面向城市用电负荷预测的混合机器学习模型
2023-09-15胡乙丹张俊芳
胡乙丹,张俊芳
(南京理工大学 自动化学院,江苏 南京 210018)
0 引言
智能电网的理想场景是供应给目标区域的电量等于客户的消费量,不仅能对电力资源进行合理分配从而产生巨大的经济效益,而且能抵御引起大规模停电的诸多不确定因素,例如自然灾害、季节性高峰、恐怖袭击、城市动乱、战争等,因而也具有很高的社会价值[1]。
城市用电负荷的精准预测是实现智能电网的前提条件,其中中长期用电负荷预测对电力系统的运行和规划非常重要[2]。城市中长期用电负荷预测是一个非线性时间序列趋势预测问题,与诸多因素有关,例如一个国家的整体经济发展速度、季节性气象周期因素、节假日规划以及各种不确定因素等。因此,如何准确刻画影响城市中长期用电负荷的诸多因素是实现精准预测的关键。
现有城市中长期用电负荷预测方法主要分为两大类,即经典的时间序列方法和新兴的机器学习(Machine Learning,ML)方法[3]。时间序列方法的代表模型有自回归积分移动平均(Autoregressive Integrated Moving Average,ARIMA)、指数平滑(Exponential Smoothing,ETS)和线性回归,其优势在于模型相对简单、稳健、高效,且能很好地处理季节性时间序列[4]。ML 方法是当前的新兴技术,具备强大的非线性表征学习能力和复杂数据挖掘能力,现已得到了广泛应用[5-7]。
在所有ML 方法中,对于神经网络(Neural Network,NN)的探索与应用最为广泛,一些代表工作有:文献[8]结合历史需求和天气因素学习负荷需求的变化规律;文献[9-14]利用Kohonen NN、循环神经网络(Recurrent Neural Network,RNN)以及其它基于NN 的变体实现准确的电力负荷预测。
最近,随着深度学习(Deep Learning,DL)的快速发展,基于DL 的城市用电负荷预测得到了广泛关注[15]。例如,节点之间的连接沿着时间序列形成一个有向图的RNN,能够利用其内部状态(记忆)来处理输入序列,从而表示时间动态行为。另外,最近研究表明,长短期记忆(Long Short-Term Memory,LSTM)网络预测结果优于大多数经典时间序列方法和ML 方法[16],现已有诸多将LSTM等DL 方法应用于负荷预测的成功案例[17-19]。例如,文献[20]提出一种新颖的卷积网络结合双向LSTM 来实现短期负荷预测;文献[21]提出一种用于学习深度序列预测的残差循环高速网络;文献[22]提出N-BEATS 模型,具有可解释性,且训练速度快,无需修改即可应用于广泛的目标领域;文献[23]提出的DeepAR 模型基于对大量相关时间序列的自回归RNN 训练,实现准确的概率预测;文献[24]提出将深度学习与状态空间模型相结合,可保留状态空间模型的所需属性,如数据效率和可解释性,同时具备从原始数据中学习复杂模式的能力。
此外,为了提高预测性能,ML 方法还与ETS 等其它方法混合使用[25-26]。例如由文献[27]开发的模型是一种结合统计学和ML 的混合方法,将ETS 与LSTM 相结合,使得LSTM 模块具备了诸如扩张、残差连接和注意力机制等可提高其学习与泛化能力的机制[28-30],实现了精确的负荷预测。但是,由于城市中长期用电需求不仅受长期经济趋势和季节循环因素的影响,而且存在诸多不确定性和非线性问题,因而文献[31]提出利用集成学习融合LSTM 和ETS,使预测模型具备较好的综合性能。
然而,影响城市用电负荷需求的因素众多,各因素对趋势特性、季节特性等方面的影响各不相同。例如历史用电负荷数据和经济状况可较好地反映趋势特性,气候和节假日等因素可很好地反映季节特性。因此,在开展城市用电负荷需求预测时,需要对各因素进行重要性分析,并对各方面特性进行针对性建模,才能准确刻画诸多因素,实现精准预测。但是,现有方法并未针对上述问题进行建模解决。为此,本文参照文献[31],通过引入特征选择筛选出影响城市用电负荷趋势特性和季节特性的重要特征,提出一种面向城市用电负荷预测的混合机器学习(Hybrid Machine Learning,HML)模型。该模型针对负荷的趋势和季节特性筛选出重要特征,利用ETS 捕捉负荷时间序列的季节和趋势分量,然后利用LSTM 和所筛选的特征对趋势和季节分量进行非线性预测,最后利用集成学习实现各学习模块性能的有效聚合。在实验中,本文选择中国两个城市的月度用电量作为标准数据集,通过特征选择筛选出节假日、天气、湿度、风力、降雨、气压、云量、最高温度、最低温度等12 个重要特征进行建模。实验结果表明,本文提出的HML 模型在月度用电量预测精度方面优于现有最新的相关模型。
本文主要贡献包括以下两点:
(1)提出一种面向城市用电负荷预测的混合机器学习HML 模型,该模型同时具有经典时间序列方法的稳健性和机器学习方法的强非线性学习能力两个优点,在城市月度用电量预测精度上优于现有的最新模型。
(2)对所提出的HML 模型进行了详细阐述和分析,并在真实数据集上进行了实证分析,证明了其有效性。
1 预测模型
本文所提出的HML 模型是一个混合机器学习模型,可以有效结合特征选择、ETS、LSTM 和集成学习的优点。在特征选择中,不仅会筛选与用电负荷预测相关的特征,而且将分别针对趋势特性和季节周期特性进行针对性的特征选择;在ETS 方法中,目的是为了将用电负荷时间序列拆解为趋势分量和季节分量,在后续预测建模中将单独针对单个分量进行预测;在LSTM 模型中,将分别针对趋势特性和季节周期特性筛选的特征进行单独预测,可分别提升单个分量的预测精度;最后基于集成学习的多样性原则构造多个预测子模型,利用多个子模型的综合预测能力减少随机特性对预测结果的影响,提升模型预测的稳定性。下文详细阐述HML 模型。
1.1 模型框架与功能
本文所提出的预测模型结构如图1所示。
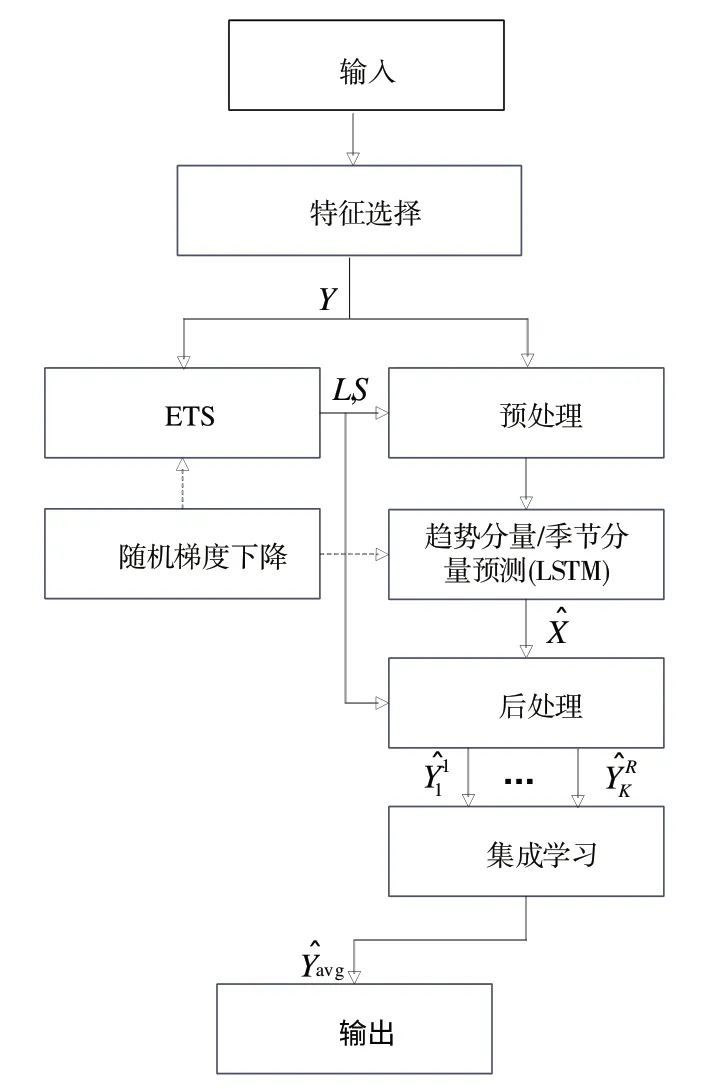
Fig.1 Structure of HML model图1 HML模型结构
HML 模型由以下部分组成:
(1)特征选择。输入与用电负荷相关的各种因素特征,通过特征选择方法筛选出与季节因素和趋势因素最相关的特征用于后续模型建模。
(2)ETS。一种乘法季节性分解模型,其可从时间序列中提取两个分量趋势和季节分量。ETS 加载一组时间序列(Y),分别计算每个序列的趋势和季节分量,并返回趋势分量集(L)和季节分量集(S)。
(3)预处理。趋势和季节分量用于时间序列的去季节化和适应性规范化。预处理模块的输入包括时间序列集Y、趋势分量集L和季节分量集S。预处理后的数据被划分为输入和输出训练数据,并最终返回训练集ψ。
(4)LSTM。由4 层组成的残差扩张LSTM 具有的重复特性使其能够学习连续数据中的长期依赖关系。LSTM 在训练集ψ 上进行交叉学习,其产生的全部时间序列预测将返回集合。
(5)后处理。对去季节化和归一化的时间序列预测进行重新季节化和重新归一化。后处理模块的输入包括预测集、趋势分量集L和季节分量集S,输出则为包含每个时间序列预测的集合。
(6)集成学习。对单个模型产生的预测进行平均,以进一步增强方法的鲁棒性,减轻模型和参数的不确定性。集成学习模块接收由单个模型生成的预测集(k和r与集合成员有关),对其进行聚合并返回所有时间序列的预测集Yavg。集成学习结合了训练阶段、数据子集和模型3 个层面的单个预测,以减少与随机梯度下降的随机性、数据和参数的不确定性相关的方差。
(7)随机梯度下降(Stochastic Gradient Descent,SGD)。ETS 和LSTM 通过相同的整体优化程序——SGD 算法来更新参数,其首要目标是使预测误差最小化。
1.2 特征选择
特征选择也称为特征子集选择或属性选择,是从输入的用电负荷众多特征中筛选出最相关的有效特征,降低数据集维度,去掉不相关特征和冗余特征,提高学习算法的性能,是本文HML 模型的关键步骤。本文输入众多相关特征,如节假日、天气、湿度、风力、降雨、气压、云量、最高温度、最低温度等,并采用相关性分析和冗余分析筛选出重要特征[32],具体流程如图2所示。
首先,计算每个输入特征x(i)与负荷时间序列y 之间的皮尔逊相关系数(Pearson Correlation Coefficient,PCC),假设总共有N个时间序列,PCC计算公式如下:
如果x(i)的PCC大于设定的阈值2,则为强相关特征,直接保留输出;如果PCC小于设定的阈值1,则为不相关特征,将其抛弃;如果阈值1≤PCC≤阈值2,则为弱相关特征,进入冗余性分析。采用马尔可夫毯分析方法分析x(i)是否为冗余特征,如果x(i)是冗余特征,则x(i)应满足如下条件:
其中,MB(y)代表y 的一个马尔可夫毯,ζ代表一个任意集合。对于冗余特征,则应该抛弃。
1.3 ETS
时间序列拥有复杂的性质,可利用各种分解方法分解出其中的重要分量[33]。本文所提出的HML 模型使用ETS作为预处理工具,从时间序列中提取趋势分量和季节分量,然后使用这些分量对原始时间序列进行规范化和去季节化处理,预处理后的时间序列由LSTM 进行预测。季节性周期为12(适用于月度电力负荷数据)的ETS 模型更新公式具体如下:
其中,yt是时间点t的时间序列值,lt、st分别是趋势分量和季节分量,α,β∈[0,1]是平滑系数。
趋势分量方程显示了经季节调整的观测值与时间点t-1 趋势分量之间的加权平均值。季节分量方程将时间点t+12 的季节分量表示为季节分量新估计值(yt/lt)和过去估计值(st)之间的加权平均值。通过SGD 调整ETS 模型参数、12 个初始季节分量、每个时间序列的两个平滑系数以及LSTM 权重,获得这些参数后,可以计算趋势分量和季节分量,参与后续负荷时间序列预处理的去季节化和归一化,以及最终负荷预测结果的计算。
1.4 预处理与后处理
计算每个时间序列所有点的趋势分量和季节分量,然后在动态预处理期间将其用于去季节化和自适应归一化。这是预测过程中最关键的因素,决定了预测模型性能。在每个训练时段中,使用趋势分量和季节分量的更新值对时间序列进行预处理。这些更新值由公式(3)计算得出,其中ETS参数在每个训练轮次中由SGD 逐渐进行微调。
时间序列使用滚动窗口进行预处理,包括输入和输出窗口。两个窗口的长度均为12,等于季节周期和预测范围的长度。输入窗口Δin包含12 个连续的时间序列元素,经过预处理后作为LSTM 的输入(即输入向量)。对应的输出窗口Δout也包含12 个连续元素,经过预处理后作为LSTM 的输出(即输出向量)。通过将两个窗口内的时间序列片段除以输入窗口中趋势分量的最后一个值,对其进行归一化,然后除以相关的季节分量,通过此操作获得接近1 的正输入和输出值。最后,使用一个压缩函数log(.)限制异常值对预测的破坏性影响。预处理结果可表示如下:
其中,xt是第t个预处理的时间序列元素是输入窗口Δin中趋势分量的最后一个值,st是第t个季节分量。注意归一化是自适应和局部的,“归一化器”遵循系列值,即允许将输入和输出变量中序列(和st)的当前特征包括进来。
包含在连续输入和输出窗口中时间序列的预处理元素可由如下向量表示:
第一对输入和输出窗口:
第二对输入和输出窗口:
第N对输入和输出窗口:
这些表示输入和输出窗口中时间序列预处理元素的向量包含在第i个时间序列的训练子集中:Φi=。所有M个时间序列的训练子集被组合起来并形成训练集Ψ={Φ1,Φ2,...,ΦM},用于LSTM的交叉学习。注意训练集的动态特性,由于公式(4)中的趋势和季节分量已更新,因此其在每个训练轮次中都会更新。
LSTM 对预处理的时间序列值xt进行操作。在后处理步骤中,LSTM 生成的预测需按以下方式展开:
注意,公式(5)中的趋势分量值和季节分量st是已知的,这是通过计算所必需的,其由公式(1)根据负荷时间序列的历史值计算得到。
1.5 LSTM
LSTM 是一种特殊的RNN,能够学习序列数据中的长期相关性[34]。一个普通的LSTM 块由一个能够随时间步更新而更新状态的存储单元和3 个称为门的非线性调节器组成,其能控制块内的信息流。一个典型的LSTM 块如图3 所示。在本文中,经过预处理后的LSTM 输入并非标量,而是长度为12(即季节周期)的时间序列向量,其允许LSTM 直接暴露于即时的历史序列。LSTM 输出是一组长度为12 的完整预测序列的向量。同时,在输入过程中,还将一起输入对应时间序列长度的特征,例如将对应时间序列的气温或节假日天数作为特征一起输入。确定x的输出模式后,根据公式(3)计算月需求的预测值。
1.6 集成学习
集成学习是一种应用广泛的可提高单个弱学习器性能的方法。与单个学习器相比,集成学习方法以某种方式将多个学习算法结合起来产生一种共同的响应,以提高预测结果的准确性和稳定性。集成学习的关键问题是确保学习器的差异性[35],对单学习器性能与差异性之间的正确权衡决定了集成学习的有效性。HML 预测模块有以下3种差异性来源:一是使用SGD 的随机训练过程;二是类似于采样数据集,即使用随机抽取的训练集子集来训练每个学习器;三是使用不同的参数初始值训练基学习器。因此,相对应地,由LSTM 模型生成的分量预测结果在以下3个级别上进行集成学习:
(1)训练阶段级。对L个最近训练轮次产生的预测结果进行平均。
(2)数据子集级。对在训练集子集上学习的K个预测模型所产生的预测结果进行平均。
(3)模型级。对数据子集级预测的R次独立运行所产生的预测结果进行平均。
在第一层级别上进行平均计算具有平息噪声SGD 优化过程的效果。SGD 使用小批量的训练样本来估计实际梯度,梯度搜索计算所得的近似梯度在收敛曲线上表现为噪声。当算法在局部最小值附近收敛时,对最近训练轮次获得的预测结果进行平均,可以减少随机搜索的影响,形成更准确的预测。
在第二层级别上,在训练集子集Ψ1,Ψ2,...,ΨK上学习的K个模型产生的预测将被平均。训练集Ψ={Φ1,Φ2,...,ΦM}是由包含第i个时间序列训练样本的子集Φi构成的。要创建训练Ψ 子集,首先需将一组M个时间序列随机分成大小相似的K个子集:Θ1,Θ2,...,ΘK。第K个Ψ 子集包含所有时间序列的Φ 子集,但Θk中的Φ 子集除外,即Ψk=Ψ{Φi}i∈Θk。在K个模型中,每一个模型都在其训练子集Ψk上学习,并为Ψk中包含的时间序列生成预测。然后,对K个模型池生成的预测结果进行平均。
在最后一层级别上,简单地对K个模型R次独立运行中产生的每个时间序列的预测进行平均,每次运行中训练子集Ψk都会被重建。
注意学习器的差异性是决定集成学习性能[35]的一个关键属性,在本文提出的方法中有各种方式实现学习器的差异性,包括:①数据不确定性:在小批量和训练集的不同子集上学习;②参数不确定性:在每次运行中使用不同的模型参数初始值进行学习。
在最后两个集成学习级别中,创建了K个训练Ψ 子集。第k次运行中包含的第k个子集中的时间序列集合用表示,本例中模型生成的预测集合用表示。对于每个时间序列,R(K-1)预测取平均值。这两种集成学习级别的联合操作可表示为:
其中,K是模型池大小,R是运行次数,而表示第k次运行生成的预测y向量。
2 实验结果与分析
2.1 基本设置
(1)数据集。本文选择中国两个城市的月度用电量作为基准数据集,分别命名为D1、D2。这两个数据集还包括节假日、天气、湿度、风力、降雨、气压、云量、最高温度、最低温度等12 个对应时间序列的特征。表1 总结了数据集的统计信息,其中本文使用过去12 个月的数据,即将从2021 年1—12 月的月度用电量作为测试集,其余数据作为训练集。

Table 1 Statistics of the dataset表1 数据集统计数据
(2)评价指标。对于用电负荷预测,主要关注估计值与实际值的接近程度,因此通常选择平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和平均绝对误差(Mean Absolute Error,MAE)作为评价指标。MAPE 和MAE 分别反映了预测误差率与绝对预测误差,由式(7)计算:
其中,Ri代表第i个月份的真实值,表示第i个月份的预测值,N代表预测的总共月数。
(3)标准对比模型。本文将所提出的HML 模型与7 个相关的最新模型进行对比实验。这些对比模型具有不同特点,分为两种类型,包括5 个ML 模型(GRNN[36]、MLP[37]、XGBoost[38]、SVR[39]和LSTM[40]),以及2 个混合模型(NBEATS[41]和APLF[42])。表2 简要介绍了这些模型,其中所有模型的超参数都是在验证集(部分训练集)上调参所得。

Table 2 Descriptions of comparison models表2 对比模型描述
2.2 预测准确性比较
2.2.1 MAE比较结果
图4 展示了所提出的HML 模型和两类对比模型在两个数据集上的MAE 比较结果。
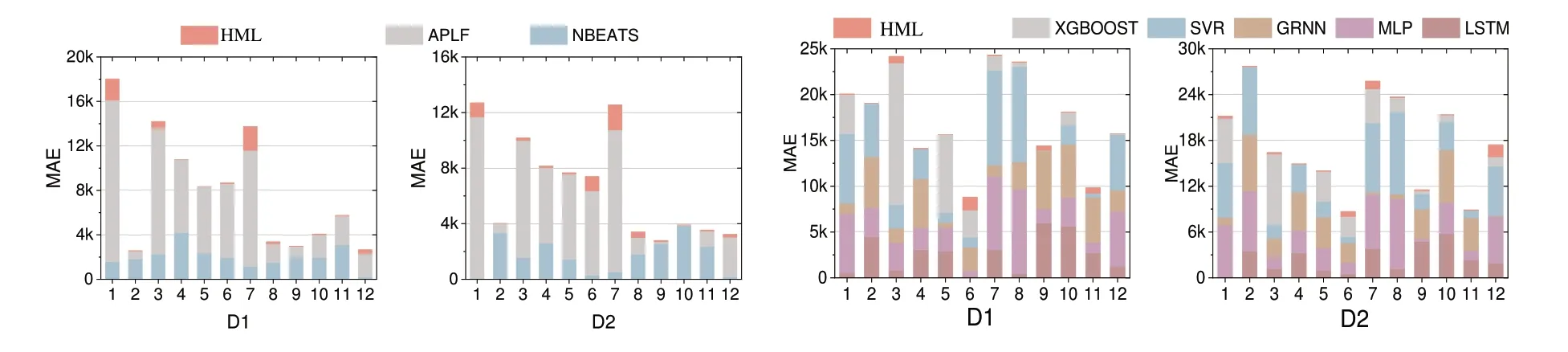
Fig.4 MAE comparison results of HML and other methods图4 HML与其他方法MAE比较结果
观察图4可以得到:
(1)总体上第3-6 月的误差相对于第7-8 月的误差要小;APLF 的预测误差最大;MLP 和XGBoost 的波动很大,且准确率时而高,时而低。
(2)在所有的对比模型中,HML 表现最好,不仅取得了最低的MAE,而且在大多数情况下取得了最稳定的预测结果。
(3)HML 比其它基于ML 的模型表现都好,验证了融入传统时间序列预测ETS 和集成学习可提升单一ML 方法的性能。
2.2.2 MAPE比较结果
MAPE 在D1 和D2 上的比较结果分别记录在表3、表4中。
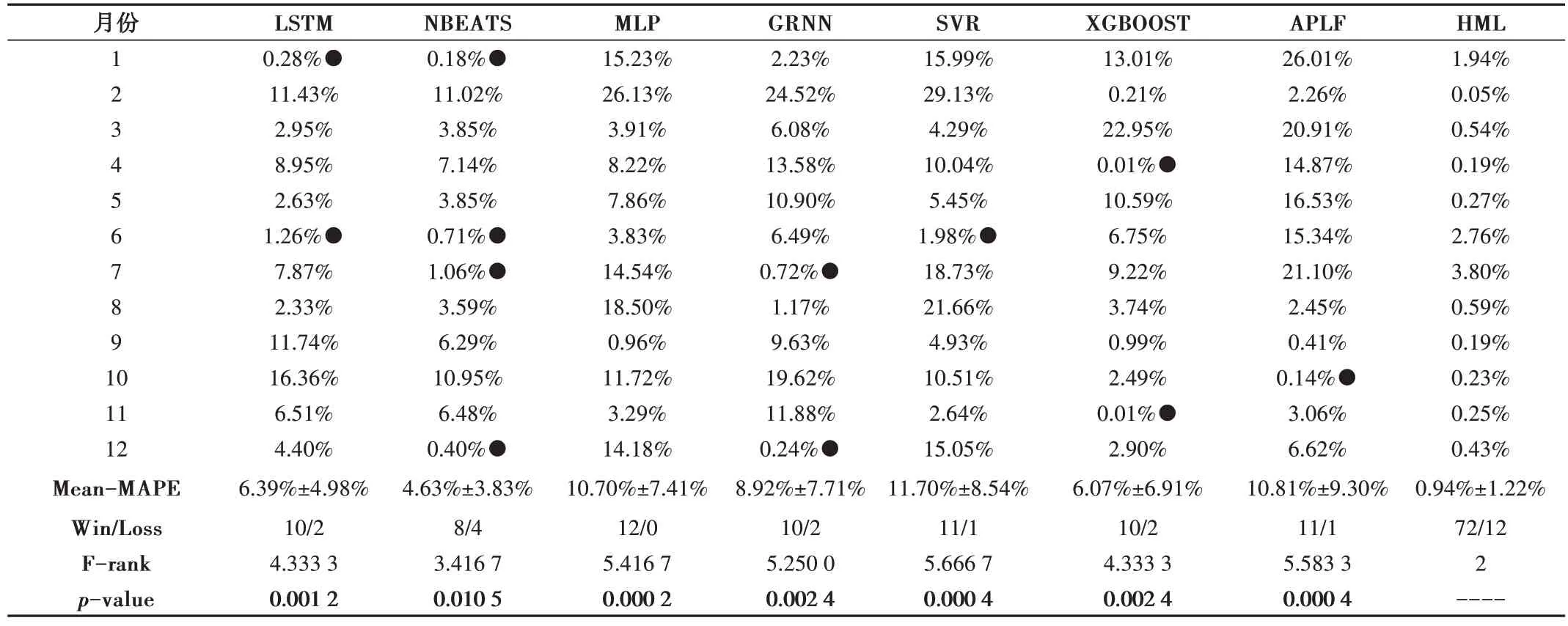
Table 4 Comparison results of MAPE on D2表4 MAPE在D2上的比较结果
为了更好地理解这些结果,对其进行了一些统计分析。首先,12 个月的平均MAPE 被记录在倒数第四行;其次,每个模型在12 个月中预测输/赢的比分在倒数第三行进行了总结,其中对某个月份预测精度比HML 高的预测结果追加以黑点“●”标记;再次,采用Friedman 检验来检查多个模型在多个数据集上的表现,F-rank 值越小表示准确率越高,结果记录在倒数第二行;最后,采用Wilcoxonsigned 检验HML 是否比每个对比模型的MAPE 明显更低,其中显著性差异水平小于0.05 的结果被加粗显示,相关结果记录在最后一行。
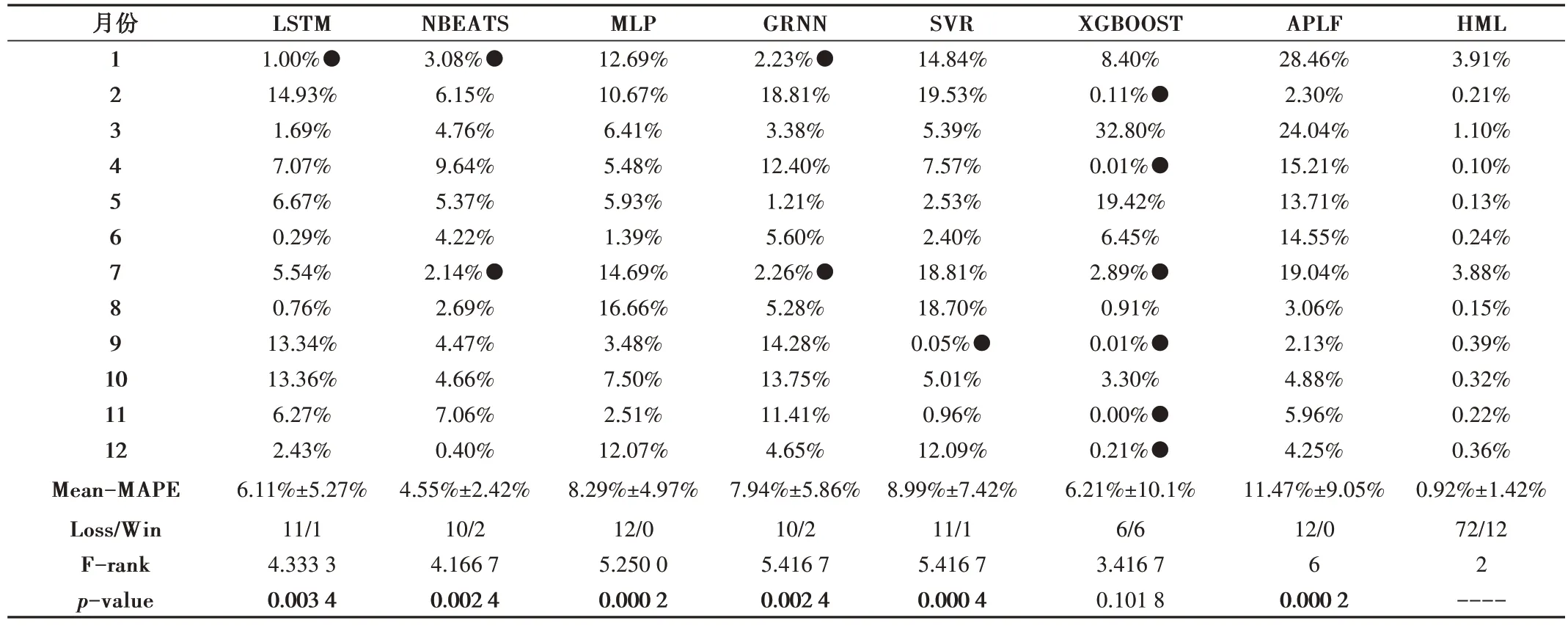
Table 3 Comparison results of MAPE on D1表3 MAPE在D1上的比较结果
从表3、表4可得出以下结论:
(1)在大多数情况下,HML 取得了比其他模型更低的MAPE,在D1、D2 上的平均MAPE 分别为0.92%±1.42%、0.94%±1.22%。在两数据集的比较实验中,HML 均只输了12 个案例,赢了72 个案例,证明HML 比其他模型误差更低,且更稳定。
(2)与其他所有模型相比,RD-ETS+LSTM 在两个数据集上取得了最低的F-rank 值,表明其在所有数据集上取得了最高的预测精度。
(3)除1 个案例外,其他的p值都小于0.05,表明HML在两个数据集上比其他模型的预测精度明显更高。注意,虽然只有一种情况的假设不被接受,但HML 仍然比其它对比模型的MAPE 低得多。
综上所述,MAE 和MAPE 的比较结果验证了本文所提出的HML 模型在月度用电负荷预测的准确性和稳定性方面显著优于其他同类模型。
3 结语
本文提出一种面向城市用电负荷预测的混合机器学习(HML)模型。该模型首先对影响城市用电负荷的各因素进行特征选择,筛选出重要特征;其次利用指数平滑(ETS)捕捉用电负荷时间序列的季节分量和趋势分量;然后利用长短期记忆(LSTM)网络发掘用电负荷时间序列的非线性趋势;最后利用集成学习实现各学习模块性能的有效聚合。为了验证HML 模型的有效性,选择中国两个城市的月度用电量作为标准数据集,并与最新的5 个机器学习(ML)模型和2 个混合模型进行了对比分析。实验结果表明,HML 模型在预测精度方面显著优于对比模型。在未来研究中,计划引入智能优化算法如差分进化来优化HML模型的特征选择,进一步提升模型性能。
