结合自适应图卷积与时态建模的骨架动作识别
2023-09-25甄昊宇
甄昊宇,张 德
北京建筑大学电气与信息工程学院& 建筑大数据智能处理方法研究北京市重点实验室,北京100044
人体动作识别作为计算机视觉领域一项重要的研究内容,在智能监控、人机交互、虚拟现实和视频分析等方面具有广泛的应用前景。目前对人体动作识别的研究主要分为基于RGB视频的人体动作识别[1]和基于3D骨架的人体动作识别[2]。基于RGB 视频的方法需要高成本的计算资源来处理RGB 图像和光流中的像素信息,并且在面对复杂的背景条件时,计算量更大,鲁棒性较差。随着深度成像技术的快速发展,通过Kinect深度传感器获取3D 人体骨架数据,使用主要关节点的三维空间轨迹变化来描述动作,计算效率较高,且对背景噪声具有较强的鲁棒性。因此,基于骨架的人体动作识别受到研究人员更多的关注。
1 相关工作
早期的骨架动作识别模型主要是基于手工设计特征的方法,例如可以依据骨架数据序列中的关节坐标点位置形成时序特征向量[3],或者考虑关节点之间的相对位置,根据身体不同区域的姿态变化、偏移等信息形成特征向量[4],还可以整体考虑人体姿态的静止特征和时序动态偏移特征形成特征向量[5-7]。基于这些特征,使用传统的机器学习算法进行分类识别。这类方法的不足之处在于特征表达能力有限,当数据量增加、动作类别增多的时候,识别准确率不高。
随着深度学习的快速发展,基于深度学习的骨架动作识别方法逐渐成为主流,并且可以分为三类,基于循环神经网络(recurrent neural network,RNN)、基于卷积神经网络(convolutional neural network,CNN)和基于图卷积神经网络(graph convolutional network,GCN)的方法。
RNN 适合针对时序相关性强的数据进行建模,Du等[8]提出级联RNN 建模的方式,使用多个子RNN 分别对不同身体区域的骨架数据序列进行处理,然后逐级合并子网络并进行信息融合。为了构建更深层次的网络,Li等[9]提出一种基于独立神经元的RNN模型,提升了骨架动作识别的准确率。为了更好地表达时序数据的上下文依赖关系,并解决传统RNN 存在的梯度弥散问题,长短期记忆(long short-term memory,LSTM)结构得到了更多的应用,例如Liu等提出的ST-LSTM(spatiotemporal LSTM)模型[10]和GCA-LSTM(global contextaware attention LSTM)模型[11]等。尽管如此,RNN类方法仍然难以处理骨架数据在空间和时间各个维度上的同时变化特性。CNN类方法考虑通过预先设定的规则把骨架数据序列转换为一组语义图像,然后再使用CNN模型进行处理。例如可以直接把关节点的三维坐标对应到图像的三通道像素值[12],或者选定几个参考关节点,计算其他关节点到参考点的相对位置变化,还可以考虑加入视角的变化,转换生成一系列连续图像[13-14]。CNN 类方法识别性能有了一定提升,但是依然不能充分地利用骨架数据天然的内在信息,人体关节之间固有的相关性无法很好地进行建模表达。
图卷积神经网络GCN在多个领域的良好表现为骨架动作识别提供了新思路。由于骨架在非欧几里德几何空间中自然地被构造为一个图形,Yan 等[15]构建了时空骨架图,提出ST-GCN(spatial-temporal GCN)模型,将人体关节之间的时空关系很好地嵌入到骨架图的邻接矩阵中。为了进一步挖掘关节之间的自然连接关系和动作过程中关节之间不同程度的依赖关系,Li等[16]提出了基于动态连接和静态结构连接的AS-GCN(actionalstructural GCN)模型。Zhang等[17]则利用关节所属类型(手部关节、肩部关节等)等语义信息引导建立一个更有效的GCN 模型,充分表达全局和局部特征。但是仅依靠预设定图拓扑结构的模型不够灵活,无法应对变化多样的动作数据。Shi 等[18]提出了自适应图卷积模型,以端到端的方式学习个体数据驱动矩阵,作为图拓扑结构邻接矩阵的补充,增加了GCN 模型的数据适应性。Chen 等[19]设计了一种双头GCN 模型,把粗粒度和细粒度特征有效结合起来。马利等[20]提出区域关联自适应GCN 模型,捕获非物理连接关节之间的内在依赖联系。近年来,GCN 类方法的应用使得骨架动作识别率得到明显提高,已经成为当前的主流方法。
在文献[18]中,Shi等考虑到人体骨架是由关节点和骨骼两种元素组成,关节点连接相邻的骨骼,因此也提出了基于双流数据处理的网络结构,把初始骨架数据分解为关节点数据流和由骨骼表示的肢体数据流。此后,数据分流的模型构建思路得到了广泛的应用[19-22],识别性能得到了进一步提升。
但是,大多GCN 类方法对骨架动作数据序列的时域变化动态分析还不够深入,特别是对于非相邻时间步长的动作单元间的关系特性由于信息稀释而被忽略。一个动作一般由一些连续且顺序固定的动作单元组成,它们之间的相邻和非相邻时序相关性决定了该动作的时域特征[23]。例如,跳远动作包含“助跑”“起跳”“腾空”和“落地”四个部分,“助跑”和“腾空”,或者和“落地”之间的非相邻时间步长距离等特性对识别跳远动作也能够起到重要作用。因此在时域动态建模中,还应充分考虑非相邻时间步长动作单元之间的相关性。
基于以上分析,本文提出了结合自适应图卷积与多尺度时态建模的双流GCN模型。自适应图卷积模块以端到端的方式自适应的学习人体关节之间固有的连接关系和不同动作类别的关节变化依赖关系。多尺度时态建模模块提取骨架序列的时间特征,增强了时间卷积,扩展了时间维度上的感受野,有效地聚合了相邻时间步长和非相邻时间步长的时态关系。两个模块相互补充,丰富了模型整体的特征表达能力,提升了识别性能。
2 模型介绍
2.1 骨架图卷积表示
人体骨架图可以表示为G=(V,E) ,其中V={v1,v2,…,vJ}代表J个关节点的集合,E是边集,表示为邻接矩阵A∈RN×N,邻接矩阵仅包含0、1两种数值,其中(i,j)=1 表示第i个关节点和第j个关节点之间有直接相连的边,(i,j)=0 则反之。A是对称的,因为G是无向图。骨架序列可以表示为特征张量X∈RC×T×J,其中C表示坐标维度,T表示动作序列中骨架帧的数量。因此,完整的视频骨架序列可被表示为每一帧骨架图的堆叠G=(G1;G2;…;GT)。
图卷积网络是学习图结构数据表示的有效框架,根据上面定义的符号,图卷积网络在骨架序列上执行多层图卷积以提取高层特征。每个图卷积层通常由空间图卷积块和时间卷积块组成,空间图卷积块提取骨架的空间特征,其具体公式为:
其中,fin表示输入特征,表示输出特征。A为邻接矩阵,I为单位矩阵,Λ为度矩阵。邻接矩阵有三个子集,分别为(1)根节点本身(root);(2)向心子集(centripetal),包含比根节点更靠近重心的相邻节点;(3)离心子集(centrifugal),包含比根节点离重心更远的相邻节点。因此,A相应地分为Mk∈RJ×J作为一个可学习的矩阵,用来调整边缘的重要性。Wk是大小为Cout×Cin×1×1 的可学习参数,用于调整特征图的通道。
时间卷积块提取骨架序列的时间特征,对同一关键点在不同帧的信息进行融合,具体公式如下:
其中,Conv2d[Kt×1]是卷积核大小为Kt×1 的二维卷积运算。
2.2 模型网络架构
本模型采用双流网络结构对关节点信息和肢体信息同时建模处理,主要包括三个部分,数据预处理、特征提取和动作分类,如图1所示。
数据预处理:把骨架数据序列分解为关节点流和骨骼流(表示肢体信息)。关节点流数据由各关节点的三维坐标组成,骨骼流数据按照如下方式获得[18]。
每个骨骼都与两个关节点绑定,定义靠近人体骨架重心的关节点为源关节点,远离重心的为目标关节点。这样,每个骨骼都表示为一个从源关节点指向目标关节点的向量,该向量包含了长度信息和方向信息。骨骼向量计算公式为:
式中,vi表示目标关节点,vj表示源关节点,boneij表示关节点vi和vj间的骨骼向量。
特征提取:该部分由10个基础网络层堆叠而成,每层网络的输出通道数依次是64、64、64、64、128、128、128、128、256 和256,每层网络结构相同,如图2 所示。BN 是批归一化操作(batch normalization),ReLU 是常用的非线性激活函数。为了稳定训练过程,增加了一个残差连接。这样,经过多个基础网络层后,特征能够沿空间和时间维度进行集成。

图2 网络层结构单元Fig.2 Network layer structure unit
动作分类:将关节点流网络和骨骼流网络的输出进行加权融合,得到融合分数并预测动作所属的类别。
2.3 自适应图卷积模块
本文使用的自适应图卷积模块以端到端的学习方式,将图的拓扑结构与网络的其他参数一起优化。对于不同的图卷积层和不同类别的样本,该拓扑结构是唯一的,增加了模型的辨识能力。自适应图卷积模块的结构如图3所示。

图3 自适应图卷积模块Fig.3 Adaptive graph convolutional module
为了使图表示具备自适应的特性,将式(1)进行如下变化:
这里,骨架图表示的邻接矩阵分为三部分:Ak、Lk和Pk。Ak与原始的邻接矩阵相同,表示人体的整个物理结构。Lk也是一个邻接矩阵,它的元素值初始化为0,在训练过程中与其他参数一起被优化,它不仅表明两个关节点之间存在连接,还表明了连接的强度。Lk可以学习针对待识别样本的图,并且对于不同层中包含的不同信息更加个性化,与式(1)中的Mk类似,执行注意力机制的角色。然而,由于原矩阵Mk与Ak进行点乘,如果Ak中的一个元素为0,无论Mk中元素的值如何,它都将始终为0。因此,它无法生成原骨架图表示中不存在的新连接。而Lk能够增强非自然连接关节点对之间的特征传递,比Mk更加灵活。
Pk是一个数据相关图,它为每个样本学习一个唯一的图。Pk应用了Non-local 注意力机制[24],通过归一化嵌入高斯函数计算图中任意两个顶点之间的交互来获得其连接强度,如式(5)所示:
其中,J是顶点的总数,使用点积来计算两个顶点的相似性。具体来说,给定输入特征fin∈Cin×T×J,J是顶点总数,zi和zj代表任意两个顶点,θ和ϕ是两个嵌入函数,分别为1×1的卷积操作,eθ(zi)Tϕ(zj)是一种相似度函数,计算zi和所有相关联的zj之间的相似关系。在具体实验中,首先将输入特征fin∈Cin×T×J分别通过两个嵌入函数(即1×1 卷积层)映射并分别重新排列为J×Cm×T矩阵和Cm×T×J矩阵,然后将它们相乘,得到J×J大小的相似矩阵Pk,其元素pij表示顶点zi和顶点zj的连接强度。将矩阵的各元素值归一化,作为顶点zi和顶点zj的虚拟连接。Pk可以如式(6)所示:
Wθk和Wϕk分别表示嵌入函数θ和ϕ的参数。
另外,如图3所示,其中添加残差连接,允许将该模块插入到任何现有的模型中而不破坏其初始特征,如果输入通道的数量不同于输出通道的数量,则在残差路径中插入1×1卷积(图3中带虚线的紫色方框),以转换输入来匹配通道维度上的输出。
2.4 多尺度时态建模模块
为了捕获骨架序列的动态时间模式以及建模相邻和非相邻时间步长之间的长距离时态关系,本文提出使用多尺度卷积建模时间序列的多尺度信息,增强了时间卷积层,丰富了模型在时间维度上的感受野。该模块的网络结构如图4所示。

图4 多尺度时态建模模块Fig.4 Multi-scale temporal modeling module
模块的输入为特征矩阵fin∈C×Tin×J,Tin为输入骨架序列的初始帧数,采用并行的多分支结构,在不同的感受野下进行特征的提取来实现对多尺度时间信息的捕捉。该模块由四个分支实现,每个分支包含一个1×1卷积以减少通道维数。从左到右看,前两个分支分别使用空洞率为1、2,卷积核大小都为5×1 的空洞卷积。空洞卷积可以在不引入额外参数的同时增加感受野,是卷积操作的一种。它的实现方式为在卷积核的每行每列中间加入零元素,将插入的空洞个数称为空洞率(dilation rate)。空洞卷积的参数包括卷积核个数k,卷积核大小w×h,空洞率d,步长s和填充值p。这里没有选择更大空洞率是因为稀疏的卷积核会使无用的权重增加,产生一些无效信息。不同空洞率产生的有效感受野在时间维度上体现为不同的时间间隔,在具体实验中,将上一层输出的空间特征C×Tin×J作为输入,按通道维数平均分成四个部分,每个分支通过1×1卷积操作来转换通道数,使每个分支的通道数为C′(即C′=C/4)。之后前两个分支通过5×1的空洞卷积操作,将输入特征转换为C′×T1×J矩阵和C′×T2×J矩阵。因此前两个分支分别捕获了相邻时间帧和非相邻时间帧上的高级时间特征,也对不同持续时间的动作序列选择了合适的尺度进行特征的提取。时域维度上时间帧数T1、T2如下计算得出:
第三个分支保留了时间帧上的原始特征,得到的特征矩阵为C′×T3×J。第四个分支采用3×1的最大池化操作得到C′×T4×J的特征矩阵,提取了时间维度中具有最突出信息的特征。时间帧数T3、T4计算如下:
将四个分支的结果连接起来得到融合特征,获得了时间维度上的多尺度信息,其公式如下:
Tout为输出骨架序列的时间帧数,通过将四个分支串联使通道数变为C(即保证了输入特征的通道数不变),最终提取到多尺度时间特征f tout∈C×Tout×J。通过聚合多尺度时间信息来更新节点的特征,如图5所示。

图5 时间域上的卷积Fig.5 Convolution in time domain
另外,同自适应图卷积模块一样,增加残差连接(图4中带虚线的绿色方框),以转换输入来匹配输出通道的维数。
3 实验及结果分析
本文的实验在NTU RGB+D 和NTU RGB+D 120两个大型公开数据集上完成,后一个数据集是前一个的扩展。这两个数据集是目前骨架动作识别任务中使用最广泛的,本文以此验证所提出模型的有效性,并与近年来主流的方法进行了比较。
3.1 数据集介绍
NTU RGB+D数据集[25]:该数据集包含了60个动作类别,其中40 个为日常行为动作,9 个为与健康相关的动作,还有11 个属于双人交互动作。这些动作由40 个年龄从10 到35 岁的志愿者完成,共56 880 个样本序列。数据采集由位于相同高度,三个不同角度的摄像机完成,并通过Kinect深度传感器获得了3D骨架数据,每个人体骨架包含25个关节点,如图6所示。该数据集提供了两种训练和测试模式,CS(cross-subject)和CV(crossview)。CS模式下,训练集使用20个志愿者的40 320个样本,而其余20 个志愿者的16 560 个样本作为测试集进行模型评估。CV模式是依据摄像机角度划分训练集和测试集,其中来自0°和45°视角的37 920 个样本作为训练集,来自-45°视角的18 960个样本作为测试集。
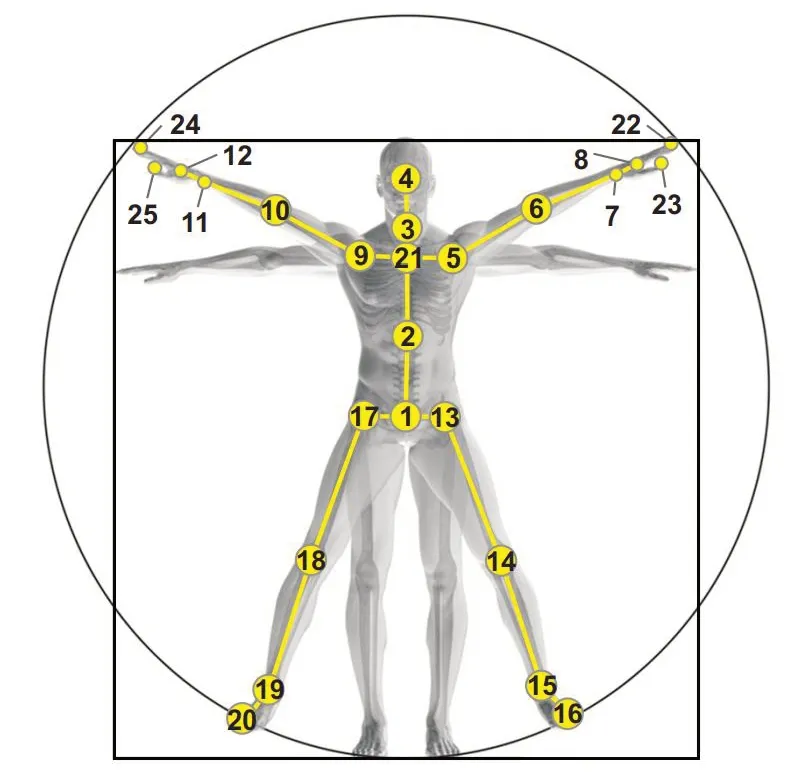
图6 NTU RGB+D数据集的关节标签Fig.6 Joint label for NTU RGB+D dataset
NTU RBG+D 120数据集[26]:该数据集是目前最大的室内动作识别数据集,也是NTU RBG+D数据集在志愿者和动作类别数量上的扩展。由106 名志愿者参与采集,共计包含120 个动作类别,114 480 个样本序列。采集过程中共设置了32 个不同的场景,主要包括位置和背景的变化。该数据集也提供两种训练和测试模式,CSub(cross-subject)和CSet(cross-setup)。CSub 模式下把志愿者分为两组,训练集和测试集各包含来自53 个志愿者的样本。而CSet 模式按照场景设置进行分组,训练集和测试集分别包含来自16个场景设置下采集的样本。
3.2 实验设置
实验均在PyTorch 深度学习框架下完成,运行环境为Win 10 操作系统,32 GB 内存,GPU 为1 块RTX 2080Ti 显卡。在模型训练过程中,批量大小设为16,并采用带动量的随机梯度下降优化算法。选用交叉熵损失函数,把权重衰减初始值设为0.000 1。初始学习率设为0.1,在第30轮、40轮后减小为1/10。整个训练过程可在第50轮迭代后结束(如图7所示)。本文基于top-1准确率评估和比较模型的性能。
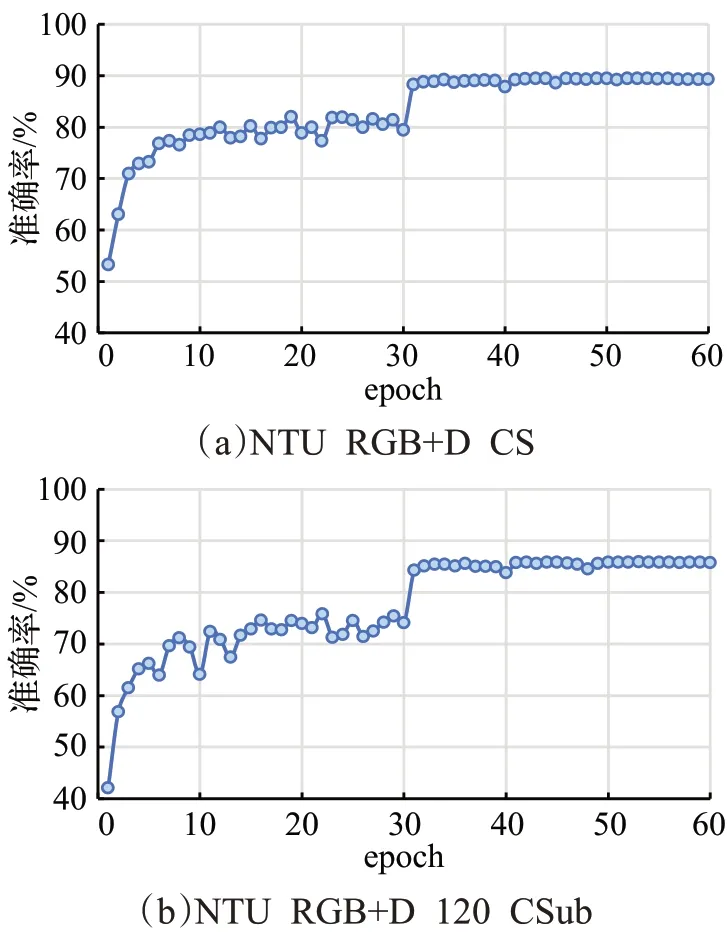
图7 模型训练过程中准确率的变化Fig.7 Changes of accuracy during model training
3.3 实验结果
首先在NTU RGB+D 数据集的CS 模式和NTU RGB+D 120的CSub模式下进行了训练和测试,观察本文模型随迭代次数增加而发生的性能变化,如图7 所示。可以看出,当迭代次数(以epoch表示)超过31之后top-1 准确率即趋向平稳。第50 轮后,准确率呈现稳定不变的趋势。接下来,对本文模型中使用的不同模块分别进行性能验证和分析。
3.3.1 自适应图卷积模块性能分析
如2.3 节所述,自适应图卷积模块中有3 种类型的图,分别是Ak、Lk和Pk。Ak表示整体骨架结构,Lk+Pk组合与数据样本的关节点具体连接强度相关,表示自适应性。仅保留Ak或Lk+Pk组合,进行消融实验比较分析。这里,使用关节点数据流在NTU RGB+D 120数据集的CSub 模式下完成实验,top-1 准确率结果如表1 所示。可以看出,使用Lk+Pk组合的识别准确率高于仅使用Ak的情况。自适应图卷积模块在Ak、Lk和Pk都使用的情况下识别率是最高的,为了更好地说明Lk和Pk的作用,以跑步动作为例进行了可视化展示,如图8所示。

表1 自适应图卷积模块有效性验证Table 1 Validation of adaptive graph convolution module

图8 自适应图卷积效果可视化示例Fig.8 Visualization example of effectiveness for adaptive graph convolution module
图8中为跑步动作序列某帧的骨架图,红色圆点代表关节点,其外面粉色圆圈的大小代表当前关节点和第25个关节点(图6所示)之间的关联强度,圆圈越大表示强度越大。自适应图卷积模块中通过引入Lk和Pk增强了模型的灵活性和对样本的自适应性,从图8中手和腿、手和脚之间有着更强的关联度可以看出其作用,原本相距较远的关节点由于动作样本类别的特性也可以产生较强的连接。由以上分析可以表明,自适应图卷积模块根据不同的层和样本学习了不同的图拓扑结构,提取到了骨骼空间域中更高级的特征,能够帮助提升动作识别的准确率。
3.3.2 多尺度时态建模性能分析
为验证多尺度时态建模模块的有效性,在NTU RGB+D和NTU RGB+D 120两个数据集上进行消融实验,top-1 准确率结果如表2 所示。可以看出,多尺度时态建模模块在两个数据集上都可以帮助提高识别准确率。在包含动作类别数量更多的NTU RGB+D 120 数据集上,可以使准确率增加3 个百分点(CSub)和2.7 个百分点(CSet)。因此,充分挖掘动作序列的时域内在联系,进行多尺度时态建模分析,能够增强模型整体的识别性能,使得识别结果更加准确。

表2 多尺度时态建模有效性验证Table 2 Validation of multi-scale temporal modeling
为进一步分析多尺度时态建模的作用,选取了2类持续时间较长的动作“刷牙”和“脱鞋”,3类持续时间较短的动作“手里东西掉落”“鼓掌”和“敲击键盘”,以柱状图的方式展示这5 类动作的识别性能,如图9 所示。可以看出,在多尺度时态建模加入的情况下,所选5 类动作的识别性能都有明显提高。虽然各类动作的持续时间长短不同,但是利用多尺度卷积建模方式,有效地聚合了相邻时间帧和非相邻时间帧上的时态关系,减少了在局部空间中干扰时间特征聚合的与动作无关的时间信息,赋予了网络在时间域上更好的特征表达能力,从而能够更好地进行动作分类。
3.3.3 双流数据网络性能分析
基于人体骨架的关节点流和骨骼流数据信息构成双流网络结构,本小节使用NTU RGB+D 120数据集比较了单独使用关节点流数据和骨骼流数据作为输入的性能,以及将这两种数据组合之后的性能,如表3所示。所使用的本文模型为自适应图卷积+多尺度时态建模。可以看出,将两流数据组合后可以进行信息的相互补充,识别性能明显高于基于单流的情况。

表3 不同的数据流输入下准确率比较Table 3 Comparison results with different input data-stream
3.3.4 与其他模型比较
在NTU RGB+D和NTU RGB+D 120两个数据集上,将本文方法和近年来有代表性的模型进行了比较,比较内容包括top-1 准确率和模型复杂度(参数量和FLOPs)方面效率的比较,如表4所示。用于比较的方法主要分为4种,包括手工设计特征的方法[6]、基于RNN的方法[8-11]、基于CNN的方法[12,14]和基于GCN的方法[15-18,21-22,27]。其中文献[18,21]也属于使用双流网络结构的方法。另外,还选择了结合多个注意力机制的GCN 类方法[27]用于比较。

表4 本文模型与其他方法的结果比较Table 4 Results comparison between proposed model and other methods
从表4 可以看出,自从Yan 等[15]首次将图卷积引入基于骨架的动作识别并提出ST-GCN 模型以来,基于GCN 的方法逐渐实现了显著的性能提升,这表明了图卷积网络在处理动作识别骨架序列数据方面的有效性。与RNN类的方法和CNN类的方法相比,本文模型在两个数据集的两种验证模式上的性能表现都有大幅提升。与同样采用双流结构的方法[18,21]相比,本文模型的top-1 准确率更高,有效地证明了模型的优越性。在模型复杂度方面,与GCN类方法进行了比较。由表4可知,本文模型的参数量和FLOPs 指标相对不高,不需要过多的运算资源支持。多尺度时态建模的引入丰富了时域特征,强化了特征的多维整体表达能力,对网络训练的收敛速度起到一定的促进作用。因此,综上而言,本文方法具有较强的竞争性,预期的应用前景良好。
4 结语
本文提出了结合自适应图卷积模块和多尺度时态模块的骨架动作识别模型。自适应图卷积通过把骨架数据的拓扑结构参数化,并嵌入图网络中,以便与模型一起学习和更新。多尺度时态模块可以提取较复杂的时间动态特征,丰富了时间维度上的感受野,建立了时间域中的短期和长期依赖关系。两个模块相辅相成,使得网络模型在时域和空域上具备更好的特征表达和建模分析能力。本文模型在两个大规模的动作识别数据集NTU RGB+D 和NTU RGB+D 120 上进行了评估,识别性能均取得了较大程度的提升。在今后的工作中将考虑利用多模态数据融合的方式,进一步提高模型识别准确率,并加强模型的泛化能力。
