基于词嵌入和BiLCNN-Attention混合模型的政务文本分类方法
2023-06-15胡文烨许鸿奎郭旭斌赵京政
胡文烨 许鸿奎 郭旭斌 赵京政
摘 要: 针对政务文本分析语境复杂、分类准确率低的问题,提出基于BERT词嵌入和BiLCNN-Attention混合模型的文本分类方法。首先采用BERT模型对政务文本进行词嵌入向量表示,然后混合使用双向长短时记忆网络BiLSTM和卷积神经网络CNN,同时引入注意力机制进行特征提取,融合了时序特征及局部特征并使特征得到强化,最后使用Softmax进行文本分类。实验表明,BERT词嵌入处理后混合模型的准确率较CNN和BiLSTM模型分别提升了3.9%和2.51%。
关键词: 政务文本分析; 词嵌入; 双向长短时记忆网络; 卷积神经网络; 注意力机制
中图分类号:TP391.1 文獻标识码:A 文章编号:1006-8228(2023)06-92-05
Method of government text classification based on word embedding
and BiLCNN-Attention hybrid model
Hu Wenye1, Xu Hongkui1,2, Guo Xubin1, Zhao Jingzheng1
(1. School of Information and Electrical Engineering, Jinan, Shandong 250000, China;
2. Shandong Provincial Key Laboratory of Intelligent Buildings Technology)
Abstract: Aiming at the problems of complex context and low classification accuracy of government texts, a text classification method based on BERT word embedding and BiLCNN-Attention hybrid model is proposed. Firstly, the BERT model is used to represent the word embedding vector of the government text. Then, BiLSTM and CNN are mixed, and the attention mechanism is introduced for feature extraction. The timing features and local features are integrated and strengthened. Finally, Softmax is used for text classification. Experiments show that the accuracy of the hybrid model after BERT word embedding is improved by 3.9% and 2.51% compared with CNN and BiLSTM models, respectively.
Key words: analysis of government texts; word embedding; bi-directional long and short-term memory (BiLSTM); convolutional neural network (CNN); attention mechanism
0 引言
信息技术的快速发展为各行业发展注入了新的活力。随着电子政务由信息化向智慧化转变,文本分类技术作为能够加速政务工单审批、提高互动效率的可行途径之一,逐渐受到了广泛认可和关注[1]。
文本分类研究始于二十世纪五十年代[2],其方法主要包括机器学习算法和深度学习算法[3],机器学习算法如朴素贝叶斯、支持向量机等,深度学习算法如卷积神经网络、循环神经网络等。政务文本分析语境,其复杂性所导致的数据与算法匹配不充分问题是文本分类的一个难点。要提高文本分类准确性,分类模型构建、词嵌入表示及特征提取是重要环节。分类模型需根据研究场景调整,文本词嵌入在很大程度上决定了后续任务的整体性能,基于数据挖掘的特征提取可以构建数学模型,以解决传统二进制表示[4]方法应用时维度灾难的问题。本文采用BERT模型作为词嵌入表示,提出了BiLCNN-Attention混合神经网络,实现对政务文本分类效果的提升。
1 相关研究
政务文本分类场景使用神经网络模型可自动提取特征并进行文本分类,而文本词嵌入表示是提高模型效果的方法之一。2003年Bengio等人[5]提出了词向量的概念,之后Collobert和Weston里程碑式的引入了神经网络模型结构[6],2013年Tomas Mikolov[7]等提出word2vec,2018年ELMo模型[8]和BERT[9]模型相继被提出。应用方面,文献[10-11]实现了BERT模型在政民互动留言的分类,文献[12]采用融合BERT和注意力机制的方法进行中文文本分类研究,文献[13]将BERT与BiLSTM算法结合进行命名实体识别。
在CNN的应用发展中,2008年Collobert和Weston[14]率先提出了CNNs,2014年Kim Yoon[15]提出TextCNN模型用于文本分类。RNN也用于文本分类,并衍生出了长短期记忆网络LSTM,在中文文本分类上取得了较好结果。文献[16-17]均采用CNN与LSTM模型结合的方式提高文本分类任务的准确性,文献[18-19]融入了注意力机制,以更好的捕捉文本数据中的局部信息。
2 BERT词嵌入和BiLCNN-Attention混合神经网络模型
2.1 BERT+BiLCNN-Attention模型
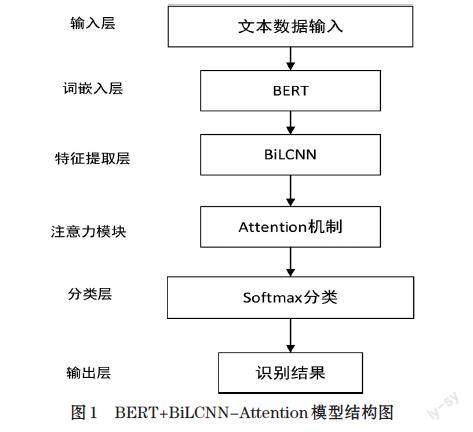
BERT+BiLCNN-Attention模型结构如图1所示。图1中,预处理后的政务文本数据作为输入,利用BERT模型进行词嵌入表示,而后输入BiLCNN-Attention混合神经网络中进行特征提取和学习并融合,经过Softmax层进行分类结果预测,输出模型识别结果。
2.2 BERT词嵌入模型
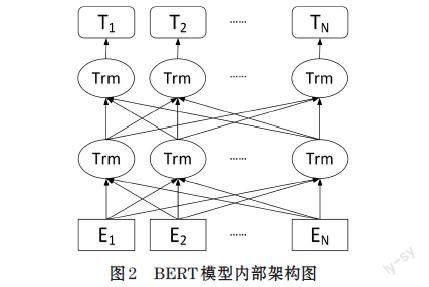
BERT作为动态词嵌入模型的典型代表,既可以直接进行文本分类,也可以作为词嵌入层处理文本数据。BERT模型架构如图2所示,它可以共同调节left-to-right和right-to-left的transformer,并通过将预训练模型和下游任务模型结合在一起,更注重于识别句子中单词之间或句子之间的关系,使整体性能大大提升。
BERT词嵌入的本质是运用自监督的方法进行特征学习,并给目标单词或句子赋予特征表示。经过BERT模型处理后的词向量由三种不同向量求和而成,包括Token Embeddings、Segment Embeddings、Position Embeddings。按元素相加后得到(1,n,768)的合成表示,句向量之间的分隔以[CLS]作为开头标记,[SEP]作为结尾标记,加入向量表示结果中即为词嵌入层的编码结果。
2.3 BiLCNN-Attention混合神经网络
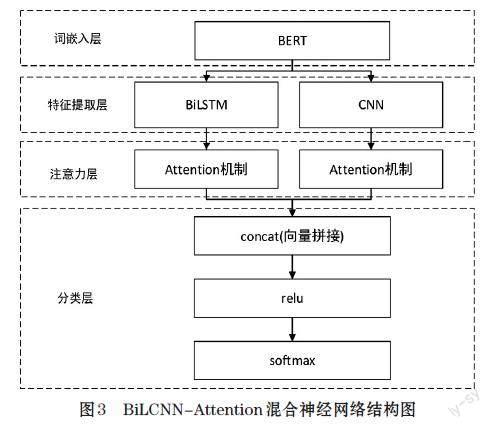
词嵌入表示后的向量经过BiLSTM和CNN处理形成特征向量,再引入Attention机制进行参数优化以提高模型的拟合能力,而后进行特征融合,最后经由sofmax层得到分类预测结果。图3为BiLCNN-Attention混合神经网络结构图。
2.3.1 BiLSTM模型
原始RNN在训练时容易出现梯度爆炸或梯度消失的问题,因此不能处理距离较远的序列数据,而LSTM能够克服这一问题。LSTM通过控制细胞状态对信息进行读取、写入和删除操作,其核心结构如图4所示。
LSTM细胞由输入门、遗忘门、输出门和单元状态组成。其中输入门决定当前时刻输入数据量[Ct],遗忘门决定上一时刻需要保留的状态量[Ct-1],输出门控制输出量。以[ht-1]代表上一时刻输出,[xt]代表当前时刻输入,[Vt]代表当前时刻暂时状态,[ht]代表最终输出,其工作过程如式⑴~式⑹所示。
[ft=σWf?ht-1,xt+bf] ⑴
[it=σWx?ht-1,xt+bi] ⑵
[Vt=tanhWc?ht-1,xt+bc] ⑶
[Ct=ft*Ct-1+it*Vt] ⑷
[Ot=σWo?ht-1,xt+bo] ⑸
[ht=Ot*tanhCt] ⑹
其中,[W]、[b]分别表示单元的权重向量和偏置值,[σ?]表示sigmoid激活函数,[tanh]表示双曲正切激活函数。
为了在特征提取中兼顾过去和未来时刻的序列信息,Graves等人[20]提出BiLSTM模型。BiLSTM模型由前向和后向的两个LSTM叠加构成,可以更好的捕捉双向的语义依赖。在某一时刻[i],BiLSTM的输出向量为前向和后向的向量按位加和操作结果,如式⑺表示:
[hi=hi⊕hi] ⑺
2.3.2 CNN模型
CNN的核心结构包括输入层、卷积层、池化层以及全连接层。词向量输入CNN模型时工作过程如下。
对于输入序列输入序列[S=t1,…,tn],[S∈Rd×n],其中,[ti]为词向量,[n]为词向量数量,[d]为词向量的维数。设置卷积核[K]进行卷积操作[S∈Rd×h],[h]为卷积窗口取词数,则利用卷积核[K]对输入序列[S]的卷积运算及池化运算如式⑻-式⑼表示:
[Ci=tanh
[yi=maxiCi] ⑼
其中,[yi]为池化计算得到的向量结果,[yi∈R]。当选择不同尺度卷积核进行卷积计算时,将[yi]进行向量合并,得到最终运算结果。利用这种方式进行卷积计算,可以更好的表征政务文本数据的特征。
2.3.3 Attention机制
注意力模型在训练过程中将计算每个单词的权重系数,计算过程如式⑽~式⑿所示:
[ei=tanh(hi)] ⑽
[αi=Softmax(wTiei)] ⑾
[yi=hiαTi] ⑿
其中,[hi]为特征提取层的模型输出,[αi]为注意力权重系数,[wi]为权重矩阵,[yi]为注意力机制的输出。
本文联合使用BiLSTM及CNN神经网络建立语义向量信息,在特征提取层的输出端引入Attention机制,突显语义信息与上下文之间的关联性,有效增强语义信息的特征表达,从而提升模型分类性能。
3 实验
3.1 实验环境
实验基于Windows10操作系统,CPU为Intel(R) Core(TM) i5-10300H CPU@2.50 GHz,内存容量为16GB,GPU为NVIDIA GeForce GTX 1650,Python版本为3.7,Pytorch版本为1.5。
3.2 实验数据
实验数据来自政务热线系统脱敏数据,原始数据量123277条。文本类型按照政务事件处理部门进行直接划分,类型标签包含城管、交警、供电公司、管委会、热电、民政、消防、林业等90个政务部门。原始数据采用随机划分的方式,将每个标签对应的数据以8:1:1的比例划分为训练集、验证集、测试集。使用训练集作为模型训练数据,使用验证集在训练过程中评价模型性能,使用测试集在训练完成后评价模型性能。
3.3 实验评价指标
实验过程中,模型性能评价指标为准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数,其中统计全类别精确率、召回率、F1分数的方法为macro方法。
3.4 实验设置
在综合考虑实验中的准确率与过拟合因素后,实验参数设置方面使用Adam优化器,词嵌入向量维度设置768,epoch参数设置20,学习率设置1e-5。
3.5 实验结果与分析
选择不同的词嵌入方式和不同的特征提取方法进行对比实验,实验结果如表1所示。
⑴ 在词嵌入层上BERT模型具有明显的性能优势,各项性能指标明显高于word2vec,在与CNN、RNN/BiLSTM进行融合时,BERT+CNN的准确率比word2vec+CNN高1.71%,BERT+BiLSTM的准确率比word2vec+RNN高1.81%。
⑵ 在单一特征提取模型处理上,RNN/BiLSTM模型的处理效果优于CNN模型,更适合处理政务文本分类任务。
⑶ BERT+BiLCNN模型准确率相较于BERT+CNN模型和BERT+BiLSTM模型分别提升了2.50%、1.11%。可见,混合神经网络BiLCNN融合了BiLSTM以及CNN的特征和优点,使得特征向量表示信息更加丰富。
⑷ BERT+BiLCNN+Attention模型相较BERT+CNN、BERT+BiLSTM以及BERT+BiLCNN模型准确率提升了3.9%、2.51%和1.4%,注意力机制的加入使得重点特征更加突出,类别间特征区分更加明显。
4 总结
本文基于实际应用中政务热线系统脱敏数据进行文本分类分析,提出了词嵌入和BiLCNN-Attention混合神经网络的文本分类方法。实验结果表明,BERT模型相较于word2vec模型表现出明显的性能优势,BiLCNN-Attention混合神经网络能够融合多方优点,在特征向量表示上更加丰富,各项评价指标都有所提升。
参考文献(References):
[1] 陈思琪.基于深度学习的电子政务文本分类算法研究[D].
硕士,西安电子科技大学,2021
[2] 毕云杉.基于深度学习的中文文本分类研究[D].硕士,浙江
科技学院,2021
[3] 贾澎涛,孙炜.基于深度学习的文本分类综述[J].计算机与
现代化,2021(7):29-37
[4] 李炳臻,刘克,顾佼佼,等.卷积神经网络研究综述[J].计算机
时代,2021(4):8-12,17
[5] Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C.
(2003). A neural probabilistic language model. Journal of machine learning research,2003,3(Feb):1137-1155
[6] Collobert, R., & Weston, J. (2008). A unified architecture
for natural language processing. In Proceedings of the 25th International Conference on Machine Learning (pp. 160-167)
[7] Mikolov T, Chen K, Corrado G, et al. Efficient estimation
of word representations in vector space[J].arXiv preprint arXiv:1301.3781,2013
[8] Peters M, Neumann M, Iyyer M, et al. Deep Contextualized
Word Representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers),2018
[9] Devlin J, hang Mingwei, ee K, et al. BERT: Pre-training of
eep Bidirectional Transformers for Language Understanding[J]. 2018
[10] 茶麗菊.基于深度学习的政民互动留言文本分类研究[D].
硕士,东华大学,2022
[11] 范昊,何灏.融合上下文特征和BERT词嵌入的新闻标题分
类研究[J].情报科学,2022,40(6):90-97
[12] 孙红,陈强越.融合BERT词嵌入和注意力机制的中文文本
分类[J].小型微型计算机系统,2022,43(1):22-26
[13] 胡为,刘伟,石玉敬.基于BERT-BiLSTM-CRF的中医医案
命名实体识别方法[J].计算机时代,2022(9):119-122,135
[14] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural
language processing (almost) from scratch[J]. Journal of machine learning research,2011,12(1):2493-2537
[15] YOON KIM. Convolutional Neural Networks for
Sentence Classification[C]. //Conference on empirical methods in natural language processing, (EMNLP 2014),25-29 October 2014, Doha,Qatar:Association for Computational Linguistics,2014:1746-1751
[16] 马正奇,呼嘉明,龙铭,等.运用CNN-LSTM混合模型的短
文本分类[J].空军预警学院学报,2019,33(4):295-297,302
[17] 王星峰.基于CNN和LSTM的智能文本分类[J].辽东学院
学报(自然科学版),2019,26(2):126-132
[18] 赵云山,段友祥.基于Attention机制的卷积神经网络文本
分类模型[J].应用科学学报,2019,37(4):541-550
[19] 汪嘉伟,杨煦晨,琚生根,等.基于卷积神经网络和自注意力
机制的文本分类模型[J].四川大学学报(自然科学版),2020,57(3):469-475
[20] Graves A, Schmidhuber J. Framewise phoneme classifi-
cation with bidirectional LSTM and other neural network architectures. Neural Networks,2005,18(5-6):602-610
