雨天场景下单目图像深度估计与清晰化算法
2023-11-10张家豪郎晓奇
张家豪,张 娟,郎晓奇
(上海工程技术大学 电子电气工程学院,上海 201620)
1 引 言
深度估计一直以来都是计算机视觉领域的一个核心问题,也是视觉感知的基本组成部分,能为图像理解、目标识别、机器人抓取等任务提供物体深度信息.以往场景的深度图一般通过深度相机或者激光雷达来获取,但这类能直接获取场景深度的传感器目前还存在价格高昂、分辨率较低、使用场景有限等问题.此外场景深度还可以通过多视角几何学从多个相机中推算出来,但是要建立一个立体相机系统需要大量复杂的校准、矫正和同步计算,因此实际运用较少[1].近些年出现了不少依靠深度学习算法只使用单目RGB相机实现场景深度估计的算法[2-5].这类算法通过大量成对的图像-深度数据集进行训练,克服了传统算法需要多个视图才能恢复场景深度的局限性,并且恢复深度图像质量较高,物体轮廓信息更清晰,成为了深度估计领域的热门研究方向.然而在计算机视觉领域研究中常假设光线在传输过程中是不受任何干扰的,这种假设在正常天气条件下是合理的.然而在恶劣天气情况下,如常见的雨、雪、雾等都会干扰光路的传输,使采集的图像出现退化现象,给目标检测、深度估计、语义分割等计算机视觉算法带来了额外的挑战[6].尤其在雨天场景下,雨水会对单目图像的深度估计任务产生极大的干扰,由于雨线会对图像产生密集的遮挡且接近相机,因此雨天场景下的深度图不仅边缘不清晰,还会将原本处于远处的物体误认为在近处.如图1所示,现有深度估计算法在雨天场景下深度图质量严重下降.
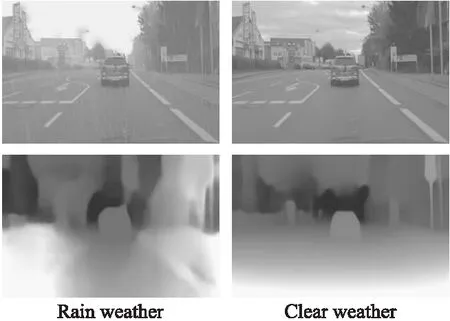
图1 雨天与正常天气下深度估计结果对比Fig.1 Comparison of depth estimation results in rainy and normal weather
单目RGB图像的深度估计算法所需硬件价格低廉、应用场景广泛,因此吸引了众多研究者的关注.Eigen等人[7]首次使用卷积神经网络,通过多尺度结构分别对全局深度信息和局部细节进行优化,实现了端到端的深度估计.Chen等人[8]提出了一种通过金字塔残差网络结构实现多尺度特征融合的方法,通过自适应特征融合模块融合不同尺度的有效特征,实现了从全局场景到局部细节残差的逐步细化恢复.文献[9]将结构化注意力和多尺度条件随机场(Condition random field,CRF)模型引入编码网络,进一步提升了算法精度.这类有监督单目深度估计方法目前精度较高,但仍然存在一些缺陷,其中恶劣天气场景下鲁棒性较差限制了该类算法的实用价值,恶劣天气场景下的深度估计依然是一个具有挑战性的难题.自监督学习深度估计算法由于不需要成对的训练样本,因此进一步扩展了使用场景.Aletti等人[10]结合对抗生成网络建立一个无监督单目深度估计框架,通过判别器对重建深度图进行鉴别和约束,取得了不错的效果.自监督算法拓展了深度估计算法的应用场景,但由于缺乏真实的监督信号,恢复结果的质量还有待提高.
本文对目前基于深度学习的深度估计算法在雨天情况下效果欠佳的原因进行了分析,通过研究发现大多数基于深度学习的深度估计算法和其他图像任务一样通过控制标准卷积的步长或者进行池化操作来改变网络的感受野.这种方法针对图像分割、目标识别等粗粒度视觉任务能取得不错的效果,但深度估计算法需要对每个像素的值进行精确估计,然而扩大步长、池化等操作会丢弃大量特征信息,大幅降低需要细粒度表示任务模型的性能[11].有雨场景下不同深度的雨线颜色接近,此时如果在深度估计网络中大量使用最大池化操作,就会导致局部的深度信息丢失,局部位置在不同深度的图像块计算得到相似的特征值,场景深度图中各类物体边缘模糊,造成如图1所示预测结果.此外,采用编码器-解码器网络架构的单目深度估计算法中,解码器使用的传统上采样策略[12,13]也很难保留足够的细节信息用来恢复场景的准确深度.
针对雨天场景本文提出使用视觉Transformer结构组建编解码网络提取不同尺度的特征,并通过跳跃连接在不同层级和解码器部分共享信息,实现长距离上下文信息共享.不同于普通的编码器-解码器结构通过标准卷积核对图像进行降采样,在编码器网络中本文利用补丁合并层(Patch Merging Layer)对图像特征进行降采样,补丁合并层在增加一定运算量的情况下能有效防止下采样过程中的特征丢失;编码-解码网络中还引入了Swin Transformer[14]结构,通过多头注意力机制整合不同尺度的空间和语义信息,该结构能通过融合各位置的语义和空间信息对每个像素进行约束和分类,提高了雨天场景下物体边缘信息的准确性;编码器和解码器在各级尺度间加入了跳跃连接,进一步减少网络下采样带来的空间信息损失;实验结果表明本文方法在雨天场景下的深度估计结果优于现有的单目深度估计算法.此外本文还设计了以场景深度图作为先验知识的轻量级去雨网络,去雨网络中通过深度信息引导的全局注意力模块(Depth-guide Global Attention Module,DGGA)来捕捉深度差异较小的不同空间位置的关联性以及各位置图像特征的关联性.通过深度信息指导不同深度位置图像的恢复.在公开合成和真实数据集上的表现验证了本文去雨算法的有效性,去雨网络能够有效移除雨天场景中存在的雨痕和雾气.本文提出的雨天场景下联合的深度估计与清晰化的整体网络结构见图2.
总的来说本文主要有以下创新:
1)针对现有单目深度估计算法在雨天场景下精度较低问题,提出了联合的深度估计和图像清晰化算法,不仅能够对雨天的场景深度进行准确预测,还能根据深度信息还原出纹理清晰、无雨线残留的清晰图像.
2)将目前深度学习领域效果最佳的Transformer结构应用于单目深度估计网络,改善了现有深度估计算法中存在的特征丢失问题,通过自注意力机制加强了图像中各类像素的语义分类,降低了深度图的边缘误差,在雨天场景下的表现优于现有算法.
3)提出了一种基于图像深度信息先验的去雨算法,利用深度信息引导全局注意力模块进行雨天图像的恢复,恢复结果纹理清晰锐利,去雨效果显著.
2 联合单目深度估计和去雨网络
2.1 单目图像深度估计模型
单目深度估计算法的目的是利用单张RGB图像对场景中各个位置的深度信息进行预测,目前的研究主要是通过深度学习网络对图像特征进行表示学习,建立场景特征和深度的映射关系,主要采用多尺度结构、注意力机制、编码-解码网络等结构加强对场景全局特征和局部特征的语义学习.但传统的深度估计网络扩大感受野的方法影响了场景深度的边缘轮廓和细节恢复效果,还需要进一步改进.本文通过transformer结构对输入特征进行保留位置信息的多尺度特征编码,避免了下采样操作带来的特征丢失问题,还能高效地对场景的全局信息进行提取,网络中Swin Transform Block(STB)的多头自注意力机制对不同尺度的重要特征进行了重点关注,增强了对边缘语义信息的学习.
图2左侧部分是本文提出的U型transformer架构的深度估计网络,模型主要包含了编码、解码、跳跃连接三大部分.其中编码、解码网络中最主要的特征提取结构是STB,STB的加入让网络具有全局注意力能力的同时还降低了算法的时间复杂度.编码器网络首先将输入尺寸为H×W×3的图像转化成包含位置信息的有序嵌入块,每个嵌入块的维度为4×4×3,随后通过线性嵌入层将特征映射到任意维度C.转化后的特征通过补丁合并层和STB进行降采样和语义信息提取,减少了多尺度特征信息变换和融合过程中的特征丢失.具体来说,补丁合并层对特征降采样的方式不同于池化操作,池化操作会丢去窗口内的大部分响应值.补丁合并层不会丢弃对窗口内其他响应,补丁合并层将相邻补丁块以2×2的大小进行切分,随后在通道维度上对特征进行连接,最后通过全连接层调整通道维度.补丁合并层在增加少量运算的代价下,提高了对细节特征的响应;接着编码器中的STB负责对不同尺度下的语义和空间特征进行表示学习.解码器部分采用了和编码器类似的对称结构,通过补丁扩展层(Patch Expanding layer)和STB对特征进行上采样和表示学习,并最后输出场景深度图.其中补丁扩展层通过对特征维度进行重组,将特征上采样为输入特征的2倍大小,编码器和解码器对应尺度之间通过跳跃连接实现特征融合,缓解下采样造成的空间特征损失.最后的补丁扩展层将特征进行4倍上采样还原到输入分辨率W×H,输出像素级的深度估计结果.网络中的重要特征提取结构STB见图3.
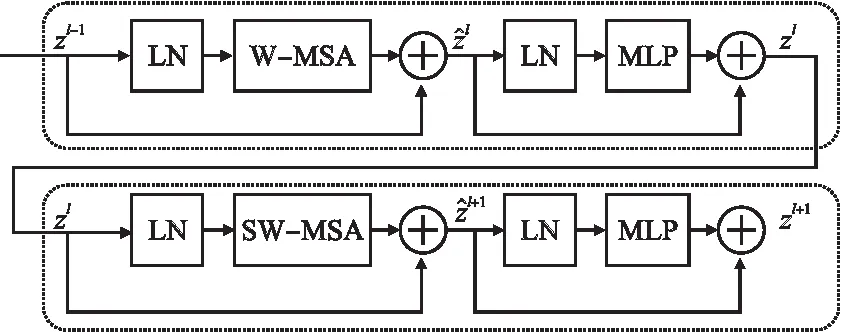
图3 Swin transformer block 具体结构Fig.3 Detailed structure of swin transformer block
STB与传统的多头自注意力(multi-head self-attention,MSA)模块的不同之处是采用了不同的窗口切分方式,通过滑动窗口操作实现了跨窗口的通信,提高了传统MSA的建模能力.如图3所示STB由归一化层(LN)、transformer层以及多层感知机(MLP)构成,其中transformer部分分别使用了窗口多头注意力(W-MSA)和移位窗口多头注意力(SW-MSA),STB的工作机制如公式表示:
(1)
(2)
(3)
(4)

(5)
其中Q,K,V∈M2×d分别代表query,key和value矩阵,M2和d是窗口内的嵌入块特征数量和key的维度,B是一个重采样的偏置矩阵.
2.2 深度估计网络损失函数
根据RGB图像进行深度估计是一个回归模型,根据深度图的特性,本文损失通过最小化深度估计结果和真实标签的差异来优化重建深度图的质量.本文损失函数由3种损失加权得到,损失函数公式见公式(6):
(6)

(7)

(8)
其中g是梯度求导函数.
最后一部分是Lssim损失,SSIM主要评价的是图像在结构上是否相似,相比于像素间损失,对高频细节和边缘更加敏感,能让预测结果在全局视觉效果上更接近人眼的真实视觉结果.当SSIM值接近1时表示两张图像在结构上极为相似,反之则极为不同.利用这一特性本文设计的基于SSIM的结构性损失函数如公式(9)所示:
(9)
其中fssim是相似度函数,δ是一个极小正值,防止除零错误.
3 深度引导的去雨网络
Garg[15]等人对雨天场景进行分析,发现可以利用场景的深度函数来描述雨线在不同场景深度下的遮挡和雾效应,Garg指出距离相机较近的物体主要受雨线遮挡的影响,距离较远的位置主要受到雨滴产生的雾气效应的影响,雨天场景下不同位置的具体情况与图像的深度信息存在关联性.受到基于雨天物理模型中场景深度和雨线关系的启发,本文将雨线残差层R(x)定义为两部分组成:
R(x)=Rspace(x)⊙tr(x)
(10)
其中Rspace(x)是雨线的空间分布强度信息,tr(x)是场景的雨线强度图,tr(x)取决于场景的深度信息d(x),tr(x)的强度随d(x)的增加而减小.为了捕捉场景深度和雨天图像特征对应的全局关联性,本文设计了图4所示的深度引导的全局特征注意力模块.
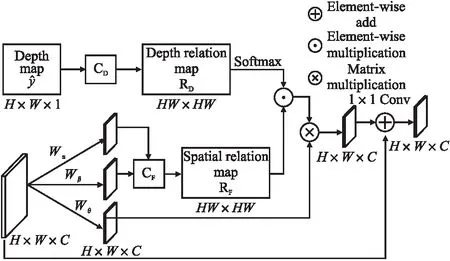
图4 深度的引导的全局特征融合模块Fig.4 Depth-guide global attention module
该模块的输入是预测的场景深度图,首先通过CD计算深度图各位置之间的全局深度信息关系图RD,CD操作先将特征图变换成一维向量,随后计算每个位置之间在对数空间的距离,Ry计算公式如公式(11)所示:
RD[i][j]=Softmax(e-0.1×|d[i]-d[j]|)
(11)
其中d[i],d[j](i,j)∈[1,HW]是对应位置的深度值.
对于输入的图像特征F,本文对雨线强度在各空间位置的强度相关度进行计算,先通过3个卷积操作得到特征图Fα,Fβ,Fθ,然后对特征图Fα和Fβ进行CF操作得到位置关系图RF.RD和RF二者进行矩阵相乘,并归一化处理来计算深度和图像特征的相关性,最后通过残差结构和输入特征相加获得DGGL的输出Z:
Z=Wz(g⊗Softmax(RD⊙RF))+F
(12)

(13)
其中Ll1是L1距离损失,Lp是感知损失.
4 实验结果与分析
4.1 实验设置
为了对本文提出算法的效果进行检验,本文在公开的RainCityscapes[16]数据集上进行了模型的训练及测试.RainCityscapes包含了来自Cityscapes数据集中成对的清晰图像、深度图以及合成雨天图像.在和其他去雨算法比较去雨效果时,选择了公开的合成数据集和一个真实世界数据集.
本文算法使用Pytorch进行部署,GPU为NVIDIA GTX 2080,处理器为Intel Xeon CPU E5-2603,内存32GB,实验平台为Ubuntu16.04.在实验中训练数据的分辨率为256×256,使用Adam优化器进行梯度下降优化,批大小为4.深度估计网络中超参数设置为α=0.01,β=0.5,θ=1,去雨网络中的超参数设置为λ=0.04,初始学习率为0.0005,使用余弦退火策略来控制学习率的下降,在数据集上进行1200轮次训练,随后在对应测试集上进行测试.
为了客观评价深度估计网络的性能,本文使用了深度估计算法常用的5个评价指标,其中包含4个距离误差指标:均方根误差(RMSE)、均方根对数误差(RMSE log)、绝对相对误差(Abs Rel)、平均相对误差(Sq Rel),以及不同阈值的准确率(δ).去雨网络采用了PSNR和SSIM两种客观指标和现有去雨算法进行公平对比.
4.2 实验结果对比
为了验证本文提出算法中深度估计算法的有效性,将本文算法和其他8种先进的单目深度估计算法在RainCityscapes数据集上进行了量化比较.不同于Mondepth2[17]中在编码器网络中使用了池化层对提取特征进行降采样,本文通过STB对特征进行降采样和编码,STB通过补丁合并层避免了进行多尺度变换时对窗口内部分响应的丢弃,减少了特征的丢失.STB还通过多头注意力机制对加强了对场景中语义信息和空间信息的约束,使深度图结果中各物体的边缘轮廓更加清晰,场景中各类物体深度信息更具有连续性.此外本文在transformer结构中使用了跳跃连接加强了对上下文信息的利用,实现了不同尺度语义特征的融合.不同尺度特征的充分提取和融合让本文算法在雨天场景下各类物体的轮廓更加清晰、细节更加丰富,深度信息更加准确.因此如表1中实验结果所示,本文算法在同类算法中表现更好,尤其在雨天场景下对物体的边缘轮廓的估计更加准确,各项误差相比于其他算法均有降低,不同阈值下的精度也有提升.

表1 不同深度估计算法在RainCityScapes测试集上结果对比Table 1 Comparison with state-of-the-art methods on RainCityScapes test set
图5是本文和Xu[19]、GeoNet[20]、Mondepth2[17]算法在雨天场景下深度图的视觉结果对比图,图中可以观察到由于受到雨线的影响,Xu和GeoNet的预测结果在雨线密集区域出现了明显的同化现象,错误地将雨线遮挡部位误认为深度相同的区域,物体轮廓信息模糊、边缘细节较差.Mondepth2算法在雨天场景下表现较好,在雨天场景下依然能对中远距离的物体进行有效识别,但对于小目标物的识别效果较差.

图5 雨天场景下各算法深度估计结果对比Fig.5 Comparison of depth estimation results of different methods in rainy weather
本文算法相比其他3种算法在雨天场景下受雨线影响最小,其中编码器部分的结构以transformer为主体,显著改善了算法在不同尺度下对上下文信息的利用率,使得本算法在雨天场景下在依然可以准确捕捉到物体的清晰轮廓信息,在视觉效果上优于其他算法.从图5的前两幅图中可以看出对于雨天图像中路边的树木以及路灯等小目标物,Xu的预测结果由于受到雨水的影响,物体轮廓不够清晰,深度信息有部分缺失,GeoNet和Mondepth2则基本没有估计出树木和路灯等小物体的深度信息.本文采用的STB能有效减少网络中特征丢失的问题,因此对场景中小物体的深度信息估计准确度更高.图5最后一列是本文根据深度估计结果通过去雨子网络实现的去雨结果,从图中可以观察到相比于输入图像,经过去雨处理之后,图像中近处的雨线和远处的雾都有了不同程度地减少,提高了目标在恶劣天气情况下的辨识度,改善了目标检测、语义分割等任务在恶劣天气下的鲁棒性.
表2是本文算法和现有8种去雨算法在去雨数据集Rain100H[24]、Rain100L[24]上的表现,去雨网络部分是先将联合的深度估计和去雨网络在RainCityScapes数据集上进行预训练,随后冻结深度估计网络权重,然后在相应的去雨数据集上对网络进行fine-tune.表2实验结果表明本文相比于其他算法在去除雨纹方面有较大优势.例如在Rain100L上相比于PreNet[25]和MSPFN[26],PSNR分别提高了2.98dB和7.27dB,在SSIM上比MSPFN提高了6%,类似地提升在Rain100H数据集上也有体现.这表明本文算法对不同密度、大小、速度类型雨线都能够进行有效捕捉,将雨天图像处理成纹理清晰、无雨水遮挡的干净图像.此外本文的去雨网络此外考虑到Rain100H和Rain100L都是合成数据集,并没有考虑在真实场景下雨天也会有雾的存在.因此在数据集上的表现并不能完全代表实际场景中的表现,本文还将去雨算法在真实场景中进行了测试,从图6中可以看出相比于没有图像深度信息引导的其他去雨算法,本文以雨天场景下的物理模型为依据,利用图像的深度信息作为先验,不仅可以去除场景中的雨线还能减弱雨天场景下雾的影响.真实场景下本文算法结果中的雨线残留最少,并且有效保留了原有图像的纹理信息,画面中的噪点最少,画面更加纯净.
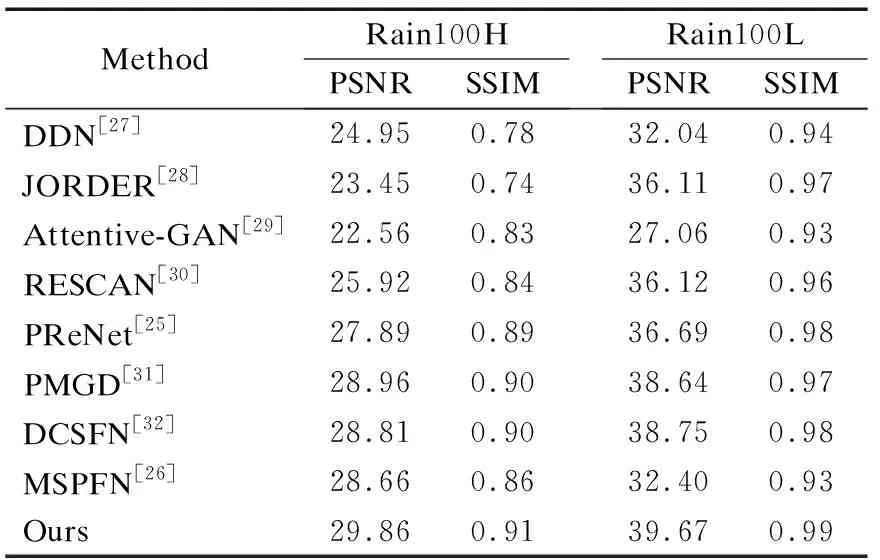
表2 和其他去雨算法在Rain100H/L测试集上对比结果Table 2 Comparison with state-of-the-art methods on Rain100H/L testset

图6 真实场景下各算法去雨结果对比Fig.6 Comparison of rain removal results of different methods in real scenarios
4.3 消融实验
为了验证本文提出算法的有效性,针对雨天深度估计网络中的上采样方法、跳跃连接结构进行了消融实验,去雨网络中则对深度信息的引导作用以及本文提出的DGGA模块在RainCityscapes数据集上进行了消融验证.
在深度估计的解码器网络中,本文设计了补丁扩展层来实现上采样和特征维度的增加,为了验证本文提出的补丁扩展层在本文解码器网络中的作用,分别与双线性插值、转置卷积方法进行了对比实验,表3消融实验结果表明,本文提出的上采样方法能够让物体的边缘和细节深度信息更加准确.本文中将编解码网络之间的跳跃连接添加在了1/4、1/8和1/16处,因此针对跳跃连接的对数也进行了消融实验,探索跳跃连接个数对估计精度的影响.表4消融实验结果表明随着跳跃连接个数的增加模型性能也不断提升.考虑到模型的大小和稳定性,本文将连接数设置为3.

表3 不同上采样方法消融实验对比Table 3 Comparison of ablation experiments with different up-sampling methods

表4 跳跃连接数量消融实验结果Table 4 Ablation study on the impact of the number of skip connection
在场景深度引导的去雨子网络中,本文针对深度信息的引导作用以及DGGA模块进行了消融实验;表5中第1行是将深度信息移除后去雨网络得到的基准结果,第2行是将深度信息作为先验使用普通的残差(Residual Block,RB)网络对深度和雨线空间信息进行融合得到的去雨结果,最后一行是加入了本文提出的DGGA模块对雨天场景下的深度信息和雨线特征进行全局特征融合后得到的结果.消融实验结果表明深度信息的加入有助于恢复更高质量的图像,且本文提出的深度信息与雨线特征融合方法结果的PSNR和SSIM最高,更接近真实标签.

表5 去雨网络消融实验结果Table 5 Results of deraining network ablation experiment
5 结束语
本文提出了一种联合的雨天场景下单目图深度估计和清晰化算法,改进了现有深度估计算法雨天场景下鲁棒性较差的问题,实现了雨天场景下的图像清晰化.本文首先提出了一种以transformer为基础的U型多尺度编解码网络,该网络在基于单目图像深度估计的公开数据集上的表现,验证了本文提出深度估计算法的有效性.此外本文还基于场景深度和雨线位置之间的相关性设计了场景深度信息引导的残差去雨网络,实现了雨天场景下雨线和雾的移除.和其他去雨算法相比在真实场景下表现更佳.目前本文的主要工作内容是实现雨天场景下的深度估计和去雨,并未对算法的运行速度和算法复杂度进行深入研究,未来将着重算法的轻量化研究,为雨天场景下的自动驾驶、目标检测等任务提供更多帮助.
