基于LightGBM和LSTM指纹定位算法的研究
2023-07-03柴志远王小妮
柴志远,王小妮
(北京信息科技大学理学院,北京 100192)
1 引言
随着网络及移动通信技术的发展,人均一部手机已成为了现实,而在移动通信业务发展的过程中,无线定位技术[1]受到的关注度越来越多,基于位置的服务更是运营商们一直广泛关注的重点,因此对用户定位的需求占据了很高的地位。目前,无线定位技术主要包括GPS卫星定位,位置指纹定位技术、蓝牙定位技术、红外线定位技术以及超宽带定位技术等[2]
在众多移动定位的方法中,指纹定位技术[3]可以不受外界遮挡物,天气差异的影响,具有成本低、准确率高、抗干扰能力强等优点,得到了业界的广泛青睐。传统的指纹定位通常为基于WIFI的室内位置指纹定位,近年来,学者针对指纹定位提出了多种相关算法模型。吴虹[4]等人提出了一种基于KNN的室内定位算法模型,该模型具有良好的预测精度,但并未考虑到信号波动性对定位结果产生的影响;许甜[5]等人针对这一问题提出了一种基于离散系数改进的VWKNN位置指纹定位算法,使KNN指纹定位的准确率得到很大提升;文献[6]提出了一种基于RSS和CSI的混合指纹定位方法,该方法利用了卡尔曼滤波器和高斯函数,有效消除了噪声数据,实现了RSSI和CSI值的准确和平滑输出,从而提高定位的准确率;同时,为了解决室内定位系统中因环境动态变化而导致定位精度下降的问题,康晓非[7]等人提出了一种基于XGBoost(极端梯度提升)并融合弹性网的误差补偿算法,在变化的室内环境采用弹性网算法构建误差补偿模型,提高了定位算法的精度。上述算法使指纹定位具有可观的准确率,但所研究的均是基于WIFI的室内指纹定位。基于此,周志超[8]等人提出一种基于移动蜂窝网的机器学习室外指纹定位的算法,但定位准确性较低;李达[9]等人提出了基于LTE网络的室外指纹定位算法,但提出的算法并未考虑到海量数据模型,数据的纬度因素以及数据的时序性问题,因此,本文在此提出一种基于LightGBM算法和LSTM网络相结合用于指纹定位的模型,且所选数据为中国移动基站所收集到的用户数据。LightGBM算法是 常用的机器学习算法,是为了解决XGBoost在处理海量数据时空间复杂度和时间复杂度高等问题而提出的;LSTM网络模型是一种时间递归神经网络,它是RNN(循环神经网络)模型的变种实现,具备处理和预测包含时间序列数据的能力;文章结合两者的优点,构建利用基站数据预测指纹定位算法的模型。
2 构建预测模型
2.1 指纹定位算法介绍
作为一种监督学习的算法,指纹定位算法利用了每处位置多径结构(即电波传输过程中遇到障碍物会产生散射波,这些波会一起构成多径效应)唯一性的优点,在训练阶段,将每个位置的信号特征与该位置经纬度信息结合起来,构成一条指纹,合并多个位置的指纹并存储在指纹数据库中,以便于在线阶段的定位匹配[4]。利用基站数据进行指纹定位的实现如图1所示,其中(X,Y)是该位置的经纬度信息,ai,bi,ci……为该位置的特征信息。
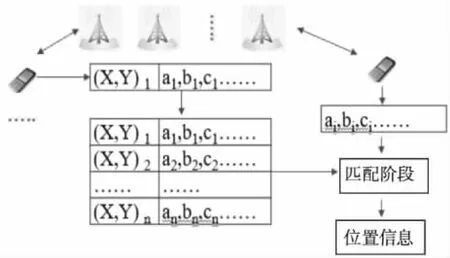
图1 指纹定位过程
2.2 算法模型介绍
2.2.1 LightGBM算法模型
LightGBM是一种用于分类的机器学习算法[10],该算法是XGBoost的改进算法,适用于数据量呈现出高维度的背景下。LightGBM的核心是GBDT (梯度提升树)算法[11],通过改进GBDT,并提出了GOSS (梯度单边采样)和 EFB (互斥特征捆绑)两种新方法,提高了算法的高效性。
GOSS算法给不同的样本点赋予不同的权值,计算信息增益时,梯度大的样本点具有更高的权值,梯度小的样本点,随机按照比例赋予权值,其算法描述如下:
step1:按照数据样本点梯度的绝对值,对样本点进行排序;
step2:选择一部分较大梯度的样本(此处为a%)作为较大梯度值的训练样本,从另一部分的样本中,再次随机一部分(设为b%)作为较小梯度值的训练样本;
step3:合并步骤二所得的样本,并给小梯度样本赋予权重;
step4:利用以上步骤得到的数据样本,通过学习得到一个弱学习器;
step5:重复上述步骤,当达到设置的迭代次数或收敛时,停止。
GOSS算法有效降低了模型学习的时间,在一定程度上提升了训练模型的泛化能力。
EFB算法被称为互斥特征捆绑,在实际应用中高维数据一般都是稀疏的,EFB被设计用于减少有效特征的数量,且样本中许多特征可能是互斥的,EFB还可以将这些特征组合成一个特征,降低特征的维度。
因此,LightGBM算模型引入了基于GOSS模型和EFB互斥特征捆绑等方法,优化了XGBoost算法耗时的缺点,并降低了需要处理数据的维度,研究表明,用此方法对数据进行处理,不但不会损失预测的精度,有时还会提高精度。
2.2.2 LSTM网络模型
LSTM是一种深度学习模型的框架,它是RNN网络的变种,为了解决RNN在对长序列训练时存在梯度爆炸和梯度消失的问题而提出的,LSTM网络结构和RNN的主要IO(输入和输出)区别如图2所示。可以看出,LSTM网络比RNN多了一路输入,一路输出和一个存储单元用于存储记忆[12]。
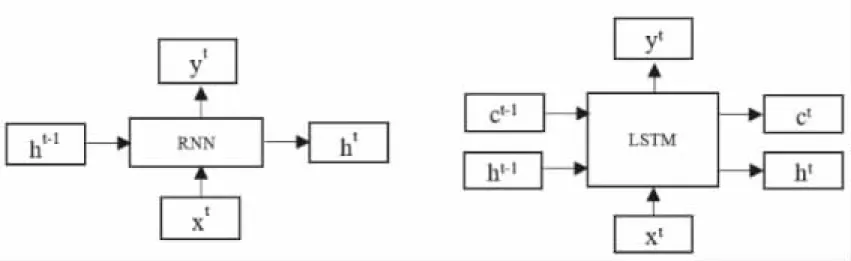
图2 RNN和LSTM网络结构
从图中可以看出,LSTM有两个传输状态,一个ct(细胞状态),对应于RNN中的ht和自身的一个ht(隐藏状态)。通常ct由上一个状态传过来的ct-1加上一些数值构成,而ht的区别往往会很大,LSTM网络的当前输入xt和上一状态的输出ht-1结合训练得到以下四个状态
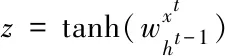
(1)

(2)

(3)

(4)
其中,zf,zi,zo是0到1之间的数值,作为一种门控状态。z的取值范围是-1到1(这里使用tan h是将其作为输入数据,而不是门控信号)。
LSTM内部图如图3所示,其中

图3 LSTM模型网络内部图
ct=zf⊙ct-1+zi⊙z
(5)
ht=zo⊙tanh(ct)
(6)
yt=σ(W′ht)
(7)
LSTM模型的内部有三个阶段,第一阶段为忘记阶段,此阶段会进行选择性忘记上一节点的输入,此处用zf来表示忘记门控,控制上一状态的ct-1需要忘记的东西;第二阶段为选择记忆阶段,此阶段将输入的一部分进行“记忆”,即对输入xt进行选择记忆,即对于重要的赋予高权值记录下来,不重要赋予低权值,当前的输入由计算得到的z表示,zi用于控制选择的门控信号,对以上两个阶段的结果求和,得到传给下一状态的ct,即为上式(5);第三阶段为输出阶段,此阶段决定当前状态的输出,由zo来进行控制,并缩放上一阶段所得到的co(通过tanh激活函数)。输出的yt最终通过ht变化得到[13,14]。
2.3 LightGBM+LSTM组合模型实验
为了提高用户位置指纹定位预测结果的准确率,并有效地预测带有时间序列的数据,同时解决对高维数据特征进行处理时,算法的时间复杂度高等问题,本文将LightGBM算法和LSTM模型进行组合用来实现用户指纹定位,组合方式此处选择误差倒数法并更新权值,误差倒数法即赋予误差大的模型较小权值,进一步减小了组合模型误差。计算公式为
fi=w1f1i+w2f2i
(8)
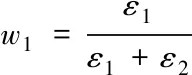
(9)

(10)
其中,εi模型i的预测误差,wk是赋予模型k的权值参数,fi即赋权后的目标组合模型对样本i的预测结果,fki是第k个模型的预测值[15]。同时,求出前m时刻权重平均值对本时刻模型进行赋权
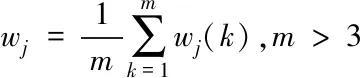
(11)
其中wj(k)为第k时刻组合模型的权值,计算该时刻组合模型的预测值与真实值的误差绝对值分别为eit,ejt,即

(12)

(13)
比较式(12)与式(13)结果的大小,若eit 图4 LightGBM+LSTM组合实现流程图 step1:对基站原始数据进行预处理,去除“脏数据”及无用数据处理,并对得到的结果归一化处理。 step2:设置LightGBM的learning_rate=0.05,early_stopping_rounds=80,num_boost_round=200,max_depth=5,对预处理的数据进行预测; step3:设置LSTM神经网络采用Adam随机梯度下降算法,学习率0.05,堆叠层数为5,批量大小为128,隐藏单元数为50,延迟阶数为3对第一步预处理的数据进行预测; step4:对第二步和第三步得到的结果利用误差倒数法加权求和并更新权重得到最终预测结果。 本文选择2019年5月5日12时北京移动基站所收集的用户信息(已去除用户手机号等隐私信息)及工参数据进行测试,测试数据包括数据获取时间(TimeStamp),小区ID(CellID),物理小区标识( SCPCI),频点(SCFreq),信号接收功率(SCRSRP),经度(Longitude),纬度(Latitude)以及一些相邻小区(邻区)的PCI,FREQ,RSRP等数据;工参数据包括源小区ID(src_eci),基础经度(base_lon),基础纬度(base_lat),基础偏移角度(base_angle)。数据每5分钟获取一次,一小时内共12次,样本部分数据如表1,表2所示。 表1 工参样本数据 表2 测试样本数据 3.2.1 “脏数据”及无用数据处理 上述所得数据,由于基站覆盖和网络等原因可能出现某些数据字段值为空或字段出现明显错误等问题,此类数据通常称之为“脏数据”,对于出现的“脏数据”,此处采用线性差值的方式将其补全或修改;同时,有些字段对于定位来说毫无用处,在此该类将字段直接去除,结果的部分数据如表3所示。 表3 数据预处理结果 表4 三种算法平均实现时间比较 表5 三种算法经纬度平均RMSE比较 3.2.2 数据归一化处理 由于所用的测试数据存在不同的量纲,可能会造成预测准确度下降的问题,在此对数据进行归一化处理[17],除经纬度和时间数据外,将其它数据的范围限制在0-100之间。 (14) 式中,y为归一化后所得的值,x为待处理数据值,Max为待处理数据最大值,Min为待处理数据的最大值。 本文使用RMSE(均方根误差)进行评估预测模型的准确率,RMSE是反映预测值y与真实值Y偏差平方与样本数n的比值的平方根,在一定程度上能够有效地测量预测结果的准确率,RMSE的公式如下[18] (15) 4.2.1 实验环境与实验数据 为了验证LSTM+LightGBM结合模型的准确率,实验在同一台计算机(Win10,32G内存,Inteli7-8750H)利用Python编程语言,JetBrains PyCharm Community Edition程序开发环境,建立LSTM+LightGBM相结合的模型进行仿真测试。选取北京市海淀区2019年5月4日的所有数据结合工参数据作为训练集,并随机选取北京市海淀区2019年5月5日12时去除位置信息的20000条数据作为测试集。 4.2.2 模型仿真 将LSTM+LightGBM模型预测得到的经纬度转换为距离信息随机取100条与真实位置进行比较,得到的经纬度距离上相差的结果分别如图5所示,结果表明,即使存在一些差异,结合的模型在预测地理经纬度等方面均具有较高的准确率。 图5 LSTM+LightGBM模型预测距离偏差 4.2.3 模型对比及分析 为验证构建模型的准确率和运行速度,分别构建KNN算法模型,XGBoost算法模型和LSTM+LightGBM组合的模型,实验数据取5组,分别为5分钟,10分钟,15分钟,20分钟,25分钟部分数据,利用构建的三种算法模型对数据进行多次仿真;三种预测模型在平均实现时间和平均RMSE方面的比较如下表所示,经纬度RMSE计算公式为 (16) 其中,RMSElat为经度的平均RMSE,RMSElon为纬度的平均RMSE,此式能够在一定程度上反映出实际距离的误差值。 由仿真结果得,即使将两种模型进行结合,在运行速度方面,由于LightGBM模型中采用了直方图算法和leaf-wise的生长策略,LSTM+LightGBM模型运行速度仍明显优于KNN算法和XGboost算法;且由于引入LSTM与LightGBM结合来减小误差,在最终实现的精度方面,LSTM+LightGBM模型最高,在测试数据集为25min部分数据时,本文提出模型的RMSE达到0.00017,约为实际距离的15-25米,具有很高的应用价值。 文章提出了一种基于LightGBM和LSTM结合的分类模型用于用户位置指纹定位的实现,通过对基站收集到的用户数据进行预处理,将得到的结果传入LightGBM模型和LSTM模型进行组合预测。相比于传统实现指纹定位的KNN与XGBoost等方法,本文提出的模型更具有优越性;同时通过实验与比较可得,本文提出的模型在预测精度方面表现的较好,且明显优于KNN和XGBoost算法模型,在处理海量时时间复杂度较低,具有更高的优势。在如今大数据的背景下,可将本文模型应用到指纹定位算法来进行用户位置的预测,具有广泛的应用价值,为进一步在大数据集群上研究指纹定位算法提供了一定的参考价值[19]。
3 数据来源及数据预处理
3.1 实验数据获取


3.2 数据预处理




4 实验结果及分析
4.1 实验结果评估方法

4.2 LSTM+LightGBM模型仿真


5 结语
