结合特征融合的跨域服装检索
2023-09-15乐鸿飞余锦露
魏 雄,乐鸿飞,余锦露
(武汉纺织大学 计算机与人工智能学院,湖北 武汉 430200)
0 引言
随着服装电子商务的快速发展,互联网上的服装图像数量急剧增长,对海量服装图像进行自动化准确检索有助于提高顾客购买意愿。目前服装图像检索方法主要分为基于文本的检索和基于内容的检索两种[1]。国内电商平台主要使用基于文本的图像检索,但这种方法过于依赖对图像的文本标注,且在语言表达习惯的限制下,其检索结果与顾客需求可能大相径庭。因此,基于内容的跨域服装图像检索技术具有很大研究意义。
跨域服装检索是指待检索图像和图像检索库来自两个异构域,分别为用户域和商店域。用户域由用户拍摄的照片组成,这些照片可能会因照明条件、相机质量、角度和焦距而有所不同;商店域由专业人士在相同工作室使用同一设备拍摄的同一风格的照片组成。跨域服装检索任务主要有以下两个难点:①服装图像可变性极大。同一件服装在拍摄角度、光线、对象不同时所得图像会有很大不同,用户域的查询图像多在复杂环境下拍摄,包含多个对象,服装经常被遮挡或裁剪,而大多数商店的图片背景是单色,光线良好,服装单品完全可见;②类内方差大、类间方差小。这是服装图像的一个固有特性[2]。
图像表征在服装检索任务中起到核心作用,用于对图像内容进行编码,并衡量其相似性。随着深度学习技术的发展,智能提取表征的方法取得很大进展[3-5],手工特征提取已逐步废弃。基于深度学习的服装检索方法中,两种类型的图像表征被广泛使用:一种是全局特征作为高级语义图像签名;另一种是局部特征,包含特定图像区域的几何判别信息。目前,跨域服装图像检索方法缺少对局部特征的利用,一些利用局部特征的方法先通过高查全率的全局特征检索候选对象,然后利用局部特征重新排序,进一步提高精度,然而这样提高了计算代价和检索时间[6]。更重要的是,两个阶段均不可避免地存在错误,这可能导致错误积累,成为进一步提高检索性能的瓶颈。因此,将局部特征与全局特征集成为一个紧凑的表征,在端到端检索中相互促进,可以避免错误积累,该方法成为目前研究热点。
1 相关研究
对图像特征提取的好坏直接影响跨域服装图像检索算法的性能。传统特征提取方法包括方向梯度直方图(Histogram of Oriented Gradient,HOG)、局部二值模式(Local binary patterns,LBP)、颜色直方图等。例如,Liu 等[7]提出首个跨域服装检索方法,通过定位30 个人体关键区域缩小人体姿势的差异,然后通过对这些区域提取HOG 和LBP 等手工特征进行检索。然而,传统算法在跨域服装检索准确度方面表现欠佳。
近年来,深度神经网络在服装检索领域广泛应用,将该领域的发展推向了一个新的阶段。例如,Luo 等[8]提出一种端到端的深度多任务跨域哈希算法,与传统方法学习离散属性特征不同,该方法考虑属性之间的顺序相关性,并为属性序列激活空间注意力;同时使用哈希散列组件替代传统连接的特征向量,避免低效的查询处理和不必要的存储浪费。然而面对细分种类繁多的服装图像时,该方法能学习的顺序属性有限;Kuang 等[9]提出基于相似金字塔的图推理网络,通过在多个尺度上使用全局和局部表示来学习查询图像与库之间的相似性。其中相似度金字塔采用相似度图表示,图中的每个节点为对应的两个服装区域在相同尺度下的相似度,连接两个节点的每条边是它们的归一化相似度,查询图像与图库图像之间的最终相似度可以通过在这个图上进行推理来实现;Mikolaj 等[10]分析了人的再识别研究领域与服装检索研究领域的相似性和差异性,然后考察了行人再识别模型的可转移性,将调整后的模型应用于跨域服装检索,取得显著的检索效果,为跨域服装检索引入了强有力的基线;刘玉杰等[11]将空间语义注意力模块加入到分类网络VGG16 模型中,对卷积层特征赋予可学习的权重,以增强重要特征、抑制不重要特征;同时引入短链接模块,整合整幅图像的深层语义特征以获得更具鲁棒性的特征描述子,解决服装部位不对齐导致的重要信息丢失问题。然而,该方法分类精度不佳,在使用分类损失约束的情况下检索准确率较低。
对局部特征与全局表示进行联合学习可以提高检索效果。例如,Song等[12]提出一种融合局部与全局建模的框架,该框架在利用Transformer 进行全局特征提取的基础上设计了一个由多头窗口注意和空间注意组成的局部分支,基于窗口的注意模式模拟了局部重叠区域内的不同视觉模式,而基于空间的注意模式模仿了重要性抽样策略,最后通过交叉注意模块将分层的局部与全局特征结合起来;Sarlin 等[13]提出一种联合估计局部和全局特征的卷积神经网络(Convolutional Neural Network,CNN)——HFNet,其以固定的非学习方式解码关键点和局部描述符,并将其与转置卷积得到的全局特征聚集成一个紧凑的描述符,这样能快速高效地处理大规模图像。然而,即使该方法使用了多任务蒸馏来提高准确率,检索精度仍较低;Cao 等[14]提出基于ResNet的可以联合提取局部和全局图像特征的DELG(Deep Local and Global features)模型,其利用广义平均池产生全局特征,利用基于注意的关键点检测产生局部特征。然而,该模型虽然使用了端到端的框架,在执行上还是分为两阶段,较为繁琐。
本文在CNN 的基础上引入一种深度正交局部与全局特征融合模块[6],通过一个局部分支和一个全局分支分别学习两类特征,并由一个正交融合模块将其结合起来,聚合为一个紧凑描述符。通过正交融合可以提取最关键的局部信息,消除全局信息中的冗余分量,从而使局部与全局分量相互增强,产生具有目标导向训练的最终代表描述子。本文贡献如下:①设计了基于全局和局部特征融合的跨域服装检索方法,能融合低层局部特征与高层全局特征,使用相互增强的融合特征进行检索;②在DeepFashion数据集上进行了广泛的实验分析。结果表明,该方法能有效提高检索准确率,并缩短了检索时间。
2 融合全局与局部特征的服装图像检索方法
图1 为融合全局与局部特征的服装图像检索网络框架。对于输入图像,首先使用骨干CNN 提取特征,使用全局和局部特征融合模块获取全局特征与局部特征互相增强的融合表示;然后使用全局平均池化的方法得到全局特征向量,分别计算三元损失、中心损失和质心损失;最后对全局特征向量进行归一化,得到图像嵌入。该图像嵌入在训练期间作为全连层的输入用于计算分类损失,并结合之前得到的3 种损失计算联合损失以约束聚类任务。在检索阶段,该图像嵌入用于计算相似距离,并基于该距离使用质心损失方法进行检索。

Fig.1 Framework for clothing image retrieval network integrating global and local features图1 融合全局与局部特征的服装图像检索网络框架
2.1 特征融合模块
2.1.1 全局与局部分支
局部特征分支的两个主要部分为多重空洞卷积(Atrous Spatial Pyramid Pooling,ASPP)[15]和自注意力模块。前者模拟特征金字塔,用于处理不同图像实例之间的分辨率变化;后者用于建模局部特征的重要性。ASPP 包含3 个空洞率分别为6、12、18 的空洞卷积层,不同空洞率可以获得不同的感受野,因此本文模型可以在同一时间获得具有不同感受野的特征图,完成多尺度信息捕获。对3 个不同空洞卷积提取的特征和全局平均池化分支进行级联操作得到一个特征矩阵,再经过一个1×1 卷积层降维后作为ASPP 输出。ASPP 输出的特征映射被提交到自我注意模块,用于进一步建模每个局部特征点的重要性。首先使用1×1的卷积—批处理层对ASPP 输入进行处理;然后分成两个分支,一支对特征进行L2 正则化,另一支经过Relu 激活函数和1×1 卷积层后进行SoftPlus 操作,对每个特征点计算注意力分数,将该注意力分数与L2 正则化后的特征相乘计算出来的最终结果作为该图像的局部特征fl。
全局分支对第4 层卷积层后得到的特征进行Gem 池化[16]后得到最后输入到正交融合部分的全局输出fg。对于f∈RC×W×H(C 为通道数)的张量而言,Gem 池化可表示为:
式中:pC为可学习参数,当pC=1 时Gem 池化等同于均值池化;当pC>1 时,Gem 池化关注显著特征点;当pC→∞时,Gem 池化等同于全局池化。根据DELG[14]中的设置,本文将其初始值设置为3.0。
2.1.2 特征融合
特征融合过程图2 所示。具体步骤为以局部特征fl和全局特征fg作为输入,计算出fl在fg上的正交分量,并将该正交分量与全局特征聚合成一个联合表示。
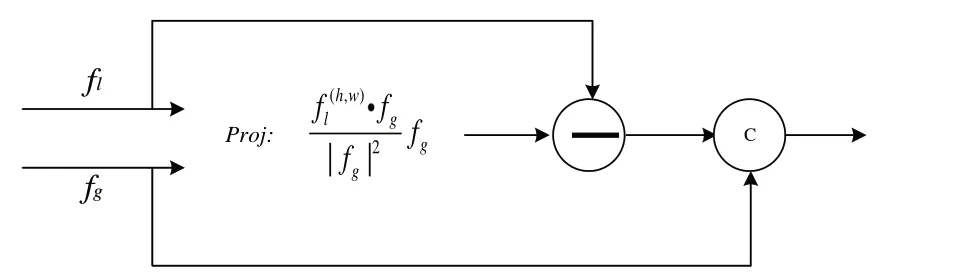
Fig.2 Feature fusion process图2 特征融合过程
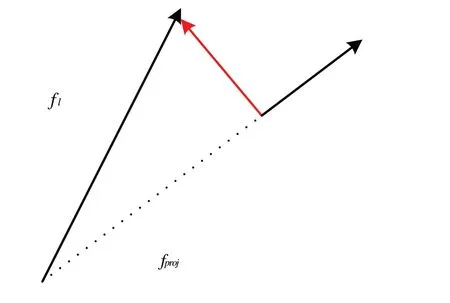
Fig.3 Orthographic projection process图3 正交投影过程
2.2 损失函数
在训练阶段使用一个由4 个部分组成的损失函数:①在原始嵌入上计算的三元组损失;②中心损失作为辅助损失;③在批量归一化嵌入上使用全连接层计算的分类损失;④使用查询向量和批类质心计算的质心损失。因此,总目标优化函数表示为:
式中:δ1为可学习参数,表示损失函数所占权重,初始设置为5e-4。
以上聚合表示对异常值更稳健,能确保更稳定的特征。在检索阶段使用质心表示,每个图像不需要像三元组损失一样计算输入图像与批类每一个图像的距离,大大减少了检索时间和存储需求。
2.2.1 中心损失
在目前基于深度学习的实例检索方案中,三元损失是应用最广泛的方法之一。计算公式为:
式中:A为输出图像,P为正例图像,N为负例图像,Ac为三元组损失的边际。三元组损失只考虑了A与P、N之间的差值,忽略了它们的绝对值。例如,当f(A)-f(P)=0.4,f(A)-f (N)=0.6,ac=0.4 时,三元组损失为0.2;而f(A)-f(P)=1.6,f(A)-f (N)=1.4时,三元组损失也为0.2,但此时输入图像与正类的距离大于负类距离。三元损失由两个在正负类中分别随机抽取的图像计算,即使三元损失很小,也很难确保整个训练数据集中正类的距离大于负类距离。为弥补三元组缺失的缺点,在训练中引入中心损失[18],同时学习每个类别深度特征的一个中心,并根据深度特征与其相应类别中心之间的距离进行惩罚。中心损失函数表示为:
式中:yj为输入的第j 个图像标签;cyj表示深度特征的yj类中心;B为输入图像的批大小。
2.2.2 质心损失
除了聚类效果不佳,三元损失还具有以下缺点[19-21]:①三元损失主要通过硬负采样创建训练批图像,但可能会导致糟糕的局部极小值;②硬负采样计算成本高,需要计算批内所有样本之间的距离;③容易出现异常值和噪声标签。为减小三元损失硬负采样带来的影响,在训练和检索阶段引入质心损失,见图4。图中的距离指测量样本与代表一个类的质心之间的距离;质心为批中每一类所有图像表示的聚合。质心方法可使每个图像只用计算一次嵌入,解决了计算成本和存储问题。
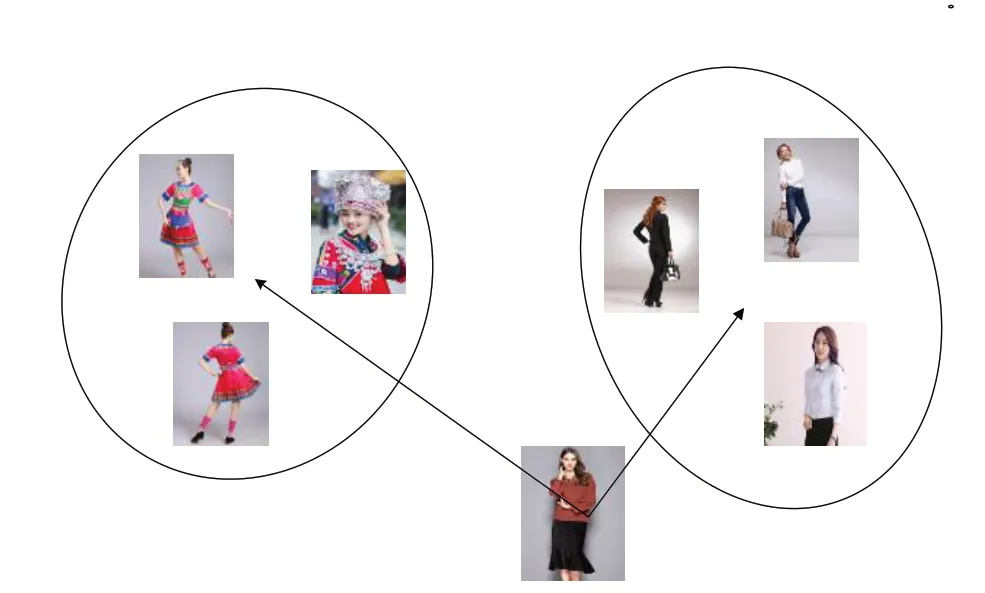
Fig.4 Centroid loss图4 质心损失
三元组损失是比较图像与正负图像之间的距离,而质心损失是测量图像A 与两个类别中心Cp和Cn之间的距离。质心损失计算公式为:
式中:Cp为与输入图像同一类的质心,Cn为与输入图像不同类的质心。
3 实验方法与结果分析
3.1 数据集
本文在包含80 万张图像的DeepFashion 数据集[21]上进行实验,其由4 个子集组成。选择其中的Consumer-toshop 服装检索子集,包含33 881 种商品,共 239 557 张图片。
3.2 评价指标
跨域服装检索方法通常采用均值平均精度(Mean Average Precision,MAP)作为检索结果位置信息的评价标准。计算公式为:
式中:Q为检索数据库中的服装图像数量;AP为平均查询正确率,是一次查询结果查准率与查全率曲线下的面积。
Top-k 准确率为跨域服装检索中最常用的评价指标。计算公式为:
式中:q为待查询图像,Q为查询库中所有图像的数量。如果根据相似度距离检索出的前k 个图像中至少有一个与q匹配,那么h(q,k)=1,否则h(q,k)=0。
3.3 实验设置
使用PyTorch Lighting 框架实现代码,在Google Colab中使用Ubuntu18 系统、26g 内存和P100 显卡进行实验。使用47 434 张查询图像验证本文方法的检索效果。使用 ResNet50-IBN-A 作为预训练网络,Stride=1,ResNet 最后一层输出维度为2 048,批大小为12,中心损失加权系数为5e-4,所有其他损失权重为1。使用基础学习率为1e-4的Adam 优化器,同时使用学习率调度器,在第40、70 个epoch后学习率降低10倍,模型训练120个epoch。
使用 ResNet50-IBN-A 作为预训练网络,Stride=1,ResNet 最后一层输出维度为2 048,批大小为12,中心损失加权系数为5e-4,所有其他损失权重为1。使用基础学习率为1e-4的Adam 优化器,同时使用学习率调度器,在第40、70个epoch 后学习率降低10倍,模型训练120个epoch。
3.4 实验结果
在检索阶段,使用批归一化向量后的图像嵌入计算相似度距离,距离度量为余弦相似度。比较本文方法与GRNRT[9]、CTL-S-50[10]、VGG16-atten[11]、GSN[22]模型的top-k 检索准确率,结果见图5。可以看出,本文方法比对照方法表现出色。这是由于将全局特征与局部特征融合起来能有效弥补特征表达的不足,提高检索准确性,且本文方法仅使用图像级标签进行训练,无需复杂注释。
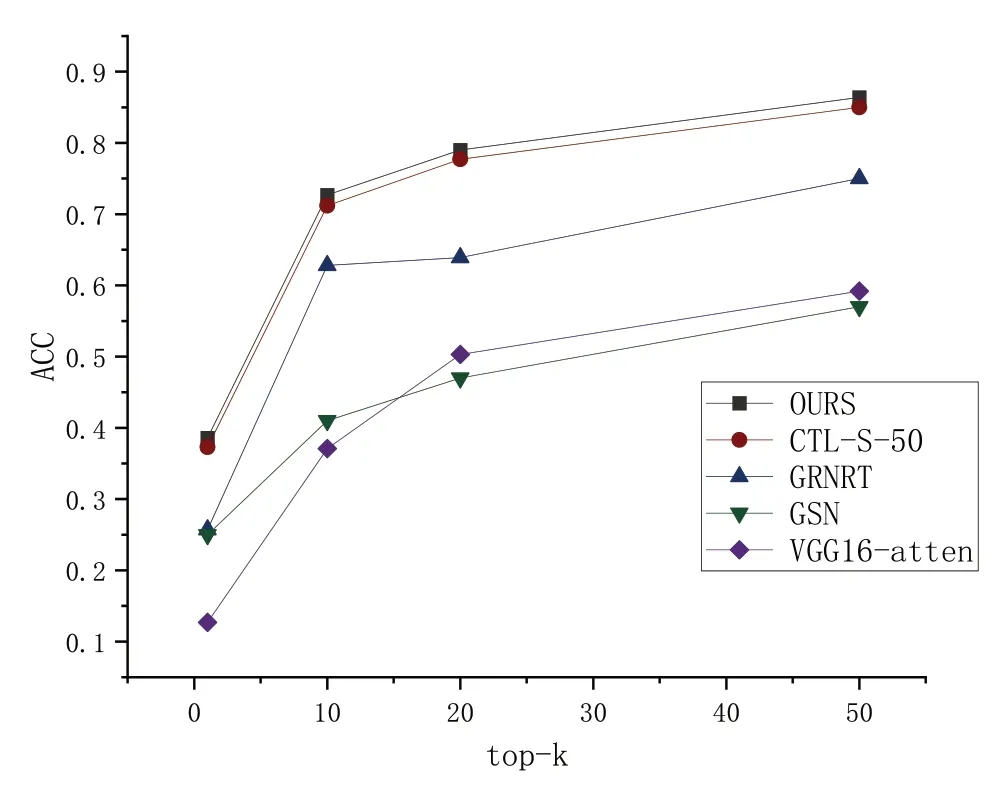
Fig.5 Comparison of top-k retrieval accuracy of different models图5 不同模型top-k检索准确率比较
表1 为本文方法和实例检索方法在DeepFashion 测试集上所需时间和空间比较。前文中的VGG16-atten、GRNRT 均属于实例检索的范畴。可以看出,在检索阶段使用质心方法大大减少了所需图片数量,检索速度有较大提升。这是由于每个类通常有若干个图像,而一个质心可以表示每一类的一整组图像。

Table 1 Comparison of time and space required by the proposed method and the example retrieval method表1 本文方法和实例检索方法所需时间和空间比较
图6 为DeepFashion 数据集上的部分检索结果,由在320×320 图像上训练的最佳模型产生。左边第一列图像为查询图像,其右侧图像为相似度递减的top-5 检索结果,带边框的检索图像为与查询图像匹配正确的结果。检索是在整个图库数据集上执行的,没有对查询项类别进行修剪。

Fig.6 top-5 search results图6 top-5检索结果
4 结语
本文提出一种基于特征融合的跨域服装检索方法,其在传统CNN 的基础上嵌入全局和局部特征正交融合模块,在端到端的框架中将多重空洞卷积和自注意力机制得到的重要局部特征与全局特征融合,以获得互相增强且更具判别力的图像表征,弥补对于局部特征利用不足的缺陷。同时,在训练和检索阶段均使用质心损失,大大减少了检索过程的计算量,加快了检索速度。实验表明,与其他常用跨域服装检索方法相比,本文方法在准确性指标上有一定提升。虽然使用质心损失、中心损失、三元损失和交叉熵分类损失联合的损失函数进行训练能取得较好效果,但这些损失函数的目标并不一致,有些甚至差距较大,如三元损失和分类损失。过于复杂的损失函数可能是准确率继续提高的瓶颈之一,后续可考虑对损失函数进行改造,使用具有协同效应的损失函数联合训练。
