基于深度卷积特征重构的井漏事故预测
2023-09-04李盛阳
罗 鸣,李盛阳,彭 巍,周 壮
(1. 中海石油(中国)有限公司湛江分公司,广东 湛江 524000;2. 中国科学院空间应用工程与技术中心,北京 100094)
1 引言
海上石油钻井井漏事故可造成资金、时间的巨大浪费和海洋的破坏性污染[1]。如何在井漏事故的前期或早期,给出线索性价值的警示或预警,对于预防和控制事故的发生和发展,确保油气资源的安全开发具有重要的价值与应用意义。
为了降低钻井事故危害,研究人员从异常检测模型角度,提出并使用相关数学模型,旨在检测钻井过程中数据异常征兆等以实现事故预测。异常检测常用的方法可以分为以下四类:基于近邻的方法[2]、基于聚类的方法[3]、基于统计的方法[4]、基于分类的方法[5]。
基于近邻的方法通过计算自身数据与相邻节点数据之间的距离来确定自身数据是否异常,如果某个数据与邻居节点采集的数据存在较大差异则称为异常数据[6]。由于该方法计算每个数据之间的距离会花费较长的时间,因此难以面向海上石油钻井大规模、长时序的监测数据开展应用。
基于聚类的方法通过对数据分簇来孤立异常数据,但此方法需要在得到全部数据后再进行分簇,不能在线式地检测异常数据。因此该方法更多用于事故的事后验证与分析,无法满足海上石油钻井事故预测的实际应用需求[7,8]。
基于统计的方法是利用历史数据分布,建立数据的统计模型,不符合该模型的数据视为异常数据[9-11]。由于海上石油钻井监测参量维度大,基于统计的方法难以面向大规模数据集合建立较准确的统计模型,方法应用受限。
基于分类的方法通过历史数据训练得到一个模型,再将待检测数据分类到所属类别,不属于任何类型的数据视为异常。其中,自动编码器[12]、OCSVM[13]等为代表的单类分类方法通过训练学习正常模式的数据,寻求区分正常与异常数据的模型,已成为当前钻井事故预测领域最常用的方法。然而,上述常规方法在应对复杂多变的实际工程环境时,可靠性无法保证,难以实现精确、有效的事故预测。
近年来,以LSTM[14,15]、卷积神经网络[16,17]等为代表的深度学习方法在异常检测与事故预测领域得到越来越广泛的关注。其中,LSTM通过预测时序数据,并基于预测值与实际值的差值实现异常区间的判别,适合用于处理与时间序列高度相关的问题。而卷积神经网络将异常检测看作分类问题,与常规分类方法相比,卷积网络通过多层级非线性操作,将原空间的特征表示不断变换到新的特征空间,通过逐层提取过程,自动学习得到数据更本质、抽象的特征,以提高区分异常征兆的准确度。
海上石油钻井工程实施过程,需要作业人员机动性地进行钻具调换、停钻、井壁修整等不同工序操作,上述人为干预的工况切换会导致各监测数据在数值上出现不规律跳变,整体时序呈现高动态、非周期性。钻井监测数据无规律的时序模式使得以LSTM为代表的算法预测值与实际值总体偏差过大,无法精确检测出与事故关联的异常,因此LSTM等时序预测类方法难以适用,目前该领域还未见深度学习相关技术的应用。鉴于此,本文以我国南海乐东10-1油田井区为研究区,基于多源录井时序监测传感器数据,开展数据预处理与井漏事故关联分析,设计搭建深度卷积特征重构网络,训练学习正常工况的特征变化模式,并以此为基准分析计算待检测数据的重构特征误差,以捕捉井漏事故发生前的异常征兆,探索海上石油钻井井漏事故预测的可行性。
2 实验数据
2.1 录井时序监测数据
海上石油录井监测参数包括钻头的传感器参数,如:钻头深度、井眼深度、大勾悬重、泵压、机械钻速等,以及钻井液的出入口密度、出入口温度、流量、体积等。其中钻井液参数变化通常直接反映井下地层流体的活跃情况及井筒压力与地层压力的平衡情况。
本文实验数据来自乐东10-1油田多个钻井的实测数据,包括有效监测参数共计20个,数据类型介绍见表1.
2.2 样本数据集
根据乐东10-1油田钻井监测数据记录,截取1口无事故和6口包含井漏事故的钻井监测序列数据,完成清洗、筛选、重采样、平滑等预处理,处理后的数据采样间隔为0.5分钟,进一步根据各钻井的工作日志标注事故发生的起止点位。构建的样本数据集用于算法的模型训练和验证评价,样本数据列表见表2,参量时序变化曲线示例见图1.
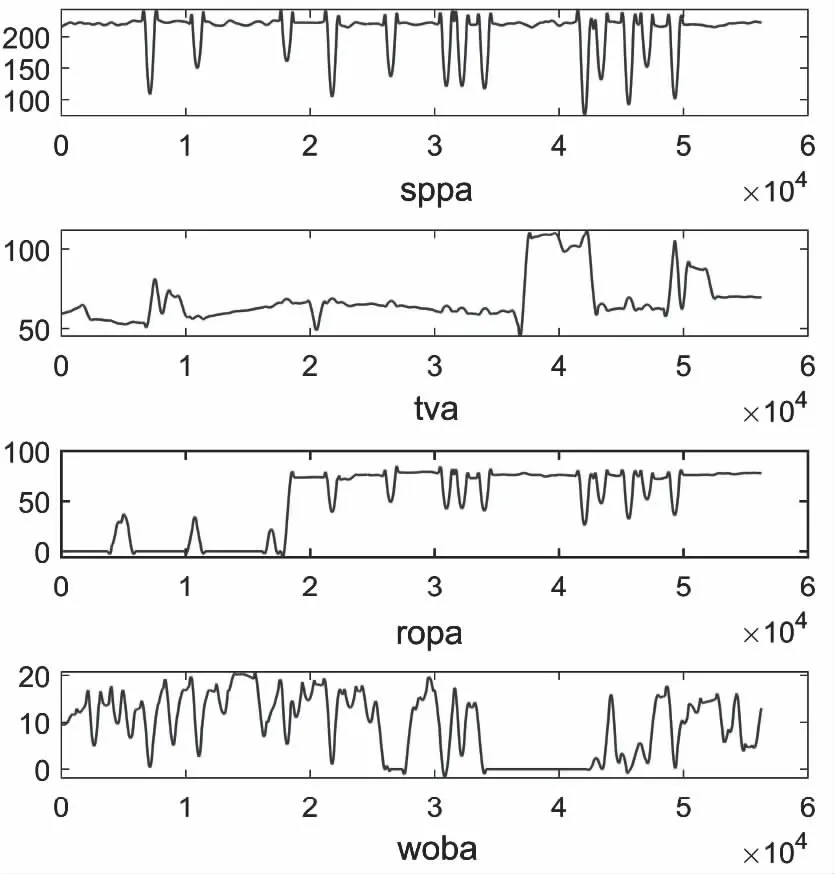
图1 时序录井监测参数示例(ld10-xx-7)
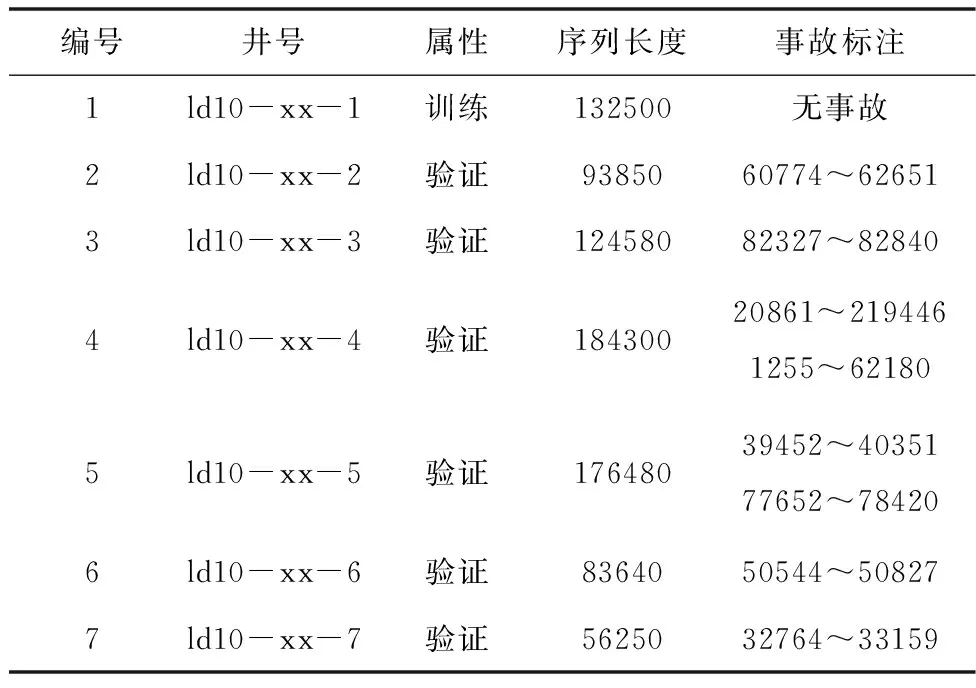
表2 样本数据列表
3 研究方法
本文针对构建的录井监测样本数据,首先开展基于ReliefF的特征权重计算,优选事故关键因子,通过滑窗内积计算能反映时序关联耦合特性的特征矩阵。设计并搭建深度卷积重构网络,基于无事故的钻井数据训练模型以获取正常工况数据分布模式与规律。利用训练后的网络模型对验证数据进行特征重构,并基于重构误差开展事故前异常征兆的检测,从而实现井漏事故预测,并与自动编码器方法开展验证对比与分析。图2为本文总体技术流程图。
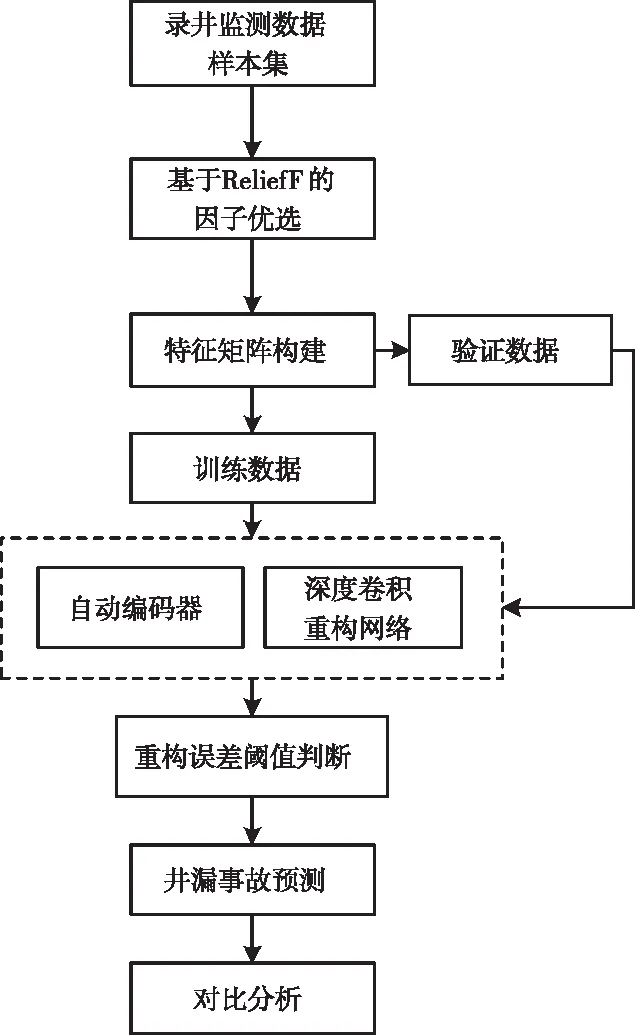
图2 技术流程图
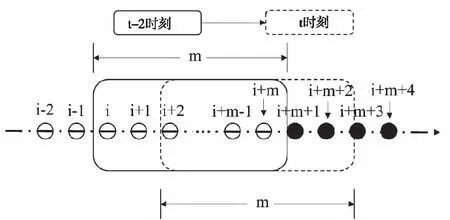
图3 滑动窗口模型
3.1 基于ReliefF的因子优选
综合利用多类录井监测参数作为事故预测算法输入,能够丰富特征信息量,但过多的特征输入意味着加入了与事故相关性较弱的参量,难以避免地存在互相关性较高的冗余特征,增加算法计算复杂度并影响精度。鉴于此,在事故预测时对已有参量进行筛选,获取优选参量因子,能够通过特征降维提升算法性能。
ReliefF是一种常见的多类别特征选择算法,基于特征对近距离样本的区分能力计算样本和特征的相关性,依据各个特征与类别的相关性赋予每个特征权重[17]。特征的权重大小代表了该特征分类能力的强弱,权重越大意味着分类能力越强,权重越小则分类能力越弱。算法每次从训练样本集中随机抽取一个样本,先从同类样本集中选择k个近邻样本,再从每个不同类样本集中选择k个近邻样本,从而将每个特征的权重更新。权重计算公式如下
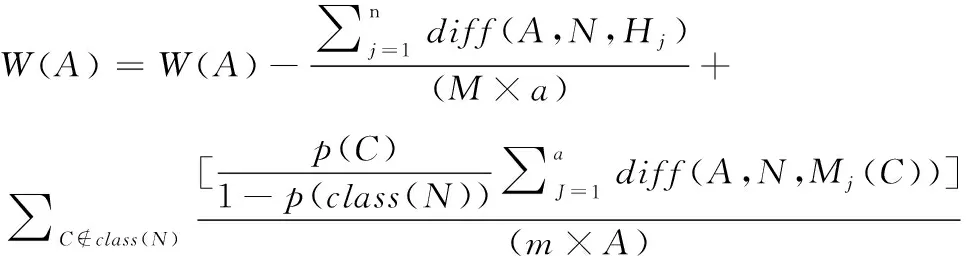
(1)
式中,diff(A,N,Hj)表示样本N和Hj在特征A上的差,diff(A,N,Mj(C))表示样本N和Mj(C)在特征A上的差,Mj(C)表示类C∉class(N)中第j个最近邻样本。
3.2 特征矩阵构建
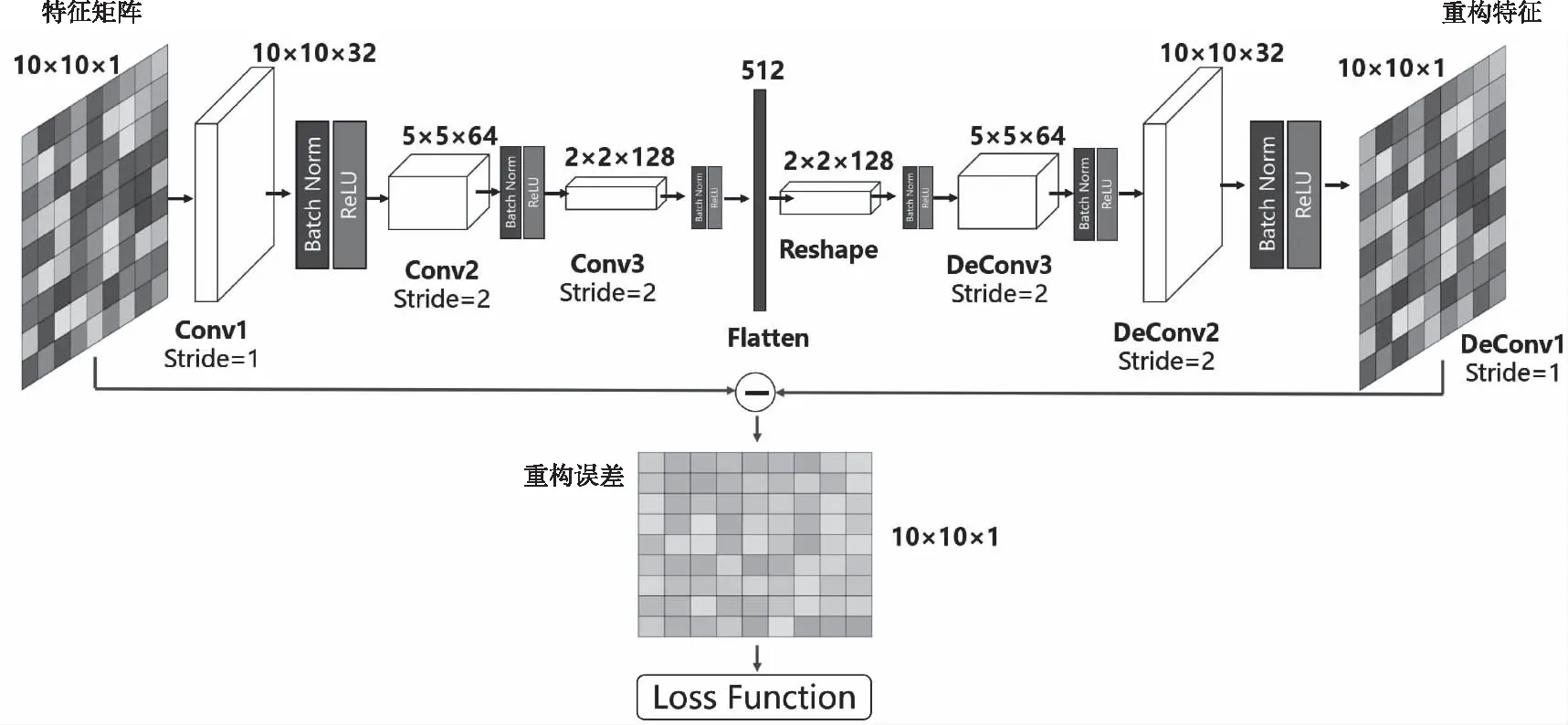
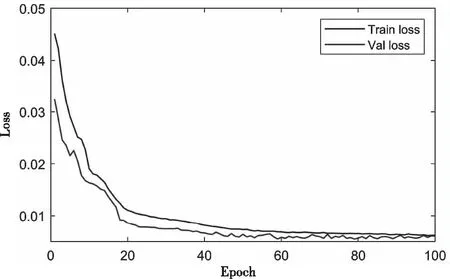
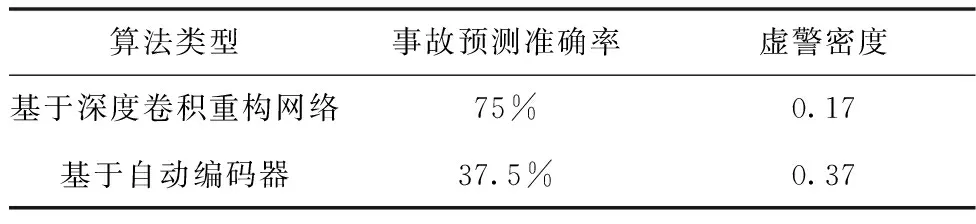
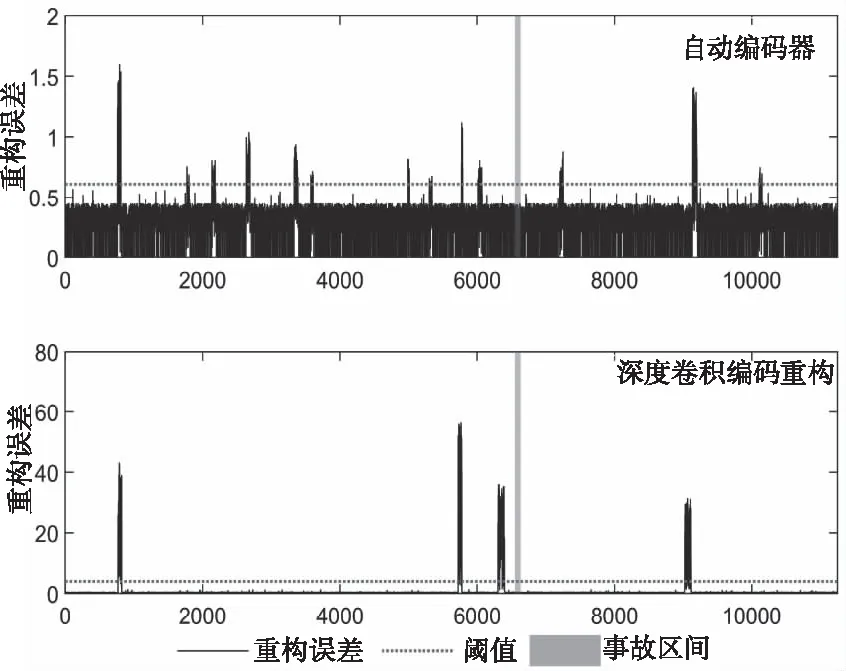
为了强化事故关键参量间的时序变化和关联耦合信息,最大化突出事故异常征兆的特性,本文构造特征矩阵作为事故预测算法的输入。对于长度为T,包含n个特征的时间序列数据,在一个时间点t(t (2) 本文设计的多层级卷积重构网络类似自动编码器,通过对输入的特征矩阵进行卷积运算,将录井监测数据映射到隐层空间,然后利用反卷积操作对隐层空间的特征进行解码,获取输入的重构特征。基于重构样本与输入特征矩阵的误差实现事故征兆异常的检测。本文搭建的深度卷积重构网络结构图见图4. 图4 模型结构 1) 输入层和输出层: 深度卷积重构网络采用端到端的学习方式,输入与输出尺寸大小一致,网络的隐含层对输入的特征矩阵进行学习,输出层采用残差学习的方法得到重构的特征矩阵。在模型训练过程中,输出层得到重构矩阵后将进行损失函数计算,并基于损失评估结果确定合理的参数优化模型权重。 2) 卷积层和反卷积层: 由于输入的特征矩阵尺寸较小,对于过深的网络特征图经过多次卷积运算会缩小至无法在网络中传输,而当网络映射层级过少时难以提取深层、本质的特征。基于此,本文搭建的网络由3层卷积层和3层反卷积层组成,并在各层中使用Batch normalization和Relu激活函数,使网络能够更好的收敛。 通过卷积层,从原始特征矩阵或上一层卷积结果提取当级输出特征,以此捕捉时序数据中各特征间的关系。通过反卷积层,对卷积输出特征逐级重建,得到输入的重构特征。为了保证各层级对应的卷积-反卷积输出特征尺寸一致,对第三层卷积输出特征进行向量化拉伸,并基于相同维度进行特征矩阵变换处理。 3) 损失函数: 该网络的损失函数设定为输入特征矩阵重构误差的2范数 (3) 为了加速训练过程,采用mini-batch随机梯度下降和Adam optimizer最小化误差损失。基于无事故数据训练后的网络,可学习到正常工作条件下各关键参量变化特性和关联耦合规律。在测试阶段,网络对输入特征矩阵计算重构误差,对mini-batch的误差集进行均值计算,对于超出均值的部分判断为事故征兆异常,进而实现事故预测。 海上石油钻井井漏事故预测结果的实验验证,需要从以下三个方面评价有效性: 1) 预测有效期: 算法输出的预测结果必须在实际事故发生时刻之前的有限时间内才有效,即样本数据中标注的历次事故起始节点前的有限序列范围内。 2) 虚警可控: 算法输出的预测节点在事故标注之后,或距离事故发生节点之前过长均应判断为虚警。鉴于钻井工况实际的复杂性,虚警难以完全避免,但算法对应的虚警频次应总体可控。 3) 时间窗预警统计: 井漏事故的异常征兆包含突变异常和阶段持续异常,算法在特定时间窗内若多次预警应针对的是同一事故。因此,需以时间窗统计预警次数,即时间窗口内的多次预警仅记一次。 综合上述条件,通用的验证指标如准确率、精准率、召回率、ROC等并不适用海上石油钻井事故预测的应用场景,无法真实、客观评价算法的有效性。因此,本文定义事故预测准确率和虚警密度作为算法验证评价指标 (4) (5) 其中,P表示事故预测准确率,Countaccident表示验证数据中井漏事故出现的总次数,Countperiod表示算法在历次事故前有效期内准确预测的总次数。根据海上石油钻井实际工程经验,本文定义事故预测有效期序列长度为500,约4小时。仅有效期内的预测结果参与统计准确率,其余为虚警。事故预测准确率越高,说明算法结果越精准。 Fdensity表示虚警密度,Length表示验证数据序列总长度,Countwindow表示序列中基于时间窗口统计的虚警次数,本文约定统计时间窗口长度为500,2880表示钻井天数与序列长度转换因子。该指标表示平均一天的虚警次数,反映了算法整体的虚警情况,虚警密度越低,说明算法结果中与事故无关联的预警越少。 基于事故预测准确率和虚警密度,可综合评价算法在海上石油录井数据集中的性能表现,且不受不同钻井时序长度等差异的影响,客观反映事故预测算法的有效性。 本文定义样本数据集中井漏事故阶段和无事故阶段为不同类别,通过ReliefF算法基于录井监测参量对近距离样本的区分能力计算相关性,并依据相关性赋予各监测参量不同的权重。权重越高说明监测参量对事故的区分性更强,权重越低则意味对事故的区分能力弱,以此可实现井漏事故关键因子的优选。 实验基于ReliefF算法对样本数据集中的20类监测参量进行特征贡献值计算,并排序获取前10类参量作为优选后的因子,包括:返出流量(mfoa)、返出流量比(mfop)、计量罐体积(tva)、泵冲(spm)、钻压(woba)、机械钻速(ropa)、泵压(sppa)入口流量(mfia)、悬重(hkla)、出口泥浆密度(mdoa)。 海上石油钻井井漏事故的成因主要在于地层结构存在缺陷,特别是孔隙、裂缝或洞穴等,导致钻井液相关参量出现异常,进而出现泵排出口压力降低等。结合井漏事故先验知识,本实验基于ReliefF优选的参量涵盖了返出流量、计量罐体积、入口流量等钻井液相关参量,以及泵压等关键因子,实验优选的因子具有可信度,说明本文选取ReliefF算法作为特征优选方法具有可靠性,有效去除输入参量的冗余特征,降低后续算法的运算复杂度,为提升事故预测性能提供必要性基础。 本实验在Tensorflow平台下搭建完成深度卷积特征重构网络,并通过Python Scikit-learn库实现基于自动编码器的事故预测对比方法。实验环境为1台服务器,配置为Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz,NVIDIA Titan RTX GPU. 两种方法均以无事故的ld10-xx-1井作为训练数据,提取上述10类优选后的监测参量为原始特征,并以窗口大小为10,滑动步长为5进行特征矩阵的构建。对构建的序列特征矩阵按照8:2的比例划分为训练集和测试集,用于算法模型的训练和训练阶段模型的损失评估。其它6口钻井以相同方式构建序列特征矩阵,作为独立的样本开展算法精度验证。 其中,深度卷积特征重构网络在学习率为0.001的条件下,经过100次epoch迭代完成模型训练,训练集和测试集的模型损失变化曲线见图5。 图5 模型训练损失曲线图 在实验验证阶段,基于3.4节定义的事故预测准确率和虚警率,分别统计深度卷积重构网络和自动编码器的结果表现,见表3。 表3 验证评价对比 标注的验证数据集中共记录了8次井漏事故,以事故起始点前500个序列作为预测有效期,算法在该阶段给出预警则说明算法结果有效。本文所提基于深度卷积重构网络算法,在8次井漏事故中准确预判了6次事故,事故预测准确率为75%。而常规基于自动编码器的方法仅准确预判断出3次井漏事故,事故预测准确率为37.5%。 由于海上石油钻井工程持续时间一般较长,且不同钻井间工程时长差异较大,从数天到数年不等,因此虚警的绝对数量值并无实用意义,对于稳定的算法,虚警数量随验证数据时序长度的增加而增加。因此相比虚警数量,虚警密度指标能够更为客观反映算法表现。本文所提算法虚警密度为0.17,反映算法平均约5.8天(=1/0.17)误报预警一次,其指标优于基于自动编码器算法的0.37。本文所提算法在虚警频次上整体可控,具备指导实际钻井工程的可行性。 为进一步分析算法在钻井监测序列数据中的具体表现,本文以ld10-xx-7钻井为例,可视化深度卷积重构网络和自动编码器特征重构误差的时序变化曲线,结果见图6。 图6 ld10-xx-7钻井事故测试结果 从图中可以看出,基于深度卷积特征重构的算法中,重构误差超出阈值的部分出现多次。根据本文3.4节所定义的预警次数统计方式,在ld10-xx-7钻井中算法共计预警了4次,并且预警阶段的重构误差在数值上远高于其它阶段,数值的区分特性明显。结合事故预测有效期,本文所提算法4次预警结果中有效预测为1次,虚警为3次。考虑实际钻井过程中,事故异常征兆阶段,作业人员会基于专家经验进行人工避障等操作处理,使得事故未必一定发生,因此事故虚警在某种程度是不可避免的。相比较虚警,算法对实际生产作业的指导意义更在于是否能有效预测即将发生的事故。 相比本文所提算法,基于自动编码器的重构误差超出阈值的部分呈分散、高频分布,基于时间窗统计算法共预警13次,且事故有效期前未给出准确预测,算法对ld10-xx-7钻井失效。 结合样本集整体验证评价结果和具体的钻井可视化分析,表明本文构建的深度卷积重构网络效果优于常规自动编码器的方法,分析原因在于,本文通过对事故关键因子进行滑窗内积计算所构建的特征矩阵,其数值分布上表征了参数的时序变化和关联耦合特性,通过多层级卷积特征提取和重构,可挖掘深层次、抽象、本质的特征规律。此外,网络中二维卷积滤波器可以捕捉矩阵中因参数间联动、滞后性变化导致的异常偏移。而常规自动编码器将构建的输入特征矩阵拉伸为一维向量进行数值特征提取,其本身特征学习的难度更高,且网络层级浅,难以全面捕捉正常工况下复杂多样的监测数据表征规律,导致事故预测效果较差。 考虑实际海上石油钻井工程的应用条件,作业工况和底层地质结构存在较大的模糊性和随机性,本文所提方法在其它钻井的测试表现中,算法结果对应预测的提前时间、异常征兆的剧烈程度、事故预测的频次等均存在差异性,但总体具备较好的预测表现。受限海上石油钻井井漏事故的稀缺性,难以大规模标注充分的验证样本以开展更广泛的算法验证与分析,本研究目前仅面向乐东10-1油田中代表性钻井进行应用与验证工作,针对性的分析评价所提方法性能表现。 本文面向海上石油钻井事故风险预警需求,开展基于深度卷积特征重构的井漏事故预测方法研究。论文首先基于乐东10-1油田钻井构建的样本数据集,开展基于ReliefF算法的特征分析与权重评价,优选与井漏事故关联程度较大的监测参量。进一步构建时序特征矩阵,强化优选参量的关联耦合与时序变化特性。设计并搭建多层级卷积特征重构网络,训练学习正常状态下时序特征矩阵的深层、抽象特征,在验证阶段以网络重构误差为依据实现井漏事故前异常征兆的检测。最后结合海上石油钻井工程场景与实际需求,设计验证评价指标,开展算法对比验证与分析。结论主要如下: 1) 基于ReliefF算法对数据集开展近距离样本的相关性计算,可优选出井漏事故关键参量,且优选结果与事故致因分析关联性强,可为事故关键特征筛选、数据降维等提供技术支持。 2) 深度卷积特征重构网络可学习正常数据模式的表征规律,并基于重构误差捕捉井漏事故的征兆异常。通过事故预测准确率、虚警密度等验证,所提算法能有效预测井漏事故,且精度指标等优于常规自动编码器等算法。 本文提出的基于深度卷积特征重构方法,探索实现了海上石油井漏事故的有效预测,为钻井工程作业提供风险评估指导,对保障安全、高效的开展海洋钻井平台作业具有重要的应用价值,且方法具有一定的可推广性。 本文所提算法属于半监督学习,其监督信号仅有正常作业下的录井监测数据特征表现,由于海上石油钻井外部环境的复杂性,不同区域对应的地层结构、油气分布等差异较大,算法训练模型在不同区域钻井间的可迁移性有待进一步检验。此外,当前算法还不具备区别不同事故类型的征兆异常,理论上难以面向更精细的如井涌、井控等多类型事故进行针对性的预测,如何针对异常征兆进行划分是本研究后续的工作方向,以更好的满足海上石油钻井工程作业生产指导的信息服务。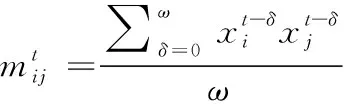
3.3 深度卷积重构网络
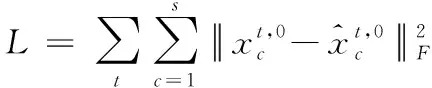
3.4 验证评价
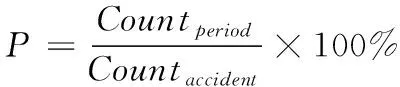
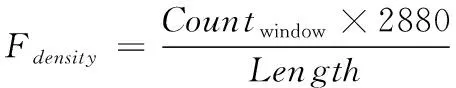
4 结果与分析
4.1 井漏事故因子优选
4.2 井漏事故预测
4.3 实验结果分析
5 结论
