基于三维激光扫描的岩质边坡结构面自动识别方法
2023-07-13胡武婷董秀军袁阳杰
胡武婷, 刘 昶, 董秀军, 邓 博, 袁阳杰
(1.地质灾害防治与地质环境保护国家重点实验室(成都理工大学),成都 610059;2.广西壮族自治区 地质环境监测站,南宁 530005)
随着中国基建事业的快速发展,各类工程建设的范围及规模也日益扩大,在水利水电、公路铁路等工程建设中往往需要评价和处理岩体带来的潜在工程隐患[1]。岩体结构面也被称为不连续面,在与岩体相关的工程活动中,对岩体的强度、变形和稳定性等方面起关键作用[2]。岩体结构面信息可以用于各种地质工程活动中,如围岩分级、场地评价、稳定性分析等[3-6]。但对于一些山体陡峭、地质环境复杂的地区,人工测量难以实施。因此,如何高效且快速地获取结构面信息已成为开展岩体分析工作的首要问题。
传统的人工测量采用的地质罗盘已不满足于现代工程地质发展的需求,不仅野外工作量巨大,危险性高,并且人为经验影响大,无法高效快速地获得结构面信息[7-8]。摄影测量的出现改变了野外工作模式,实现了非接触式的岩体测量,但这种方法仍存在许多问题。摄影测量对拍摄照片的精度要求较高,受光照影响大,并且需要对获取的影像进行几何校正、影像镶嵌及影像增强等一系列处理[9-10]。而三维激光扫描由于能够实时、快速地采集目标物体表面三维空间信息,具有非接触、实时、动态、高密度、高精度等特点,逐渐受到广大学者青睐,已有众多学者通过三维激光扫描获取的点云数据对岩体结构面进行研究。N.R.Adriá[11]采用基于邻点共面检验的分析方法,通过核密度估计寻找主方向,并提出一种去除点云噪点的方法,结合密度簇算法对岩体结构面进行识别与分组。R.E.Hammah等[12]采用模糊聚类算法实现了结构面自动识别。A.Buyer等[13]使用DSE软件结合Mathworks对岩体结构面进行自动识别。葛云峰等[14]通过获取岩体露头点云数据,结合改进的区域生长法和几何理论,实现了岩体结构面的智能识别。郭登上等[15]基于三维激光点云数据,改进了点云主成分分析算法,并利用区域生长算法对点云法向量夹角及曲率阈值进行分析,识别出了结构面。王培涛等[16]计算了领域点法向量,利用夹角阈值收集同组结构面法向量的坐标系信息,对共面点云赋予同种颜色,从而开展了优势结构面最优分组的相关分析。刘昌军等[17]对三维激光获取的点云数据进行三角网重构,并在此基础上研究了岩体结构面平面方程的拟合方法,从而得到了岩体结构面产状信息。宁浩等[18]通过计算点云法向量,并利用法向量对不同组结构面点云赋以不同的颜色,从而实现了结构面的识别,完成了结构面产状信息的提取。
通过前人的研究成果,可以发现利用三维激光扫描获取的点云数据进行结构面研究已成为主流的地质调查手段。结构面识别中聚类算法尤为重要,其直接决定了最终的识别结果。但目前诸如K-mean均值聚类、密度峰值聚类、高斯混合聚类等非监督聚类方法,需要人工确定分类组数,往往会忽视小峰值的点云优势结构面,导致识别效果差强人意,难以在工程中运用。
为了解决这一问题,实现岩体优势结构面的自动识别,本文以三维激光扫描仪获取的岩体点云数据为基础,通过KD树(K-dimension tree)索引、共面分析、法向量提取、产状计算、密度峰值计算等流程,提出了一种改进的分水岭算法,结合密度簇阈值分割实现点云优势结构面的自动聚类并得到对应的产状信息。
1 实验数据
实验所用的点云数据是一种具有离散型和随机性的高密度点坐标数据,除了包含物体的坐标信息,同时也包含物体的灰度及彩色信息。这些离散的点能够快速复建出被测实体的三维模型,即具备物体三维空间特征又有别于真实物体,这里用抽象的离散点代表连续的、非平整的岩体结构面。
贵州灰:观赏石界称黔太湖石、乌蒙石及盘江石,主要产于贵州喀斯特石山地区,石质主要为石灰岩、白云岩,储量巨大,用途广泛,对石漠化地区农民扶贫解困、创业发展具有重要意义。
为了判断算法的准确性和有效性,本文采用标准二十面体进行算法运行效果检验;为了保证算法的适用性和抗噪性,采用真实岩体边坡案列进行验证。正二十面体数据集由瑞士洛桑大学使用三维扫描仪(Konica Minolta Vivid 9i)采集[11]。对物体总共进行了10次扫描,平均距离为1 406 mm,设备扫描视线与顶点的倾斜角度约为301°。正二十面体是由10个不同不连续集上的20个三角面片组成的多面体,可由37.226万个点表示。
无机非金属材料工程专业课程改革应在改善课程设计与教学设计的基础上开展.线上线下教学结合、过程与集中相结合的考核方式有利于提高教学效果和学生成绩.线上教学应体现面的要素,课堂教学应体现点的要素.课堂教学宽松的气氛、自由的交流有利于促进学生学习的主动性与参与意识,培养学生的综合素质.科学、公正的考核方式是促进改革成功,有效提高学生综合素质的基本保障.
现场岩体结构面的采集数据来源于康定市一个自然岩质边坡,是通过徕卡ScanStation 2扫描仪获取的点云数据,边坡经度103°27′21.40″,纬度29°17′48.08″,体积约28 m×48 m×11 m,岩性为花岗岩,颜色呈灰白色。岩体节理裂隙发育,结构面之间相互交叉,坡脚有明显碎石堆积。其扫描速率可达50 000点/s,岩体灰度及彩色信息可现场扫描获取。采集点云数量为183.786万个,点密度860个/m2。整体而言,三维点云数据完整,未出现明显缺损情况,可精确识别边坡岩体的空间信息。实验数据如图1所示。
由于结构面交界处二十面体法向量会出现偏移,使得点云极坐标成环状分布。利用高斯核密度分析对其进行划分,能够获得密度峰值点,即聚类中心;同时能够分配样本点与剔除噪声点,是点云聚类前一个重要步骤。核密度估计被广泛运用于机器学习、图像处理等领域。由于高斯核密度估计函数不会对概率密度估计造成明显的影响,因此,其应用较为广泛。

图1 实验所用数据Fig.1 Experimental data(A)标准二十面体;(B)真实岩体边坡;(C)二十面体点云数据;(D)岩体边坡点云数据
2 原理与方法
为实现岩体结构面自动识别,需要进行以下几个步骤。首先,通过KD树索引局域点云,利用PCA主成分分析法估算出点云法向量并进行邻域共面分析;其次,根据公式求解出点云局域平面的产状,再使用高斯核密度处理点云极坐标并进行密度划分;随后,利用改进分水岭算法实现对岩体优势结构面密度簇聚类;最后,通过设定一定的阈值完成优势结构面的融合和修正,完成岩体优势结构面产状信息提取。具体流程如图2。

图2 基于改进分水岭算法识别岩体优势结构面流程图Fig.2 Identification of flow chart of rock mass dominant structural plane based on improved watershed algorithm
2.1 KD树索引
为了高效获取采样点周围邻域的点,方便后续法向量的计算,本文采用以KD树为索引的点云最邻近点搜索(图3-C)。KD树为二叉搜索树的拓展,其本质仍为二叉树,对比八叉树和四叉树等索引方法,KD树索引效率高,被广泛应用于高维数据索引。KD树内节点用(a,V)值表示,a为划分纬度,V为划分值,使用KD树划分空间数据点的树结构图如图3-A所示。在n维数据空间,(a,V)可以是一个n-1维的超平面。超平面将空间数据进行划分,可以划分成a≤V与a>V的两个子空间。图3-B展示了KD树在空间中的划分,首先,红线对空间进行划分,将空间一分为二;随后绿线将两个空间二分为四;最后蓝线将4个空间四分为八。
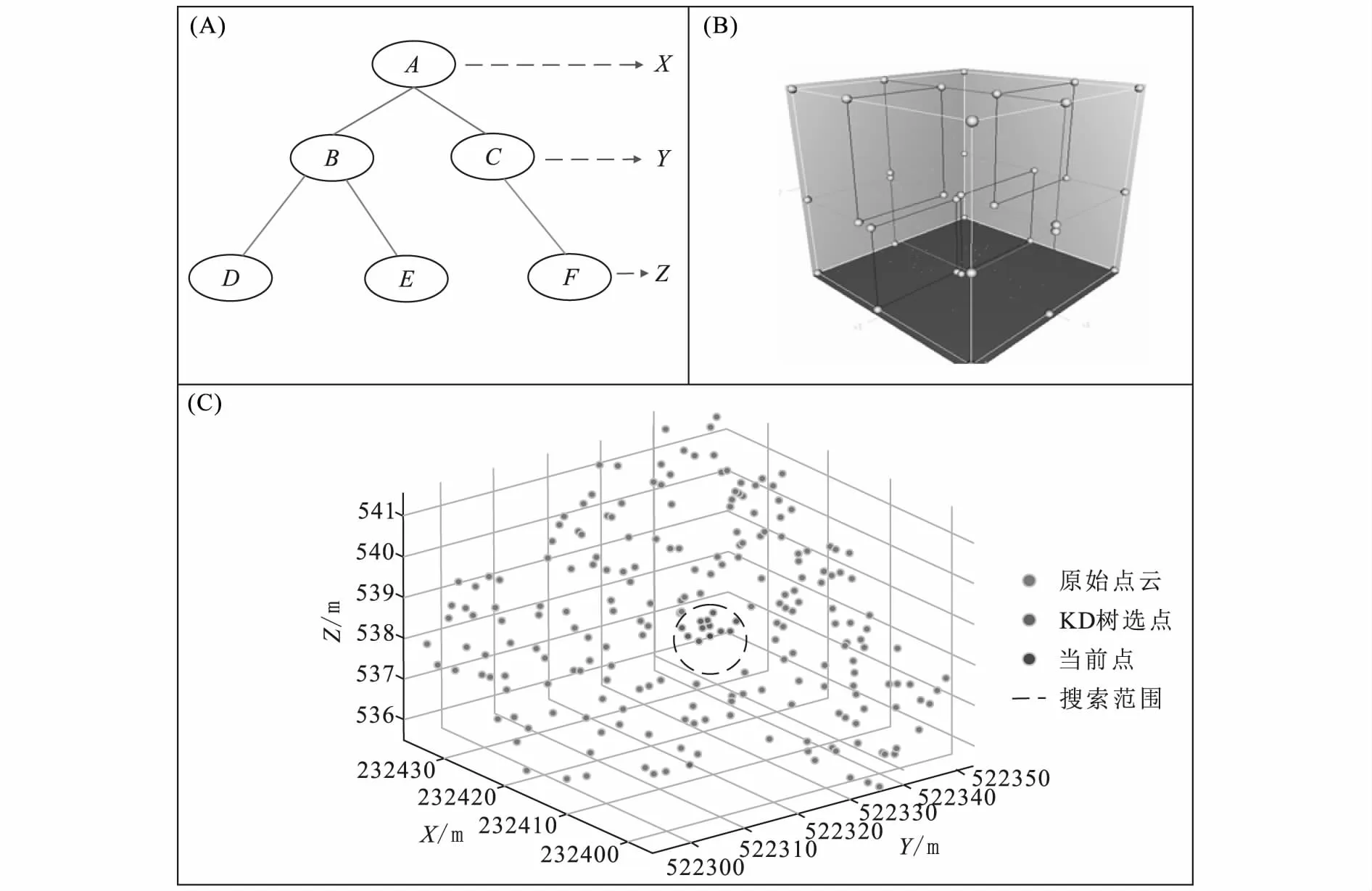
图3 KD树示意图Fig.3 Diagram of KD tree(A)KD树平面图;(B)KD树空间示意图;(C)KD树索引示意图
2.2 法向量提取



图4 法向量提取示意图Fig.4 Normal vector extraction diagram
(1)
根据《关于印发政府和社会资本合作模式操作指南(试行)的通知》(财金〔2014〕113号),PPP项目基本流程可概括为5大环节,共计19个节点。5大环节分别是项目识别、项目准备、项目采购、项目执行和项目移交。19个节点分别是项目发起、筛选、物有所值评价、财政承受能力论证、管理架构组建、实施方案编制、实施方案审核、资格预审、采购文件编制、响应文件评审、谈判与合同签署、项目公司设立、融资管理、绩效检测与支付、中期评估、移交准备、性能测试、资产交割和绩效评价(见图1)。

2.3 共面分析和法向量转换
共面检验是基于PCA主成分分析法的,通过PCA算法确定点云集中各个点的3个特征值(λ1,λ2,λ3),其中通过λ3可以得到点云的局部曲率η。曲率η由以下公式定义
基于MIKEFLOOD阳澄湖一二维水动力耦合模型研究………………………………………马天海,孙 娟,颜剑波(1.25)
(3)
曲率(ηmax)被定义为点子集中最大允许偏差,是通过一定试验条件下的实际数据进行灵敏度分析所得到的。η最大值为20%,当η>ηmax时,该子集将会被舍弃[19]。
很多观景点都是根据四季植物景色的诗文而命名的,例如,苏州怡园。夏天有赏荷花的藕香榭,冬天有赏梅花的南雪亭。同一种植物,在不同的季节也会有别样的观赏氛围。例如,扬州个园。代表春的笋发百兽兴,代表夏的云蔚松鹤亭,代表秋的叠石问书径,代表冬的踏雪闻风行。沿着庭院游览一圈,真的能感受到一年四季,仿佛经历了一次春夏秋冬的轮回。
完成点云法向量提取后,以方向朝Z轴正坐标的方向为正方向,对方向为反方向的法向量进行坐标转换,确保所有点云法向量都为正向,方便后续岩体倾向、倾角的计算(图5)。若提取的点云法向量n=(A,B,C),当C<0时,新的法向量n′=(-A,-B,-C);当C>0时,n′=(A,B,C)。
2.4 产状计算
完成倾向倾角提取后,二十面体点云产状极坐标分布如图6所示。
Ax+By+Cz+D=0,(A,B,C,D)∈R
(4)
式中:R为实数集;A、B、C不同时为0;平面法向量坐标为n′=(A,B,C)。通过结构面上的点,拟合出平面,就能得到相应的平面方程,从而解算出方程参数。结构面倾角β与倾向α的计算式如式(5)与式(6)所示[20]。
(5)
(6)
当sinα0>0,cosα0>0时,α=α0;当sinα0>0,cosα0<0时,α=180-α0;
在建筑工程施工中需要依靠大量的人力、财力与物力作为支撑,因此在建筑工程结构设计过程中,不仅要充分考虑建筑工程的实用性、用户需求等影响因素,还需要考虑当地的施工条件与施工技术,才能够建设出质量最好、功能最完善的建筑工程。要尽量避免结构设计无用功情况的存在,因此需有机统一理论与实际,以保障建筑工程结构设计的可实行性。
当sinα0<0,cosα0<0时,α=180-α0;当sinα0<0,cosα0>时,α=2π+α0。
对标国外先进技术,渤海装备目前已先后完成中国石油集团公司科研项目6项,专利申报26项,技术攻关48项,为产品升级换代、适应用户新的更高要求提前做好技术储备。

图5 法向量转换示意图Fig.5 Normal vector conversion diagram
结构面的倾向、倾角是通过法向量转换而来的,在三维影像数据中计算产状的基本数学模型如下:通过平面上不在同一直线的点(x,y,z)求取其平面方程

图6 点云产状极坐标分布Fig.6 Polar coordinate distribution of point cloud occurrence
2.5 密度峰值计算
利用语音分析软件Praat对这些单词进行语音的提取和分析,其中元音共振峰的测量借鉴了Lobanov 1971年首次使用的方法,并根据数据的特征,从统计学角度比较贵州民族学生和美国英语母语使用者内部及其之间的F1F2数值,分析是否呈现显著性差异。
若已知某个数据点p的概率分布,当另一个数据q在附近出现,则认为数据点p的概率密度也会变大。针对观察的第一个数,一般常用K“核”来拟合概率密度,但“核”的选取对概率分布的影响不大。核密度估计通常表示为[21]
(7)
其中:h表示核函数宽度;xi-xj表示两点距离;n表示分布数目。
核函数通常包括高斯核函数、三角核函数、二次核函数、均匀核函数等,高斯核函数通常表示为
(8)
与大多数算法相比,高斯核密度分析所需计算参数相对较少且简单高效,可以迅速找到聚类中心。利用高斯核密度分析对正二十面体进行划分,结果如图7所示。

图7 二十面体核密度分析结果Fig.7 Icosahedral nucleus density analysis results
2.6 改进的分水岭聚类算法
密度分析后的结果需要通过聚类的方式完成岩体优势结构组的自动分割。目前常用的聚类算法有划分式算法、层次化算法、基于密度的算法、基于网格的算法等[22]。但这类算法都需要人工监督分类,主观意识影响大,且面对高维或大规模数据时,都需要选择参数,参数的选择也是一项耗时的工作。本文利用的改进分水岭聚类算法无需人工选择优势结构面组数而能够自动聚类,避免了人工主观性的影响。经典的分水岭最先由Luc Vincent[23]提出,这种算法能够自动发现相对集中的类簇[24]。其分割方法可以通过模拟浸入过程实现,将梯度图像中所有像素点的灰度值对应地形的海拔高度,盆地等向下凹的区域则代表局部灰度极小点,山脊则表示原始图像的边缘以及山脊与盆地之间的山坡。将整个模型浸入水中,并在各个“盆地”的最低点处刺孔,则水会从极小处向四周蔓延,在两个相邻盆地汇合处所构成的大坝即为分水岭(图8)。

图8 分水岭模型Fig.8 Watershed model
在分水岭算法中,由于暗纹理细节与暗噪声的影响,图像中出现许多伪极小值。而算法会混淆真正的极小值与伪极小值,把它们作为独立区域分割出来,造成严重的分割问题,这种现象也被称为过分割现象。处理过分割的方法通常有两种,一是在分水岭算法结束后,把相邻的小区域进行合并;二是对原图像进行滤波处理,从源头上解决噪声所引起的过分割问题。本文针对分水岭算法存在的过分割现象,通过把相邻小区域进行合并改进了传统的分水岭算法[25],具体步骤如下:
a.任意选择一块极小区域作为种子区域。
根据第2节内容,求得自然岩质边坡结构面产状后,利用高斯核处理得到的点云极坐标,再通过改进分水岭算法完成岩体优势结构面自动聚类。将ηmax设为20%进行共面滤波去噪,滤波后通过分水岭算法,得到8组密度簇。对于滤波过后的数据,由于部分小区域结构面距离极近,将夹角阈值设定为15°,对改进后的模型进行密度簇的融合与修正,最后得到6组结构面(图10),其表征效果如图11所示。
(9)
其中:(ai,bi,ci)和(at,bt,ct)为相邻区域法向量;H为法向量夹角阈值,可根据用户需求进行设置。而对于夹角相差较大的区域则定为新的种子区域。
c.反复迭代计算,持续更新种子区域,直至所有相邻区域不再相似,则完成合并,得到最终结果。
二十面体聚类结果如图9所示。

图9 二十面体聚类结果Fig.9 Cluster results of icosahedron
3 实例分析
3.1 工程实例
将第1节所提到的自然岩质边坡的三维点云数据作为研究对象,用以验证改进的分水岭聚类模型的可行性。
b.将与该区域相邻的区域进行合并。设与种子区域A1相邻的区域为A2、A3、…,对应的向量夹角为θ2、θ3、…,计算两向量夹角,其计算公式为

图10 产状夹角阈值归类Fig.10 Classification of threshold of occurrence angle

图11 边坡数字化表征效果Fig.11 Effect of slope digital representation(A)边坡点云;(B)边坡立面图;(C)边坡剖面图;(D)高斯核密度分析结果;(E)基于改进分水岭算法提取优势结构面结果
在产状阈值归类结束后,得到的6组优势结构面,分别为:123.6°∠82.2°、87°∠76.1°、66.7°∠63.2°、306.8°∠49.3°、302.3°∠80.5°、328.4°∠61.1°。
开放获取运动开展至今已经有十几个年头,在科学界、出版界的推动下,这场以促进学术研究资源无限制获取和再利用为宗旨的全球运动总体上呈增进趋势。2018年6月18日,开放获取学术出版协会(OASPA)发布的2017年度会员机构出版的开放获取论文数量显示,2017年全开放(full open access)杂志上发表的论文数为219,627篇,2016年为189,529篇,且在过去的几年里开放获取论文数量平均以14%—15%速度稳步增长[1]。
3.2 效果检验
应用本文所提出的改进分水岭算法实现岩体优势结构面的自动识别,与人工测量相比,算法得益于以点云数据作为基础数据,不仅可以识别出完整且大块的结构面,对于一些破碎、层面出露不明显的结构面也有较好的识别效果。对算法提取出的优势结构面进行精度检验后发现,其倾向、倾角提取结果与人工测量结果高度吻合,统计结果如表1所示。
炮弹雨一样泼了下来,底柱捂着耳朵数响声,大声喊:八二炮、山炮、野炮……炮声渐渐稀了下去,正往后作延伸炮击。
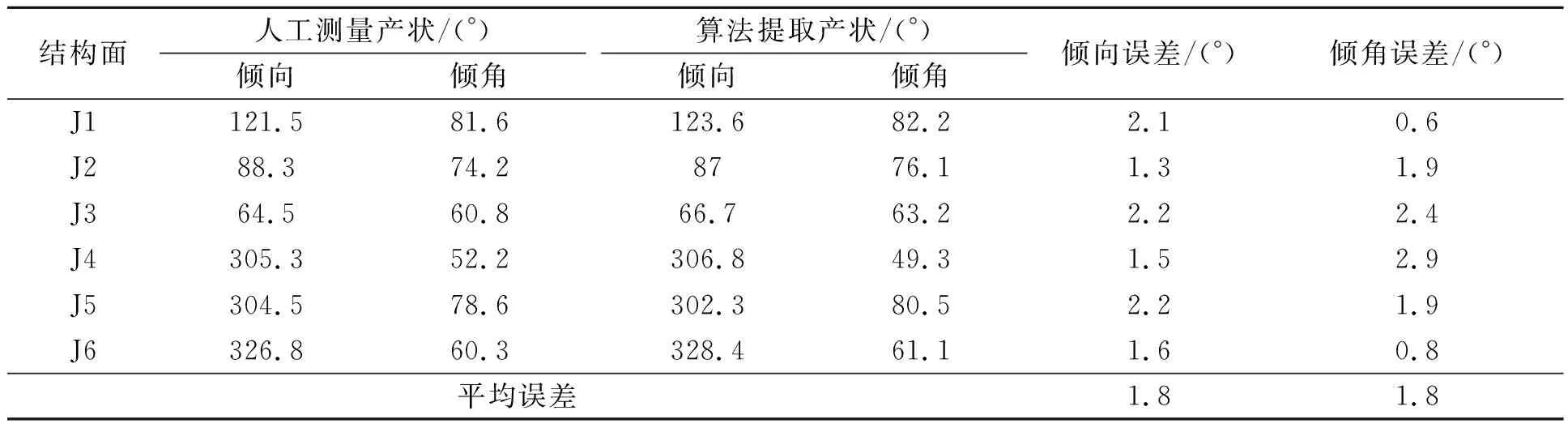
表1 人工测量产状与算法提取产状结果对比Table 1 Comparison of the results of manual measurement and algorithm extraction of occurrence
结果显示,倾向、倾角最大误差分别为2.2°和2.9°,均满足地质结构面产状测量精度所要求的±5°范围内[26]。倾向、倾角平均误差值都为1.8°,可以看出改进分水岭算法对优势结构面有较为准确的识别效果,极大程度上还原了岩体结构面特征,满足工程需求。
将算法运用于其他复杂岩质坡体后发现,改进分水岭算法除了适用于本文的自然岩质边坡点云数据,对于危岩体以及人工开挖岩质边坡也同样适用。其结构面识别效果如图12所示。利用改进分水岭算法提取人工开挖边坡优势结构面,可以得到9组优势结构面(图12-B)。利用该算法提取危岩体优势结构面,可以得到8组优势结构面(图12-D)。与人工测量结果相比较,改进分水岭算法对于不同类型的坡体,产状识别精度都比较高,其实测值与计算值对比情况如表2及表3所示。

图12 分水岭算法应用Fig.12 Application of watershed algorithm(A)人工开挖岩质边坡;(B)人工开挖岩质边坡优势结构面识别结果;(C)危岩体;(D)危岩体优势结构面识别结果

表2 人工开挖边坡人工测量产状与算法提取产状结果对比Table 2 Comparison of the results of manual measurement and algorithm extraction for slope excavation

表3 危岩体人工测量产状与算法提取产状结果对比Table 3 Comparison of the results of manual measurement and algorithm extraction for dangerous rock mass
结果显示,人工开挖边坡与危岩体优势结构面的实测值与计算值之差均满足精度要求的±5°之内。改进分水岭算法除了对于人工开挖边坡与危岩体优势结构面的识别准确度较高外,更避免了人工主观性过强而影响识别结果。使用改进分水岭算法能够更大精度挖掘细小结构面,达到良好的识别效果。
4 结论
本文提出了一种基于改进分水岭算法的优势结构面自动识别方法,通过标准二十面体点云数据与现场自然边坡点云数据验证了算法的可靠性。取得的结论如下:
a.本文提出的改进分水岭算法,采用密度簇的阈值分割方法,与非监督聚类算法不同,此算法无需确定种数类别,便可得到结构面最优聚类组数及产状。
关于语体分类的问题,众说纷纭。口语和书面语的语体分类是根据语言表达的媒介物来区分的,对话语体和独白语体则是根据场景中语言使用者是否即时互动为特征的,科技体、文艺体等是根据语言使用的领域来区别的。我们认为还可以根据语言使用的功能和意图来区分(参见李秀明:2011)。
b.改进分水岭算法对于优势结构面自动提取的适用性更强,不仅能够适用于自然岩质边坡,同时也能适用于一些复杂岩体边坡,如人工开挖边坡、危岩体等。
c.本文算法对于层面出露不明显以及野外难以观测的次发育结构面仍有良好的识别效果,且识别结果满足精度要求。
