主任务,因此SAFL模型的完整损失函数如下:
Loss=Lossmain+αLosswindow+βLossDSA
(5)
其中α和β是两个超参数,分别用于控制RPRSW和DSA任务对于SAFL的影响力.
开源的预训练语言模型都是基于维基百科等公开数据集进行训练的,不具备足够的对话领域知识,因此本文提出了新的后训练策略PIL,PIL将对话上下文随机截取成长度不定的对话数据,在这些对话片段中通过优化MLM和NSP任务学习对话的阶段语义信息,为微调阶段提前提供关于短对话文本的指导信息,加强模型在短对话上下文中执行回复选择任务的能力.关于阶段信息学习PIL的详细信息将在3.6中进行详细说明.
3.3 随机滑动窗口回复预测任务
为了引导预训练语言模型学习到更多信息,以往多轮对话模型使用自监督学习策略,在策略中设计多个辅助任务来与主任务共同优化预训练语言模型.但是多个辅助任务带来的时间与计算资源代价是巨大的,同时与主任务相差过大的优化目标也可能会为回复选择任务引入噪声.为了解决上述问题,SAFL模型提出了效率更高的自监督学习策略,具体是提出了滑动窗口回复预测任务来取代以往多轮对话方法中的多个辅助任务,帮助模型更好的理解对话数据.该任务在预训练语言模型的输入中设定一个滑动窗口,使用[PAD]标记屏蔽掉滑动窗口以外的内容,然后针对滑动窗口中的最后一句话,提取这句话后面的特殊标记[EOT]并在这个标记上添加分类层,建立分类任务,预测这句话是否为滑动窗口中最合适的回复.RPRSW将滑动窗口的大小,长度,位置设为随机,从而让BERT中的[EOT]标签学习到对话中不同片段、不同时刻的语义信息,丰富[EOT]的对局部上下文信息的理解能力.为了RPRSW能够在对比学习之中准确的掌握局部区域信息的合理程度,SAFL模型从训练集的上下文中随机抽取话语,为每一个窗口构造负样本.
相比于以往研究工作中设计的插入,删除,替换等子任务,该子任务更加贴近主任务,本质上来说还是在做多轮对话中的回复选择任务,只是将范围关注到上下文中的局部范围内,使用不同的特征计算得分.因此,与主任务相似,子任务同样具有编码层,特征融合层,预测层3个部分.
1)编码层
子任务中共享了主任务编码层部分的参数:
E=BERT(x′)
(6)
其中x′是子任务的输入,与主任务不同,x′只保留窗口内部的信息,其他的信息由[PAD]替代:
x′={[CLS],[PAD],[PAD],…,ui,[EOT],ui+1,[EOT],…,
ui+w,[EOT],…,[PAD],[PAD]},w∈[κ,m]
(7)
其中w代表当前窗口的大小,m代表当前上下文的话语个数,κ是一个超参数,代表最小窗口的大小.
2)特征融合层
由于在BERT的预训练中,[CLS]位置是为了学习到全局的信息,为了不破坏全局信息,不采用主任务中使用[CLS]做分类的做法,转而使用窗口中的最后一个[EOT]的信息作为最后计算分数的输入.
3)预测层
(8)
其中wc,wr代表着窗口数据中的上下文和回复,Ww是预测层中可训练的参数,D′代表窗口数据集.使用交叉熵作为损失函数:
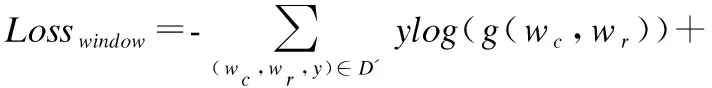
(9)
3.4 重点局部信息蒸馏机制
预训练语言模型的输出中包含着模型在预训练阶段已经学习到的大量信息,传统的基于预训练语言模型的多轮对话方法只使用能够代表全局信息的[CLS]表示进行微调,忽视了预训练语言模型中除[CLS]外其他位置的宝贵语义信息,导致了预训练语言模型的潜力无法被充分地发挥.同时,多轮对话中靠近回复部分的话语包含了与当前对话主题最相关的部分,而距离回复较远的话语通常与当前对话主题相关性较低,只针对全局信息进行学习可能会导致无关的信息被引入到模型之中.
因此本文提出了新的特征融合方法,并将其命名为重点局部信息蒸馏KLID机制,KLID采用了多个门控分别在不同的粒度上筛选全局信息,从而保证最终用于分类的语义表示一定是与回复最相关的.KLID机制的具体流程如下:
首先在主任务的特征融合模块中,KLID先从预训练语言模型之中提取出n个靠近回复的局部语义表示E[EOT]以及全局语义表示E[CLS],其中n是一个超参数,n个局部语义表示根据其与回复之间不同的距离表达了n种粒度的局部信息,然后将所有局部语义表示拼接起来作为整体的局部语义表示:
Eeot-ensemble=E[EOT]l⊕E[EOT]l-1⊕⊕E[EOT]l-2⊕…⊕E[EOT]l-n+1
(10)
其中l代表距离回复最近的条目,n代表取出[EOT]表征的个数.得到多粒度的局部信息表征后,KLID采用了多路门控机制来过滤全局语义表示中的噪声.具体的,KLID采用每一种粒度的局部语义表示去和全局语义表示做门控选择:
pk=gate(Wgate[E[EOT]k;E[CLS]]),k∈[1-n+1,l]
(11)
fusionk=pk×E[CLS]+(1-pk)×E[EOT]k
(12)
全局语义表示在经过多路门控选择后,能够根据不同粒度局部语义表示蒸馏得到不同粒度的混和语义表示fusionk,受门控机制的影响,每一个粒度的混和语义表示都包含了全局语义表示与当前粒度局部语义表示中最重要的部分.KLID进一步将由多路门控选择得到的多粒度混合语义表示与多粒度的局部语义表示进行拼接作为预测层的输入:
Eensemble=fusion1⊕fusion1⊕fusion2⊕…fusionl-n+1⊕E[EOT]l
⊕E[EOT]l-1⊕E[EOT]l-2⊕…E[EOT]l-n+1
(13)
输入进预测层,使用sigmoid激活函数计算最终的得分:
g(c,r)=σ(WTEensemble+b)
(14)
3.5 对话结构感知任务
除RPRSW辅助任务之外,SAFL模型在自监督学习策略上做了进一步的探索.任务中用到的预训练语言模型是使用维基百科等百科类公开数据集进行训练的,但是多轮对话文本具有特殊的对话结构,每一个对话话语与其他话语根据其相对位置、对话人的不同具有不同的语句联系.对话文本是由两个到多个的对话参与人构建而成的,不同对话人会拥有着自己特定的对话风格,在讲话时为了承接其他对话人的话也会产生与百科类文本不同的依赖关系,同时每个对话人自己的话语互相之间也会存在一定的联系.因此,SAFL模型进一步提出了对话结构感知(Dialogue Structure-aware Task,DSA)任务学习对话过程中不同语句之间的联系.DSA任务根据对话人说话的先后顺序构造图结构,并使用GCN进行编码,促使预训练语言模型学习正确的对话结构特征,增强预训练语言模型对对话数据的理解.对于对话关系图的构建,SAFL模型采用了文献[27]中的方法,将每个话语作为一个节点,每个边表示着话语之间的关系.如表1所示,在包含两个对话人的对话中,根据话语所属的对话人以及先后顺序,可以将其分解为表中的8种关系.

表1 对话话语之间的关系类别Table 1 Categories of relationships between utterances
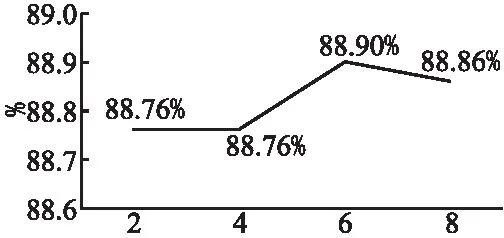
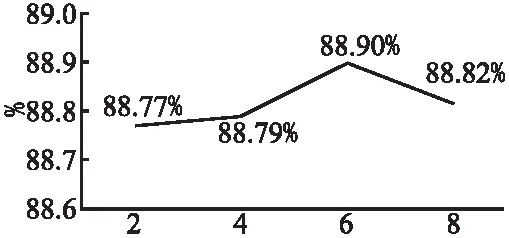
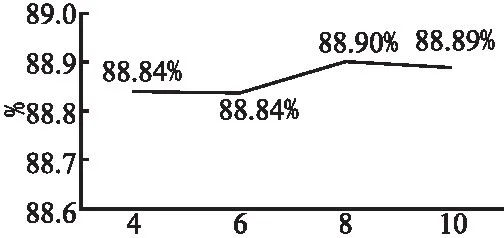
其中p(ui)表示了上下文中的第i个话语所属的对话人,p1、p2分别表示第1个对话人与第2个对话人,i 在结构上DSA任务依然具有编码层、特征融合层以及预测层.在编码层中,对话结构感知DSA任务使用主任务的BERT参数编码上下文: E=BERT(x″) (15) x″={[CLS],u1,[EOT],…,ui,[EOT],…,us,[EOT]} (16) 其中输入数据中包含s个话语以及其对应的局部语义标签,这些话语是从对话上下文中抽取出的连续对话片段,其中s为一个超参数,用于控制抽取片段的长度大小.为了让局部语义表征能够学习到对话结构信息,让所有的局部语义表征根据对话结构建立起联系,SAFL模型将s个局部语义表征从预训练语言模型的输出中提取出来,作为每一个话语的区域语义表征.以节点表示的形式输入到特征融合层中. 特征融合层采用与文献[27]相似的双层GCN学习图结构,第层的GCN为关系图卷积网络,能够对图结构中的边关系进行学习.首先使用注意力机制计算边关系的权重: (17) (18) 其中σ(·)代表sigmoid激活函数,R表示了表1中的所有的边关系集合,N表示图中所有节点的集合,ci,r是自动学习的边关系系数,Wr、Wm是模型需要学习的参数.得到了第1层的GCN中每一个节点的表示之后,SAFL模型使用不考虑边关系的普通GCN进一步学习对话结构信息: (19) 其中σ(·)代表sigmoid激活函数,Wnr、Wnm是第2层GCN中需要学习的参数. 在预测层中,SAFL模型将特征融合层中节点的表示进行拼接,获得整体的对话结构表示,并使用线性层计算分数: Es-ensemble=h1⊕h2⊕…⊕hs (20) g(ws)=σ(WTEs-ensemble+b) (21) 为了能够充分优化DSA任务,SAFL模型将连续的对话段落作为DSA任务的正样本,同时使用乱序的手段破坏对话语句之间的联系,并将其作为DSA任务的负样本.在优化的过程中采用交叉熵作为损失函数: (22) 其中ws代表着当前对话片段数据,D″表示对话片段数据集. BERT等开源预训练语言模型是在维基百科等大规模公开数据集上进行训练,上述数据集的文本特点与多轮对话数据并不一致,因此需要在对话数据中进行领域学习.对于领域学习,现有模型如BERT-VFT、SA-BERT、DCM、UMS-BERT、BERT-SL等主要采用后训练(Post training)策略.具体方法是先将多轮对话数据集中的上下文部分截取出来,输入到BERT模型中继续训练BERT.但由于所采用的预训练语言模型是在文本较长的百科类数据集上进行学习,用于较短的多轮对话文本上可能出现语义理解错误.同时数据集中上下文信息过少也会限制RPRSW任务的效果,导致BERT难以通过该任务学习到质量足够高的局部语义表示. 针对上述问题,SAFL模型提出了阶段信息学习PIL策略.PIL让预训练语言模型在领域学习的过程中学习大量的短句来提前学习对话的局部语义表示.具体而言,阶段信息学习策略的优化任务与BERT中的方法一致,使用遮蔽语言模型(Masked Language Model,MLM)以及下一句预测(Next Sentence Prediction,NSP)任务共同优化BERT模型.与传统后训练策略不同的是,PIL从对话上下文中随机的采样长度κ以上的连续对话段落,其中κ与RPRSW任务中的最小窗口大小κ是相同的,表示采样的连续对话片段至少要具有κ个话语的长度.领域学习阶段模型的损失函数如下: LossPLM=LossMLM+LossNSP (23) 本文选择使用Ubuntu和E-commerce两个数据集对SAFL模型进行评估.Ubuntu数据集是目前检索式多轮对话领域中最大的英文数据集,其内容收集于Ubuntu的公共交流社区之中.Ubuntu训练集中包含了100万条的多轮对话数据,每个多轮对话的正样本数据都有一个与之对应的负样本,因此Ubuntu训练集由50万组的正负样本对构成.Ubuntu测试集与验证集都各自包含了50万条多轮对话数据,其中每个多轮对话的正样本数据都有9个与之对应的负样本数据.Zhang等人[5]提出了E-commerce数据集,该数据集是多轮对话研究领域中第一个中文的电商场景数据集,收集于淘宝网上的客服平台.数据集中涵盖了包括商品咨询、物流快递、推荐、交涉、闲聊等主题在内的多种对话主题.在训练集和验证集中,正样本和负样本的比例为1∶1,在测试集中为1∶9.表2显示了两个数据集的统计信息. 本文选择最新的多轮对话模型作为对比模型,包括DUA[5]、DAM[6]、IMN[8]、MSN[10]、BERT-VFT[11]、DCM[13]、UMS-BERT[18]、BERT-SL[19]. 本文基于Pytorch框架实现了SAFL模型,并在两张NVIDIA Tesla V00 GPU上进行实验.对于用于微调的英文预训练语言模型,使用由huggingface官方提供的BERT-base模型;对于用于微调的中文预训练语言模型,使用由哈工大讯飞联合实验室提供的Chinese-BERT-wwm.模型设定训练的批大小为8,并使用梯度累积策略,在累积5个批次后更新梯度.模型使用Adam算法作为梯度下降的优化器,学习率设定为8×10-6.模型中所有的分类层dropout比例统一设定为0.8.领域学习采用由SAFL模型中阶段信息学习策略训练得到的模型,设定训练的批大小为16,累积24个批次后更新梯度,其他的训练基本参数与微调阶段一致. SAFL模型设定了多个超参数,包括随机滑动窗口回复预测任务中的最小窗口大小、重点局部信息蒸馏机制中融合的局部信息感知表征个数以及对话结构感知任务中抽取对话片段的长度.模型对不同数据集采用不同的超参数组合.在Ubuntu数据集中,模型将随机滑动窗口回复预测任务中的最小窗口大小κ设定为6,将重点局部信息蒸馏机制中融合的局部信息感知表征个数n设定为6,将对话结构感知任务中抽取对话片段的长度s设定为8.在E-commerce数据集中,模型将最小窗口大小κ设定为2,局部信息感知表征个数n设定为2,抽取对话片段的长度s设定为5.对于随机滑动窗口回复预测任务中不同类型的负样本比例,在两个数据集中都采用 100%随机采样策略.损失函数中的超参数α,β设为1. SAFL模型使用R10@k,k∈{1,2,5}召回率作为评测指标. 表3展示了SAFL与对比模型在两个数据集上的性能.表中所有对比模型的结果均取自各个模型对应的文献.从实验结果可以发现,SAFL模型在Ubuntu数据集上的各项性能指标均优于所有对比模型;在E-commerce数据集上的性能指标同样优于对比模型,仅在R10@5上略低于BERT-SL. 表3 SAFL与基准模型的性能对比Table 3 Overall performance of SAFL and the baseline models 对于Ubuntu数据集,SAFL与基于匹配架构的多轮对话算法中效果最佳的MSN模型相比,R10@1、R10@2、R10@5分别提升8.90%、5.20%、1.31%.SAFL的预训练语言模型借助自注意力运算根据语境充分学习全局的对话文本语义,而MSN单独编码每个句子,难以建立准确的全局语句依赖关系.与采用预训练语言模型的效果最佳的DCM模型相比,SAFL模型在R10@1、R10@2、R10@5指标上分别提升2.10%、1.50%、0.41%.说明多任务学习方法相比增加额外模块或数据能更有效挖掘预训练语言模型的潜力.与基于多任务学习的最佳模型BERT-SL模型,SAFL在最能够体现模型关键性能的R10@1、R10@2指标上获得了0.50%、0.50%的性能提升.此外,SAFL相较于BERT-SL少了两个辅助任务,大大减少了训练时间与计算资源的消耗,说明SAFL的辅助任务具备更有效的多轮对话学习能力. 对于E-commerce数据集,SAFL与基于匹配架构的最佳模型IMN相比,R10@1、R10@2、R10@5分别提升了16.70%、12.40%、2.60%.与采用BERT的最佳模型SA-BERT相比,分别提升8.40%、4.20%、0.50%.与基于多任务学习的最佳模型BERT-SL相比,R10@1、R10@2指标提升了1.20%、0.20%,表明SAFL的辅助任务在文本长度较短的E-commerce数据集上依然具备精度与效率的双重优势.综上,SAFL在中英文数据集上的性能均优于对比模型. 本节分析SAFL各模块对整体性能的影响.消融模型包括SAFL w/o DSA、SAFL w/o KLID、SAFL w/o RPRSW与SAFL w/o PIL.SAFL w/o DSA去除了对话结构感知任务;SAFL w/o KLID去除重点局部信息蒸馏机制,同时将预测层的输入替换为预训练语言模型中的CLS全局语义表征;SAFL w/o RPRSW去除随机滑动窗口回复预测辅助任务;SAFL w/o PIL去除用于领域学习的阶段信息学习策略. 表4展示了消融实验的详细结果.从表中可以看到,SAFL w/o DSA的R10@1、R10@2、R10@5指标分别下降了0.10%、0.07%、0.01%,证明对话结构感知任务所学习的对话结构信息能够有效增减预训练语言模型对多轮对话的理解能力.SAFL w/o KLID则分别下降了0.28%、0.28%、0.05%,证明重点局部信息蒸馏机制所提取的重点局部信息与全局信息能够有效帮助模型甄别正确的回复;SAFL w/o RPRSW分别下降了0.63%、0.32%、0.05%,相较于DSA任务来说对模型带来的影响更大,说明RPRSW任务的能够有效提升局部语义理解能力.SAFL w/o PIL下降了4.82%、3.07%、0.84%,说明SAFL模型提出的阶段信息学习策略能够为预训练语言模型带来丰富的领域信息. 表4 消融实验结果Table 4 Ablation experiment results 本节通过多组参数实验分析各超参数对SAFL模型的影响.参数实验包括了SAFL模型中随机滑动窗口回复预测任务的最小窗口大小、重点局部信息蒸馏机制采用的局部语义表征个数、对话结构感知任务抽取的对话片段长度分析. 图3列出了在Ubuntu数据集上RPRSW任务不同最小窗口大小对SAFL模型的影响.从图中可以发现,当κ<6时,模型性能显著低于κ=6时的模型性能.当κ过小时,RPRSW任务可能会接收到轮数过少的短对话文本,无法学习到足够的信息.同时当κ过大时同样会限制RPRSW任务对SAFL模型的增益,因为当窗口的下限大小接近了对话数据集的平均长度时窗口可滑动的空间就越小,导致了RPRSW任务难以学习到更多样性的信息.因此RPRSW中最小窗口大小κ决定了RPRSW能够学习信息,适中的κ才能够综合考虑到局部语义学习和信息多样性. 图3 RPRSW最小窗口大小分析图Fig 3 Effect of the minimum length of the sliding window on the performance of SAFL 图4列出了在Ubuntu数据集上重点局部信息蒸馏机制KLID采用的局部语义表征个数n对SAFL模型的影响,KLID从预训练语言模型的输出中采样了距离回复最近的n个局部语义表征用于门控融合筛选以及后续的预测,因此超参数n直接影响着SAFL模型能够运用多少粒度、距离回复多远的局部语义表征.从图中的实验结果可以看到,当n≤6时,模型性能随着n的增长逐渐提升,说明更多的局部语义表征用能够为模型带来更丰富的信息,同时运用更多的局部语义表征进行门控筛选也能够提高最终特征的质量.但当n≥6时,模型性能随着的增大而下降,说明过多的局部语义表征会导致许多与回复关联度较低的信息被融合到预测层中. 图4 KLID采用的局部语义表征个数分析图Fig 4 Effect of the number of local semantic representations adopted by KLID on the performance of SAFL 图5列出了在Ubuntu数据集上DSA任务抽取的对话片段长度s对SAFL模型的影响.超参数s直接影响到DSA任务能够学习多少对话结构信息.当输入的对话文本轮数只有4轮时,每个对话人各自只说了两轮的话语,整体对话文本中存在的结构信息太少,DSA任务难以从中学习到足够完整的对话结构信息.从图中可以发现,当s≤6时,SAFL性能较差,而当s≥8时DSA任务接收到足够长度的对话文本,能够学习到完整的对话结构信息,模型性能也随之提升. 图5 DSA任务中抽取对话片段的长度分析图Fig 5 Length analysis diagram of extracted dialogue fragments in DSA task 本文针对检索式对话方向上的多轮对话任务,提出了一种局部信息增强与对话结构感知的多轮对话模型SAFL.SAFL提出了随机滑动窗口回复预测任务RPRSW来充分学习不同对话阶段、对话长度的语言特点,显著加强了预训练语言模型对不同位置对话数据的理解能力.SAFL模型提出了重点局部信息蒸馏KLID机制借助多门控融合方法从全局和局部信息之中蒸馏出重点信息,解决了现有方法对重点信息的筛选不够充分的问题.SAFL提出阶段信息学习PIL在微调前加强预训练语言模型对短对话数据的理解能力,解决了基于预训练语言模型的方法学习短对话数据困难的问题.SAFL采用了对话结构感知DSA任务根据对话人说话的先后顺序构造图结构,并使用图卷积网络进行编码,在对话结构的方向上进一步加强了模型的效果.在Ubuntu数据集和E-commerce数据集上进行了实验分析,实验结果表明SAFL在两个数据集中均优于了所有的对比模型,并且通过多组实验证实了模型中各个模块的有效性.在未来的工作中,本文工作将会针对如何促进预训练语言模型生成像对话主题、指代关系等更深层次的语义特征这一问题做更进一步的研究探索.3.6 阶段信息学习
4 实验和结果
4.1 数据集与对比算法
4.2 实验设置和评估指标
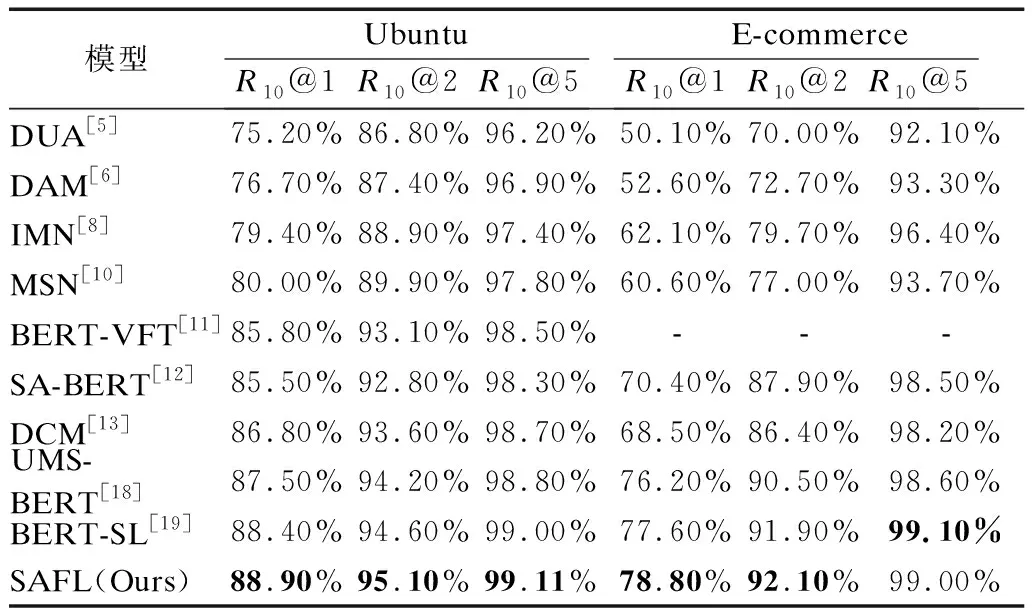
4.3 实验结果分析
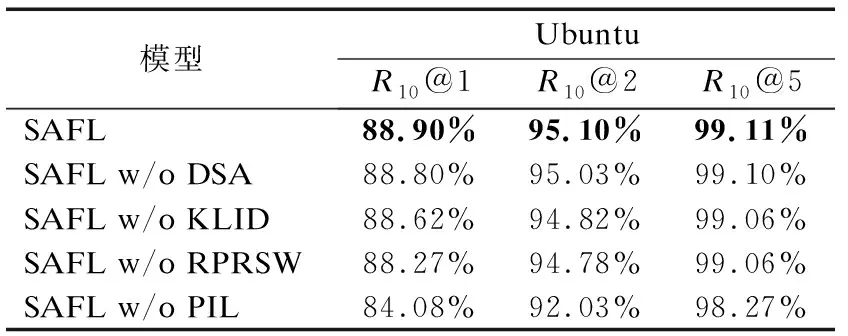
4.4 消融分析
4.5 参数分析
5 总 结
