ChatGPT:生成式AI对弈“苏格拉底之问”
2023-06-21杨俊蕾
杨俊蕾
摘 要: 生成式 AI 是人工智能领域中的新技术分支,在近20年的产业发展和布局中形成了九组应用类别。其中,ChatGPT 作为人机对话模型的新兴产品,经历了跃迁式的技术迭代,在全球范围内引发了未来 AI 将如何辅助人类工作的讨论。基于“苏格拉底之问”和逻辑要素辨析可以发现,生成式AI 的对话模型更多依赖于“指令”设置,不同于传统意义上的对话文体。凝聚西方思想传统的“在场”对话方式被改写为内部循环的数据流动。如何建构符合全人类利益的开放性系统正在成为保障人机协作安全性的共识基础。
关键词: ChatGPT;生成式AI;苏格拉底之问;对话模型;开放性系统
中图分类号:TP18 文献标识码:A 文章编号:1004-8634(2023)02-0014-(08)
DOI:10.13852/J.CNKI.JSHNU.2023.02.002
生成式AI(AI Generated Content,缩写为AIGC)旨在利用人工智能技术来生成内容。从人工智能的发展历程看,生成式AI是弱人工智能向强人工智能/通用人工智能(Artificial General Intelligence,缩写为AGI)迈进途中新生出来的技术分支。它在基础原理上更接近阿兰·图灵(Alan Turing)关于“无限容量计算机”的智能机器设想,类似于“数字计算机思想的基础上出现了一个有趣的派生物”。1 而在关于智能生成技术的场景想象方面,美国哲学家约翰·塞尔(J. R. Searle)在1980年提出的“中文屋论证”(Chinese Room Argument)与“系统应答”设计(Response of System)初步设想了智能机器与人进行对话的系统性程序建构,“在某个根本不存在意向性的领域中,一个系统也可以在概念和经验上具有像人类一样的能力”。2
事实上,生成式AI的技术主导框架正是20世纪社会思想全面进入信息论、控制论和系统论的思维范式转换之后的新路径开发,它以人机界面的构建为平台端口,将二者间有效而即时的无限交互作为主攻方向。在很大程度上,技术开发的着重点更多倾向于显著改善应用体验:一方面是在程序生效的阶段耗时上,尽可能缩短人脑信息输入与类人智能应答输出两项步骤之间的信息流动延时;另一方面则是在系统架构的模型基底上,连续激活开放性对话的生成模式,不划分固定的边界,也不进行断点式的层级分化判断。由此导致的现象级后果之一,就是人工智能再度成为技术社会时代的全球焦点。它与影响重大的另外一些核心新技术发展如新能源、自动化、基因生物和外太空探索等构成可资关联的实际协同,并在引导大众认知的话语导向方面持续地实现自身作为驱动力技术的观念传播,既为自我演化改进的技术迭代进行系统优化升级,也在扩张性发展中起到“形塑未来”(shaping future)的深远影响。
需要注意的是,“形塑未来”是代表当前生成式AI的热门产品ChatGPT(Chat Generative Pre-trained Transformer)的开发方OpenAI在其官网上做出的愿景陈述,从字面含义来看,是技术乐观主义的衍生映射,在更深层次的知识权力竞争中,则更多包含着对于未来技术路径的话语权、定义权,甚至是主控权的实际享有。而在关于ChatGPT的具体定义中,OpenAI将之描述为“优化对话语言模型”(Optimizing Language Models for Dialogue)。因此,梳理生成式AI对话模型的优化与迭代历程,分析该类模型的应用场景与垂直化运行的开放式系统模式,有助于进一步理解人工智能在当前阶段的实际状况,为生成式AI在特定用途中的引入增加专业性的思想准备。
一、从NLP到LLMs的奇点跃迁:生成式AI对话模型的技术迭代
按照产业数据统计的曲线表征来看,人工智能的产业化历程先后经历了三个阶段的波谷运行。从1956年的正式宣告推出,到20世纪90年代的专家系统问世,再到2000年后因为个人电脑用户激增而出现新的爆发式增长,人工智能的技术迭代之路始终与市场化的产品推广存在着若即若离的不确定关联。直到2022年冬季,OpenAI发布了可以在网页上直接应用的ChatGPT系列产品,在相对短暂的时段内迅速引发了井喷式的同类型产品跟进和几何倍速增长的全球用户规模。至此,标志着人工智能的产业发展进入第四阶段,主要表征为系统的开放性和实际运行中的点对点模式。且随着竞品商业化的渠道益发顺畅,付费用户应用智能程序的即时生成在耗时方面能够明显优于网络普通访客。此举的经济获益在当前阶段既不是开发方的主要目的,也不是公众最关心的内容。它的标志性意义在于推动生成式AI进入知识付费服务,让智能机器的生成内容开始潜入人类知识领域,在看起来似乎更加“开放”的系统使用中替换了“开放”实际导出的方向,从原来的开放性系统构建以释放AI的能量,改变为倒逼现有知识系统向生成式AI的内容产出逐渐开放。促成该转换发生的根本驱动正在于对话模型的技术迭代带来的效能加速和远超一般算力的内爆式内容增长。
“让机器像人一样思考”,是阿兰·图灵为智能机提出的“模仿游戏”基本原理。经过计算机编程实验之后,人工神经网络(Artificial Natural Networks)的搭建借助机器学习(Machine Learning)开始进行连接模型(Connection Model)的算法训练。建立连接的第一步就是人与机器间实现有效的信息交互,亦即生成式AI技术思维中的互信息链式法则。作为信息论基础的“互信息”(Mutual Information)概念,意味著“一个随机变量包含另一个随机变量信息量的度量”。1 旨在运行生成式程序以输入新的信息变量并及时有效到达信息发出端的AI对话模型,前期调试过程经历了较长时间的瓶颈期停滞,其中的制约原因就在于从信息输入层到信息输出层之间的转化受到随机变量的不确定影响。
由于计算机语言的内部系统编码迟迟不能降低导入信息的理解误差,人工智能技术在生成式AI的发展道路上陷入徘徊。带来改变的是从外部系统引入的人类语言处理模式,承担起突破研发困境的新思路。自然语言处理任务(Natural Language Processing,缩写为NLP)将类脑设计带入机器理解的预备程序,实现了多系统间的开放与协同。在智能机器所能读取的方法模型中搭建类脑的神经网络,已经在计算机图像识别和自然语言理解等方面连续得到证实,并逐渐成为机器认知的关键夹层,在隐层工作状态下完成信息转换,并再次转换到输出环节。也正是在这个意义上,计算机的计算过程表现出更近乎人脑特点的黑箱机制,隐在夹层中的卷积层响应方式不再是明显可见的,相应地也是不可回逆的,其功能导向因此契合了对话模型的应答需求。
更进一步来看机器理解文本内容的技术原理,可以发现具体的自然语言理解(Natural Language Understanding,缩写为NLU)任务包含了众多的子项,诸如词语标注、词性分理、文本分类与语法析取等。通过目标化的训练与深度学习,承担具体任务的智能算法显示出接近常人的语言理解能力。然而这一节点上的任务是人机共同协作才能达成的。建立(预)训练集的信息抽取与标注,最初都由人力手动进行,由此附加产生的数字化劳工问题是人工智能伦理学的关注焦点。在结果产出后的用户反应与评价,则又一次将大型语言模型如何建构的问题推到了公众面前。
就在ChatGPT的日活用户注册量超过2亿之后,《自然》杂志在一周内连续刊发两组科学评论文章,集中分析了大型语言模型(Large Language Models,缩写为LLMs)作为ChatGPT应用基础的技术弊端与潜在风险可能。LLMs对于服务器的硬件要求和计算速度的算力要求都远远超出了此前的同类型应用。OpenAI在产品介绍中呈现了该对话模型的迭代细节。首先,ChatGPT是经过训练而来的对话模型,通过网页接口与用户进行交互式对话。它的训练重点在于对话格式的构建与完形,不僅能够使ChatGPT连续回应、回答系列问题,而且能够做到反身调节,包括衡量正误与否,做出及时的判断,对提问前提进行反思、质疑并中止不合乎训练内容的不当请求。1 其次,ChatGPT的训练方法与InstructGPT模型大致相同,但是作为升阶后的兄弟模型,在针对性训练中格外强化了指令(Prompt)模块,并在数据喂养中给予详细的相应范例。该操作使ChatGPT不同于其他更早使用InstructGPT方法训练而成的同类AI产品。其中的技术奇点是人机协同在生成式AI训练中的深度关系,甚至是超越限定的跨边界融合。
ChatGPT的模型训练使用了来自人类反馈的强化学习(Reinforcement Learning from Human Feedback,缩写为RLHF)。尽管与InstructGPT的方法原理相同,但在具体的数据收集方式与标注上做出了不同的设置。ChatGPT的初始模型就是在人类监督下的微调训练,作为提问者的用户和作为AI辅助应答的回复,在初始环节里都深度依赖人类视野。“人工智能训练师提供对话,他们扮演用户和人工智能助手的双方角色。”2 在模型训练的具体过程中,人工智能训练师的文献工具是阈值确定的,因而保证了他们所撰写的回复的信息可靠性。但是接下来,上一回合积累得到的对话数据集在形式上转换为对话格式,并和此前由生产转换器得出的数据集加以混合,形成排序和比较,依照对话生成的质量,对模型进行相应的序列整理。再接下来,开始又一个回合的人机协同对话。先由训练师与应答程序继续展开对话,再随机择取模型输出的多条信息,在抽样备选中做出顺序排名以形成值得优选出来的奖励模型。对照奖励模型的排序,ChatGPT会受到更为优化的模型微调,以及上述训练过程的反复迭代。
二、生成式AI的技术语境与产业布局
人类在历史上先后经历了不同劳动方式的改变,如狩猎、游牧、农耕和工业生产。即使在不同生产方式作为主导的时期,新技术的跃迁总能将社会组织整合成新的运作系统。工业革命、信息革命和互联网革命是塑造当前技术社会状态的主要动因。随着ChatGPT的用户数量快速扩张与全球传播效果的蔓延,传闻已久的人工智能技术革命正在让人们感受到未来加速涌现的先声。而且,ChatGPT并非一枝独秀。尽管在金融投资视野中,以非营利为目的的科技创新公司OpenAI是独角兽一般的突出存在,但是回归到生成式AI技术的初创领域,还有其他五家开发组织在市值规模、技术开发和产业布局等方面同样举足轻重。如果经由行业专家的视角来看,这些各自握有生成式AI代表性产品的大型公司或许将在未来的赛道上共同博弈,并决定着技术接入基底应用的参数、标准和公共安全规则。
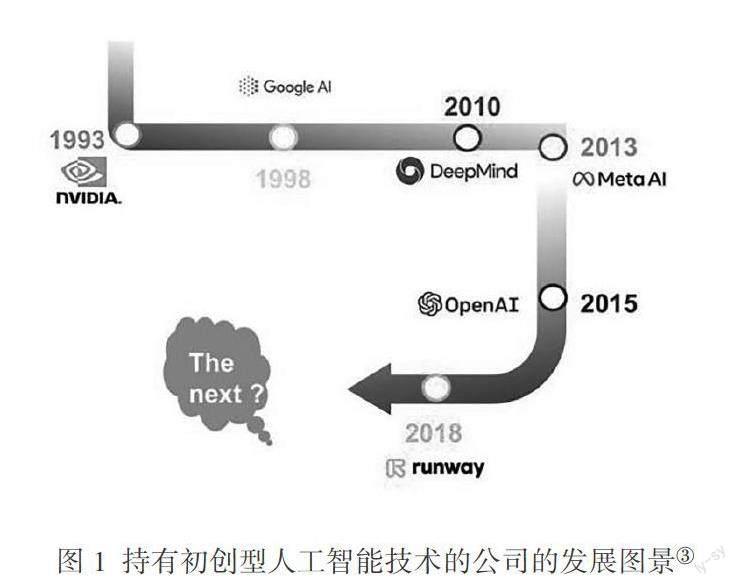
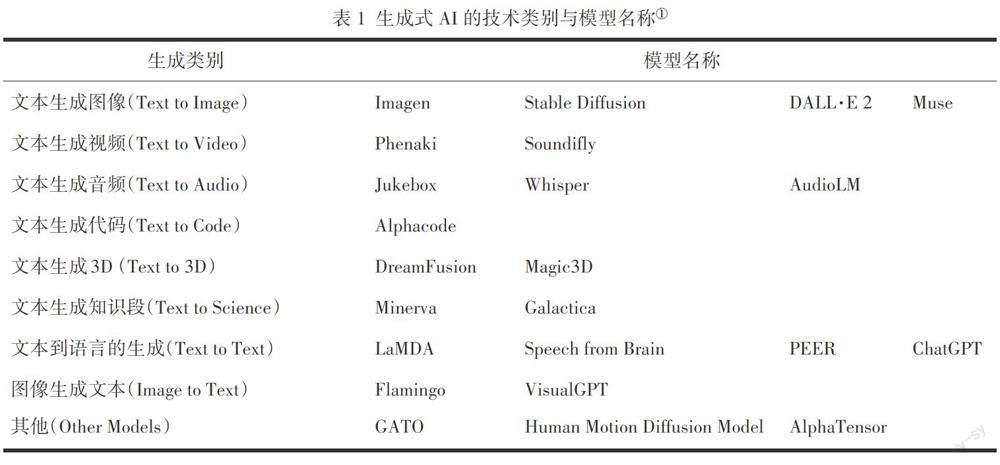
目前握有生成式AI初创技术的大型公司共有六家。只有谷歌旗下的DeepMind在2010年成立于英国伦敦。其他五家都在美国境内注册,其中有三家位于加利福尼亚,分别是成立于1993年的NVIDIA、1998年由谷歌搜索另外挂牌的Google AI和2015年初成立的OpenAI;另外两家在纽约,是2018年成立的Runway和2013年成立的FAIR(Facebook Artificial Intelligence Research),后者于2021年正式更名为Meta AI(见图1)。这些科技初创公司的实际经历共同形成了生成式AI的技术语境,也为ChatGPT在全球范围内突然获得公众层面的普遍瞩目进行了将近20年之久的产业布局积累。分析上述六家开发方所持有的23项生成式AI模型(表1),有助于准确定位并预判ChatGPT的新应用场景,以及它作为互联网搜索暨辅助型智识/知识应答工具,在接下来的人机协同发展中还将增加哪些维度和容量。
从1993年NVIDIA最早研发并定义生成式AI技术中的图形处理器概念(Graphics Processing Unit,缩写为GPU),到2023年初引发全球热议的OpenAI新产品ChatGPT,近20年的算法研发主要集中于9种转换生成模式。基于表1,可以分为三组方向:第一组方向为文本驱动型,包括文本生成图像、文本生成视频、文本生成音频、文本生成代码、文本生成3D、文本生成知识段和文本到语言的生成;第二组的转换方向是将第一组中的文本生成图像加以翻转,建成图像生成文本的模型;第三组的开发方向与上述二者对比来看,不再受限于单项的任务驱动,而是面向多种模式,对多项任务做出回应,表现出生成式AI在未来可能具有的加强型多任务处理能力。以2022年10月发布的动作模型MDM(Human Motion Diffusion Model)为例,它基于文本描述所能生成的人类动作在3D空间中的多样性表现已经堪称流畅,接下来继续使用开源项目Stable Diffusion,为新生成的数字形象加上纹理贴图,以加快实现文本对象的现实性风格,使AI生成的机制产品更接近有个性辨识特征的类人出品。
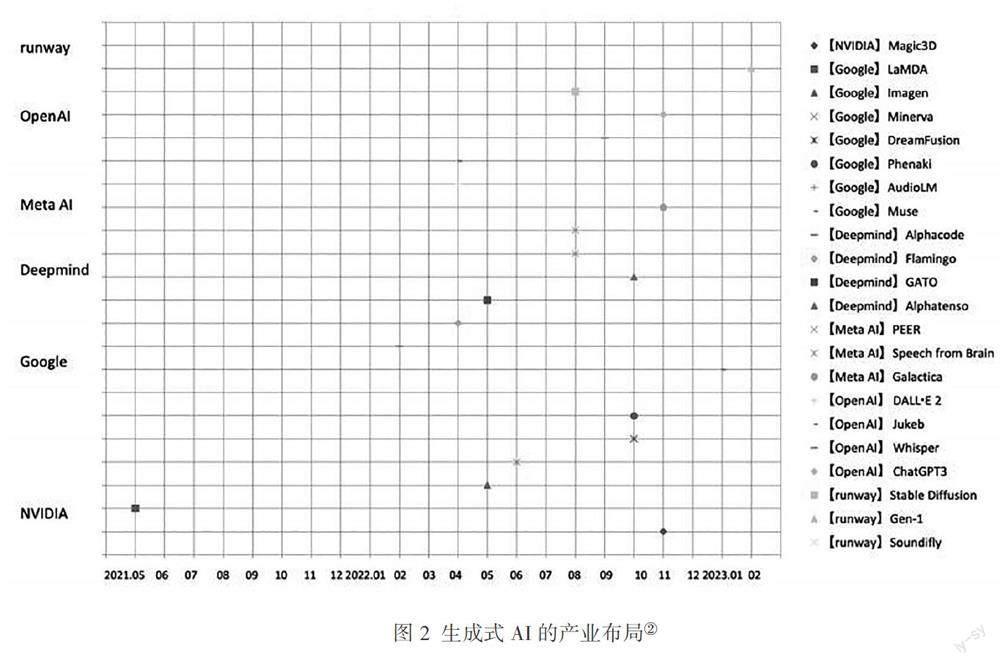
根据图2,通览上述三组类别中的数十项生成式AI模型与产业发展的实际历程可以发现,ChatGPT系列的开发及开源投放既不是占据先发优势的技术破冰者,也不是提供技术基底的系统构架者,甚至在与同类别的模型进行实际比较的多个维度上,都不构成多任务处理的场景便利。因此,思考该模型成为生成式AI代表性产品的根本原因就显得尤为必要,从中可以更全面地理解当前技术社会对于人工智能技术的大众心理预期,以及应答式AI与用户间的互动关系走向。
三、设置“指令”、“苏格拉底之问”与人机协同路径
ChatGPT在正式开放测试之后的三个月内,已经飞速积累起数以亿计的用户,他们在不同语言的场景下对该模型提出应答要求。由人机对话生成的各种回答一次次刷新人们对于AI智能水平的认知视野,也引发了IT界和知识界的震动。《科学》与《自然》两大刊物密集推出连续文章,对该技术可能改变知识教育表示担忧,并提出技术改善和溯源反制的设想。作为知识界和教育界的代表之一,香港大学几乎在第一时间明确公布了绝对的禁令,“禁止在港大所有课堂、作业和评估中使用ChatGPT或其他AI工具,除非学生事先获得有关课程讲师的书面同意豁免,否则将被校方视为剽窃个案。若没有书面许可,ChatGPT和其他基于AI的工具一律不能用于任何涉及学分的活动,若教师怀疑学生使用ChatGPT或其他AI工具,可要求学生就其作业进行讨论、进行额外口试及考试等措施”。1 然而,类似禁令在IT界和其他交叉学科的研究者看来,不仅在现实层面难以操作,而且AI应答技术在未来工作中的扩大使用几乎是“不可避免的”。2
回望近来围绕ChatGPT进行的跨领域应用实践,以色列总统伊萨克·赫尔佐格(Isaac Herzog)的案例具有特别的示范性。根据英国天空电视台的时事新聞现场视频,赫尔佐格在2023年2月出席了于特拉维夫举行的重大网络安全会议,面向数千名高新技术企业的从业者发表了一段开幕发言。他先用完全正确的语法描述了以色列在人工智能等前沿领域取得的前沿成果:
Over the past few decades, Israel has consistently been at the forefront of technological advancement, and our achievements in the fields of cybersecurity, artificial intelligence (AI), and big data are truly impressive.
接下来,再以完全合乎发言者政府领导人身份的口吻,高度赞誉了本国高科技公司在世界舞台上的亮眼表演:
From the development of cutting-edge cybersecurity technologies to the establishment of successful startups, Israeli hi-tech companies have made a significant impact on the global stage.
然而,在常见流程下即将用励志语录进行总结的最后环节,ChatGPT作为发言稿的“特别助手”被推到了众人瞩目的聚光灯下。比借助ChatGPT完成政府发言稿更重要的是,赫尔佐格在发言结尾坦然说明了这篇机器答问的驱动重点在于“让机器人开始行动”。继而,以色列总统办公室向天空电视台新闻的采访做出进一步证实,生成此次任务的提示语设计是“写出一篇人类在超人技术世界中发挥作用的励志语录”。3
赫尔佐格的ChatGPT生成文本之所以比网络上流传的各种类型的应答生成更具有样本意义,并非因为使用者的政治身份更加特殊,也不是因为该文本的生成质量明显趋近于政府公文,而是因为使用者在完成演讲过程中,及时坦承了工具来源,以及最重要的,通过建构怎样的驱动指令才能生成符合使用者预期的机器应答。换言之,对话型AI在经过多次问答环节后能够产出怎样的内容,在很大程度上既取决于它的技术基础,也取决于“指令”如何构建。在收到具体任务的文本指令后,根据预训练过程中的数据标注进入专门的LLMs,在基于“人类反馈强化学习”的基础上生成应答内容。对话框中最后会出现怎样的语句段落,不仅与大语言模型中的数据链有关,还和文本指令在拟定过程中的微调或修正直接相关。由此也构成了生成式AI在导出内容后的条件反溯。用户本身对于任务主题的理解程度,以及用怎样的文本进行指令驱动,在当前阶段里显得比程序所能应答出的实际内容更为重要。1
生成式AI对于“指令”的依赖程度颠覆了一般意义上的“对话”文体,将凝聚西方思想传统的“在场”的对话进行了全面改写。从西方思想史的脉络来看,始于古希腊时期的“对话”是承载哲学思想启蒙的根源。柏拉图对话录中记载的苏格拉底与同时代不同人员的对话几乎覆盖了当时可能认知到的所有知识范围。进行对话的最高宗旨不是为了交换信息,而是通过共同在场的活性思维来探求认知个体对于某一对象的真实认知。对话可能达到的“真”不只是针对认知对象的固有知识,同时也是智慧上的“解蔽”,让对话人经由对话的方式向内反转,认识到自己对某一对象的认知程度,最终实现的是德尔菲神庙的门楣神谕:认识你自己(to Know Yourself)。只能说,ChatGPT在典型的苏格拉底对话中很难找到存身之处,根本分歧在于发起对话的原因不同。苏格拉底是提问方,但是他的问题指向不是要从对方的回答中有所获取,而是让回答者对自己的认知情况形成判断。正是在这个意义上,对话成为在场者的思想的交流。ChatGPT则完全相反。如果没有恰当的、有针对性的指令,无论多大规模的LLMs都是循环在内部存储中的纯粹数据流动。如果指令内容尚未包含在已有的预训练范围内,则有可能出现对话不能启动,或者尽管生成了对话,所答却与所问不相契合,甚至毫无关联、完全荒谬。如从图3可以看到ChatGPT在电影知识存储方面的中国谱系盲点。在有问必答的程序预先规定下,哪怕它对中国著名导演费穆一无所知,也要强不知以为知,用一字之差的物理学家“费米”构成应答内容。
ChatGPT在生成回答后的道歉环节已经在应用中成为标准配置。其中的指令输入—快速生成—判断正误—道歉的信息链触发方式,在根本上正在偏离人工智能概率推理算法中的马尔科夫链。根据工作机理的不同,马尔科夫链的仿真推理采样算法“可以被视为在状态空间中——所有可能的完整赋值的空间——的随机走动——每次改变一个变量,但是保证证据变量的值固定不变”。3 利用马尔科夫链所能达到的稳态分布(Stationary Distribution),升级后的GPT文本生成工具曾经成功地帮助名为Benjamin的AI剧本写作软件,完成了第二部科幻短片Zone Out(2018)。整个任务在48小时内完成,指令层次是多重的,包括给定的片名“Zone Out”,生发对话的提示句“他们要严肃地称之为‘亚当”,道具与行动的设计所基于的描述是,“人物手持镜头,在转动中反射出明亮的光”。再考虑到竞赛单元所在的伦敦科幻电影节的特殊性质,多处指令中的最后一条是“用作备选项的科学观念”,“一种只针对孕妇的基因定制病毒”。1 从该片在网络上公布的在线放映情况看,升级后的Benjamin不再自我局限于预训练的语料库,它摆脱了初级阶段的剪切、复制和语料粘贴,做到了以人类剧作为模仿对象,通过预测字母与词语的共同出现倾向来生成语句,并利用公共领域的电影片段对短片中的人物表演进行“换脸”(Faceswap)的复杂操作。
ChatGPT和名为Benjamin的剧本算法在开放的AI技术系统中共享了GPT3的神经网络卷积平台,拥有共同的人机协同基础,然而二者在结果生成的指令设置方面存在差异,所依据的数据库也完全不同。后者的预训练数据保持在同类型成果的边界以内,可以清晰地回溯路径并辨识出风格迁移的关联元素,且最终成果在生成后达到了一般意义上的文本规模,作为结构独立的人机协同作品而存在,不再自动融入源数据。与此相反,ChatGPT将生成式AI的应用场景带入普遍的用户终端,虽然意外地提早实现了人工智能产业在全球视野中的破壳而出,却是以指令触发方式的容错率为代价,一方面将算力资源最大可能地集中在应用的便利和效率方面,另一方面则是超大扩容大语言模型,降低甚至是裁撤对于数据内容的标注点数量。因此,大幅提高人机协同中的机器产出占比所导致的路径问题在于,“有很多人工智能生成的文本可能很快就会进入文献中”。《科学》杂志的主编霍尔顿·索普(H. Holden Thorp)分析了ChatGPT从LLMs中析取出的应答成果可能造成的误用,指出“有时候ChatGPT会写出一些听起来言之凿凿而实际上既错误又荒谬的回答”。2 联系前文图3呈现的“费穆”与“费米”之间的混淆和张冠李戴,就可以完全理解《科学》编辑部为什么将ChatGPT写出的文段定义为“抄袭”(Plagiarized)。该刊还明确表述,未来除了创作者有意识地使用AI工具辅助生成合法的数据集,其他所有借助生成式AI完成的产品,无论是文本、图表、图形还是图像,都是工具性剽窃,是科学类学术期刊“不可接受的”。
除了部分学术期刊有条件地拒用ChatGPT之外,还有不同语类的文学杂志先后对此发出否定性公告。随着ChatGPT技术的滥用,AI生成的稿件数量激增,使专业审稿的编辑行业感受到强烈的冲击。中国著名的科幻杂志《科幻世界》对外宣布“不接受AI创作的科幻小说”,美国科幻杂志《克拉克世界》(Clarkesworld)更是直接关闭了自由投稿通道。我们从中看到的悖论是:生成式AI不仅没有如其所许诺的那样成为人的助力,反而导致负面效应,挟制了人的创制性道路。正如泰格马克(Max Tegmark)在提出阿西洛马人工智能原则时对科幻作家阿西莫夫(Issac Asimov)名言的引用,“生命最大的悲哀莫过于科学汇聚知识的速度快于社会汇聚智慧的速度”,3 对于ChatGPT造成的当前境地,这句名言或许可以仿写为:技术最大的悲哀莫过于AI生成文本的速度快于人类写出作品的速度。人机协作路径在未来发展的方向上需要反思新的可能性,其中的关键或许正在于技术系统如何做到真正的开源、开放和安全。
四、结语:真正开放的专家型系統
针对AI系统的安全和开放问题,埃隆·马斯克(Elon Musk)在社交媒体上发表了最新看法。他回顾了自己作为OpenAI创始人的企业理想是“创建一个真正开放的非营利性公司,与谷歌相抗衡”,并以此来反对微软将其改造为“非开源的、追求利润最大化的公司”。越来越多的专业研究者发现,在繁花似锦的表象下,ChatGPT及其前期模型ChatGPT3并没有完全公开它们的基础训练集和大型语言数据库。生成式AI的对话模型在技术系统内部的运作方式也不透明,数据闭环导致了内容生成过程析出大量冗余信息,间或出现知识盲点甚至常识性谬误。这与趋向透明和科学日益开放的进步观念背道而驰,也使得应用者很难发现一场对话在知识谱系上的起源或缺失。
事实上,不公布项目开发的源代码意味着系统在技术上的实际封闭,而在系统理论中,“系统的开放是系统自组织演化的前提条件之一”。1 当对话模型只限于模式化的应用场景,通过互联网提供的平台来构建人机交互界面并虚拟出人机对话的在场感时,使用生成式AI作为辅助的人类个体就背离了作者的定位,而仅仅是在一次次指令设置的调整修改中变为不断降智的临时用户。假设那些不明确的信息源和不能充分判断的生成结果继续自动返回系统本身,“自行独立演化”的后果很可能就是在网络化的知识空间中增加了大量并非由人完成的“突变”。2 因此,对于构建专家型系统的呼吁和进一步向公众开放生成式AI技术的呼吁变得同等重要。在经历了各种兴奋的业绩增长和难以预测的抵制或禁用之后,OpenAI在公司主页上做出了提示语的调整,从“形塑未来的技术”改回了“创建安全的、使全人类受益的人工智能”(Creating safe artificial intelligence that benefits all of humanity)。之所以用“改回”来形容这次研发方向上的调整,是因为该公司在最初成立的时候,关于人工智能的原则讨论集中在两个方面:一是伦理意义上的“安全系统”,二是价值定位上的“服务于全人类利益”。如果对于全人类福祉的考虑能够真正成为生成式AI的未来技术开发重点,也将意味着一个真正开源、开放的系统正在建构当中。
ChatGPT: Generative AI versus “Socratic Inquiry”
YANG Junlei
Abstract: As a new technology branch in the field of artificial intelligence, generative AI has formed nine groups of application categories in almost 20 years of industrial development and layout. ChatGPT, as an emerging product of human-computer dialogue model, has undergone continuous technology updates and sparked a global discussion on how AI will assist human work in the future. Based on the “Socratic inquiry” and the analysis of logical elements, it can be found that the dialogue model of generative AI relies more on the “instruction” setting, which is different from the traditional dialogue style. The dialogue of “presence” that unites the Western intellectual tradition is rewritten as an internal circulation of data flow. The construction of open systems for the benefit of all humanity is becoming the basis for consensus on how to guarantee the safety of human-computer collaboration.
Key words: ChatGPT; AIGC; Socratic inquiry; dialogue model; opening system
(責任编辑:苏建军)
