基于跟踪关联的行人检测方法研究
2023-11-07张可心
张可心,宋 辉,刘 淇
(1.沈阳工业大学信息科学与工程学院,沈阳 110870;2.烟台东方威思顿电气有限公司,烟台 264000)
1 引 言
随着技术的发展和基础设施建设的完善,为保证交通安全,从视频或图像中对行人目标进行检测已成为近年来研究的热门课题。在道路交通场景中,由于受到行人的关节部位的运动变化、背景遮挡、行人重叠等因素的影响,对行人进行即时准确的检测就变得十分复杂。行人检测算法可以根据行人检测的研究过程分为传统行人检测算法和基于深度学习技术的行人检测算法[1]。目前基于深度学习的行人检测技术主要被分为两类:基于回归模型的一阶段检测算法和基于区域生成的二阶段检测算法。行人被遮挡的情况在行人检测问题中是占绝大多数的,令许多学者的目光关注到对被遮挡的行人的检测上。在遮挡行人检测中,行人突然从司机的视野里出现或消失这一现象虽然属于小概率事件,但不能完全避免,也一直缺乏解决的对策。对于被遮挡行人的检测算法,遮挡面积的大小以及遮挡的部位都对检测的准确性有一定影响,且由于行人的遮挡情况比较复杂,无法对每种遮挡情况进行逐一研究;同时由于遮挡行人的姿态较为多样,模板匹配法不能很好地匹配被遮挡行人的目标特征。针对现有的诸多问题,在此提出一种基于前后帧关联的部分被遮挡行人检测方法。
2 网络设计
2.1 算法模型的发展
在基于卷积神经网络的行人检测算法中,二阶段算法的特点是需要使用生成算法找到不同的候选框,然后将候选框提取的特征组作为回归和分类输入[2]。2014 年,Donahue 等人[3]提出了经典二阶段目标检测算法R-CNN,采用卷积神经网络进行特征提取,替代了传统的特征提取方法,之后用SVM 分类器进行回归分类,是首次将深度学习应用到目标检测之上的算法。2015 年,何凯明团队提出了Faster R-CNN 网络[4],采用区域生成网络(Region Proposal Network, RPN)获取预选区域,并使用多种尺度的锚框解决多尺度目标和检测问题,提升了网络检测速度。在此基础上,特征金字塔网络[5](Feature Pyramid Networks, FPN)采用多尺度特征融合模型解决了目标尺度差异较大的问题。
另一类方法是基于回归的一阶段算法,常用的包括YOLO[6]、SSD[7]、RetinaNet[8]等。这类算法只需要一步即可完成所有操作,极大地提高了网络的检测速度。YOLOv5 算法在速度与精度的平衡上做了许多优化,比如最近有人提出的改进YOLOv5 的行人检测算法[9],通过放大数据集的训练网格的方式,提高了对遮挡行人的检测精度。
针对部分遮挡行人目标的检测问题,在此提出一种基于目标跟踪的被遮挡行人检测方法,其网络整体设计流程图如图1 所示。
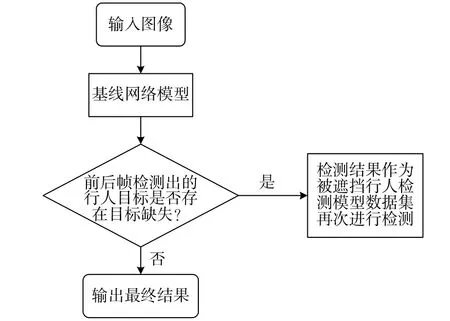
图1 网络整体设计流程图
方法的总体思路为:通过目标跟踪的方式对被遮挡的行人目标进行图像前后帧关联,将数据集输入到基线网络模型中进行训练,输出预测结果;同时对同一个视频的视频帧判断输出的预测结果中是否存在目标缺失,若存在目标缺失,即可能存在未被检测出的被遮挡行人目标。将预测结果作为训练样本再次输入基线模型进行二次训练,通过卡尔曼滤波算法对未被检出的目标可能出现的区域进行预测,随后利用匈牙利算法对目标消失区域进行特征两两匹配,以实现前后帧目标关联,从而检测出未能被检出的被遮挡目标。
2.2 基于目标跟踪的被遮挡行人检测算法
为解决行人目标被遮挡问题,通过目标跟踪的方式对被遮挡的行人目标进行前后帧关联,整体检测结构如图2 所示。
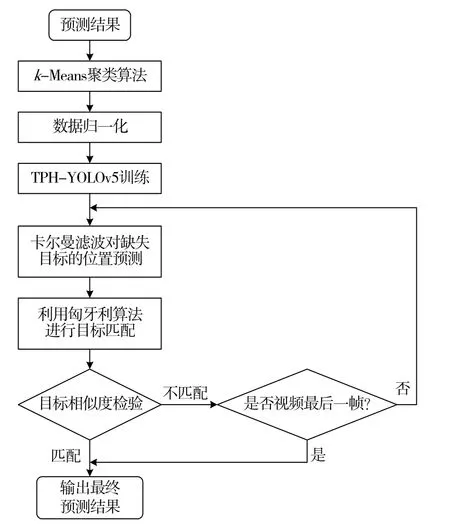
图2 基于跟踪关联的行人检测结构图
将数据集输入到模型中进行第一次训练,判断模型的预测结果在同视频的情况下是否存在目标缺失,若存在目标缺失的问题,则将全部的预测结果输入到针对被遮挡的行人检测模型中。模型通过卡尔曼滤波利用图像中行人目标的运动信息和外观信息得到关联矩阵,对第一次检测中存在目标缺失的区域进行位置预测,关联出感兴趣的区域,然后通过匈牙利算法进行预测匹配,通过比较完整行人目标与感兴趣区域的颜色特征、纹理特征以及轮廓特征,在该模型的感兴趣区域找出与完整目标部分特征相同的区域。当存在部分特征相同,则代表信息匹配,说明这是缺失的目标,因此能够检测出在第一次检测中未被检出的被遮挡的行人目标。此方法能够减小网络的搜索区域,在提高被遮挡行人检测的准确率的同时也能提高检测效率。
3 实验验证
3.1 实验建模
实验选择滴滴发布的D2-City 视频跟踪数据集为样本库,它是大规模行车视频数据集,涵盖不同的天气、道路、交通情况,视频均以高清或超高清分辨率录制。选取含遮挡行人的视频片段转换成视频帧,标签用labelimg 工具进行标注。数据集样本总量3744 张,并按6:2:2 的数量比例进行划分。
采用TPH-YOLOv5[10]作为基线网络模型。它是一种基于YOLOv5 网络的改进算法,在YOLOv5 的基础上,在Head 部分加入一个用于检测更小尺度物体的检测头。此处采用Transformer Prediction Head(TPH)替换YOLOv5 的预测头,提升了预测潜力。为了能大范围覆盖图像,此处采用注意力模块CBAM生成注意力图,提高对一些易混淆类别的分辨能力。
评价指标选用平均精度AP、召回率R、平均对数漏检率。其中,召回率R 指的是在所有正样本中,TP 所占比例,即:
平均对数漏检率LAMR 是衡量模型漏检的指标,定义为:
LAMR 越大,模型的漏检率越高,性能也就越好。同样,平均精确率AP 值越高,模型的检测效果也越好。
3.2 实验结果与分析
实验所得到的数据如表1 所示。包括常规AP、召回率R、LAMR 以及AP(遮挡行人)四个指标,再分不同情况进行分析。
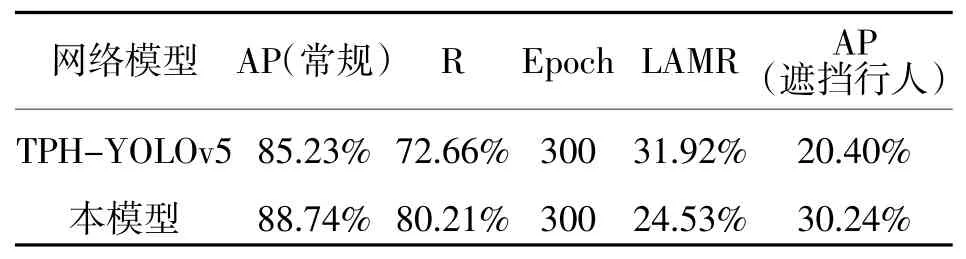
表1 对比实验结果
1)光线不足(过暗)的情况
在光线过暗场景且行人服装颜色几乎与背景融为一体的情况下,本模型的检测准确率较原模型有所提高。主要是在将目标跟踪的关联方式引入模型后,相当于在原模型中加入了一个“注意力机制”,预测被遮挡的目标可能出现的位置,以减小模型的搜索范围,同时提高模型的检测效率和对行人特征的识别度。检测效果的实际对比如图3 所示。

图3 光线不足情况下的实验效果对比
从图3 可以看出,在光线不足时,由于行人所穿衣服以黑色居多,与昏暗背景环境几乎融合,因此导致原模型只检测出了两个行人,而本模型检测出了四个,其中包括一个被严重遮挡的行人目标。
2)遮挡面积较大的情况
影响模型检测准确度的因素有很多,遮挡面积也是重要影响因素之一。本模型通过在制作数据集时选取大量部分被遮挡的行人样本来使网络对其进行学习,同时通过对被露出的特征进行匹配,以期解决对被遮挡的行人目标检测准确度较低甚至漏检的问题。从数据集中选取行人被严重遮挡的图片进行检测检测。检测效果的实际对比图4 所示。

图4 遮挡范围较大情况下的实验效果对比
表1 数据表明,本算法的LAMR 相比原模型降低了7.39%,被遮挡行人的AP 值也提高了9.84%。行人的漏检情况得到了很大的改善。
图4中行人被栅栏的遮挡面积很大,只露出了约20%,且由于书包颜色与栅栏在颜色上很相似,模型很难识别。对此,原网络只检测到了2 个行人,而本模型检测出了3 个行人,其一被严重遮挡,也被检测出来。
4 结 束 语
本研究提出的基于目标跟踪的前后帧关联的行人检测算法模型在对网络预测结果进行目标关联的情况下,被遮挡的行人目标检测准确率获得了极大的提升,即使在同样只检测出一个行人目标的情况下,本算法模型的置信度也要高于原模型的表现,表明基于目标跟踪的行人检测算法在被遮挡行人目标的检测准确度上有实质性的改善。
