基于TextCNN 融合模型的离散情感分析
2023-09-12陈秀明
程 钢,陈秀明*,于 翔
(1.阜阳师范大学计算机与信息工程学院,安徽 阜阳;2.台州学院电子与信息工程学院,浙江 台州)
引言
文本情感分析是自然语言处理中的热门研究方向,又称作文本挖掘。它的主要工作,是对网络各种媒体消息材料、社会媒体文章,尤其是对带有情感色彩的主观性信息,进行提取、分析处理、整合和判断。
情感表达由观点持有者、评论对象、情感种类及评论时间等四要素构成。其中评论时间和文字发布时间保持一致,通常按网页发布时间来确定文章持有者与评论对象的提取通常由命名实体抽取和语义角色分析等方式在文章中获取; 而对于文字中所表达的情感种类分析,根据其目的内涵的不同而选取为不同的情感类种类,在体系上一般包括褒贬、喜怒哀乐悲恐惊、情感评分(列如1-5 分)等类型。
情感分析领域在国外已经有了十几年的历程,但是我国的研究却刚刚起步。由于语言的差异,部分国外的研究技术无法转化到中文处理中。所以,对于中文处理领域的专家们来说,如何针对中文语言的特点将某些较为娴熟的技巧与手段应用到中文情感研究领域,是一个值得积极探索的任务。
1 方法介绍
1.1 Jieba 分词与隐马尔可夫模型
Jieba 库的主要作用为分词、关键词提取、添加自定义词典和词性标注,并有精确模式、搜索引擎模式和全模式三种分词模式。
隐马尔可夫模型是一种概率转化模型, 如表1 所示:一个人换下一份工作的转换可能性[1]。

表1 隐马尔可夫模型转化举例说明
1.2 LDA 模型
LDA 主题分类法主要是用于预测文章的主题状况,LDA 认为文章可根据主题这么表示:
《美妆日记》{美妆:0.8,美食:0.1,其他:0.1}
假设我们要制作一个文本,它里边的所有单词产生的概率是[2]:
1.3 TextCNN 模型
与传统图像的CNN 网络相比,TextCNN 在网络结构上几乎没有任何变化(甚至更加简单了),TextCNN 其实是一层卷积,就是一个max-pooling,然后再把图像进行外接softmax 来n 分类[3]。
1.4 改进算法TextRCNN 模型
在TextCNN 系统中,整体网路架构使用了卷积层+池化层的架构,在RCNN 中,基于卷积层的特征提取的功能逐渐被RNN 所替代,导致整体架构设计上成为了双向的RNN+池化层架构,又称为RCNN[4-5]。
1.5 多头注意力机制
多头注意力机制即将输入数据进行多次映射,每次使用不同的作为注意力机制输入的查询,以捕捉不同的表示子空间的特征,从而可获得更全面、更富有表现力的表示结果,如图1 所示。
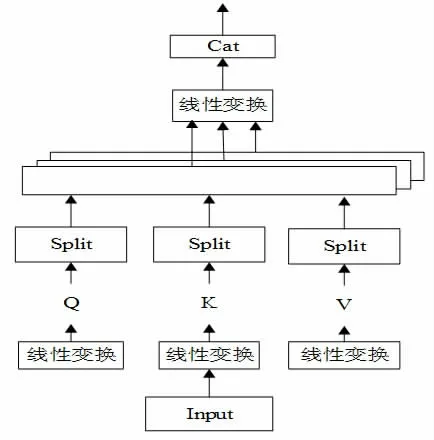
图1 多头注意力
2 实验过程
2.1 数据来源
这里使用了阿里天池上的语料库。共获取了2500 条数据,并将原来的两种情感,变为6 种情感:其中pos:开心pos1:信任neg:难受neg1:疑惑neg2:愤怒neg12:疑惑又愤怒,并将文件以纯文字文档进行保存。将其中的4/5 划分为训练数据,1/5 划分为测试数据,表2 展示的是数据具体的分布情况[6-7]。

表2 数据分布情况
2.2 数据预处理
去除数字,字母,分词,去除停用词。由于数据集的内容经常会出现一些非中文与不用的字符以及标点符号等[8]。文本数据预处理后结果如表3 所示。
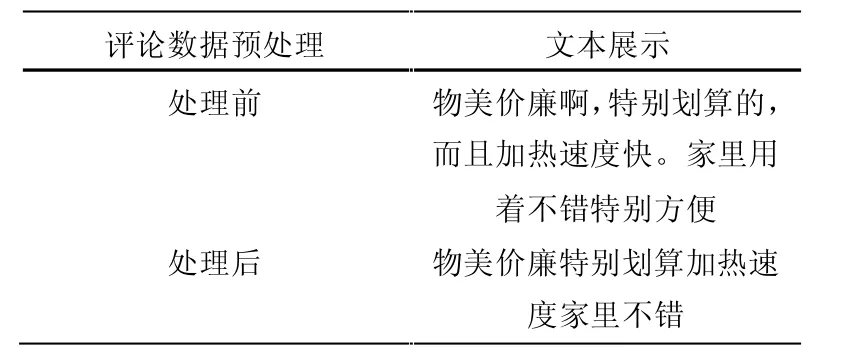
表3 数据预处理展示
2.3 举例说明构建开心和疑惑又愤怒的情感的词云图[6]
快乐情感词云见图2,疑惑又愤怒词云见图3。

图2 快乐情感词云

图3 疑惑又愤怒词云
2.4 从每种情感的词云图中挖掘主题
各种情感的主体见表4。

表4 各种情感的主题
通过对比:开心的主题是价格和快递方面,信赖的主题是物流价格与产品不错,难受的主要主题是售后没有免费,只免费了材料费,疑惑的主要主题是售后的态度比较差,愤怒的主要主题是安装费,愤怒疑惑混合的主要主题是安装收费这方面,因为这种情绪最为强烈,所以这种情感反应的问题也是最急切的。
2.5 实验依据
采用分类精确率precision、召回率recall、平衡F分数f1-score 作为评价实验好坏的指标,其表示方法如下:TP:将正类预测为正类数;TN:将负类预测为负类数;FP:将负类预测为正类数误报;FN:将正类预测为负类数,如下依次表示为精确率P,召回率R,平衡F分数F1[9-10]。
2.6 实验结果
TextCNN 各情感效果对比见表5,TextRCNN 各情感效果对比见表6,TextRCNN-Attention 各情感效果对比见表7。

表5 TextCNN 各情感效果对比
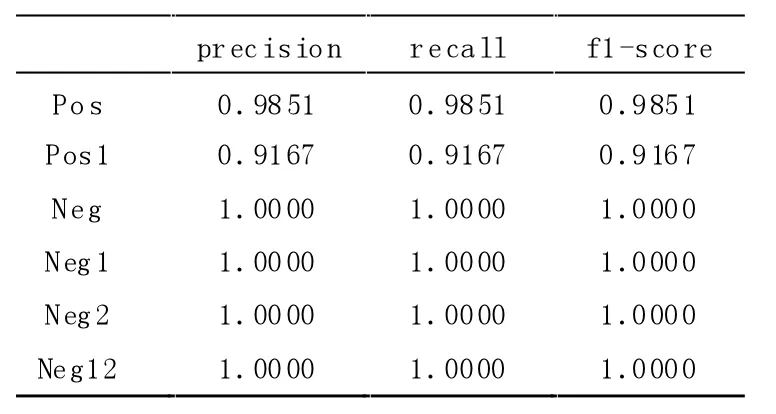
表6 TextRCNN 各情感效果对比

表7 TextRCNN-Attention 各情感效果对比
通过观察TextRCNN-Attention 的预测效果较好。
结束语
为了数据背后的故事,对文本做情感分析是一种可行的方式,但它还是不能完全挖掘数据背后的故事。我国汉字博大精深,一词能代表许多的意思,它涉及对词汇、句法和语义规则的深刻理解,所以对情感的准确分析还有很长的一段路要走。在大数据背景下,自然语言的广度和复杂度得到进一步的发展,同时也带来了更大的挑战,其发展仍需要很长一段时间,望砥砺前行。
