基于文本挖掘与知识图谱的文献计量方法研究
2023-08-04辛瑞昊董哲原苗冯博王甜甜李英瑞
辛瑞昊,董哲原**,苗冯博**,王甜甜**,李英瑞**,冯 欣
(1.吉林化工学院 信息与控制工程学院,吉林 吉林 132022;2.吉林化工学院 理学院,吉林 吉林 132022)
当今时代正是各行各业发展的时代,也是革新的时代。伴随改革开放的不断深化,我国高等教育实施全面性的改革,作为人才培养基地,各大高校面临的改革任务越来越重[1]。利用现有高等教育改革文献,厘清高等教育改革的现状和发展,才可能有的放矢促进高等教育的发展[2-4]。鉴于此,本文提出一种文本挖掘和知识图谱相结合的文献分析方法,利用文本挖掘技术挖掘高等教育改革文献信息,为文本分析提供数据支撑;利用高频词共词分析构建词频矩阵,挖掘关键词间的相互关联,有效确定高等教育研究热点;利用文本聚类对主题词间距离进行计算,划分不同研究主题,明确高等教育主要研究主题;借助可视化结果直观展示,为后续学者的研究提供思路。
1 方 法
1.1 基于自然语言处理的文献主题提取
自然语言处理是计算机科学与人工智能学科中的一个交叉方向[5],利用NLP技术可以使机器自动化对语言进行处理。为了能够获得更多研究方向下的重要信息,利用自然语言处理对摘要中主题词进行抽取,用于对研究的相关数据扩充[6],利用jieba分词对摘要中信息进行分割[7],提取出能准确表达文本信息的词项单元,这些关键词能表明文献的中心观点[8]。为了深入分析高等教育改革内容,本文通过引用文献、规则判断和专家审核方法,将主题词分为研究对象(O)、研究内容(T)和研究方法(M)[9]。
1.2 基于TF-IDF算法的主题词特征提取
目前对文本的特征提取大多使用词频统计方法。由于本文研究的主题词主要分为研究对象、研究内容、研究方法,所以在计算特征频率的过程中,通过词频特征提取计算某个特征词的特征频率。采用TF-IDF(Term Frequency-Inverse Document Frequency)方法对文献特征进行提取。通过计算TF-IDF值对数据集特征进行分类训练,TF-IDF计算值越大,说明该词与文本的相关性越大。
以人才培养词频统计为例,首先统计文献中不同关键词出现的次数,例如人才培养出现过X次,文本共有N个词,可得人才培养出现的词频为X/N;随后计算逆文本频率指数IDF,计算方法为log(DA/D),其中D为出现人才培养的文本的具体数量,DA为全部文献样本数量;最后进行TF-IDF具体数值的计算,计算公式如下:
(1)
采用TF-IDF特征提取法计算出文本中每个特征词的TF-IDF权重值,并对其进行降序排序,然后根据预先设定的筛选条件选出满足要求的特征词,从而实现了对原特征空间的降维。
1.3 基于K-means算法的研究内容聚类
为了更深层次剖析高等教育改革文献研究内容中的主要研究方向,运用K-means算法结合余弦距离函数对研究内容主题词进行聚类[10-12]。K-means算法是一种通过多次迭代求解的聚类分析算法,是基于划分式方法的一种聚类方法,它有线性的时间和空间复杂度。K-means算法流程如下:
1)上传高等教育改革文献数据集DS,设置随机种子数(Seed值)及目标簇K值;
2)随机从数据集中,选取K个文本{S1,S2…,SK}作为文本集初始聚类中心点;
3)通过计算每个对象与初始聚类中心的距离dis(DS,Sk);
4)对文献和距离最近中心点进行匹配,将其分配给距离最近的聚类中心;
5)重新计算簇的中心,重复上述步骤1~4,直到簇心稳定。
在进行聚类时,需要选择合适的聚类距离衡量尺度。考虑到使用欧式距离来度量样本之间的相似度会造成很大的误差,本文利用K-means算法和余弦距离相结合的方法对研究内容主题词进行聚类,余弦公式相似度计算公式如下:
(2)
式中:si和cj表示两个数据点;‖·‖表示为向量,若其值等于1,则两向量相等;若等于零,则两向量共同点。两个主题词之间的余弦相似度越高,这两个主题词之间的相似度越大。
2 实例分析
2.1 基于知识图谱技术的文献智能分析
为了定量化分析高等教育改革趋势,本文采用文本挖掘与知识图谱相结合的文献智能分析方法,如图1所示。

图1 文献智能分析框架
第一阶段为数据收集。以“高等教育”和“改革”为主题,设置检索时间为“2010—2020年”,逻辑关系为“与”,期刊来源为CSSCI、EI、SCI、北大核心,利用网络爬虫从选定的内容中获取文献文本数据。
第二阶段为数据预处理阶段。在对重要信息提取后,将获取到网页加载存在问题的文献进行筛选,将清洗后数据进行存储。
第三阶段是数据分析阶段。利用处理后的文本数据,对数据进行知识图谱分析。通过高频词共现分析、文本聚类分析和可视化分析方法,揭示高等教育改革领域的核心主题和研究热点。
2.2 数据来源和数据处理
本文数据来源于“中国知网(CNKI)”的期刊数据库,研究文献类型选择“期刊”,以“高等教育”和“改革”为主题词进行精确检索,设置检索时间为“2010—2020年”,逻辑关系为“与”,选择期刊来源为CSSCI、EI、SCI、北大核心,共检索出论文10 642篇,将这些文献作为本文统计分析的数据源。采取定向爬虫的方法,爬取知网有关“高等教育+改革”为主题的数据信息,作为本文分析的数据基础。
2.3 作者产出与共现分析
中介中心度是衡量作者影响力的重要因素。一个结点充当“中介”的次数越高,它的中介中心度就越大[13]。高等教育改革研究领域核心作者发文量统计见表1。
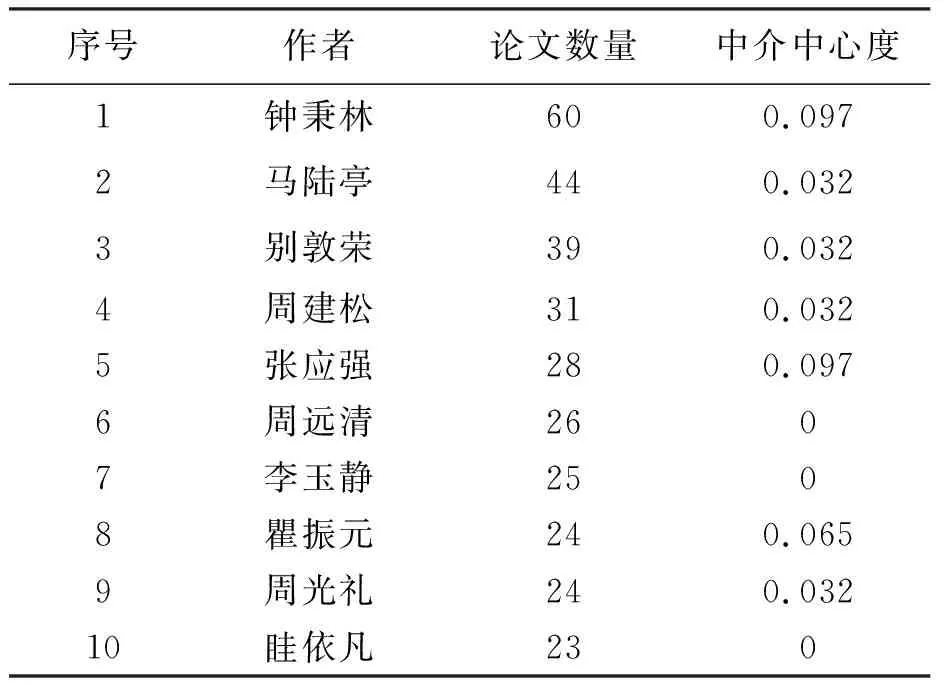
表1 高等教育改革研究领域核心作者发文量统计
其中,钟秉林的发文量最多(60篇),其次是马陆亭(44篇),别敦荣以39篇的发文量位列第三。从作者的中介中心度来看,钟秉林、马陆亭也位于前列。此外,张应强、瞿振元中介中心度也较高,表明他们在高等教育改革研究领域有着较高的影响力。钟秉林、马陆亭、张应强等都从事高等教育工作,在高等教育改革中提出了很多鲜明的观点。由此可知,在当下的高等教育改革中,从事教育的工作者,是高等教育改革过程中的主力军。
2.4 主题词的频度和TF-IDF分析
关键词通常指一组词或者短语可以表达一个文档核心主题,它能够对文本内容进行提取和凝练,帮助人们筛选信息从而定位到所需文档。本文通过对样本文献提取高频关键词,可以从整体上呈现近十年间高等教育改革领域存在的研究热点。目前确定高频词的方法主要以下三种:①平均TF-IDF排序。利用计算主题词在所有文献出现的平均TF-IDF,构建高频词矩阵,来确定高频关键词。平均TF-IDF值越接近1,说明该词在总文献出现的频率越高。②主观选定法,依据研究者的经验在词频阈值和选词个数之间进行平衡选定。③利用齐普夫定律确定高频词频值。本文采取第一种方法来确定高频主题词。
由于研究文献数目大,在剔除无法明确定义类型的主题词后,表2中可以看出排名前10主题词的频数、类型和平均TF-IDF权数,其中“O”表示研究对象、“T”表示研究内容。
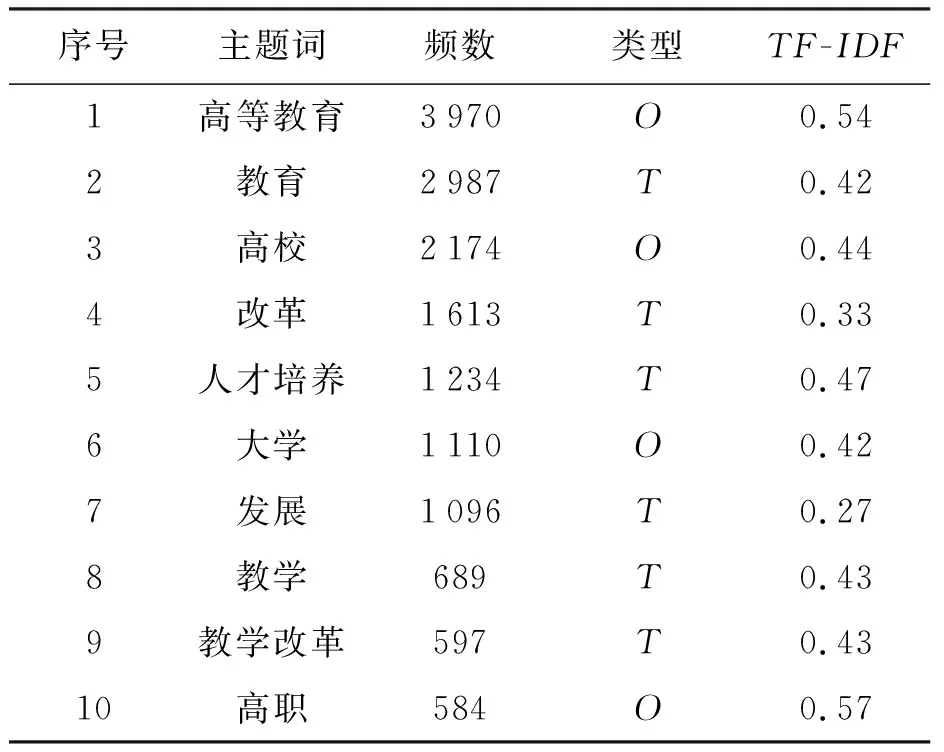
表2 “高等教育”加“改革”研究高频主题词
2.5 文本聚类分析
共词聚类分析法(Co-word Cluster Analysis)是文本聚类分析中的一种。它通过对期刊研究的关键词进行聚类分析,对共词网络中各关键词间的联系强度进行运算,把相互间联系相对紧密的主题聚集起来形成概念相对独立的团体,可以直观展现关键词之间的关系。其结果如图2所示。圆形节点越大,表示该关键词的共现次数越多,连线越多,表明该关键词与其他关键词的共现次数越多。直观地发现,“高等教育”聚类面积最大,其次是“高校”“人才培养”“培养”,学者们密切关注这几个层面。
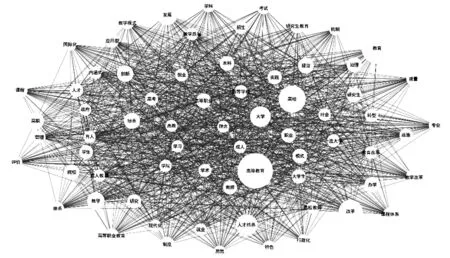
图2 主题关键词聚类
2.6 高频共词分析
研究内容表征了高等教育中重点关注的问题和现象。本文利用余弦距离相似度对研究主题词进行K-means聚类,将研究主题词聚类成3个区域,聚类中心分别为人才培养、教学改革及治理,这3个主题词所代表的主题形成了文本聚类研究领域的3个方面,如图3所示。

年份/年图3 研究主题年限统计分布图
从研究主题年限统计分布能发现,2010—2018年是我国高等教育改革研究的萌芽阶段,学者们开始了高等教育探索,3个主题每年发文量在60篇以内。在这个阶段,高等教育改革引起学术界的广泛重视。2018—2020年间是我国高等教育改革升温阶段,三个主题发文量呈逐年上升趋势。2020年“人才培养”主题文献发文量接近700篇,“教学改革”和“治理”主题文献发文量接近300篇,这个阶段学者们聚焦于高等教育改革研究。同时,根据研究主题年限统计分布图,结合“十四五”建设高质量教学改革内容,预示着相关主题增长趋势还将持续下去。
2.7 高等教育改革热点分析
为了清晰呈现研究内容(O)和研究对象(T)的关系,探究其内在关联,通过计算二者相关性进行热点领域分析,如表3所示。通过相关性结果与高等教育研究主题相结合能够得出,除“教育”“改革”“发展”等过于宽泛的热点外,紧随其后的就是“人才培养”;此外,在后续中主要热点还有“教学改革”“治理”等。“十四五”建设高质量教学体系指出,高校建设改革体系要坚持围绕学生、关爱学生,真正把学生放在主体地位,研究学生的思想动态、成长规律,注重学生的全面发展,利用科技教学手段,培养新时代高层次人才;同时,将严格管理与人性管理结合起来,统筹教育体系和治理能力之间的关系,深化高等教育改革的总目标。“高等教育+改革”主题主要围绕“人才培养”“教学改革”“治理”这3个方面,这也与“十四五”高质量教育改革要求相契合。
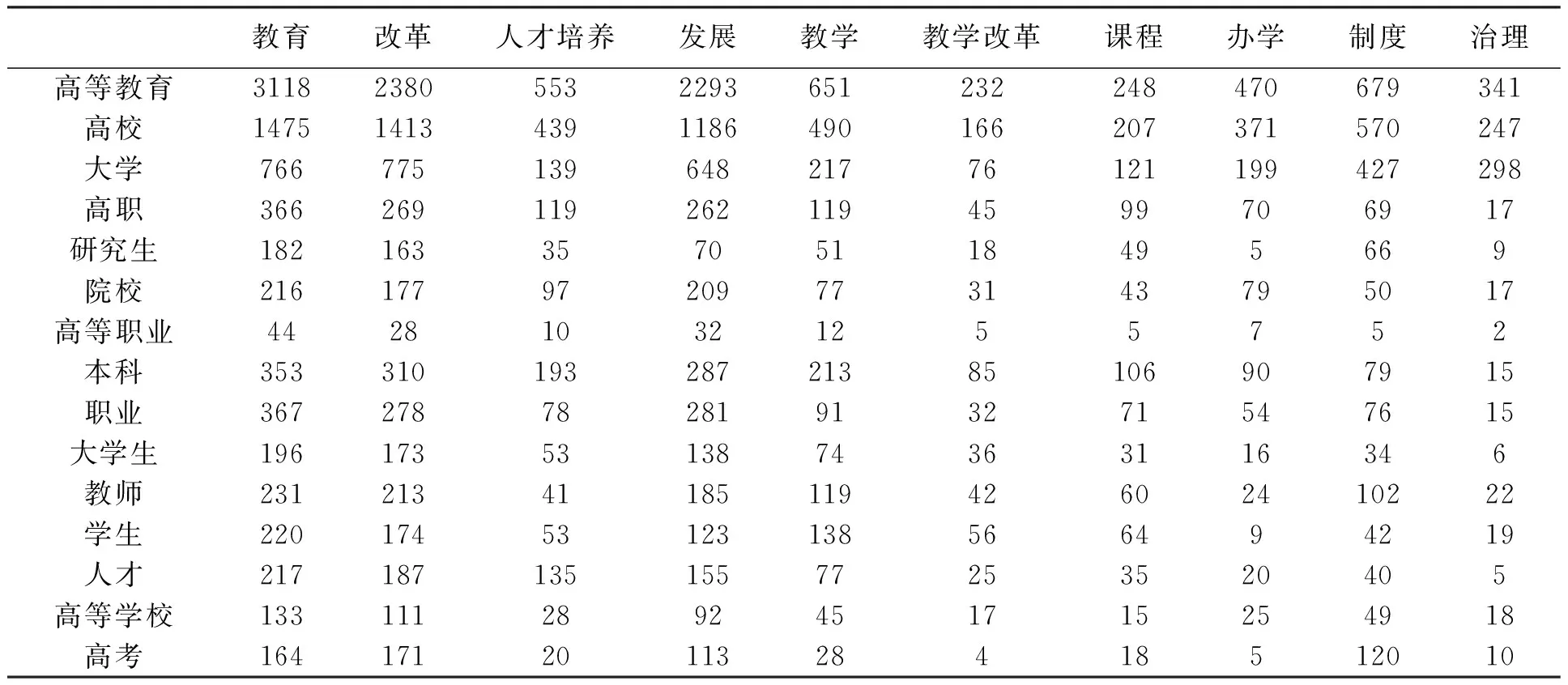
表3 “高等教育+改革”研究对象和研究内容相关性
3 结 论
本文提出一种文本挖掘和知识图谱相结合的方法,对国内的高等教育改革相关文献进行数据挖掘和分析。通过作者产出与共现分析、高频词进行共现分析、主题词文本聚类和可视化分析方法,揭示高等教育改革领域的核心主题和研究热点。根据主题词频矩阵统计,高等教育(0.54)、教育(0.42)和高校(0.44)所对应的平均TF-IDF值高于知识图谱构建规定的标准,在一定程度反映了高等教育改革较为集中于对高等教育、教育和高校的研究。文本聚类和热点相关性分析结果表明,未来该领域的研究应该仍集中在人才培养、教学方式、治理体系及治理能力改革上。通过本文的研究,可以为我国高等教育改革的现状研究及新研究方向的开拓,提供一定的依据和借鉴。
