低光照图像增强研究方法综述
2023-09-25彭大鑫李智慧
彭大鑫,甄 彤,李智慧
1.河南工业大学粮食信息处理与控制教育部重点实验室,郑州450001
2.河南工业大学信息科学与工程学院,郑州450001
在科技高速发展的今天,各种设备也使用得越来越多,视频图像的应用也越来越广泛。由于条件的复杂性特别是在夜晚条件下形成的视频图像往往亮度较低、噪声较大、对比度较低,很难达到理想的采集效果,获取想要的信息。因此对这些低光照条件下形成的图像进行增强就很有必要。低光照图像增强的目的是突出关键信息,尽可能地排除干扰信息,将原来不清晰或者亮度较低的图像变得清晰或者增强亮度[1]。在低光条件下,由于光照条件的不确定性,捕获的图像质量不佳,并夹杂着噪声导致对比度和亮度严重下降,从而影响图像暗区的细节,出现色彩偏差。根据增强算法设计的不同,目前的低光照图像增强算法主要分为传统的低光照图像增强算法以及基于深度学习的低光照图像增强算法。传统的增强方法主要是对图像的像素进行处理,目的是提高图像的对比度、亮度以及去除噪声。但是这类方法不能注意到低光照图像自身对光照的需求关系同时忽略了内在的上下文信息,进而产生图像颜色失真以及噪声较大的现象。为了克服上述方法的不足,深度学习技术成为了低光照图像增强的主流技术。深度学习的方法分为有监督和无监督的方法。有监督的方法利用端到端的网络[2]来学习输入低光照图像与正常光照图像的映射来达到增强的目的。无监督的方法建立一种非配对映射来增强图像[3]。但实时性问题没有得到解决,仍然有改进的空间。
综上,低光照图像增强方法有规律可循并且呈现百家争鸣的态势,但仍然存在着许多问题。因此有必要对低光照图像增强方法进行全面分析讨论及对比。本文从传统方法以及深度学习方法两个方面进行详细分析与阐述。具体方法间的区别与联系如图1所示。

图1 各类方法间的联系与区别Fig.1 Relationship and difference between various methods
1 传统的低光照图像增强算法
目前最常见的低光照图像增强方法大致包括以下几种,包括色调映射算法、直方图均衡化算法、伽马校正算法、暗通道先验算法、基于Retinex分解的算法以及基于融合的算法。
1.1 色调映射算法
关于色调映射的增强分为全局和局部两种方法。全局色调映射过程是将全部的像素点都通过同样方法加以处理,这就会导致图像的较亮部分或者较暗部分没有考虑到,造成图像颜色映射处理过后缺少了部分的细节信息。局部色调映射时像素点周围的空间位置也需要被考虑,因为在执行多尺度转换的同时,拥有同样亮度值的两个像素点之间会表现出不同的比值,因此在它们的空间位置周围的对比度数据也不相同。
色调映射在保证在高光和低阴影区域的部分对比度和细节数据的同时处理之后也会出现一些噪声。为增加低光照图像的对比度以及保持颜色一致不变性,赵军辉等人[4]将Lab 颜色空间和颜色映射融合,提供了一种图像增强方案。所提算法很好地保存了图像细节的自然程度,同时也强化了图像的反差度。曹红艳和刘长明等人[5]提出的自适应阈值和色调映射结合的算法解决了赵军辉等的方法可能产生的过度增强以及光晕问题。该方法使用了改进的基于贝叶斯的自适应阈值方法以实现去噪,并转换颜色空间,较好地提高了图像品质,具有很大的对比度。庞泽邦等人[6]将交叉分解的思想与色调映射算法结合有效提升了图像的质量。同样,朱世松等人[7]提出了一种基于协同滤波的色调映射算法。该算法结合色度亮度颜色空间进一步提升了图像的质量。
色调映射算法通过对像素及其周围像素的处理来达到对比度增强的效果。由于考虑了这种位置关系,使得处理之后的图像具有较好的细节信息,全局与局部信息更加凸显。
由于不同位置的像素值不同,在处理的时候可能会产生不好的效果。该方法的缺点总结如下:
(1)由于像素之间的关系兼顾不到位,会使得增强之后的图像对比度往往不高。
(2)处理之后的图像细节信息有待进一步加强。
1.2 直方图均衡化算法
直方图均衡化方法,是图像增强空域法[8]中一个最常见的图像增强方式,其通过扩展灰度数值的覆盖范围来增加对比度和突出部分细节内容。但也有某些缺点:灰度层的异常拉伸会形成伪影,锯齿效应以及过度增强,还会导致图像细节丢失。为了解决上述问题,许多学者提出了不同的算法。如MEMBHE 算法[9],利用动态直方图均衡化来解决过度增强的问题。但是这也会导致增强效果不理想。王利娟等人[10]提出了一种加权直方图均衡化的方法,该方法通过加权方法来解决细节丢失问题。杨嘉能等人[11]提出了自适应校正的动态直方图均衡算法,有效地防止了灰度级的合并,并且较大程度上保留了图像的细节。康利娟等人[12]提出了一种多级直方图形状分割的图像增强技术,在保留细节的同时有效抑制了噪声。Jebadass 等人[13]结合模糊集理论,首先将低光照图像模糊化,再利用对比度有限的自适应直方图均衡化方法增强图像,进一步改善了图像的质量。
直方图均衡化是对图像的灰度值均衡化,使其均匀分布在整个灰度域范围内。通过均匀化之后的图像表现有较好的对比度。该方法的缺点总结如下:
(1)由于是对图像的直方图直接拉伸,会导致过度拉伸进而产生块效应使图像质量下降。
(2)由于是基于直方图,不同区域如过曝光和曝光不足区域的反差不太明显,导致图像细节信息丢失。
1.3 伽马校正算法
伽马校正有着简便快捷的特性,但是却容易产生色彩失真对比度不够的现象。对于低光照图像,伽马校正可能会引起过增强及欠增强的问题。因此许多的改进算法被提出。侯利霞等人[14]提出了一种自适应的伽马校正的图像增强算法,通过多尺度分解并结合自适应伽马校正来提升图像的对比度。杨先凤等人[15]提出了一个改进的自适应伽马转换图像增强算法,该算法改进了伽马函数并且自适应定义了相关基本参数,使得相关图像的亮度和对比度得到了提升。
伽马校正对图像亮度的处理取决于伽马值与1 的大小关系,大于1 时亮度被抑制,小于1 时亮度被提升。因此其具有简单快速的优点。但也存在一些不足,总结如下:
(1)采用伽马校正往往会造成图像的色彩失真,对于不同的场景效果不佳。
(2)伽马值和像素值之间的关系未能对应好,使得处理之后的图像过度曝光。
1.4 暗通道先验算法
基于暗通道先验的方法借鉴了暗通道先验模型的思想。
Dong 等人[16]发现把一幅低光照图像倒置所得的图像和雾天图像极为接近。基于这一研究,Dong 等人将暗通道所需理论运用到了反转后的低光照图像上,将低光照图像增强算法与图像除雾算法相结合给出了暗通道算法。之后,在Dong 的基础上学者进行了深入的研究。暗通道先验算法中透射率的估计是关键。刘峰等人[17]提出使用快速导向滤波器计算透射率,但是得到的图像具有块效应。王硕等人[18]提出了能自适应校正估算的透射率的算法,该算法针对图像中部分不适应暗通道算法的区域设计了置信度计算法方法来自适应地补偿估算的透射率。算法很好地解决了天空区域可能会出现的伪影问题,但是仍然不能解决部分区域的细节问题。Li等人[19]细化了透射率并且优化了大气光值,很好地解决了噪声以及边缘问题,为低光照图像增强提供了很好的理论支持。
暗通道先验算法基于去雾原理,该算法考虑了成像模型使得处理之后的图像有更好的视觉效果。其关键是大气光值以及透射率的估计。其值估计直接决定了图像增强后的质量的好坏。
该方法的缺点总结如下:
(1)估计透射率时,使用不同的方法会导致块效应现象的出现。
(2)该方法的计算复杂,速度较慢。
(3)对于一些特定的区域处理效果不是太理想。
1.5 基于Retinex分解的算法
Retinex 算法以色彩一致性的理论为基础,由于其更符合人眼的视觉系统,所以一系列算法应运而生。Land 首先提出了Retinex 算法[20],该算法利用路径随机法在一定范围内来计算某一像素的相邻像素的相对亮度值,由于是随机路径选择,得到的结果不具有太多的可参考性。Funt 等人提出的迭代计算的Retinex 算法[21]很好地解决了上述问题,该算法利用螺旋的路径通过多次迭代来估计光照分量与消除分量,但是迭代的起始点选择不确定会造成视觉效果较差,同时也会有一些噪声。中心环绕的Retinex方法的引入很好地解决了以上方法带来的问题,其结合滤波估计来改进Retinex 算法。Jobson 等人[22]通过结合高斯核提出了一种单尺度Retinex算法(SSR),由于SSR算法利用高斯核函数估计亮度图像,这就难以保证图像的对比度。此外在一些亮度差异较大的边缘区域也会导致光晕现象。多尺度Retinex 算法(MSR)[23]的提出有效地解决了上述问题。经过不断改进之后,带色彩恢复的多尺度Retinex 算法[24]MSRCR 又被提出。MSRCR 算法很好地解决了出现的颜色失真问题,但会出现伪影导致纹理细节不够清晰。针对上述问题,常戬等人[25]提出一种空间转换和自适应灰度矫正的低光照图像增强算法,该算法结合Retinex理论避免了过亮或过暗现象的出现。同时,苏康友等人[26]通过引入颜色恢复因子提出了改进的Retinex算法,消除了光照不均匀的干扰。随着研究的进一步深入,许多研究者发现图像的细节信息不能完全恢复。基于此,李淼等人[27]将残差思想与Retinex理论相结合提出了改进算法,该算法能更好地提取图像细节特征,能恢复更多的细节信息。
上述基于Retinex分解的算法充分结合了颜色恒常性理论。随着研究的不断深入,虽然上述方法如SSR算法估计了光照分量并且消除了光照分量的影响,在视觉上取得了不错的效果,但是一些问题仍然存在。比如暗区没有得到充分改善、细节纹理信息不够突出以及出现噪声等。为了解决上述问题,Pan 等人[28]利用亮度增强函数以及改进的自适应对比度增强方法,通过多尺度融合获得增强的图像。Yang 等人[29]提出一种模糊C 均值聚类算法与Retinex 理论相结合的低光照图像增强算法。由于聚类是对图像的灰度直方图进行聚类,这就使得增强后的图像具有丰富的细节信息。针对噪声的问题,Ma 等人[30]提出了一个基于Retinex 理论的低光照图像增强的变异模型,该模型能有效地生成无噪声的图像,并能很好地适用于不同的光照条件。Lin 等人[31]提出了一种新颖的基于Retinex 理论的低光图像增强方法,该方法利用收缩映射和像素权重来抑制噪声并保留细节。
该方法基于色彩恒常性理论,通过估计光照分量并且消除光照分量的影响来增强图像。Retinex理论的引入更好地提升了图像的质量,更加符合实际。但也会存在不足,总结如下:
(1)在估计照度分量的时候会产生图像失真。
(2)对噪声不敏感、去噪效果不好。
1.6 基于融合的算法
基于融合的方法需要将不同曝光条件下的图像融合,但是得到其他曝光条件的图像目前来说是一个难题。基于此,王殿伟等人[32]通过曝光插值技术生成了中等曝光图像,并以低光照图像和高曝光图像为主要输入,以此来得到增强后的图像。Rao 等人[33]将人对夜间与白天的照度图融合来增强图像,但是这样的处理往往会使图像具有不好的视觉效果。翟海祥等人[34]融合多种图像并与Retinex 理论结合提出了新的增强算法,改善了图像的质量不佳问题。有时基于融合的方法处理之后会使图像变得不自然,基于此,Ueda 等人[35]提出了一种基于融合的图像增强算法。其通过凸组合系数同时兼顾全局与局部信息对图像增强,使得增强后的图像变得更加自然。
基于融合的方法考虑了不同图像的差异性,增强后的图像亮度及对比度较好。但仍然存在着不足:
(1)不同曝光条件下的图像难以获取。
(2)增强之后的图像往往质量不稳定。
综合以上方法,分别从六个方面对传统的低光照图像增强方法进行分析与总结。在深度学习技术还没兴起之前经过学者的不断探索,传统的方法不断被改进并表现出了不错的性能。在上述方法中,大都是对图像的像素进行处理。直方图均衡化算法通过拉伸灰度范围使得图像对比度以及亮度得到提升;Retinex 分解的方法结合了低光照图像的成像特点有针对性地增强,可以获得更多的细节信息以及更好的视觉效果。其他各种方法也在一定程度上增强了图像。传统的低光照图像增强方法对比如表1所示。
2 基于深度学习的低光照图像增强方法
随着技术的不断更新,深度学习在各个领域表现出了强大的应用潜力。同时也越来越多地应用到低光照图像增强领域。根据方法的差异,可分为有监督与无监督的方法。
2.1 有监督的方法
有监督的方法需要事先搜集配对的图像,以此来建立正常图像与低光照图像的映射关系。
受Retinex理论的影响,Zhang等人[36]提供了一种低光照图像增强网络,网络结构如图2所示。其可以解决更严重的视觉问题,同时方便随时调整对比度,得到效果较好的图像。在此基础上,Zhang 等人[37]又加了一种映射函数,提出了KinD++算法,使处理后的图像更加符合实际情况。因为现有的方法通常依赖于一些假定,它们也往往忽视了图像噪声等其他因素的影响,所以它们往往无法同样解决包含光度、反差、伪影,以及噪声等内容的影响。为解决上述问题,Wang 等人[38]提出了一种基于归一化流的增强方法。通过标准化流模型来学习低光与正常光图像的对应关系,更好地模拟了正常光图像的曝光分布,从而提升了对比度以及去除了噪声。之后,Jiang 等人[39]提出了一种新的退化到细化生成网络(DRGN),该网络更加关注图像的细节信息,在提升图像的可视性的同时保持了比较好的自然度。

图2 KinD的网络结构图Fig.2 KinD network structure diagram
上述方法设计了合适的网络取得了良好的效果。但是现有的一些方法没有充分考虑到关键特征导致细节不突出。基于此问题,Xu 等人[40]提出了一个分层的特征挖掘网络HFMNet,其在不同的网络层中提取光照和边缘特征,并且建立了一个特征挖掘注意力(FMA)模块,结合分层监督损失,充分地挖掘关键特征。提高了图像的可视性。深度学习方法具有强大的特征学习和映射能力,学习能力的提高也是一个亟待解决的问题。Lu等人[41]提出了一种多分支拓扑残差网络,利用拓扑残差块提高了网络的学习能力,提升了图像的质量。一些方法如CNN通常是对空间域的低频局部特征进行采样,这就会导致一部分信息被忽略,为此Zhuang 等人[42]提出具有相位感知的傅里叶卷积的双分支扩张网络进行低光图像增强。其能更加全面地关注图像信息并突出图像的纹理细节,但不能更好地挖掘深层多尺度特征。Fan等人[43]提出了带照度约束的多尺度低光照图像增强网络,该网络用Res2Net[44]通过提取深层多尺度特征来增强模型的能力从而避免了颜色失真问题同时具有更自然的视觉效果。
针对在不同照明环境下获得的图像可能会出现过增强或欠增强的情况,Wu等人[45]提出了一种基于Retinex理论的深度展开网络(URetinex Net),该网络将隐式先验正则化模型与Retinex 理论结合,更好地抑制了噪声以及保留了细节。但是这类算法需要成对图像作为数据集,事实上成对图像并不是很好获取。Lu等人[46]针对上述问题提出了一种双分支曝光融合网络来解决低光照图像增强问题,其结构图如图3所示。该方法通过估计不同光照水平的传递函数,提出了一种快速有效的增强策略。为了进一步应对输入图像的盲目性带来的挑战,引入了一种新的生成和融合策略,其中对轻微失真和严重失真的图像分别在两个增强分支中进行增强,然后使用自适应注意力机制进行最终融合。此外,还提出了两阶段去噪策略,以确保有效地降低噪声。

图3 TBEFN的网络结构分支图Fig.3 Branch diagram of TBEFN network structure
为了进一步地去除噪声以及消除色偏,Lu等人[47]提出了频分多尺度学习网络。将低光照图像分为高频和低频两个分量,利用多尺度特征提取以及注意力机制来增强图像。Xu 等人[48]提出结构纹理感知网络,其利用低光图像的结构和纹理特征来增强图像,更好地关注全局与局部的关系来去除噪声以及减轻色彩失真。Garg等人[49]设计了利用色相饱和度亮度的光通道增强算法,使用自编码器和卷积神经网络结合色相饱和度亮度的光通道来解决颜色失真等问题。Chen 等人[50]将卷积和自我注意力机制结合来增强低光照图像,在提取特征的同时关注局部与全局特征进而消除噪声以及色偏问题。Yang等人[51]提出了基于多流信息补充的增强网络,通过信息补充恢复图像的丰富结构并且去除噪声以及消除色偏。
有监督的方法依赖于配对的数据集,构建端到端的网络学习低光照图像到正常光照图像的映射关系。这种方法更加依赖于特征信息的提取,注意力机制能使网络关注更加有效的信息,设计合适的网络可以使图像的内在信息更好地表达出来最终生成高质量的图像。但仍存在不足,该方法的缺点总结如下:
(1)有监督方法依赖配对的数据集,但是配对的数据集很难获取,并且也费时费力。
(2)模型的泛化能力不够。由于是依赖配对的数据集训练,导致在某一特定数据集上取得不错的效果,但是在其他场景下效果不佳。
2.2 基于无监督的方法
无监督的方法不需要配对的数据集。这极大地提高了研究效率。Jin等人[52]针对增强后会产生过度增强以及增强不足的问题,提出了一种无监督的增强方法。该方法引入层分解网络和光效应抑制网络进一步抑制了亮区和提高了暗区的增强程度,保持了较好的对比度。
Guo 等人[53]提出了一种新的无参考深度曲线估计(Zero DCE),其用轻量化的深度网络DCE-Net 来调整给定图像的动态范围,并且不需要事先准备成对的数据集。流程如图4 所示。但是该方法并没有考虑噪声的影响,并且网络模型较大比较耗时。Li等人[54]进一步介绍了Zero DCE的加速和轻型版本,称为Zero DCE++,它利用了只有10 000参数的小型网络。Zero DCE++具有快速的处理速度,同时保持了Zero DCE 的增强性能。使网络更加轻量化,便于开展。
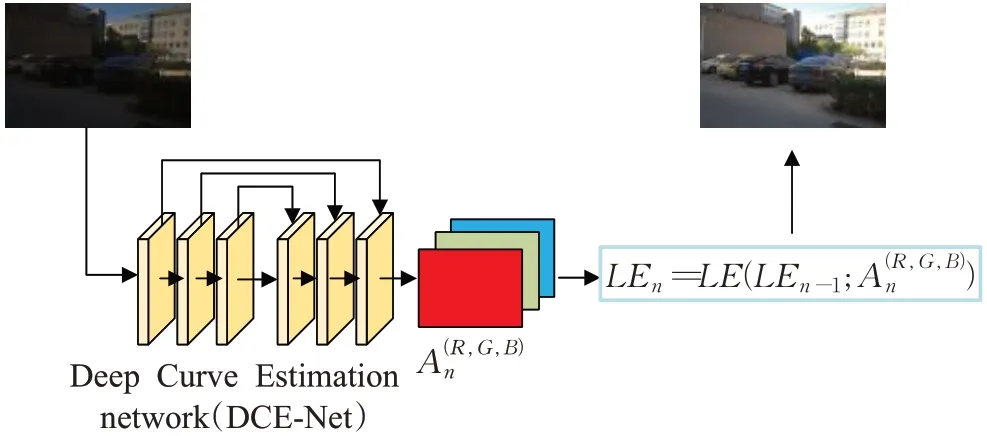
图4 Zero DCE结构图Fig.4 Zero DCE structure diagram
在弱光条件下获得的图像往往带有噪声并且有不同程度的退化。大多数恢复方法忽略了噪声并在拉伸对比度时将其放大。基于此Jiang 等人[55]在U-Net 网络的基础之上结合注意力机制提出了一种快速有效的增强策略(EnlightenGAN)。其结构图如图5 所示。Jiang等人还提出了基于局部和全局的自我特征保留损失的损失函数,更加提升了网络的精度,以生成高质量的增强图像。

图5 EnlightenGAN网络结构图Fig.5 EnlightenGAN network structure diagram
上述方法考虑了网络的性能以及推理速度,使用GAN 网络以及利用U-Net 网络的特征提取能力在确保网络性能的前提下有效提升了增强之后的图像的质量。
Fu 等人[56]提出了一种新的无监督低光照图像增强网络LE-GAN,该网络以生成对抗网络为基础网络,并使用非成对的低光照图像进行训练。同时该网络引入感知注意模块增强特征提取去除噪声以及消除色偏,进一步地引入新的损失函数以解决过度曝光问题。Ni等人[57]提出了一种新的用于无监督低光照图像增强的循环交互式生成对抗网络(CIGAN),该网络分三个部分并且结合注意力机制来提升图像质量。Wang等人[58]提出了一种混合注意力机制引导的生成对抗网络MAGAN,该网络通过引入混合注意力层来学习像素和图像之间的关系来增强图像同时达到去除噪声的目的。Qiao 等人[59]提出了一种基于反注意力机制的生成对抗网络方法,该方法利用深度聚合金字塔池模块结合多尺度背景信息来去除噪声,利用反注意力模块来消除色差提升增强图像的质量。Xu等人[60]提出了一种新的质量感知损失来进一步提升图像的质量。Jiang 等人[61]提出了一种无监督的分解与校正网络,并引入了噪声去除网络去除噪声。受CycleGAN[62]的启发,Bhattacharya 等人[63]提出了一种图像增强模型(D2BGAN),将几何和照明一致性以及上下文损失与多尺度颜色、纹理和边缘鉴别器相结合有效地去除了伪影。
无监督的方法不需要配对的数据集。该方法更加有效地关注低光图像与正常光图像之间的关系。一致性损失确保两者之间的相似性,注意力模块关注更深层次的全局与局部特征,因此得到的图像具有更好的效果。虽然不依赖配对数据集,但成像效果往往不是太好,并且依赖于较高的硬件条件。
综合以上方法,分别从有监督以及无监督两个方面进行归纳分析与总结。在有监督的方法中,设计端到端的网络提取更多的图像特征来确保图像的质量。在无监督的方法中,结合GAN 网络和其他无监督网络以及各种损失函数来引导网络生成高质量的增强图像。各种方法的对比如表2所示。

表2 基于深度学习的方法对比Table 2 Comparison of methods based on deep learning
3 数据集以及评价标准
3.1 数据集介绍
要想使训练的模型具有泛化性,必须要与数据集结合。深度学习指的是深度神经网络。所以说数据集对于训练来说是非常重要的。用于低光照图像增强的数据集根据是否有配对分为有配对数据集和无配对数据集。对应于有监督训练和无监督训练。有配对数据集有LOL、SICE、MIT-Adobe FiveK、SID、DRV。无配对数据集有Exclusive Dark、HDR等。
LOL 数据集[64]都是在现实环境中拍摄得到的。该数据集是一个含有大量真实场景图片的数据集,照片的最大尺寸是400×600。该数据集保留了真实条件下的特征和属性,广泛应用于图像增强研究中。
SICE 数据集[65]包括589 个来自室内和室外场景的图片,共包含4 413 张不同程度下的曝光图像。大多数图像的分辨率在3 000×2 000 到6 000×4 000 之间。在MEF 和HDR 算法评估、图像质量评估等方面有广阔的应用前景。
MIT-Adobe FiveK 数据集[66]由MIT 提出,为了解决训练量过大以及输出图像与输入图像之间的关联性不大的问题。包含了5 000 张图像,包括直接来自相机的原始图像和经过处理后的图像。数据集中约有4%的低光照图像,几乎涵盖了各种场景。
SID 数据集[67]包含了5 094 个原始的曝光不足的图像,每一个曝光不足的图像都对应一个正常曝光的图像。图像是由索尼相机Fujifilm 和Sony 拍摄。涵盖了室外场景和室内场景。室外场景通常是在光线不足的条件下拍摄,照度在0.2~5 lx之间。室内场景则更暗,照度在0.03~0.3 lx之间。
DRV数据集[68]是专门用于处理视频图像的。该数据集包含室内场景和室外场景,图片分辨率大小为3 672×5 496。
Exclusive Dark 数据集[69]由10 种不同类型的低光图像组成。HDR 数据集[70]包含74 个场景,原图大小为5 760×3 840。为了避免对其错位带来的问题下采样到1 500×1 000。
3.2 评价标准
3.2.1 主观评价
主观评价就是根据视觉效果进行评价。由于视觉评价具有一定的误差,所以主观评价只能是做个参考,不太能准确判定图像的增强质量。
3.2.2 客观评价
客观评价就是根据一定的数学公式计算,根据得出的结果值的大小来判定图像的增强质量,显然这种方法具有准确性,有很大的参考价值。常用的评价标准有均方误差(mean square error,MSE)、峰值信噪比(peak signalto-noise ratio,PSNR)、结构相似性(structural similarity index measurement,SSIM)、自然图像质量评估(naturalness image quality evaluator,NIQE)、信息熵(information entropy,IE)。
(1)MSE:均方误差,表示待评价图像质量与标准图像间的平均灰度的偏差程度,其值越小代表误差越小,图像品质也越好。公式如下:
其中,f′(i,j)和f(i,j)分别表示待评价图像和原始的图像,M和N分别表示图像的长与宽。
(2)PSNR:峰值信噪比,是一种评价图像的客观标准。其值越大代表图像质量越好。
MAXI表示图像颜色的最大数值,8位采样点表示为255。
(3)SSIM:结构相似性,是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。取值范围0-1,值越大代表失真越少。
其中,μx是x的平均值,μy是y的平均值是x的方差,是y的方差,σxy是x和y的协方差。c1=(k1L)2,c2=(k2L)2是用来维持稳定的系数,L是像素值的动态范围。k1=0.01,k2=0.03。
(4)NIQE:自然图像质量评估,是一个客观的评价指标,提取自然图像中的特征来对测试图像进行测试,这些特征拟合成一个多元的高斯模型。其值越低代表图像质量越好。
(5)IE:信息熵,代表了图像细节的丰富程度,其值越大说明图像的细节越丰富。
4 各种方法的分析对比
为了说明本文所述算法的效果及实用价值,本章将从方法性能以及方法复杂性两个方面进行分析对比。
4.1 性能分析对比
4.1.1 传统的低光照图像增强方法性能对比
在传统的低光照图像增强方法中,在不同场景下的低光照图像上测试。传统的低光照图像增强算法的性能对比如表3所示。

表3 传统的图像增强方法的定量比较Table 3 Quantitative comparison of traditional image enhancement methods
表3是上述传统方法用低光照图像测试的定量评估效果(IE 的值越大越好)。可见,由于Retinex 结合了颜色恒常性理论,使得增强后的图像更加自然,所以该方法的信息熵值最高,达到了7.94。保留了更多的细节信息,优于其他算法。
传统的低光照图像增强方法的定量比较如下:在传统方法中,直方图均衡化的IE值为4.43。色调映射算法的IE 值为7.27,比直方图均衡化方法提高了64.11%。伽马校正算法的IE值为7.78,比直方图均衡化方法提高了75.62%。暗通道先验算法的IE 值为7.16,比直方图均衡化方法提高了61.63%。Retinex分解的算法的IE值为7.94,比直方图均衡化方法提高了79.23%。基于融合的算法的IE 值为7.04,比直方图均衡化方法提高了58.92%。
4.1.2 基于深度学习的低光照图像增强算法性能对比
在深度学习的方法中,用Pytorch框架和Tensorflow框架基于LOL 数据集在GPU 上进行测试。并且设置Adam 优化器以及动态变化的学习率。初始学习率为0.000 1。基于深度学习增强方法的性能对比如表4所示。表4 是深度学习的方法的定量评估结果。在评估时在LOL数据集上进行测试,用PSNR指标进行定量评估,其值越大代表图像质量越好。如表4 所示,由于引入了标准化流模型来学习低光图像与正常光图像的映射关系,文献[38]所提方法的性能优于其他算法,在LOL数据集上的PSNR值达到了25.19。

表4 基于深度学习的图像增强方法的定量比较Table 4 Quantitative comparison of image enhancement methods based on deep learning
基于深度学习的增强方法的定量比较如下:
在有监督的方法中,MLLEN-IC 的PSNR 值为15.11。KinD 的PSNR 值为20.87,比MLLEN-IC 提高了38.12%。KinD++的PSNR 值为21.30,比MLLEN-IC 提高了40.97%。文献[38]的PSNR值为25.19,比MLLEN-IC提高了66.71%。DRGN的PSNR值为19.88,比MLLENIC提高了31.57%。HFMNet的PSNR值为22.64,比MLLENIC 提高了49.83%。MTRBNet 的PSNR 值为21.21,比MLLEN-IC提高了40.37%。DPFNet的PSNR值为24.15,比MLLEN-IC提高了59.83%。URetinex Net的PSNR值为21.33,比MLLEN-IC提高了41.16%。TBEFN的PSNR值为17.14,比MLLEN-IC提高了13.44%。FDMLNet的PSNR值为24.66,比MLLEN-IC提高了63.20%。STANet的PSNR值为21.35,比MLLEN-IC提高了41.30%。LiCENt的PSNR值为18.44,比MLLEN-IC提高了22.04%。HCSAMNet 的PSNR 值为24.52,比MLLEN-IC 提高了62.28%。文献[51]的PSNR值为24.92,比MLLEN-IC提高了64.92%。
在无监督的方法中,Zero-DCE的PSNR值为14.86。文献[52]的PSNR值为21.52,比Zero-DCE提高了44.82%。EnlightenGAN 的PSNR 值为17.48,比Zero-DCE 提高了17.63%。LEGAN 的PSNR 值为22.45,比Zero-DCE 提高了51.08%。CIGAN的PSNR值为19.89,比Zero-DCE提高了33.85%。MAGAN 的PSNR 值为22.39,比Zero-DCE 提高了50.67%。AABGAN 的PSNR 值为19.38,比Zero-DCE提高了30.42%。文献[60]的PSNR值为20.38,比Zero-DCE提高了37.15%。UDCN的PSNR值为19.83,比Zero-DCE 提高了33.45%。D2BGAN 的PSNR 值为16.53,比Zero-DCE提高了11.24%。
4.2 复杂度分析对比
4.2.1 传统的低光照图像增强方法复杂度对比
为了评估传统的低光照图像增强算法实用价值,对所述算法的复杂度进行了分析对比,如图6所示。

图6 传统的图像增强方法的复杂度与效果对比Fig.6 Comparison of complexity and effect of traditional image enhancement methods
由图6 可以看出,算法的复杂度在不断提高,但是效果在不断变好。
4.2.2 基于深度学习的低光照图像增强算法复杂度对比
为了评估基于深度学习的低光照图像增强算法实用价值,对所述算法的复杂度进行了分析对比,如表5所示。
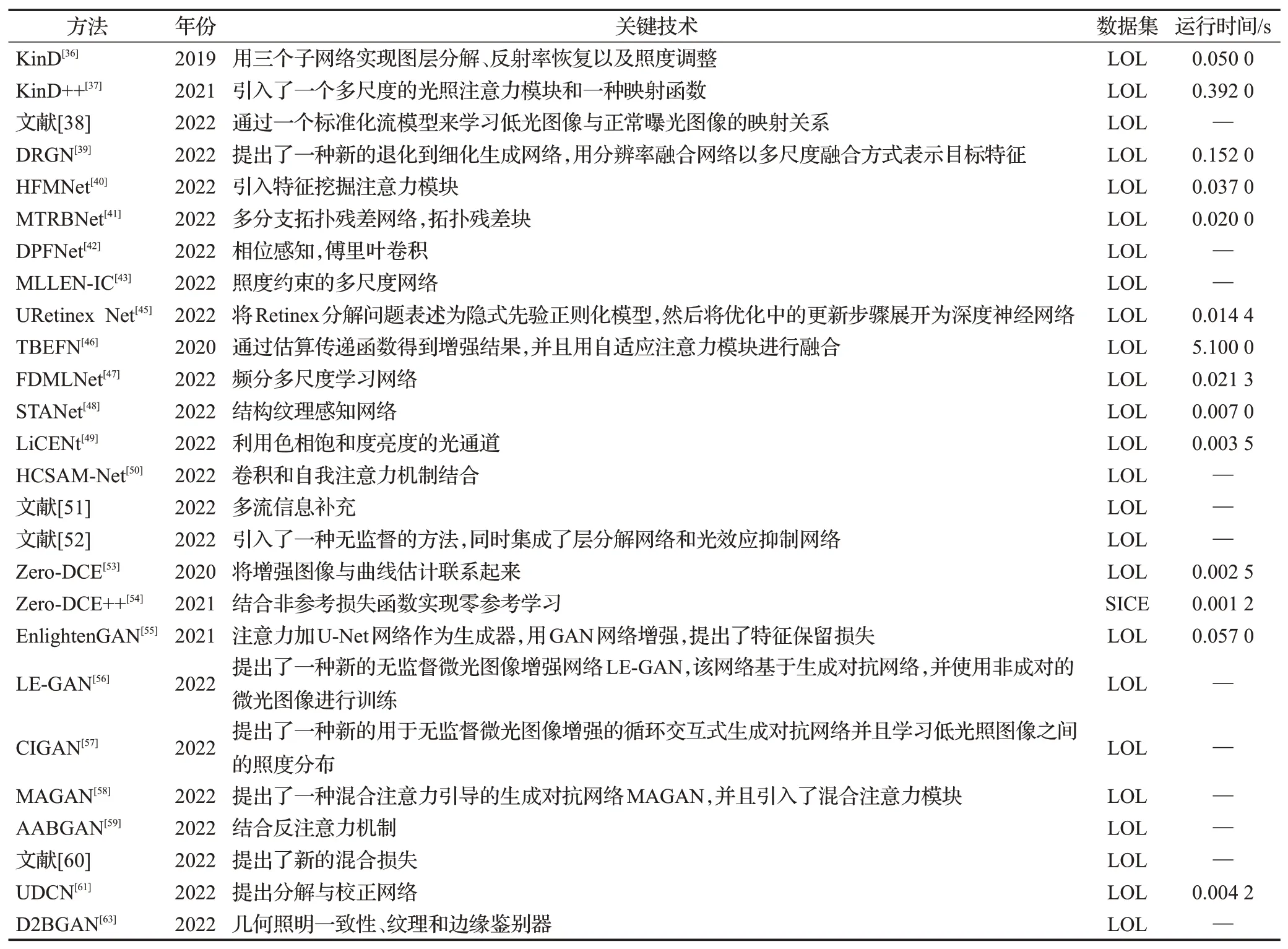
表5 基于深度学习的图像增强方法的复杂度对比Table 5 Comparison of complexity of image enhancement methods based on deep learning
如表5 所示,本文以算法的运行时间来进行评估。可以看出,Zero-DCE++通过直观和简单的非线性曲线映射实现图像增强,具有最快的运算速度。优于其他算法。表中“—”表示评估时未用到该指标或该数据集。
5 总结及展望
本文总结了近年来的低光照图像增强技术。对于传统的方法进行了分类阐述,对于深度学习的方法将其分为有监督方法和无监督方法进行详细的阐述与分析。又详细介绍了所用到的数据集。最后详细给出了所用到的主流的评价指标。深度学习的方法与传统方法相比更加快捷,但也会出现细节信息丢失、图像特征提取不到位、噪声的产生等问题。通过深入研究文献,发现低光照图像增强方法仍然面临着诸多挑战以及仍有许多未来可研究的方向。
(1)结合一些特定的网络结构
应用合适的网络结构能极大地提高增强的图像质量,之前的方法大都是以U-Net 网络结构为基础改进的,但是这样并不能保证能适用于所有的低光照图像增强的情况,又考虑到低光图像的对比度低,像素值小等情况,选用合适的网络结构应用于增强是很有必要的。结合低光照图像的特点,深度可分离卷积[71]、自校准卷积[72]可以替换原有的网络;结合神经结构搜索技术[73-74]获得更加高性能的网络结构;Transformer可以更加关注输入与目标之间的关系,将Transformer[75-80]应用于低光照图像增强可以得到质量较高的图像。因此,如何结合低光照图像的特点进一步地探究合适有效的网络结构尽可能多地获取到图像的特征用于后续处理也是一个未来的研究方向。
(2)使用新的损失函数
损失函数是决定生成图像与原始图像质量的关键。目前的大多数模型都是参考视觉任务来设计的,常用的损失函数已经不能解决一些特定问题,所以设计一种新的损失函数是非常有必要的。一些深度神经网络[81-82]的理论给图像增强任务带来了可能。因此,如何将现实的视觉效果与低光图像的特征相结合来设计损失函数是一个极具潜力的研究方向。
(3)低光照视频增强
虽然低光照图像增强研究较多,但是低光照视频增强的研究却很少。低光照视频需要考虑视频帧与帧之间的连续性以及闪烁问题。将现有的方法直接应用到低光照视频增强中,往往会产生伪影以及不连续的问题。因此如何应用到视频领域以及结合视频去模糊[83-84]以及视频超分辨率[85]保持视频帧与帧之间的连续性也是一个未来值得研究的方向。
(4)结合语义信息
近年来,语义信息应用得越来越多,在低光照图像增强中也是十分重要的。语义信息包含了图像的颜色等特征,能使得网络区分图像中的不同亮度的区域,对于细节恢复很有益处,已经广泛应用于图像超分辨率[86-87]、人脸修复[88]等方面。因此,利用语义信息带来的优势结合语义信息[89]也是一个未来的热门研究方向。
