基于改进YOLOv5的轻量化口罩检测算法研究
2023-07-03黄家興南新元张文龙徐明明
黄家興,南新元,张文龙,徐明明
(新疆大学电气工程学院,新疆 乌鲁木齐 830049)
1 引言
自2019年12月以来,由新型冠状病毒(COVID-19)导致的肺炎疫情已经蔓延至多个国家和地区,造成了不可估量的损失,影响着人们的安全和健康。截至目前,国内新冠疫情虽然已得到基本的控制,但是面对外部环境的多变性和复杂性,疫情的防控工作依旧面临着严峻的挑战。新冠病毒与以往传染病的不同之处在于,它可以通过气溶胶传播,在短的时间内接触并感染人。研究发现,佩戴口罩等防护用具可以有效地减少被传染的风险。因此,要求人员在乘坐公共交通(火车、地铁、飞机等)和人员聚集场所(商场、医院、农贸市场等)必须佩戴口罩。但是以人力进行监督和提醒又会增加相关人员被感染的风险,因此开发一套人脸口罩检测系统对于疫情防控有着至关重要的意义。
截至目前,目标检测领域主要分为基于回归思想的one-stage算法和基于候选区域的two-stage算法两种。其中one-stage算法中以YOLO系列[1-4]和SSD系列[5]为代表,极大的提高了检测速度但检测精度较差;而two-stage算法中以Fast-CNN[6]和Faster-CNN[7]为代表,有较高的检测精度,但由于其模型复杂导致检测速度较慢。随着深度学习的快速发展,越来越多的基于目标检测的算法被部署到嵌入式设备上以实现目标检测,所以要求算法有较快的检测速度和较高的检测精度。YOLO系列是目前使用较为频繁和成熟的目标检测算法之一,从YOLOv1到YOLOv5,该算法经过大量学者优化和验证,逐渐弥补了因提高检测速度而下降的检测精度,使其兼顾检测速度的同时,又能保持较高的检测精度。
目前,国内外用于检测口罩佩戴情况的算法较少。文献[8]以YOLOv3为框架引入注意力机制SENet[9]进行特征提取,并使用特征金字塔FPN[10]进行特征融合,提高了检测精度。文献[11]在YOLOv3原有的基础上增加了一个检测头,用以提高对小目标的敏感度进而提升算法的精度,但是也导致了算法参数量的暴增。文献[12]以YOLOv4为框架提出了一个MaxMoudle结构用以获取目标的更多特征进而提高检测精度。文献[13]用MobileNetv3替换了原YOLOv4的主干特征提取网络用以减少模型的参数量,并用SiLU激活函数替代了MobileNetv3浅层网络中的ReLU激活函数以提高其收敛性,最终算法取得了较高的检测速度但牺牲了检测精度。文献[14]提出了一种以MTCNN算法进行人脸关键点定位,并使用MobileNet进行检测和分类的口罩检测算法,该算法可以在人脸倾斜、面部遮挡严重及采光不足等多种复杂环境下取得较高的精度,但是其检测速度较慢。文献[15]使用RetinaFace算法检测人脸关键点并提取人脸的鼻尖区域,而后使用YCrCb椭圆肤色模型去判断鼻尖位置皮肤的暴露情况,以此设定阈值来判断是否佩戴口罩,但是该方法在复杂环境下鲁棒性较差,尤其是当佩戴与肤色相近的口罩时较容易造成误检。
本文针对上述算法中存在的问题,提出了一种改进型轻量化YOLOv5人脸口罩检测识别算法。主要改进如下:
1)针对YOLOv5主干特征提取网络参数量大和特征提取不充分的问题,使用了EfficientNetV2轻量化网络进行替换,降低了模型的参数量,大大提高了网络的训练速度。
2)提出使用ECA模块去替换EfficientNetV2中原有的SE注意力模块,进一步降低模型参数量和提高模型的收敛性。
3)提出使用DIoU-NMS替代原YOLOv5模型中加权NMS的方式,提升了对遮挡目标的检测效果,并在删除冗余预选框上具有更好的效果。
4)构建口罩数据集,验证本文算法的有效性。
2 相关研究
2.1 YOLOv5基本理论
YOLO是一个基于回归思想的one-stage算法,它将目标检测重新定义为回归问题,从而提高检测速度。YOLOv5是YOLO系列中最新提出来的算法,相较于YOLOv3、YOLOv4,其在保持精度的情况下还能拥有更小的结构,权重更小,更易于布署到移动端设备。如图1,YOLOv5的网络结构分为三部分:Backbone, Neck, Head。在主干中,输入图像分辨率为416×416×3,通过Focus结构进行切片操作,它首先成为208×208×12 Feature map,然后经过32个卷积内核的卷积操作,最后成为208×208×32 Feature map。CBL模块包括Conv2D、BatchNormal和LeakyRELU。BottleneckCSP模块主要对特征图进行特征提取,从图像中提取丰富的信息。与其它大规模卷积神经网络相比,BottleneckCSP结构可以减少卷积神经网络优化过程中的梯度信息重复,它的参数量占据了整个网络的大部分参数,通过调整BottleneckCSP模块的宽度和深度,就可以得到四种不同参数的模型,如YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。SPP模块主要是增加网络的感受野,获取不同尺度的特征。YOLOv5的Neck中采用PANet[16]作为其特征融合网络,该网络可以有效地利用细节特征信息,来提高网络对不同尺度目标的检测能力。

图1 YOLOv5系统框架
2.2 EfficientNetV2基本理论
Tan Mingxing等[17]在2019年提出了一种简单高效的网络模型结构EfficientNet。通过使用复合系数来实现多维度混合模型的缩放,该方法通过平衡网络的深度、宽度和图像分辨率三个维度的放缩倍率(d,r,w)使网络取得更好的性能。EfficientNet的网络架构借鉴了MnasNet[18],采取了同时优化精度及计算量的方法,选择只在小模型上进行网络搜索,大大的减少了计算量。EfficientNetV2[19]是该作者在EfficientNet基础上进行改进之后提出的新模型。该模型可以有效解决EfficientNet训练过程中存在的三个问题:当训练图像的尺寸很大时,训练的速度非常慢;在浅层网络中使用DepthwiseConvolution训练时速度会很慢;同等的放大每个stage是次优的。针对以上三个问题,EfficientNetV2引入了Fused-MBConv模块和改进的渐进式学习方法,该方法根据训练图像的尺寸动态调节正则方法,相较于EfficientNet,EfficientNetV2在训练速度上提升了11倍,模型的参数量降低了6.8倍。表1为EfficientNetV2的网络结构,图2为MBConv和Fused-MBConv模块的结构图。由表1可知,其特征提取网络包含一个3×3卷积,3个Fused-MBConv模块和4个MBConv模块。其中Fused-MBConv模块相较于MBConv模块,用一个3×3的卷积替换了MBConv中的1×1卷积和Depthwise Convolution3×3卷积,原因在于Depthwise Convolution不能充分利用模型进行加速。而在浅层网络结构中加入Fused-MBConv模块能带来模型在训练速度、精度和浮点计算量上的一个提升[19]。

表1 EfficientNetV2网络结构
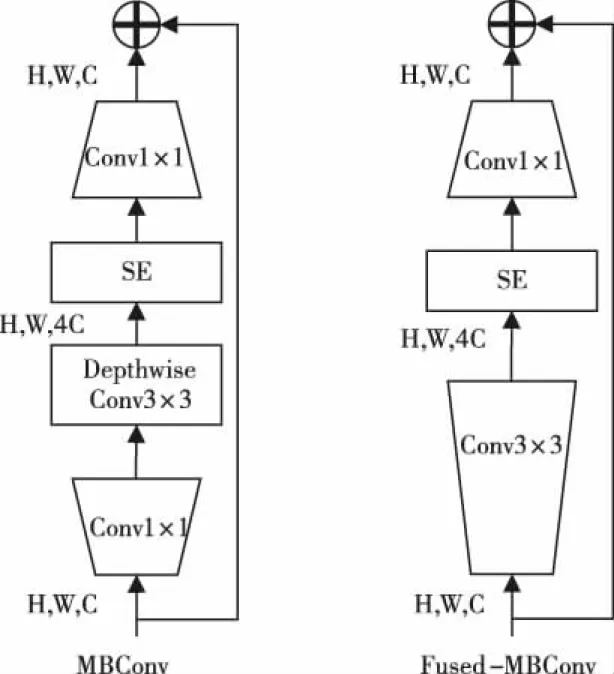
图2 MBConv和Fused-MBConv结构图
3 YOLOv5-Mask口罩检测算法
3.1 YOLOv5-Mask网络结构
本文提出了一种改进YOLOv5的新网络结构,简称YOLOv5-Mask网络结构,如图3所示。输入图像尺寸为416×416×3,该结构的Backbone是以改进的EfficientNetV2网络作为特征提取网络,在Neck部分,本文通过C3单元替换原结构中的BottleNeckCSP单元,C3单元是由CBL组成的一个网络结构更深的残差结构,网络结构如图4所示,通过Concat层和Add层可以完成CBL模块和上采样层的张量拼接,增加特征的复用。

图3 YOLOv5-Mask网络结构图
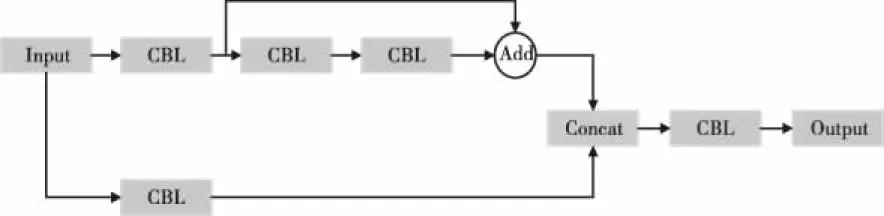
图4 C3单元结构图
3.2 改进的EfficientNetV2网络
在EfficientNetV2网络结构的MBConv模块和Fused-MBConv模块中,均采用的SE通道注意力机制。但是该机制中降维对于学习通道注意力非常重要,需要适当的跨信道交互才可以在降低模型复杂度的同时保持性能。所以本文提出了使用了一种不降维的局部跨信道交互策略ECA模块[21]去替换原MBConv模块和Fused-MBConv模块中的SE模块,如图5。ECA模块可以在不降低通道维数的情况下进行逐通道全局平均池化,通过考虑每个通道和它相邻K个通道的信息来捕获局部跨通道交互信息,避免特征完全独立,其结构如图6。

图5 改进后的MBConv和Fused-MBConv结构图

图6 ECA结构图
为了避免通过交叉验证手动调整K,设计了一种自适应地确定K的方法,内核大小K 自适应描述如式(1)所示

(1)
其中|t|odd奇数表示最近的奇数t,本文在所有实验中分别将a和b设置为2和1。从公式可以看出,高维通道具有较长的相互作用,而低维通道则具有较短的相互作用。
3.3 DIoU-NMS在改进网络中的使用
与传统的NMS不同,DIoU-NMS将DIoU视为NMS的准则,因为不仅考虑重叠区域的IoU值,还应考虑了两个盒子之间的中心点距离,认为两个中心点较远的盒子可能位于不同的对象上,而不应将其删除。如式(2),本文使用该公式来决定一个盒子是否被删除,对于具有最高分的预测盒子,DIoU-NMS的ki更新公式定义为:
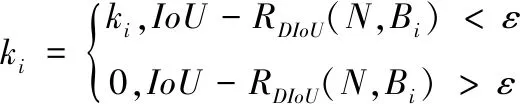
(2)

(3)

(4)
式中,IoU表示预测框与真实框的交并比;ρ2(b,bgt)表示边界框和真实框中心点之间的距离;c2表示两个框中最小封闭矩形框的对角线长度;ε是手动设置的NMS阈值;B为检测盒子;ki是分类得分。
4 实验结果分析
4.1 实验参数设置
本文实验环境为Windows10操作系统,运行内存16G,CUDA版本10.1,GPU采用NVIDIA GTX2060 6G,CPU采用I7-10875H处理器,深度学习框架为Pytorch 1.7.1,编译环境为Pycharm/Python。本文算法的训练参数设置为:batch size为4,最大迭代次数为200,优化策略采用SGD函数,动量0.937,初始学习率为0.01,权重衰减设置为0.0005,学习率衰减采用余弦退火衰减算法。
4.2 数据集介绍
本文所使用的口罩数据集定义了三个类别:T_Mask、N_Mask和F_Mask,分别对应正确佩戴口罩、没有佩戴口罩和错误佩戴口罩。由于现有公开数据集中主要定义类别为戴口罩(Mask)和不戴口罩(NoMask)两类,所以本文数据集主要分为两个部分。第一部分来源于公开数据集MAFA和Wilder Face数据集,该部分主要对两个公开数据进行筛选并删除误标和错标的图片整理所得。第二部分为自建数据集,采集对象为校园内不同场景下的行人,通过录制视频进行定时帧截取,然后使用标签标注工具LabelImg软件进行标签标注,用以扩充错误佩戴口罩的样本数量,避免造成训练样本不均衡,部分图片如图7所示。本文数据集共包含3504张图片,按8:2随机将700张图片作为验证集,剩余2804张图片作为训练集。

图7 部分数据集示例
4.3 评价指标
本文算法旨在对疫情期间行人佩戴口罩情况进行检测,对没有规范佩戴口罩的行人发出提醒,若存在漏报误报等情况可能会导致病毒的传播扩散,因此选择合适的评价指标对本文算法有较为重大的意义。本文采取的评价指标包含召回率R(Recall)、精准率P(Precision)、平均精度均值mAP(mean average precision)、模型参数量(Params)和推理时间FPS作为评价指标,来评估模型的泛化性能,其定义所示

(5)

(6)

(7)

(8)
其中,tp表示分类正确的正样本数,fp表示误将负样本分类为正样本数,fn表示分类错误的正样本数,ts表示推理单张图片消耗的时间。
4.4 实验结果分析
将本文算法与YOLOv3-tiny、YOLOv4-tiny和YOLOv5s进行对比,所有算法均采用通用的锚点框比例,训练epoch均设置为200,实验对比结果如表2和图8所示。

表2 不同结果算法对比
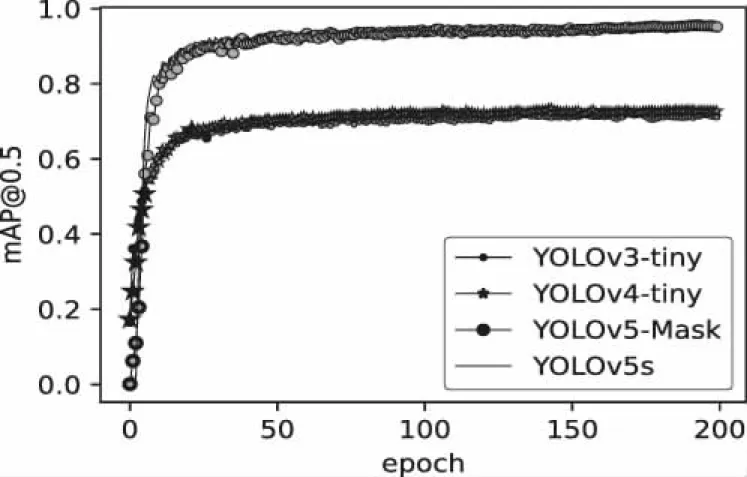
图8 不同轻量算法的mAP对比
由上表2中5类检测指标可以看出:本文算法与YOLOv3-tiny和YOLOv4-tiny和YOLOv5s模型相比较,在检测精度上,分别提高了32.8%、30.4%和1.2%,模型大小分别降低了79.0%、67.1%和45.7%。本文算法相较YOLOv3-tiny虽然推理速度降低了18.9%,但本文算法依旧满足口罩检测的实时性要求。综上所述,本文算法通过使用改进后的EfficientNetV2特征提取网络替换YOLOv5网络结构中的Backbone,降低了模型的参数量,大大提高了网络的训练速度,通过加入ECA注意力模块进一步降低模型的参数量并提升特征提取效果,通过使用Mosaic数据增强提高对小目标的检测能力,最后通过使用DIoU-NMS改善了遮挡目标的检测效果,提升了系统的检测性能。本文算法在减小模型参数量的基础上提高了1.2%的检测精度,同时也保持了较高的推理时间,更适合部署于移动端。最终,实验结果表明了本文算法的有效性。
改进前后模型对比效果如表3所示,其中①表示YOLOv5s原模型,②表示使用EfficientNetV2特征提取网络替换YOLOv5模型的Backbone融合之后的模型,③表示在模型②的基础上引入了ECA通道注意力模块,④表示在模型③的基础上引入了DIoU-NMS。可以看出,使用EfficientNetv2替换YOLOv5的backbone后,参数量减少了43.9%,mAP提高了0.5%。当引入ECA通道注意力模型后,其模型复杂度更低,推理速度得以提高。最后引入DIoU-NMS,提升了对遮挡目标的检测性能。最终,本文算法的mAP@0.5提高了1.2%,模型大小降低了45.7%,FPS达到了270.3。综上所述,本文所提出的方法满足实际检测场景的实时性和准确性要求,且模型体积更小、计算需求更低,更适合部署在计算资源不足的移动设备上。

表3 消融实验
为了直观的说明不同算法之间的区别,本文选取部分图片进行对比分析,如图9。

图9 不同算法检测效果对比图
由图9可看出,YOLOv3-tiny算法和YOLOv4-tiny算法均存在漏检和误检情况,且检测框位置偏差严重,YOLOv5s算法存在冗余检测框,而本文算法弥补了以上缺陷,取得了较好的检测结果。因此,本文所提算法更为适合规范佩戴口罩检测任务。
5 结束语
本文提出了一种基于YOLOv5-Mask轻量化网络为核心的规范佩戴口罩检测算法。提出了通过使用改进的EfficientNetv2替换原YOLOv5网络中的主干特征提取网络,使用ECA通道注意力模块替换原网络中的SE注意力模块,并使用DIoU-NMS替代原YOLOv5模型中加权NMS的方式,减小了网络模型的参数量,提高了模型的收敛性和精度,并提升了对遮挡目标的检测效果。最后,基于网络公开和自然场景下的口罩数据集的试验结果表明,本文提出的轻量化YOLOv5-Mask口罩检测算法在模型参数量下降了45.7%,mAP达到了95.3%,推理速度达到了270.3FPS。相比于其它轻量化网络,本文提出的算法在减少参数量的同时还能够保持较高的精度,更适合部署在计算资源不足的移动设备上,去有效识别人员是否规范佩戴口罩,来实现对人员的有效监控。
