基于元学习的双目深度估计在线适应算法
2023-08-04张振宇
张振宇 杨 健
深度估计是视觉场景理解中的基础性问题,并且越来越多地受到计算机视觉和机器人研究领域的关注.近年来,一些基于深度学习的RGB 自动深度估计方法陆续提出,取得了令人印象深刻的效果[1-7].在这些研究工作中,深度神经网络模型的训练需要依赖深度真值作为监督信息,可供训练的深度真值越多则效果越好.然而,在现实场景中进行数据收集需要对应的硬件平台和设备(例如汽车和雷达),且使其在不同环境中工作相当长的时间.因此,数据收集通常需要昂贵的财力和时间开销,这制约了以上监督学习方法的实际应用.为了避免开销较大的数据收集和人工标注过程,一些自监督(也称为无监督)深度估计方法相继提出[8-11].值得一提的是,尽管没有精确的深度真值,这些方法仍能通过图像重构误差训练模型,获得与监督学习方法接近的结果.
尽管上文提到的自监督方法获得了相当好的结果,其在现实场景中的使用仍然受到制约.原因在于这些方法均在封闭世界假设下进行设计和评估,这意味着训练和测试数据处于同一个数据集,或者二者的环境表观差异很小.当模型在全新的场景中工作时,由于数据域转移的影响,方法的结果将大打折扣.因此,为了增强方法的实际应用效果,用于深度估计的深度神经网络模型需要考量开放世界的设定,即可用的视觉数据是在连续变化的环境中被采集的数据流.以自动驾驶场景为例,模型需要连续适应于变化的环境(如城市、乡村和高速公路场景等)以及光线场景(如黑夜、黄昏和白昼等).也就是说,深度神经网络模型需要具有在线适应的能力.
根据以上的分析和动机,本文提出了一种基于元学习的双目深度估计方法,用于需要快速在线适应的开放世界场景.方法的框架在图1 中展示.首先,一种新的在线元学习适应算法(Online metalearning with adaptation,OMLA)得以提出,用于模型的快速在线学习.具体地,为了处理源域数据(即训练数据)和目标视频数据之间的域转移问题,模型通过调整源域和目标域的批归一化(Batch normalization,BN)层统计量,使域间特征分布对齐.该方法受启发于文献[12-13],本文对其进行改进,使该方法适用于在线学习场景.然后,特征对齐过程与元学习算法相结合,利用先前时刻的模型反馈选择能够快速适应未来场景的网络超参数.此外,本文提出了一种新的基于元学习的预训练方法(元预训练).具体地,在使用OMLA 算法进行一段视频的在线适应过程后,模型评估其在未来帧上的表现,并以此为反馈更新初始参数.由此,模型获得了适用于OMLA 算法进行快速在线学习的初始参数.
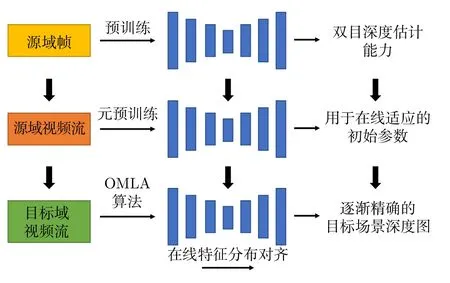
图1 本文提出的基于元学习的深度估计在线适应算法框架Fig.1 The proposed meta-learning framework for online stereo adaptation
本文的主要贡献总结如下: 1) 提出了一种新的基于元学习的在线适应算法,用于在线视频流的双目深度估计.该方法与特征对齐过程相辅相成: 元学习算法有助于更新特征对齐动量以提升模型的适应能力;特征对齐则更好地支持元学习算法进行优化过程的快速收敛.2) 提出了一种基于元学习的预训练方法,利用OMLA 算法使模型获得适用于快速在线学习和收敛的参数以及特征对齐动量.3) 在KITTI 数据集[14]上的实验表明,本文提出的OMLA 算法与预训练方法均有助于在线深度估计效果的提升,其效果超越了当前最佳的在线深度估计适应算法[15].
1 相关工作
1.1 深度估计
随着深度卷积神经网络的发展,近年来涌现了许多基于监督学习的深度估计方法[1-4,16-17],这些方法需要依赖深度真值训练网络模型.一些大规模数据集,例如NYU[18]、KITTI[14,19]等为深度估计任务提供了支持,一些合成数据库的提出(例如Synthia[20])使得深度估计的迁移学习成为可能.
为了避免耗费较高的数据收集和标注过程,自监督的深度估计方法[8-10]得以陆续提出.例如,Godard 等[9]利用双目一致性损失函数使自监督训练成为可能.其他相关工作主要包括结合相机位姿估计的方法[21]、利用对抗学习的方法[10,22]、基于视觉里程计的方法[17]以及结合图像超分辨的技术[11].最新的研究主要关注高效深度估计网络的设计[6]和雷达点云的补全[7].然而,以上方法仅适用于封闭世界设定下的深度估计,缺少对开放世界问题的研究.
1.2 域适应问题
域适应是经典的机器学习问题,近年来逐渐为计算机视觉和机器人领域所关注[23].近期基于深度学习的方法主要通过以下策略减轻域转移造成的影响: 分布对齐损失函数[24-25]、对抗生成网络[26-28]和域对齐层[13,29-31].在机器人领域,域适应方法主要用于机器人抓握[12,27]、可行驶区域分割[31]以及基于目标定位的机器人控制问题[32-33].
与绝大多数先前工作采用离线设定(即源域与目标域数据在训练过程中是可以全部获取的)不同的是,近期一些域适应算法开始研究在线学习设定下的问题,即目标域数据以序列化形式获得且其分布不断改变,相关工作如文献[12,30-31].一些工作研究了针对深度估计问题的域适应方法[32-35].Tonioni 等[15]首先利用在线数据流进行了相关尝试.文献[35]利用元学习方法增强了深度估计模型的在线收敛速度.然而,以上两种在线深度估计方法并未清晰地对域转移进行建模,也未使用任何策略以减弱源域和目标域数据差别带来的影响.与其不同的是,本文方法具体地讨论了在线深度估计中的域转移问题,并给出了合理且新颖的解决方案.
1.3 元学习算法
元学习的目标是使模型利用先前学习的经验,学会如何在未来的问题中进行高质量学习.在文献[36-39] 中,元学习被用于获得在新数据域和类别上的快速泛化能力.在迁移学习应用中,文献[38]利用元学习方法,使主网络模型引导学生网络合理地微调参数.Park 等在文献[39] 中提出了一种离线元学习方法,使网络获得较好的在线跟踪能力.本文方法受启发于文献[39],与其不同的是,本文方法提出了适用于在线场景的元学习方法,在引导模型获得合理初值的同时,使模型在线学习超参数以加速收敛.
2 基于元学习的深度估计在线适应方法
本节详细介绍了本文提出的基于元学习的在线深度估计与适应方法.为方便形式化讨论,假定源域是由N个双目视频序列组成的数据集,这些数据集使用同一个经标定后的双目相机采集.首先,使用该源域数据集训练参数为θ的神经网络模型 Φ,使模型获得双目深度估计能力.然后,模型需要在目标域视频VT上进行预测,该视频由不同的双目相机在新的环境中采集,且视频帧为数据流形式.本文方法的目标是在线调整网络参数θ(即在线适应),使其在目标域连续变化的视频中逐渐获得更精确的场景深度图.
一种基本的用于在线适应的方法为: 在当前时刻计算当前帧的自监督损失,并通过梯度下降更新整个网络参数.尽管这种方法非常简洁,但其存在明显的缺点,如其对于域转移是非常敏感的,且仅关注于当前帧的做法可能会对模型更新过程带来不良影响,例如场景突变导致的模型漂移会减缓收敛速度.为了避免这些问题,本节提出了两种互补策略: 特征分布对齐和在线元学习适应算法(见图2).具体地,使用批归一化层的统计量对域转移进行建模,并以此为基础进行源域和目标域的特征分布对齐(见第2.1 节).该过程在前馈中的网络浅层进行,仅需要非常有限的计算开销.此外,使用基于元学习的优化器更新模型,使模型获得对未来帧的快速收敛能力(见第2.2 节).由此,在在线适应过程中,特征对齐能够应对不同域数据的表观特征差异,元学习优化器则可处理高阶表征的转移问题.此外,基于元学习的预训练策略被用于获得模型初始参数θ0,使模型获得针对数据流的快速适应能力(见第2.3 节).训练和更新模型使用的自监督深度估计损失函数在第2.4 节中介绍.
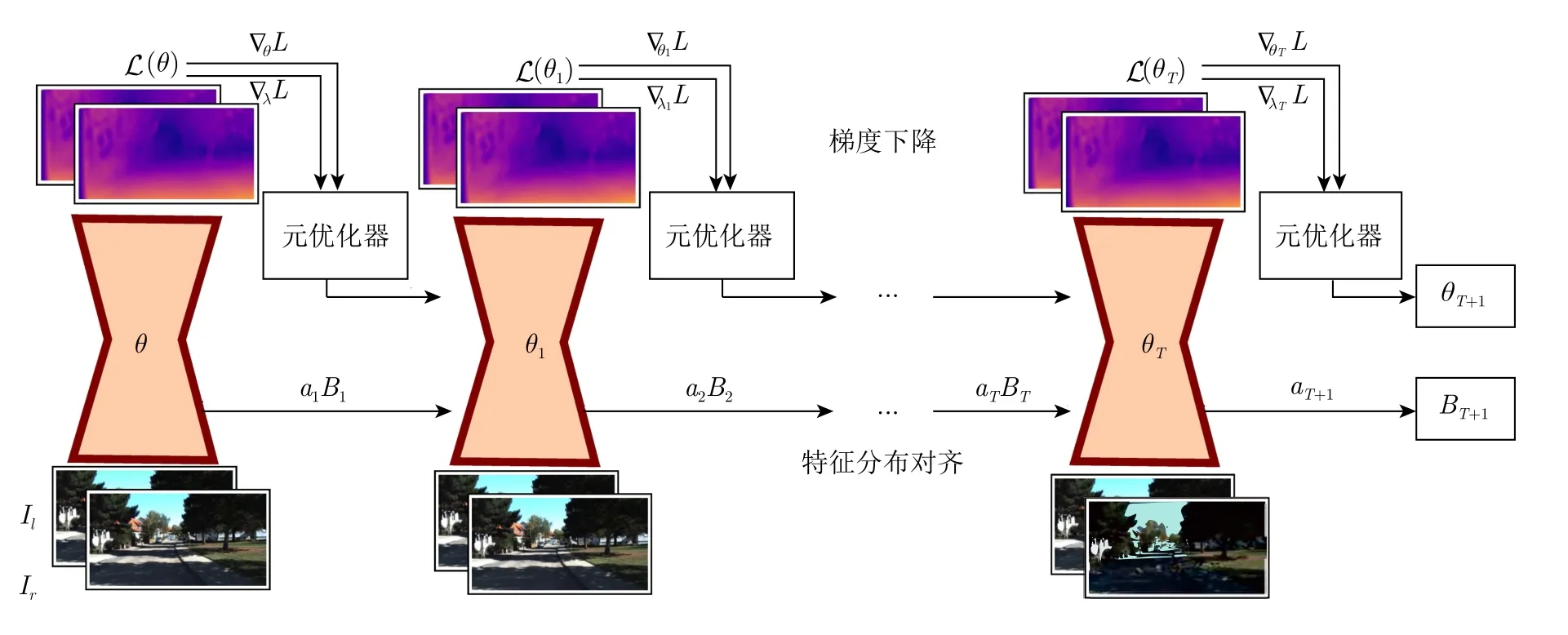
图2 本文提出的在线元学习适应方法Fig.2 The proposed online meta-learning with adaptation (OMLA) method
2.1 在线特征分布对齐的域适应算法
考虑一个包含批归一化层的神经网络模型 Φ,根据文献[12-13,30]的研究,域适应可以通过更新BN 层统计量实现.在本文问题设定下,模型无法获得全部目标域数据以计算真实的目标域统计量,但是由于数据流的存在,可以随时间渐进地更新统计量使其逼近真实值.受此启发,本文提出一种针对BN 统计量的在线更新策略,通过目标域数据流逐渐更新BN 统计量,使目标域模型特征分布逐渐对齐.与文献[13,30] 的封闭世界方法不同的是,本文方法无需目标域的全部数据,适用于数据流可用的开放世界问题.为简洁起见,此处仅讨论单个BN 层的情况,但相关操作可部署至网络任意BN 层.首先,模型在源域S进行训练后,可以获得对应的BN 层统计量Bs(µs,).然后,模型按照以下过程在目标域视频流中更新统计量.在t0时刻,将统计量初始化BoBs.在t时刻,将先前时刻的BN 统计量Bt-1(µt-1,)对齐至Bt.假设特征向量由m个样本{x1,···,xm}得到,则首先计算当前时刻BN 统计量的观测值
给定动量参数atR,以及t-1 时刻更新后的统计量Bt-1(µt-1,),则t时刻更新后的统计量为
该更新后的统计量更接近当前场景统计量的真实值.对该BN 层给定输入x,则此时输出特征为
其中,γ和β为BN 层仿射变换参数,ϵR 为极小常量以保持数值稳定.事实上,动量at对特征分布对齐至关重要,其决定了该BN 层适应于当前帧的程度.因此,与文献[12]中手动设定方法不同的是,本文采用元学习方法自动地获得合适的动量at值,使其更好地引导BN 统计量更新和特征分布对齐.为简洁起见,在下文中,at表示所有BN 层动量的组合.
2.2 在线元学习适应算法
本节介绍所提出的在线元学习适应算法.假设目标域双目视频序列为V其长度为T,其中,It为t时刻图像对.当模型在视频V上进行在线适应时,使用算法1 进行参数更新.
算法1.在线元学习适应算法
算法1 的动机在于: 对每个时刻t,网络自适应学习并获得用以更新参数的学习率.对于算法初始化,首先定义网络参数θ0,BN 统计量B0,网络参数的初始学习率λ0,以及元学习率λ*.对每个网络参数均设定对应的学习率,因此,λ0和λ*与网络参数θ维度相同.第3 行表示在t时刻,给定当前网络参数θt,输入图像对It,则预测的深度图为Dt(dr,dl)Φ((θt,at,Bt),It).此处dl和dr分别定义左图像与右图像对应的深度图.在前馈过程中,算法使用第2.1 节中描述的特征分布对齐算法,动量为at.统计量Bt+1储存至下一时刻使用.第4 行表示预测的深度图由损失函数L(Dt,It) 进行评估.注意到学习率λt-1为t时刻损失Lt的参数,因此,在t时刻前馈完成后,通过损失Lt求解针对λt-1的梯度,并以元学习率λ*进行梯度下降即可获得针对t时刻用于更新参数的学习率λt.以上过程在第6 行表示.由此,算法基于上一时刻的网络参数学习率λt-1和当前时刻损失Lt,得到了更适合于当前时刻场景的λt用于参数更新.最后,在第7 行和第8 行,算法基于λt对网络参数θt和动量at进行梯度下降更新.通过该算法,每一时刻当新的场景输入模型后,优化器以先前时刻学习率为经验,以当前时刻的自监督损失为引导获得适用于当前时刻的参数学习率,使网络中每个参数均得到合理更新,帮助模型快速适应于当前场景.在OMLA 过程结束后,模型获得θT+1,aT+1,BT+1和λT.
2.3 基于元学习的模型预训练方法
算法2.基于元学习的模型预训练方法
2.4 深度估计损失函数
本节介绍在算法1和算法2 中使用的自监督深度估计损失函数.与文献[9] 相同的是,模型以双目图像Il,Ir为输入并获得对应的视差图dl,dr.使用扭转操作fw,通过视差图dl从右图像重构左图像:
对称地,可用相同的方法从左图像获得右图像的重构结果.计算两个重构图像与原图像的误差可以反映深度预测的效果.最终的损失函数由L1重构误差和基于结构相似性(Structural similarity index,SSIM)的自重构误差LSSIM(参见文献[9])组成:
使用上述损失函数进行训练,模型能够无监督地获得深度估计能力,进行在线适应过程时也无需深度真值.
3 相关实验
3.1 评估方法和标准
1) 在线适应效果的评估方法.在线学习或适应过程中,视频帧被序列化地输入模型.对每个视频帧,模型均进行深度估计和参数更新.需要强调的是,在实验中为了合理地评估模型效果,在模型获得预测结果后立即进行评估,然后进行参数更新.在整个视频输入完毕后,计算针对该视频的平均效果以评估模型在该视频上的整体表现,同时计算最后20% 视频帧的平均效果以评估模型在最后阶段是否已经较好地收敛.
2) 评估准则.本文采用与文献[1,9,40]相同的评估准则.设P为测试视频中具有深度真值的像素点总数,di分别为在像素i处的预测结果和深度真值,则评估准则如下:
3.2 数据库与部署细节
本文实验以包含视频序列的自动驾驶合成数据库为源域数据库,在该数据库上进行预训练.以现实驾驶场景为目标域数据库,在该数据库上进行在线适应和评估.所使用的数据库如下:
1) Synthia[20]为一个城市驾驶场景的合成数据库.其包含5 个不同场景和季节的双目视频流.本文使用春季场景中模拟汽车以前置摄像头记录的视频流,共包含4 000 对双目图像,并在该数据上进行预训练过程.
2) Scene Flow Driving[41]为一个驾驶场景的合成视频数据库.其包含不同的相机设定、车速和行驶方向.本文选择汽车前进场景中所有的视频数据,共2 000 对双目图像.
3) KITTI[14]为现实行车场景数据库.本文选择文献[1] 提供的子集(简称Eigen 子集)为目标域数据.该子集包含32 个不同的训练场景以及28 个不同的测试场景.实验中以28 个测试视频进行在线适应和评估.
本文以Pytorch[42]平台部署方法,以一块Nividia P40 GPU 进行训练和测试.在实验中,每个网络模型均在卷积层后包含BN 层[43],以进行特征分布对齐.在合成数据集上的预训练过程中,首先以10-4为学习率进行100 个周期的训练,然后利用算法2 进行10 个周期的元预训练过程.此处设定λ10-4,λmeta10-5,K8,视频长度T8,t′5.在目标视频的在线适应过程中,使用OMLA 算法(即算法1),元学习率设置为λ*10-7,特征分布对齐方法仅在编码网络的BN 层中进行.所有的训练和测试过程使用Adam 优化器[44].
3.3 实验结果与分析
3.3.1 算法消融实验
为了验证本文算法的有效性,本节选择在常用的双目深度估计框架(在文献[9]中提出)上进行算法消融实验.值得一提的是,尽管该框架最初是作为单目深度估计方法而提出的,但随后在文献[9-10]中成功用于双目深度估计.除特别说明,所有模型均在Synthia 数据集上进行预训练,并且在Eigen子集的测试集视频上进行在线适应和评估.每个视频序列被单独评估效果,即均从Synthia 数据集预训练得到的初始网络参数开始在线适应过程.最终的效果得分为所有视频帧的平均得分.
相关的实验结果在表1 中展示.其中,基准方法表示仅使用一般梯度下降法的在线适应模型,在线特征分布对齐表示仅使用第2.1 节中方法,且采用基准方法进行在线适应的模型.标准预训练方法表示不使用第2.3 节中元预训练方法,仅采用一般训练方法的模型.首先可以观察到,不使用预训练过程的模型难以直接在目标域视频流上取得令人满意的效果,而使用基准方法对效果的提升也相当有限.这证明了仅在源域训练时,或者数据间存在域转移时会导致算法效果的显著下降.当模型使用在线特征分布对齐方法后,其效果有明显提升,这表明其能够较好地处理在线适应过程中的域转移问题.使用OMLA 算法使结果进一步提升.同时,使用元预训练方法的模型,其在线适应效果均好于使用标准预训练方法的模型.这些结果证明了本文元学习算法的有效性.
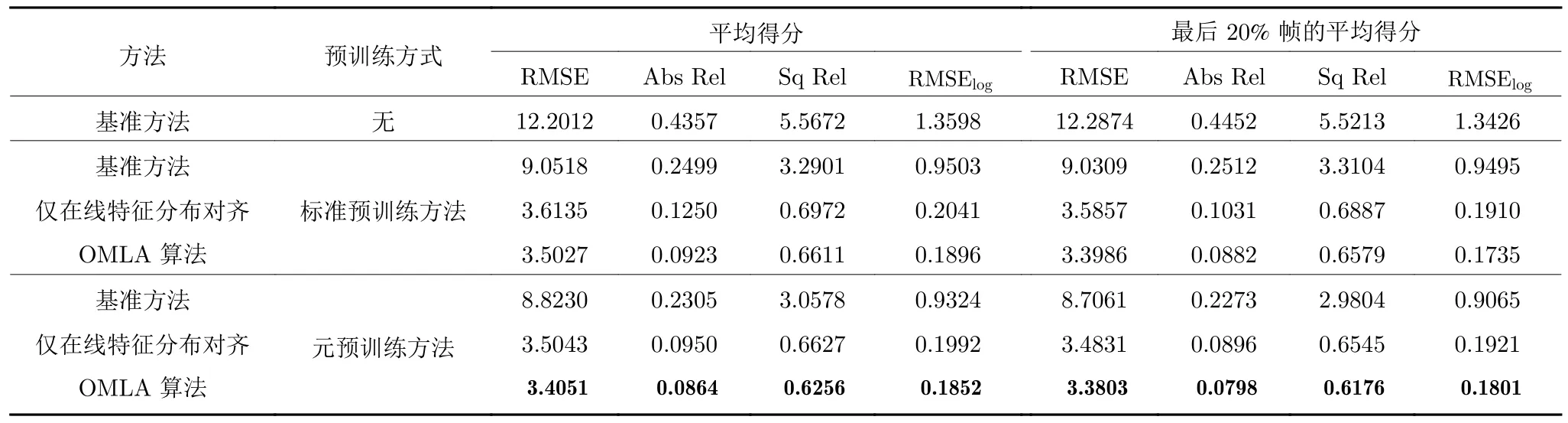
表1 KITTI Eigen 测试集的算法消融实验 (仅评估 50 m 之内的深度估计效果)Table 1 Ablation study on KITTI Eigen test set (the results are evaluated within 50 m)
3.3.2 不同网络模型和数据库的实验
为了进一步验证本文方法的有效性,本节首先在3 种网络框架下进行对比实验,分别为: DispNet[41],MADNet[15]和ResNet[9].实验主要比较了基准方法和OMLA+元预训练算法的效果,其中基准方法在源域上进行标准预训练过程.同时,为了验证本文方法在不同数据库上的普适性,本节分别在Synthia和Scene Flow Driving 数据库上进行预训练以比较效果.相关实验结果在表2 中展示.可以看到,在每个网络模型中,OMLA 算法均取得了明显的提升.这证明了本文方法在小型网络(如DispNet和MADNet)中仍能取得良好效果.在两个数据库上,OMLA 算法均带来了提升,证明了其在数据库间的普适性.表2 中同时比较了算法的运行时间,以帧速率 (帧/s)为指标.可以看到,OMLA 算法由于需要额外的梯度回传过程,因此相比于基准方法,其帧速率降低了大约20%.然而,考虑到取得的效果提升,该运行时间是可以接受的.
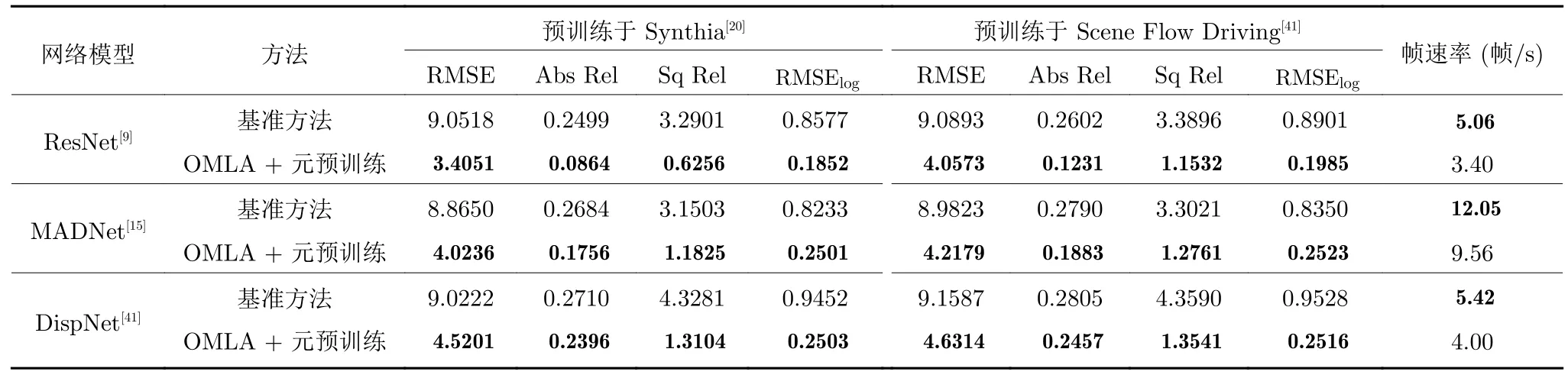
表2 不同网络模型和数据库上的结果对比Table 2 Comparison on different network architectures and datasets
3.3.3与理想模型和当前最佳方法的比较
本部分通过实验比较本文提出的算法与理想模型(即利用目标域数据训练的模型)的在线适应效果.实验中的网络模型均为以ResNet 构建的模型[9].为训练理想模型,首先将模型在KITTI Eigen训练子集上进行预训练.这样一来,当模型用于目标域数据,即KITTI Eigen 测试子集时,不会受到域转移问题的影响.对于理想模型的分析,采用了两种做法: 1)在目标域上不进行在线适应和模型更新;2)在目标域以基准方法进行在线适应和模型更新.同时,实验比较了L2A 算法[35],该算法为当前双目深度估计领域最佳的在线适应方法.相关结果在表3中展示,除OMLA+元预训练方法外,其余模型均采用标准预训练方法.可以看到,当模型在目标域进行预训练后,基准方法无法增强在线适应的效果.进一步地,相比于在目标域预训练的理想模型,尽管存在域转移问题,OMLA 算法获得了有竞争力的在线适应效果.相比于L2A 算法,尽管其使用基准方法进行在线适应,帧速率略高于OMLA算法,但OMLA 算法的准确度较之获得了明显提升,这证明了处理在线适应过程中域转移问题的重要性,也进一步验证了本文方法的效果.以上结果表明,尽管模型在训练过程中从未接触真实世界数据,其仍然可以利用本文的在线适应方法获得针对目标场景的快速收敛能力,并逐渐预测精准的场景深度图.
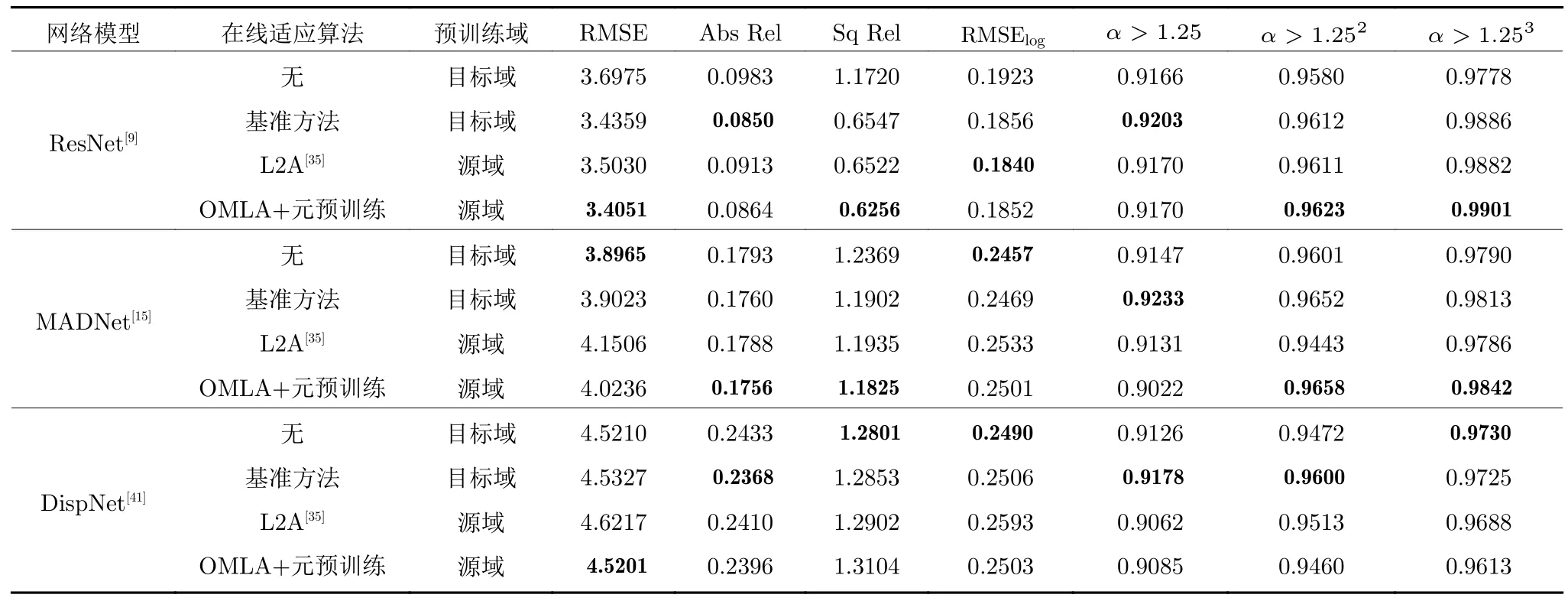
表3与理想模型和当前最优方法的比较 (仅比较实际深度值小于50 m 的像素点)Table 3 Comparison with ideal models and state-of-the-art method (Results are only evaluated within 50 m)
为了进一步分析本文方法,图3 展示了不同模型的深度估计视觉效果.为了评估不同模型的在线适应效果随时间的变化,此处展示了视频初始、中段和末段时刻的深度估计效果.可以看到,理想模型在3 个时期的效果均是良好的,这是由于理想模型在目标域进行训练,因此不存在域转移问题,模型的在线适应效果可以得到保证.L2A 算法也取得了不错的效果,但其问题也较为明显,例如在初始阶段无法预测出道路树木、交通标志杆的深度,在中段和后段依然存在大目标(如大型标志牌、大货车)的深度不准确、丢失等问题.相比之下,本文方法在视频初期预测效果有限,但在中段和末段帧上的表现较好,接近理想模型和深度真值.这是由于在视频开始阶段,模型仍然受到场景差异的影响而难以获得准确的预测结果.当进行一段时间的在线适应后,本文方法使模型较好地收敛至当前视频场景,因而预测效果获得了明显提升.以上的视觉效果展示较好地说明了本文方法对模型在线适应效果的提升.
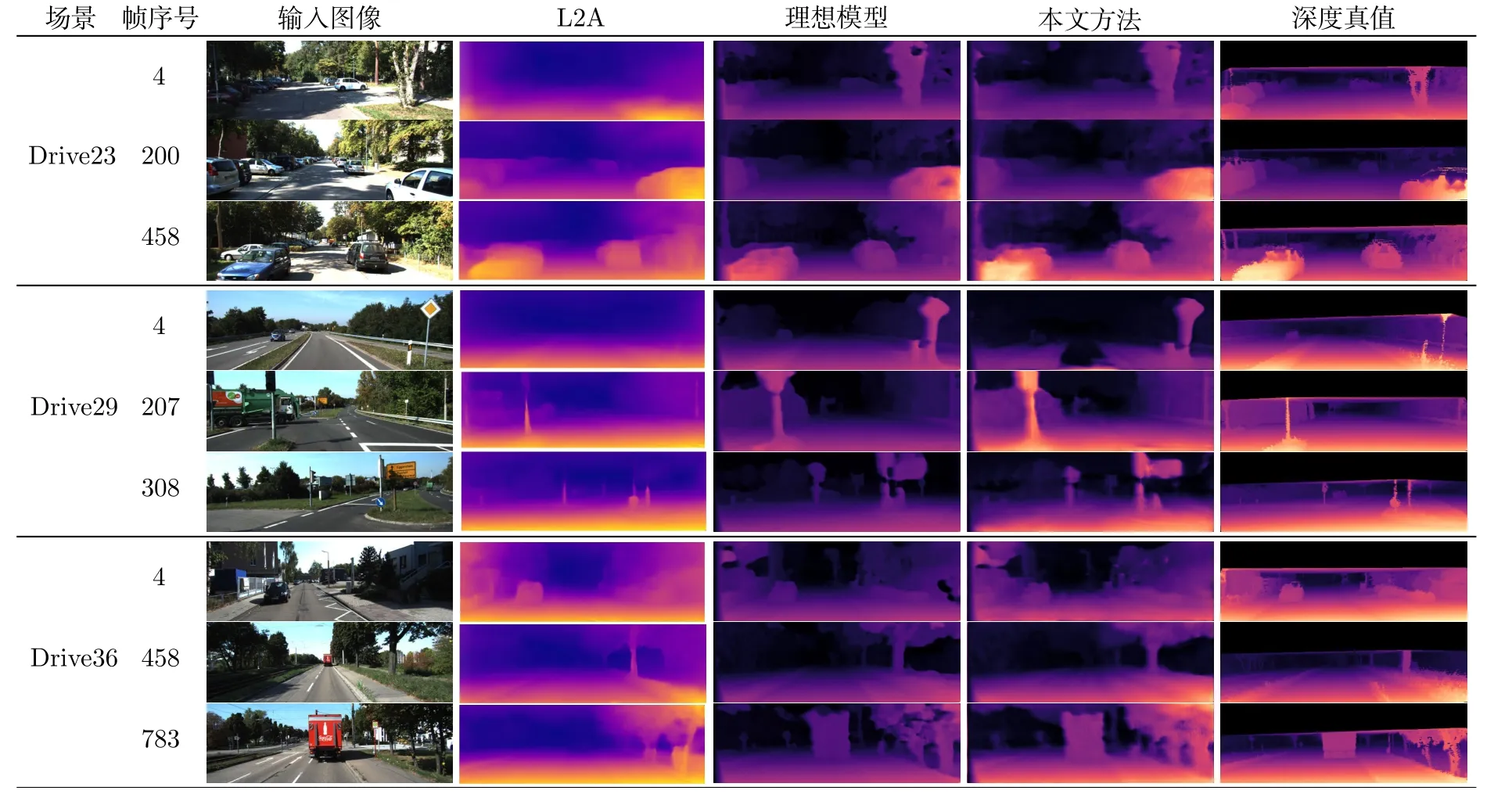
图3 在KITTI Eigen 测试集中3 个不同视频序列上的效果 (为了展示模型的在线适应效果随时间的变化,此处展示了视频初始,中段和末段时刻的深度估计效果)Fig.3 Performance on three different videos of KITTI Eigen test (We illustrated predictions of initial,medium,and last frames)
4 结束语
本文研究了深度估计模型的在线适应问题,并提出了一种新的在线元学习适应算法OMLA.该算法适用于需要深度估计网络模型快速收敛和适应于目标视频流的在线序列化学习场景.在公开数据集上的大量实验表明,相对于一般的梯度下降算法,本文方法较好地处理了域转移问题,并通过元学习方法充分利用每一时刻的学习反馈,有助于提升深度估计模型的在线适应效果.与当前最好的方法相比,本文方法取得了明显提升;与理想模型相比,本文方法获得了接近的并有竞争力的效果.
