多维注意力机制与选择性特征融合的图像超分辨率重建
2023-10-02邵剑飞邵建龙冯宇航
温 剑,邵剑飞*,刘 杰,邵建龙,冯宇航,叶 榕
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.云南警官学院 云南警用无人系统创新研究院,云南 昆明 650223)
1 引言
单图像超分辨率(Single Image Super-resolution,SISR)的任务是将低分辨率图像(Low Resolution,LR)通过重建技术获得更自然逼真的高分辨率图像(High Resolution,HR)。通常图像的分辨率越高,代表细节纹理带来的视觉效果越好。由于硬件设备采集图像的过程中受自然环境、数字设备成本或人为干涉因素的影响,拍摄的图像不清晰,这会降低图像分类[1]、无人机侦察[2]、医疗辅助[3]、遥感测绘[4]等视觉任务的性能。图像超分辨率(Super Resolution,SR)重建算法不受平台的限制,降低了设备的硬件成本,并有效提高了图像分辨率,因此成为计算机视觉领域具有重要研究意义的底层任务之一。
多年来,为解决SR 重建任务中的非适定性问题,早期的超分辨率研究包括基于插值方法和基于先验方法。插值方法主要有双线性插值[5]和双三次插值[6],实现从LR 到HR 的映射,该方法虽然操作简单,但应用范围及超分辨率效果较差,因此,基于先验的方法被提出。孙玉宝等[7]利用稀疏先验信息获得线性组合预测HR 图像,潘宗序等[8]利用自相似先验信息引导模型实现超分辨率重建,然而这种依赖先验信息的方法需要过于耗时的代价完成任务,在一定程度上阻碍了研究者的工作。
近年来,基于深度学习的深度卷积神经网络(Convolutional Neural Network,CNN)依靠其灵活的端到端架构和卓越的学习能力,得到了广泛的应用。Dong 等[9]于2016 年利用基于卷积神经网络提出了一个构建3 层神经网络来学习LR 到HR 的映射,其图像超分辨率重建性能验证了基于深度学习方法的竞争力。随后,Dong 等[10]提出了在网络最后一层采用Bicubic 上采样方式放大图像尺寸的算法,受该方法启发,相关研究人员设计出大量具有堆叠卷积层特征的网络模型,通过实验发现,深度的堆叠网络虽然可以有效提高重建性能,但在训练过程中也出现了梯度消失或梯度爆炸的问题。因此,Kim 等受ResNet[11]启发,设计了更深的卷积超分辨率网络(Super-Resolution using Very deep SR Network,VDSR)[12],将残差网络设计到SR 模型中,利用残差学习技术获取遗失的特征信息,以防止梯度爆炸或消失。Kim 等又通过跳跃连接来引导模型融合全局和局部特征,提出了降低模型复杂度的递归神经网络算法[13]。Tai 等[14]利用递归学习和门控单元构建了深度为80 层的网络模型,该模型能够提取多级特征信息,提高预测图像质量。Lim 等[15]提出了基于增强的深度残差图像超分辨率网络(Enhanced Deep Residual Network for Single Image Super-Resolution,EDSR),通过去除残差块中的批归一化层来降低模型复杂度,重建后的HR 图像展现出良好的视觉效果和性能指标。Zhang 等[16]受EDSR 的启发,在模型基础上引入注意力机制完善残差网络,模型增强了不同通道的相互依赖型,采用自适应性过滤冗余的低频特征,进一步提高了重建后的SR 质量。
然而,以上模型在重建过程中需要计算大量参数,导致算法依赖具有较高算力和内存的硬件设备,过深的网络结构也会导致训练过拟合等问题。为解决此类问题,使超分辨重建任务能够在实际应用领域得到发展,一些参数较少、计算复杂度低的算法模型被提出。宋昭漾等的倒N 型网络[17],MSRN[18]和CARN[19]以略微降低图像SR 质量为代价,大规模减少参数量。另一方面,对于追求主观视觉效果更好、细节纹理丰富的计算机视觉任务,一些学者选择增大模型复杂性,从而实现提升性能指标和丰富重建图像纹理的目的,例如Ledig 等[20]提出的基于生成式对抗网络的超分辨率模型(Photo-realistic Single Image Super-Resolution using a Generative Adversarial Network,SRGAN)。Wang 等[21]在SRGAN 模型的基础上引入密集残差块作为生成器的特征提取块,改用相对判别器提升模型性能,重建后的图像SR 视觉效果卓越,但细节信息失真的特性,使此类方法不能有效应用到医学图像的SR 重建领域。
目前,主流SR 重建方法均采用尺寸为3×3或5×5 的卷积来降低参数量,但较小的感受野不能完全学习各区域的特征信息。近年来,注意力机制的有效性得到验证,并成功应用至计算机视觉领域,能够很好地捕捉图像全局信息,重建后的图像具有更加丰富的纹理特征,但同时也产生了大量冗余信息。本文提出了一种融合多维注意力机制与选择性特征融合的图像超分辨率重建方法,并构建了一种由对称组卷积块、互补卷积块和特征增强残差块组成的特征提取模块。两个并行对称的对称组卷积块用于提取不同通道间的内部信息,并使用选择性内核特征融合内部信息。互补卷积块采用多维注意力机制以并行策略动态学习核空间的四个维度,捕捉全部通道的特征,以获得更加细腻的纹理特征信息,特征增强残差块在增强特征的同时去除产生的冗余信息。最后,提出了一种丰富图像纹理,降低计算参数量的网络模型,该模型在SISR 任务中表现出优越的视觉效果和性能指标。
2 网络模型
受文献[22]启发,本文提出的网络模型的主体组件包括两个带有Relu的全维动态卷积层(Omni-Dimensional Dynamic Convolution,ODconv)、6 个具有特征提取作用的异构组块(Heterogeneous Group Block,HGB)和一个用于提取高频特征的亚像素卷积选择块,分别完成网络的浅层特征提取、深层特征提取和超分辨率重建工作,如图1 所示。具体流程为:
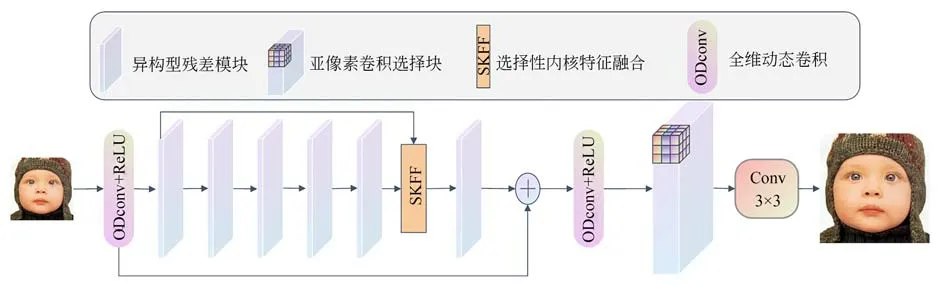
图1 融合多维注意力机制与选择性特征融合的网络结构示意图Fig.1 Schematic diagram of network structure integrating multi-dimensional attention mechanism and selective feature fusion
(1)浅层特征提取:网络第一层采用全维动态卷积从空域、输入通道、输出通道以多维注意力机制提取输入图像ILR的浅层特征信息,并使用Relu 作为激活函数,提取过程如下:
式中:ILR表示输入的初始低分辨率图像,ODconv(·)表示全维动态卷积操作,R(·)表示进行Relu 操作,F1表示经过浅层特征提取后的特征信息。
(2)深层特征提取:该部分使用5 个HGB 模块逐渐提取特征,并用第一层HGB 与第五层HCB 使用SKFF 采集特征信息,最后将浅层特征与第6 个HGB 模块进行残差连接。深层特征提取公式如下:
(3)图像重建:在深层特征提取之后,使用ODconv+Relu 对深层特征的冗余信息进行去除工作,然后使用亚像素卷积选择块进行尺度选择,选择块采用并行的上采样机制,将获得的高频特征信息递交至1×1 卷积层,以获得预测的HR 图像。重建过程如下:
式中:PUM(·)表示执行3 种不同的尺寸(X2,X3,X4)来训练模型。
2.1 选择性内核特征融合模块
选择性内核特征融合[23]作为一种动态选择卷积核的机制被提出后,在计算机视觉领域得到了广泛的关注,它在超分辨率重建任务中,通过适应性调整感受野机制在平行流间进行信息传递,提取丰富的低频特征信息,并进行特征选择和聚合。本文模型改进了一种二分支特征提取策略的选择性内核特征融合模块(SKFF),整合不同内核特征增强抗干扰能力,提高超分辨率重建泛化能力,使模型适应不同测试集的数据,如图2 所示。
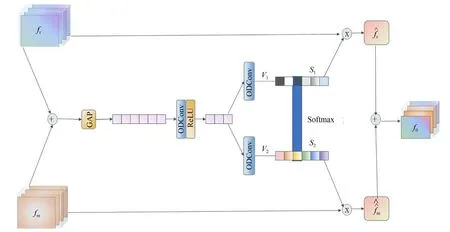
图2 选择性内核特征融合模块示意图Fig.2 Schematic diagram of selective kernel feature fusion module
该机制分为融合和选择两部分。融合是根据输入的分组数为二的两个并行信息源进行聚合,聚合后的特征为:L=fr+fm,然后将得到的特征在L∈RH×W×C的空间维度上采用全局平均池化操作来计算通道数据,通道统计数据为:s∈R1×1×C,接下来使用ODconv 对s进行缩减并生成紧凑的特征Z∈,最后再通过两个并行的ODconv 扩充通道至C,得到两个特征描述符:V1,V2。选择是两个特征描述符经过softmax函数分离不同类别的特征后,选择更具有代表性的特征S1,S2,并分别与fr,fm进行元素层面的乘积,得到特征校准的特征图后进行聚合。
2.2 异构型残差模块
在基于深度学习的超分辨率重建任务中,大多网络都采用具有有效缓解网络深度退化功能的标准残差模块提取图像的特征信息,或使用密集残差块通过网络层提取特征,但两者都会增加网络结构的复杂性,并产生模型过拟合的问题。为了解决这些问题,本文提出一种异构型残差模块提取特征,模块以对称组卷积块提取通道中的内部特征,以互补卷积块提取不同通道间的特征。两者连接增强不同通道间内部与外部的关系。为防止过多的冗余信息影响特征提取的准确率,使用特征增强残差块作为细化块,进一步融合整体和局部的低频结构特征。对称组卷积块、互补卷积块和特征增强残差块的具体结构如图3 所示。
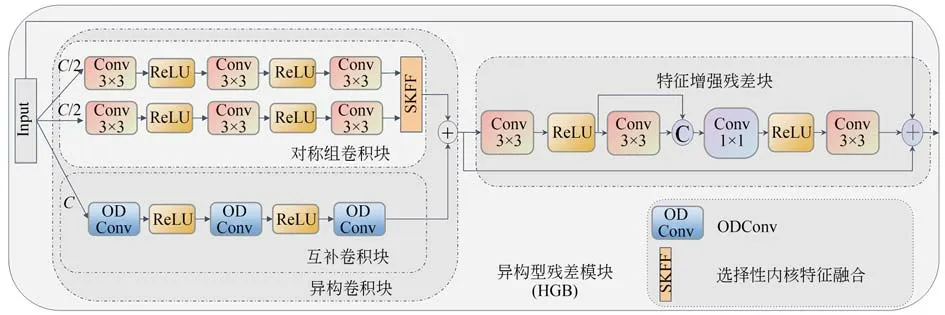
图3 异构型残差模块内部原理示意图Fig.3 Schematic diagram of internal principle junction of heterogeneous residual module
2.2.1 对称组卷积块
对称组卷积块由两个并行的三层卷积子网络分别学习所有通道的上半部分特征和下半部分特征,并通过选择性内核特征融合获得的特征,以增强所有通道内部的关联性。具体来说,子网络的第一层和第二层都是Conv3×3+Re lu,第三层是Conv3×3。每层的输入通道和输出通道都是32 个,三层网络后使用SKFF 作为特征连接的方式。并行特征的提取公式如下:
2.2.2 互补卷积块
ODconv 的 概念由Li[24]于2022 年提出,它是对CondConv 的进一步延伸。4 种注意力运算方式为:从空域维度的位置进行乘法运算、从输入维度进行通道乘法运算、从输出维度进行滤波器乘法运算、以内核乘法沿着卷积核空间进行核维度运算。这4 个维度以动态特性进行卷积,利用一种多维注意力机制以并行策略对4 个维度进行互补性学习,并将注意力逐步应用到相应的卷积核,以此增强卷积操作的特征提取能力。一个内核的ODconv 能达到多核动态卷积的效果,因此ODconv 减少了额外的参数量,这有利于提升模型的训练准确率、降低训练成本。计算公式如下:
式中:awi表示卷积核wi的注意力标量,asi表示卷积核awi的核空间维度,aci和afi分别表示输入通道维度和输出通道维度,⊗表示内核空间不同维度的乘法运算。
网络模型将初始图像进行ODconv 处理后的特征分成两部分,一部分交给对称组卷积块,另一部分交给互补卷积块,互补卷积块由三个串联的全维动态卷积和Relu 操作组成。互补卷积块利用全维动态卷积对每一层得到抽象特征再提取,得到更加抽象的特征,使互补卷积块具有捕捉输入特征复杂关系的能力,最后将三层ODconv 提取的特征与对称组卷积块相结合,有利于补充对称组卷积块遗失的特征。
2.2.3 特征增强残差块
传统的残差块包括两层3×3Conv 和一层Relu 操作,并将第一层卷积和第三层卷积聚合,这种基础残差块提取图像特征的过程会存在信息丢失的问题。为利用残差块更好增强异构卷积块提取的特征,本文构建一种特征增强残差块,它可以有效捕捉长距离特征之间的依赖关系,并降低图形中的冗余信息。如图1 所示,第一层卷积采用3×3 的卷积核,输入通道数和输出通道数分别为64 和32,并进行Relu 操作,与输入通道和输出通道均为32 的第二层3×3 卷积核执行concatenate 操作。随后采用通道数为64,卷积核分别为1×1,3×3 的卷积核进行特征提取和整合。特征增强残差块获得的初始信息与第四个卷积层做聚合操作。
式中:Fc1是异构卷积块获得的特征图经过第一个卷积层和Relu 操作处理后的特征图,表示特征增强过程,concat(·)表示连接合并,half(·)表示取特征图的一半通道数。
2.3 损失函数
本文将均方误差公式(Mean Square Error,MSE)[22]作为损失函数来训练网络模型,模型对输入的LR 图像PLR进行预测,得到HR 图像PHR。随后使用MSE 计算HR 图像与HR 图像之间的差异,并进行参数优化,公式如下:
式中:Loss 表示损失函数,分别表示训练的第j个LR 图像和HR 图像,N表示训练图像的数量。
3 实验及结果分析
3.1 实验设置
本文使用公开数据集DIV2K 彩色图像数据集[25]作为融合多维注意力机制与选择性特征融合的图像超分辨率重建算法的训练集,该数据集由放大因子为2~4 的800 张高清HR 图像、100 张HR 验证样本和100 张HR 测试样本组成。为增强模型的稳定性,本文使用文献[22]实验设置的方法扩大数据集,并将每张LR 图像裁剪尺寸为81×81。测试集使用研究领域的标准数据集:Set5[26],Set14[27],BSD100[28]和Urban100[29]。这里使用峰值信噪比(Peak Singal-to-Noise Ratio,PSNR)[30]和结构相似度(Structural Similarity,SSIM)[31]作为评价指标。公式如下:
式中:MAX1代表图像像素点的最大值;PMSE代表尺寸为M×N的HR 图像和重建后图像的均方误差;μik μik'和σikσik'分别表示HR 图像与重建后的图像以第i个像素为中心点的窗口的平均值与标准差;NR表示图像数量;a1与a2表示常量。
本文在图像RGB 上训练模型,在YCbCr 彩色空间中的Y 通道测试模型的超分辨率重建效果。初始参数如下:初始学习率为10-4,每迭代40 000 次学习率降为原来的一半,总迭代为152 400次,图像批处理大小为32。实验在Linux 系统下实施,硬件环境为CPU 处理器24 核AMD EPYC 7642 48-Core Processor,内存80 G,GPU 为NVIDIA GeForce RTX 3090,24GB 显存;开发平台为Python 3.8 和Pytorch 1.11.0,Cuda 11.3。
3.2 消融实验
为了验证本文设计的异构型的有效性,对互补卷积模块、选择性内核特征融合模块和特征增强残差模块进行5 种组合,并对其网络进行了消融实验及数据分析对比,对于没有选择性内核的特征融合模块使用普通连接操作。测试集使用放大因子为2~4 的Urban100 数据集,其中Plan A~Plan E 5 种方法放大2 倍的数据分析结果如表1 所示。表中,所有方法均使用对称组卷积模块,Plan A 方法仅包括互补卷积模块,对称组卷积块以并行卷积的方式分别对所有通道的上半部分和下半部分进行特征提取,不使用SKFF 模块进行特征融合,只使用普通的特征连接方式,评价指标显示效果较差,PSNR 只有30.43,证明互补卷积模块虽能提取特征,预测的图像接近真实图像,但细节纹理处理欠缺。Plan B 方法仅包括选择性内核特征融合模块,对称组卷积块的融合方式和网络第五个异构型残差模块后的融合方式均采用选择性内核特征融合模块,Plan B 与Plan A 相比,评价指标明显提高。Plan B 和Plan C 的结果证明了选择性内核特征融合模块和特征增强残差模块的有效性。Plan D 使用互补卷积模块,并按照Plan B 的方式进行特征融合,实验结果较Plan C 的PSNR 提升了0.64,SSIM提升了0.029。Plan E 同时使用互补卷积模块、选择性内核特征融合模块和特征增强残差块,评价指标PSNR 和SSIM 分别达到32.12 和0.928 8,结果表明三个模块的结合能够更好地提取特征信息,提高模型的超分辨率重建效果。

表1 不同方法在Urban100 数据集放大2 倍的比较结果Tab.1 Comparison results of different methods on Urban100 data set magnified by 2 times
如图4 所示,本文将Plan A~Plan E 使用放大2~4 倍的U100 数据集进行主观视觉效果对比,结果通过可视化展示,在训练批次为152 400的结果中发现,Plan A 与Plan D 对比表明,信息的叠加也导致一些错误特征的产生,SKFF 有效地融合特征使纹理的细节信息更加清晰。Plan B与Plan D 对比表明,互补卷积模块使特征提取的过程更加注重与周围特征的联系,条纹更加合理,同时降低了模糊感。Plan D 和Plan E 对比表明,特征增强残差块有效地降低了信息冗余造成的特征失真程度,恢复图像的高频信息特征更加接近HR 图像。

图4 Urban100 数据集放大2 倍的PSNR 消融对比Fig.4 Comparison of PSNR ablation on Urban100 dataset magnified 2 times
3.3 与其他主流方法对比
为了从不同角度客观地评估本文算法的超分辨率重建效果,从定量和定性两个方面进行分析,定量分析以PSNR 和SSIM 作为评价指标,对比算法采用Bicubic 插值[32],A++[33],RFL[34],基于无监督退化表示学习的盲超分辨率网络(DASR)[35],去噪卷积网络(a denoising CNN,DnCNN)[36],基于模型驱动的深度神经盲超分辨网络(A Model-Driven Deep Neural Network for Blind Super-Resolution,KXNet)[37],具有三十层残差的编码器解码器网络(RED30)[38],记忆网络(MemNet)[39],级联残差移动网络(Cascading Residual Network Mobile,CARNM)[19],端到端的深浅网络(End-To-End Deep and Shallow Network,EEDS+)[15],深度递归融合网络(Deep Recurrent Fusion Network,DRFN)[40],多尺度深度编码器解码器网络(Multi-scale Deep Encoder-Decoder with Phase Congruency,MSDEPC)[41],CFSRCNN[42],轻量级增强残差卷积网络(Lightweight Enhanced SR CNN,LESRCNN)[22],多尺度 的LESRCNN(LESRCNN-S)[22],非对称SR网络(Asymmetric CNN,ASCNN)[43],以及用于盲SR 的ACNet(ACNet-B)[43]。为更好展示SR的定量对比分析结果,本文使用Set5,Set14,B100 和Urban100 测试集放大2~4 倍作为补充测试集,对评价指标最高的最优算法进行加粗注释,次优算法用下划线注释。由表2~表5 可知,本文提出的融合多维注意力机制与选择性特征融合的图像超分辨率重建算法在4 个放大2~4倍的基准数据集上均有较好的定量数据,在Set5数据集上,本文算法在放大2~3 倍的PSNR 测试效果上比次优算法分别提升0.004,0.005,在放大4 倍的测试效果上与次优算法数据持平,SSIM指标在放大3~4 倍的Set5 和BSDS100 测试集上达到最优。在Set14 数据集上,本文算法的PSNR 和SSIM 均达到最优。在Urban100 和BSDS100 数据集上,本文算法的PSNR 指标在放大2~3 倍的情况下均达到最优,SSIM 指标在放大2倍的Urban100 数据集上达到次优。

表2 不同方法在4 个基准数据集放大2 倍的比较结果Tab.2 Comparison results of different methods on 4 Baseline datasets enlarged by 2 times
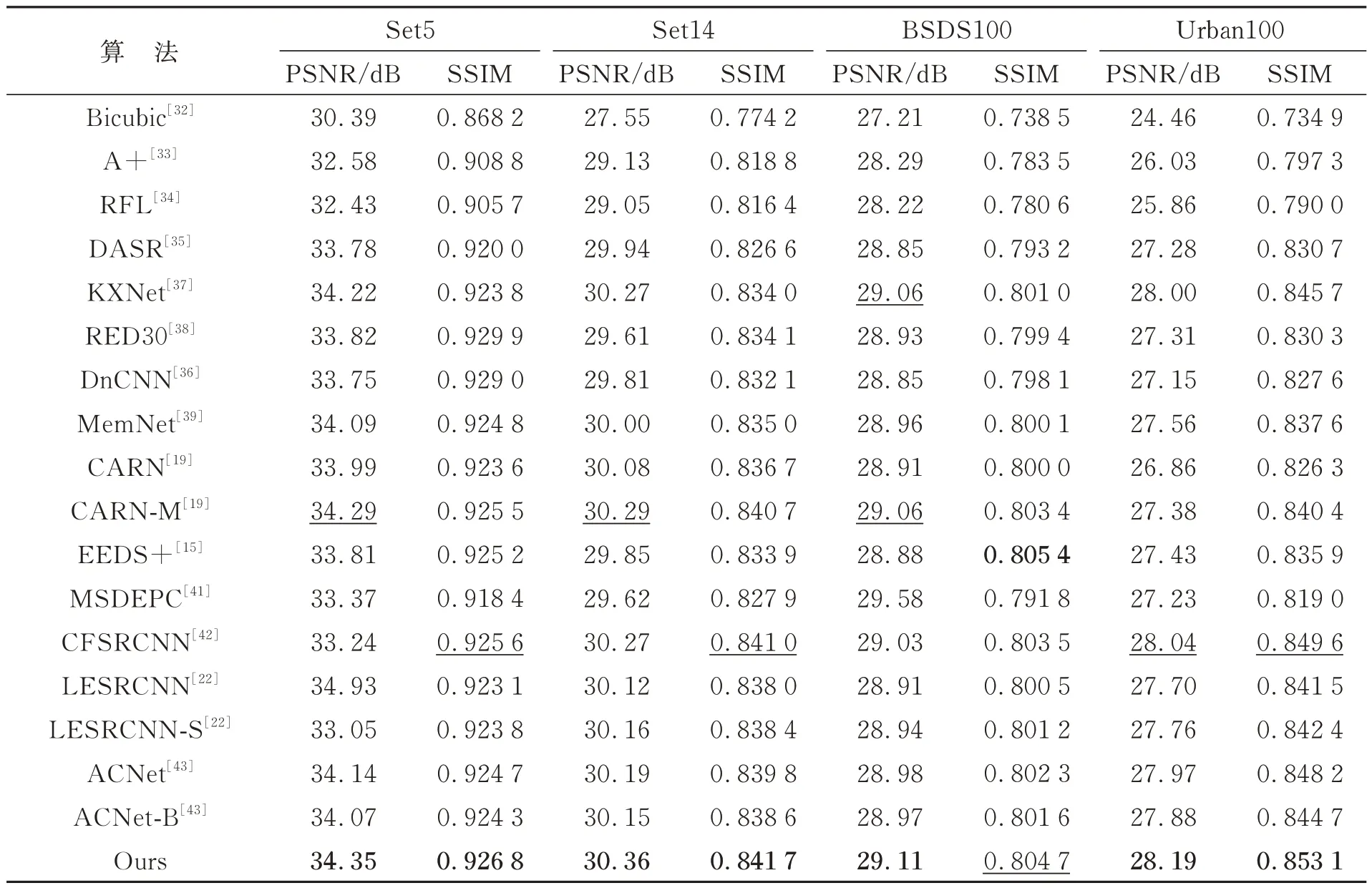
表3 不同方法在4 个基准数据集放大3 倍的比较结果Tab.3 Comparison results of different methods on 4 Baseline datasets enlarged by 3 times

表4 不同方法在4 个基准数据集放大4 倍的比较结果Tab.4 Comparison results of different methods on 4 Baseline datasets enlarged by 4 times

表5 不同模型在Set5(×4)上的推理时间Tab.5 Inference time of different models on Set5(×4)dataset
为验证本文算法的主观视觉效果,选取Urban100 基准数据集中的img015 和img030 和img039 三张图片分别放大2~4 倍进行对比测试。对比算法选用定量数据最好的6 种方法,通过观察发现,重建2~4 倍的大多数方法存在边缘模糊和伪影,本文方法可以有效缓解边缘模糊和伪影的问题,恢复更多的图像细节,产生的细腻纹理更接近真实超分辨率图像。在图5 中,其他算法在重建高楼窗户的细节纹理时,两侧栏杆的模糊感较重,而本文算法重建的图像可以较清晰地观察到栏杆的形状。在图6 中,其他算法重构的六组窗户边缘纹理呈圆矩形,反光细节产生了泛白的虚假信息,本文算法重构的窗户清晰,窗户与墙面对比凹凸清晰。在图7 中,其他算法重构的大厦交错的结构细节模糊不清,而本文算法重构的图像中有“V”型结构轮廓。

图5 Urban100 数据集中Img015 放大2 倍的对比图Fig.5 Comparison of Img015 magnified 2 times in Urban100 dataset

图6 Urban100 数据集中Img030 放大3 倍的对比图Fig.6 Comparison of Img030 magnified 3 times in Urban100 dataset

图7 Urban100 数据集中Img039 放大4 倍的对比图Fig.7 Comparison of Img039 magnified 4 times in Urban100 dataset
将本文方法与其他主流方法从定量和定性两个方面进行对比。图8 和表5 分别表示在Set5放大4 倍的重建任务中,模型与其他模型在评价指标、参数量及推理时间的对比结果,本文算法的SR 重建性能与模型复杂度数据取得了良好的平衡,在提升性能的同时并未带来大量的参数量,相对于DASR 和KXNet 算法,本文算法的推理时间更短,仅有0.051 6 s。

图8 不同模型在Set5(×4)上的PSNR 以及参数量Fig.8 PSNR and parameters on Set5(×4)dataset of different models
4 结论
本文介绍了一种融合多维注意力机制与选择性特征融合的图像超分辨率重建方法,该方法将全维动态卷积融入到互补卷积块,以并行策略动态学习核空间的四个维度,捕捉全部通道的特征,选择性内核特征融合应用到对称组卷积块,融合不同通道间的内部信息。对称组卷积块和互补卷积块的组合通过特征增强残差块去除冗余信息后提取的深层特征具有更加细腻的纹理边缘信息。数据分析及数据可视化结果显示,本文提出的模型在超分辨率重建任务的基准数据集上有着较好的性能,尤其在放大因子为3 的Set5 数据集上峰值信噪比提升0.06 dB,在放大因子为4 的BSDS100 数据集上峰值信噪比提升0.07 dB。在后续工作中,将应用模型对医学图像和遥感图像进行重建,以满足高级视觉任务的实际应用需求。
