核酸适配体筛选与亲和力评价技术主要研究方向、进展与挑战*
2023-10-10贾海静高亚菁娄新徽
贾海静 高亚菁 娄新徽*
(首都师范大学化学系,北京 100048)
核酸适配体是一类具有特异性分子识别能力的单链DNA或者RNA分子,通过指数富集的配体系统进化技术(systematic evolution of ligands by exponential enrichment,SELEX)经过体外筛选得到[1]。核酸适配体的靶标类型极为广泛,包括小分子、蛋白质、离子、细胞、细菌、组织切片等。核酸适配体相比抗体具有热稳定性高、便于化学合成与修饰、免疫原性低等优点,在生物分析、生物医学、生物技术、传感技术等众多领域引起广泛关注。
1990年美国的Gold课题组[2]和Szostak课题组[3]通过基本相同的体外筛选技术,分别获得了能够与T4 DNA聚合酶和小分子有机染料特异性结合的RNA序列。Gold将该技术命名为“SELEX”,Szostak将这种对靶标具有特异性结合能力的核酸命名为“aptamer(适配体)”。1992年,Bock等[4]利用SELEX技术筛选获得首个单链DNA适配体。自上述开创性工作报道以来,30多年来核酸适配体研究领域已经发展成为多学科交叉的研究领域[5]。目前已经报道了数千种靶标的适配体,在生物标志物发现、药物靶向递送、生物成像、疾病诊断、食品和环境安全检测等领域展示了广阔的应用前景,然而核酸适配体的产业化应用还寥寥无几。如何获得具有高亲和力、高特异性、高体内稳定性的核酸适配体依然是亟待解决的核心问题。另外,核酸适配体的性能评价缺乏标准化,不同表征技术的结果存在不一致性的问题,极大地制约了核酸适配体的推广应用[6]。核酸适配体评价技术的标准化是加快核酸适配体推广应用的另一个亟待解决的重要问题。
由于核酸适配体筛选与亲和力评价技术的重要性,近年来国内外期刊报道了大量综述类论文,从不同的角度归纳总结技术进展,本文将在相关部分进行推荐阅读。绝大多数综述都侧重于对各种筛选和亲和力评价技术原理和应用的介绍,普遍缺乏对技术细节和问题的深入评述。基于上述情况,本文采用简单归纳与详细评述相结合的撰写方式,对30多年来核酸适配体筛选技术的进展进行表格式分类归纳,按照筛选技术的主要研究方向,分别介绍快速筛选方法、适用于小分子靶标核酸适配体筛选的方法,以及提高核酸适配体亲和力、特异性和稳定性的筛选方法的研究现状与发展趋势,对十多种常用亲和力评价技术的主要技术参数进行列表对比,突出各种技术的优劣。考虑到近几年小分子靶标核酸适配体筛选技术备受关注,本综述详细评述捕获-SELEX技术(Capture-SELEX)的实验条件选择、小分子靶标核酸适配体亲和力鉴定常用的纳米金(gold nanoparticle,AuNP)比色法和等温热滴定法(isothermal titration calorimetry,ITC)的技术进步和存在的问题,以期为本领域的工作人员提供较为具体的技术指导。本文最后对核酸适配体筛选与亲和力评价技术的标准化和未来发展趋势进行了展望。
1 SELEX技术的原理与关键步骤
SELEX技术基于亲和富集的原理,从含有大约1014~1015个随机序列的化学合成单链DNA或RNA库中筛选与靶标具有高亲和力、高特异性的序列。当筛选RNA适配体时,包括:(1)单链DNA随机寡核酸文库的设计与化学合成;(2)单链RNA文库的制备(通过转录过程);(3)核酸库与靶标的孵育;(4)靶标一核酸复合物的分离;(5)由单链RNA到单链DNA的转化(通过反转录过程);(6)聚合酶链式反应(polymerase chain reaction,PCR)扩增;(7)单链DNA次级文库的制备,共7个步骤,重复以上筛选步骤1~25轮。最后对富集后的文库进行测序,利用各种亲和力评价技术进行解离常数(dissociation constant,KD)和特异性的测定,获得核酸适配体。当筛选DNA适配体时,不包括步骤(2)和(5),其他步骤均相同。获取关于SELEX技术的基本知识,推荐阅读Sharma等[7]的综述;获取各个技术步骤进行更为详实的介绍,可以参阅Kohlberger等[8]2022年的综述。下面仅对SELEX技术的部分步骤进行简单介绍,着重介绍各步骤所面临的问题或者局限性。
1.1 核酸库的设计
1.1.1 核酸库类型
自SELEX技术提出以来的十几年里RNA适配体筛选占主导地位。2008年开始,DNA适配体的数量超过RNA适配体,且逐年快速增加[1]。DNA适配体或RNA适配体都容易被细胞或生物样品中核酸酶的降解。对适配体进行化学修饰不但大幅提高其抗酶降解能力,还可以提高适配体的亲和力、特异性和功能[9]。多种不同化学修饰的核酸文库已被用于核酸适配体的筛选[9]。由于化学修饰文库尚未实现廉价的商业化合成,而且存在知识产权问题,目前这类方法基本上局限于实验室应用。最近刚刚报道了使用环状DNA文库进行适配体筛选的工作[10],制备简单,易于推广。
1.1.2 固定区域和随机区域的设计
起始文库的设计对筛选结果具有显著影响[11-12]。固定区域的设计直接影响文库PCR扩增效率。引物区平均长度为18~21个核苷酸(nt),在设计时要保证其在扩增过程中不形成自身二聚体化,避免扩增时产生非特异性PCR产物。研究表明,较短的引物区对后续筛选的影响更小,而且有利于筛选出更加多样性的序列[13]。两端的固定序列部分互补的文库设计有利于获得二级结构稳定的核酸适配体[14-15],但同时存在筛选出的序列多样性相对低的问题,可能不利于筛选高特异性的核酸适配体。
随机区域长度绝大多数为30~60 nt,其中40 nt随机区最常用。短随机区域的设计有利于后续截短和应用,但更依赖于引物区结合位点的结构和功能,而较长的随机区域在筛选中有机会找到尺寸较大、结构较复杂的适配体,有利于获得特异性高的适配体[1]。研究表明,富鸟嘌呤(guanine,G)的文库更容易筛选获得具有G四聚体结构(G-quardruplex,G4)的适配体。目前报道了大量具有G4结构的核酸适配体,G4结构可以与多种多样的靶标结合,因此需要注意这类核酸适配体的特异性是否能够满足特定场合的需要。
1.2 筛选过程监控
在筛选过程中对每一轮的文库富集情况进行监控至关重要。最常用的监控方法包括凝胶电泳、荧光定量PCR(fluorescent quantitative PCR,qPCR)、文库KD测定、高通量测序、解链温度(melting temperature,Tm)测定等[16-17]。其中凝胶电泳法对每轮文库正、负筛选以及背景洗脱量进行半定量评价,结果直观。由于洗脱量较低,需要对样品进行PCR扩增(一般7~10轮)。需要注意扩增轮数的选择,扩增轮数太少时达不到凝胶电泳的检出限,扩增轮数太高无法真实反映出各样品中DNA的含量。qPCR与凝胶电泳类似,根据核酸库扩增曲线的Ct值推算出单链DNA的物质的量[16]。但需要注意的是,该方法不能确保文库定量的准确性。在筛选过程中,随着每轮的富集,核酸库的多样性会有所下降,倾向于筛选出富G和富C碱基的核酸库。研究表明,SYBR Green I对G、胞嘧啶(cytosine,C)丰富的DNA比腺嘌呤(adenine,A)、胸腺嘧啶(thymine,T)丰富的DNA亲和力低,从而导致更低的荧光信号,因此会对低估Ct值[18]。虽然换一种荧光染料可能会改善这种情况,但普通qPCR技术不能保证绝对定量的准确性。当筛选进行到一定轮数之后,可以对文库进行KD测定来判断文库的富集程度。文库Tm测定是监控文库富集程度的一种辅助性便捷方法,不少文库在富集过程中由于互补序列或者富G序列的富集,其Tm会随着富集程度的提高而逐渐升高。另外,高通量测序被越来越多的用来监控文库的富集程度。
1.3 PCR扩增与单链DNA制备
PCR扩增与单链DNA制备是制备次级文库的两个关键步骤。PCR扩增对序列的偏好性直接影响文库的多样性和适配体的筛选效率。为了减小PCR的偏好性,数字微液滴PCR(droplet digital PCR,ddPCR)技术被用来代替传统PCR进行文库的扩增。Takahashi等[12]利用高通量测序技术系统对比研究了ddPCR与传统PCR对核酸适配体筛选的影响,结果表明,基于ddPCR的文库在筛选过程中的确具有更高的文库多样性,但是文库的富集速率显著低于基于传统PCR的筛选过程,而且所获得的适配体性能并没有超越基于传统PCR筛选所获得的适配体。
目前将PCR双链产物制备为单链DNA次级文库的常用方法包括生物素-链霉亲和素磁珠(琼脂糖球)法、长短链法、λ核酸外切酶法、不对称PCR法。这些方法的实验细节已经有综述详细阐述[19],本文不再赘述。国内外团队也先后对这些制备方法的效率和纯度开展了对比性研究[20-21]。本团队曾经分别使用上述方法进行过单链DNA的制备,对这几种方法的对比研究结果与文献报道基本一致。生物素-链霉亲和素磁珠(琼脂糖球)法快捷,但价格贵,少量双链DNA和链霉亲和素也会在碱洗脱步骤被洗脱下来,但通常不影响适配体筛选。长短链法利用凝胶电泳来分离纯化单链DNA产品,所获得的单链文库最纯净,价格最低,但耗时长,收率相对较低。不对称PCR法需要较为繁琐的实验条件优化。λ核酸外切酶法利用核酸酶将双链DNA中5'磷酸化修饰的反义链降解掉,然后利用乙醇沉淀法进行DNA纯化,该方法操作简便,成本低,收率高,但高盐浓度抑制λ核酸外切酶的活性,剪切反应是否完全需要利用凝胶电泳进行验证。近期也报道了一些新的制备单链DNA文库的方法[22],相比现有技术的优劣有待实践的验证。
1.4 富集文库的测序与候选适配体筛选
富集文库的测序可以通过传统克隆测序的方法获得,一般测序数量20~100条。随着二代测序技术的快速发展,近几年来文库的测序成本快速下降,近5年二代测序已经成为适配体筛选文库测序的主要技术手段,获得的序列数量高于10 000条。文库无需高度富集就可以通过二代测序的数据分析筛选出候选的核酸适配体。同时人工智能、分子对接等计算机辅助技术的兴起,也为高质量核酸适配体的筛选提供了新的策略。
2 SELEX筛选技术的研究进展
核酸适配体领域发展迅速。从科学引文数据库(Web of Science)以“aptamer”为主题进行文献检索,研究文献逐年快速增加,从2000年96篇左右,2011年5 250篇,截至2023年6月核酸适配体相关文献已达25 400篇。这些文献80%~90%是基于核酸适配体的应用类文章,以筛选技术为主要研究内容的文献每年不足百篇。造成这种局面的主要原因是核酸适配体筛选费时费力、失败率高、成本高、发表高水平文章困难等等。尽管如此,30年来研究人员围绕SELEX技术的各个关键技术步骤不断进行优化和创新;SELEX技术的靶标范围从最初的纯化蛋白质和有机小分子已经拓展到细胞、病毒、组织切片、离子等几乎所有类型的靶标[5]。
目前核酸适配体的应用可以粗略地划分为两大领域,一是环境与食品安全领域,二是生物医学领域。前者最主要的应用场景是基于核酸适配体的快速检测技术,靶标主要是抗生素、真菌毒素、激素、农药等各类有机小分子和重金属离子。后者的应用场景更为多样化,包括疾病标志物快速检测技术、生物成像、药物递送等体外和体内的应用,靶标主要是蛋白质。蛋白质靶标核酸适配体的筛选和亲和力评价方法相比小分子靶标更为简单。筛选技术研究早期主要围绕蛋白质靶标核酸适配体筛选展开,近十年对小分子靶标核酸适配体的筛选方法研究得到越来越多的重视。为满足不同领域的需求,国内外筛选技术研究主要围绕建立提高核酸适配体的特异性、稳定性、亲和力的筛选方法、快速筛选方法、适用于复杂靶标和小分子靶标核酸适配体的筛选方法展开。其中快速筛选技术研究是最受关注的研究领域(表1、2)。
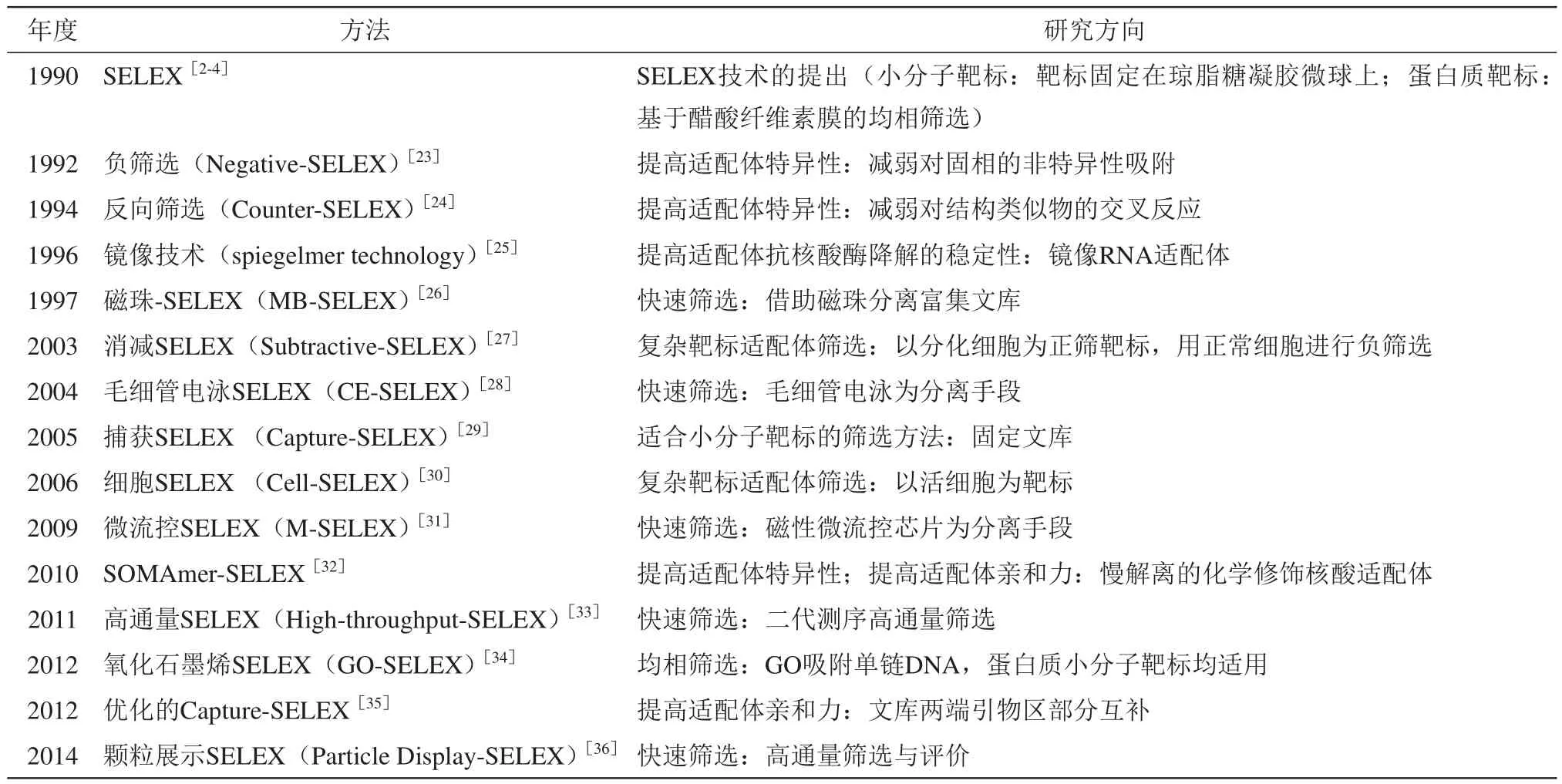
Table 1 Popularly applied SELEX variants表1 推广应用较广的SELEX筛选技术
30年来报道了60多种改良的SELEX技术,目前应用较广的SELEX技术大约10种(表1)。其中Negative-SELEX、Counter-SELEX、Subtractive-SELEX已经是目前筛选技术中提高核酸适配体特异性的常规技术步骤。随着二代测序价格的大幅下降,High-throughput-SELEX的二代测序技术已经是目前核酸适配体筛选进程研究、候选适配体筛选的常规技术步骤。MB-SELEX和Cell-SELEX在蛋白质靶标和肿瘤细胞特异性的核酸适配体筛选中应用极为广泛。琼脂糖凝胶微球-SELEX和MBSELEX是小分子靶标核酸适配体筛选常用的筛选方法。近年来Capture-SELEX和GO-SELEX的应用越来越广泛,特别是优化的Capture-SELEX[35,37-38]。SOMAmer-SELEX 需要使用化学修饰的文库;M-SELEX和Particle Display-SELEX需要非商业化的微流控装置;CE-SELEX需要复杂的分离条件优化和装置。这些局限性使这些方法相比上述其他方法的推广应用较少。近些年来,MSELEX技术的发展趋势是面向集成化、微型化,但是筛选效率还有待提高[39]。CE-SELEX在2004年首次报道以来,陆续报道了一系列改良的方法,详细的进展可以阅读相关综述[40-41]。
近5年来,对SELEX筛选方法的研究性论文的数量呈现稳定增长的趋势(表2)。快速筛选技术依然是SELEX筛选技术研究最受关注的研究方向。近三年,对高特异性、高体内稳定性、高亲和力的核酸适配体的筛选方法研究关注度显著提高。

Table 2 Advances of SELEX in recent five years表2 近5年的SELEX筛选技术研究进展
关于核酸适配体筛选技术的综述通常按照SELEX流程中分离结合序列与未结合序列的方法进行分类,比如基于磁珠的SELEX、基于文库固定的SELEX、基于微流控技术的SELEX,或者基于毛细管电泳(CE)的SELEX等。这样的分类方法突出了分离技术上的差异。纵观核酸适配体筛选技术30年来的研究进展(表1,2),提高筛选效率、获得高特异性、高体内稳定性、高亲和力的核酸适配体是核心技术难题。特别是近三年来,小分子靶标核酸适配体的筛选备受关注。因此下面对快速筛选方法、适合小分子靶标适配体筛选的方法、提高核酸适配体性能的筛选方法的研究进展进行较为详细的评述,以突出目前核酸适配体筛选技术的重点研究方向。
2.1 快速筛选方法
提高筛选效率是核酸适配体筛选技术领域长期以来持续关注的研究领域。快速筛选方法不局限于能够提高复合物快速分离或者降低筛选轮数的方法,还包括能够加快核酸适配体发现的其他技术步骤,比如快速的次级文库制备方法、高通量的候选适配体鉴定方法、适配体关键结合域快速鉴定方法等等。30多年来,快速筛选技术的研究重点集中在“降低筛选轮数”(表1,2)。下面围绕这一研究方向阐述。
1998年提出自动化筛选技术[72],但是目前并没有被广泛推广。SELEX的筛选循环中靶标一核酸复合物的分离步骤对文库富集效率具有极大影响,是建立快速筛选方法的核心优化步骤。截至目前,几乎所有用于生物分子分离的技术手段都已经用于SELEX,来代替传统的基于醋酸纤维素膜或者琼脂糖亲和柱的低效分离手段。其中最具影响力的快速筛选方法是基于CE、微流控芯片和磁珠的SELEX技术。CE-SELEX将筛选效率大幅提高,仅需要1~3个循环就可以获得KD在纳摩尔每升(nmol/L)水平的适配体[40-41]。由于CE分离的实验条件选择依赖较复杂的专业技术,一般生化实验室难以推广。另一方面,由于CE分离基于核酸适配体与靶标结合所引起的滞留时间的变化,小分子靶标通常难以引起足够大的滞留时间变化,因此CE-SELEX目前主要用于蛋白质靶标核酸适配体的筛选。2009年以来报道的各种基于微流控技术(M-SELEX)的快速核酸适配体筛选方法,为技术的微型化、自动化和集成化奠定基础[73]。但由于微流控芯片加工的技术门槛高,基于微流控芯片的筛选技术基本停留在实验室应用。
不依赖特殊设备和装置的便捷筛选方法更利于推广应用。1997年磁分离技术被首次应用于SELEX,将靶标化学固定在官能团化的磁球上,极为便捷地将结合序列和未结合序列分离开来[26]。基于磁珠的SELEX(MB-SELEX)在各类靶标核酸适配体筛选中应用极为广泛。但MB-SELEX筛选效率不高,需要的筛选轮数较多,这与核酸在磁珠界面上的非特异性吸附密切相关[42]。另外靶标的固相固定有可能改变或者封闭靶标的结合位点,批次间界面化学也会存在难以控制的差异,这些都会导致低的筛选效率。
为了克服上述问题,近年来报道了一系列基于高效化学反应的均相筛选技术,不但提高了筛选效率,而且所筛选的核酸适配体可以便捷地转化为传感器。2019年我们团队报道了一种将磁性分离与化学偶联反应相结合的SELEX方法,简称MCPSELEX[42]。先将蛋白质靶标与文库均相孵育,使两者在自然状态下结合,然后利用蛋白质上一级胺基与磁珠上活化羧基之间的高效偶联,通过捕获蛋白质靶标来捕获与靶标结合的核酸序列。该方法在5轮之内快速获得多种蛋白质靶标的核酸适配体。通过与Capture-SELEX联用,快速筛选获得了人血清白蛋白的结构开关型核酸适配体(structureswitching aptamer,SSA)。2022年华侨大学的团队巧妙地将脱氧核酶(I-R3)识别序列设计在Capture-SELEX文库引物区内,利用I-R3的DNA剪切反应实现了对小分子靶标的适配体酶(aptazyme)的快速筛选[58]。此外,2023年谭蔚泓院士团队[64]报道了基于甲醛交联反应(formaldehyde cross-linking-assisted phase separation,FCPS)的均相筛选方法,利用甲醛将靶蛋白与胺基修饰的DNA交联,利用有机溶剂萃取,实现对蛋白质靶标核酸适配体的快速筛选,仅需1~3轮。可以预见,快速筛选方法的研究还将持续成为研究热点。由于目前的快速筛选方法多数都是仅适用于蛋白质靶标,期待未来开展更多面向小分子靶标快速筛选方法的研究。
2.2 适合小分子靶标核酸适配体筛选的方法
近十年来,核酸适配体在环境和食品污染物快速检测领域展现出很好的应用前景。小分子污染物是这类应用中数量最大的一类靶标,包括毒素、抗生素、内分泌干扰物、农药等。小分子靶标的核酸适配体筛选技术研究受到越来越多的关注。由于小分子靶标的结合位点少、结构类似物多,相比蛋白质靶标,筛选获得高亲和力、高特异性的小分子靶标结合核酸适配体的难度更大。另外,由于很多小分子靶标缺乏可以进行固相固定的官能团,基于靶标固定的适配体筛选方法需要进行复杂的化学修饰。为了避免小分子靶标的固定,先后报道了基于文库固定的Capture-SELEX技术和均相的GO-SELEX[74]。鉴于屈锋教授课题组[37-38]已经综述了2019年以来的小分子靶标核酸适配体的筛选进展,归纳了约120种小分子靶标的核酸适配体的序列和KD,较为详细地介绍了基于靶标固定的SELEX技术(包括琼脂糖凝胶微球-SELEX和MBSELEX)和GO-SELEX,但未对Capture-SELEX进行介绍。本文着重介绍Capture-SELEX的技术原理、技术进展、应用情况和局限性。
2.2.1 基于靶标固定的筛选技术
1990年Szostak课题组[3]建立了基于靶标固定的核酸适配体筛选技术,解决了小分子靶标结合序列和未结合序列的分离难题。但是该技术存在以下4个问题[5]。a.文库在固相界面上存在非特异结合。为了解决这个问题,Szostak课题组[23]于1992年提出负筛策略(negative-SELEX),将文库先与固相孵育,以除去文库中对固相界面具有高非特异性吸附的序列。Jenison等[24]于1994年引入反向筛选(counter-SELEX),使用靶标结构类似物修饰的固相,不仅消除了与固相载体结合的非特异序列,还提高了核酸适配体的特异性,减小与靶标结构类似物的交叉反应。为了简化描述,本文中统一使用“负筛选”来描述从文库中去除非特异性序列的实验步骤。然而,需要注意的是,非特异结合受固相界面状态(比如靶标密度、界面带电量等)的影响很大,筛选过程中界面状态发生变化时(比如使用不同批次制备的靶标-固相载体复合物)负筛选难以消除非特异性序列。此外,非特异性吸附常常不具有序列特异性,比如静电吸附,因此利用负筛选消除固相非特异性吸附时,有可能造成序列的大量丢失,负筛选的强度不能过高。b.靶标的固相固定不仅有可能占据重要的结合位点,而且存在空间位阻,两者均阻碍适配体与靶标的结合,对小分子靶标来说这一点尤为重要。因此,在小分子靶标固定时建议增加间隔链(spacer)以降低空间位阻。c.固定的靶标可能与天然状态的结构存在显著差异,造成适配体在检测自由态靶标时亲和力差的问题。d.小分子靶标不具备便于固相固定的官能团时需要进行化学修饰,不但需要复杂的多步化学合成,在小分子中添加官能团还可能会改变其构型,进而影响与文库的特征结合,筛选得到的核酸适配体与未修饰靶标的亲和力差。尽管存在上述问题,由于筛选过程简单,基于靶标固定的方法仍然应用广泛。屈锋课题组[37]对2015―2019年的小分子毒素的核酸适配体筛选方法进行了列表总结,17种毒素中有12种毒素的核酸适配体利用基于靶标固定的方法筛选获得。
有趣的是,目前报道的特异性最好的几条小分子靶标和金属离子的适配体都是通过靶标固定的方法获得的[1]。适配体领域的国际著名专家LI Ying-Fu教授课题组[1]最近的综述中列出了目前报道的特异性最高(非靶标-适配体与靶标-适配体的KD比值大于1 000)的6个靶标的核酸适配体,其中3条为小分子和离子的适配体,分别为L-精氨酸的RNA适配体Ag.06、双酚A的DNA适配体3#和铜离子的DNA适配体Cu-A2。这3条适配体全部是通过基于靶标固定的SELEX获得的。我们认为这可能是由于靶标的界面固定提高了筛选压力,适配体与靶标只有满足更高的结构匹配,才能克服空间位阻的压力。
该方法的关键是靶标的固定和选择文库非特异性吸附最小化的实验条件。我们团队曾经以凝血酶和链霉亲和素的适配体为例,系统研究了实验条件对文库富集效率的影响,发现高靶标密度、活化后未封闭的羧基界面、低文库浓度、文库进行淬冷热处理、使用单链文库而非双链变性文库、将结合序列进行热洗脱均有利于特异性文库富集[75]。尽管我们的研究以蛋白质靶标为例,可以预见基于小分子靶标固定的筛选方法的筛选效率受到界面化学等因素的影响更大,甚至导致筛选失败。
2.2.2 基于文库固定的筛选技术——Capture-SELEX
为了避免靶标固定所带来的各种问题,2005年加拿大的LI Ying-Fu课题组[29]首次报道了将文库固定在磁珠上的筛选方法。2012年该方法正式被Stoltenburg课题组命名为Capture-SELEX[76]。同年Stojanovic课题组[35]建立了优化的Capture-SELEX流程,目前已成为小分子靶标适配体筛选应用最广的方法之一。Capture-SELEX与传统SELEX筛选过程大致相同。主要区别是前者将文库固定在固相上,而后者是将靶标固定在固相上。Capture-SELEX将生物素标记的与文库中固定序列互补的短链核酸作为捕获链,通过与随机文库杂交,将文库固定在链霉亲和素修饰的固相载体上。固定的文库与游离的靶标结合,诱导文库发生构象变化,使文库被释放到溶液中,较弱或未结合的序列仍被保留在固相载体上。Capture-SELEX筛选得到的适配体常常属于SSA,即核酸适配体与靶标结合前后的二级结构变化较大。目前报道的大量核酸适配体传感器均基于SSA的构象变化,因此Capture-SELEX技术在筛选SSA时具有独特优势。影响Capture-SELEX效率的因素主要包括文库设计、正筛靶标浓度、负筛选靶标及其浓度、文库的自解离。Stojanovic等[15]在2016年报道了优化的Capture-SELEX的筛选流程。下面将结合近年来报道的利用Capture-SELEX技术筛选的36个靶标的实验条件和结果(表3),评述Capture-SELEX的实验细节对筛选结果的影响。

Table 3 Experimental conditions and results for the isolation of small molecule and ion-binding aptamers via Capture-SELEX表3 Capture-SELEX筛选小分子靶标和离子的核酸适配体的实验条件和结果
a.三种文库设计及其靶标适用性
Capture-SELEX中使用的文库由随机序列、对接序列和引物序列3部分组成。捕获链与对接序列互补((15±2)个碱基)。适当的互补长度不仅保证了随机文库的固定效率和稳定性,还确保了亲和序列的洗脱率。与捕获链相互补的对接序列的最佳Tm在36~40°C之间[77]。
文库中的对接序列有3种设计方式。第一种设计中对接序列位于等长[42,78]或者不等长[29]两段随机区域之间。第二种设计中对接序列位于随机序列一侧的PCR引物区,两端的引物区不存在稳定的互补序列[79]。第三种设计与第二种设计基本相同,差异在于文库的两端引物区存在8~10个碱基的互补序列[15,35]。目前小分子靶标核酸适配体筛选时多采用第三种文库设计。在这种设计中当文库与小分子靶标结合时,更利于茎环结构的形成,便于文库脱离固定相。
我们利用第一种文库设计进行多种蛋白质靶标核酸适配体的筛选时均获得成功[42,78],但是利用相同的文库设计进行三磷酸腺苷(ATP)适配体筛选时失败(未报道)。有趣的是,第三种文库设计在筛选蛋白质靶标核酸适配体时失败[15]。不同文库设计在靶标适用性上的差异,应该与核酸适配体与不同类型靶标的结合模式的差异密切相关。
b.正筛靶标浓度对适配体亲和力的影响
提高筛选压力是提高核酸适配体亲和力的常用策略。根据表3的数据,在进行小分子靶标(或者离子)的适配体第一轮筛选时,正筛靶标浓度在50 μmol/L~5 mmol/L之间。36例筛选中14例的正筛靶标浓度为100 μmol/L,7例的正筛靶标浓度为1 mmol/L。随着筛选的进行,或者保持正筛靶标浓度不变(14例),或者逐步降低(22例)。正筛靶标浓度降低的幅度差异很大,2例金属离子适配体筛选的例子中正筛靶标浓度均降低至原来的1/10 000,小分子靶标适配体筛选的例子中正筛靶标浓度降低到原来的1/1.67~1/5 000,绝大多数降低至原来的1/100或稍高。36例筛选所获得的最佳适配体的KD差距很大,从0.1 nmol/L到71.94 μmol/L。其中KD大于1 μmol/L的有7例,小于100 nmol/L的20例。在这些筛选工作中使用了不同的KD测试方法,尽管不同方法的测试结果会存在不一致性,但5个数量级的差异足以说明Capture-SELEX筛选得到的适配体的亲和力差异很大。
最近美国和加拿大的两个课题组分别开展系统研究,研究结果均显示低的正筛靶标浓度更有利于高亲和力适配体的富集。第一个工作中正筛靶标氟尼辛的浓度从第一轮的100 μmol/L逐步降低到第15轮的10 μmol/L[69];第二个工作中正筛靶标腺苷的浓度从第一轮的5 mmol/L逐步降低到第12轮的1 μmol/L[70]。第一个工作中氟尼辛的浓度从第一轮的600 μmol/L逐步降低到10 μmol/L时,文库富集效率并不高[69]。然而从表3中的数据看,使用高浓度的正筛靶标进行筛选,比如1 mmol/L的氟喹诺酮类药物[80]或者玉米赤霉烯酮[81],也可以得到高亲和力的核酸适配体,KD分别为0.1~56.9 nmol/L和(15.2±3.4)nmol/L。使用低浓度的正筛靶标进行筛选,比如100 μmol/L的有机磷农药[82]或者皮质醇[83],所得到的核酸适配体的亲和力也不高,KD分别为0.8~2.5 μmol/L和16.1 μmol/L。因此,对于不同靶标,正筛靶标浓度和KD值之间不存在明确的相关性,关键取决于靶标本身的结构。
c.负筛靶标种类和浓度对适配体特异性的影响
和其他SELEX技术一样,负筛选是Capture-SELEX提高适配体特异性的主流方法[38]。小分子靶标的核酸适配体按照特异性可以划分为靶标特异和大类特异两大类,在分析测试中分别用于对特定靶标的高特异性检测和大类特异性检测。通常同时采用化学结构差异大的靶标和结构类似物两大类分子进行负筛选,来获得靶标特异性核酸适配体;采用化学结构差异大的进行负筛选,采用结构类似物进行正筛选,来获得大类特异性核酸适配体。
在已报道的筛选工作中,负筛选的实验条件选择差异很大。表3所列的36个例子中,有20例没有进行负筛选,其他的2~7轮开始第一次负筛选,最常见的从4~6轮开始。由于小分子的结构简单,结构类似物数量多,筛选靶标特异的核酸适配体通常更具有挑战性。引入结构类似物进行负筛选时,如果浓度过高,有可能造成筛选失败[69]。负筛靶标的浓度多数与正筛靶标浓度相当,随着筛选轮数的增加,保持不变,或者逐步增加或者降低。比如盐酸克伦特罗[84]和精胺[85]的高特异性核酸适配体的筛选,用于负筛的结构类似混合液的浓度随着筛选轮数增加逐步下降。值得指出的是,20例没有进行负筛选的筛选过程也获得了特异性较好的核酸适配体。随着高通量测序和高通量表征技术的发展,具有高靶标特异性或者大类特异性的适配体可以通过高通量表征测试获得。
理论上来讲,目前依靠负筛选来获得高靶标特异性核酸适配体的策略存在明显的局限性。一方面由于负筛靶标的数量是有限的,常常仅是实际样品中可能存在的结构类似物的一小部分,因此通过负筛选获得仅对正筛靶标高特异性的核酸适配体存在很大随机性。比如上述利用降低正筛靶标浓度获得高亲和力的氟尼辛的核酸适配体的例子中,当负筛选靶标包含结构类似物时,正筛的洗脱比甚至小于负筛选的洗脱比,文库富集不理想,当负筛选时去掉结构类似物时,文库对正筛靶标产生了较理想的富集,但是最终富集程度最高的适配体虽然具有高的亲和力,但对结构类似物的特异性不理想(40%的交叉反应)[69]。此外,Capture-SELEX的第三种文库设计方法尽管目前应用广泛,但是这种末端互补的文库设计有利于具有三向结构(three-way junction)的序列的富集,而这类结构的靶标特异性差[8,35]。
d.文库的自解离
Capture-SELEX的一个固有问题是固定文库的自解离[77]。文库的自解离导致文库的富集效率低,所需要的筛选轮数通常较多(8~18轮,绝大多数12~16轮,表3)。为了尽可能地减小文库的自解离,通常使用高离子强度的缓冲液,可能对某些弱相互作用是不利的,比如静电吸引作用。另外,为了减小自解离的背景信号,通常需要在正筛选之前进行多次的清洗(一般10~40次),不但操作繁琐,而且会造成文库多样性的丢失。
2.2.3 均相筛选技术
均相筛选方法中靶标与适配体均不被固相固定,处于自然状态,这种条件下的分子互作不受界面因素的影响。1990年Gold课题组[2]筛选T4 DNA聚合酶时采用均相孵育文库和靶标,随后利用醋酸纤维素膜分离与靶标蛋白结合的适配体,这一筛选技术本质上属于均相筛选技术。由于该项技术基于蛋白质在醋酸纤维素膜上的强非特异性吸附,小分子靶标不具有这种吸附能力,因此该技术不能用于小分子靶标核酸适配体的筛选。为了克服醋酸纤维素膜分离效率低的不足,2004年Mendonsa和Bowser[28]首次将CE和SELEX技术进行结合,利用复合物和游离适配体在电场中迁移率的差异分离与靶标结合的适配体。由于CE极高的分离效率,CE-SELEX可以高效筛选蛋白质靶标的核酸适配体。但小分子靶标与适配体复合物的迁移率与游离的适配体非常相似,因此该项技术很少应用于小分子靶标核酸适配体的筛选。
韩国的Man Bock Gu课题组[34]于2012年建立了一种适用于均相核酸适配体筛选技术(GOSELEX),该方法基于氧化石墨烯(GO)对单链DNA(ssDNA)的吸附作用比对双链 DNA(dsDNA)或靶标-核酸分子复合物的吸附力强的特点。利用该方法成功筛选到了脂肪因子烟酰胺磷酸核糖转移酶(nicotinamide phosphoribosyl transferase,Nampt)蛋白的适配体。先将文库和靶标孵育形成文库-靶标复合物,然后加入GO,未与靶标结合的ssDNA被吸附到GO上,通过离心除去,而结合的文库仍被保留在上清液中,用于下一轮筛选。2014年该课题组进一步建立了多重GOSELEX(multiple GO-SELEX)技术,成功获得了3种小分子农药的适配体[86]。其方法类似于Capture-SELEX,先将文库和GO孵育,使文库吸附在GO上,然后加入靶标,与靶标发生强结合的文库从GO上解离下来,回到溶液中用于下一轮筛选。在GO-SELEX中文库通过物理吸附固定在GO上,无需在文库中设计对接序列,更为简单。2018年王周平团队[87]报道了用磁性还原氧化石墨烯代替GO用于3种小分子海洋生物毒素适配体的筛选,进一步简化了分离步骤,提高分离效率。近三年利用GO-SELEX筛选小分子靶标核酸适配体筛选的论文数量与Capture-SELEX相当(表4)。总体上GO-SELEX筛选轮数比Capture-SELEX少,所获得的适配体的亲和力也多在nmol/L水平。
2.3 提高核酸适配体性能的筛选方法
随着筛选技术的成熟、筛选成功率的提高,具有更好实际应用价值的体内高稳定性、高特异性、高亲和力的适配体筛选方法研究成为近几年的研究热点。
2.3.1 体内高稳定性核酸适配体的筛选
a.化学修饰核酸适配体的筛选
化学修饰是目前提高适配体体内稳定性最常用的方法。30年来,核酸的化学修饰从最初的磷酸骨架和戊糖的修饰,拓展到碱基修饰,甚至引入人工碱基[9]。提高核酸抗酶降解能力的主要化学修饰包括:硫取代磷酸骨架上的非桥接氧;戊糖2'位的氟(—F)、氨基(—NH2)、叠氮基(azido,—N3)或甲氧基/OMe(—OCH3)修饰;锁核酸(LNA)。多种多样的碱基修饰,包括萘基(Nap—)、苄基(Bn—)、色胺基(Trp—)等疏水性官能团,用来增强与蛋白质间疏水相互作用,提高适配体的亲和力。
可以直接对化学修饰的文库进行适配体的筛选,也可以对含天然碱基的文库筛选所获得的适配体进行化学修饰。后者需要大量的优化,直接筛选化学修饰的适配体更为直接。美国Somalogics公司研发的SOMAmers筛选技术,利用在2′-脱氧尿苷的碱基C5位置上进行各种各样的化学修饰,获得了3 000多种蛋白质的核酸适配体,性能可以媲美抗体。2013年Hirao课题组[88]首次开发了将高疏水的Ds与Px人工碱基引入文库进行筛选的方法,所获适配体的亲和力比仅含天然碱基的适配体高100倍以上。2015年Benner课题组[89]合成了新的基于氢键配对的碱基对P和Z,该碱基对表现出了比G-C碱基对更高的稳定性。但这类方法需要特殊的化学合成技术、DNA扩增酶和测序技术,因此未得到广泛使用[9]。
b.镜像核酸适配体的筛选
传统的核酸适配体筛选方法,筛选出的核酸适配体为D型核酸,在人体血清中极易被迅速降解,而镜像核酸适配体(mirror-image aptamer)为L型核酸,无法被天然核酸酶降解,具有高稳定性。镜像筛选技术(mirror-image selection)利用手性分子具有旋光性的特点,从D-核酸适配体文库中筛选出与L-靶标分子结合的核酸适配体,再将其合成为L-核酸适配体,即筛选出对D-靶标分子有高亲和力的L-核酸适配体。1996年,Klußmann等[25]利用该技术从D-核酸适配体文库中筛选出58 nt的L-RNA核酸适配体,其能在溶液中与天然D-腺苷结合,KD为1.7 μmol/L。且L-RNA核酸适配体对D-腺苷的结合亲和力是其对L-腺苷的亲和力的9 000倍。此外,Maasch等[90]采用此方法筛选出与高迁移率族蛋白A1(HMGA1)特异性结合的镜像适配体NOX-A50,其KD为7 nmol/L。然而,镜像靶分子不易合成,特别是对于具有大尺寸、存在大量翻译后修饰(PTM)和低体外折叠效率的蛋白质。在实践中,大多数生物学上重要的靶分子都不能根据目前的技术进行化学合成[56]。因此,2022年朱听等[56]进一步改进该筛选技术,直接从L-DNA核酸适配体文库中筛选L-DNA核酸适配体,避免了合成L-靶标分子。成功选择并评价出数种对天然人凝血酶有高亲和力的L-DNA适配体,其中KD最好的为22 nmol/L。
c.环状核酸适配体的筛选
环状核酸(CNA)相比于开链适配体具有更高的稳定性,可有效抵御核酸外切酶的降解[91],广泛用于基于滚轮扩增(rolling cycle amplification,RCA)的生物传感器[92]。将适配体设计成环形结构时可能导致适配体亲和力降低。2019年,LI Ying-Fu课题组[10]首次使用了环状DNA文库进行筛选,获得了谷氨酸脱氢酶(glutamic dehydrogenase,GDH)的环状核酸适配体。所获得两条环状DNA适配体以高亲和力与GDH不同位点结合,展现出了结合位点多样性和高亲和力的优势。环状DNA适配体可使用基于固定靶标于磁珠上,后加入文库进行孵育的方法进行筛选,也可使用基于均相孵育,后加入磁珠捕获的方法进行筛选[93]。在筛选过程中的PCR及文库制备步骤包括滚轮扩增反应和酶切等,要注意优化反应条件[94]。
2.3.2 提高核酸适配体特异性的筛选方法
核酸适配体的特异性是核酸适配体极为重要的性能指标,然而大约1/3的SELEX文献中没有进行核酸适配体的特异性测试。而且特异性测试缺乏标准,绝大多数仅仅是测试1~2个浓度下靶标与其他测试物信号响应的差异,定量比较核酸适配体与靶标和测试物KD的报道极少。此外,特异性测试中测试对象的选择比较随意,有些选择与靶标结构差异大的进行测试,有些选择常见的蛋白质或者小分子进行测试,有些甚至选择完全不相关的分子进行测试。急需建立核酸适配体特异性测试的规范。
提高核酸适配体的特异性目前主要依靠负筛选。用核酸适配体与靶标和测试物KD的比值来衡量核酸适配体的特异性,绝大多数适配体的特异性位于1~10之间,少量位于10~100之间,有6个适配体(1个RNA适配体和5个DNA适配体)的特异性大于1 000[1]。然而实践证明目前报道的核酸适配体的特异性常常不能满足实际需要,在实际应用中存在高交叉反应和背景干扰。
提高核酸适配体的特异性的一个常用方法是2~3种SELEX技术的联用,以消除一种SELEX技术可能引入的非特异性序列。2021年我们团队报道了modular-SELEX,将MCP-SELEX、Capture-SELEX、tissue-SELEX 3种方法联合筛选PD-L1的核酸适配体[51]。2021 年许丹科团队[54]报道了precision-SELEX,先后以纯蛋白质靶标KPC-2和细菌为正筛靶标,筛选KPC-2表达的细菌的高特异性核酸适配体。2023年Citartan等[65]报道了tripartite-hybrid SELEX,联合使用基于硝化纤维滤膜、微量滴定板和非变性 PAGE 3种分离技术的SELEX,筛选LipL32的RNA适配体。此外,在实际应用环境中进行适配体筛选是提高适配体特异性的一种有效手段。2023年Park团队[67]报道了微生理系统SELEX(MPS-SELEX),以双通道人脑微血管内皮细胞/星形胶质细胞/周细胞界面为筛选平台,筛选具有高血脑穿透性和特异性的适配体。
核酸适配体的高特异性主要决定于核酸适配体与靶标的结构互补性。提高筛选文库的序列多样性有利于筛选到具有更优结构互补性的核酸适配体。突变是自然界推动生物进化的原动力。与自然界中的进化过程不同,传统的SELEX方法中,只有PCR扩增步骤可以引起低频率的突变,即SELEX筛选技术本质上是对初始文库中已经存在的序列进行富集,而不是进化出新的功能性序列。为了解决文库多样性不足的问题,报道了利用低保真的PCR扩增酶来提高点突变频率的方法,但最后得到的新序列与初始文库序列相差不大[95-97]。非均相随机DNA重组技术也被用来提高序列多样性[98]。然而上述两种技术所引入的突变都是随机不可控的,与靶标亲和力进化无关。2021年我们团队将II型限制性内切酶-Alu I作为工具运用于核酸适配体筛选过程中,诱导产生与亲和力相关的文库突变(REase-SELEX),成功获得了高特异性PD-L1的核酸适配体,实现了对临床多种癌组织切片的PD-L1表达水平的荧光成像,与免疫组化的结果一致[50]。
获得对小分子靶标具有高特异性的适配体尤其困难。如上所述,尽管目前报道了少数几种具有很高特异性的小分子和金属离子的适配体,但只是个例,具有随机性。我们团队最近与军事医学科学院的邵宁生研究员合作,将MCP-SELEX技术用于高特异性同型半胱氨酸(homocysteine,Hcy)适配体的筛选[71]。该方法基于适配体与靶标结合会阻碍靶标上官能团发生化学反应效率的现象[99]。当适配体与Hcy的氨基(氨基酸的共有官能团)结合力强时,该氨基不能与磁球上活化羧基发生化学偶联;反之,当适配体与Hcy的侧链(氨基酸的特有官能团)结合力强时,Hcy上的氨基能够与磁球上活化羧基发生化学偶联。利用上述效应,从Hcy与文库的混合物中,通过氨基和活化羧基之间的化学偶联磁性富集出对Hcy的巯基侧链具有高特异的适配体。所获得的Hcy适配体对还原态Hcy的亲和力远高于氧化态Hcy,且对含巯基其他氨基酸(甲硫氨酸、胱氨酸)、其他含硫小分子(谷胱甘肽、二硫苏糖醇)和氨基酸均无显著交叉反应。利用该适配体构建的光纤传感器实现了对临床样本中Hcy总量的快速检测,与临床经典的酶循环法的测试结果一致。这是利用上述独特“适配体保护基团效应”进行高特异性小分子适配体的初次尝试,其是否具有通用性还有待检验。
2.3.3 提高核酸适配体亲和力的筛选方法
核酸适配体的亲和力是其实现分子识别的最重要的性能。提高筛选压力来提高核酸适配体的亲和力是目前最常规的方法。通过SELEX技术获得的核酸适配体的蛋白质靶标的KD通常在0.1~100 nmol/L范围,少数两价的核酸适配体的KD达到1~100 pmol/L范围。小分子靶标的核酸适配体的KD通常在1 nmol/L~100 μmol/L范围。除了上述降低正筛靶标浓度、使用化学修饰文库进行筛选的方法之外,还有一些提高适配体亲和力的方法,但应该并不广泛。2000年Koch等[100]建立了photo-SELEX技术,用5-溴-2'-脱氧尿苷代替胸腺嘧啶,当蛋白质靶标与适配体结合时发生光交联反应,将蛋白质与适配体共价偶联,然后使用严苛的清洗条件进行清洗,从而获得人碱性成纤维细胞生长因子(bbFGF(155))的高亲和力适配体。通过工程化设计或者体外筛选高价的核酸适配体是大幅提高核酸适配体的一种技术手段。2008年谭蔚泓院士团队[101]率先展示了凝血酶的二价核酸适配体比单价适配体具有更好的抗凝血功能和1/50的解离速率常数。2017年该团队报道了二价的环状DNA比单价适配体具有更很高的亲和力、热稳定性和抗酶降解能力[102]。工程化设计通常需要大量的优化,为了克服这一问题,2012年Soh课题组[103]建立了直接筛选凝血酶的二价适配体的SELEX方法,文库两端固定序列分别包含凝血酶适配体TBA15和TBA29,两者之间通过随机序列连接。二价适配体的设计需要一对能够结合在蛋白质不同位点的核酸适配体,为了筛选结合不同位点的适配体对,该课题组先后建立了几种SELEX方法,但方法较为繁琐[104-105]。小分子靶标多价核酸适配体的设计更为有限。蛋白质靶标的二价核酸适配体与靶标的两个区域协同结合,因此亲和力很高,KD可以比单价的适配体低1~3个数量级。小分子靶标的多价核酸适配体与多个小分子结合,通常结合位点的增多仅能够小幅提高亲和力。比如我们课题组2022年报道了真菌毒素交链孢酚(AOH)的单价、二价和三价核酸适配体,KD分别为701 nmol/L、445 nmol/L和274 nmol/L[106]。小分子靶标的多价核酸适配体更适合于用于亲和柱来提高柱容量。
按照传统的筛选方法进行筛选时,不少小分子靶标由于结合位点少、结构拥挤、空间结构多样等各种原因,难以获得高亲和力的适配体。哥伦比亚大学的Stojanovic课题组[107]利用将小分子与有机配体或者金属配合物形成复合物的方法,结合优化的Capture-SELEX技术,成功获得了多种低表位(low-epitope)小分子靶标的高亲和力和高特异性的适配体。该课题组近期在《科学》(Science)发表了一篇筛选小分子靶标核酸适配体的新方[108]。该方法根据小分子靶标中官能团和结构开展不同的筛选路径,最终获得了以前筛选失败的几种小分子靶标的高亲和力的适配体。比如在对亮氨酸(leucine)的适配体筛选中,先筛选获得能够特异性结合氨基-羰基-环戊二烯基合铑(III)复合物结构的适配体,再将该适配体的序列设计到随机文库中,对能够结合亮氨酸侧链异丁基的适配体进行筛选,然后再将亮氨酸侧链的结合适配体序列设计到随机文库中,在加入铜离子的条件下,筛选对亮氨酸-铜离子复合物具有高亲和力的适配体。但是根据文章中报道的数据,所获得的适配体的特异性有限,对结构类似物存在强的交叉反应。比如,筛选获得的亮氨酸的适配体对别异亮氨酸(alloisoleucine)具有强交叉反应。另外,筛选得到的小分子药物伏立康唑(voriconazole)的核酸适配体对其结构类似物2a也具有高交叉反应。
3 核酸适配体亲和力评价技术的研究进展
3.1 常用核酸适配体亲和力评价技术概览
目前几乎所有蛋白质-蛋白质互作研究使用的常用生物物理表征技术都已用于核酸适配体的亲和力和特异性评价(表5)。这些技术大体上可以划分为均相表征技术和基于固相固定的表征技术。这些表征技术的基本原理在多篇综述中都进行了详细介绍[109-110],在本综述中不再介绍。
对于特定的核酸适配体-靶标体系,在表征方法选择时需要综合考虑多种因素。表5对这些因素进行了总结,具体包括表征技术是否需要对核酸适配体或者靶标进行固定、标记、是否需要分离核酸适配体-靶标复合物、是否适用于小分子靶标、能否进行高通量测试、样品用量、测试时间、操作的复杂程度和测试费用等参数。由于其标准化的测试流程,表面等离子体共振(SPR)和ITC被普遍认为是蛋白质靶标和小分子靶标核酸适配体亲和力评价的经典方法。但是,值得注意的是,标准化的测试流程并不能完全排除假阳性或者假阴性结果的出现。此外,由于影响各种表征技术测试结果的因素存在巨大差异,应使用至少两种表征手段来测定适配体-靶标的亲和力。特别是由于核酸适配体的尺寸相对抗体小很多,结构稳定性相对抗体差很多,空间位阻和界面非特异性吸附对核酸适配体亲和力的影响往往很大,因此在进行核酸适配体亲和力评价时至少应使用一种均相的评价技术。目前报道的核酸适配体筛选文章中对核酸适配体进行亲和力评价时,普遍存在表征方法单一(表3,4)、实验条件选择随意性强,特别是特异性测试时测试靶标的选择极不充分、KD测试数据点不充分等种种问题,亟需建立相对标准化规范。
基于固相固定的亲和力评价技术受到界面化学、靶标或者适配体固定方式等因素的影响很大,篇幅原因不在本文中进行深入评述。均相评价技术的影响因素相对简单,在小分子核酸适配体亲和力评价中应用广泛。近年来不断报道,使用不同表征技术进行小分子靶标适配体亲和力评价时测试结果不一致性的问题,亟需澄清问题所在。下面将围绕这一问题,评述均相亲和力评价技术的局限性和研究进展。
3.2 常用的均相核酸适配体亲和力评价技术局限性及其研究进展
均相亲和力评价技术无需对靶标或者适配体进行固相固定,因此能够更准确地反映出核酸适配体与靶标的相互作用强弱,避免了空间位阻的问题和界面固定的不确定性。这种情况下获得的亲和力数值通常被称为本征亲和力(native affinity)。由于排除了上述潜在的干扰,均相表征技术相比非均相的技术重现性更好。此外均相表征技术实验操作更为简单,测试成本也较低。由于这些优势,建议在核酸适配体亲和力评价时尽可能采用至少一种均相表征技术。常用的均相表征技术包括凝胶阻滞(EMSA)、纳米金(AuNP)比色法、圆二色谱(CD)法、ITC、荧光光谱/荧光极化和微量热涌动法(MST)(表5)。其中荧光法是小分子靶标核酸适配体KD测试时应用最广泛的方法(表3,4),其次是AuNP比色法和ITC法。荧光法的测试原理多种多样,可以基于荧光共振能量转移、荧光极化[111]、荧光增强等,体系比较简单,本文不再一一介绍,可以参见相关综述类或研究性论文[109-110]。AuNP比色法和ITC法的测试原理单一,但其测试结果受靶标和适配体的性质影响大,下面就这两种表征技术进行较为详细的评述。
3.2.1 AuNP比色法
分散状态的10~30 nm直径的AuNP由于特征等离子共振吸收,呈现酒红色。当纳米金聚集时,特征等离子共振吸收消失,呈现灰蓝色。AuNP比色法测定核酸适配体亲和力的原理基于分散态和聚集态AuNP紫外可见吸收的差异。当AuNP表面吸附核酸适配体时,核酸适配体对AuNP起到保护作用,增强AuNP抵制盐离子诱导聚集的能力,此时体系呈现红色。当溶液中游离的靶标与AuNP表面的核酸适配体特异性结合时,核酸适配体离开AuNP表面,AuNP发生盐离子诱导的聚集,此时体系由红色变为紫色甚至灰色。靶标的浓度越高,AuNP的聚集越严重。对含不同浓度靶标的样品进行特征吸收峰处吸光度的测定。以靶标浓度为横坐标,吸光度为纵坐标绘制结合曲线,就可以实现对KD的测试。以不同的潜在干扰物代替靶标,就可以实现对核酸适配体的靶标特异性的测定。交叉反应性越高,AuNP的聚集越严重。此外,AuNP便于合成、成本低、检测快捷、结果可视化,可以转化为比色传感器,因而AuNP法是应用广泛的一种核酸适配体均相表征技术[6,112]。
尽管AuNP比色法具有多重优点,但是存在假阳性的风险。这是由于AuNP界面可以非特异性吸附多种多样的物质,当AuNP对靶标的吸附力比较强时,靶标在AuNP上的非特异性吸附会直接取代AuNP上吸附的核酸适配体,而非由于核酸适配体与靶标结合,使得核酸适配体与AuNP的吸附解离。加拿大滑铁卢大学的刘珏文课题组对文献中基于AuNP评价的砷和卡那霉素A的核酸适配体的实验数据提出质疑,通过系统的对比实验证实了亚砷酸根和卡那霉素A与AuNP存在强的吸附力,含负控制链体系在不同浓度亚砷酸根存在时所引起的AuNP的聚集程度,与核酸适配体所引起的没有差异[113-114]。此外,在高浓度盐溶液中DNA提高AuNP的能力与DNA的组成、二级结构和长度密切相关,比如腺嘌呤(A)碱基在AuNP上的吸附力最强,对AuNP的保护性也最强,充分吸附的情况下,较长的DNA能够更好地防御AuNP的聚集。因此在利用AuNP比色法进行核酸适配体的截短和工程化设计的序列的亲和力对比时,需要考虑到这些因素的可能影响。建议在使用AuNP比色法时,首先对靶标及其特异性测试中所使用的分子是否显著影响AuNP在高浓度盐溶液中的稳定性进行测试。另外,采用其他亲和力评价方法进行进一步验证。
由于蛋白质具有多个能够与AuNP吸附的官能团,微量的蛋白质能够引起AuNP的聚集,因此上述基于DNA防御AuNP聚集的比色方法不能用于蛋白质靶标的核酸适配体的亲和力和特异性评价。我们团队2020年报道了一种反向显色的AuNP方法用于蛋白质靶标的核酸适配体KD的测定,称为Nano-Affi[115]。该方法基于吸附质的带电状态显著影响AuNP聚集程度的现象:带正电或接近电中性的靶标(蛋白质)由于静电吸引或疏水相互作用,非特异性吸附在带负电的AuNP的表面,显著降低AuNP之间的电荷排斥作用,从而引起AuNP的快速聚集;靶标(蛋白质)-核酸适配体复合物具有比靶标更多的负电荷,因而复合物在AuNP上非特异性吸附后没有显著降低纳米金的负电量,因此AuNP聚集程度较小或不发生聚集,由此利用AuNP的颜色变化或粒径变化进行蛋白质靶标的核酸适配体KD测定。此外,AuNP具有超高的消光系数,比有机染料至少高出1 000倍以上,例如13 nm AuNP 为 2.7×108L·mol-1·cm-1。纳摩尔每升浓度的AuNP发生聚集时就可以肉眼观察到从粉色(酒红色)到蓝色/灰色的颜色变化,因此AuNP法进行蛋白质靶标的核酸适配体评价时所需要蛋白质的浓度低,每个测试仅需要0.2~4 pmol的蛋白质,当蛋白质样品量小或者价格昂贵时尤其具有吸引力。此外,我们也成功地利用该方法评价了卡那霉素A的核酸适配体(未报道),克服了上述靶标诱导AuNP聚集方法的假阳性问题。
3.2.2 ITC法
ITC被普遍认为的测试核酸适配体亲和力的“金标准”方法[116]。ITC基于测定分子互作过程的热量变化的准确测定,实现对核酸适配体KD以及热力学函数的测定。ITC在工作时需要两个工作单元,分别是样品检测单元和标准参考单元。样品池中盛有大分子或核酸适配体等受体,进样针中装载配体,参比池中盛有水。工作时利用进样针将配体溶液注入样品池中,这一过程会伴随热量变化直至达到结合平衡。由于滴定过程是逐滴进行的,所以结合带来的温度变化可以被实时监测并通过外部的加热器保证两池间的温差为零。通过实时采集加热器功率从而得到时间和功率的关系图,经过拟合可以得到结合过程的焓变数值和KD。进而根据等温等压条件下的热力学方程(∆G=∆H-T∆S,∆G=RTlnKD),获得吉布斯自由能(ΔG)和熵变(ΔS)[117]。该方法可对100 μmol/L~1 nmol/L范围内的结合亲和力进行测定。
ITC法的优点是一次滴定不仅可以获得KD,还可以获得热力学函数值,为结合模式研究提供依据,这是其他表征技术都不具备的。主要缺点是样品的用量大、检测通量低。近些年来,我们以及文献都报道了ITC失败的多个案例,包括亚砷酸根[118]、氨苄西林[119]、氯霉素[120]、乙醇胺[121]、交链孢酚[106]的核酸适配体等。然而这些核酸适配体的亲和力被多种其他方法所证实,说明ITC方法存在局限性,未必适用于某些核酸适配体的KD的测定。
ITC是基于结合热测定的表征技术。核酸适配体与靶标的结合可以是焓驱动、熵驱动、焓和熵共同驱动的三种结合过程。对于焓变小的结合过程,以及稀释热过大的过程,均可能导致ITC测试的失败。在ITC数据解析过程中需要更为严谨和慎重。
4 展望
30多年来,核酸适配体筛选技术和亲和力评价技术不断发展。然而目前走向实际应用的适配体数量仍然非常有限。核酸适配体筛选与评价技术还需进一步完善,至少应包含以下几个研究方向。
a.如何获得高特异性的核酸适配体是未来筛选技术应该关注的重点。如何获得高特异性的小分子靶标的核酸适配体依然富有极大地挑战性。由于核酸适配体可以与多种多样信号放大技术兼容的特点,具有nmol/L范围KD的核酸适配体已经能够满足绝大多数应用场景检测灵敏度的需求。由于体外筛选压力的复杂程度远小于体内抗体的产生过程,相比抗体,核酸适配体的识别能力更容易受到样品基质、传感界面的影响。对高特异性核酸适配体的需求因此高于进一步提高核酸适配体的亲和力。理论上不可能获得绝对特异性的核酸适配体,只能筛选获得在特定应用场景下满足特异性需求的核酸适配体,因此在筛选过程的实验条件选择时应密切结合实际应用场景。
b.人工智能大数据分析技术将助力高性能核酸适配体的发现。高通量测序的数据利用率极低,缺少快速、准确分析序列二级结构的工具。候选序列的筛选还主要依赖丰度排序和一级结构中的保守序列出现的频次。不少的研究数据均已表明,更有性能的核酸适配体未必在丰度上占据优势。随着人工智能和技术辅助技术的快速发展,将极大地助力高通量序列分析和高性能核酸适配体的识别与序列优化设计。
c.核酸适配体评价技术体系亟需完善。2019年和2021年国家市场监督管理总局、中国国家标准化管理委员会先后发布了《核酸适配体体外筛选技术导则》(GB/T 38137-2019)和《核酸适配体亲和力和特异性评价技术导则》(GB/T 40187-2021)。但是上述两个导则,内容不够具体,对实际核酸适配体的筛选和评价的指导性极为有限。近些年来核酸适配体筛选技术和评价技术快速进展,涌现出大量新方法新技术。特别是对核酸适配体的亲和力(KD)和特异性评价,亟需建立相对标准化的具体实验规范和定量方法。
建议广大从事核酸适配体筛选领域研发的技术人员在KD评价时至少使用两种不同的表征技术,其中至少一种为均相表征技术。在进行蛋白质靶标适配体KD评价时,不但要以膜蛋白高表达的细胞为靶标进行KD测试,还应该尽可能地以纯化蛋白质为靶标进行测试。鉴于动力学测试KD的方法受界面探针密度、界面电荷、靶标浓度等因素影响较大,尽可能地基于热力学平衡的方法进行KD的测定。在进行特异性评价时,应选择尽可能多的结构类似物和实际应用场景相关的可能干扰物进行测试。考虑到交叉反应性与测试物的浓度密切相关,应该在实际应用场景中的常见浓度下进行测试,结构类似物和可能干扰物的浓度可以比实际应用场景的浓度更高。建议分别测试核酸适配体对正筛靶标、最相关的结构类似物或者可能干扰物的KD,而不仅仅是定性比较。
尽管高通量的蛋白质芯片技术、微液滴(微球)展示技术为核酸适配体的高通量评价提供了策略。但由于其价格昂贵,适用范围的局限性,并未得到广泛推广应用。研发低成本、高通量的核酸适配体评价技术对于阐明文库进化规律,推动高性能核酸适配体的识别与序列优化设计的人工智能化均具有重要意义。
