突发公共卫生事件中的应急政策知识图谱
2023-09-15管雨涵
管雨涵,刘 勘
(1.华中科技大学 管理学院,湖北 武汉 430074;2.中南财经政法大学 信息与安全工程学院,湖北 武汉 430073)
0 引言
突发公共卫生事件多指有扩散趋势、严重危害公众安全的突发性重大传染疾病等,这类事件影响力大、危害程度高、涉及范围广,将严重危害经济发展、人民健康及社会安定[1]。面对突发公共卫生事件,需要依据国家政策快速制定和部署综合性的应急管理方案,及时响应和解决可能出现的各类突发问题。
2020 年初期,新冠疫情暴发,国务院及各地政府不断发布各项应对政策和通告,指导各级部门采取相应措施;后疫情时期,在大多数国家选择与“病毒共存”的趋势下,中国仍坚持“动态清零”,总体应急管理取得显著成效。不可忽视的是,疫情初期由于信息输入渠道单一、跨域部门协调薄弱等原因,导致“信息疫情”暴发,政策发布落后于谣言传播,群众陷入恐慌状态,各种“信息孤岛”也导致后续应对策略发布迟缓,疫情管控和应急处理处于弱势地位。此外,由于政府应急管理实行分级条块管理模式,应急中心分散,地方决策参与和风险分担机制不足,部门间尤其是横向部门间协调能力低,合作机制运行不畅,导致部分处理政策出现程序不明确、多头同质化处理、权责混乱的情况,极大降低了政府应急管理效率[2]。
基于此,本文以新冠疫情治理为例,构建突发公共卫生事件应急政策知识图谱。知识图谱及其实体、关系的多层次性能较好地匹配应急政策中的多主体、多主题、多对象,因此,考虑将知识图谱运用于政府应急政策。应急政策知识图谱能通过多元的输入信息、综合的共享信息,帮助政策快速传播流转,构建跨部门的应急联防联控机制网络;同时,通过在图谱中对防控政策进行归纳、分类,形成应急政策知识深度关联,更好地聚焦应急政策核心,辅助中央地方联合响应、共同决策,改进应急政策部署和执行效率。本文主要贡献在于:①构建应急管理知识图谱的Schema 模式框架;②利用深度学习和文本处理技术,形成SPO(Subject To Object)政策三元组知识结构,进而通过推理发现政策信息传递流向,构建突发公共卫生事件管理政策知识图谱;③对应急政策通过知识图谱结构化、规范化,建立基本应急政策知识库,实现专业应急部门的快速查询、更新及可视化分析,并为突发公共卫生事件的应急管理提供方案生成、自动推荐等决策支持。
1 相关工作
知识图谱可以被看作是一种特殊的语义网络,形成一种以信息为节点、关系为边的有向图,它能将数据凝练整合形成智能型知识库,清楚呈现每一条知识的全息结构,同时利用推理机制发现数据关系及其逻辑关联。知识图谱的研究主要从理论与应用两个方面展开。理论研究主要探讨知识抽取、知识融合、知识推理等构建方法中的关键步骤[3]。在知识图谱构建上,Hogan 等[4]详细介绍了知识图谱的完整构建过程与构建方法。随着机器学习领域的发展,越来越多的技术被运用在了知识图谱构建中,刘峤等[5]介绍了一些最新的知识抽取、融合、加工技术。在知识抽取方面,目前多采用依存句法分析[6]、深度强化模型[7]等方法进行实体与关系识别;将知识通过Trans 模型[8]进行表示,再通过基于逻辑规则、深度学习和强化模型[9]的方式进行实体关系的发现与推理;对于构建完成的知识图谱,则多采用Neo4j 或Gephi 数据库进行可视化[5],或直接使用CiteSpace 软件构建整体关系知识图谱。
应用研究则可以分为通用知识图谱和领域知识图谱应用。其中,通用知识图谱的构建已经较为成熟,目前典型的通用知识图谱包括国外的YAGO、DBpedia、Freebase和国内的zhishi.me、CNDBpedia 和OpenKG 等项目,包括谷歌、百度、搜狗在内等企业都构建了基于知识图谱的搜索引擎,如谷歌搜索引擎、搜狗知立方等[10]。这些知识图谱,将无规则语言转化为高度结构化可用知识并用于深度搜索和知识问答,有效地提高了网络检索的效率与质量。
近年来,领域知识图谱应用越来越多,针对2020 年初暴发的新冠肺炎疫情,研究人员构建了病毒传播知识图谱[11]、医疗用药知识图谱[12]。国内OpenKG 平台[14]则建立了新冠知识图谱专题,包含病毒科研知识、临床方案、防控常识等[14]。这些知识图谱在疫情传播控制[15]、疫情舆论引导[16]、风险防范管理[17]等方面发挥了重要作用。
关于应急管理图谱,李纲等[18]关注重大国家安全事件构建图谱,全面监控掌知全局安全动态。张海涛等[19-20]以新冠疫情和大旱事件为例构建事件图谱,探究国家安全事件图谱的态势状态提取方法。正是由于图谱的强关联性,能较好地着重于事件发生状况和发展状态,与政策文本处于发展传递状态相匹配,故而考虑构建政策知识图谱。
此外,由于政策的格式规整性,知识图谱对于政策文件有较好应用。Wang 等[21]基于规则和机器学习抽取实体关系,构建政策图谱分析平台。韩娜等[22]聚焦于“开放数据”和“数据安全”主题,利用规则关联和定量分析对政策文本进行协同性语义推理。张雨等[23]构建科技垂直领域知识图谱,更好发挥科技政策引领科技发展。单晓红等[24]构建政策影响事理图谱,找出关键节点有效进行政策管控。霍朝光等[25]利用TF-IDF 和强化字典构建新冠肺炎政策知识图谱,归档重大突发公共卫生事件处理方案,追溯政策法律渊源。
目前政策图谱多聚焦于政策计量,集中于关联分析和归档处理,多采用人工或简单规则方式[26],灵活性与完整性较差;而知识图谱构建方面少有聚焦于重大突发公共卫生突发事件,且未有完整的可以重复利用的应急管理框架以供未来参考和回溯。
在应急管理方面,尽管目前新冠疫情在国内得到了良好的控制,但是不可忽视疫情初期的无序状态。丁荣嵘等[27]提出当前政府应急管理效率低下,需要建立一个统一的应急管理体系标准,健全协同管理体系,对政策信息智能分类、简化归口、直达直报。杨雯等[28]认为疫情期间政策发布制度不完善,逐级政策发布导致跨域部门沟通不充分,建议应建立应急治理中心指挥枢纽,加强行政系统内部合作,共享信息协调多部门联合调动。王媛[29]强调对于突发公共卫生事件,政府应急管理缺乏内部主动性,过度依赖上级决策,同时应急预案制定沟通不充分,跨区域协调困难,提出中央和地方、多地方、多机构、多部门合作平台的亟需性。
基于此,本文聚焦于上述问题,利用知识图谱在构造和应用上的独有特征,构建突发公共卫生事件中应急政策知识图谱。
2 知识图谱构建
2.1 Schema构建
在逻辑上,知识图谱分成两个层系:Schema 本体模式层和Data 数据层。其中,Schema 层是知识图谱构建的核心与重点,它定义了各类实体间以及实体属性间的关系,通常使用本体库进行管理。本体库相当于知识库的模型,良好的Schema 层次为知识图谱的构建搭建了框架,这样形成的知识冗余少、泛化能力强,推理出的关系也更全面。而Data 数据层由基本的事件、事实构成[30],是知识的基本存储单位,一般情况下,使用SPO 三元组形式来表达知识。
华斌等[31]结合政策精准性四大要素,将政策分为主体、客体、目标、工具四大类。本文针对疫情应急管理知识图谱设计的Schema 本体则需要考虑两个因素:①每则政策公文的结构层次体系;②执行部门对政策的落实要求。
政策数据实体关系如图1 所示,包括部门、标题、内容、附件等。本文设计6 种实体类型和9 种属性类型,各类实体的定义与实体间的映射关系如表1、表2所示。

Table 1 Knowledge graph entity types and examples表1 知识图谱实体类型及样例

Table 2 Knowledge graph attribute types and examples表2 知识图谱属性类型及样例
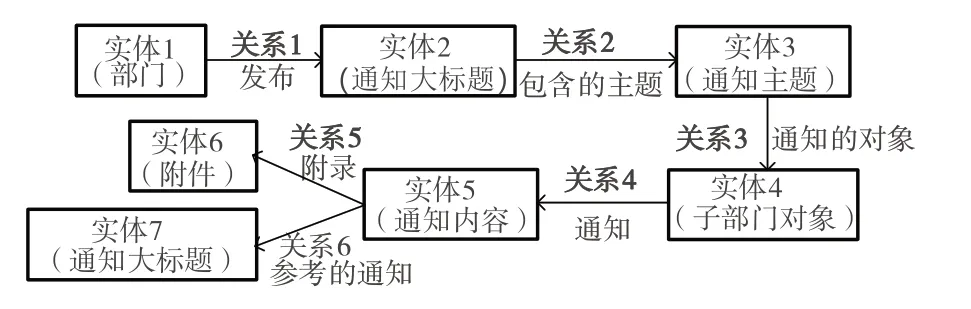
Fig.1 Policy data entity relationships图1 政策数据实体关系
政策文件的实体间关系较为简单,华斌等[31]将政策实体间关系主要分为六类,张雨等[23]则分为四大类。根据构建的以上实体及属性,本文主要设计了6 种关系类型,将实体之间连接起来,其关系映射如表3 所示。这样,通过对实体、关系、属性的定义,将来源于国务院和各省政府政策文件库的半结构化数据和部分非结构化数据转换为知识图谱所需的结构化格式,通过实体间关系与属性,可以实现政策知识的统一表示,使分散的管理政策相互联系。
2.2 知识抽取
知识抽取过程中可以将实体与关系分别抽取,也可以采用联合抽取模型,联合抽取能同时考虑实体与关系之间的联系,故而犯错较少。但由于本文实验中使用大量半结构化数据,可以通过简单的规则提取出部分实体与关系,因而采用实体与关系分开抽取的流水线模型。
2.2.1 实体抽取
本文采取基于BiLSTM+CNN-CRF 的实体抽取[32]算法,先用NLPIR 汉语工具[33]识别出主要实体,再用少量人工标注语料训练BiLSTM+CNN-CRF 模型实现命名实体抽取,这样能在极大减少人工标注的基础上得到有效的实体识别效果。
BiLSTM+CNN-CRF 模型由CNN、BiLSTM 和CRF 3 个模块组成。首先将输入文本通过Word2vec 分布式嵌入方式将每个词处理为n维词向量;然后将处理好的词向量分别输入CNN 模块,提取出文本的字符级特征,再输入BiLSTM 模块,提取出全局特征,将得到的字符向量和词向量进行拼接,输入全连接层和CRF 模块进行解码,利用已有标签,选取一个最优的标记序列。只使用BiLSTM 时,如果输入过长,会对较前的输入丢失较多的特征,因此引入CNN 先输入文本的局部特征,减少信息丢失。同时,CRF相比于Softmax 可以更好地考虑标签间的影响与偏置,综合计算每个词X 的得分s(X,y),得到实体标签的概率p(y|X),在训练过程中,使用对数似然最大化正确概率p(y|S),计算公式如式(1)所示,尽可能地优化标签序列如式(2)中的结果y*。
BiLSTM+CNN-CRF 模型进行实体抽取的算法如下:
输入:部分标注数据集、原始数据
输出:标注实体数据集
步骤:(1)将原始数据转换为词向量集
(2)得到的词向量输入CNN和BiLSTM
(3)初始化双向长短时层,求解网络权重矩阵
(4)初始化卷积层,设置参数
(5)拼接输入(3)、(4)的词向量
(6)对结果进行加权后输入条件随机场,得出最优序列标注模型
(7)修改参数的设置,比较结果
(8)将模型应用到数据集
对政策文本进行序列标注的具体处理过程如图2所示。
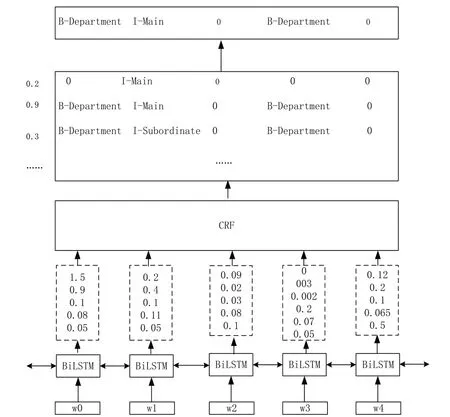
Fig.2 Entity recognition algorithm flow based on BiLSTM+CNNCRF图2 基于BiLSTM+CNN-CRF 的实体识别算法流程
2.2.2 关系抽取
关系抽取主要是为了得到应急管理政策公文、实施部门等实体间的关系。本文关系抽取通过卷积神经网络CNN 实现。将对政策信息实体抽取完成后得到的词向量和相对位置特征作为输入,加入到CNN 中获得句子级向量表示,这个句向量通过非线性全连接层计算输出进行关系分类,通过上述模型训练得到实体间的关系。关系抽取流程如图3所示。
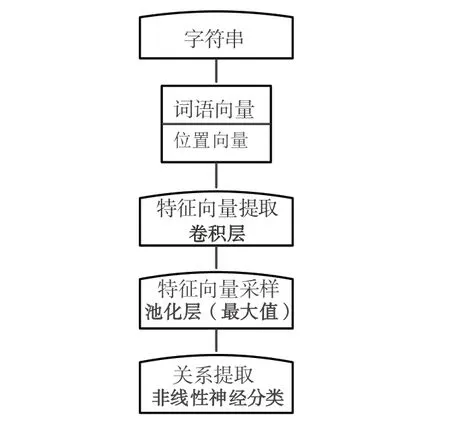
Fig.3 CNN-based relation extraction process图3 基于CNN的关系抽取过程
2.3 知识表示与推理
在进行知识推理前,首先要通过实体链接和实体对齐等方法,统一实体名称、合并同义三元组,消除知识冗余。由于本文构建知识图谱源数据为政策类文件,格式较为工整,并无太多相似或冗余知识,通过定义一些简单的规则即可进行消歧,如将实体“新冠”“新型冠状”“COVID-19”看作是同一个实体,将“省政府”“省人民政府”看作同一对象等。数据经过人工检测已基本不存在有歧义或多余的三元组。
知识推理是知识图谱构建中十分重要的一环,通过知识推理可以发现一些新的政策间和政策部门间的关系,这对应急管理尤为重要,能极大程度地提高政策部署和执行过程中众多实体的深度关联。由于本文知识图谱所涉及的部门实体大多是上层部门(Department),同时政府应急管理政策文本常常较为宽泛,没有详述具体部门(Subordinate),为了更方便具体部门内部人员查询和使用,实现政策通知更精准的发放,在进行知识推理前先补充了600 个常见具体政务部门实体数据,加入管理政策知识库中,数据来源于中文通用百科知识图谱中的部门数据[34]。针对其中出现的部门间名称重复、简写的情况,需要在特定的简写前加上部门限制,使其一一对应。以教育部为例,导入的子部门节点如表4和图4所示。

Table 4 Example of triplet for a sub-department of the Ministry of Education表4 教育部子部门三元组示例
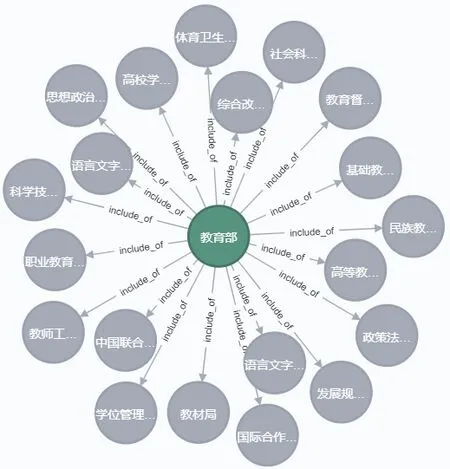
Fig.4 Sub-departments of the Ministry of Education imported图4 导入的教育部所属子部门
本文采用基于规则的推理与基于分布式图的推理两种推理方式[35]。基于规则的推理能利用简单的逻辑运算推断出政策通知的传递过程;基于分布式的推理则能在信息缺失的情况下更好地关联知识,深入挖掘实体间的关系,更好地处理复杂的实体间关系。
2.3.1 基于规则的推理
按照实体周围政策节点的连接推断出此节点可能存在的新连接,进而推理出实体之间的连接关系[36]。比如消息在管理部门之间可能的传递性,从主部门推理到具体从属部门,推理过程用一阶谓词逻辑表示为:<通知,notify_to,对象A>∧<对象A,include_of,对象B>→<通知,notify_to,对象B>。实例如图5、图6 所示,从<教育部—do_realse(发布)—新冠肺炎防治方案>∧<教育部,include_of,高等学校>→<新冠肺炎防治方案,notify_to,高等学校>。其中,图5 为教育部发布通知,通知自动推理到其下属涉及部门,推理结果如图6 所示,从而揭示了教育部疫情防控方案与高等学校的关系。这种推理规则只适用于所属子部门属于同一类对象而不适用于各司其职分管不同事物的子部门,如教育部分管所有高校,有关考试防疫的政策通知应传递到与通知内容相关的所有高校而不能传递到下属报刊社、传媒出版集团等部门。
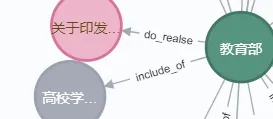
Fig.5 Pre-inference relationship of the three(example of rule reasoning)图5 推理前三者关系(规则推理举例)
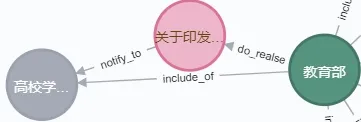
Fig.6 Post-inference relationship of the three(example of rule reasoning)图6 推理后三者关系(规则推理举例)
2.3.2 基于表示学习的推理
本文基于TransR 模型[37]为每个关系引入一个映射矩阵,将实体投影到对应的关系空间中,得到三元组的映射向量,具有关系的实体相互靠近,其损失函数表示如式(3)所示。
基于表示学习的推理,其具体思想是将实体、关系映射为向量表示,根据向量的空间距离自动学习推理所需特征,使得知识图谱能够通过预设向量空间的特征表示自动计算实现推理过程。理论上,重复路径多的并在同一层次上的实体被通知到的可能性更大,推理过程表示为<通知,notify_to,对象A>→<通知,notify_to,对象B>,其中对象A 与对象B 之间没有明显上下层次关系。如从<强化中医医疗机构新冠肺炎疫情防控工作,notify_to(通知),直辖市>推理到<强化中医医疗机构新冠肺炎疫情防控工作,notify_to(通知),自治区>,其中自治区和直辖市都属于同等层次Target 可通知目标实体,它们在许多通知中有相似的传递路径,空间距离向量近,因而可以合理推理出该通知应该同时传递给两者。
3 实验与分析
3.1 总体框架
本文基于新冠肺炎疫情的管理政策文件实现知识抽取、知识推理、知识存储等知识图谱构建过程。其中,知识抽取从半结构化和非结构化的疫情应急政策数据中通过人工抽取与自动抽取的方式得到图谱中的部门节点与政策节点,核心是抽取出数据中的对象实体、关系及属性,形成SPO 三元组知识。知识推理则是发现实体节点之间可能存在的关系,实现政策间互联,发现更多潜在的应急方案知识。最后,将知识存储在图数据库以进行可视化且不断补充完善,形成全面的突发公共卫生事件应急管理知识库。本文总体知识图谱构建模型如图7所示。
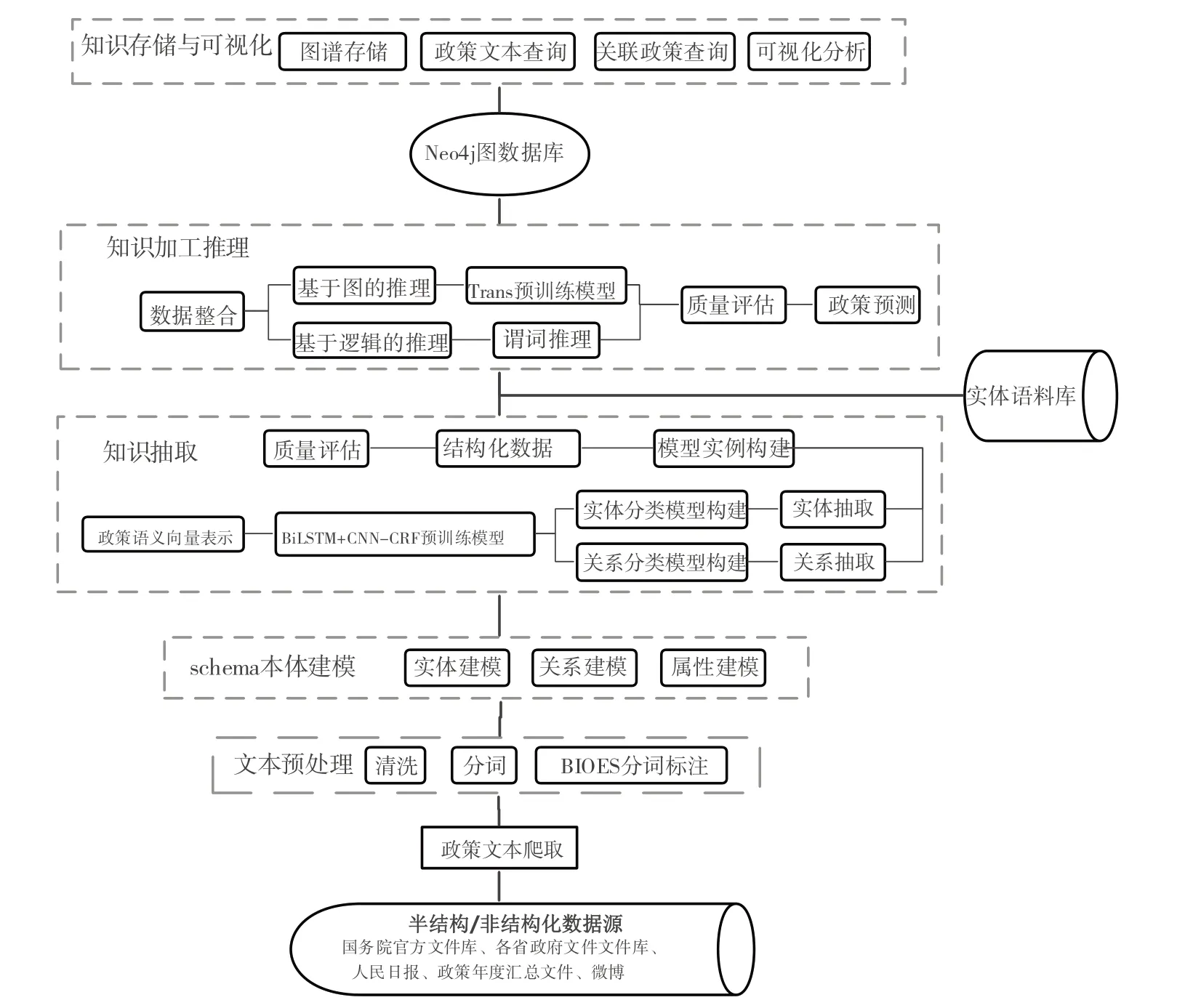
Fig.7 Knowledge graph construction model of COVID-19 emergency management policy图7 新冠疫情应急管理政策知识图谱构建模型
3.2 数据来源与预处理
可供选择的新冠肺炎疫情应急管理政策信息来源主要包括国务院政府政策文件库、各省官方网站、人民日报官网等,考虑到国务院和省政府官网数据较为正式明确、数据格式规范,本文选择国务院文件库与各省政府官方网站作为数据来源,选择湖北、湖南、广东、河南、江西、浙江、安徽7 个疫情较为严重的省份。采集数据时设置检索关键字为“新冠肺炎”“新型冠状病毒肺炎”或“COVID-19”,设置时间“两年内”进行筛选,截至2021 年12 月31 日,最终共搜集国务院政策文件304篇,各省政府文件8 951篇。
为了后续政策文本实体抽取,需要先对训练数据进行标注以训练模型,本文采取BIOES 标注规范,只要不在三元组中的字标签都为O,其余字符按照标注格式:实体类型(下述6 种实体类型每种用一个字母表示)-位置(B begin/I inside/E end/S single)+顺序编号(B/I/O/E 种的第几位),依次进行标注,具体方法如图8 所示。其中,“教”标记为“部门Department 类型-处于实体开头begin+开头的第1 个字符”,“育”标记为“部门Department 类型-处于实体中间inside+中间的第1 个字符”,“部”为“部门Department 类型+处于实体末尾end+最后的第1 个字符”,“关于……”一律标记为“O”表示非实体。

Fig.8 Schematic diagram of data labeling strategy in the process of entity relation extraction 图8 实体关系抽取过程中的数据标注策略示意图
标注完成后,按照一定的规则检验标注正确性,包括:①同一个实体对象中,B 和E 只能出现在开头结尾处且只能被编号为1;②I 只能出现在B 和E 中间且编号递增;③S只能出现编号1的情况。
3.3 图谱构建
目前阶段,并没有专门针对政府文件的标注语料库,实验中利用中文语料库以及部分手工标注数据训练,共选取国务院发布的200 篇政策共10 069 条数据进行了标注。实验中,训练语句取80%,测试语句取20%。
本文利用BiLSTM+CNN-CRF 模型从9 255 篇政策数据中共抽取实体33 072 个,表5 列举了部分抽取的实体结果及规模情况。

Table 5 Examples and specifications of main entity extraction results表5 主要实体抽取结果举例与规格
关系抽取仍采用此前标注的10 069 条数据进行训练。实验中,经过多次参数调整,最终选择学习率为0.01,dropout 值为0.1,迭代次数选择为10 轮,filter 为3,kernel_size 为4。
经过关系抽取,共获得405 368 条关系,以“新冠肺炎疫情联防联控机制”政策为例,关系抽取后得到的部分结果如表6 所示,每行展示一组信息,表示为实体1 与实体2之间的关系,由于一句话可能包含多个实体与关系,故需将每个关系分开进行单独处理,如“联防联控机制”包括“激活应急指挥能力”“提升核酸检测能力”“加强溯源”等7个小要求,需将每个小要求均与大政策“联防联控机制”单独联系为subtitle_of(包含)。
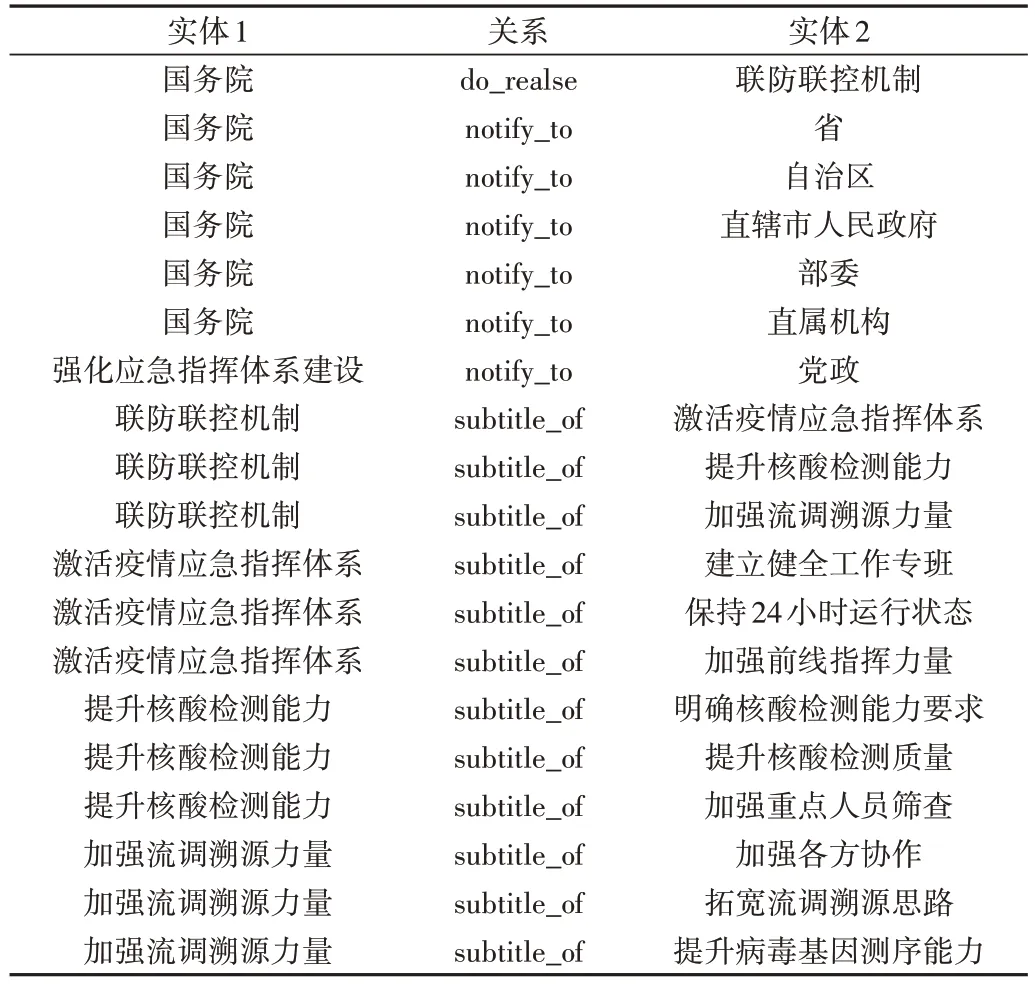
Table 6 Partial extraction results of policy relationship of joint prevention and control mechanism for COVID-19表6 “新冠肺炎疫情联防联控机制”政策关系部分抽取结果
知识抽取完成后,基于简单部门逻辑的推理后,再将实体映射到对应关系空间进行向量表示以预测链路,每次选择80%三元组作为训练集,设置向量嵌入维度为200 维并通过10 轮迭代训练,进行实体关系预测。同时,在训练过程中,对于不符合事实逻辑的错误推理,需要及时进行修正、删除,然后重新进行训练,经过多轮反复,新冠疫情政策知识图谱内容会逐渐完善,推理结果将会逐渐准确。以上实验重复5 次,最终结果取均值,实验结果如图9 所示。试验结果表明,该模型能较好地在该政策数据上进行推理。
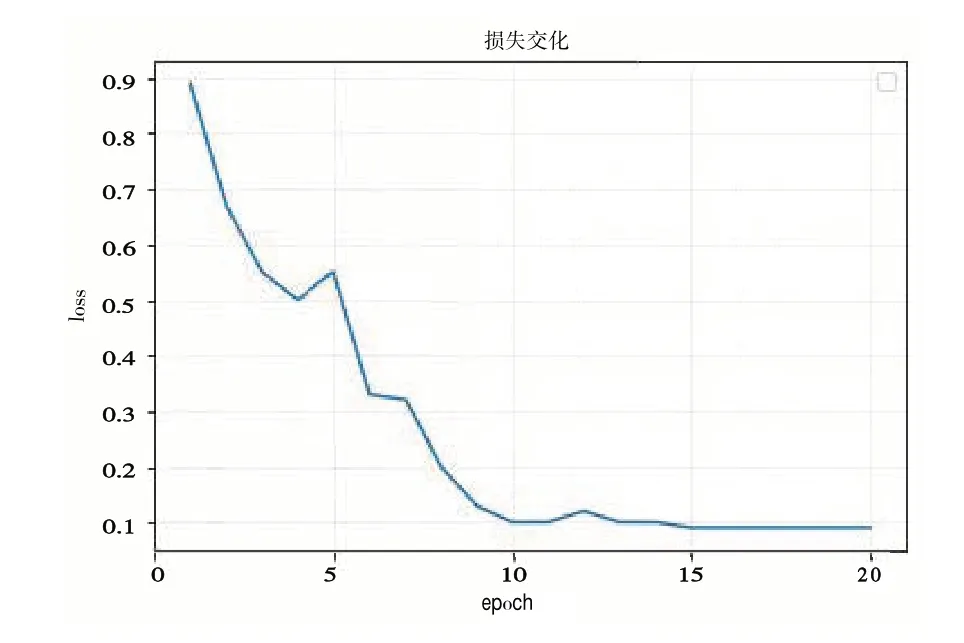
Fig.9 Change of loss curve图9 损失变化曲线
经过两种推理完成后,本文知识图谱关系数量增长26 933 条,最终图谱规模如表7 所示。随着通知数目的增加、涉及部门的进一步详细分类以及图谱中加入更多的部门实体,图谱将能够推理出更多的关系。

Table 7 Policy knowledge graph scale表7 政策知识图谱规模
3.4 模型质量评估
在进行知识抽取后,对抽取结果进行评估,采用常规准确率、召回率和F 值作为评价指标。如表8 所示,分别与只使用BiLSTM 的算法和BiLSTM-CRF 算法进行对比,最终本文模型准确率达85%以上,说明了BiLSTM+CNNCRF 模型的有效性。
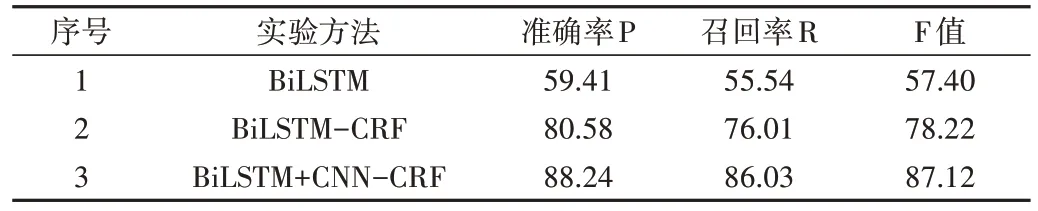
Table 8 Entity extraction algorithm comparison results表8 实体抽取算法对比结果(%)
在知识推理环节,采用损失值Loss 作为判断指标,当损失函数不再下降时,认为推理完成。在知识推理完成后,还需要进行错误评估、知识更新等加工过程,以提升知识图谱的可靠性和结构性。
构建好的知识图谱可能存在一些错误,主要集中在3个方面:上下位问题即图谱应该呈树状结构而无环、实体属性偏差、实体间关系逻辑错误。推理后得到的图谱经过查找,发现无环状结构;对于属性偏差和逻辑错误的问题,通过人工分组随机抽检,从最终图谱中随机抽取500 个实体和500 组推理关系,经过检验,认为它们的属性无异常情况,推理均符合实际逻辑。
此外,在实际应用时,每个部门也应该自行检查自己部门的知识可信度,若发现可能存在的推理错误时,可及时更正、删除,保证图谱及时更新,这也是进一步提升政策传递推理准确性的关键。
3.5 图谱可视化
本文利用RDF 和图数据库的方式实现政策知识存储,然后利用Neo4j 图数据库实现管理政策信息可视化。通过Neo4j 数据库实现实体关系存储,实体包括疫情政策的对象、主题、内容等。图10 展示了单个政策信息结构(彩图扫OSID 码可见),包括发布部门Department“中医药局办公室”(绿色圈)、通知主体Announcement“强化中医医疗机构新冠肺炎疫情防控工作”(粉红色圈)、内容Contents(玫红色圈)、通知对象Target(蓝色圈)等。图11 则为部分政策通知的节点展示。
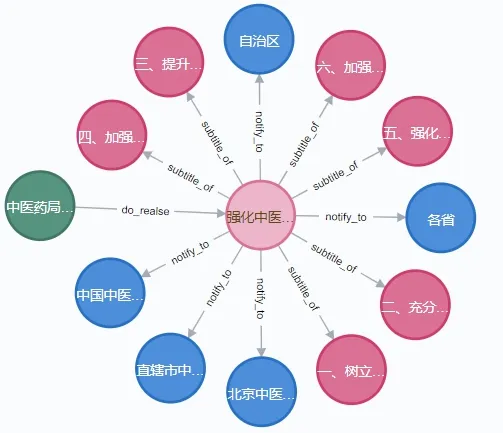
Fig.10 Single policy structure图10 单个政策结构

Fig.11 Partial management policy nodes图11 部分管理政策结点
以管理政策实体“强化中医医疗机构新冠肺炎疫情防控工作”为例,其属性情况如图12 所示,包括公文主题分类、公文种类、发文字号、发文机关、成文日期等。

Fig.12 Entity property图12 实体属性
一个通知对象会被若干个具体通知所涉及,这些通知属于不同主题,其中通知节点会根据通知路径的相似或距离的相近自动推理到可能被通知的对象。图13 以中医药管理局为中心节点展示了知识图谱中发布政策的代表性细节结构,一个部门会发布若干个通知,每一则通知又包含若干个具体通知内容,会通知到不同的对象。
4 图谱应用分析
4.1 应用部署
整个突发公共卫生事件应急管理政策知识图谱的部署和应用结构如图14 所示。在这种政策发布模式中,中央政府具有最高权限,原先政策分级发布、疫情分级管理模式变为扁平化结构,将权力分散,极大减少了政策传递的时间损耗。该结构通过“政策知识图谱+信息系统”的智能模式,辅助中央机关部门实时自动监督各地机关部门,从全局评估并强化各地应急管理能力。这样知识图谱的构建相当于建立了一个全面的政策信息管理平台,形成了一个专业的突发公共卫生事件资源库,辅助实现多元共治、内生驱动的绿色响应信息应急通道,实现统一快速的应急管理。
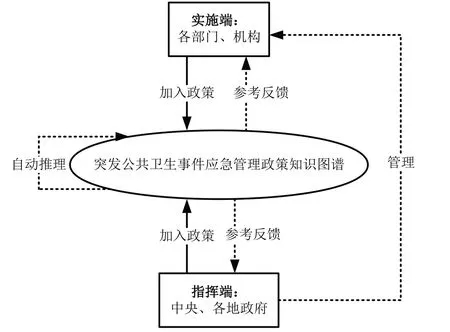
Fig.14 The deployment structure of knowledge graph图14 知识图谱部署结构
4.2 政策解读
利用Neo4j 数据库,相关政策人员可以查询到具体每一则政策文本的细节,包括内容、主题、部门等,对其进行可视化操作,发现政策通知的协作管理部门及其联系,并在图谱中发现推理后政策可能的流向。部分查询语句如表9 所示,查询界面如图15 所示,部门关系查询实例如图16、图17 所示,在图中可以查询到“人社部发(2020)24 号”通知及其在各部门的传递网络。

Table 9 Part of the commands to query the graph表9 部分查询图谱指令
Fig.15 User query interface图15 用户查询界面

Fig.16 Policy notification example图16 政策通知实例
知识图谱的构建可以清晰地从长篇政策文章中快速捕捉重点,围绕核心展开部署。同时,该政策通知与其他子通知、子部门对象之间的关系也可以展示出来,比如该通知所涉及的司法、人力资源、卫生健康、知识产权等多部门合作,还可以利用多级查询展示各部门在下一层的图谱关系,同时探索出可能存在的多级政策传递链,快速帮助快速传递政策文件,提升政府政策文件管理及传播效率。
4.3 主题关联
政策知识图谱除可以按照部门查询信息,还可以从主题视角发现政策间的关联,这些主题通过抽取得到,在数据库中搜索相关关键词即可查到相关政策并可视化观察它们之间的联系。比如,多则政策通知同时涉及物资调配与复工复产相关主题,通过主题到政策再到部门的链接分析可以得到这两个主题下的相应机构(见图18),进而可以给这些关联的物资生产机构推送与其权责相关的政策通知,促进相关机构根据各级政府发布的政策合理合规地安排自己的生产工作,减少信息不对称和信息传递所造成的成本和时间浪费。
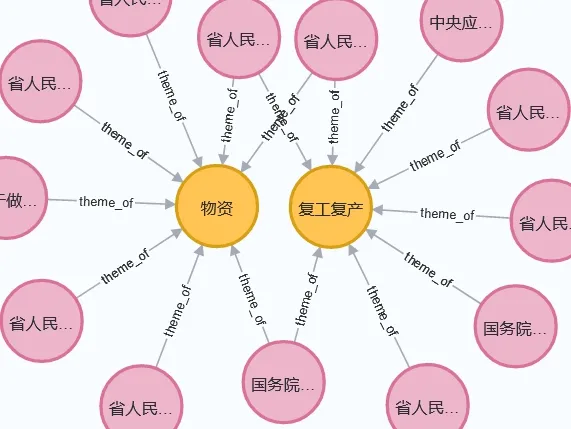
Fig.18 Materials and resumption of work and production policies series(part)图18 物资与复工复产系列处理政策(部分)
类似地,对于疫情初期救援物资调度混乱、责任不清等问题,包括应急管理部、物资局在内的多个部门之间都发布了物资调度政策,有些政策重复发布,有些分管部门权责不清,导致物流物资一系列处理政策混乱的问题。而通过应急管理政策知识图谱能及时更新所有部门发布的政策与处理方案,聚合中央及地方政府下达的物资调配指令,促进援助物资配置优化,区域联动资源共享,形成有效的物资联动机制。这样,疫情防控政策知识图谱的构建相当于用另一种方式将政策文件深度关联,为一个主题类型的政策制定提供知识库。
5 结语
本文以新冠疫情防控政策为例,构建了一个突发公共卫生事件应急管理政策知识图谱,实现了构建的主要步骤,即Schema 构建、知识抽取、知识推理、可视化及应用分析,进而提取和分析新冠疫情应急管理的经验知识和管理策略。该知识图谱的构建丰富了突发公共卫生事件应急管理知识体系,建立了应急政策信息快速响应通道,形成整体的信息传递网络结构,在发生类似事件时能提供应急管理政策的整体布局、可视分析、精准传达等智能决策功能。
知识图谱的扩展和更新是下一步研究的重点,比如不断加入新颁布政策、加快图谱更新速度、将时间属性嵌入到推理过程中、探索更准确的关系抽取模型、融合更便捷的人机交互查询方式和更有效的知识图谱检验系统等。同时,由知识图谱带来的一系列应急政策及管理方式的变革思路等也值得探索。
