改进YOLOv5算法在停车场火灾检测中的应用
2023-07-10晋志华陈可鑫
张 震, 晋志华, 陈可鑫
(1.郑州大学 电气与信息工程学院,河南 郑州 450001;2.郑州大学 计算机与人工智能学院,河南 郑州 450001)
近年来,随着中国经济的高度发展,居民汽车拥有量不断增加,地下车库成为汽车的主要停泊地。然而,由于电气短路、油箱漏油等原因,车辆在地下车库停放时容易发生火灾。停车场车辆密度大、火焰燃烧迅速、场所较为封闭、施救难度大,一旦发生火灾,经济损失巨大[1]。目前,大部分的公共场所都在使用传统的光电感烟探测器。由于地下停车场空间大,并配备一定的通风设备,使得传统的烟雾火灾检测装置效果大大降低,且光电感烟探测器工作需要一定的颗粒浓度,所以实时性较差。车库一般都安装有监控摄像头,因此将基于视频的目标检测用于地下停车场的火灾检测具有重要的研究意义。
当前目标检测算法主要分为由R-CNN代表的二阶段(two-stage)目标检测算法以及YOLO(you only look once)代表的一阶段(one-stage)目标检测算法[2-3]。主流的二阶段目标检测算法有 R-CNN[4]、Fast R-CNN[5]等,这类算法首先生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。代表性的一阶段目标检测算法有SSD[6]、YOLO等。以YOLO为代表的一阶段目标检测算法仅需处理一次图像就可以得到目标的位置以及分类结果,相较于二阶段目标检测算法,能够有效提升目标检测的速度,因此更适用于实时性要求高的地下停车场火灾检测问题。
YOLOv5[7]在目标检测领域有着广泛的应用。考虑到地下停车场空间较大、发生火灾初期火焰目标较小,原始的YOLOv5s模型在此条件下检测效果较差,本文通过增加小目标检测层、增加注意力机制以及修改损失函数来提升对小型火焰目标的检测效果。
1 YOLOv5算法介绍
YOLOv5网络结构分为输入端Input、骨干网络Backbone、颈部Neck和预测部分 Prediction。算法一共包含4个模型,按照模型由小到大分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。其中,YOLOv5s的模型最小,相同实验环境下检测速度最快、易于部署,且拥有较高的检测精度,能够满足对火灾火焰实时检测的要求。
YOLOv5模型在数据输入端Input采用Mosaic数据增强算法对数据集进行训练前处理。随机读取数据集中的4张原始图片,对图片进行随机缩放、翻转、改变色域等操作,随后将处理后的图片进行拼接,得到一个拥有更高复杂度的样本。通过对数据集多次处理,可以大大增加数据集的复杂度,从而提升模型的泛化能力。
YOLOv5模型的骨干网络Backbone采用了最新的Focus结构。输入矩阵经过间隔采样操作变为4个具有原矩阵信息的低维度矩阵,然后将4个矩阵在同一维度上进行堆叠,使得堆叠后的新矩阵能够得到更明显的原始矩阵信息,大大提高了后续的特征提取的效率。YOLOv5在CSP模块[8]中加入SPP模块,有效地增加了主干特征的接收范围,即提高了感受野,显著地分离了最重要的上下文特征,从而提升了模型精度。
2 检测算法优化
本文的主要工作主要体现在以下3个方面:在原模型的基础上增加一个小目标检测层、加入改进坐标注意力结构以及使用CIoU替换GIoU。
2.1 增加小目标检测层
针对火灾初期火源目标较小、原模型漏检的问题,在YOLOv5s模型的基础上增加一个小目标检测层,通过增加模型对细粒特征的分辨能力,从而增强模型对小目标的检测效果,虽然增加了计算成本,但是能够很好地检出小型火焰目标。
增加小目标检测层网络如图1所示,与原始YOLOv5s网络相比,改进后的网络从骨干网络的第2层就开始特征增强、提取浅层特征;将提取到的特征图与深层特征进行融合,继续进行上采样处理,特征图继续扩大,与骨干网络提取出的浅层特征进行融合,得到具有更多特征信息的特征图,并将富含细粒信息的特征图向下层传递。由此,模型能够提升对细粒信息的敏感度,从而提高对小目标的检测性能。

图1 YOLOv5s增加检测层结构图Figure 1 YOLOv5s added detection layer structure diagram
如图2所示,不同的特征层对小目标的感知是不同的,通过增加浅层的检测层,以及提供更小的Anchor,使模型可以更好地关注小型目标的信息,能够提升模型对于小型火焰目标的检测能力。

图2 不同特征层检测不同大小目标示意图Figure 2 Schematic diagram of objects of different sizes detected by different feature layers
2.2 改进的坐标注意力结构
坐标注意力机制[9](coordinate attention, CA)在SE注意力机制[10]的基础上进行了针对性的改进,保留了图像的特征位置信息。相较于SE注意力模块,该模块不仅能获取到空间方向上的长程依赖,还能增强特征的位置信息表达,同时增大网络的全局感受野。
如图3所示,通过将输入特征分别进行X轴与Y轴方向上的一维自适应平均池化,从而分别得到保留有X轴与Y轴信息的独立方向感知特征,其中一个空间方向捕获长程依赖,另一个空间方向保留精准的位置信息。对得到的两个一维特征在W维度上进行拼接,再经过一个卷积以及非线性激活函数,紧接着将特征在通道维度进行拆分,通过卷积以及Sigmoid激活函数得到两个带有特定空间方向长程依赖的特征图,这两个特征图可以互补地应用到输入特征图来增强感兴趣的目标。通过与原特征进行特征融合,最终得到在宽度与高度方向上带有注意力权重的特征图。
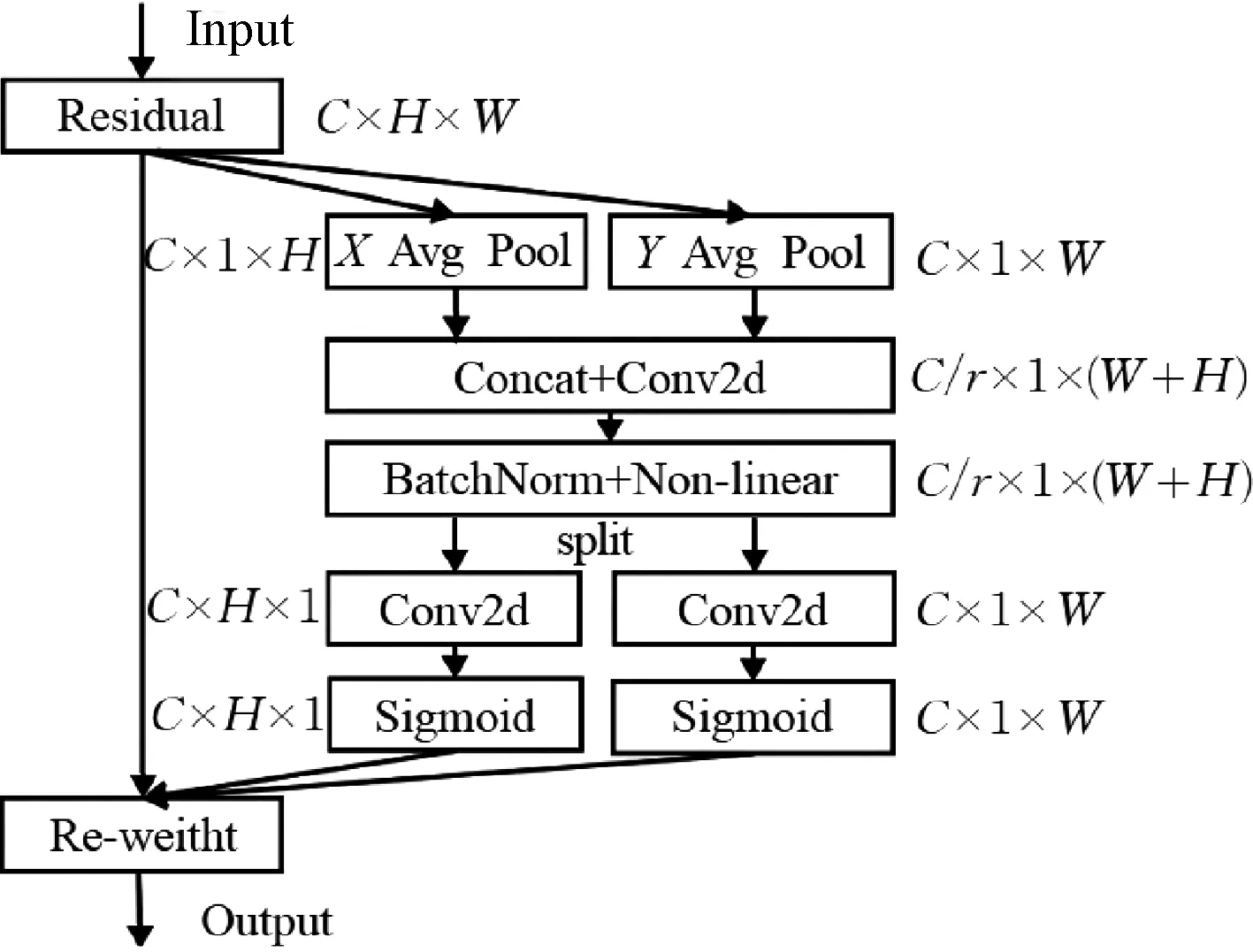
图3 坐标注意力机制网络图Figure 3 network diagram of coordinate attention mechanism
目前,常见的Backbone注意力结构如图4(a)、4(b)所示。其中,C3CA结构是将注意力模块嵌入YOLOv5的C3模块中,即对每个特征层提取的特征均进行注意力机制的处理;CA结构是只对深层次的特征图进行特征的增强。
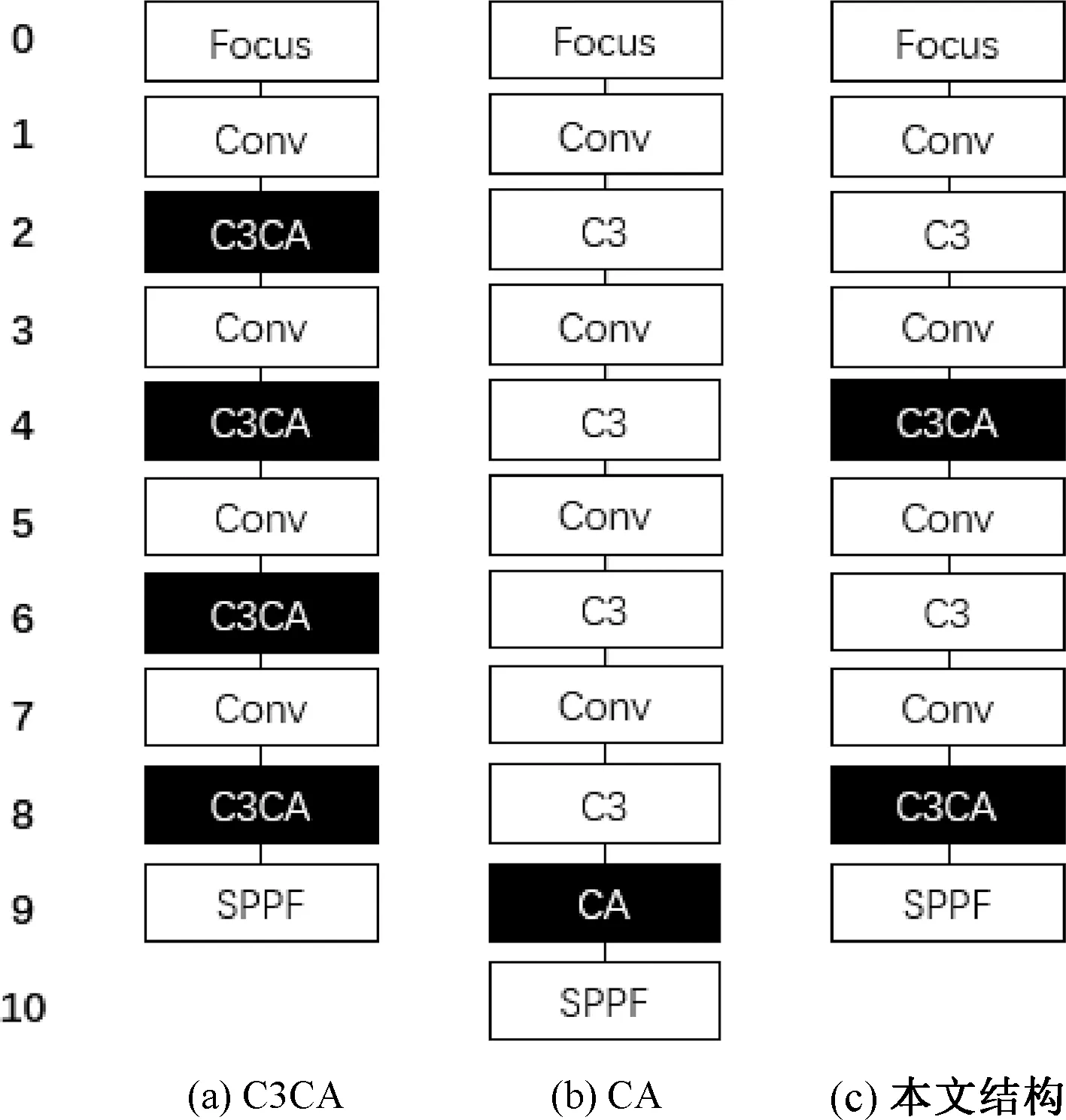
图4 C3CA、CA结构与本文结构对比Figure 4 Comparison among C3CA, CA structure and this structure
本文提出一种新的间隔注意力结构,如图4(c)所示。图像经过一次提取得到的特征图经过注意力机制,得到一个小感受野的、具有独立方向感知特征的特征图;该带有位置信息的特征图继续进行一次特征提取,然后再一次通过坐标注意力机制,得到一个具有大感受野并具有独立方向感知的特征图。相较于常见的C3CA、CA结构,本文使用的间隔注意力结构在Backbone中间隔使用了两次注意力模块,将第2、4个C3层替换为具有注意力机制的C3CA层。本文结构能够让模型更加关注中小目标的特征,有助于对深层次目标的特征强化,使模型能够更精准地提取目标特征,从而增强目标检测的精度。
相比于C3CA结构,本文结构减少了两个注意力模块,模型的复杂度大大降低,使网络模型更加精简,有助于提升模型的检测速度;相比于CA结构,本文结构增加了在中间特征层的注意力模块,通过注意力模块提取的带有位置信息的特征经FPN结构融合,得到更多的特征语义信息,能够进一步提升模型的检测效果。
2.3 CIoU损失函数
YOLOv5中采用GIoU Loss作为Bounding box的损失函数。如果预测框与真实框出现非相交的情况,此时梯度将变为0,神经网络将无法优化,预测框与真实框的相对位置无法区分。考虑到上述情况,本文使用Complete IoU(CIoU) Loss[11]代替GIoU Loss。CIoU损失在考虑GIoU损失的基础上,考虑了BBox的重叠面积、中心点距离以及BBox长宽比的一致性,使模型得到更好的回归效果。
3 实验
3.1 创建自定义的地下停车场火灾数据集
当前并没有公开的地下停车场火灾的数据集,本文选择自定义数据集。其中图像来自于包括CVPR实验室采集的KMU Fire and Smoke database火焰图像[12]、停车场监控模拟火灾视频、室内火焰模拟视频以及网络视频等。为了更好地对小目标火焰进行检测,更快对地下停车场火灾做出反应,通过模拟实验采集一部分小型火焰图像数据。另外,地下停车场光线较差,普通监控摄像机容易过曝,本文对这种情况也进行了模拟。数据集包含夜晚、灯光、日光等多种场景,火焰目标大小不同,共计3 420张图片。本文通过labelImg标注工具对数据集图像进行标注,并保存为YOLO系列的txt格式。通过对数据进行乱序排列,随机选出训练集2 394张,测试集共513张,验证集共513张。数据集示例如图5所示。

图5 数据集示例图Figure 5 Dataset example graph
训练集中所有标签框的大小分布如图6所示,其中横纵坐标分别代表标签框的宽度和高度。图中深蓝色表示尺寸在该区域的标签图较多,更符合火灾初期火焰目标较小的情况,所以该数据集适用于本文研究的火焰目标检测的问题。
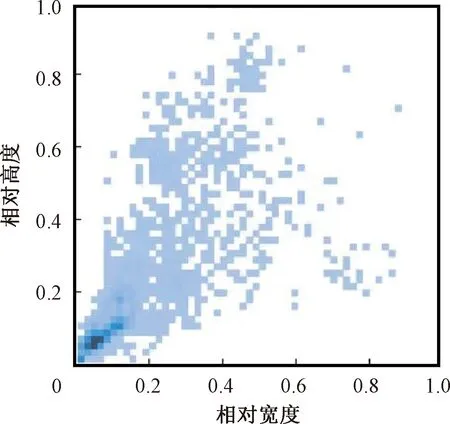
图6 标签框大小分布图Figure 6 Label box size distribution
3.2 实验环境与配置
本文通过搭建PyTorch深度学习框架对自定义数据集进行训练和测试。操作系统选用Windos10专业版21H2,CPU为Ryzen 5800X,GPU为GeForceRTX3060Ti,显存为8 GB,内存为32 GB,CUDA版本号为11.1.1,PyTorch版本号为1.8.0。
实验中训练参数设置如下:输入图像尺寸为像素640×640,batch size为16,epoch设置为100。
3.3 实验结果的评价指标
本实验中采用mAP0.5、参数量(parameters)、复杂度、精确率P(precision)、召回率R(recall)和帧率等指标[13]作为模型性能的评价指标。其中复杂度用GFLOPs衡量,1 GFLOPs=109FLOPs,FLOPs(floating point operations)为浮点运算数,可以衡量模型的复杂度。
3.4 实验结果和分析
在训练阶段,选用Ultralytics6.0版本的YOLOv5s模型作为基准模型,使用上述数据集对YOLOv5s模型与本文算法进行重新训练,以下所示结果均为采用同一数据集得出。
为了提升对火灾初期小的火焰目标的检测效果,加入小目标检测层模型A与YOLOv5s对比如表1所示。加入小目标检测层后mAP0.5提升0.9百分点,R提升1.2百分点,由于增加了网络的深度,导致模型复杂度上升,帧率有所下降。
加入小目标检测层后,置信度损失有较大的下降,置信度损失曲线如图7所示。随着迭代次数的增加,本文算法的置信度损失曲线明显收敛更快、损失值更小。
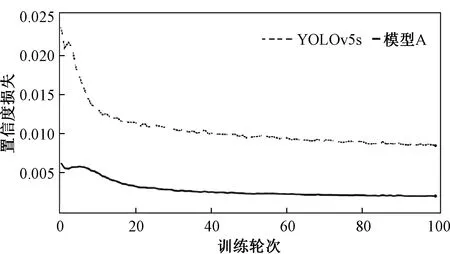
图7 置信度损失曲线Figure 7 Confidence loss curve
通过以上实验,说明采用小目标检测层虽然帧率有所降低,但是对火焰目标的置信度误差大大降低,对于小的火焰目标的检测置信度和对网络的检测精度有所提升。因此,通过增加FPN+PAN的网络深度,以及增加小目标检测层,能够有效提升网络对小目标的检测效果。
为了加强检测网络对火焰目标的特征提取能力,在网络加入改进的注意力模块,并与主流的SE注意力机制、CBAM注意力机制、原CA注意力机制进行对比,以验证本文改进结构的性能,结果如表2所示。其中,本文模型B的mAP0.5最高,相较于YOLOv5s网络,mAP0.5有1.8百分点的提升,R提升1.4百分点;与主流的注意力机制SE、CBAM机制相对比,模型B检测精度及检测速度均最高;与C3CA、CA结构相对比,模型B的mAP0.5分别提升0.9百分点、1.8百分点,R分别提升2.8百分点、0.5百分点。
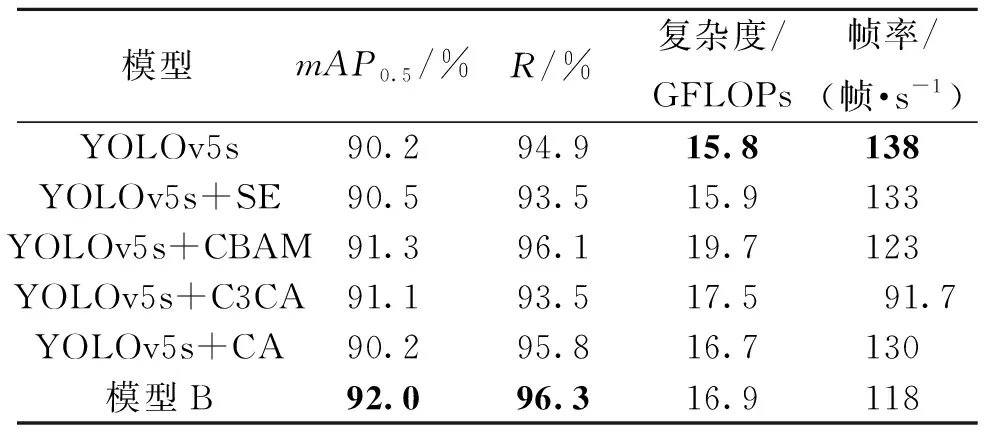
表2 消融实验2数据表Table 2 Data sheet of ablation experiment 2
为了验证CIoU替换YOLOv5s中GIoU后的效果,实验3对比了YOLOv5s替换目标框损失函数前后的表现,如表3所示。使用CIoU损失函数后,mAP0.5有0.6百分点的提升,R提升2.3百分点,可见CIoU能够显著提升模型的召回率。并且可以优化模型的检测速度。

表3 消融实验3数据表Table 3 Data sheet of ablation experiment 3
对各个模块的有效性及性能进行验证后,与目前主流的目标检测算法YOLOv3、YOLOv5s以及YOLOv5m进行对比,对比结果如表4所示。
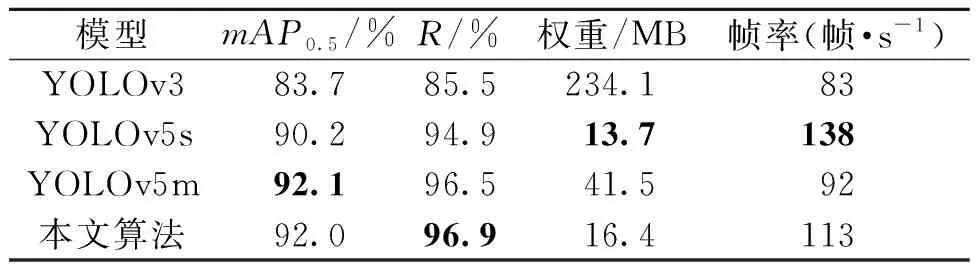
表4 主流目标检测算法对比Table 4 Comparison of mainstream target detection algorithms
实验表明,本文算法在地下停车场火焰目标检测任务上可达到mAP0.5为92.0%的检测精度。相较于未改进前的YOLOv5s算法,本文算法的mAP0.5有1.8百分点的提升,R有2.0百分点的提升,虽然牺牲了一部分的检测速度,但是得到了具有更好检测精度的模型。相较于YOLOv5m算法,虽然两种算法在精度上相当,但是本文算法具有较高的召回率R以及较高的帧率,具有较快的检测速度,且本文算法权重仅为16.4 MB,远远小于YOLOv5m的41.5 MB,对检测设备的配置要求更低。
为了更好地验证本文算法对于小型火焰目标的检测性能,从测试集中选取部分图像数据进行测试,如图8所示。在图8(a)中,本文算法在检测精度上明显高于原始模型。在图8(b)中,YOLOv5s出现了漏检,无法可靠地检测出目标,而本文算法能够准确地检测到火焰目标,主要是因为本文模型增加了小目标的检测层,从而具有更强的分辨力,能够更准确地检测到小型火焰目标。在图8(c)中,YOLOv5s模型没有正确框选出火焰目标,而本文算法能够准确地框选出火焰目标,这归结于坐标注意力机制带来了较大的感受野,增加了模型对火焰的感知能力,并且CIoU损失函数能够提升预测时的定位精度。
4 结论
目前地下停车场缺乏成熟的视频火灾检测算法,已有的技术依赖传感器等设备,且无法针对火灾初期小型火焰目标做出快速反应,本文提出一种改进的YOLOv5火灾检测算法。
为增强对小型火焰目标的检测性能,增加小目标检测层,提升了检测网络对小型火焰目标的检测效果;为提高模型对火焰特征的提取以及获得更大的感受野,提出了一种新的间隔注意力结构,进一步提升了网络对火焰目标的特征提取能力,且相较于C3CA、CA结构,本文改进模型具有复杂度较低、精度高的特点;为了提升定位精度、降低目标漏检率,使用CIoU损失函数,提升了网络的回归性能。在实验设备不变的情况下,本文算法与原YOLOv5s相比,mAP0.5提升了1.8百分点,召回率R提升了2.0百分点,本文算法权重大小仅为16.4 MB,帧率在本文实验环境下能达到113帧/s。
实验表明,本文算法对火焰目标较小的情况也能够正确检出,具有较高的精确率和召回率、较小的模型体积,易于部署,基本能够满足地下停车场对火灾实时检测的要求。
