基于改进DeepLabv3+的火龙果园视觉导航路径识别方法
2023-09-23周学成肖明玮梁英凯商枫楠罗陈迪
周学成 肖明玮 梁英凯 商枫楠 陈 桥 罗陈迪
(1.华南农业大学工程学院,广州 510642; 2.南方农业机械与装备关键技术教育部重点实验室,广州 510642)
0 引言
水果产业已成为我国继粮食和蔬菜之后的第3大农业种植产业,我国水果种植面积和产量常年稳居世界首位[1]。尽管我国水果产业已经逐步实现规模化种植,但是机械化采摘程度依然较低,大多仍以人工采摘为主,和发达国家相比存在明显差距。由于果园环境多为半结构化环境,大型机械作业受限,限制了果园机械智能化的发展[2]。因此我国迫切需要提高果园机械化、智能化水平,提高生产效率[3]。视觉导航作为果园机械提升智能化水平的关键技术之一,具有成本低、信息丰富等特点,适用于不规则地块[4]。而且有效弥补了果园因树叶遮挡、卫星信号弱而无法进行导航的情况[5]。能够实时准确地识别导航路径是当前国内外学者研究的重点。
目前在果园环境下的导航路径识别研究中,研究人员通常将果树树干或者作物行作为获取导航信息的参照物,利用参照物具有的颜色、形态和纹理特征运用传统的图像处理技术提取出导航路径。目前已有针对苹果园[6]、黄瓜园[7]、橙园[8]、枸杞园[9]、桃园[10]等环境的视觉导航研究。但是,在设施农业、果园等复杂环境中,图像处理算法易受光照、阴影的影响[11]。而且果园道路属于非结构化道路,无明显道路边界线,传统图像处理算法不能完全适用。
近年来随着深度学习技术的不断发展,许多研究人员将深度学习技术应用在导航路径的识别研究中[12-15],与传统的语义分割方法相比,基于深度学习的语义分割方法能获取更多、更高级的语义信息来表达图像中的信息[16]。SONG等[17]利用全卷积网络(FCN)对小麦、地面和背景进行语义分割,进而拟合出导航路径。KIM等[18]提出了一种半结构化环境自主路径检测方法实现路径区域分割。YANG等[19]提出了一种基于神经网络和像素扫描的可视化导航路径提取方法。韩振浩等[20]提出了一种基于U-Net网络的果园视觉导航路径识别方法。
以上基于深度学习算法的导航路径识别研究为本研究提供了借鉴。然而在火龙果园导航路径检测识别任务中,果园道路存在的杂草以及掉落的枝条,使得道路的边界信息模糊,增加了导航路径的识别难度。而且大多数研究较少关注模型的部署问题,所提出的网络结构较为复杂,使得模型的参数量大,不利于部署至硬件条件有限的果园视觉导航系统。为此,针对视觉导航应用在果园环境中面临干扰因素多、图像背景复杂、复杂模型难以部署等问题,本文以火龙果园的自然环境为研究对象,提出一种基于改进DeepLabv3+网络的果园视觉导航路径识别方法。本研究选择轻量化的MobileNetV2替换原网络中的主干特征提取网络,并将空间金字塔池化模块(Atrous spatial pyramid pooling,ASPP)中的空洞卷积替换成深度可分离卷积(Depthwise separable convolution,DSC),以降低模型的复杂度。为了提高模型对道路特征的提取能力,考虑在特征提取模块处引入坐标注意力机制(Coordinate attention,CA);最后利用网络模型生成的道路掩码,得到道路的边界信息并通过最小二乘法拟合道路边界,再运用角平分线算法拟合出导航路径。
1 材料与方法
1.1 图像数据获取
本研究所需的果园图像数据于2022年7月采自广州市番禺区火龙果种植园。拍摄设备为英特尔公司生产的D435i深度相机,图像数据通过USB接口传输并保存在计算机内,自动曝光;图像分辨率为1 920像素×1 080像素,以PNG格式存储,图像采集帧率为30 f/s。数据采集时将深度相机固定在相机支架上,向下倾斜10°,拍摄方向为道路正前方。根据研究目标,本文只对果园垄间道路进行图像数据采集,不包括果园地头以及果树行间。为了提高样本的多样性,分别在不同道路条件下共采集原始图像456幅,如图1所示。

图1 火龙果园道路图像示例
1.2 果园道路数据集制作
通过相机直接获取的原始图像分辨率较高,在训练时会占用过多显存,降低训练速度,同时图像没有语义标签,需要预先进行标注,才能传入神经网络进行训练。为了减少模型训练时间,将456幅原始图像尺寸等比例缩放为960像素×540像素,再使用像素级标注工具Lableme进行语义标注,标注后的文件以.json格式存储。针对现场采集的数据样本量不足,本文通过几何变换(平移、旋转)与颜色变换(对比度、亮度)进行数据增强。增强后的图像共1 074幅,按照8∶1∶1比例划分为训练集、验证集和测试集。训练集用于训练深度网络模型参数权重;验证集用于训练过程中对模型参数进行调优;测试集用于评估最终模型的泛化能力。
2 果园道路场景语义分割
2.1 改进的DeepLabv3+语义分割算法
DeepLabv3+网络被称为语义分割网络的新高峰,但也存在不足。首先,为了追求分割精度,选择了网络层数较多、参数量大的Xception作为特征提取网络,同时ASPP模块中采用空洞卷积,使得模型参数量增加,提高了模型的复杂度;另外,这些特点也对硬件提出了更高要求[21]。为了使得移动机器人能够实时准确地识别果园道路,确保该网络模型能够部署在嵌入式设备上,本文针对上述问题对传统的DeepLabv3+网络进行了如下改进:首先,为了减小参数计算量并降低模型的复杂度,将DeepLabv3+模型中原本用于主干特征提取的Xception网络更换成更为轻量级的MobileNetV2。为了增强模型学习特征的表达能力,在主干提取网络输出的高层特征层处添加CA模块。为了提高模型的检测速率,减小内存占用量,将ASPP模块中的空洞卷积替换成深度可分离卷积。改进后的网络结构如图2所示。
2.2 轻量化特征提取模块
传统的卷积神经网络通过扩充网络深度和广度,提高网络模型准确性,但也存在复杂度高、运行速度慢等问题。MobileNetV2是由谷歌团队在2018年提出的高性能轻量化的卷积神经网络,相对于MobileNetV1而言准确率更高,模型更小[22]。MobileNetV2采用一种具有线性瓶颈的残差结构,该模块将输入的低维压缩表示首先扩展到高维并用轻量级深度卷积进行过滤。随后用线性卷积将特征投影回低维表示。最后采用跨连接层将输入特征与输出特征相加,从而增加网络的实时性和准确性。为了让MobileNetV2模块能够适用于语义分割,本文对该网络结构做了如下修改:将第1部分用于提取特征的3×3卷积块以及包含多个深度可分离卷积的中间部分保留,把包含全局平均池化层与特征分类层的第3部分去掉。
2.3 CA模块
注意力机制常用来告诉模型需要更关注哪些内容和哪些位置,已经被广泛使用在深度神经网络中来加强模型的性能。HOU等[23]为轻量级网络设计提出了新的注意力机制,该机制将位置信息嵌入到了通道注意力中,称为坐标注意力机制(Coordinate attention,CA)。
不同于通道注意力将输入通过2维全局池化转化为单个特征向量,CA将通道注意力分解为两个沿着不同方向聚合特征的1维特征编码过程。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后,将生成的特征图分别编码,将其互补地应用于输入特征图,以增强关注对象的表示。该模块的结构如图3所示,图中C表示通道数,H表示特征图高度,W表示特征图宽度。
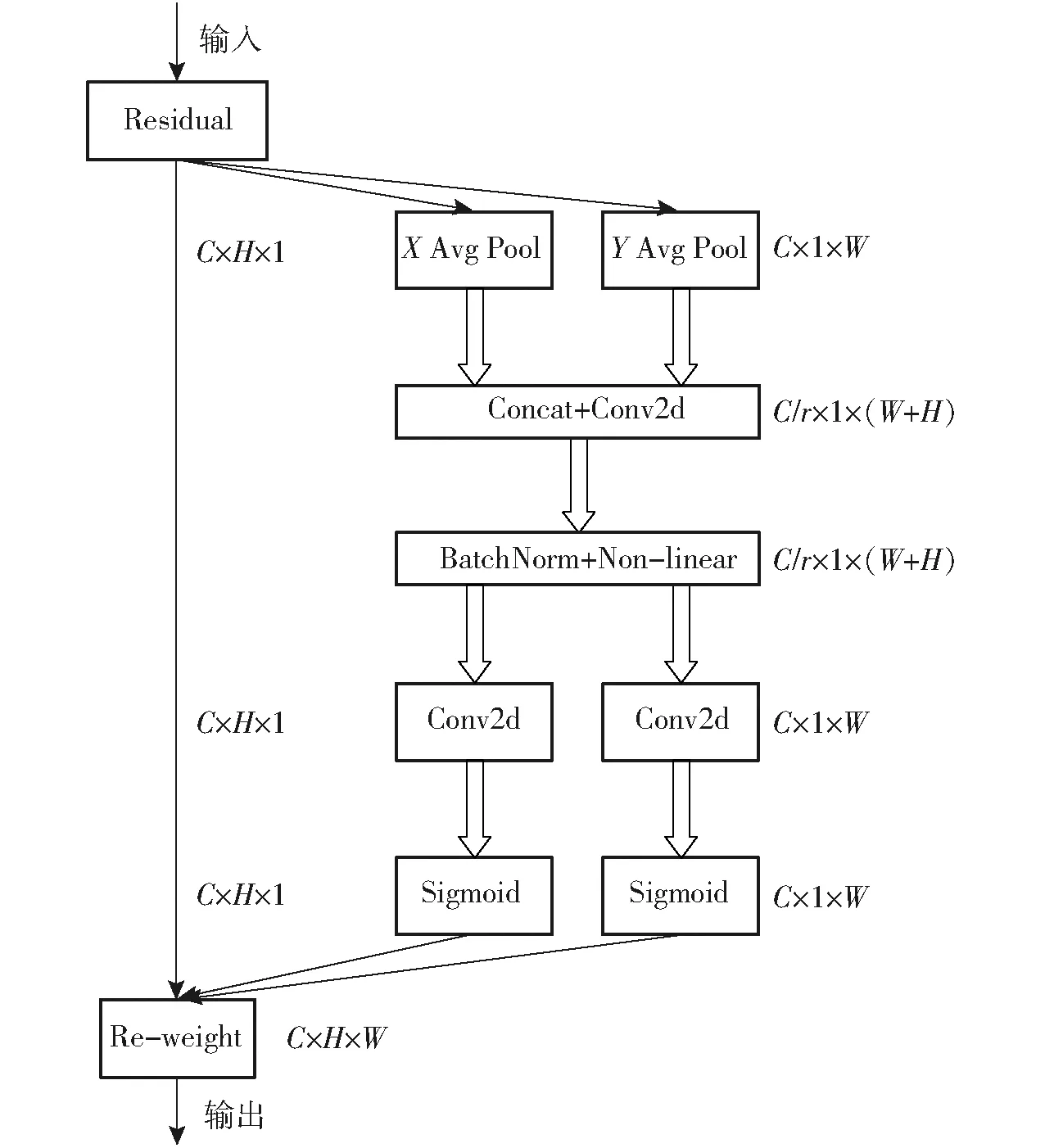
图3 坐标注意力机制结构图
2.4 网络损失函数
损失函数是一种用来度量模型预测值与真实值之间差异程度的函数,损失函数的值越小,模型的鲁棒性就越好。为了解决处理前景和背景体素数量之间存在严重不平衡的问题,MILLETARI等[24]提出了DiceLoss。本文将其作为损失函数,其表达式为
(1)
式中LDice——损失函数Dice——损失系数
X——真实分割图像的像素类别
Y——模型预测分割图像的像素类别
|X∩Y|——X和Y的点乘结果之和
|X|——X对应图像中的像素之和
|Y|——Y对应图像中的像素之和
3 导航路径拟合
本文研究所涉火龙果园采用较为规范化的种植模式,果园道路较为平直,采摘机器人可将道路中线作为导航路径。常用的直线拟合算法包括霍夫变换、随机采样一致性、最小二乘法等[25]。果园道路非结构化,道路边缘信息不规则,为此本文利用网络模型生成的道路掩码,提出一种基于道路边界拟合的角平分线提取导航路径算法。通过逐行扫描提取道路左右边缘信息点,再根据边缘信息点用最小二乘法拟合出道路左右边界线,最后利用角平分线算法拟合导航路径。具体流程如图4所示。
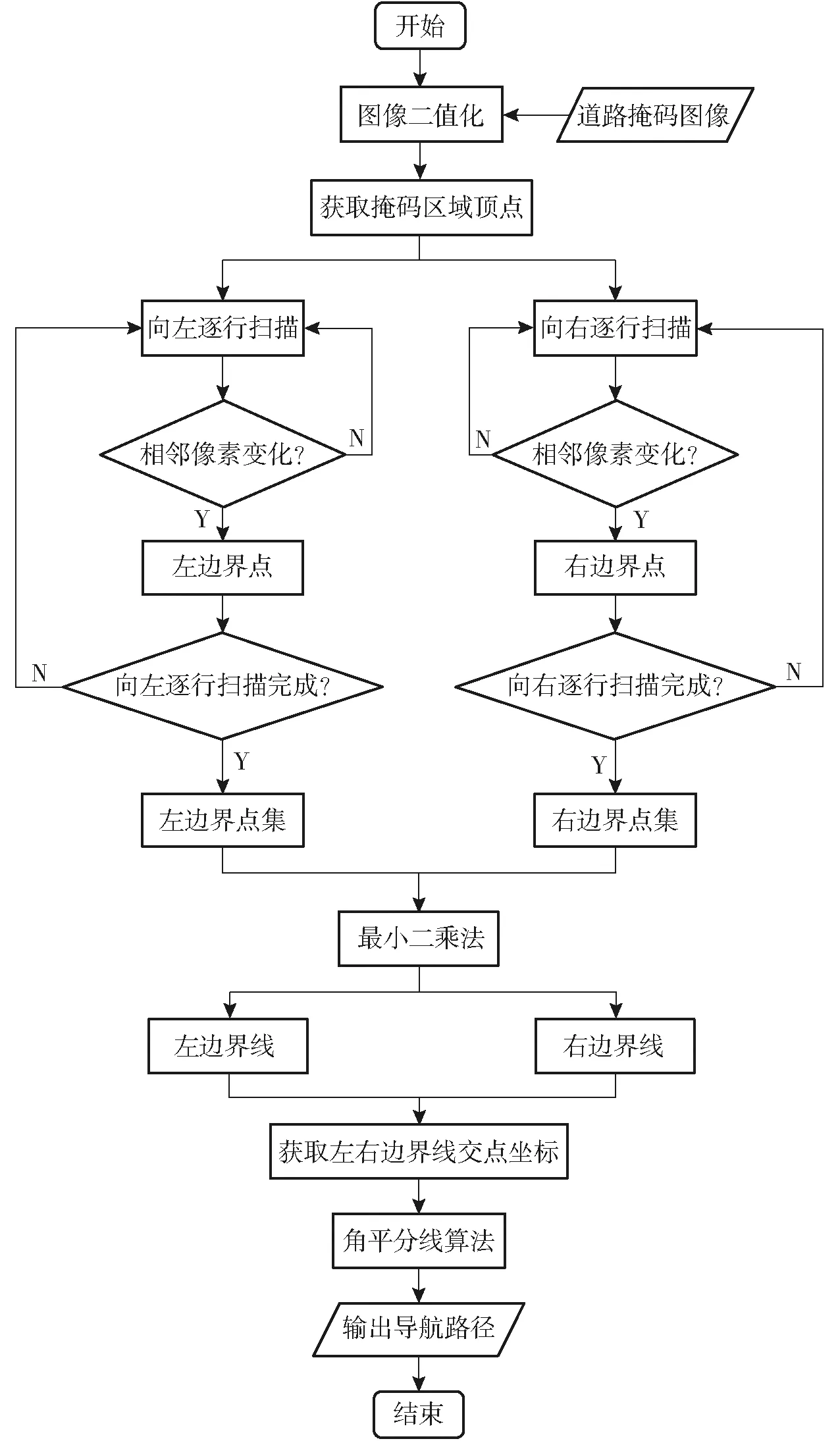
图4 导航路径拟合流程图
3.1 道路边缘信息提取
首先对模型生成的道路掩码区域二值化,使得掩码区域像素值为255,背景区域像素为0。道路掩码区域可以近似看成上底边有凸起的梯形区域,如图5所示。为了提取道路的边缘信息,首先需要确定掩码区域的顶点。逐行扫描像素,以掩码区域图像的前景首行像素的所有像素的中点位置为顶点,并记录下此时顶点的坐标(W,H)。其次以顶点的横坐标W当作逐行扫描的分界线,以分界线为基准,分别向左、向右扫描。如果向左扫描时某个像素点的相邻两列像素值不同,则该点记为左边界点。同理向右扫描时,如果某个像素点的相邻两列像素值不同,则记为右边界点,直到整幅图像像素遍历完毕。

图5 图像分割结果
3.2 基于角平分线算法拟合导航路径
根据得到的道路边缘信息,用最小二乘法拟合出道路边界。但根据果园导航的需求,如果选择道路边线当作导航路径会造成较大的导航偏差,而且也不利于采摘,为了提高导航路径的精度,本研究将道路左右边界线的角平分线当成导航路径。图像坐标系中道路左右边界直线分别为mL和mR,假设mL和mR直线方程分别为
yL=kLx+bL
(2)
yR=kRx+bR
(3)
式中yL、yR——道路左边界和右边界对应点的纵坐标值
kL、kR——道路左、右边界直线方程斜率
bL、bR——道路左、右边界直线方程截距
为了得到正确的导航线斜率,本文利用向量来求解。假设左右边界线的交点记为点O(x0,y0),随机在左右边界线上分别取两个点,记为点A(xa,ya)和B(xb,yb),则有
lOA=(xa-x0,ya-y0)
(4)
lOB=(xb-x0,yb-y0)
(5)
考虑将lOA和lOB归一化,需要求出2个向量的模长,根据模长公式则有
(6)
(7)
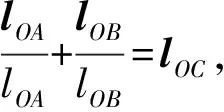
(8)
(9)
b=y0-k
(10)
从而得到导航基准线方程为
y=k(x-x0)+y0
(11)
3.3 导航路径精度测试方法
本文通过人工方法来拟合果园实际导航路径。首先通过卷尺测量同一行左右两棵果株间的距离,然后在中点位置做好标记,接着利用白色尼龙绳将测得的中点位置依次连接。为了使得实际导航路径更加精确,用钉子将尼龙绳加以固定。本文从像素误差、实际距离两个参数指标来评价拟合导航路径的精度。将相机支架放置在道路中间,拍摄角度和采集图像时一致,从道路尽头开始,从拟合导航路径上以70像素为间距等距选取10个关键点,利用D435i制造商提供的SDK来计算每幅图像上10个关键点与分别对应具有相同纵坐标的实际导航路径上10个点之间的像素误差和实际距离。像素误差的计算公式为
epix=|Xfit-Xreal|
(12)
式中epix——像素误差
Xfit——拟合导航路径上关键点的像素横坐标
Xreal——实际导航路径上关键点的像素横坐标
为了将图像中的像素误差转换为火龙果园中的实际距离,根据针孔成像模型分别将拟合导航路径以及实际导航路径上关键点的像素坐标转换成相机坐标,通过计算两点的欧氏距离得到实际距离。相机的内外参数以及畸变参数已标定,坐标转换公式为
(13)
其中
(14)
(15)
式中 (u,v)——像素坐标
fx、fy、u0、v0——相机内参
(xcorrected,ycorrected)——归一化平面纠正坐标
k1、k2、p1、p2——相机畸变参数
r——归一化平面极径
(X,Y,Z)——相机坐标系坐标
(x,y)——归一化平面直角坐标
4 结果与分析
为了验证基于改进DeepLabv3+的火龙果园导航路径识别算法以及基于角平分线算法拟合导航路径的准确性、稳定性和鲁棒性,分别进行了果园道路分割和导航路径提取实验。
4.1 果园道路分割
4.1.1实验平台
本研究所使用的训练平台为配备Windows 10 64位操作系统的台式图形工作站,其中CPU为Intel i9 10900X@3.75 GHz,GPU为NVIDIA GeForce GTX3090,RAM为128 GB,软件环境为PyTorch 1.7.1,CUDA 11.1,以及CUDNN 8.0.2。
4.1.2训练参数设置
训练前,将数据集中的1 074幅图像按照8∶1∶1随机划分为训练集、验证集和测试集,训练集有860幅图像,验证集和测试集分别有107幅图像。DeepLabv3+模型在批量大小为16、初始学习率为0.007时,在Pacal VOC 2012和Cityscapes数据集上取得了良好的分割效果[26]。本研究将其作为模型训练超参数,同时根据经验,优化方法选择随机梯度下降优化器(SGD),优化器动量设置为0.9,权重衰减设置成0.000 1,采用余弦退火的学习率下降方式。为了提高模型精度,使用Pytorch官方提供的MobileNetV2预训练权重。由于本文需求是分割道路和背景,故将分类个数设置成2,并训练300个周期。
4.1.3评价指标
本文采用平均像素准确率(Mean pixel accuracy,MPA)、平均交并比(Mean intersection over union,MIoU)、检测速率(Frames per second,FPS)、模型内存占用量、参数量(Params)作为语义分割算法性能评价指标。假设总共有k+1个类,令Pij表示第i类被预测为第j类的像素数量,则Pii表示预测准确的像素数量。
4.1.4改进前后网络模型训练结果对比
改进前后的DeepLabv3+网络的训练过程如图6所示。根据图6可知,随迭代次数增加,二者的训练集损失值呈减少趋势,而且随着迭代次数逐渐增加,MIoU越来越高。当迭代次数到达100次时,二者的损失值和精度均趋于稳定。但是与传统DeepLabv3+网络比较,改进后的DeepLabv3+网络的收敛速度更快,精度也更高。

图6 改进前后网络模型训练结果
4.1.5模型有效性验证
为了验证在传统DeepLabv3+网络中添加CA注意力机制模块的有效性,从测试集中选取了一幅道路条件较为复杂的图像进行验证,如图7所示。原始图像的右下方区域包含较多的杂草,同时由于受到光照的影响,路面上存在周边果株的投影区域。对比图中绿色椭圆区域分割结果发现,传统DeepLabv3+网络模型丢失了部分道路边缘信息,而且未能分割出道路存在杂草覆盖的区域。而添加CA模块后的DeepLabv3+网络模型对道路边缘信息提取更完整,能准确分割出覆盖杂草的道路,说明添加CA模块后提高了网络模型的特征提取能力。
为了验证将传统DeepLabv3+网络中的主干特征提取网络由Xception更换为轻量级的MobileNetV2的有效性,以及验证添加注意力机制模块CA、替换ASPP模块中的空洞卷积为深度可分离卷积对分割结果的影响,本文根据语义分割评价指
标,设置4组不同的改进方案进行消融实验,实验结果如表1所示。

表1 消融实验结果
根据表1可得,将DeepLabv3+的主干网络由Xception换成MobileNetV2后检测速率提升23.55 f/s,而且极大减小了参数量以及模型内存占用量,参数量和模型内存占用量仅为原来的1/9。其次,主干网络为MobileNetV2的基础上添加CA模块后,MIoU以及MPA分别提升0.46、0.26个百分点,表明CA模块可以在一定程度上提高模型分割精度。另外,将APSS模块中的空洞卷积换成DSC时,相比原来的训练结果MIoU和MPA有略微下降,分别降低0.20、0.08个百分点,但是参数量和模型内存占用量分别减小33.70%、33.50%,表明DSC可以有效降低模型复杂度。最后,本文提出的改进DeepLabv3+网络模型的训练结果和原模型相比,无论是分割精度还是检测速率都有明显提升,更重要的是改进后的网络模型的参数量和模型内存占用量仅相当于原来的1/14。因此改进DeepLabv3+模型可以更好适用于果园道路的检测,而且也便于在嵌入式设备和移动设备上部署。图8为改进网络在不同环境条件下果园道路场景分割效果图。

图8 不同环境条件下果园道路场景分割结果
从图8可以看出,白色地膜道路图像中的道路区域被有效分割,分割结果没有受到地面散落枝条的影响;黑色地膜道路图像中,路面不但覆盖杂乱无章的杂草,而且由于光照的影响,路面上还存在周边果株的投影区域,但分割结果并没有受到复杂路面环境的影响,道路分割完整,同时道路尽头的白色地膜道路没有被错误分割为背景,而是和黑色地膜区域一块识别为道路区域,说明模型具有良好的抗干扰性;在无地膜道路图像中,道路无明显边界,而且无地膜道路的杂草较为密集,同时沙土路面潮湿且不平整,加上光照的影响,这些复杂环境因素会对分割结果造成干扰,但根据模型的预测结果,道路边缘信息完整,道路的左右边界连续且对称分布,分割效果精细,说明模型具有较高的鲁棒性。
4.1.6不同模型性能对比
为了进一步分析改进DeepLabv3+模型的分割性能,选择分割精度较高的Pspnet、U-net与本文模型进行对比,以上网络模型均利用果园道路数据集进行训练,训练结果如表2所示。

表2 不同网络模型性能对比
由表2可以看出,本文模型和Pspnet相比,无论是在分割精度还是检测速率都优于后者,其中MIoU和MPA分别提高0.49、0.25个百分点,另外检测速率提高11.7 f/s,参数量和模型内存占用量减小91%。另外本文模型相较于U-net,尽管在分割精度上略低于后者,但是在检测速率、参数量和模型内存占用量方面都显著优于U-net,其中检测速率提升20.58 f/s,参数量和模型内存占用量分别减小4.003×107和152.0 MB,相比U-net,本文模型更加适合部署至嵌入式设备,而且保证了模型具有较高的分割精度的同时也更加轻量化。
4.2 导航路径提取
选择白色地膜道路、黑色地膜道路、无地膜道路3种不同的道路环境来验证本文设计的导航路径提取算法精度。导航路径识别结果如图9所示(上图为原始图像,下图为结果图像)。从图9中可以看出,本文方法能够完整提取道路两侧的边缘信息,而且通过最小二乘法拟合出道路边界线与两侧的果树行衔接紧凑,角平分线算法拟合的导航路径能够有效减小不规则道路边缘对导航路径提取的干扰。

图9 不同环境条件下果园导航路径识别结果
3种不同道路条件下的导航路径精度测试结果如表3所示。在白色地膜道路条件下,平均像素误差和平均距离误差分别为17像素和7.42 cm。在黑色地膜道路条件下,平均像素误差和平均距离误差分别为32像素和10.55 cm。在无地膜道路条件下,平均像素误差和平均距离误差分别为17像素和4.76 cm。可得不同道路条件下的平均像素误差是22像素,平均距离误差是7.58 cm。已知所在火龙果园的道路宽度为3 m,平均距离误差占比为2.53%。在当前火龙果园环境中本文方法具有较高的精度,能够适应不同的火龙果园道路环境。

表3 导航路径精度测试结果
5 结论
(1)提出了一种基于改进DeepLabv3+的火龙果园道路识别方法,通过加入CA模块提高了模型的特征提取能力;另外将原模型中的主干特征提取网络更换成MobileNetV2,以及将ASPP模块中的空洞卷积更换成DSC,极大降低了模型内存占用量,改进模型和原模型、Pspnet以及U-net相比内存占用量分别减小97.00%、91.57%和91.02%。并且检测速率和平均交并比分别提升至57.89 f/s和95.80%,说明本文模型更加适合部署至嵌入式设备上。
(2)根据网络模型分割出的道路掩码,提出一种基于道路边界拟合的角平分线提取导航路径算法,该算法能准确提取出导航路径。
(3)在火龙果园3种不同道路环境条件下,进行了导航路径精度测试实验。实验结果表明,平均像素误差为22像素,平均距离误差为7.58 cm。已知所在果园道路宽度约为3 m,平均距离误差占比为2.53%。说明本文提出的导航路径拟合方法具有较好的适应性。因此本研究可以为火龙果园视觉导航提供有效参考。
