嵌入句法信息在汉蒙非自回归机器翻译应用
2023-07-03程永坤苏依拉仁庆道尔吉
程永坤,苏依拉,王 涵,仁庆道尔吉
(内蒙古工业大学信息工程学院,内蒙古 呼和浩特 010080)
1 引言
机器翻译的研究由来已久,从基于规则翻译到基于统计机器翻译再到神经机器翻译[1],其思想是借助计算机使一种语言转换成另一种语言且保持含义不变,翻译的理想目标是能达到高速度高质量的效果。机器翻译的快速发展可对不同民族文化交流产生重大意义,促进民与民,国与国的共同体发展理念。
由于对汉蒙翻译研究起步较晚,所以在如今的汉蒙机器翻译研究中存在着很多问题亟待解决,一方面,汉蒙双语属于低资源语言,故存在汉蒙平行语料库资源不足,且现有的语料库多有低频词和稀有词存在造成语料质量差出现翻译质量低的现象; 另一方面,对于汉蒙翻译的研究模型现在多是自回归神经翻译(AT)模型,该模型不能很好的利用GPU的计算能力,同时在翻译中出现解码信息错误前后传递性问题。针对以上问题的存在,对于像汉蒙这样的低资源语言研究,在翻译速度和翻译质量上都没有取得令人十分满意的效果。
直接使用AT模型进行本文研究并不能得到理想化的实验结果,故提出使用非自回归机器翻译(NAT)模型,该模型能直接进行并行解码推理,充分的利用到GPU的计算能力。同时为使翻译质量得到提升,将生成对抗网络[2,3]应用到语料训练中,利用生成器生成难以分辨的假样本序列,并将生成样本和真实样本输入判别器中进行判断,提出用判别二分类结果加上双语BLEU值反馈给生成器模型进行优化;然后,利用教师模型知识蒸馏汉蒙语料,将提取出的目标句子蒙古语与源句子汉语重新组合成新语料供NAT模型;最后,借助句法解析器斯坦福CoreNLP得到词汇间的句法关系,构建成图,用图卷积神经网络(GCN)[4]学习句法图中句子里单词上下文信息,并首次提出将学习到的句法信息融入到非自回归机器翻译模型中的嵌入层,从底层开始改善非自回归翻译模型的翻译效果。
2 相关模型
目前机器翻译使用模型大体可分为两类,一类以循环神经网络和基于Transformer改进的一系列自回归机器翻译模型;另一类是本文使用的非自回归机器翻译模型。但研究最多的还是自回归机器翻译模型,尤其是在语料丰富的语言中如中英双语。在自回归机器翻译模型中以Transformer模型最为优秀,2017年末经Google提出就在NLP领域造成巨大影响,完全的借助注意力机制对源端的输入和目标端的输出关系进行建模,并打破了RNN模型编码器在训练时不能并行计算的问题。
2.1 自回归机器翻译模型Transformer
NMT模型的研究是从Simple RNN开始,到后来注意力机制的发现,随后在一篇《Attention is All You Need》论文中提出Transformer模型,该模型对注意力机制进行了充分的利用,使其编码端能一次对源语言并行编码处理,很多实验中Transformer模型都被作为优先选择来使用。
本文考虑到Transformer模型优秀的性能存在,故选其作为实验中的基线模型[5],下图1为模型中编码端的一个子Encoder模型结构。

图1 Encoder结构
每个能够并行编码的Encoder模块都是由Multi-Head Attention和Feed forward network决定,其中Multi-Head Attention类似多个Attention同时进行,Attention之间的Q、K和V均不同,最后将多个Attention的输出进行拼接,经过多头注意机制的处理可以获得词与词之间更多联系信息。相关计算如下
Attention_output=Attention(Q,K,V)
(1)
MultiHead(Q,K,V)=
Concat(head1,head2,…,headn)W0
(2)
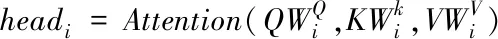
(3)

在上述并行编码计算过程中,可看出该模型相比RNN模型在现今的机器翻译研究中具有一定的优势,因此,Transformer模型不仅被选作本文研究中的基线模型,同时还作为接下来的教师模型来进行知识蒸馏处理。下图2 为Transformer整体结构。

图2 Transformer结构
2.2 非自回归机器翻译模型
NAT模型的研究目前是以Transformer为基础进行改进,与自回归模型相比,区别体现在解码端,删除了Masked Multi-Head Attention[6],添加了位置注意力机制,产生的效果即解码端可并行解码,但解码过程中的目标语言词汇不存在联系,造成翻译速度提高翻译质量明显下降现象。基于以上问题,出现了一系列的解决方案,2018年Gu等人[7]提出NAT模型理念时,即提出增加一个Fertility Predictors块预测目标长度和提供解码器的输入;Yiren Wang,Fei Tian等人添加辅助正则化项,即通过解码器隐藏状态相似远离的原则提高翻译质量;Xiaoya Li,Yuxian Meng提出基于“环顾”解码和字典关注的方式,即解码时让当前信息能提前预知周围的信息,从而抑制重复性翻译和漏译现象;Chunqi wang等[8]提出半自回归机器翻译,将自回归和非自回归结合起来抑制非自回归机器翻译不足现象。针对NAT模型现存问题的解决方案可从三个方向进行思考:基于latent variable方向[17]、基于Iterative Refinement方向、基于knowledge distillation方向。
NAT模型最大的问题是目标语言词汇间的联系缺失造成翻译的多峰问题。在增强词汇信息联系方面AT模型做的比较好,葛东来等人[9]提出利用AMR解析语义角色信息;王振晗,何健雅琳等人[10]利用句法解析器融合源语言句法信息。本文在综合以上AT模型所用方法后提出在NAT词嵌入层中融入句法信息。
NAT模型结构隶属于序列到序列。编码器端在顶层上增加Fertility Predictors模块,解码器端移除Mask操作同时添加位置注意力机制,嵌入层中融入句法图卷积神经网络(SynGCN)。下图3为研究模型NAT结构所示。
研究中在解码端可根据式(4)将NAT模型的解码问题进行建模处理,利用式(5)可表示出解码端的概率输出。

(4)

(5)
其中,T表示目标序列的长度,X=(x1,…xT′)表示源语言,T′表示源序列长度,Z表示隐变量,yt表示要一次解码的目标信息。
相关研究试图学习词汇上下文信息进行单词嵌入,却出现词汇量明显增加。本文为抑制上述情况出现,对语料句子中的句法信息首先进行构图处理,然后借助图卷积神经网络进行编码,在不增加词汇量的前提下将句法信息融合到词嵌入层中,下图4为SynGCN词嵌入结构[11]。

图4 SynGCN词嵌入结构
3 相关技术
3.1 生成对抗网络
生成对抗网络主要由生成器和判别器两部分组成[12]。文中生成器是基于双向LSTM模型,负责生成假样本,而判别器选择卷积神经网络,利用其二分类器判别输入的真假样本,在训练过程中通过二分类器的取值和译文质量BLEU值反向指导生成器模型中的参数优化。
在生成器生成句子长度不相等情况下,用CNN对句子进行增删处理,使其长度统一固定在T。基于双向LSTM模型的生成器遵循着由源语言序列生成目标语言序列输出假样本,在判别器中,首先根据源语言和目标语言生成对应源矩阵X1:T和目标矩阵Y1:T,然后对源矩阵通过卷积计算得到相应的一系列特征向量cij,对不同卷积核得到的特征向量进行最大值池化,再将特征向量池化结果进行拼接得到源序列向量表示cx,同理可以获取目标序列向量表示cy,最后利用取得结果来计算样本的真实概率P,相应计算过程如下。
X1:T=x1;x2;…;xT
(6)
Y1:T=y1;y2;…;yT
(7)
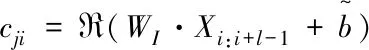
(8)
cx=[c1,c2,…,cT-l+1]
(9)
p=ς(V[cx;cy])
(10)
其中xt,yt∈Rk,属于k维词向量,卷积窗口WI∈RlXk,R表示Relu函数,ς表示Softmax函数, V表示转变矩阵。
研究中,利用译文质量BLEU值和判别器对样本评测结果来反向指导生成器生成更真样本,具体训练过程可借助文献[2]中GAN算法训练策略思想进行,在此不做叙述。
3.2 知识蒸馏
目前机器翻译还在“数据驱动”阶段,在模型训练中,多是利用大规模数据进行特征提取改善翻译模型的质量,使的研究成本大大提高。因此对于NAT模型翻译的语料,利用教师模型借助知识蒸馏技术来提高语料的精确度而不是利用大规模数据[13]。本文利用知识蒸馏将一个大规模、高精度的教师模型Transformer能力传递到小规模,低精度的学生模NAT。具体是利用Transformer模型输出Softmax层的temperature参数调整来获得一个合适的软目标集,然后对本文用的学生模型NAT利用得到的软目标集配合对应temperature参数作为总目标函数的一部分进行学生模型的训练,提高学生模型的泛化能力。对应流程如下图5所示。

图5 知识蒸馏流程
根据图5知识蒸馏流程过程可归纳如下:
1)选择一个泛化能力强翻译质量高的模型作为教师模型,本文以Transformer模型;
2)对现有蒙汉语料库先进行数据处理,然后借助Transformer模型进行预测得到数据集;
3)用步骤2)中获得的知识来训练新的模型即学生模型,本文使用的是带有隐变量的NAT模型。
3.3 图卷积神经网络
图卷积神经网络是在卷积神经网络(CNN)的基础上进一步提出来的概念,它们都被用来进行特征提取,不同之处在于CNN无法对不规则的结构进行操作[14],如图结构,而GCN则不存在这样的问题。利用提取出来的特征信息有助于节点分类、边预测、图分类和图嵌入表示等相关方面。


(11)

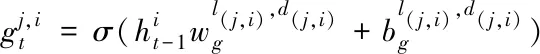
(12)

(13)


(14)

4 实验
4.1 数据预处理
所选语料库为内蒙古大学现有67288句蒙汉平行语料库、购买的“基于深度学习的蒙汉统计机器翻译的研究与实现”平行语料库120万句。蒙古语词是由词干和词缀组成[15],且词缀有限,而词干无限,故组成复杂多变的蒙古语词。预处理时,首先筛除句长单词大于25的句子,其次,蒙古语句具有天然的分割符,故直接使用BPE[16]切分,而汉语不像蒙古语那样词汇间有空格,则先利用Jieba进行分词,然后再利用BPE进行切分。最终实验使用的语料库为1072776句。表1是数据集划分。

表1 数据集划分

表2 数据集结果
4.2 仿真环境
开发系统为Ubuntu 16.04,Python版本为3.6.0,TensorFlow版本1.6.0。模型参数配置方面,模型层数N=6,多头注意力设置为8头,隐藏层大小为512,Adam负责优化参数,dropout设为0.3,学习率设为0.01,train_steps为200000, batch-size设置为4096,epoch为30,最后使用BLEU和TIME进行评估。
4.3 仿真结果
本文进行了基线模型Transformer,文献[7]模型NAT,知识蒸馏后非自回归模型,嵌入句法信息的非自回归模型在train_steps上的实验,图6、7为4个模型在实验时得到的BLEU值和TIME值。

图6 模型BLEU值
通过图6,图7 可以看到本文在引入句法信息后,无论是在翻译速度还是在翻译质量都得到了保证。以下用表格的形式来表示4个模型的具体结果。
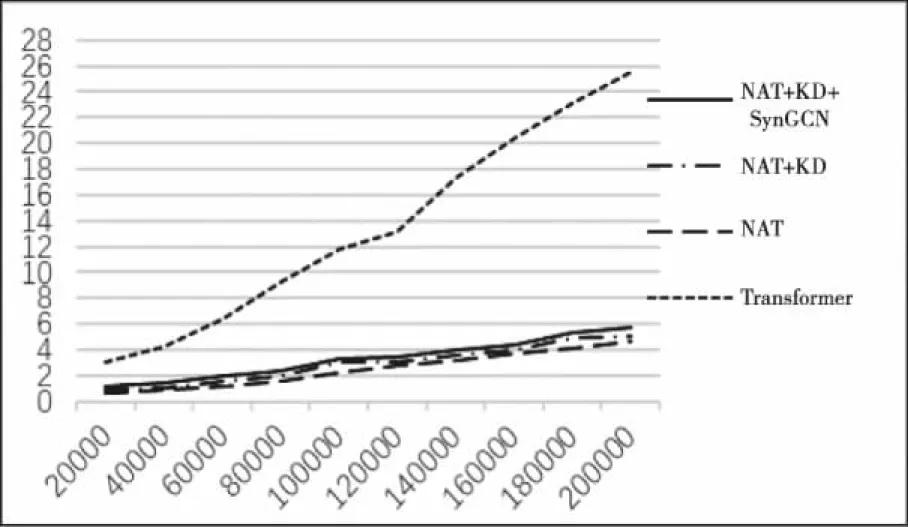
图7 模型TIME值
通过表格2可以得出,以文献[7]模型进行的相关实验在翻译时间上相比基线模型都明显缩短,最高达到20.97个小时,本文的研究方法NAT+KD+SynGCN也提高19.96 个小时。但从表格中看到文献[7]模型相比基线模型BLEU值降低很多,在进行知识蒸馏后实验,翻译质量同样无法改善,但本文研究方法NAT+KD+SynGCN,在保证翻译速度提高的前提下相比基线模型的BLEU值提高1.1,比文献[7]模型提高3.2。以上仿真数据证明,本文的研究方法在非自回归机器翻译的嵌入层中融入句法信息是有效的。
5 结论
本文提出使用NAT模型对汉蒙进行翻译,研究中对生成对抗网络进行优化,在训练中不仅使用判别器的结果指导生成器优化,还增加双语BLEU值作为生成器的目标函数来评估生成样本,其次,利用Transformer模型对得到的语料进行训练,降低生成目标语言句子的多模态,使本文研究模型更适用;最后,更是在NAT模型编码端的嵌入层融入图卷积神经网络,学习更多句法信息。未来方面将考虑如何把更多的语义[18]、语法信息融入到NAT模型中。
