融合注意力机制的增强受限玻尔兹曼机驱动的交互式分布估计算法
2023-10-30孙晓燕巩敦卫
暴 琳 孙晓燕 巩敦卫 张 勇
近年来,随着大数据、云计算等技术的迅猛发展,信息呈现爆炸式增长,给用户带来新资讯的同时,也增加了用户筛选有用信息并最终做出决策的难度.个性化搜索和推荐算法深度而准确挖掘用户潜在需求和兴趣偏好,向用户推荐其可能感兴趣且满足用户需求的项目,进而提供高质量的个性化服务[1-2].然而,互联网技术的发展以及互联网参与人数的激增,使得各类互联网应用中聚集了大量用户生成内容(User generated content,UGC),如:用户评分、商品类别标签、用户文本评论、社交网络信息、地理位置信息、图像或视频等各种各样的复杂数据,这些信息具有多源异构异质特性.在个性化搜索过程中充分利用多源异构UGC 数据,势必将在很大程度上提高个性化搜索和推荐的综合性能[3-4].其中,构建精确描述用户个性化偏好的用户兴趣模型是个性化搜索问题的关键.目前常用的构建用户兴趣模型的方法包括贝叶斯模型[5]、多层感知机[6]、自编码器[7]、受限玻尔兹曼机(Restricted Boltzmann machine,RBM)[8]、卷积神经网络(Convolutional neural network,CNN)[9]等.Kim 等[9]整合了CNN 和概率矩阵分解,提出了卷积矩阵分解(Convolutional matrix factorization,ConvMF)模型.Jin 等[10]通过元路径引导邻域捕获节点间的交互模式,提出了高效的端到端基于邻域的交互模型,用于基于异构信息网络的推荐.这些方法的成功应用展示了综合考虑多源异构信息对于提高推荐系统和个性化搜索性能是十分有利的.另外,受到人类视觉机理的启发,基于注意力机制(Attention mechanism,AM)的神经网络已成功应用于图像处理、自然语言理解、语音识别、模式生成等领域[11-12].融合AM 的神经网络充分利用特征及其重要性程度,使得神经网络在处理数据时加强重要特征,有利于更有效地进行特征提取.Zhou 等[12]提出了基于AM 用户行为模型处理推荐问题.汤文兵等[13]提出了基于注意力机制的协同卷积动态推荐网络,捕捉高阶特征交互.Li 等[14]提出了基于时间间隔感知的自注意力序列推荐算法.这些方法证明了融合AM神经网络的有效性,加强了重要特征对应用领域的贡献.然而,现有大部分研究工作均假设所有数据已知且充足,模型训练复杂度较大,且考虑的数据类型较单一,面对高稀疏性数据时通常表现不佳,同时,未考虑用户兴趣偏好的动态变化特性,模型难以随新增UGC 及时更新,不适用于实际应用场景中个性化搜索.
个性化搜索本质上是一类复杂的定性指标优化问题,也是目前人工智能领域亟待解决的难题.用户参与进化搜索的交互式进化计算(Interactive evolutionary computations,IECs)能够有效利用用户对优化问题的主观评价和决策,将人类智能评价信息与传统进化优化算法相结合,是处理个性化搜索这类复杂定性指标优化问题的可行途径[15-17].Sun 等[15]考虑区间适应值的不确定性,提出了基于代理模型的交互式遗传算法(Interactive genetic algorithm,IGA),处理复杂设计问题.Chen 等[17]利用基于语言模型的编码,结合基于Dirichlet 多项式复合分布的用户偏好表示和贝叶斯推理机制,提出了改进IEDA 算法.Bao 等[8]充分挖掘用户隐式偏好信息,构建基于RBM 的用户偏好模型,提出了RBM 模型驱动的交互式分布估计算法(Interactive estimation of distribution algorithms,IEDA).
这些方法从构建用户偏好代理模型设计进化优化策略的角度处理个性化搜索问题,为进化计算在个性化搜索和推荐中的应用进行了尝试,取得了良好效果.但是,融合多源异构UGC 和基于偏好代理模型进化计算(Evolutionary computations,ECs)的相关研究较少,已有研究也仅仅利用了单一类型UGC信息,此外,没有考虑UGC 不同特征信息对用户认知偏好和ECs 算子的影响.
基于代理模型的进化算法在复杂工程和函数优化中已有较多研究成果,主要利用进化过程中产生的数据或者生产实践中获得的数据,采用机器学习方法等构建模型,在进化过程中,利用该模型代替复杂适应度评价函数,实现对进化个体的适应值估计,进而提高进化优化的效率.常用代理模型包括:多项式回归模型[18]、支持向量机[19]、神经网络[20]和克里金模型[21]等.Min 等[22]提出了基于多问题代理模型的迁移进化多目标优化算法.Wang 等[23]结合基于代理模型的低代价鲁棒估计和时间消耗的实际鲁棒性测量,提出了基于图嵌入的大规模网络代理模型辅助鲁棒优化算法.Cai 等[24]提出了一种广义代理模型辅助的进化算法处理高维高代价优化问题.显然,已有代理模型均基于数值型描述的优化问题,而本文研究面向UGC 的个性化搜索,需要构建用户偏好代理模型,其处理对象为文本、类别标签、打分数据甚至图像等,传统代理模型不再适用.
本文考虑深入理解和充分挖掘多源异构UGC数据,利用无监督学习RBM 模型强大的表示学习能力和AM 在特征选择方面的突出表现,设计融合多源异构数据和AM 的RBM 用户偏好代理模型,并结合IECs 进化优化框架,提出增强RBM 驱动的IEDA,应用于个性化搜索中.充分利用多源异构UGC 数据包含的文本类信息,包括用户评价和项目类别两类连续、离散混合数据,提取与用户认知偏好高度相关的特征,获取表示用户偏好的注意力权重,构建精准拟合用户搜索偏好的基于注意力机制和RBM 的用户认知偏好模型,实现多重特征交互,同时捕捉低阶至高阶的基于多源异构数据的用户偏好特征;在IEDA 框架下,设计基于RBM用户偏好的概率模型,生成含用户偏好的可行解,同时,设计基于RBM 用户偏好代理模型的进化个体适应度估计函数,为搜索对象提供量化的评价值,部分代替用户评价选择优良个体,生成用户可能感兴趣的项目推荐列表;考虑用户偏好的动态演化特性,根据新增UGC 数据和模型管理机制,动态更新融合多源异构数据和AM 的RBM 用户偏好模型,引导个性化进化搜索过程,以期快速准确地搜索用户满意解,提高个性化搜索算法的评分预测准确性和推荐效果.
本文贡献主要包括3 个方面:1)针对含用户生成内容的个性化搜索问题,充分挖掘用户生成内容中的连续语义特征和离散类别特征,给出基于RBM 的特征融合方法和注意力权重确定策略,以及融合注意力权重的RBM 用户偏好模型构建机制,以拟合用户兴趣偏好的动态变化过程;2)基于所构建RBM 偏好模型,通过计算当前用户偏好个体中决策变量属性值为1 的概率,建模用户的兴趣选择倾向,形成IEDA 进化个体生成的采样概率模型;3)基于RBM 模型参数确定法则是最小化能量函数的原则,利用能量函数构建了分布估计算法(Estimation of distribution algorithm,EDA)进化个体适应值评价代理模型,进而实现了面向含用户生成内容个性化进化搜索的高效IEDA 算法.
本文后续内容组织如下:第1 节给出所提算法框架;第2 节详细描述基于注意力机制和RBM 的用户认知偏好模型构建;第3 节提出基于偏好模型的交互式分布估计算法;第4 节给出实例分析;最后总结本文工作.
1 算法框架
本文旨在利用UGC 和RBM 建模用户偏好特征及其动态变化过程,以交互式进化优化的方式,准确刻画用户实时兴趣,抽取用户行为规律和发展动态,可望从海量数据构成的动态演化空间中引导用户尽快搜索到满意解,提高面向多源异构UGC的个性化搜索的综合性能.
所提融合注意力机制的增强受限玻尔兹曼机驱动的交互式分布估计算法(Enhanced restricted Boltzmann machine-driven interactive estimation of distribution algorithms with attention mechanism,AM-ERBM-IEDA)的基本框架如图1 所示.首先根据用户查询信息,获得初始物品集合及其UGC 数据,作为EDA 初始化搜索空间;分别将UGC 的评价文本和类别标签送入doc2vec 和multihot 编码模块,获得UGC 数据的向量化表示;将量化表示的UGC 作为RBM 偏好模型的输入,训练该模型;计算RBM 偏好模型的输入层分布概率,将其作为EDA种群再生的采样概率模型;基于RBM 能量函数定义,构建EDA 进化个体(搜索物品)适应值代理模型,以估计个体适应值,实现选择操作,将TopN列表提交给用户评价,实现交互过程;在进化过程中,根据用户交互信息和代理模型估计值管理RBM 模型更新过程,以跟踪用户兴趣变化,从而更新采样概率模型和适应值代理模型.循环上述过程,直至用户找到满意物品.
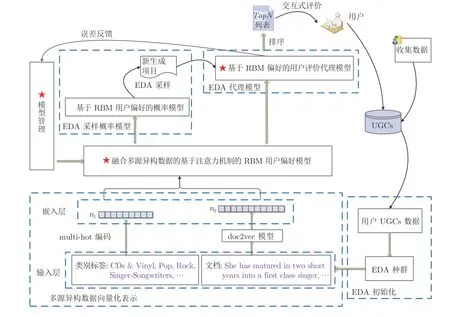
图1 AM-ERBM-IEDA 算法框架Fig.1 The framework of AM-ERBM-IEDA algorithm
图1中,“⋆”标记模块为核心部分,包括:基于注意力机制和RBM 的用户认知偏好模型构建、基于RBM 用户偏好的交互式分布估计算法,特别是EDA采样概率模型计算,以及EDA 用户评价代理模型和管理.
2 基于注意力机制和RBM 的用户认知偏好模型构建
2.1 面向评价和类别UGC 的用户偏好特征提取
多源异构UGC 数据中包含丰富的用户历史交互行为数据(如:用户对项目的评分数据、用户对项目的文本评论等)、项目内容信息(如:项目类别标签等)、用户之间的社交网络关系等,这些数据含有大量用户显式和隐式的兴趣偏好信息,充分探索和挖掘这些有用信息,建模基于注意力机制和RBM的用户认知偏好模型,能够有效提高个性化搜索算法的性能.该模型包含3 个模块:融合多源异构数据的RBM 注意力权重生成模块、注意力层和基于注意力机制的RBM 模块,其结构示意图如图2所示.
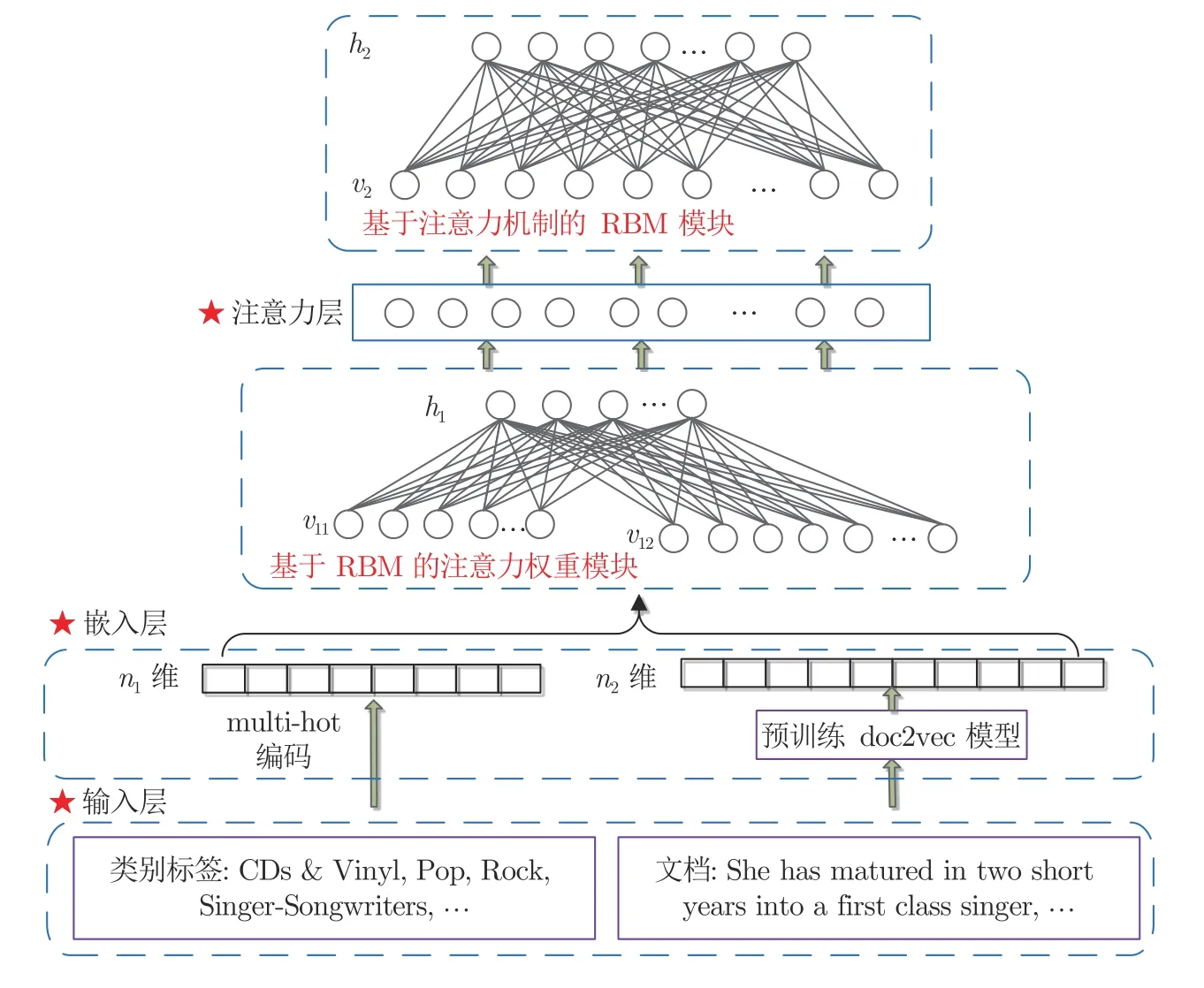
图2 基于注意力机制和RBM 的用户认知偏好模型Fig.2 User cognitive preference model based on attention mechanism and RBM
融合多源异构数据的RBM 注意力权重生成模型具有两层网络结构:v11为第1 组可见层,有n1个可见单元,表示项目的类别特征;v12为第2 组可见层,有n2个可见单元,表示用户对项目评论的文本特征;h1为隐层,有m1个隐单元,表示用户偏好特征.其中,层间全连接,层内无连接,可见单元和隐单元均为实数.该模型的输入数据由用户评分数据、项目类别标签和用户文本评论构成,具体如下:
3)将用户对项目的文本评论进行数据预处理,基于数据集的语料库训练doc2vec 文本向量化表示模型[25],生成用户文本评论的向量化表示T=,其中,tij表示用户ui对于项目xj的文本评论的向量化表示.Du中各项目的文本评论向量化表示Tu,即
由多源异构UGC 数据整合模型训练数据,表示为|Du|×n特征向量矩阵Vu,即
根据训练数据集Vu和对比散度(Contrastive divergence,CD)学习算法[26],训练融合多源异构数据的RBM 注意力权重生成模型,获得包含用户u偏好特征的模型参数,均为实数.
当给定可见单元状态时,各隐单元的激活状态条件独立,第j个隐单元的激活概率为
其中,ci表示第1 组可见层v11中第i个可见单元的状态;ti表示第2 组可见层v12中第i个可见单元的状态;表示隐层h1中第j个隐单元的状态;表示可见单元i与隐单元j之间的连接权重;表示第j个隐单元的偏置;σ(x)=1/(1+exp(-x))是sigmoid 激活函数.
当给定隐单元状态时,各可见单元的激活状态亦条件独立,第1 组和第2 组可见层第i个可见单元的激活概率分别为
模型训练完成后可同时获得两类信息:用户u对当前待搜索对象的偏好特征,即隐层输出;用户u对于项目中各决策变量的偏好程度,即输入层最终获得的.
2.2 基于注意力机制的偏好特征集成
考虑用户历史行为中不同项目的属性特征对评分预测的贡献的差异性,增加了注意力层,对用户的个性化偏好特征赋予不同权重,着力分析不同特征间的关联度,以加强重要特征对评分预测的贡献.
计算用户u的注意力权重atu,即
用户u偏好的注意力权重atu刻画了项目中各决策变量对于用户u偏好特征的重要性程度,由此得到优势群体Du中第i个项目个体的编码表示,即
则Du中所有项目个体的融合多源异构数据的基于AM 的向量表示为,即
将Du中的个体xu再次输入已训练好的融合多源异构数据的RBM 注意力权重生成模型,帮助融合多源异构数据的基于AM 的RBM 用户偏好模型将注意力集中于重要的特征,更精细地表达当前用户u的偏好特征.由此得到可见单元的输出,即
其中,softmax(·)函数保证所有权重系数之和为1.函数衡量了项目个体xu相对于用户偏好特征的注意力权重系数,计算式为
进一步获得训练数据集Xu中个体xu的基于AM 的用户偏好注意力权重At(xu),即
其中,at(xi)表示Du中项目个体xi(i=1,2,···,|D|)融合AM 的注意力权重系数,即
注意力层抽取并融合了用户对于个体决策变量的注意力权重系数A(xu),从全局的角度考虑项目各属性特征对于用户偏好的影响,加权求和获得融合AM 的注意力权重系数的用户偏好特征向量At(xu),更加关注对用户偏好贡献大的属性特征.
2.3 融合高度相关特征的用户认知偏好模型构建
各项目个体基于AM 的向量表示为At(Xu),由此训练基于AM 的RBM 用户偏好模型,获取用户偏好特征的高阶关系.当给定可见单元状态时,第j个隐单元的激活概率为
当给定隐单元状态时,第i个可见单元的激活概率为
3 基于偏好模型的交互式分布估计算法
3.1 分布估计算法概率更新模型
在IEDA 进化优化框架下,设计基于RBM 用户偏好的概率模型Pu(x),即
基于RBM 用户偏好的概率模型Pu(x)通过计算当前用户偏好的项目中决策变量属性值为1 的概率p(xi=1),以概率生成的角度表示用户对于项目的偏好,建模用户兴趣选择倾向.在IEDA 进化优化过程中,随机采样概率模型Pu(x),生成包含当前用户偏好的Pop个新个体.根据相似性准则,将生成的新个体与搜索空间中的项目进行相似性匹配,选择出相同的项目或者最相似的项目作为可行解,构成待推荐项目集合Su.
3.2 基于偏好模型的物品适应度函数
由第2 节已训练好的融合多源异构数据的基于AM 的RBM 用户偏好模型的能量函数项目x在(x,h2)状态下的能量函数隐式表达了用户u对于项目x的偏好程度,即
3.3 计算复杂性分析
本文所提算法的计算复杂性由训练用户文本评论的doc2vec 向量化表示模型、训练用户偏好模型和筛选可行解所决定.其中,用户文本评论的doc2vec向量化表示模型的训练是离线计算.训练用户偏好模型的计算复杂性为O(|Du|×(n1+n2)×m);选择Su个可行解的时间花费是O(Su×D),D是搜索空间中的项目数量;计算Su个候选项目的个体适应值的时间花费为O(Su).因此,本文所提算法每代总的计算复杂性为O(|Du|× (n1+n2)×m+Su×D).
4 实验结果与分析
为了验证所提算法的综合性能,将其应用于Amazon[14]的6 个数据集和Yelp 数据集,这些数据集包括丰富的多源异构数据,如:用户ID、项目ID、用户对项目的1~5 整数值评分、项目类别、用户文本评论、用户评论时间等信息.数据集的统计信息描述如表1 所示.
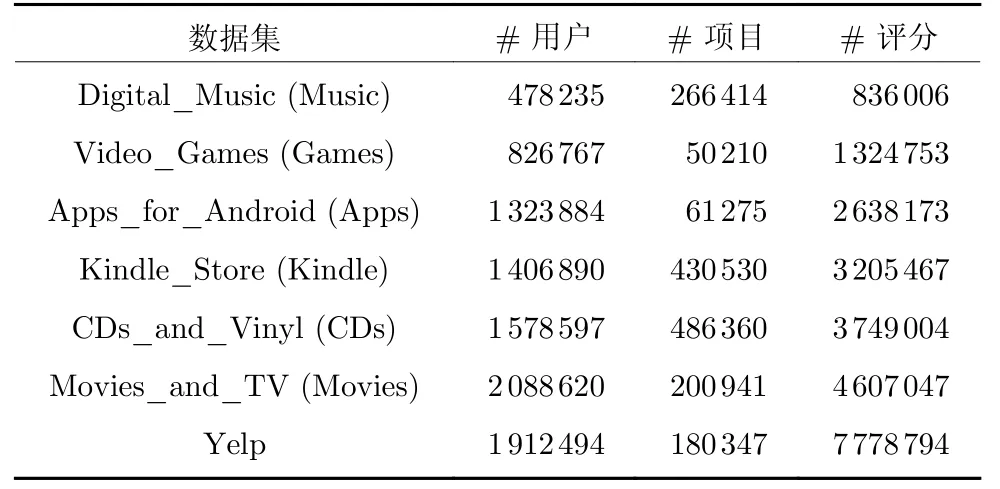
表1 数据集统计信息Table 1 Statistical information of datasets
实验环境是Intel Core i5-4590 CPU 3.30 GHz和4 GB RAM,实验平台使用Python 3.6 开发.为了客观比较本文所提算法的性能,选择Random、Popularity、BPRMF[5]、ConvMF[9]、ATRank[12]、RBMAEDA[20]、DRBM[8]算法进行对比实验和分析.BPRMF、ConvMF 和ATRank 都是有监督学习的推荐算法,BPRMF 隐因子数目为20.RBMAEDA是一种基于无监督学习的个性化搜索算法.实验中采用以下评价指标:均方根误差(Root mean square error,RMSE)、命中率(Hit ratio,HR)、平均准确率(Average precision,AP)、平均准确率均值(Mean average precision,mAP)[8]和运行时间.
4.1 用户偏好认知模型的可靠性
在数据集中随机选取10 个测试用户,按用户评论时间顺序排列,分别以70%和30%的比例划分训练数据集和测试数据集,使用各种推荐算法为测试用户进行个性化搜索实验,各种推荐算法分别独立运行10 次,记录相应的平均实验结果.本文所提算法的实验参数如表2 所示.
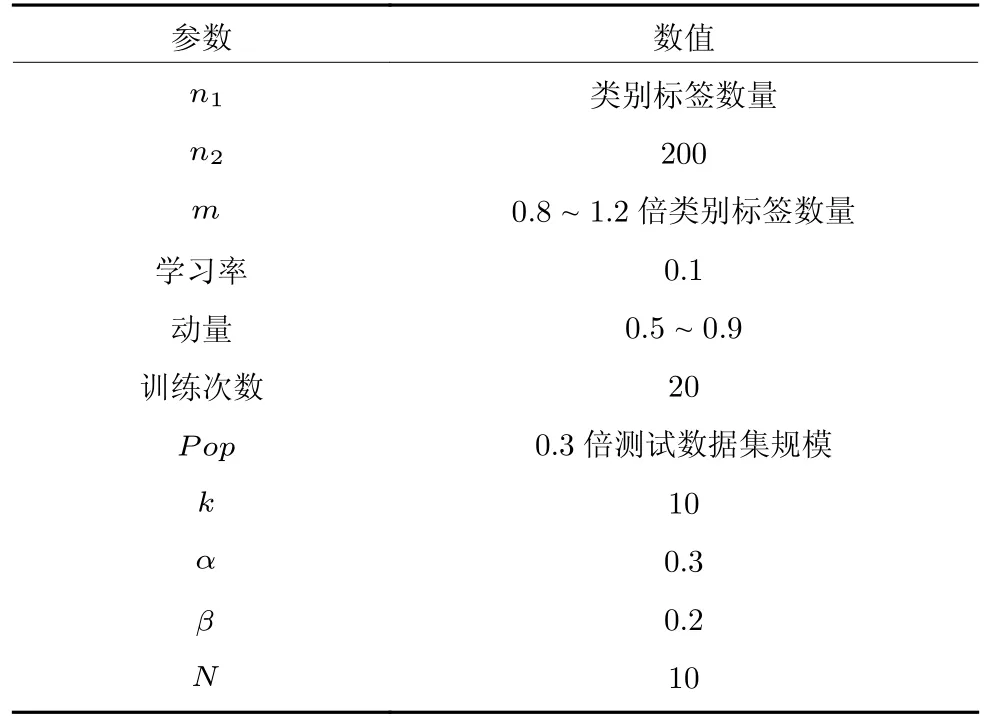
表2 算法的实验参数Table 2 Experimental parameters of our algorithm
为了证明本文所提融合多源异构数据的RBM用户偏好模型及基于RBM 用户偏好的代理模型的可行性和有效性,在各种不同领域的数据集中进行了大量实验.RBM-MsH 算法考虑了各项用户评分数据、类别标签和文本评论,是没有融合AM 的RBM用户偏好模型算法.融合了AM 和多源异构UGC数据的增强RBM 的个性化搜索算法(Integrating attention mechanism into RBM for multi-source heterogeneous UGC),记为AtRBM-MsH.表3 中展示了各算法实验结果,最优结果用粗体标注.
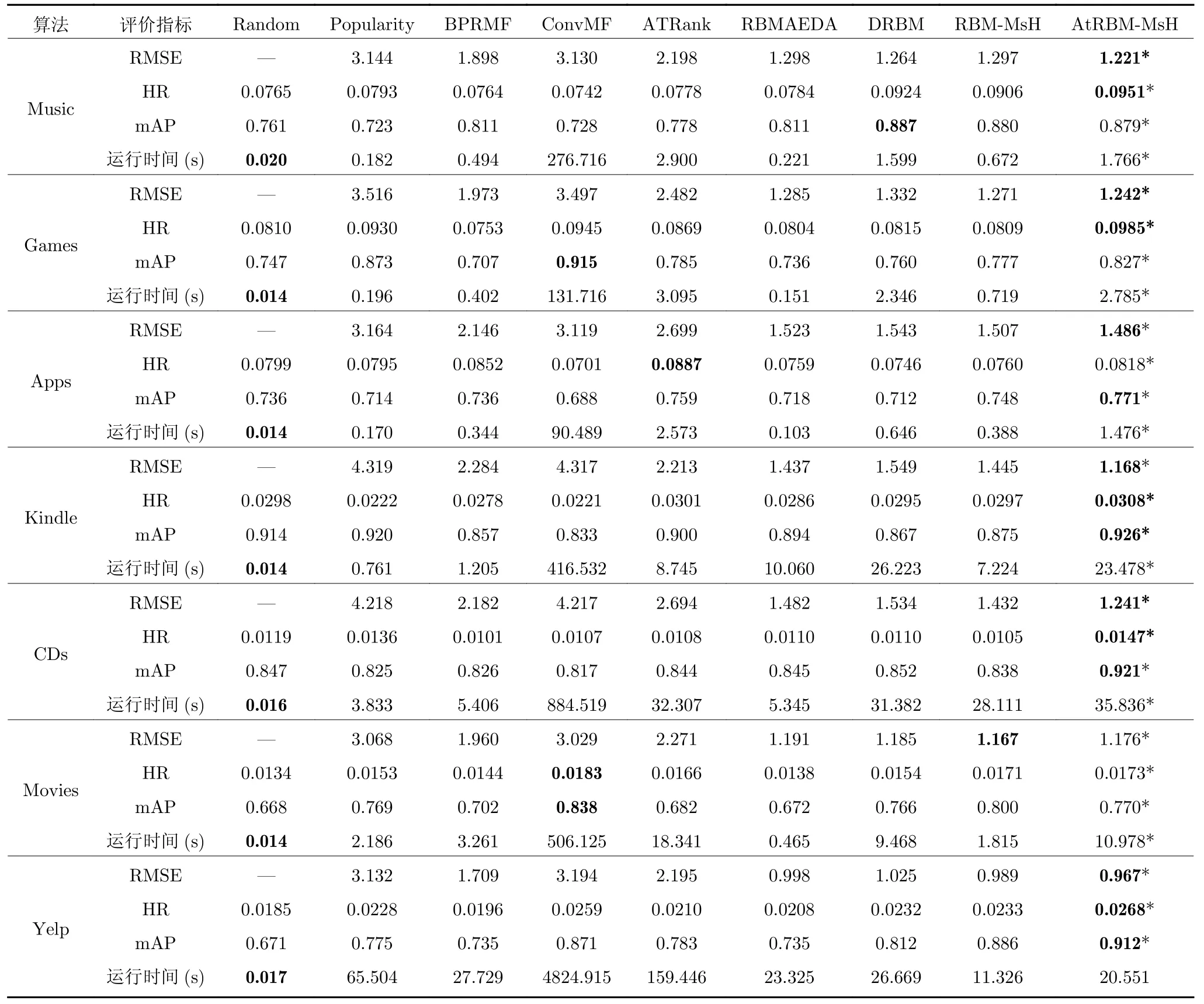
表3 对比实验结果Table 3 Experiments compared with popular recommendation algorithms
实验中,置信水平0.95 的Mann-Whitney U是一种非参数检验,用来展示本文所提算法的显著性不同,带有标记“*”的数据表示该算法与其他算法有显著性不同.
由表3 可得出以下结论:
1)在大部分数据集中,AtRBM-MsH 都取得了最优的结果,如:在Kindle 数据集中RMSE 值取得了最优1.168,低于ATRank 算法47.22%,而HR和mAP 值取得了0.0308 和0.926,分别高于次优ATRank 算法2.33%和2.89%,展示了本文所提算法模型比其他模型具备更强的特征提取能力和表示学习能力,进行更准确的评分预测和有效的项目推荐.同样地,在Yelp 数据集中也取得了优良的预测准确性和推荐效果.
2)在各数据集中,AtRBM-MsH 总体上优于BPRMF、ConvMF 和ATRank 这些有监督学习算法,其中,ConvMF 算法的时间花费巨大,是因为CNN 深度学习网络的运算过程复杂、训练时间较长,使得这类基于深度学习的推荐算法在所有数据集上计算代价最高.Random 和Popularity 算法无法有效获取用户的偏好特征,在进行推荐时不具备个性化特性,总体上的推荐效果不如个性化搜索算法.Random 算法的时间花费获得最小值,这是容易理解的.在保证预测精度和推荐准确性的情况下,AtRBM-MsH 利用基于RBM 的个性化搜索方法极大缩短了构建用户偏好模型的训练时间,在推荐效果和时间花费上取得了较好的折中效果.
3)在各数据集对比实验中,AtRBM-MsH 全部优于RBMAEDA,这是因为RBMAEDA 只考虑了用户评分数据和项目类别标签进行个性化搜索,而AtRBM-MsH 算法综合考虑了UGC 中的多源异构数据和影响用户偏好的决策变量的重要程度,构建基于AM 的RBM 用户偏好模型,更加有利于抽取用户偏好特征,取得了最优的预测精度、推荐效果和用户满意度.另外,RBM-MsH 虽然考虑了多源异构UGC 数据,但没有引入AM,综合推荐效果优于RBMAEDA,但是不如AtRBM-MsH,进一步说明了融合AM 的有效性.
因此,本文所提算法联合多源异构UGC 数据和AM,深入理解项目类别标签和用户文本评论,加强重要特征对于构建用户偏好模型的贡献,同时,减轻数据稀疏对评分预测的影响,进行有效的项目推荐,具备良好的评分预测精确性和项目推荐准确率.
4.2 基于偏好模型的个性化搜索有效性
为了充分展示本文所提算法的个性化搜索和推荐性能,以Kindle_Store 数据集中用户“A13QTZ8-CIMHHG4”为例,筛选当前用户评分数据和用户文本评论,按时间顺序排列截取前 #% 为训练数据集,后(100 -#)%为测试数据集,测试在不同的数据集稀疏度情况下用户进行个性化搜索.表4 是测试用户的个性化搜索实验结果.
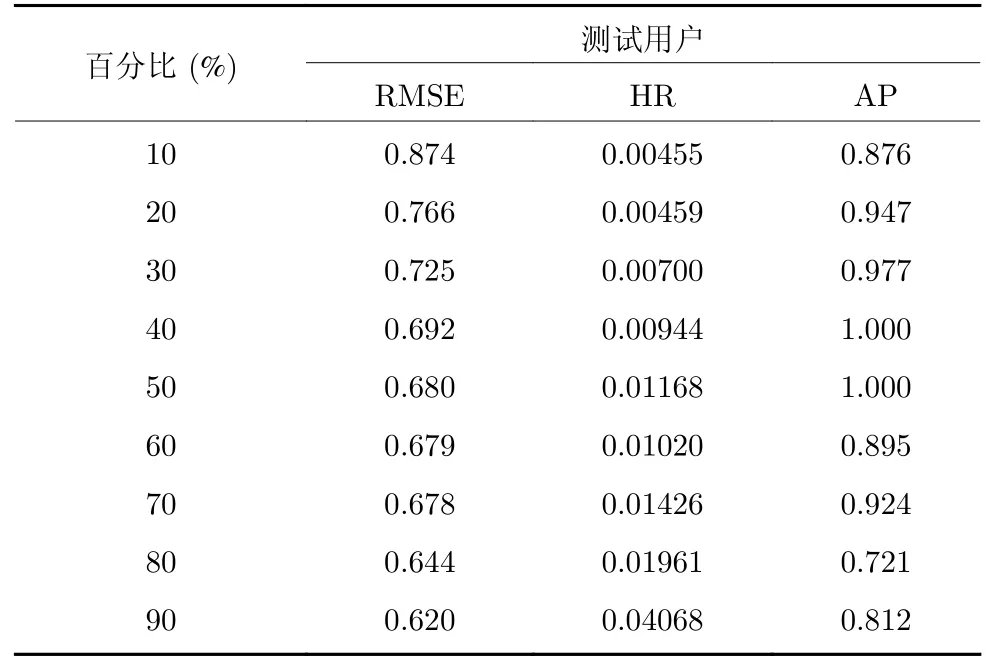
表4 测试用户个性化搜索实验结果Table 4 Experimental results of a test user
实验结果表明,在数据稠密度只有30%时,At-RBM-MsH 也达到了很好的预测精度和推荐准确性,几乎是把用户喜欢的项目都排在了TopN项目推荐列表的前面,具备更好的用户满意度和用户体验.随着数据集中稠密度的逐渐增大,AtRBMMsH 的预测精度和推荐准确性也在不断提高,说明当数据稠密时有用信息逐渐增加,有利于融合多源异构数据的RBM 用户偏好模型抽取当前用户偏好特征,为个性化搜索算法提供了有效的用户偏好策略引导.
图3是以图形形式展示测试用户分别利用RBMAEDA、DRBM、RBM-MsH 和AtRBM-MsH 算法进行个性化搜索的实验结果.
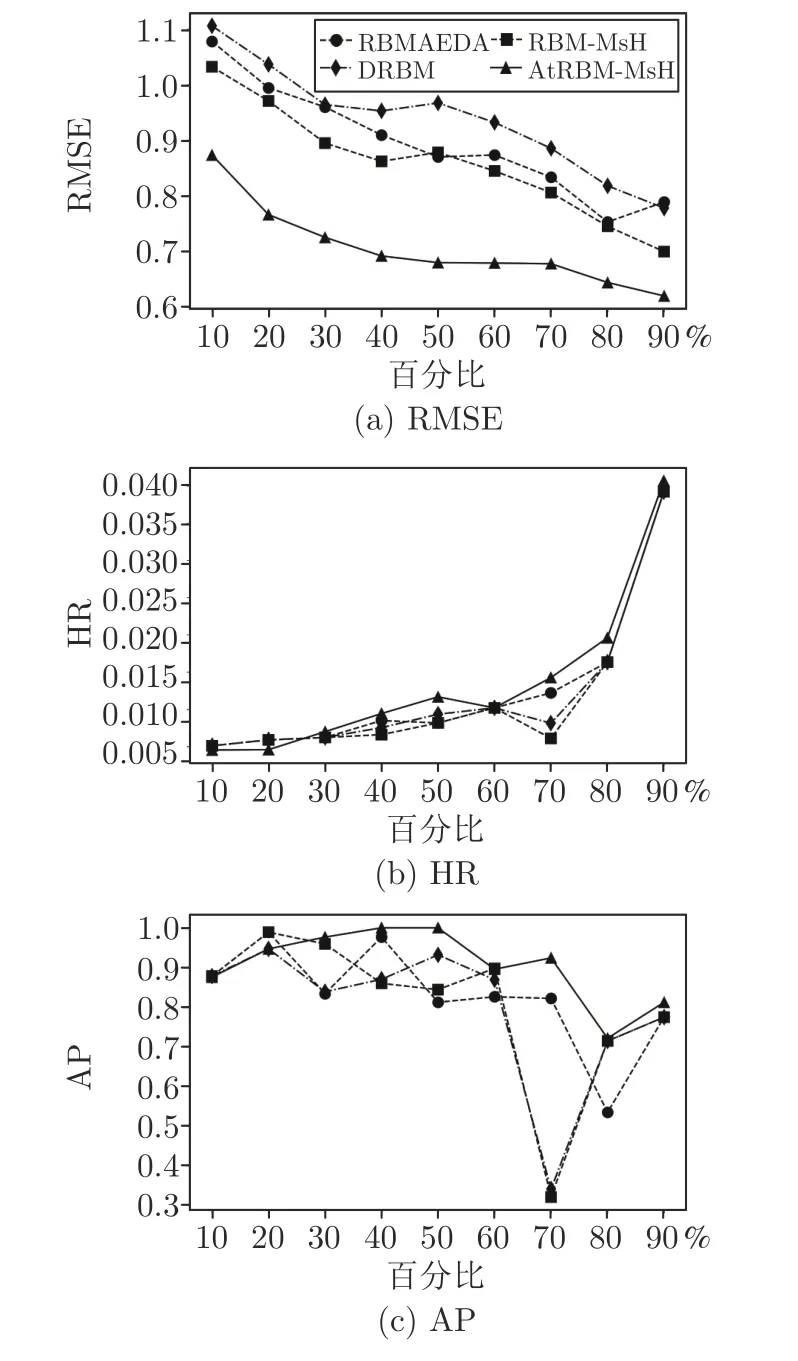
图3 测试用户个性化搜索实验Fig.3 Experimental results of a test user
从图3 可以看出,用户对于项目的文本评论包含了较多的用户偏好信息,融合多源异构数据的RBM-MsH 优于只考虑项目类别标签的RBMAEDA和DRBM,而AtRBM-MsH 能够充分整合多源异构UGC 数据和AM,有效抽取用户偏好,获得了优良的综合性能.
为了进一步展示本文提出的AtRBM-MsH 辅助的IEDA (AtRBM-MsH assisted IEDA,At-RIEDA-MsH)算法的综合性能,在CDs_and_Vinyl 数据集随机选择某用户,将未结合IEDA 框架的AtRBM-MsH 算法与AtRIEDA-MsH 算法进行了对比实验,实验结果如图4 所示.
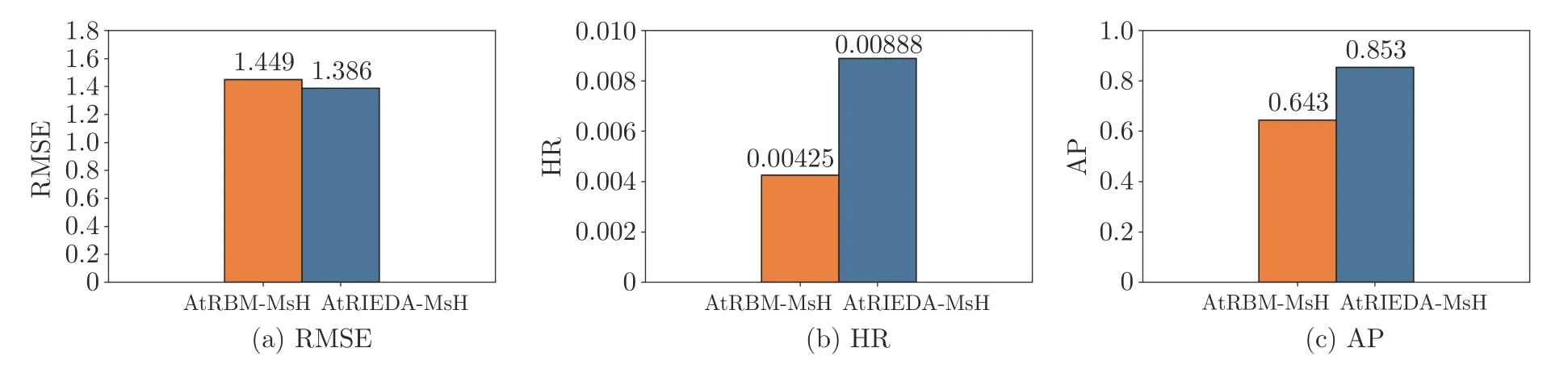
图4 CDs_and_Vinyl 数据集测试用户个性化搜索实验Fig.4 Experimental results of a test user on CDs_and_Vinyl
从图4 中可以看出,AtRIEDA-MsH 优于At-RBM-MsH,其RMSE 值降低了4.35%,HR 和AP分别提高了108.94%和32.66%,展示了在IEDA框架下充分利用多源异构UGC 数据,融合AM 构建增强的基于RBM 用户偏好模型,抽取用户偏好特征,引导用户进行个性化搜索是可行且有效的.
4.3 基于交互式分布估计算法的UGC 搜索的有效性
在实验中,随机选择某用户参与交互式个性化搜索过程,前50%作为训练数据集,其中,前20%作为初始的历史交互数据,后30% 数据分割为10 份,作为每次迭代的新增UGC,剩余50%作为个性化搜索的可行解搜索空间,模拟用户的交互式个性化搜索的动态过程,展示本文所提算法的可行性、有效性和适应能力.将本文所提算法与5 种IECs:传统IEDA、RBM 辅助的IGA (RBM assisted IGA,RBMIGA)、RBMAEDA[20]、DRBMIEDA[8]、RBM-MsH 辅助的IEDA (RBM-MsH assisted IEDA,RIEDA-MsH)算法进行对比实验,其中,IEDA 作为基线算法,RBMIGA 是IGA 框架下的基于RBM 个性化搜索算法.各算法进行10 代优化搜索,给出10 次评分预测和项目推荐,同时,各算法独立运行10 次,计算平均评价指标评估算法的综合性能.实验结果如表5 所示,其中最优解用粗体表示.
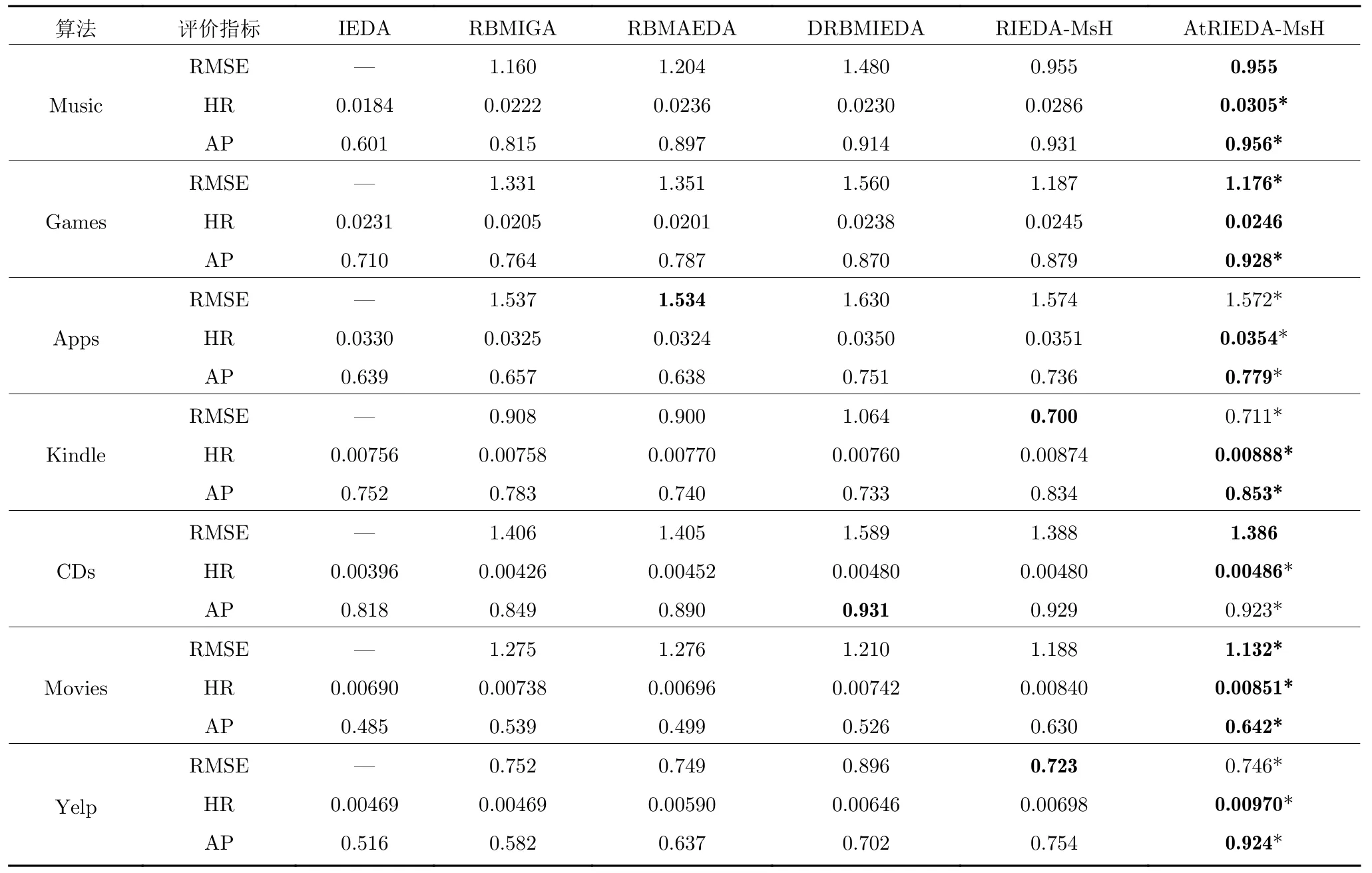
表5 对比实验结果Table 5 Comparison of experimental results
在表5 中,标记“*”表示根据置信水平0.95 的Mann-Whitney U 非参数检验算法显著区别于其他算法.另外,由于在IEDA 算法中没有构造代理模型预测用户对于项目的评分,所以IEDA 算法没有RMSE 值.由表5 可得出以下结论:
1)在各数据集中,AtRIEDA-MsH 取得了最优效果,如:在Music 数据集中AtRIEDA-MsH 平均RMSE 值获得了最优值0.955,HR 和AP 值分别为0.0305 和0.956,高于次优RIEDA-MsH 算法6.64%和2.69%.在Yelp 数据集中也获得了类似的实验结果.虽然在部分数据集中一些评价指标没有取得最优值,但是综合比较获得了最优综合性能.AtRIEDA-MsH 是在RBMAEDA 中融合了用户文本评论和AM,更有利于构建高效的用户偏好模型、EDA 概率模型和用户评价代理模型,提高了评分预测能力和推荐准确性.
2)在各数据集对比实验中,RBMAEDA 优于RBMIGA,RBMIGA 优于IEDA,RIEDA-MsH 优于RBMAEDA,说明用户文本评论相比较项目类别标签包含了更多的用户偏好信息,帮助RIEDAMsH 算法提高了评分预测能力和推荐准确性.更进一步,AtRIEDA-MsH 算法考虑多源异构UGC 数据,利用基于注意力机制RBM 模型构建用户偏好模型,引导个性化搜索,取得了最优的预测准确性和综合搜索效果.
为了进一步展示本文所提算法的优越性能,以图形的形式动态展示Music 和Games 数据集中用户的个性化搜索过程,如图5 和图6 所示.
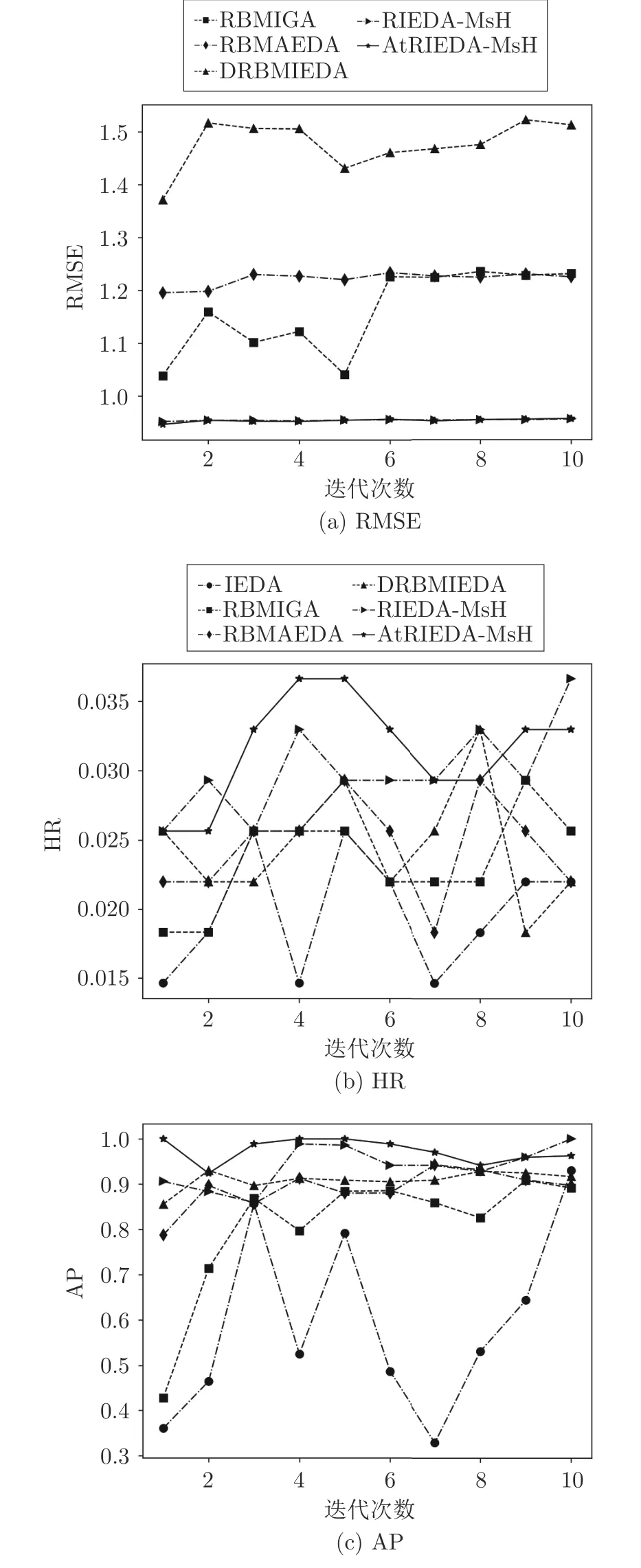
图5 Music 数据集某用户个性化搜索实验Fig.5 Experimental results of a test user on Music
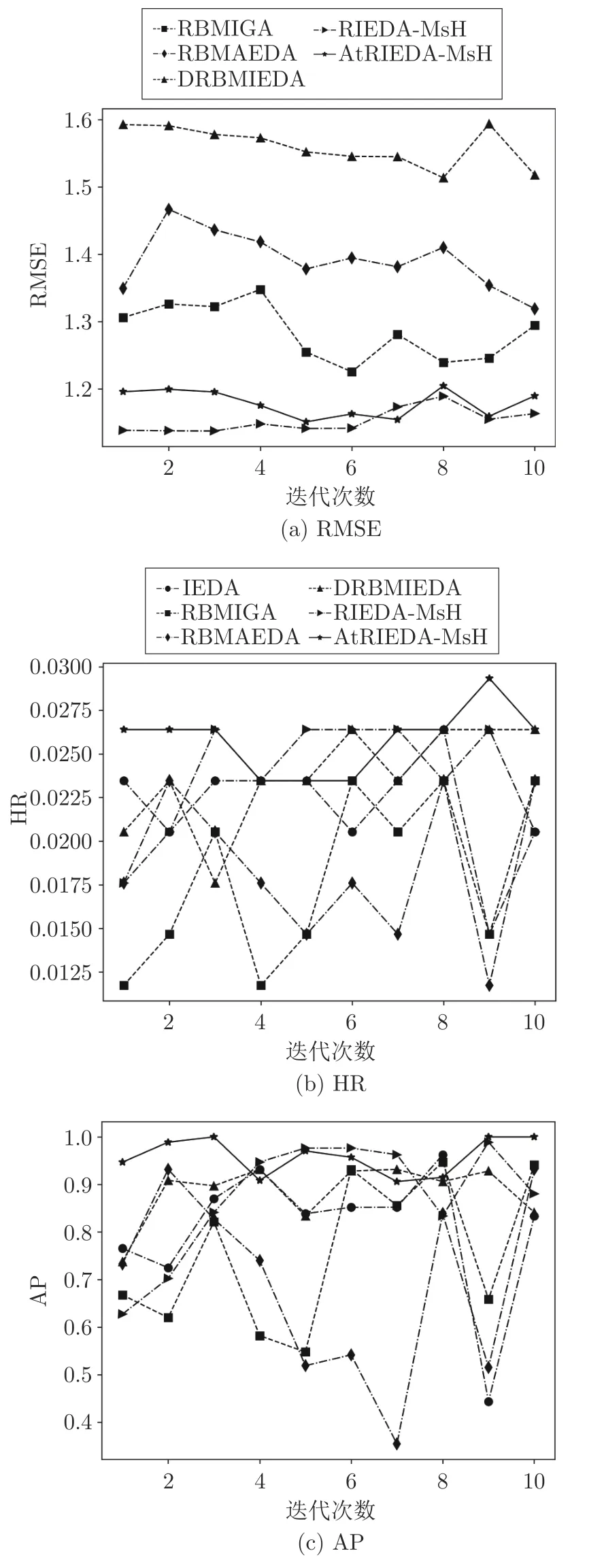
图6 Games 数据集某用户个性化搜索实验Fig.6 Experimental results of a test user on Games
从图中可以看出,大部分情况下蓝色线代表AtRIEDA-MsH 和红色线代表的RIEDA-MsH 算法的RMSE 值低于其他对比算法,而HR 和AP 优于其他算法,说明本文所提出的算法能够较好地抽取用户偏好特征,动态跟踪用户偏好,为当前用户进行有效的个性化推荐,取得了较好的预测精确性和推荐准确率,改善了用户体验和满意度.
5 结束语
针对如何在大数据环境下充分有效利用多源异构UGC 数据,本文提出了融合多源异构数据的增强RBM 驱动的IEDA,并将其应用于个性化搜索这类复杂定性指标优化问题中.利用多源异构UGC数据,构建融合多源异构数据的基于注意力机制的RBM 用户偏好模型,帮助用户偏好模型将关注点聚焦于属性信息的重要特征,有效抽取用户偏好特征,动态跟踪用户兴趣和偏好.同时,以创造良好的用户体验和平台效益为目标,在IEDA 框架下构建用户与个性化搜索算法的交互式过程,设计了相应的进化优化策略,通过用户偏好模型所获得的用户认知经验和兴趣偏好动态引导当前用户逐渐搜寻到满意解,从而有效解决了个性化搜索问题.在今后的研究工作中,拟将进一步有效利用图像、视频等信息,研究融合动态群体智能IECs 的个性化搜索算法及其应用,提供智能化、专属化的用户服务体验.
