一致性检测和航向编码的船舶航迹聚类
2023-07-03何春城管志强
何春城,曹 伟,管志强
(中国船舶重工集团公司第七二四研究所,江苏 南京 211106)
1 引言
AIS点迹数据是近年来海事安全中的重要数据源,国内的研究集中在轨迹跟踪、轨迹聚类、轨迹重构等方面[1]。
其中轨迹聚类多用于建立船舶航行的模型,基于密度的聚类算法[2-4]不需要预先设定聚类的簇数,并且可以过滤噪声,非常适合AIS点迹这类数据。聚类过程中,相似性度量包括hausdorff距离[5]、DTW距离[2],文献[2,5]中的聚类方法都需要遍历AIS轨迹中的每一个点,复杂度比较大。针对目标活动模式的挖掘手段一般分为网格法[6-8,15]和矢量法[9]两种,Alvares[10]论证了带有语义信息的轨迹数据性对于传统的时空数据处理上的优越性,提出轨迹信息与相关地理信息离线交叉的算法IB-SMoT。除此之外还有根据轨迹的速度聚类出停留点的方法CB-SMoT,缺点在于船舶进出停留点附近时噪声较多[11]导致聚类空间区域远大于实际。Jose Antonio[12]提出了可靠性更高的基于方向的停留点检测方法DB-SMoT。但是上述的停留点检测方法都是以矢量的方法遍历处理点迹信息,复杂度高,而网格化处理便于压缩轨迹信息提高效率。网格化的缺点在于以网格为单元处理轨迹信息丢失了不同网格点迹之间的时空关系,为此刘亚帅[13]提出了一种基于九宫格的网格编码方案,从而得到船舶经过的网格序列保留了点迹的时空关系,但此方法不适用于大范围的海域,且将网格内点迹压缩到网格中心的方法丢失了较多的轨迹空间信息。
针对网格化方法丢失点迹之间的时空关系问题,提出了一种基于航向的编码方案,采用基于网格化的轨迹点“抽取”的方式来压缩轨迹,保留了轨迹点之间的相对时空关系及轨迹形状的语义信息,精度取决网格划分的精细程度。在该航向编码的基础上,采用DTW算法完成了轨迹的聚类,避免了遍历所有点迹,且简化了DTW算法中序列点之间的距离度量。
2 船舶航迹一致性检测及聚类步骤
将数据库中的提取的数据进行清洗,去除无效数据之后进行MMSI一致性检测,同时筛除轨迹中不符合运动逻辑的飞点,将相关性不强的轨迹分段,提高数据的质量。预处理完成之后在网格化的基础上对轨迹进行航向编码,对航向序列应用改进的DTW算法进行密度聚类并将结果可视化。
3 基于一致性检测的点迹分离
AIS数据在实际应用中经常会碰到多艘船舶共用一个MMSI号的问题,如果这些船舶在邻近的时间内出现在研究海域会出现轨迹反复跳跃的问题,除此之外由于AIS数据中的位置信息由GPS等提供,当出现误差时会导致轨迹出现明显不符合运动逻辑的飞点(定义1)导致相关轨迹数据的可用性非常低。
为了解决上述问题,本文提出了一种基于状态信息触发的点迹来源一致性检测,在去除轨迹飞点、分离共用MMSI船舶点迹的同时提高了算法的处理速度。具体过程如图1所示,首先保存轨迹第一个点所在的网格位置,后续处于相同网格的点迹视为具有相同状态信息的点迹即正常点迹,直到一个点迹进入新的网格,视为出现了新的状态信息,此时触发算法的检测过程,若判定新状态点为飞点,则将其加入other_point集合,若不是飞点,则更新当前网格位置同时继续进行断点(定义2)检测,若是断点则认为该点前后轨迹不具有较强的相关性,将前面的点保存为一段轨迹,后续点迹重复进行前述操作,最后对other_point集合进行递归操作。其中飞点检测是为了排除不符合运动逻辑的点迹,因此利用该点迹与之前的合理点迹之间的位置与时间差计算出两点之间的速度,若速度明显大于合理值则认为该点为飞点。断点检测是为了将相关性不强的轨迹段分割,因此当轨迹之间的间距大于一个阈值时判定为断点,本文根据经验将该阈值设为10000m,同时只保留长度达到阈值Thr(取100)的轨迹段。

图1 基于一致性检测的点迹分离
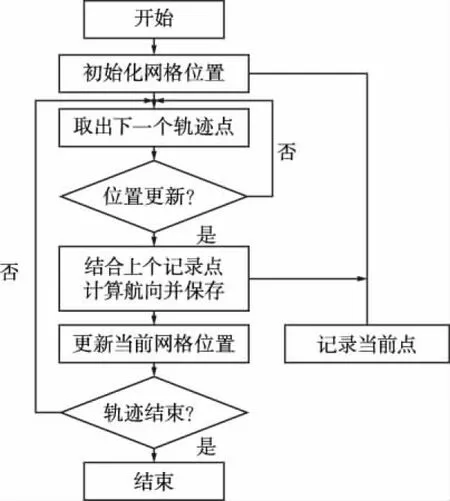
图2 航向编码
定义:
1)飞点:一串正常的轨迹点中出现的偏离了船舶的正常航道的点,且不符合船舶的运动逻辑,一般会导致船舶的轨迹出现毛刺。
2)断点:当同一个轨迹中出现较长的一段空白,认为这个轨迹缺口的前后两端轨迹之间的相关性较弱,将轨迹在此处分段,并将缺口定义为断点。
4 基于航向编码的船舶航迹聚类
当前船舶航迹聚类算法都需要计算每一个轨迹点,如甄荣[14]使用hausdorff距离作为轨迹相似性度量,赵梁滨[2]使用DTW距离作为相似性度量,且算法中每两点之间的距离使用欧氏距离,计算量非常大。为了避免计算所有点迹之间的距离,需要在压缩轨迹的数据量的基础上提取轨迹形状信息,为此提出了基于网格化的航向编码,利用航向序列中包含的轨迹形状信息进行聚类。
4.1 基于网格化的航向编码
Arguedas[8]认为船舶时空行为的变化的主要标志是船舶对地航向的变化,船舶的航向保持代表了船舶维持的一种航行状态。当船舶出现稳定的航向变化代表船舶进入另外一种航行状态,船舶的一段轨迹由多个航行状态组成。轨迹语义信息的挖掘模型DB-SMoT(Direction Based-Stop and Move of Trajectory)正是基于船舶航行过程中的航向信息聚类出停留点从而挖掘语义信息,现有的研究中对航向变化的定义为
D(Pi)=abs(direction(Pi-1,Pi)-direction(Pi,Pi+1))
(1)
针对航向信息的提取需要遍历计算所有点迹,但海上风浪以及其它客观因素的影响会使船舶在短时间内可能会出现剧烈的航向抖动导致出现大量误检的航迹拐点。为了解决上述问题,保证提取的航向变化为船舶的累计变化、过滤航迹的抖动,本文在网格划分的基础上以网格为单位提取航向信息,具体过程如下:
每当轨迹点进入一个新的网格,记录该轨迹点,同时计算该轨迹点与上一个被记录的轨迹点之间的方位角,最终按照方位角所在的区间值保存航向:
Course=direction(record_Pi-1,record_Pi)∥22.5+1
(2)
其中a∥b表示a除以b并向下取整,下图3中每当轨迹进入一个新的网格时触发一次航向编码,编码数值的大小代表了不同的航向,最终编码为一串航向序列:

图3 基于网格的航向编码
由于网格的大小是固定的,因此航向序列的长度在以网格宽度为单位的基础上反应了轨迹的长度。网格的大小对该方法影响较大,较小的网格划分使同一条轨迹会被提取更多次航向,编码出一串更长的航向序列从而更还原轨迹的航行状态,但过小的网格也会导致船舶航行过程中一些无意义的航向抖动被捕捉以及更大的计算量。当网格较大时可能会导致对原轨迹的采样率不够,丢失过多原轨迹的航行信息。综合以上考虑本文选取网格划分的大小为0.02°×0.02°,即每个网格的边长约为2224 m,如式(3),此划分下数据的压缩可以达到200倍左右[13]。

(3)
4.2 基于航向序列及DTW优化的密度聚类
考虑到AIS的特点,使用密度聚类方法,优点在于不需要事先知道聚类的簇的数量,且可以过滤噪声数据,由于航向序列是不等长的序列,采用DTW算法来计算序列之间的相似度。DTW算法的核心思想是:
D(i,j)=dist(i,j)+min[D(i-1,j),
D(i,j-1),D(i-1,j-1)]
(4)
长度为i和长度为j的X,Y两个序列之间的距离为|D(i,j)|,dist(i,j)为X的第i个值和Y的第j个值之间的距离,本文中dist的定义如下,其中d(i,j)=X(i)-Y(j):
(5)
(5)式中dist的计算结果可能为负,因此最终的距离D(i,j)需要取绝对值,这样构造dist的优点在于当进行两条轨迹的相似度量时,如果其中一条轨迹出现了航向偏离导致距离|D|增大,如图4 a段轨迹,当该轨迹航向回归时由于dist计算结果符号相异从而抵消|D|的变化,如图4 b段轨迹,但航向偏离需要保证在|D(m,n)|小于阈值Exp的前提下。

图4 轨迹航向偏离后回归
DTW算法多应用压缩语音序列来匹配语音序列,如图5(a)所示DTW算法通过将序列中的多个点匹配到同一个点来达到压缩语音中部分拉长的发音的目的,这个特点非常适合应用到船舶航向序列中,增加了船舶航行模式匹配的灵活度,但是由于航向序列的长度代表了船舶航迹的长度,必须防止过多的点对应同一个点,如图5(b)。

图5 DTW算法中点的匹配
因此DTW路径搜索的过程中将搜索范围限定在对角线附近,如图6,保证了航向序列中匹配上的状态在实际中航迹长度不会相差过大,同时减小了搜索的范围。为进一步减少计算量,如(6)式,当搜索路径中所有候选项已经大于阈值Exp时可以直接判定不相似,这样也保证了所允许的(5)式对航向偏离的纠正范围限定在Exp以内
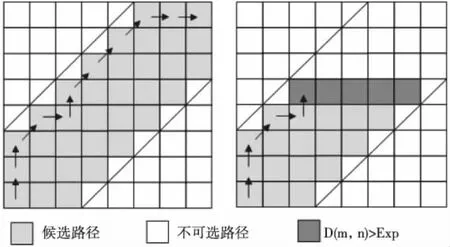
图6 路径搜索过程优化
dist(m,n)+min[D(m-1,n),D(m,n-1),
D(m-1,n-1)]>Exp(0 (6) 聚类采用DBSCAN算法,由于其时间复杂度为O(N2),因此本文从全部的10494条轨迹中抽样出部分轨迹,通过对样本聚类得到核心轨迹,再将所有的轨迹与核心轨迹进行匹配,如果距离小于阈值Exp,则认为被聚类到该簇中,抽样的数量如下: (7) 其中f是一个0到1之间的分数,当样本的大小为s时,对于数量为mi的一个簇,将以概率1-δ(0≤δ≤1)从该簇中得到至少f*mi个对象,本文s=5389。在使用DBSCAN聚类时,将形成聚类核的近邻数量阈值MinPts设置为5,衡量对象之间是否为近邻的距离阈值为Exp=log1.8min(l1,l2),其中l1,l2分别是两个序列的长度。 本实验的硬件平台为Windows10 x64位系统,内存为16 GB,处理器为AMD Ryzen 7 4800HS CPU @ 2.9 GH,软件平台为python 3.8版本。实验使用的是山东半岛附近海域近半个月的AIS数据。 经过点迹分离处理之后,能够有效地将具有相同MMSI号的异源点迹分离,避免了轨迹在两条航道上反复跳跃。 上图7的上部分中分离了分属两艘船的航道且保留了AIS点迹数量大于100的航迹,下半部分是部分轨迹的处理结果,一致性检测算法有效地筛选出了轨迹的断点和飞点,并做出相应的处理以提高数据的质量。本文提出的基于状态信息触发检测的点迹分离在具有以上功能的同时还可以省略对具有相同状态信息的点迹的检测过程,算法效率对比遍历所有点的检测算法如表1所示。 表1 检测算法对比表 表2 不同相似性度量方法下密度聚类的效率对比 图7 部分轨迹一致性检测处理结果 基于航向编码的轨迹聚类优势在于处理速度高于传统的方法,在DBSCAN算法复杂度高的前提下,着重于简化聚类的数据,以及数据之间相似性度量的算法。基于欧式距离的DTW是将一串AIS点迹作为比对的序列,序列元素之间的距离度量采用欧式距离,这种方法优势在于可以识别轨迹之间细微的不同,但是计算量非常大,当轨迹数量多且单条轨迹较长时算法几乎不可行。Hausdorff距离是一种计算最大最小值的相似性度量方法,受异常点影响非常大,实验中采用从轨迹中固定间隔抽样的方法来降低异常点影响以及提高效率。通过对比可以看到这两种传统的方法在效率上远低于基于航向编码的聚类方法。 图8的聚类结果中同一个簇中的轨迹形状并不完全相同,部分轨迹的部分航段的航向可能偏离其它轨迹,对于轨迹航向偏离的容忍度取决于使用DTW衡量相似度时对路径宽度的限制以及密度聚类算法对判断近邻的阈值Exp的设置,本文的Exp根据航向序列的长度动态设置,能够在轨迹长度较长时放宽对类内相似性的要求,提高了轨迹的聚类程度。路径宽度的限定,避免了多点对应一点的匹配方式,这使得判定为近邻的两条轨迹的航向序列的长度不能相差过大,在图中表现为同一个簇中的轨迹长度近似。 图8 基于航向编码的聚类部分结果 图8(a)中标记了不同轨迹段的航向编码,基于航向编码的方法提取了轨迹中的形状信息,保留了轨迹点之间相对的时空关系,也在聚类结果中保留了轨迹的航向信息。其中左上和右上图中标记了部分轨迹的航向抖动的位置,得益于网格化的编码过滤了抖动,避免了其对DTW算法的影响。a)左下图的不同轨迹中5航向轨迹段与3航向轨迹段长度不同,体现了DTW算法的压缩匹配效果;a)右下图中将轨迹尾部较长一段航向为6以及7的轨迹聚为一类,体现了动态设置Exp的优势。但由于航向编码忽略了轨迹点的地理位置信息,航向序列代表了船舶的航向状态而不包含船舶的位置信息,因此聚类的结果中会出现分布在不同位置的具有相同航行模式的簇,如图8(b)。 为了解决船舶共用MMSI以及定位误差导致出现轨迹跳跃的问题,本文提出了一套检测飞点以及断点的方法,有效分离了轨迹点以及关联性不强的轨迹段,为了提高该流程的效率,提出了基于状态信息更新的触发检测方法。为了解决轨迹信息数据量大导致现有的针对轨迹的密度聚类方法效率不高的问题,提出在网格化的基础上对船舶轨迹中的航向信息进行提取,从而对航向序列进行聚类的方法,同时改进DTW算法并且采用抽样聚类的方法以进一步提高效率同时改善航向聚类的结果。 实验中的可视化结果表明,点迹分离流程处理之后的轨迹数据中航道更加清晰合理,数据质量明显提高,基于航向的聚类方法有效地聚类了船舶的轨迹,且效率远高于传统算法。但航向聚类忽略了船舶的地理位置信息,使得同一个簇中的轨迹地理分布不集中,需要根据地理位置信息进一步进行分离。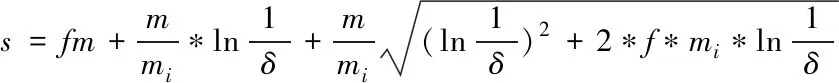
5 实验结果分析
5.1 点迹分离结果分析



5.2 基于航向编码的聚类结果分析

6 结束语
