基于可逆网络的对抗样本防御算法的设计与研究
2023-09-15杨金李智张丽王熠卢妤
杨金 李智 张丽 王熠 卢妤

摘 要:深度学习模型极容易受到对抗样本的攻击。为了提高模型的鲁棒性,提升相关技术在现实生活中应用的安全性,提出一种轻型可逆网络(lightweight reversible network, LRNet)用于有效去除对抗样本中的对抗扰动。首先,将哈尔小波变换与可逆网络相结合,获得更丰富的特征;其次,将特征通道分离,利用干净样本的高低频特征指导学习,从随机数中重采样替换高频信息去除对抗扰动;再次,提出特征分离模块,去除非鲁棒特征,提高分类准确率。结果表明:LRNet防御模型能显著提高防御准确率,其分类准确率在MNIST,CIFAR-10数据集上较防御模型ARN分别从91.62%和67.29% 提升到97.65%和78.55%;模型的参数大小降低至0.48 MiB,是APE-GAN模型的20%;防御模型的迁移能力得到极大提高,为对抗样本的防御提供了一种新方法。
关键词:对抗防御;对抗鲁棒性;可逆网络;深度神经网络;对抗样本
中图分类号:TP391;TP309
文献标志码:A
近几年,伴随深度学习的蓬勃发展,深度神经网(Deep Neural Networks,DNNs)被广泛地应用于计算机视觉图像处理[1]、语音识别[2]、自然语言处理[3]等领域,然而深度神经网络很容易受到对抗样本的攻击,其脆弱性严重影响了对安全敏感度要求较高的应用场景的正常使用,例如人脸识别[4]、自动驾驶[5]等。如何有效防御对抗样本对深度神经网络的攻击是当前深度学习安全领域极具挑战的问题。
在近年来的研究工作中,对抗样本防御算法层出不穷。对抗训练[6]是一种常用的对抗防御策略,但其效果容易受对抗样本规模的影响,且容易被新的攻击方法攻破。在样本输入分类模型前,对其進行预处理的附加网络防御方法也是一种有效的对抗防御策略:如LIAO等[7]提出一种利用高维特征为导向的去噪(high-level guided denoiser,HGD)网络,在输入样本输入分类器之前,先对输入样本进行去噪;JIN等[8]基于GAN对对抗样本进行图像重构以消除对抗扰动;ZHOU等[9]提出通过学习保留分类语义信息的攻击不变特征以去除对抗性噪声。这些防御方法有一定的防御效果,但上述算法通常存在防御准确率及泛化能力较差、作为附加网络过于复杂、计算量大等一系列问题。文献[10]对网络的可逆性进行相关研究。可逆网络具备模型轻量化、信息无损、节约内存等特点,因此利用可逆网络作为附加网络可降低模型复杂度,减少计算量。当前针对医学图像的防御具有极大的现实应用价值。MA等[11]提出的医学深度学习模型,相较于自然图像深度学习模型更容易受到对抗样本的攻击。WANG等[12]提出一种新的多尺度医学图像去噪机制,取得了不错的防御效果。
防御模型通常存在泛化能力低,模型过于复杂、防御能力较差等特点。为了更好地适应现实场景的需求,提升模型的泛化能力,本文针对医学图像的对抗防御提出一种轻型可逆网络(lightweight reversible network, LRNet),去除对抗样本中的对抗扰动,将特征通道进行分离,利用特征分离模块保留图像鲁棒信息,降低了模型复杂度,提高了网络模型去除对抗扰动的能力及防御准确率,进一步增强了模型的防御准确率和泛化性。
1 主要算法
1.1 哈尔小波下采样
可逆网络具有信息无损的特点。为了去除对抗扰动,在特征反向传送前,将输入样本的噪声信息和干净信息进行有效分离,而仅将干净信息反向传送是重构出干净图片的重要前提。
本文利用哈尔小波变换[13]对输入样本Iadv进行空间域的向下采样操作,从整体、水平、垂直和对角线等4个方向对输入样本进行平均池化,分别得到a,h,v,d平均池化通道,并将4个通道融合得到特征C传入可逆网络,如式(1)所示。在逆变换过程中,最后一个可逆模块输出特征C分成a,h,v,d四部分信息,经过哈尔小波逆变换得到重构样本Irec,如式(2)所示。
Haar(Iadv)=[a,h,v,d],C=Merge(a,h,v,d)(1)
(a,h,v,d)=split(C),Irec=IHaar(a,h,v,d)(2)
式中:Haar为哈尔小波变换;Merge为将特征通道融合;split为将通道分离;IHarr为哈尔小波逆变换。
图1展示了哈尔小波下采的过程。该方法使得下一模块获得4个方向上更加丰富的特征信息,有利于网络进一步对鲁棒特征的提取。
1.2 可逆模块通道分离
如图2所示,哈尔下采得到的特征图传入可逆模块。该模块主要由残差网络f(·)组成,负责特征的提取,模块的输入是C,输出是C′,C与C′的通道数一致,大小一致,fi(·)表示可逆模块。
正变换、逆变换如下所示:
C′=fi(C)(3)
C=fi(C′)(4)
在反传前的最后一个模块,将其特征通道划分为C1′和C2′2个部分,即
C1′,C2′=split(C′)(5)
C1′和C2′分别用于学习输入样本的低、高频信息,促进低、高频信息的有效分离。采用L2范式约束C1′和干净样本的低频特征图像ILcle,使得与C1′相关的通道学习对抗样本去除对抗扰动的低频信息,而高频与噪声信息将被编码在C2′特征通道。干净样本的低频特征图通过高斯低通滤波器获取。C1′通道特征图与ILcle的相似度损失
式中:n为样本数量;ILcle为干净样本低频特征图。
对抗样本中的对抗扰动通常以噪声信号的形式存在,高频信息对应图像的边缘、噪声以及细节部分,因此从符合干净样本数据分布的随机数中重采样替换C2′通道中的信息,从而去除对抗扰动。将采样信息D与干净的低频信息C1′融合得到C′,如式(7)所示。C′经逆变换过程重构出重构样本,使其无限接近干净样本,重构损失计算如式(8)所示。
式中:cat(·)为特征图进行通道拼接;Lrec为重构损失;N(·)为去噪防御模型LRNet,其结果为重构样本Irec;‖·‖22为L2范式。
为了进一步提升重构样本质量,本文使用预训练的VGG-16[14]网络特征提取网络,将重构样本和干净样本在VGG-16网络模型中得到的浅层特征做感知损失,感知损失计算为
式中:CjHjWj为P(·)产生的第j层特征图的大小;P(·)为VGG网络提取特征图的函数;Irec为去噪后的重构样本。Lp能使重构样本Irec获得更好的图像重建效果。
1.3 分类鲁棒特征分离
为了进一步提高重构样本分类准确率,本文设计了特征分离模块,在对抗样本转换为高、低频特征图的同时,将C1′和C2′通道特征输入特征分离模块,对分类鲁棒特征进行特征提取,如图3所示。将提取的特征变成单通道特征图F,将其融入图2中重采样特征通道D,并与去噪后的低频通道进行合并,经反变换生成重构样本。
将C1′和C2′通道进行特征提取得到的预测值p与对应正确标签做交叉熵损失,得到特征分离损失
Ls=lossBCE(p;label)(10)
通过不断学习使得分类鲁棒特征集中在特征分离模块的特征层,将其融入特征通道D用于图像重构,从而使重构样本具有较高的分类准确率。
1.4 网络整体框架
网络模型如图4所示。对抗样本进入Block i后分成C1′和C2′2个通道,C1′用于学习干净样本的低频特征信息,C2′是符合干净样本特征分布中采样的特征信息。特征分离模块用于获取鲁棒分类特征,将得到的分类鲁棒特征融合到C1′和C2′特征通道中进行重构。训练好的LRNet用作目标分类器的附加模型,对抗样本经过LRNet去除对抗扰动后,能达到正确的分类。总损失为
Ltot=αLf+βLrec+χLp+δLs(11)
式中:Lf为对抗样本C1′的特征图与干净样本低频特征图的损失;Lrec为重构样本与干净样本的重构损失;Lp为重构样本与干净样本的感知损失;Ls为特征分离损失;α、β、χ、δ分别为各类损失的权重系数。
2 实验
数据集:本文在MNIST[15]、CIFAR-10[16]、Caltech101[17]以及ISIC2018[18]等数据集验证本文所提防御模型的有效性。MNIST和CIFAR-10都是10分类图像数据集。MNIST是图片大小28×28的灰度图像,包含60 000张训练图片和10 000张测试图片。CIFAR-10是图片大小32×32的彩色RGB图像,包含50 000张训练图片和10 000张测试图片。Caltech101数据集有101个类别,每个类别由40~800张图像组成,是尺寸为300×200的彩色图像。实验中采用的攻击算法包括FGSM[19]、PGD有/无目标攻击[20]、CW攻击[21]、AutoAttack攻击[22]、DDN无目标攻击[23]以及JSMA攻击[24]。
训练细节:所有实验均在NVIDIA SMI A100 GPU上运行,由Pytorch实现。在MNIST、CIFAR-10和Caltech101上扰动的大小分别设置为εMNIST=0.3,εCIFAR-10=8/255和εCaltech101=8/255,学习率分别是ηMNIST=0.001,ηCIFAR-10=0.002和ηCaltech101=0.002。实验中MNIST使用与MagNet[25]相同的目标分类器,CIFAR-10采用ResNet18[1]作为目标分类器,Caltech101以AlexNet[26]作为目标分类器。本文实验结果皆采用目标分类器分类准确率作为防御模型防御效果的量化指标。
当前防御模型在重构过程中,重构样本的质量都远低于干净样本,从而影响重构样本的分类准确率。MNIST、CIFAR-10、Caltech101這3种数据集无攻击状态下在目标分类器上的分类准确率见表1。表中None表示干净样本在目标分类器上的分类准确率。从表1可以看出,本文所提防御模型LRNet的重构样本的分类准确率基本接近干净样本。
为了验证LRNet的防御能力及防御泛化能力,分别在MNIST、CIFAR-10、Caltech101这3种数据集中进行对抗样本防御实验。
2.1 MNIST数据集相关实验
针对MNIST数据集,在不同攻击实验下对抗样本经防御网络去除对抗扰动后在目标分类器的分类准确率如表2所示。训练阶段使用的对抗样本由FGSM、Rand-FGSM和CW攻击算法生成,扰动大小设置为ε=0.3。其余攻击算法均未参加模型训练,对模型而言是未知的。对抗防御实验中,扰动大小设置为ε=0.3,ε′=0.4。由表2可知:在JSMA攻击下,LRNet模型的防御准确率为99.39%,相较于其他模型有较大提高;在DDN攻击下以及在模型的未知对抗样本攻击下,LRNet模型的防御准确率均有所提高,防御泛化能力得到极大提升。
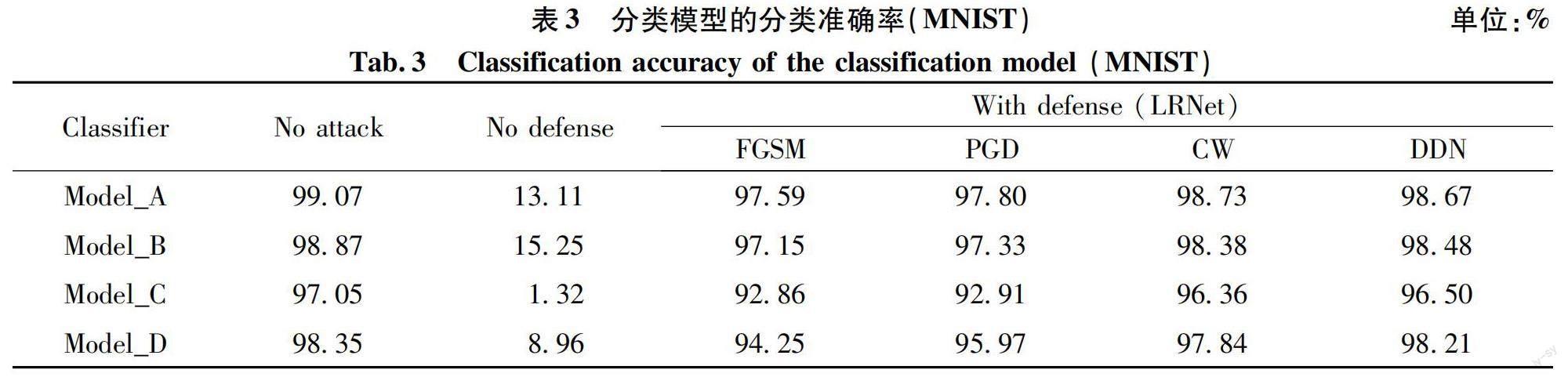
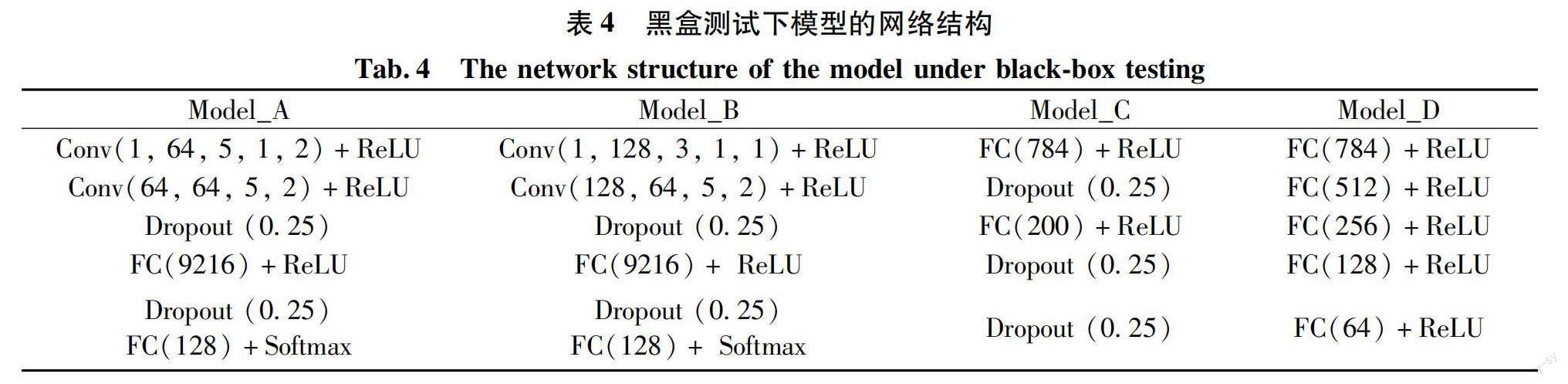
为了进一步验证LRNet在不同目标分类器上的迁移能力,本文在Model_A、Model_B、Model_C和Model_D分类器上对重构样本进行黑盒测试,分类模型的分类准确率如表3所示。No attack表示分类模型在无攻击状态下的分类准确率;No defense表示目标分类器在无防御状态下的分类准确率;With defense表示在不同对抗样本攻击下,对抗样本经防御网络重构后的分类准确率。从表3可以看出:LRNet迁移到其他分类器上仍具有较高的分类准确率,模型A的分类准确率最高,达到98%左右。模型A、B、C、D的具体网络结构如表4所示。
图5是不同攻击算法下防御网络的分类精度折线图(MNIST)。图5显示:在不同攻击实验中,LRNet模型的防御准确率保持在98%左右,在未知的对抗样本攻击测试中仍具有很强的防御能力。 LRNet不仅在常见的攻击算法攻击下保持较高的分类准确率,在JSMA、AutoAttack等强攻击算法攻击下仍保持较高的分类准确率,表明LRNet防御模型具有良好的防御泛化性。
本文使用UMAP降维技术对MNIST数据集进行簇状图可视化。MNIST干净样本的簇状图如图6所示。从图6可以看出,各类别轮廓清晰,仅有少量样本重叠。MNIST攻击前及经过防御模型得到的重构样本簇状图如图7所示。图7中,第1行是MNIST数据集在不同对抗样本攻击下的簇状图,第2行是防御后的簇状图。由图7可见,各类别防御后区分清晰,LRNet防御模型具有较强的防御能力。
2.2 CIFAR-10数据集相关实验
针对CIFAR-10数据集的对抗防御实验,训练阶段对抗样本由扰动大小为ε=8/255的PGDN和PGDT这2种攻击算法生成。测试阶段用不同攻击算法验证防御模型的防御能力。对抗防御实验中,扰动大小设置为ε=8/255,ε′=0.05,None表示对抗样本在目标分类器的分类准确率。不同防御模型在多种对抗样本攻击下的分类准确率见表5。在PGD攻击下,分类准确率有所提高。
图8是不同攻击算法下防御网络的分类精度折线图(CIFAR-10)。在CIFAR-10数据集中,LRNet防御模型得到的重构样本在目标分类器的分类准确率基本全面超越其他防御模型,表明LRNet模型具有良好的防御性能。
为验证本防御模型在CIFAR-10数据集上具有良好的迁移能力,本文训练了VGG-16和VGG-19网络,以此作为黑盒攻击测试的目标分类器。如表6所示,在不同对抗样本攻击下,经过LRNet防御后的其他目标分类器仍具有不错的分类准确率。
2.3 Caltech101数据集相关实验
针对Caltech101数据集的对抗防御实验中,训练阶段对抗样本由扰动大小ε=8/255的FGSM、L-BFGS攻击算法生成。测试扰动大小ε=8/255,在不同攻击实验下各防御模型去除对抗扰动后分类器的分类准确率见表7。在FGSM攻击下,防御准确率有所提高。实验表明,在大尺寸数据集上,LRNet防御模型仍然具有对抗防御的能力。
2.4 医学图像防御实验
本文所提防御模型不仅在自然图像上,在医学图像上也具有较强的防御能力,对一些医学诊断系统的应用提供了更加安全的保障。医学图像数据集采用7分类的ISIC2018数据集。该数据集由大小为600×450的三通道RGB图像组成,训练集有8 010张皮肤病理图像,测试集2 005张。实验采用的目标分类器是ResNet50,相关实验如下:
在不同攻击实验下对抗样本经防御网络去除对抗扰动后在目标分类器的分类准确率如表8所示。训练集采用扰动大小ε=2/255的FGSM算法生成。测试时,在FGSM,BIM,PGD,AutoAttack攻击算法攻击下,扰动大小设置为ε=2/255和ε′=6/255。由表8实验数据可知,LRNet防御模型在医学图像对抗防御下仍表现出较强的防御能力,防御泛化能力较强。
FGSM、PGD防御实验的可视化结果如图9、10所示。图9、10中,第1行表示原始干净样本Clean,第2行表示对抗样本Adv,第3行表示去噪后的重构样本Recon。FGSM、PGD攻击下的扰动大小设置为ε=6/255。
2.5 消融实验
为了验证LRNet模型特征分离模块的有效性,本文对CIFAR-10数据集进行消融实验:取消网络模型中特征分离模块,即取消了总损失函数中的Ls。在网络模型中去掉Ls时,LRNet防御模型在PGDN、DDNN、PGDN′和FGSM这4种攻击算法构造的对抗样本攻击下,平均分类准确率均有所下降,如表9所示。实验表明,特征图分离模块有利于提升模型的防御能力。
为了验证LRNet模型将特征分离为高、低频学习通道并将低频通道进行保留的有效性,本文对CIFAR-10数据集进行消融实验:将该部分通道直接作为干净样本学习通道,即取消了总损失函数中的Lf。在网络模型中去掉Lf时,LRNet防御模型在PGDN、DDNN、PGDN′和FGSM這4种攻击算法构造的对抗样本攻击下,平均分类准确率均有所下降,如表10所示。实验表明,将一部分通道作为对抗样本低频信息学习通道有利于提升模型的防御能力。
MNIST、CIFAR-10、Caltech101重構图像可视化实验如图11、12、13所示。MNIST、CIFAR-10和Caltech101数据集中,对抗样本由扰动大小分别为ε=0.30、ε=0.06和ε=0.05的FGSM攻击算法生成。由图11~13中(b)图可知,LRNet防御模型在去除对抗扰动保证高分类准确率的同时,可视质量基本接近干净样本。
2.6 模型轻量化实验
不同模型参数量大小见表11。由表11可知,LRNet模型是轻量级的,模型总参数量为12万,参数大小为0.48 MiB。在MNIST和CIFAR-10数据集中,单张对抗样本在LRNet防御模型中的去噪时间见表12。由表12可知,LRNet防御模型具有轻量化的特性。
3 结论
1)将Haar小波变换与可逆网络相结合,从多个方向提取更丰富的特征信息,实现轻量级可逆网络LRNet。LRNet能有效提高防御模型的分类准确率,提升防御模型面对不同对抗样本攻击的泛化能力。除此之外,防御模型的参数大小得到极大降低,增强了现实应用的可行性。
2)利用特征分离模块有效地分离鲁棒特征和非鲁棒特征,提升了防御模型的泛化性及迁移能力。实验表明,所提出的方法提高了分类器在对抗样本攻击下的分类精度,对模型未知的对抗样本攻击具有很强的防御能力,防御泛化能力超过了现有的防御网络,为防御算法的设计提供了新思路。
参考文献:
[1]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE Computer Society, 2016: 770-778.
[2] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[3] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[J]. Advances in Neural Information Processing Systems, 2014, 27:54-61.
[4] SUN Y, LIANG D, WANG X G, et al. Deepid3: face recognition with very deep neural networks[DB/OL]. (2015-02-03)[2023-03-28]. https://arxiv.org/abs/1502.00873.
[5] EYKHOLT K, EVTIMOV I, FERNANDES E, et al. Robust physical-world attacks on deep learning visual classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018: 1625-1634.
[6] BAI Y, ZENG Y Y, JIANG Y, et al. Improving adversarial robustness via channel-wise activation suppressing[DB/OL]. (2022-01-16)[ 2023-03-28]. https://arxiv.org/abs/2103.08307.
[7] LIAO F Z, LIANG M, DONG Y P, et al. Defense against adversarial attacks using high-level representation guided denoiser[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018: 1778-1787.
[8] JIN G Q, SHEN S W, ZHANG D M, et al. Ape-gan: adversarial perturbation elimination with gan[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton: IEEE, 2019: 3842-3846.
[9] ZHOU D W, LIU T L, HAN B, et al. Towards defending against adversarial examples via attack-invariant features[C]//International Conference on Machine Learning. New York: PMLR, 2021: 12835-12845.
[10]JACOBSEN J H, SMEULDERS A, OYALLON E. I-revnet: deep invertible networks[DB/OL]. (2018-02-20)[2023-03-28]. https://arxiv.org/abs/1802.07088.
[11]MA X J, NIU Y H, GU L, et al. Understanding adversarial attacks on deep learning based medical image ana-lysis systems[J]. Pattern Recognition, 2021, 110: 107332-107346.
[12]WANG Y W, LI Y, SHEN Z Q. Fight fire with fire: reversing skin adversarial examples by multiscale diffusive and denoising aggregation mechanism[DB/OL].(2022-08-22)[2023-03-28].https://arxiv.org/abs/2208.10373.
[13]ARDIZZONE L, L?TH C, KRUSE J, et al. Guided image generation with conditional invertible neural networks[DB/OL]. (2019-07-10)[2023-03-28]. https://arxiv.org/abs/1907.02392.
[14]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[DB/OL].(2015-04-10)[2023-03-28]. https://arxiv.org/abs/1409.1556.
[15]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[16]KRIZHEVSKY A, HINTON G. Learning multiple layers of features from tiny images[D]. Toronto: University of Tront, 2009.
[17]FEI-FEI L, FERGUS R, PERONA P. Learning generative visual models from few training examples: an incremental bayesian approach tested on 101 object categories[C]//2004 Conference on Computer Vision and Pattern Recognition Workshop. Washington, DC: IEEE, 2004: 178-186.
[18]TSCHANDL P, ROSENDAHL C, KITTLER H. The HAM10000dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions[J]. Scientific Data, 2018, 5: 180161.1-180161.9.
[19]GOODFELLOW I J, SHLENS J, SZEGEDY C. Explaining and harnessing adversarial examples[DB/OL].(2015-03-20)[2023-03-28]. https://arxiv.org/abs/1412.6572.
[20]MDRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[DB/OL]. (2019-09-04)[2023-03-28]. https://arxiv.org/abs/1706.06083.
[21]CARLINI N, WAGNER D. Towards evaluating the robustness of neural networks[C]//2017 IEEE Symposium on Security and Privacy (SP). San Jose, CA: IEEE, 2017: 39-57.
[22]CROCE F, HEIN M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks[C]//International Conference on Machine Learning. New York: PMLR, 2020: 2206-2216.
[23]RONY J, HAFEMANN L G, OLIVEIRA L S, et al. Decoupling direction and norm for efficient gradient-based L2adversarial attacks and defenses[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA: IEEE, 2019: 4322-4330.
[24]PAPERNOT N, MCDANIEL P, JHA S, et al. The limitations of deep learning in adversarial settings[C]//2016 IEEE European Symposium on Security and Privacy (EuroS&P). Saarbruecken: IEEE, 2016: 372-387.
[25]MENG D Y, CHEN H. Magnet: a two-pronged defense against adversarial examples[C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017,46: 135-147.
[26]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
(責任编辑:周晓南)
Design and Research of Adversarial Example Defense Algorithm Based on Reversible Network
YANG Jin1, LI Zhi*1, ZHANG Li1, WANG Yi1, LU Yu2
(1.School of Computer Science and Technology, GuiZhou University, Guiyang 550025, China; 2.Guizhou Power Grid Co., Ltd., GuiYang 550025, China)
Abstract: Deep learning models are extremely vulnerable to adversarial samples. In order to improve the robustness of deep learning models and enhance the security of related technologies in real-life applications, a lightweight reversible network (LRNet) is proposed to effectively remove adversarial perturbations in adversarial examples. First, Haar wavelet transform is combined with a reversible network to obtain richer features. Secondly, feature channels are separated, and high and low-frequency features of clean examples are used to guide learning. High-frequency information is replaced by resampling from random numbers to remove adversarial perturbations. Finally, a feature separation module is proposed to remove non-robust features and improve classification accuracy. The results show that this defense model can significantly improve defense accuracy. Compared with the defense model ARN, its accuracy increases from 91.62% and 67.29% to 97.65% and 78.55% on the MNIST, CIFAR-10 datasets, respectively. The parameter size of the model is reduced to 0.48 megabytes, which is 20% of the APE-GAN models. The transferability of the defense model is greatly improved, providing a new method for defending against adversarial examples.
Key words: adversarial defense; adversarial robustness; reversible networks; deep neural networks; adversarial example
