面向自动驾驶测试的危险变道场景泛化生成
2023-10-30赵祥模赵玉钰景首才刘建蓓
赵祥模 赵玉钰 景首才,2 惠 飞 刘建蓓
目前,自动驾驶汽车正在由测试示范逐步迈入量产商用阶段的过程中[1],保证自动驾驶在实际交通环境中安全运行是商用上路许可的关键[2].自动驾驶上路前需经过数十亿英里的安全性测试[3],由于传统的道路、场地测试受测试效率、成本、场景等的限制,已经难以满足自动驾驶汽车测试的需求[4].Riedmaier 等[5]和 Sun 等[6]分别分析了各类基于场景的自动驾驶汽车安全评估的方法,其中虚拟仿真测试方法利用数字虚拟仿真技术模拟真实的测试场景[7],可以为自动驾驶测试提供丰富多样的测试场景,在测试效率、成本方面具有显著的优势,已成为一种重要的自动驾驶测试验证手段[8].
在虚拟仿真测试中,场景是对真实交通运行过程中人、车、路和环境的抽象描述.ISO 21448 标准中 SOTIF 从功能安全的角度将自动驾驶场景分为已知安全场景、已知危险场景、未知安全场景和未知危险场景[9].现实中安全关键场景和罕见风险事件覆盖率较低[10],为了实现自动驾驶的全方位测试,希望能够通过虚拟仿真技术,利用有效的场景生成方法,生成危险场景,发现被测系统的未知危险场景,明晰自动驾驶系统安全场景边界,提高自动驾驶的安全性.
邓伟文等[11]系统性地综述了自动驾驶的仿真场景自动生成方法.现有场景生成方法可分为数据驱动、模型驱动和数据-模型驱动 3 类.在数据驱动的危险变道场景生成方面,陈吉清等[12]基于车辆事故数据,提出一种考虑危险事故特征的测试场景构建方法,建立了 15 个涉及道路几何特征的自动驾驶测试场景.王润民等[13]系统地阐述了测试场景、场景要素、基元场景之间耦合的逻辑关系.朱冰等[14]提出一种多维逻辑场景的自动驾驶安全性评价聚类方法,并以前车紧急制动场景验证了聚类方法的可行性.基于模型驱动的场景生成方法方面,Menzel等[15]提出一种基于本体论的高速公路场景建模方法,构建了包含道路层次、交通基础设施、临时操作、对象和环境的 5 层次知识表示模型,用类、逻辑公理和语义 Web 规则实现了对德国高速公路的建模.Jesenski 等[16]提出了一个可以描述任意道路配置场景的通用模型,考虑相关车道路段的车辆之间相互作用,设计一个层次采用分析框架,利用公开数据集拟合了模型参数,并推断出交通场景.基于数据-模型驱动的危险场景生成方法方面,Ding 等[17]提出一种自适应安全关键场景生成方法,将场景分解为条件概率,将概率称作构建块,用一系列自回归构建块来表示交通场景,利用策略梯度强化学习方法对风险场景参数进行搜索优化.
相邻车道前方车辆变道切入是常见的高风险场景,也是各类生成方法研究的主要目标场景.目前,危险变道场景生成主要基于数据-模型驱动的方法.Feng 等[18-20]提出了一种智能网联汽车测试场景库生成统一框架,并采用多启动优化方法获得局部关键场景,利用两车纵向距离、相对速度以及碰撞时间等参数,生成了变道场景.周文帅等[21]利用 highD数据集,建立了车辆变道切入描述模型,提出了基于蒙特卡罗的测试用例生成方法.上述方法仅仅考虑变道场景中两车关系的特征参数,无法精确描述人驾车辆变道切入的运动状态,难以构建动态测试场景.Sun 等[22]提出了一种评估自动驾驶安全性的自适应实验设计方法,智能驾驶员模型和三阶贝塞尔曲线被用来描述背景车辆变道切入轨迹.基于确定模型的轨迹生成方法计算简单,但生成轨迹数量有限,并且难以生成符合驾驶员特征的紧急变道轨迹.朱宇等[23]构建两车轨迹约束关系模型,以变道轨迹起始位置、变道车速度、两车距离、两车相对速度、变道切入时刻为参数,利用蒙特卡罗方法模拟车辆采样时间的车辆位置,最终形成了变道轨迹.但这种方法利用相对位置作为参数,同一场景状态下生成的变道轨迹切入点是相同的,这并没有增加生成变道轨迹的风险程度,只是增加了变道切入轨迹的数量.
现有变道场景生成方法通过优化变道场景参数或生成背景车辆运动轨迹来构建危险测试场景,但是为了满足自动驾驶高风险场景测试的需求,面向自动驾驶决策规划控制系统测试,构建动态危险变道测试场景,还需要解决的问题包括:1)如何生成符合人驾车辆特征的不同切入角度的风险变道轨迹? 生成变道轨迹需要满足真实环境中的车辆动力学约束,并接近真实驾驶人操纵下的车辆轨迹特征,但又要在同一初始状态下生成不同切入角度的变道轨迹,增加生成变道场景覆盖度;2)如何利用不同风险的背景车变道轨迹构建可从理论上避免的风险临界测试场景? 为了避免产生不切实际的危险场景,需要根据车辆动力学和物理极限,构建安全边界模型,结合背景车不同切入角度,生成理论上可避免的风险临界测试场景.
因此,本文针对自动驾驶虚拟测试动态危险变道场景生成问题,提出一种基于数据-模型驱动的自动驾驶测试危险场景泛化生成方法.基于 NGSIM US101 数据集中的紧急变道数据,提出一种考虑人驾车辆特征的紧急变道轨迹对抗生成方法(Batch normalization-attention mechanism-sequence generative adversarial nets with policy gradient,BN-AM-SeqGAN),构建基于安全距离的两车变道状态约束模型,计算风险临界场景下的被测自动驾驶车辆初始状态,提出危险场景泛化生成算法,生成危险变道测试用例,形成变道危险测试场景库.
1 变道场景数据
本文使用美国 NGSIM US101 DATA 公开数据集,该数据集收集了如图1 所示高速公路车辆的行驶数据,该路段由 5 个主线车道和 1 个辅助车道组成.记录了以 0.1 s 为时间周期的车辆位置、车辆长度、瞬时速度、瞬时加速度、车道编号等信息,前期团队研究了变道行为识别方法,已经从数据集中识别出 1 740 条变道行为[24],根据文献[25]对紧急变道工况持续时间的统计分布研究,紧急变道行为指变道车辆从变道开始到变道完成所需时间小于 2 s,因此,本文在前期研究形成的变道轨迹数据集的基础上,筛选出了变道时间小于 2 s 的变道轨迹数据,形成了由 511 条紧急变道轨迹构成的数据集,并把变道起始位置点坐标进行归零处理.选取一条紧急变道轨迹,其位置、速度和加速度轨迹如图2 所示,绿色虚线间的数据表示选取的紧急变道数据.在提取到的紧急变道轨迹数据集中,变道完成时间在1.4 s 到 2 s 之间的场景占所有场景的 70%.本文提取的真实变道轨迹数据的平均值、最大最小值、方差、标准差如表1 所示.

表1 真实数据的数据特征Table 1 Data characteristics of real data
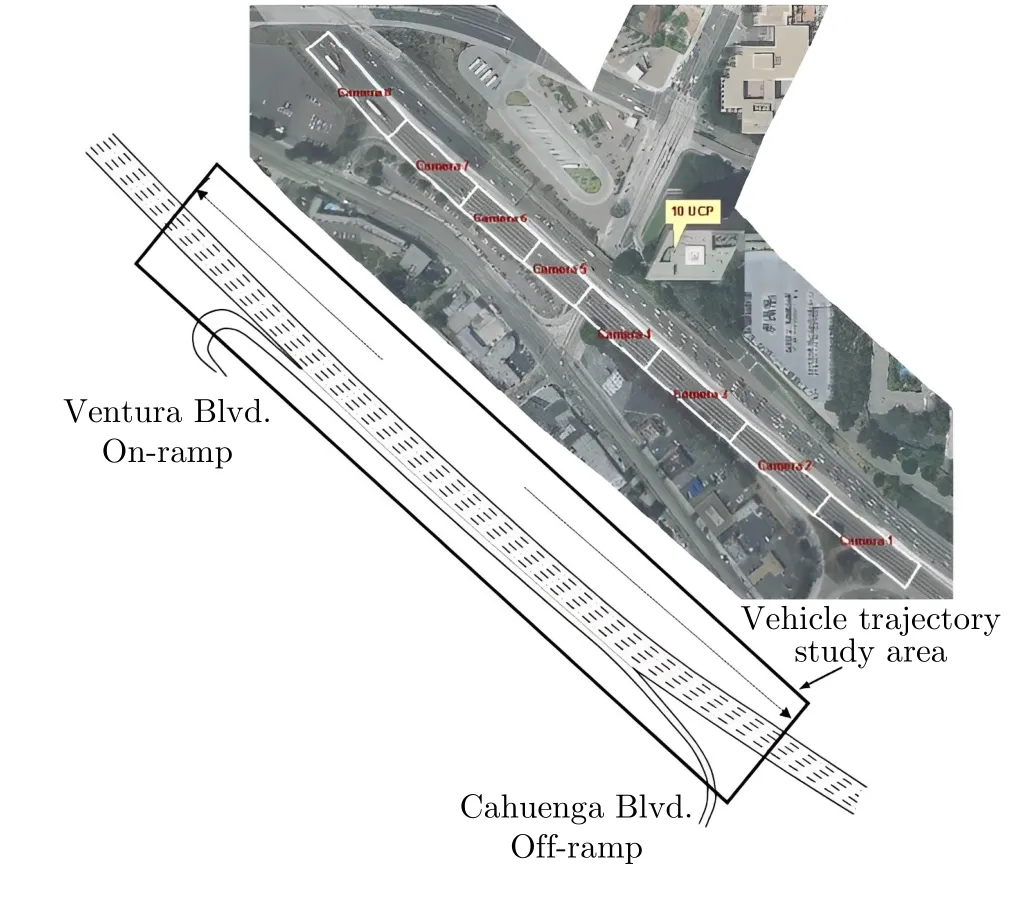
图1 数据采集区域Fig.1 Data acquisition area
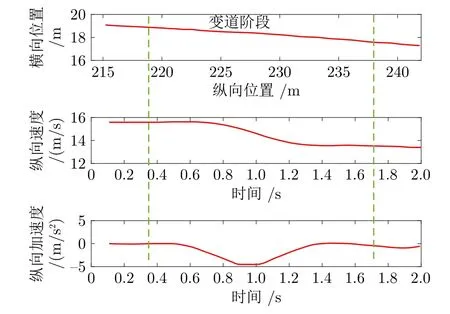
图2 变道数据速度、加速度分析Fig.2 Speed and acceleration analysis of lane-changing data
紧急变道轨迹数据集中变道背景车的速度均值和标准差分别如图3 和图4 所示.其中变道背景车平均速度取值范围为 1 m/s~23 m/s,91% 的变道背景车平均速度的标准差均低于 0.4 m/s.
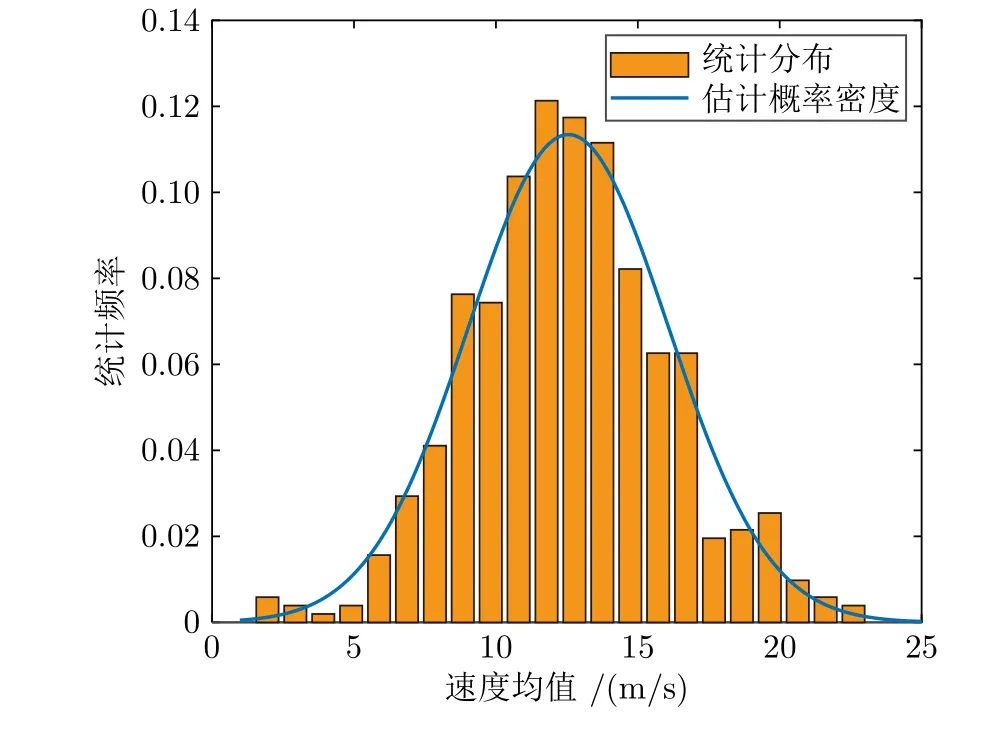
图3 真实数据纵向速度分布Fig.3 Longitudinal speed distribution of real data
2 基于 BN-AM-SeqGAN 的紧急变道轨迹生成方法
变道轨迹数据是一系列离散的序列数据,序列生成对抗网络 (SeqGAN)可以有效学习序列数据特征,生成高相似度的序列数据[26],因此,本节提出一种基于 SeqGAN 网络的变道轨迹生成方法.
本文对变道轨迹坐标进行了归一化处理,横向方向的位置变化和纵向方向的速度变化最能表征变道轨迹特征,并且纵向速度是位置关于时间的导数,因此在生成数据时考虑变道车在x轴方向上的速度vx和y轴方向的位置y.真实紧急变道车辆状态轨迹可以表示为集合L={L1,···,Li,···,L511},其中第i条变道状态轨迹,N表示变道轨迹的序列长度,本文设置为 20,Li∈L,表示变道的横向位置和纵向速度.
2.1 SeqGAN 的背景介绍
SeqGAN 是一种由θ参数化的生成器Gθ和φ参数化的判别器Dφ两部分组成[27]的序列生成对抗网络.生成器Gθ学习真实序列数据的数据特征,并合成新的序列数据样本;判别器Dφ对输入的数据进行分类,判别输入数据是真实数据还是生成数据,两个模块进行博弈直到达到平衡点[28],其结构图如图5 所示.判别器Dφ(图5 左侧)在真实数据和生成数据上进行训练,生成器Gθ(图5 右侧)通过策略梯度进行训练.训练过程中奖励信号由判别器提供,并通过蒙特卡罗搜索传递回中间值.生成器生成序列表示为,其中M表示生成轨迹的总数,生成的第m条轨迹表示为,,S是生成器可用候选数据.生成器生成第m条轨迹的状态,表示当前生成的序列,动作是下一个要选择的数据.
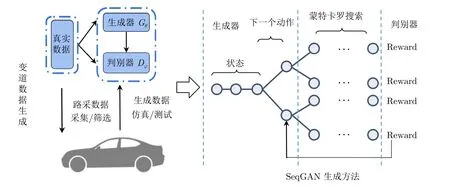
图5 SeqGAN 的结构图Fig.5 Structure diagram of SeqGAN
生成器Gθ的目标是从当前状态zn-1生成一个序列,以最大化其预期的结束奖励J(θ),判别器为蒙特卡罗搜索补全的完整序列提供奖励值,迭代更新生成器.预期的结束奖励如式 (1)所示.
其中RN是判别器对一个完整序列的奖励,zn-1表示当前状态,θ表示生成器的策略,是一个序列的动作值函数,即从状态zn-1开始,采取行动,然后遵循策略Gθ计算预期累积奖励.
SeqGAN 以长短时记忆网络 (Long short-term memory,LSTM)作为生成器,卷积神经网络 (Convolutional neural network,CNN)作为判别器.生成器基于策略梯度方法针对判别器获得新的奖励J(θ)对参数θ进行优化,以直接最大化长期回报.SeqGAN对第m条序列的训练模型如式 (2)所示,其中,pdata和分别表示真实样本序列数据的概率分布和生成样本序列数据的概率分布,I表示生成器和判别器的收益.
2.2 基于 BN-AM-SeqGAN 的轨迹生成方法
为了解决 SeqGAN 收敛速度慢、轨迹生成准确性低的问题,本文分别对 SeqGAN 的生成器和判别器进行优化,提出一种 BN-AM-SeqGAN 方法,其结构图如图6 所示.
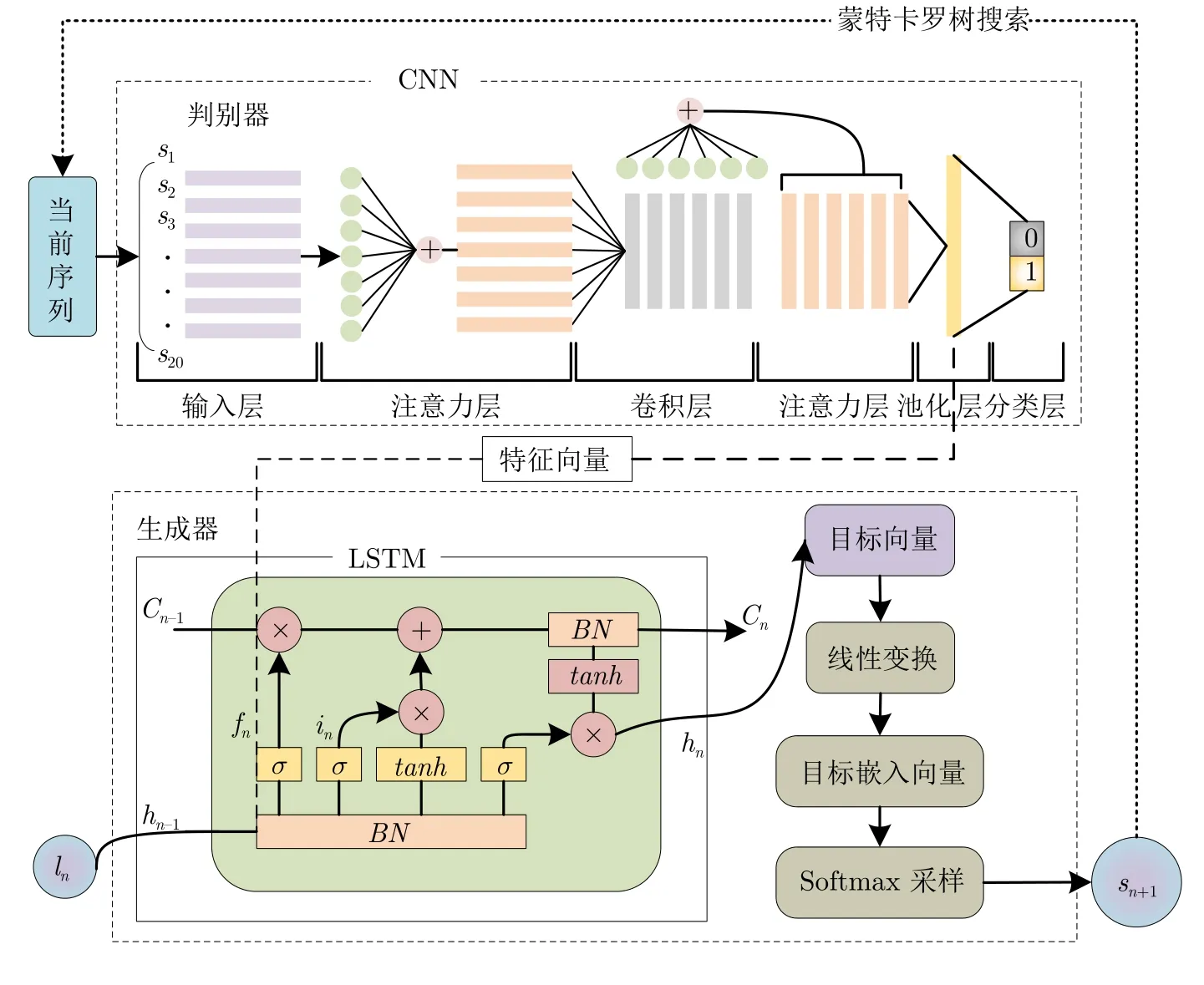
图6 BN-AM-SeqGAN 的结构图Fig.6 Structure diagram of BN-AM-SeqGAN
生成器部分展示了对 LSTM 的改进,生成器中真实数据ln输入到批标准化(Batch normalization,BN)后的 LSTM 网络中,σ表示sigmoid 激活函数,tanh表示激活函数,c表示细胞状态,BN(·)表示批标准化操作,hn表示隐藏层的信息.判别器在 CNN 的卷积层前后分别加入了注意力机制.BNAM-SeqGAN 的算法步骤见算法 1.
算法 1.BN-AM-SeqGAN
2.3 BN-AM-SeqGAN 生成器优化
原始 SeqGAN 的生成器的 LSTM 网络由输入门、遗忘门、输出门构成,在 LSTM 网络训练的过程中存在损失放大的问题,从而造成生成数据不准确,批标准化可以降低损失放大的程度.本文在生成器的 LSTM 网络引入了批标准化操作,优化后的生成器可以有效地降低后面几层的损失.批标准化包含平移参数和放缩参数,通过修改参数的值可以控制归一化之后的范围,批标准化具体过程如算法 2 所述.
算法 2.批标准化 BN
优化的生成器对每个激活函数的输入数据进行批标准化运算,LSTM 网络经过优化可以维持输入数据分布的稳定性,方便网络的训练,使生成模型更快收敛.假设当前的输入是,优化后的生成器模型中遗忘门fn可以表示为:
其中Wf表示遗忘权重,hn-1表示前一层的隐藏状态,表示当前输入的内容,bf表示遗忘门偏置项.输入门由两个模块组成,一个模块将筛选的数据信息保存到记忆细胞中,如式(4)所示:
其中Wi表示输入权重,bi表示输入偏置项.另一个模块把当前时刻传递的数据信息保存到记忆细胞中,如式(5)所示:
其中Wc和bc分别表示记忆细胞权重和记忆细胞偏置项,tanh表示激活函数.新的记忆细胞cn由遗忘门fn和输入门in更新,如式(6)所示:
输出门On计算需要输出的信息,传递隐藏状态hn,如式(7)和式(8)所示:
其中Wo和bo分别表示输出门权重和记忆细胞偏置项,hn-1表示上一时刻的隐藏状态.最后使用softmax函数将隐藏状态hn转换为概率分布,用来生成近似真实数据的轨迹数据.
生成器通过蒙特卡罗树搜索将生成的部分序列数据补充完整,判别器对完整的序列数据进行评估进而优化生成器中的参数,当前隐藏状态遗忘权重hn继续执行 LSTM 网络.
2.4 BN-AM-SeqGAN 判别器优化
原始的 SeqGAN 判别器的特征提取层是一个CNN,包括输入层、卷积层、池化层,引入了注意力机制,在特征提取层的卷积层前后加入了注意力层,保证数据在可控范围内变动,提高 CNN 提取高维特征向量的准确性,改善序列生成的质量.
将序列数据注入到判别器后,由第一个注意力层利用自注意力机制对传入序列的特征加以鉴别和整合,放缩参数为H=32,传入序列数据的长度为N=20,传入的序列数据将被表示为N×H的矩阵,注意力层对矩阵进行处理之后,矩阵大小仍然为N×H.
卷积层主要利用卷积核在注意力层处理后的矩阵上做点积运算,提取真实数据的数值特征,以便计算生成数据与真实数据的差异.
第二个注意力层的操作是利用放缩参数大小为m=64 的自注意力机制处理所有卷积核,自注意力机制可用式 (9)表示.
式中Q表示当前 Query 的矩阵,K表示 Key 的矩阵,V表示 Value 的矩阵,其中Q=K=V,Q取值为数据的概率分布矩阵.当输入一个变道轨迹坐标序列,里面的每个坐标点需要和序列中的所有坐标点进行注意力权重参数计算,然后把权重参数乘以对应的词输出结果.这样做的目的是可以学习到坐标序列内部坐标点之间的依赖关系,获得序列的结构信息.
池化层和分类层分别对特征向量进行降维、关键特征提取和分类,最后将得到的结果传递给生成器以优化生成器的参数.
2.5 损失函数
对于生成器来说,预训练和对抗训练过程中使用的损失函数是不一样的,在预训练过程中,生成器使用的是交叉熵损失函数,而在对抗训练过程中,使用的则是策略梯度中的损失函数,即对数损失乘以奖励值,可用式 (10)表示.
判别器在预训练和对抗训练过程中的损失函数是一样的,使用交叉熵作为分类和预测任务的目标函数,使用对数损失函数来训练判别器,损失函数fφ可用式 (11)表示:
其中pdata表示真实样本序列数据的概率分布.
本文使用原始数据作为评估度量,使用最小平均负对数似然作为生成序列的损失值,如式 (12)所示,在生成数据实验中NLL值越小说明生成效果越好.
3 基于碰撞约束的场景泛化生成方法
3.1 基于碰撞约束的被测自动驾驶车辆初始状态生成
在背景车辆紧急变道轨迹生成之后,为了构建危险测试场景,需要生成被测自动驾驶车辆在场景初始时刻的状态.本文利用背景变道车辆和被测车辆间的运动安全约束,推算了危险临界场景下被测自动驾驶车辆在场景初始时刻的状态,构建了危险测试场景.被测自动驾驶车辆与变道背景车不发生碰撞的临界条件是指当变道背景车完成变道时,被测自动驾驶车辆经过一定的制动恰好与变道背景车辆保持相同速度,并且保持最小距离.
人驾背景车辆的制动阶段分为 3 个部分,t1制动反应时间的匀速运动阶段、t2时间段的变减速运动阶段和t3时间段的匀减速运动阶段.被测自动驾驶车辆与人驾背景车辆相比,t1制动反应时间很小,可以忽略不计[29],整个制动过程的时间为t,与变道背景车完成变道的时间相等,因此,本文考虑的制动时间t由t2和t3两部分组成.
被测自动驾驶车辆制动过程与变道背景车辆的相对距离与相对速度的变化可由式 (13)~式 (16)表示,其中v表示被测自动驾驶车辆与变道背景车的纵向相对速度,amax表示被测自动驾驶车辆制动时的最大加速度,d1表示被测自动驾驶车辆相对变道背景车在纵向上行驶的距离,vc表示变减速结束之后被测自动驾驶车辆的速度,变减速阶段被测自动驾驶车辆行驶的相对距离[29]可用式 (13)表示,在计算时由于t2很小,可以只考虑前一项.匀减速完成后相对速度减为 0,匀减速阶段被测自动驾驶车辆行驶的相对距离可用式 (15)表示.
典型危险变道测试场景如图7 所示,其中dmin是最小安全距离,dh表示被测自动驾驶车辆行驶的距离,dt表示变道背景车行驶的距离,vav表示被测自动驾驶车辆的初始速度,vhv表示变道背景车的速度,l表示车长.被测自动驾驶车辆以最大减速度紧急制动,变道背景车完成变道的同时被测车辆完成制动,两车相对静止 (不发生碰撞的临界条件),被测车车头接近前车车尾,制动过程中存在如下公式.
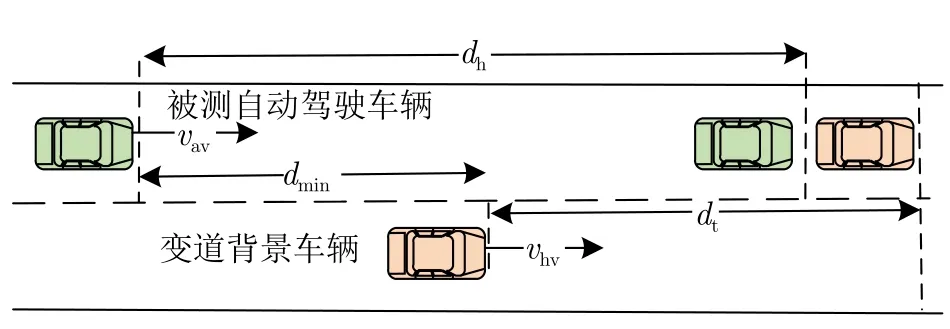
图7 被测自动驾驶车辆和变道背景车行驶状态Fig.7 Driving status of the tested automated vehicle and lane-changing background vehicle
结合式 (13)~式(17)可以求出最小安全距离dmin和被测自动驾驶车辆初始速度vav如下:
根据《公路工程技术标准》[30]给出的车辆安全行驶时的横向安全距离计算式如下:
其中,dL是被测自动驾驶车辆与变道背景车的初始横向距离.本文将变道背景车的初始位置进行了归一化处理,因此被测车纵向位置表示为xav=-dmin,横向位置表示为yav=dL,从而得到被测车的初始状态(xav;yav;vav).
3.2 危险变道测试场景泛化生成方法
为了能大规模生成危险变道测试场景,本节在被测自动驾驶车辆初始状态生成方法的基础上,介绍危险变道测试场景泛化生成.
首先对NGSIM US101 Data 数据集中的变道轨迹进行预处理,筛选出紧急变道轨迹,并将每条变道轨迹的起始点坐标进行归一化处理,再利用算法 1 生成并筛选新的变道轨迹,在碰撞约束条件下计算每条变道轨迹对应的被测自动驾驶车辆的初始状态,在第 1 节中介绍了变道场景数据的特征,因此本文采用生成变道背景车辆的平均速度计算被测自动驾驶车辆初始状态.变道数据与对应的被测车初始状态构成危险变道测试场景.具体危险变道测试场景泛化生成方法如算法 3 所示.其中,被测车初始状态集其中第m条变道轨迹对应的被测车初始状态表示生成的第m条变道轨迹,危险变道测试场景表示为
算法 3.危险变道场景泛化生成方法
4 实验和结果
本文基于真实的变道数据集来生成紧急变道轨迹数据,结合变道约束生成被测自动驾驶车辆初始状态,将两车合并生成危险变道测试场景,实现危险变道测试场景的泛化生成.
4.1 实验环境
本文所用的硬件设备为:Windows10 64 位操作系统,显卡为 Nvidia Quadro K2200,处理器为英特尔至强 E5-2 623,内存为 12 GB;软件设备为:编程语言 python3.6,深度学习框架为 Tensor-Flow1.9.0,用 Unity 创建仿真实验场景,运行环境为 pycharm2020.实验中用到的参数含义及其设置如表2 所示.
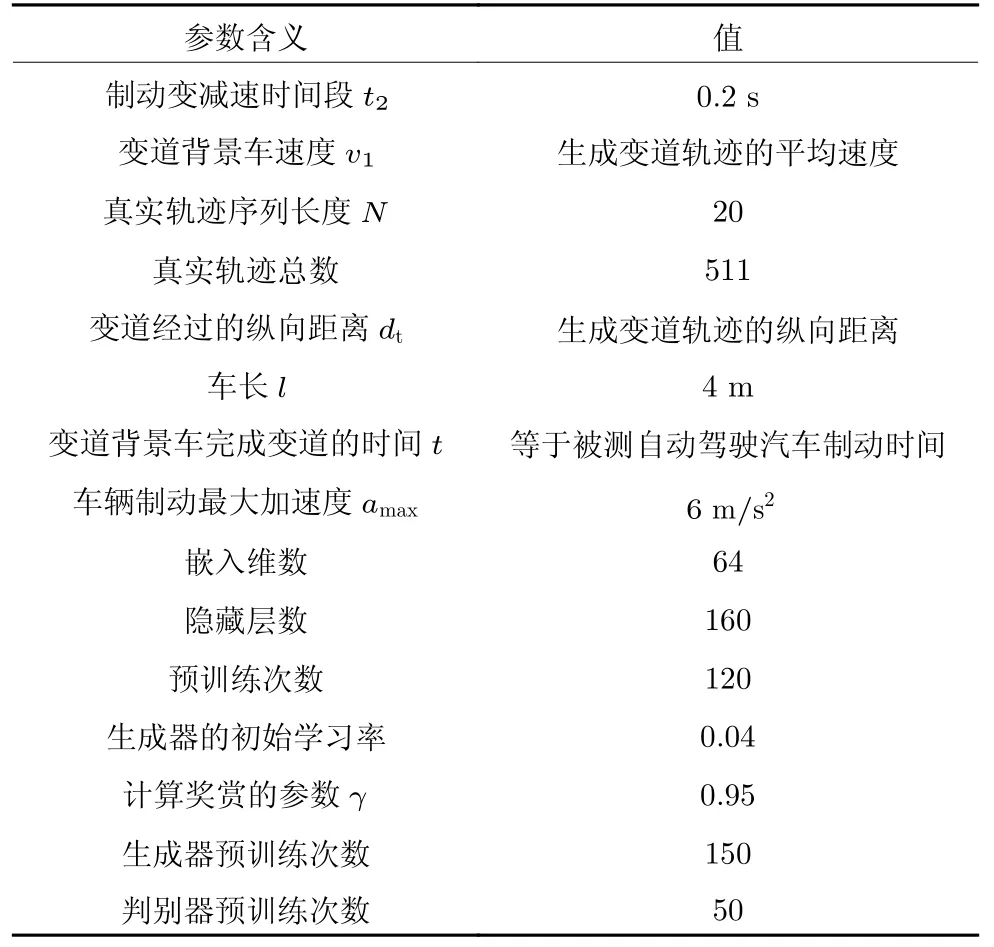
表2 实验中的参数设置Table 2 Parameter settings in the experiment
4.2 紧急变道轨迹生成
生成测试场景中变道背景车辆的运动轨迹与真实的变道轨迹的相似度越高,说明算法的生成准确性越好.因此本节从生成轨迹分布、变道完成时间分布、不同生成网络对比 3 个方面验证本文所提BN-AM-SeqGAN 算法生成轨迹的准确性.
真实紧急变道轨迹、真实轨迹分布的上界和下界以及生成的紧急变道轨迹如图8 所示,说明所生成的紧急变道轨迹符合真实轨迹的上下界分布.
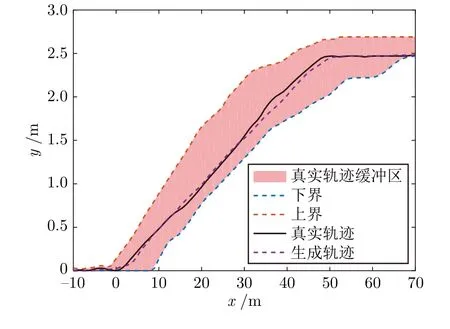
图8 变道车真实轨迹缓冲区实例Fig.8 Example of the real trajectory buffer of the lane-changing vehicle
为了验证生成变道轨迹的速度与真实变道轨迹速度的相似性,本文对比了真实变道轨迹与生成的变道轨迹变道开始时刻和变道结束时刻速度的状态分布,分别如图9 和图10 所示,其中生成的变道轨迹变道开始时刻的速度分布服从N(12.4208,3.5926)的正态分布,变道结束时刻的速度分布服从N(12.6903,3.6840)的正态分布.真实变道轨迹变道开始的速度分布服从N(12.1998,3.6887)的正态分布,变道结束的速度分布服从N(12.6799,3.7498)的正态分布.表明生成的速度概率密度符合真实速度概率密度的分布状态.
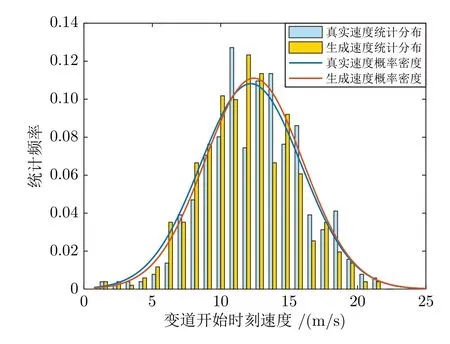
图9 变道开始时原始速度和生成速度的状态分布Fig.9 State distribution of original speed and generated speed at the beginning of lane-changing
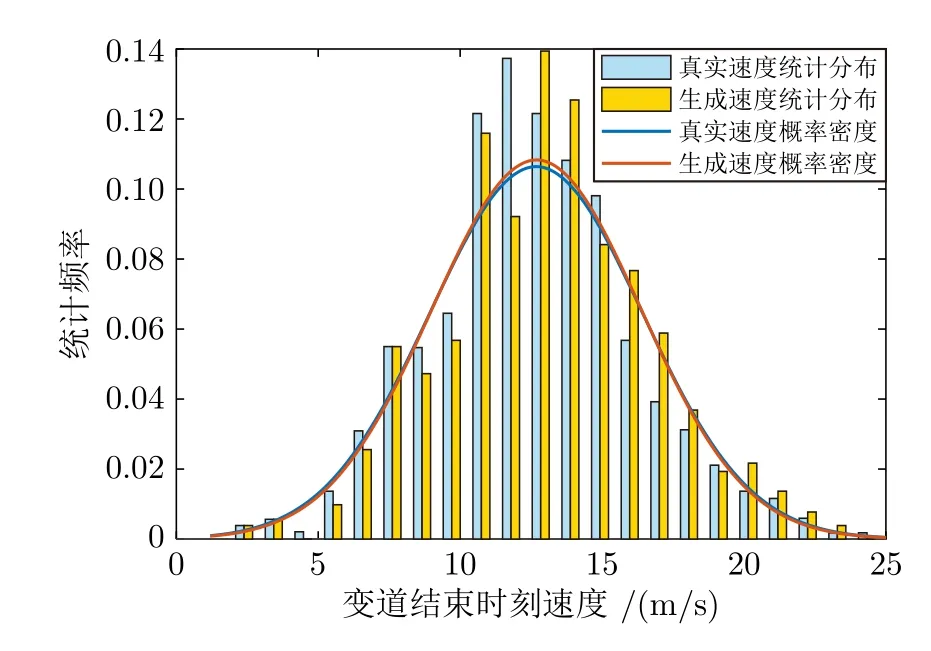
图10 变道结束时原始速度和生成速度的状态分布Fig.10 State distribution of original speed and generated speed at the end of lane-changing
本文对比了 BN-AM-SeqGAN 和 SeqGAN 生成的变道轨迹的变道完成时间与真实变道完成时间的百分比,生成的 511 条、50 000 条变道轨迹以及原始的 511 条变道轨迹的变道完成时间分布对比结果如表3 所示.
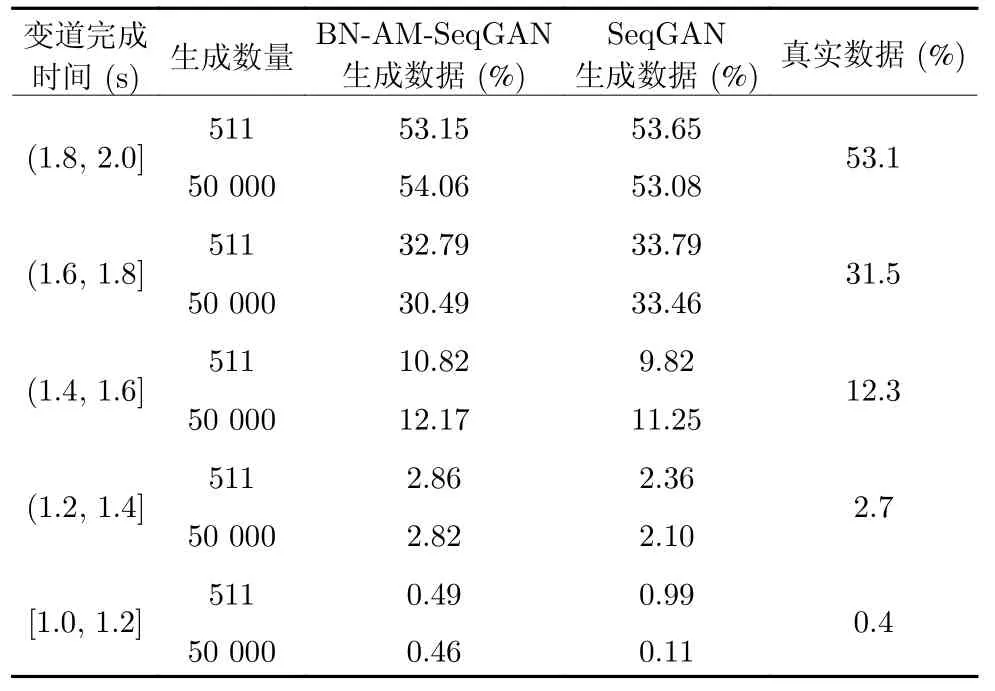
表3 变道完成时间分布表Table 3 Distribution of lane-changing completion time
BN-AM-SeqGAN 生成的变道轨迹分布更接近原始变道轨迹,与原始变道轨迹的变道完成时间分布相比,SeqGAN 生成的 511 条变道轨迹和 50 000条变道轨迹的变道完成时间分布均方根误差分别为1.56 和 1.04,BN-AM-SeqGAN 生成的 511 条变道轨迹和 50 000 条变道轨迹的变道完成时间分布均方根误差分别为 0.81 和 0.63,因此本文所提 BNAM-SeqGAN 的轨迹生成的准确性优于 SeqGAN,增加了生成轨迹与真实轨迹的近似程度.按变道完成时间进行分类,不同的变道完成时间表示不同的紧急程度,所有生成的变道轨迹都在 1 s~2 s 内完成变道,表明生成的轨迹是紧急变道轨迹.
为了进一步比较生成轨迹与真实轨迹的相似性,本文分别对比原始变道轨迹与生成变道轨迹的纵向速度及横向位置的均方根误差,如图11 所示,其中 91.36% 的横向位置均方根误差小于 0.5,81.12% 的纵向速度均方根误差小于 0.5,且最大均方根误差均不超过 2,表明生成变道轨迹与原始变道轨迹具有较高的相似性.
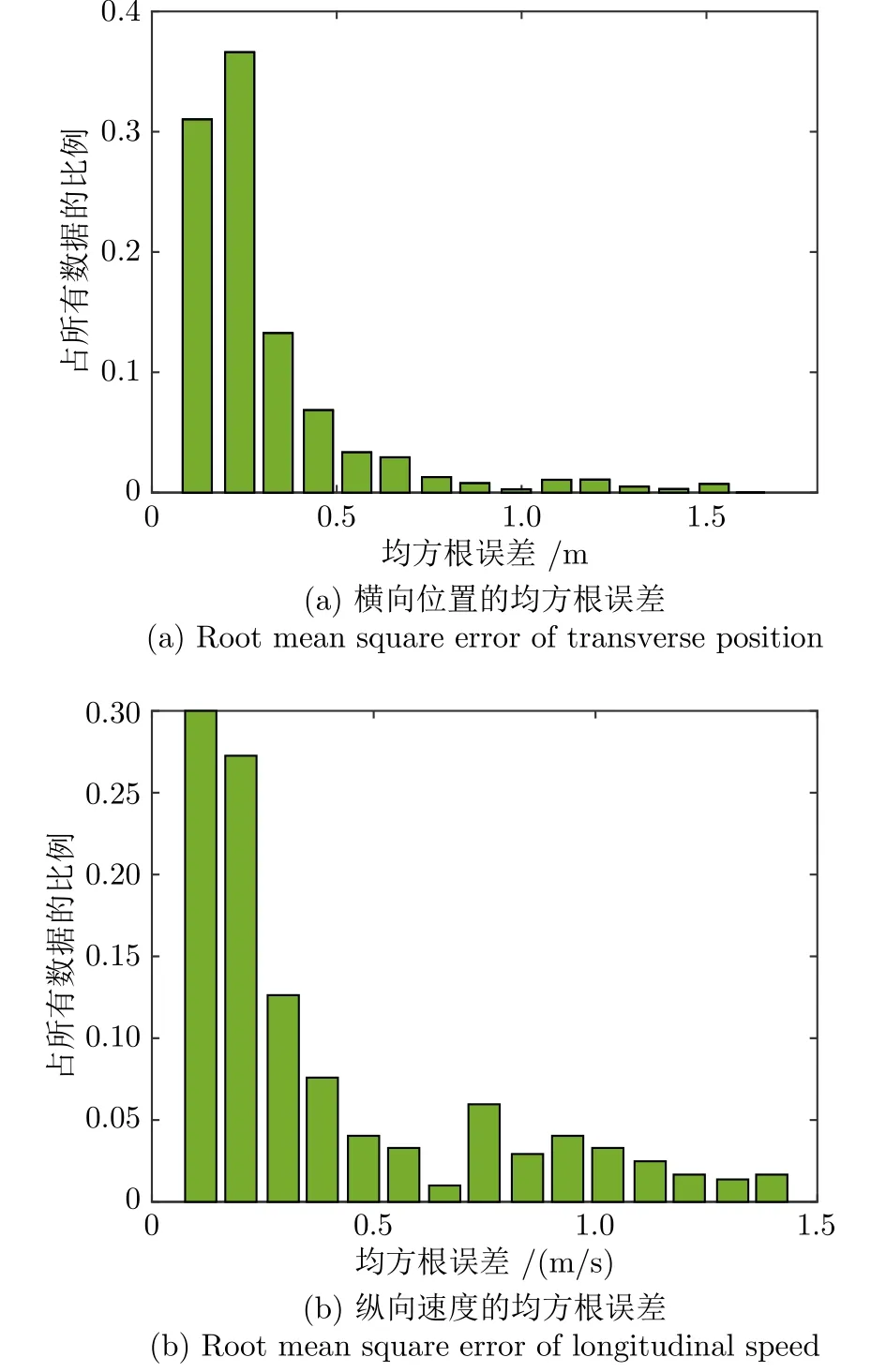
图11 位置和速度的均方根误差Fig.11 Root mean square error of position and speed
为了进一步说明本文所提 BN-AM-SeqGAN在轨迹生成方面的效果,将 BN-AM-SeqGAN 与RankGAN、SeqGAN 生成数据时的损失值进行了对比,结果如图12 所示,在生成对抗网络中损失值R 越低说明生成效果越好.BN-AM-SeqGAN 的损失值比其他两种网络都低,并且收敛速度快,说明BN-AM-SeqGAN 生成数据效果比 SeqGAN 和RankGAN 的效果好.
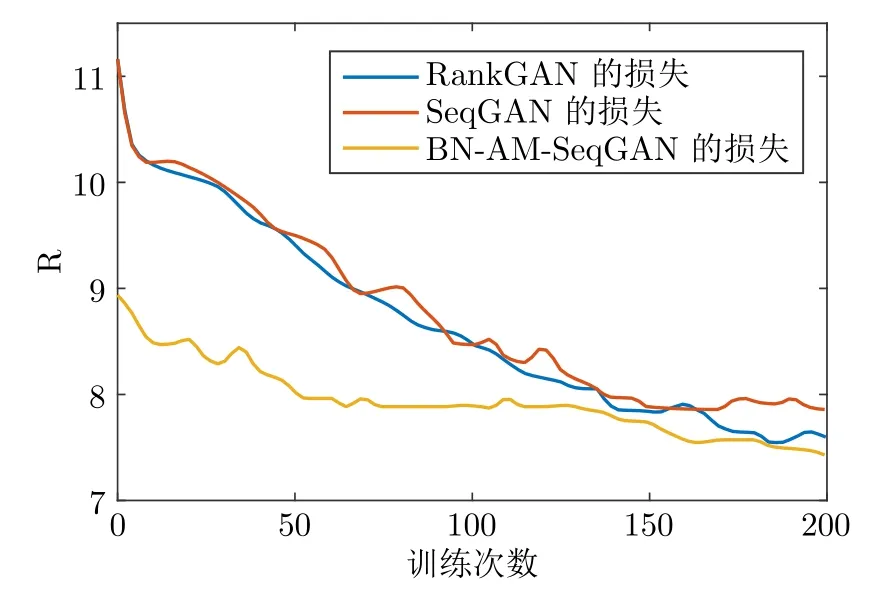
图12 三种生成对抗网络的损失值对比Fig.12 The comparison of loss values of three generative adversarial networks
为了说明所提出的网络在生成数据有效性方面的优势,本文对比了上述 3 种网络生成相同数量轨迹时符合紧急变道条件的轨迹数量,即生成变道完成时间小于 2 s,并且序列中相邻轨迹点没有较大跳跃的轨迹.BN-AM-SeqGAN 筛选 50 000 条符合要求的紧急变道轨迹需要生成 62 681 条序列.因此分别使用 SeqGAN、RankGAN 生成 62 681 条变道序列,利用相同的紧急变道条件筛选出 44 647、46 001 条符合要求的紧急变道轨迹,如表4 所示,由表4 可知,BN-AM-SeqGAN 生成数据的有效性最高.
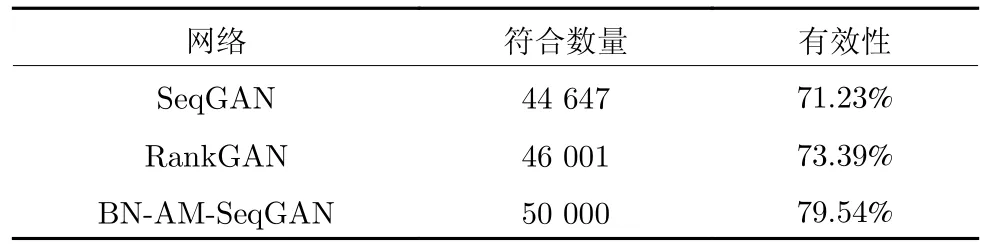
表4 网络输出效果对比Table 4 Comparison of network output effect
4.3 危险变道场景泛化生成
生成紧急变道轨迹之后,利用第 3.1 节所述碰撞约束条件计算被测自动驾驶车辆的初始状态,一条紧急变道轨迹对应一个被测车辆初始状态,构成一个危险变道测试用例,两车轨迹如图13 所示.对应的蓝色曲线表示变道背景车辆的轨迹,红色曲线表示被测自动驾驶车辆的轨迹,红色曲线的终点表示被测自动驾驶车辆按照最大制动减速度完成制动,达到与变道背景车辆相同的速度.此时两车保持最小安全距离,这时两车处于危险临界状态,这说明生成的变道测试场景属于危险变道场景.
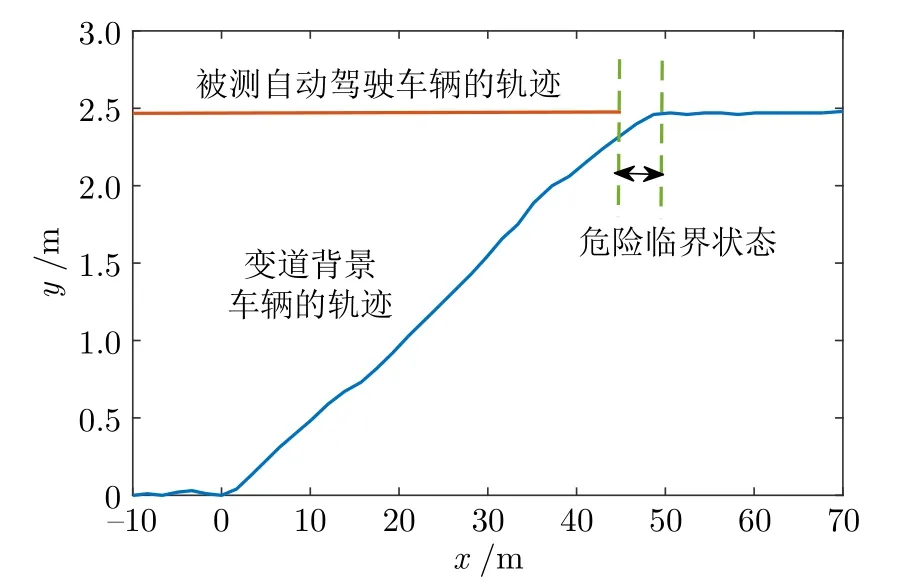
图13 危险变道测试场景Fig.13 Dangerous lane-changing test scenarios
为验证本文所提危险场景生成方法的有效性,将生成轨迹按照变道纵向速度划分成多个区间,在每个区间分别生成多条紧急变道轨迹,并按车辆以最大减速度减速的安全距离模型计算对应的被测自动驾驶车辆运动轨迹,构建不同速度的危险变道场景,选择 10 组典型的危险变道场景如图14 所示.背景车辆轨迹的变道切入角度不同,说明生成轨迹的多样性.两车轨迹保持临界安全距离,但不相交(同一颜色表示一个测试用例),表明生成的变道测试场景属于危险变道场景.
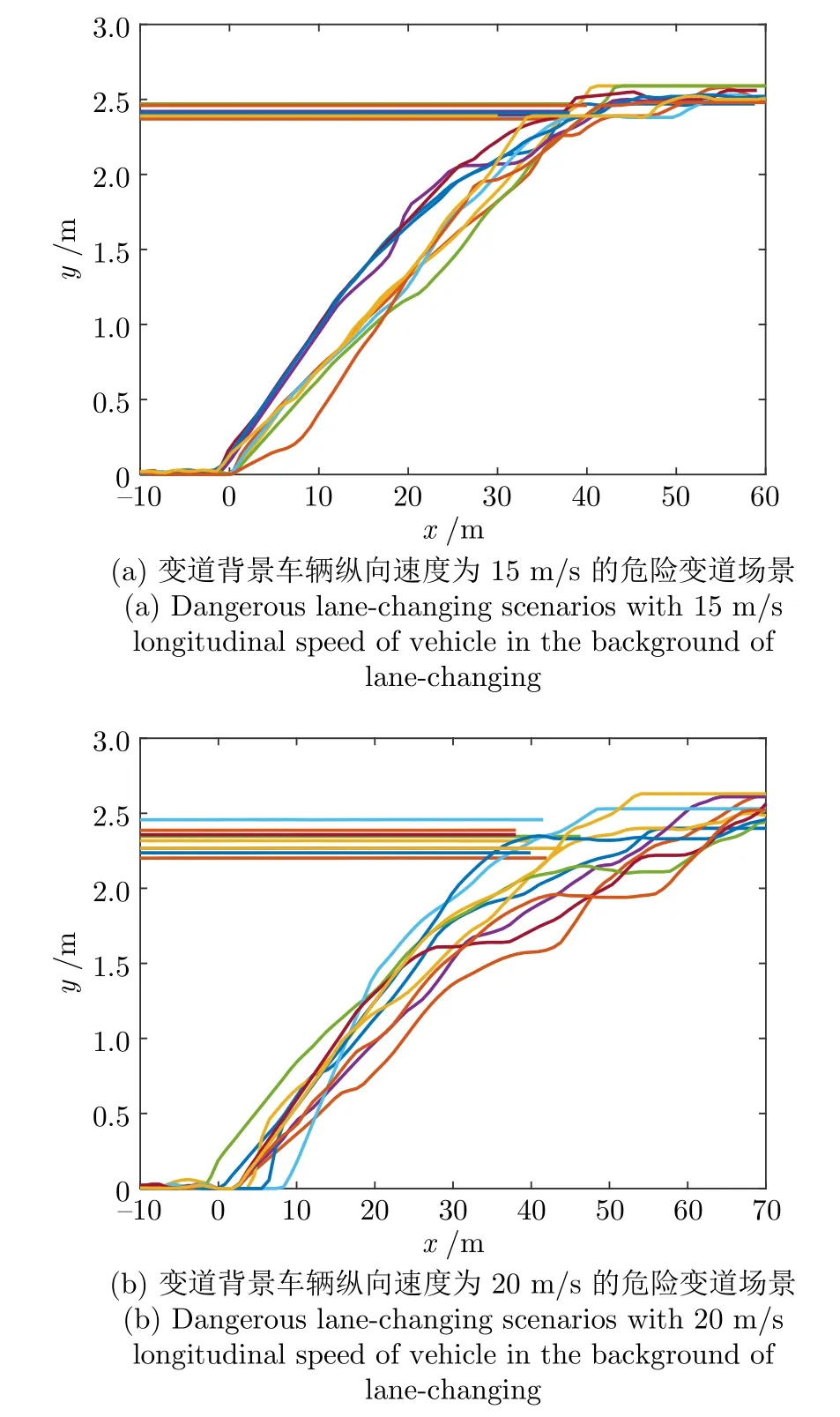
图14 不同变道车辆速度的变道场景Fig.14 Lane-changing scenarios of different lane-changing speeds
用本文提出的危险变道场景泛化生成方法生成5 万个危险变道场景构成危险变道测试场景库,并计算每个变道场景中被测自动驾驶车辆与变道背景车辆的碰撞时间 (TTC),计算结果如图15 所示.所生成的变道场景中,99.54% 的被测自动驾驶车辆与变道背景车辆的碰撞时间小于 1 s,生成场景中被测自动驾驶车辆与变道背景车辆的碰撞时间集中在 0.3 s~0.6 s 之间,均属于危险变道场景,表明本文所提方法能够有效生成自动驾驶测试危险变道场景.
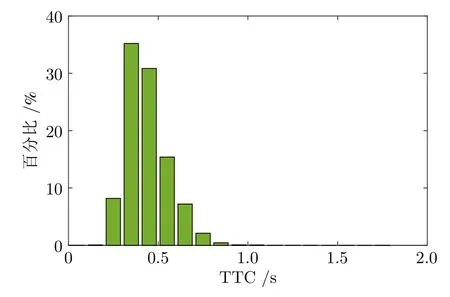
图15 危险变道测试场景库TTC 百分比Fig.15 TTC percentage of dangerous lane-changing scenarios library
4.4 危险变道生成场景验证
将生成的变道背景车辆和被测自动驾驶车辆运动轨迹导入 Unity 仿真平台,搭建了基于虚拟测试的危险变道生成场景,验证了变道切入场景生成算法的有效性.使用 Unity 中 Easyroad3D 插件建造好符合要求的道路,把生成的变道背景车辆的轨迹坐标和计算的被测自动驾驶汽车的轨迹坐标导入到数据库中,通过实时获取数据库中的车辆运动状态信息,构建了自动驾驶测试虚拟场景,效果如图16所示,其中,绿色车辆表示变道背景车辆,蓝色车辆表示被测自动驾驶车辆.被测自动驾驶车辆沿右侧车道直线行驶,背景车辆按照生成危险变道轨迹从左侧车道切入右侧车道,被测自动驾驶车辆按照最大减速度减速从而避免与变道背景车辆发生碰撞.当背景车辆完成变道时,两车达到不发生碰撞的临界状态.
5 结论
本文研究了面向自动驾驶测试的危险变道场景生成方法,基于公开数据集,利用批标准化优化生成器,引入注意力机制优化判别器,提出 BN-AMSeqGAN,结合变道安全约束,计算风险临界场景下的被测自动驾驶车辆初始状态,构建了危险变道测试场景,设计了场景泛化生成算法,形成了危险变道测试场景库.实验中,本文将 RankGAN、SeqGAN 和 BN-AM-SeqGAN 进行了对比,并使用碰撞时间评判所生成变道场景的危险程度.实验结果显示:本文所提方法生成的数据损失值低且收敛快,表明本文提出的方法效果更好;生成的 5 万条变道轨迹中,变道完成时间分布均方根误差为 0.63,表明所提方法能保证生成的紧急变道轨迹具有真实紧急变道轨迹的特征;生成的危险变道测试场景库中有 5 万条危险变道场景,其中 99.54% 的场景中被测自动驾驶车辆与变道背景车辆的碰撞时间小于 1 s,并且计算得到的碰撞时间集中在 0.3 s~0.6 s 之间,符合危险变道的定义,表明本文所提方法能够有效生成自动驾驶测试危险变道场景.
