基于改进UFSA算法的车道线检测研究
2023-07-03柯福阳朱节中夏德铸
王 祥,柯福阳,朱节中,夏德铸
(1. 南京信息工程大学自动化学院,江苏 南京210000;2. 南京信息工程大学遥感与测绘学院,江苏 南京 210000;3. 南京信息工程大学无锡研究院,江苏 无锡 214000;4. 无锡学院,江苏 无锡 214000)
1 引言
随着城镇化的加快和汽车保有量的增加,城市交通负担日益加重,交通事故频发,人们驾驶车辆的压力倍增[1]。为了避免车辆道路事故,保障驾驶的安全性,近年来在世界范围内针对为驾驶员提供帮助的车辆驾驶辅助系统的研发蓬勃展开[2-7]。这些系统通过从车辆载有的传感器获取输入,利用系统输出的某种形式的反馈信号指导驾驶员安全驾驶。车道偏离预警(lane departure warning,LDW)和车道保持(lane keeping,LK)、车道变换(lane changing,LC)和前向碰撞预警(forward collision warning,FCW)、自适应巡航控制(adaptive cruise control,ACC)及盲点检测(blind spot monitoring, BSM)系统等都属于驾驶辅助系统的范畴[8]。车道标线检测则是组成这些系统的核心部分。所以研究车道线检测有重大理论价值和现实意义。
更为精确有效地从图像中检测出车道线是近些年来相关研究人员广泛关注的问题,人们针对车道线检测方法进行了大量研究。目前,对于车道检测有两种主流的方法,即传统的图像检测处理方法[9-11]和深度分割方法[12-14]。传统的车道检测方法通常是基于视觉信息来解决车道检测问题,这些方法主要思想是通过图像处理利用视觉线索,如HSI(HueSaturationIntensity)颜色模型[15]和边缘提取算法[16,17]。而传统方法针对视觉信息不够强的时候,表现效果较差。最近,深度分割方法在这一领域取得了巨大的成功,它具有很强的代表性和学习能力。为了更有效地使用视觉信息,SCNN(Spatial CNN)[14]在分割模块中使用了一种特殊的卷积运算,通过对切片特征的处理,将不同维度的信息进行聚合,并将其逐一相加,但该方法检测速度较慢,限制了进一步地发展;文献[18]提出了自蒸馏的方法来解决检测速度慢这一问题,但由于分割SAD(self attention distillation)算法稠密的预测特性,该方法计算量大;文献[13]提出了将车道线检测看作实例分割问题,采用实例分割得到每条车道线的像素点,通过学习路面的透视投影矩阵,并将前视图转换到鸟瞰图视角,拟合每条车道线的曲线方程,最后逆变换回原视图。该方法可以有效地解决传统的车道检测方法计算成本高等问题,但容易因道路场景变化而不具有可扩展性;文献[19]针对采用像素分割的传统车道线检测方法,存在速度慢、感受野有限和未充分利用全局特征等缺点,提出了UFSA(UltraFast Structure-aware)算法。该算法检测过程使用全局特征,在全局特征上使用大感受野,此外还提出了一种结构损失来模拟车道结构。利用全局特征在图像中筛选提前预定行的车道线位置而不是基于局部特征的车道线,这样不仅减少了计算量,还可以解决速度和无视觉线索(车道线被遮挡,需要通过车的位置和环境语义信息去猜测研究)的问题。
针对解决UFSA算法网络卷积和池化提取车道特征可能会丢失重要信息、大感受野时,不能获取更丰富、捕获长距离的上下文信息等问题的存在,故在辅助语义分割网络层采用空洞空间金字塔池化ASPP(Atrous Spatial Pyramid Pooling)[20]和FCANet(Frequency Channel Attention)[21]注意力机制融合机制,定义为FCASPP(Frequency Channel Attention Spatial Pyramid Pooling),该机制可以有效地获取丰富信息、提取更有用和紧致的特征而抑制噪声信息;车道线检测对于边界信息敏感,不仅只关注对象的几何形状,更需要关注边缘信息,如颜色、纹理和照明等,L-Dice (Lane Dice Loss)函数[22]比Softmax函数更加关注车道边界的信息。通过消融实验验证了上述改进的有效性,此外,加入的FCASPP机制和L-Dice函数时,未添加任何计算量。检测速度和精度与原文相比,均有进一步地提升。与原文相当,本文算法较具竞争力。
2 基于改进的UFSA网络结构和损失函数
2.1 原始网络结构
网络的总体框架如1图所示,上分支为辅助分割分支模块,用于语义分割,且仅在训练阶段工作;下分支左侧为网络层Resnet模块用于特征提取;紧接着右分支是分类预测模块。

图1 UFSA原始网络结构
Ltotal=Lcls+αLstr+βLseg
(1)
Lseg对应于分割损失,Lstr对应结构损失,Lcls对应分类损失,α和β是为损失系数。
2.2 改进的算法介绍
2.2.1 ASPP网络层
ASPP(Atrous Spatial Pyramid Pooling)主要是对所给定的输入图片,以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文,捕捉上下文信息。为了解决已有车道线检测算法无法有效捕捉输入图像多尺度长距离上下文信息,而导致的分割准确率较低的问题。本文提出基于空洞空间金字塔池化的车道线语义分割网络,构建多尺度长距离上下文特征提取层。通过在车道线检测场景特征提取引入空洞空间金字塔池化层来对多尺度长距离上下文信息进行有效提取,更好地学习车道线图片的特征。改进的模块如图2所示,图2左侧为ASPP原始模块,膨胀率不同,可以提取不同感受野的特征,以便于更加丰富的信息;将ASPP卷积层与FCANet注意力机制相连接,将融合后的模块定义为FCASPP,基于空洞空间金字塔池化,对于特征信息具有更强的学习能力。特征提取模块中的空洞卷积如式所示

图2 FCASPP机制
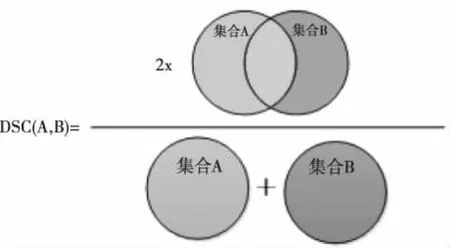
图3 L-Dice示意图
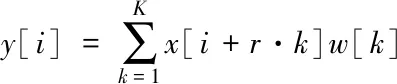
(2)
其中,y[i]是输出特征图上第i个位置的输出信号,x是输入信号,w是卷积滤波器,k是卷积核大小,r是滤波器扩张率。
2.2.2 FCANet
卷积层和池化层类似于通道注意力机制,通过网络学习的方式来获得权重函数。但存在一些潜在的问题:卷积层和池化层无法很好地捕获丰富的输入模式信息、提取特征会丢失重要信息等,因此在处理不同的输入时缺乏特征多样性。而FCANet注意力机制,可以有效解决上述问题。
为了引入更多的有效信息,使用二维的DCT(discrete cosine transform)来融合多个频率分量。具体操作流程为:将输入的X按通道维度划分为n部分,其中n必须能被通道数整除。每个部分分配相应的二维DCT频率分量,其结果可作为通道注意力的预处理结果,数学推导过程为

(3)
H为输入特征图的高,W为输入特征图的宽,X为输入的图像特征张量,h∈{1,2,…,H-1},w∈{1,2,…,W-1},ui,vi是对应于Xi二维频率分量的索引,Freqi是压缩后的C′维向量。
将各部分的频率分量合并起来为
Freq=compress(X)
=cat([Freq0,Freq1,…,Freqn-1])
(4)
其中,Freq为多光谱向量,整个多光谱通道注意力框架可以写为
ms_att=sigmoid(fc(Freq))
(5)
其中,att∈RC是注意力向量,sigmoid是Sigmoid函数,fc为全连接层或一维卷积的映射函数。可以看出,该通道注意力将原有的方法推广到一个具有多个频率分量的通道,压缩后的通道信息可以丰富有效地用于表征。
2.2.3 Lane Dice Loss损失函数
边界检测的一个直接解决方案是将其视为语义分割问题。在标注中简单地将边界记为1和其它区域记为0,即将其表示为一个二分类语义分割问题,以二值交叉熵为损失函数。然而,交叉熵具有两个局限性:标签分布高度不平衡和边界相邻像素点的交叉熵损失难确定问题。交叉熵损失值只考虑微观意义上的损失,而不是考虑全局。
Dice Loss损失可以很好地解决上述存在的问题,该损失起源于20世纪40年代,是用来测量两个样本之间的相似性,示意图如3所示。它是由米勒塔里等人应用到计算机视觉中,并在2016年[23]进行三维医学图像分割。其数学表达式为

(6)
上式显示的骰子系数方程,其中pi和gi分别表示的是像素预测值和真实值,值为0或1。在车道线检测场景中,表示像素是否为边界,是值为1,不是值为0。分母是预测值和真实值的总边界像素和,分子是正确预测的总边界像素和,只有当pi和gi值(两值为1)匹配时,损失函数才递增。在该文中,将Dice Loss定义为L-Dice(Lane Dice Loss),并将此时的分割损失定义为LL-Dice。
那么,总体的损失函数重新定义为
Ltotal=Lcls+αLstr+β(μLseg+γLL-Dice)
(7)
其中,分割损失Lseg的系数μ设置为0.7,分割损失LL-Dice的系数γ设置为0.3。
2.3 改进的网络结构
UFSA网络结构的改进如图4所示,主要改进基于辅助分割分支,加入ASPP与FCANet融合模块FCASPP,且损失引进L-Dice,在原有基础上并未增加任何计算量。
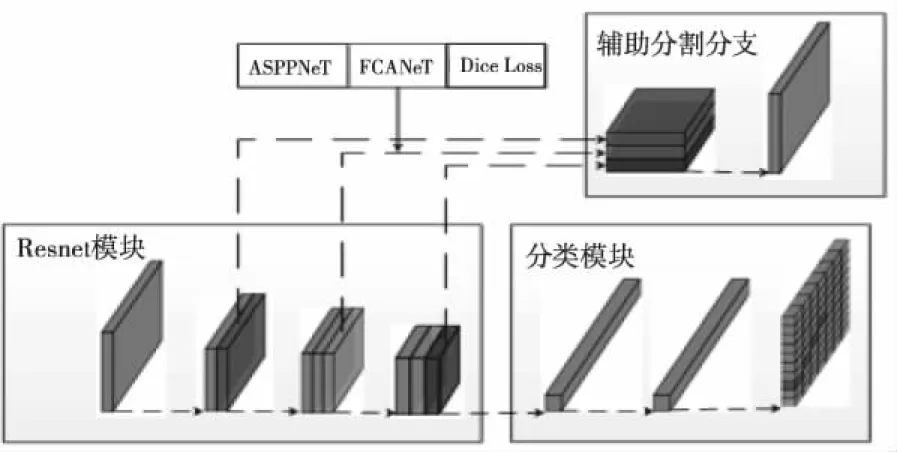
图4 UFSA改进网络结构
3 实验过程
实验运用深度学习相关理论方法与传统算法优化方法完成了算法构建,实验阶段,采用opencv库函数与pytorch框架,所用GPU(Graphics Processing Unit)为NVIDIA 1080Ti,通过CUDA10.0与CUDNN V5.0采用Python语言实现了算法内容。
3.1 模型训练
3.1.1 训练数据集
针对车道线检测选用图森未来发布的TuSimple数据集和香港中文大学发布的CULane数据集进行相关实验和研究,大部分车道线明显且清晰,车道线弯曲程度小。
TuSimple数据集采用的是结构化道路图像,包含72520个训练集和55640个测试集。该数据集将视频数据通过分帧转换成多张图片形成,并仅对未位图片进行标注。数据集标注采用中心打点式以json文件储存,一张道路图片的标注为一个元组。
CULane数据集用于行车道检测学术研究的大规模挑战性数据集,一共包含133235张图像。其中数据集分为88880个训练集,9675个验证集和34680个测试集,道路中的车道线用粗实线进行了标注。如表1所示,对两个基准数据集详细地介绍。

表1 数据集描述
3.1.2 模型训练
模型训练过程中将数据集主要分为两个部分:训练集和测试集。在TuSimple数据集时,训练迭代次数设置为100,在CULane数据集时,训练迭代次数设置为50;批处量大小为32,基础学习率初始为4e-4,其中动量和权重衰减分别配置0.9和0.00055。训练误差和验证误差使用均方误差,训练结束时训练误差收敛为0.0044,验证误差收敛为0.0045。
3.2 算法评判标准
准确率和召回率是评价目标检测识别算法时最常用的两项评估指标。准确率用来衡量输出的预测结果中为正确检测为真实值的比例,而召回率是用来衡量输出的预测结果之中所包含的应该被正确检测数量的比例。
其中,准确率和召回率的计算公式为

(8)
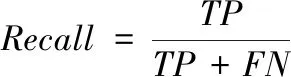
(9)
TP为真正例,指模型将正类别样本正确预测为正类别;TN为真负例,指模型将负类别样本正确预测为负类别;FP为假正例,指将负类别样本错误的预测为正类别;FN为真负例,将负类别样本错误的预测为负类别。
使用的车道线检测算的是基于深度学习分割算法与传统方法进行优化的融合算法,因此使用图像分割的评价指标对检测结果进行像素级的分类评价。F值(F-measure)又称为F1分数(F-score),是准确率(Precision)和召回率(Recall)的加权调和平均,用于判断分类模型的优劣,精准率和回归率两个因素决定,计算公式为

(10)
将β参数设置为1时,即F值函数设为常见的F1,它综合了准确率和召回率的结果,F1越高这说明分割模型越优秀。
3.3 实验结果与分析
原文的方法是基于两个基础网络模型进行,分别为Resnet-18和Resnet-34;本文基于Resnet-18网络模型进行修改,分别添加FCASPP模块和L-Dice损失,实验总共分为四个对个实验,如表2所示。

表2 UFSA算法改进不同模块对模型性能影响对比
表2所示是本文实验改进的内容,其中实验1是UFSA原文的方法,对应的F1分数为68.4%;实验2是基于UFSA原文方法,只添加FCASPP融合模块的检测结果,对应的F1分数为69.4%,比原UFSA的精度提高了1.2%,此实验证明了此融合模块FCASPP的有效性;实验3是基于UFSA原文方法,只添加L-Dice损失的检测结果,对应的F1分数为69.3%,比原UFSA的精度提高了0.9%,此实验证明了分类损失L-Dice的有效性;实验4是基于UFSA原文方法,添加FCASPP模块和L-Dice损失的检测结果,即本文改进的方法,对应的F1分数为70.1%,比原文的检测精度提高了1.7%,FCASPP模块和L-Dice损失缓解了网络卷积和池化提取车道特征丢失重要信息、大感受野时,不能获取更丰富、捕获长距离的上下文信息等问题的存在。
该改进部分实验是基于两个公开数据集进行,分别为TuSimple基准数据集和CULane数据集,进行了大量的实验验证。表3展示了7种传统分割算法,在TuSimple数据集上检测精度的对比。由表中数据可知,该改进的UFSA算法在TuSimple数据集上表现胜于改进前该算法的表现,精度有所提升,原文在Tusimple上的检测精度为95.87%,改进后的检测精度为96.08%,提高了0.21%,说明了改进的有效性。

表3 TuSimple基准数据集的检测精度对比
表4为CULane数据集基于不同算法下,9个场景的识别精度。本文基于Resnet-18改进的检测精度,如表所示。9种场景分别为:Normal、Crowded、Night、No-line、Shadow、Arrow、Dazzlelight、Curve、Crossroad,原文在Resnet-18对应的精度分别为:87.7%,66.0%,62.1%,40.2%,62.8%,81.0%,58.4%,57.9%,1743;本文实验对应的精度分别为:89.2%,68.2%,64.5%,42.9%,64.2%,83.8%,59.7%,59.5%,‘2336’。改进后比改进前,前8个场景精度分别提高为:1.5%,2.2%,2.4%,2.7%,1.4%,2.8%,1.3%,1.6%,而第9个场景的检测识别精度较低,误检的车道线与改进前相比较多,但总体检测效果良好。原Resnet-18综合检测精度为68.4%,而改进后为70.1%,提高了1.7%;同时,检测速度也较之前明显变快,由322.5FPS变为298.4FPS。
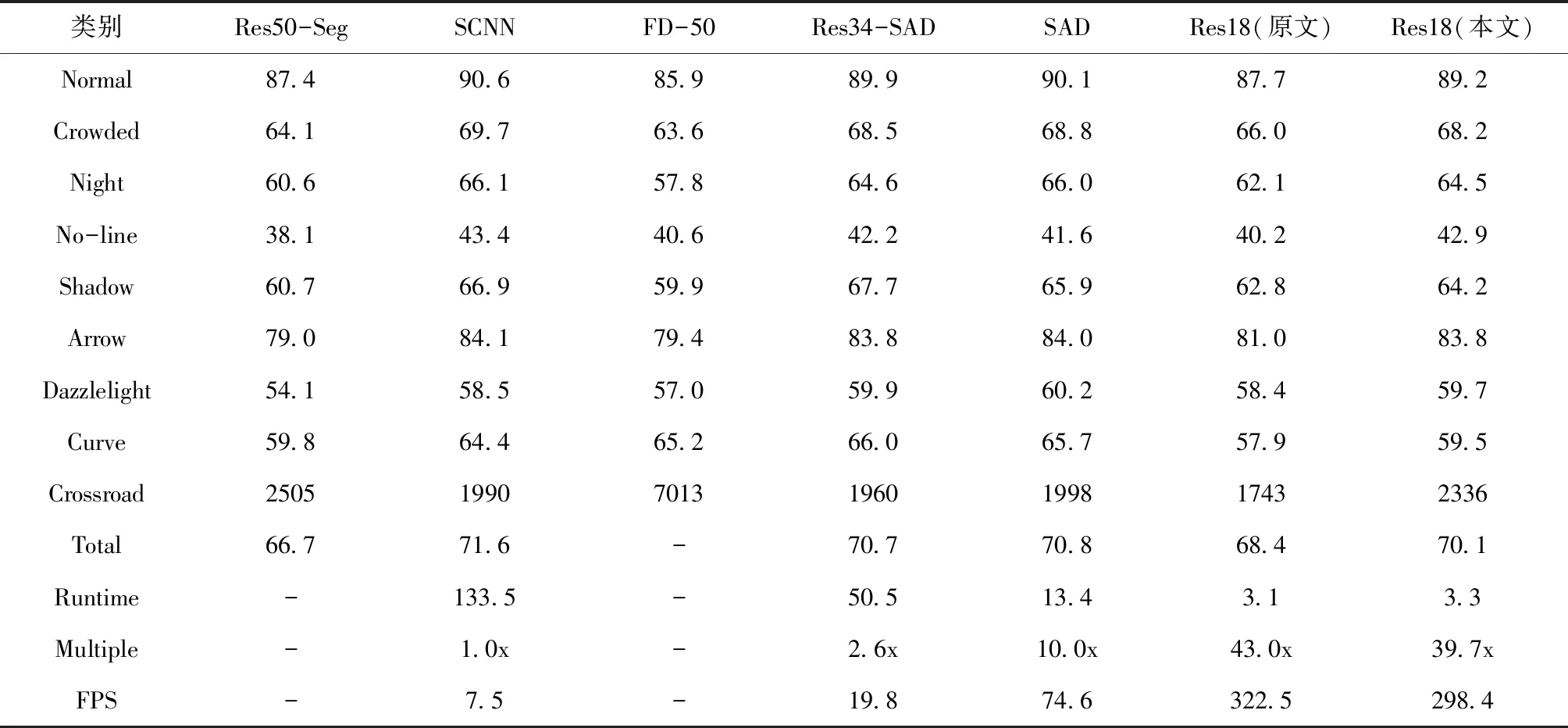
表4 在CULane数据集下9个场景的识别精度
表4中,测试阈值设为0.5,图片分辨率设为1640×590,“-”表示结果不可得。
图5(a)(b)(c)(d)主要以场景丰富的Culane数据集为例,四幅图横坐标表示迭代次数,纵坐标表示损失函数值。

图5 损失曲线
图5(a)对应的是辅助分支分割的损失,随着网络迭代的不断增加,损失逐渐降低。图中曲线表明本文提出的混合损失在迭代80k次后逐渐收敛。
图5(b)对应的是主分支的分类损失,随着网络迭代的不断增加,损失逐渐降低。从图中可知,分类网络在75k完全收敛。
图5(c)对应的是结构化损失,随着网络的迭代,损失增加。车道线理想状态下是笔直的,但是现实中相邻车道线像素之间并非在一条直线,从图中说明网络已经能够清楚的识别公路上的车道线,损失逐渐递增原因,但是迭代80k后,损失曲线呈现水平状表示已经完全收敛。
图5(d)对应的是本篇论文的多阶段学习率策略,有利于网络的学习。
从图6可知,本文采用的FCASSP和L-Dice loss对车道线检测的取得较好的效果起到关键作用。

图6 车道线效果图
4 结论
首先是介绍了UFSA算法网络模型的基本结构,然后对其进行精简和改进,主要针对的是辅助分割分支的改进。其一是ASPP网络层与FCANet注意力机制融合,并将融合模块FCASPP添加到UFSA算法网络的辅助分割分支中,这样可保证UFSA算法在大感受野时,能获取更丰富、捕获长距离的上下文信息,同时可以有效地提取更有用和紧致的特征而抑制噪声信息;其二是由于车道线检测对于边界信息敏感这一特殊性,不仅只关注对象的几何形状,更需要关注边缘信息,如颜色、纹理和照明等,故进行损失函数的修改,L-Dice损失比Softmax函数更加关注车道边界的信息。通过消融实验验证了上述改进的有效性,在两个公开数据集TuSimple和CULane测试,性能和精度都有进一步地提升。此外,加入的FCASPP模块和L-Dice损失时,未在原有的基础上添加任何计算量,且检测速度也与改进前相当。
