基于保洁机器人垃圾分类任务的数据重标记算法
2023-09-15王中磐李清都万里红
王中磐,袁 野,李清都,万里红,刘 娜
(1.上海理工大学 健康科学与工程学院,上海 200093;2.上海交通大学 电子信息与电气工程学院,上海 200030;3.中原动力智能机器人有限公司,河南 郑州 450018)
0 引言
随着我国经济快速发展,城市化进程加快,人口不断增加,城市生活垃圾日益增多,垃圾分类已成为社会热点话题[1-2]。目前,国内垃圾处理厂基本采用人工流水线分拣的方式进行垃圾分拣,工作环境恶劣、劳动强度大、分拣效率低。随着深度学习技术在视觉领域的应用与发展,使用机器人和AI 深度学习进行智能化垃圾分类任务成为可能,既极大提升了垃圾分拣效率,又节约了人力资源。
卷积神经网络(Convolutional Neural Network,CNN)具有卷积计算的人工神经网络结构,是计算机视觉领域常用的深度学习模型。1998 年,Lecun[3]最早提出卷积神经网络,尽管结构较为简单,但定义了卷积层、池化层、全连接层这些基本结构。
随着计算机算力提升,更多模型架构被提出并应用到视觉领域中。Krizhevsky 等[4]提出AlexNet 网络模型,包含ReLU 激活函数、Dropout 方法,使用GPU 加速模型训练的方法已在深度学习领域广泛应用。Simonyan 等[5]提出VGGNet 挖掘网络深度对模型造成的影响,证明使用小卷积核、增加网络深度可有效提升模型效果,但网络过深会引发模型退化问题。He 等[6]引入残差模块提出ResNet 能较好地解决网络过深的问题,后续提出的卷积神经网络大部分基于ResNet进行改进。
在视觉任务中,卷积神经网络技术的显著成就很大程度上归功于大规模已标注的均衡数据集。然而,相较于常用的公共数据集(ImageNet[7]),真实数据集通常以不平衡数据分布为主[8],即少数类别包含多数样本(头部类),大多数类别只有少数样本(尾部类[9-10])。由于垃圾数据集具有以上特点,因此在这些分类失衡数据集上训练的模型容易发生过拟合现象,导致模型在少数类别上的泛化性能较差[11-12]。
1 相关研究
现有类别不平衡解决策略可分为重采样(Re-sampling)[13-14]和重加权(Re-weighting)[15-16]。其中,重采样通过对头部类进行欠采样或过采样尾部类来调整训练数据分布类别,缓解数据不平衡问题。例如,GAN-over-sampling[17]通过对抗生成网络(Generative Adversarial Networks,GAN)生成尾部类的样本,从而使数据集重新达到平衡状态;重加权则为每个类别分配不同权重,使模型能更专注于拟合尾部类的样本[18],相关方法包括Focal Loss[19]、CB Loss(Class-balanced loss)[20]等。Focal Loss 通过研究类别的预测难易度,并提升预测难度高的样本权重,认为不平衡数据集中尾部类预测难度更高,该类的预测概率远低于头部类[19];CB Loss 引入一个有效样本数的概念来近似不同类样本的期望值,并使用一个与有效样本数成反比的权重因子来改进损失函数[20]。
虽然重采样与重加权策略可改善推理尾部类别的性能,但在一定程度上会损失头部类的性能,并且简单地过采样尾部类样本可能会导致模型过度拟合[21],在训练过程中直接提升尾部类的权重也将使模型降低对头部类的关注度。因此,在提升尾部类别泛化能力的同时,还需要保持头部类的分类性能,即在垃圾分类任务中在保持常见垃圾类别识别精确度的基础上,提升尾部罕见垃圾类别识别精确度。
为此,本文提出一种从标签层面分析数据集的重标记算法框架,从源头上缓解类别不平衡对模型训练造成的影响,在一定程度上保证头部类的识别精度不受损失。首先提出一种针对数据样本的重标记算法解决类别不平衡、降低模型泛化性能的问题。该算法将头部类划分为多个子类并分配相应的标签,以缓解标签层面的不平衡问题;然后针对多种不同垃圾类别,制作具有长尾分布的垃圾数据集。实验表明,所提算法能在著提升长尾数据集中尾部类性能的前提下,基本不损失头部类性能。
2 垃圾分类任务方案设计
本文所提重标记算法旨在缓解类别不平衡的垃圾数据集对模型分类性能造成的影响,最终将部署到保洁机器人等边缘计算设备上,以更好地完成垃圾分类任务。因此,垃圾检测分类工作是基础,需要设计垃圾分类流程,完成长尾版本垃圾数据集的建立与分析,具体流程设计如图1所示。
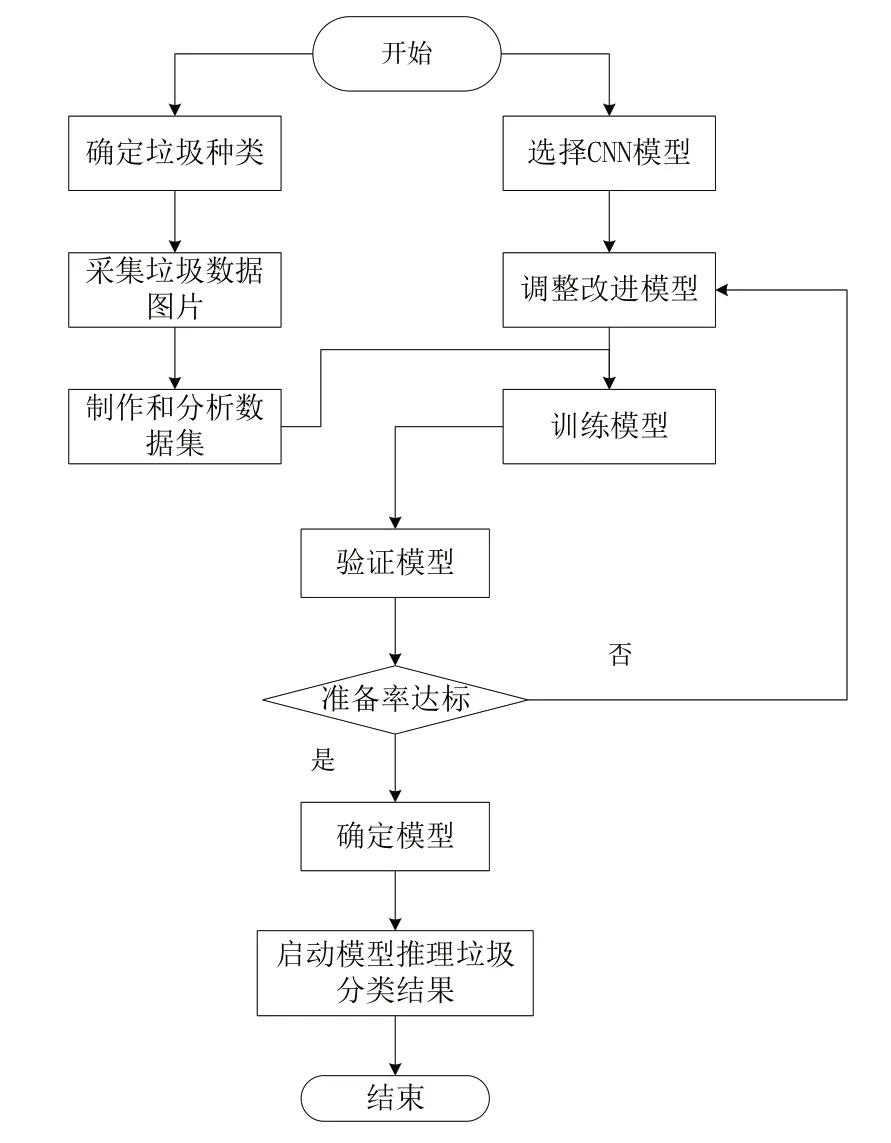
Fig.1 Waste sorting process图1 垃圾分类流程
由图1 所示,该流程主要包括数据集采集与分析、模型调整与训练两个部分。首先,确定数据集的垃圾种类,采集相应数据并对数据集进行筛选和预处理,制作出具有长尾分布的数据集版本。然后,确定分类CNN 模型,根据任务要求对模型进行调整与改进。最后,在确定数据集和模型后开始训练模型和验证测试工作,若模型精度达到项目要求则开始垃圾识别任务,反之将进一步调整模型参数,直至模型达到目标精度。
本文实验所用的垃圾图像数据大部分来源于自身相机拍摄的图片,一部分来源于比赛开源数据,共整理、制作了20 436 张,10 个类别的长尾版本数据集,数据集制作、分析流程如图2所示。
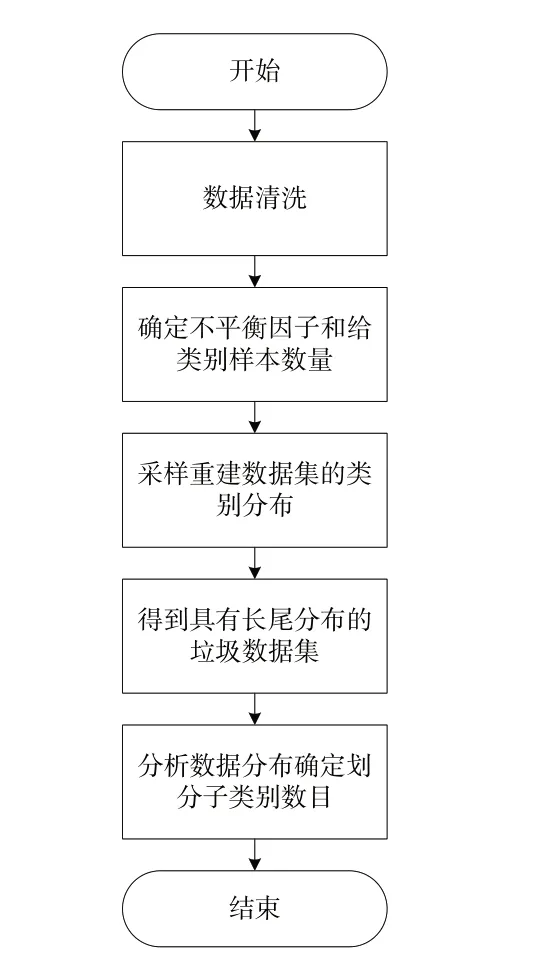
Fig.2 Dataset production and analysis process图2 数据集制作和分析流程
由图2 可见,该流程首先将采集的垃圾数据集进行数据清洗,筛选出质量较高的图片构成原始数据集;然后确定待构建的长尾数据集的不平衡因子,并进行采样重建,将原始垃圾数据集制作为具有长尾分布的数据集版本;最后综合考虑数据分布与聚类方法的分析结果,确定每个类别待划分的子类数。
本文实验中垃圾数据集的类别数不多且具有严重的类别不平衡分布情况,目前常用的网络为ResNet[6]、EfficientNet[22],由于ResNet 网络的分类精度与较为先进的EfficientNet 模型相当,但参数量更少,运行时占用内存较少,更适合部署保洁机器人的边缘计算设备,能提升算法实施和落地的可行性。因此本文分类模型选用ResNet 网络进行后续实验。
3 数据重标记算法设计
3.1 总体框架
图3 为本文所提重标记算法的总体框架,主要包含特征提取模块、特征聚类模块和标签映射模块。其中,特征提取模块由ResNet32 的主干部分构成,利用卷积神经网络提取输入图像特征;特征聚类模块根据提取特征的类内距离将其划分为几个子类,并为每个子类样本生成唯一的伪标签,完成数据重标记;标签映射模块将伪标签空间映射到真实标签空间。
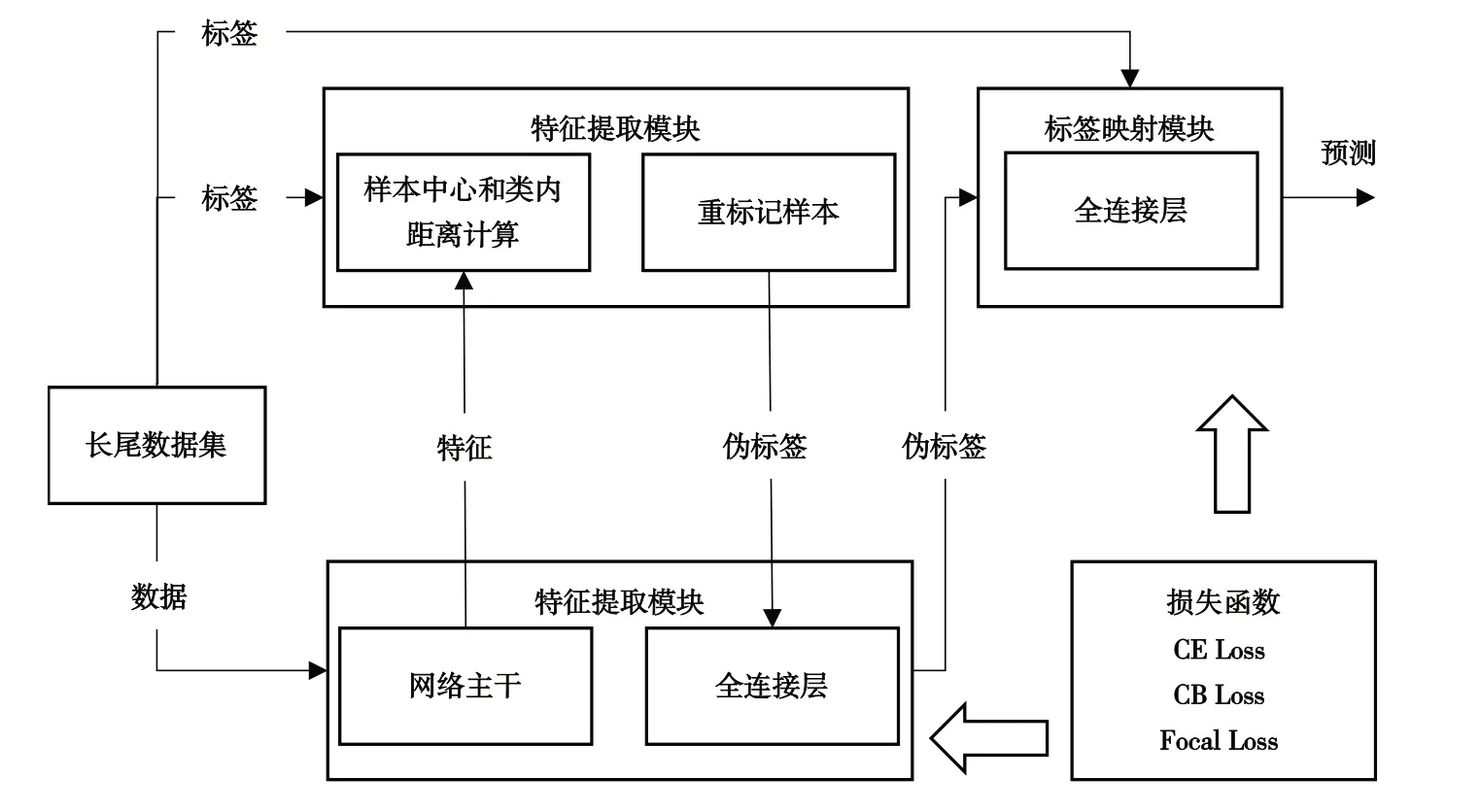
Fig.3 Overall framework of data relabeling algorithm图3 数据重标记算法整体框架
3.2 特征聚类模块
特征聚类模块将样本特征划分为指定数量的子类,并重新标记对应的伪标签。具体的,首先在训练过程中的卷积神经网络主干部分提取训练样本特征;然后通过动态特征聚类方法,根据对应类别样本中心的距离大小,将属于同一类的特征划分为若干个小的子类别;最后为每个子类赋予一个伪标签并计算损失。动态特征聚类方法计算公式如式(1)、式(2)所示。
式中:SCt为训练时第t个batch 中某个类别的样本中心;Si为该类别第i个样本;SN表示该类别划分的子类别数,即样本和样本中心的最大距离被均匀划分为SN个区间;dt为每个区间的长度。
在训练期间,将样本分批输入框架中,对每批每一类数据样本重复进行下述操作:①根据所有样本特征计算每个类别的样本中心;②计算样本到样本中心的最大距离,然后将该距离分为多个区间;③根据每个样本到样本中心的距离排序关系确定样本的所属区间,并为其分配一个唯一的伪标签。此外,划分的子类数目为一个超参数,其值与数据集分布情况相关。
3.2.1 样本中心
Mini-batch 的训练策略虽然非常适合视觉任务,但会导致样本中心计算成本过高。为了高效计算样本中心,本文采用指数移动平均法(Exponential Moving Average)使每批中各类别的样本中心更接近数据集中与之相对应类别的整体情况,样本中心计算公式如式(3)所示。
式中:α(0<α<1)表示权重衰减程度;yt表示第t批中某个类别特征的平均值;SCt表示样本中心,即第t批中某一类别特征的指数移动平均值。
3.2.2 子类数目
子类数目由数据集的不平衡程度和类内距离决定。一方面,本文所提方法旨在将严重不平衡的数据集中大多数类别划分为更多子类;另一方面,本文通过实验分析子类数对模型造成的影响,得出子类数越大,样本类内距离越小,当子类数过大时将降低模型分类精度。
因此,本文将对数据集中每个类别进行聚类分析,结合数据集的分布情况综合考虑子类数目,保证子类数量尽可能大一些,但不能使得类内距离过小。特征聚类模块中的动态特征聚类方法作为重标记算法的核心部分,具体计算流程如下:
算法1重标记算法
3.3 特征映射模块
为了将伪标签空间映射到真实标签空间,本文在特征提取模块后设置一个标签映射模块,该模块也是一个多层全连接网络。在训练过程中,由于特征聚类模块对每个类别的样本进行聚类,并将其分成几个子类,因此伪标签的总数会大于真实标签数量。为了完成初始分类任务,将相同类别样本的所有伪标签映射到真实标签,三层全连接层的输入维度设置为伪标签总数,并且输出维度等于真实标签总数。
3.4 两阶段训练策略
由于特征提取模块和标签映射模块是两个相对独立的网络,因此本文采用两阶段训练方式更新整个算法框架的权重参数,如图4 所示。第一阶段,通过特征聚类模块生成的伪标签计算骨干网络损失值,并更新特征提取模块的权重参数。第二阶段,将标签得到的真实标签作为ground-truth,计算标签映射模块网络的损失值,并更新该部分权重参数。第一、第二阶段交替进行,训练过程中损失函数保持一致。
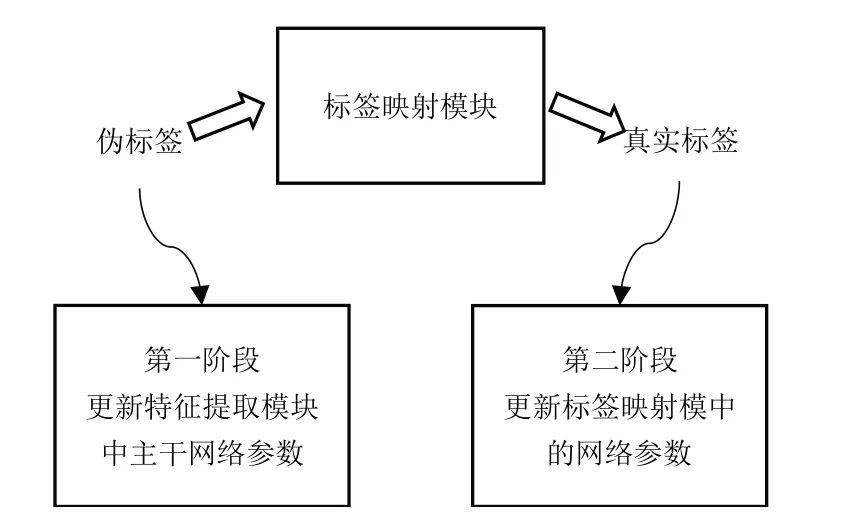
Fig.4 Two-stage training strategy图4 两阶段训练策略
4 实验与结果分析
4.1 数据集
本文数据集的不平衡因子定义为最小类别的训练样本数除以最大类别的值,以反映数据集的不平衡程度。实验中,不平衡因子分别设置为0.01、0.1,由于数据分布的不平衡化只影响数据集中的训练集,因此平衡分布测试集类别。长尾垃圾数据集分别为0—树叶、1—易拉罐、2—果皮、3—包装袋、4—纸、5—塑料瓶、6—瓜子壳、7—布制品、8—烟盒、9—烟头。实验结果如图5、图6所示。
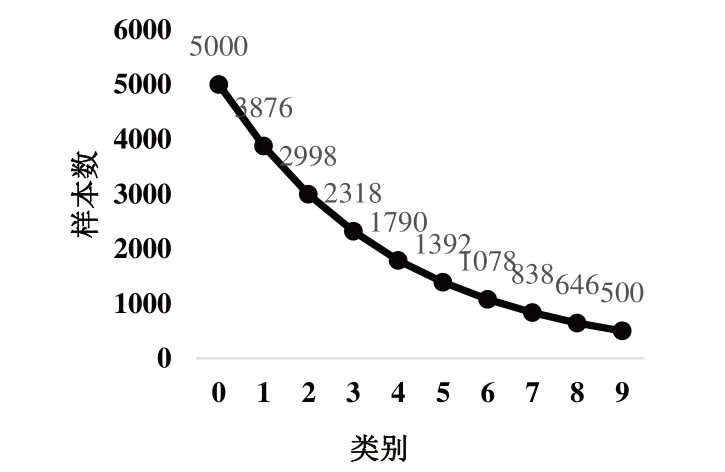
Fig.5 Distribution of garbage datasets with an unbalanced factor of 0.1图5 不平衡因子为0.1时的垃圾数据集分布
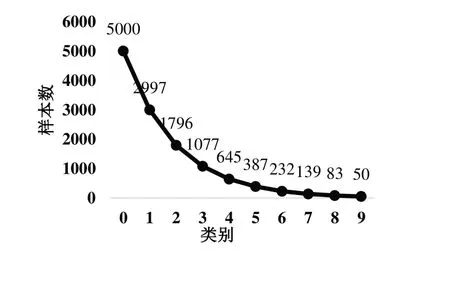
Fig.6 Distribution of garbage datasets with an unbalanced factor of 0.01图6 不平衡因子为0.01时的垃圾数据集分布
4.2 实验设置
本文将所提算法与重采样(Re-sampling)[14]、重加权(Re-weighting)[15]、Focal loss[19]、交叉熵损失(CE Loss)[23]进行比较。其中,重采样根据每个类别的有效样本数的倒数对样本进行重采样;重加权根据每个类别的有效样本数的倒数加权因子对样本进行重新加权;Focal loss 增加了预测难度较高样本的损失,降低了分类效果较好的样本权重;CE Loss不改变样本权重,代表最基础的方法。
本文将CE Loss、Focal Loss 两种损失函数与None、重采样和重新加权3 种方法相结合,作为不同训练基准方法。其中,重加权、重采样、CB Loss[20]的训练方法和参数一致,使用PyTorch 深度学习框架[24]训练所有模型,并且模型均采用ResNet[6]架构。
本文采用ResNet-32 作为骨干网络,对所有长尾垃圾数据集进行实验,模型均采用随机初始化。另外,优化器选用随机梯度下降算法(SGD)[25](动量=0.9)对网络训练200 个epoch,并按照CB Loss[20]的训练策略将初始学习率设置为0.1,然后在160、180 个epoch 分别衰减1%,实验显卡为NVIDIA RTX 3090,batch_size 为128。
4.3 实验结果
本文采用基础方法直接训练长尾数据集(CE Loss+None)、SOTA 方法(Focal Loss+Reweight)与本文所提重标记方法(Relabel)进行比较,综合分析3 种方法在不平衡因子为0.1 时垃圾数据集上每个类别的精度与平均精度,如表1 所示。由此可见,本文所提重标记方法在该数据集上的平均精度最高,达到88.37%,相较于CE Loss+None、Focal Loss+Reweight 分别提升1.72%、1.24%。此外,重标记方法能普遍提升样本数较少的尾部类精度,对于样本数较多的头部类精度损失相对较少。
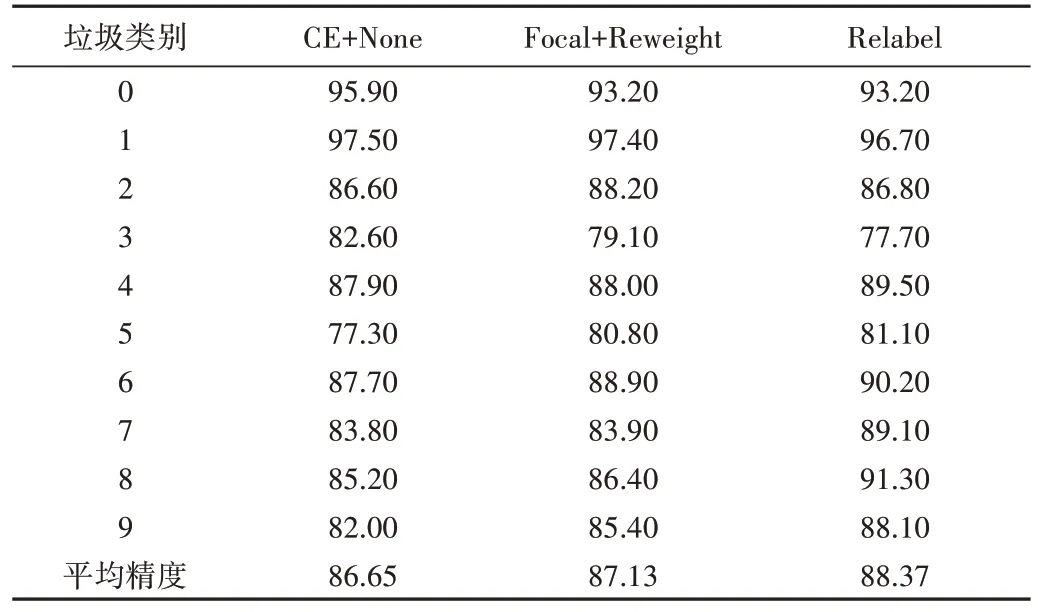
Table 1 Experimental results with an imbalance factor of 0.1表1 不平衡因子为0.1的实验结果(%)
同时,本文将3 种方法在不平衡因子为0.01 的垃圾数据集上测试的精度、平均精度如表2 所示。由此可见,本文所提重标记方法平均精度最高,达到79.78%,相较于CE Loss+None、Focal Loss+Reweight 分别提升9.56%、4.39%。此外,重标记方法能普遍提升样本数较少的尾部精度,对样本数较多的头部类精度损失相对较少。
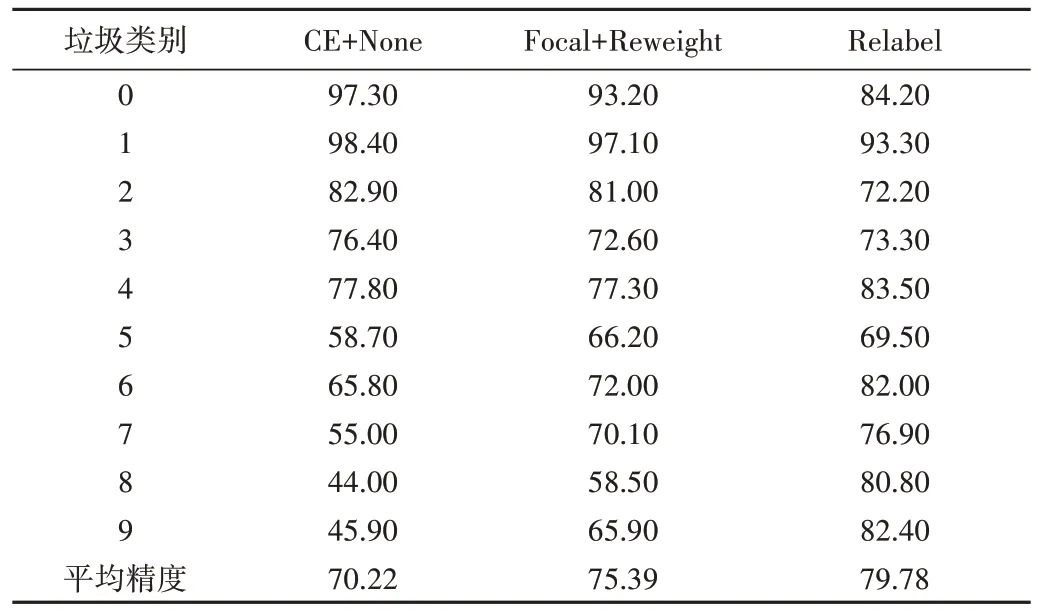
Table 2 Experimental results with an imbalance factor of 0.01表2 不平衡因子为0.01的实验结果(%)
综上所述,采用本文所提重标记算法能提升长尾数据集的分类精度,相较于现有SOTA 方法效果更优,并且对于高度不平衡的长尾垃圾数据集,平均精度提升更显著。
如图7 所示,实时测试时将重标记算法加入检测模型后(图7 下半部分),相较于较改进前方法,在保持其他类别识别效果的同时,对数目较少的烟头类别识别效果更优。
4.4 消融实验
为了研究所提重标记算法相较于baseline 中已有的多类别不平衡学习策略的提升效果,对无重标记算法、重标记算法与现有不同学习策略相结合的多种情况进行比较实验。在不平衡因子分别为0.1、0.01 的垃圾数据集的各方面实验结果如表3、表4所示。
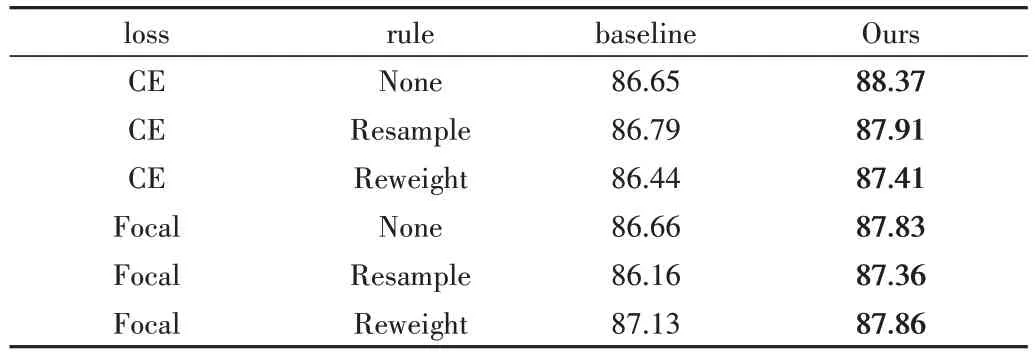
Table 3 Experimental results of different strategy combinations when the imbalance factor is 0.1表3 不平衡因子为0.1时不同策略组合实验结果(%)
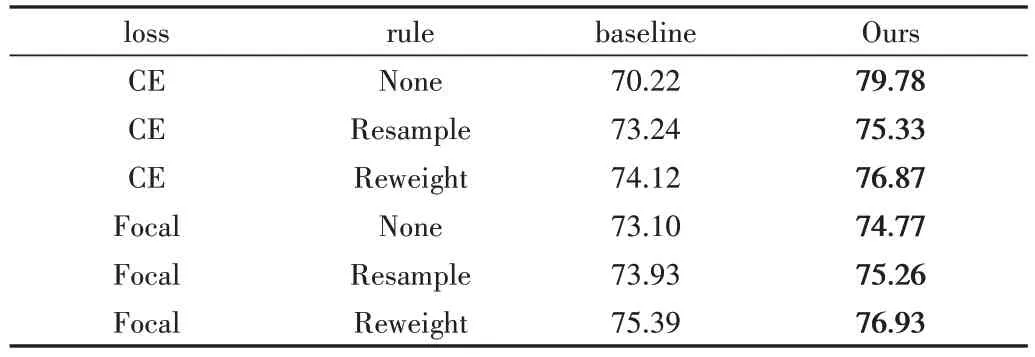
Table 4 Experimental results of different strategy combinations when the imbalance factor is 0.01表4 不平衡因子为0.01时不同策略组合实验结果(%)
由表3、表4 可知,在不平衡因子为0.1、0.01 的垃圾数据集中,重标记方法能结合baseline 中现有训练方法进一步提升模型识别效果,相较于CE Loss+None 组合方式平均精度分别提升1.72%、9.56%,达到了88.37%、79.78%。实验表明,本文所提算法能应用于现有多个不同类别的不平衡训练策略,可进一步提升模型在长尾垃圾数据集上的分类精度,当直接采用重标记算法且不采用其他训练策略时,垃圾分类精度最高。
此外,本文对算法中采用不同子类数划分的方式进行比较,以平衡因子为0.1 时为例,选取两种不同子类划分方式,分别对应两组子类数目的参数:①根据数据分布划分,即按照每个类别的样本数量占数据集的比例划分,参数选取为[10,8,6,5,3,2,2,1,1,1];②聚类分析划分,即提前对数据集的每个类别进行聚类操作,确定可划分出的子类,参数选取为[5,3,2,2,1,1,1,1,1,1],实验结果如表5所示。由此可见,重标记算法在不结合其他baseline 方法时,采用数据分布划分方式效果更好,分类精度最高;在结合其他baseline 方法后,采用聚类分析的划分方式效果更好。
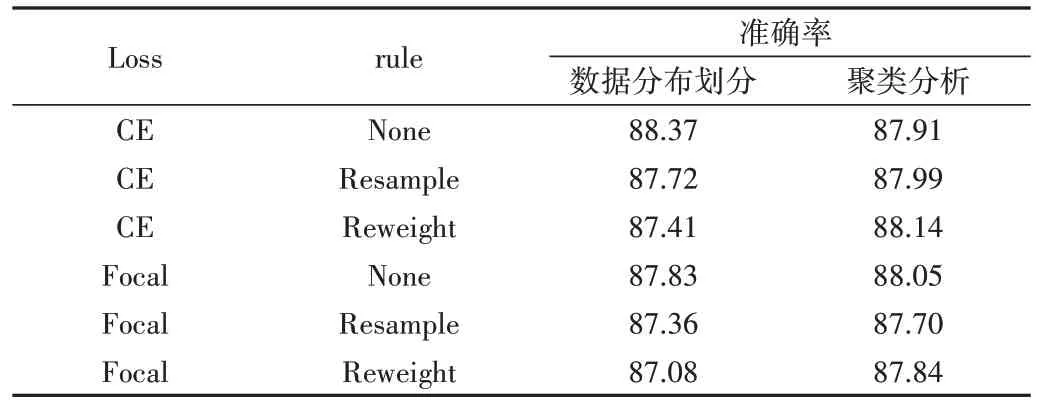
Table 5 Experimental results of different subclass classification methods when the imbalance factor is 0.1表5 不平衡因子为0.1时不同子类划分方式实验结果(%)
5 结语
本文为解决人工分拣垃圾环境差、效率低及垃圾数据集类别不均衡分布对保洁机器人等计算设备,在垃圾分类识别时对识别效果产生的负面影响,提出一种针对数据样本的重标记算法与卷积神经网络分类模型相结合的策略完成垃圾数据分类任务,并能部署在保洁机器人等边缘计算设备端。
该算法为每个类别生成多个子类和相对应的伪标签,缓解了标签层面的数据不平衡问题,在预测时通过标签映射将伪标签转换为真实标签。实验表明,本文算法能显著提升常用卷积神经网络模型对垃圾分类的泛化性和精确度,可进一步提升边缘计算设备垃圾分类任务的效率,实现了自动化、智能化垃圾分类,有助于建设生态文明社会。
