一种面向二维三维卷积的GPGPU cache旁路系统
2023-05-11贾世伟张玉明孙成璐
贾世伟,张玉明,秦 翔,孙成璐,田 泽
(1.西安电子科技大学 微电子学院,陕西 西安 710071;2.西安翔腾微电子科技有限公司,陕西 西安 710068;3.中国航空计算技术研究所 集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
1 引 言
近年来GPGPU等硬件平台算力的大幅度提升,对深度神经网络算法的实际应用提供了有效的支持[1]。而卷积神经网络因其自组织、自学习、强泛化性的特点[2-3],被广泛应用在目标识别检测领域,目前在人脸识别、车牌识别等静态、低速场景中已十分成熟[4-9]。未来卷积神经网络面向车辆、无人机、导弹等动态强实时目标识别领域的不断扩展,以及新网络运算量的不断增加,对硬件平台的计算能力、存储性能均提出了更高的要求,研究面向卷积神经网络的平台优化方案十分重要[10-11]。而卷积操作作为卷积神经网络的核心算子,其包含了大量的计算与访存操作,因此是硬件平台优化设计的重中之重。
许多研究人员进行了相关的探索研究。文献[12]提出了硬件结构通过转换矩阵减少卷积中的乘运算,但当网络模型增大时会增加大量的加运算。文献[13]使用索引表记录非0权重,计算中通过表解码来去除0元素引入的无效计算。在访存优化方面,文献[14]通过大量的处理元件(Processing Element,PE)单元实现卷积操作的并行,单元内包含保存权重值的静态存储以降低访存延时。文献[15]观察到权重值的重用性,因此在PE中使用buffer一次性缓存一行特征值,通过PE滑动来计算一行的结果。上述的优化策略均基于网络算法与硬件平台紧密耦合的设计思路,虽然得到了一定的性能优势,但均缺乏通用性与可扩展性,只能在部分算法中取得良好的效率。且由于核内存储的工艺成本昂贵,上述的架构设计难以增加更多的片上资源,因此无法适用于网络规模较大的情况。而GPGPU因其海量多核并行计算架构的特点,天然适合于大规模卷积的并行计算[16]。2012年,HINTON等正是在GPGPU上首次部署AlexNet网络,并以显著的功性能优势赢得了ILSVRC 2012比赛,从而引领了计算机视觉的新一波浪潮;此后面向卷积神经网络,GPGPU架构也进行了多次优化。NVIDIA考虑到通用矩阵乘(GEneral Matrix Multiplication,GEMM)是神经网络的核心数学操作,在GPGPU Volta架构中首次增加了张量(Tensor)核心专用于执行矩阵乘加操作。NVIDIA同时还提供了神经网络专用加速库cuDNN,确保程序开发者以最优的效率使用张量核心[17]。紧接着,NVIDIA在GPGPU Turing架构中推出了第2代张量核心设计。考虑到神经网络具备一定的误差容忍性,第2代张量核心新增加了INT8与INT4工作模式[18]。虽然网络的计算精度有所降低,但张量核心的执行效率被大幅度提升,因此Turing 架构GPGPU被广泛用于加速高误差容忍场景下卷积神经网络的计算。2020年,NVIDIA推出的GPGPU Amper架构在前一代架构基础上进一步引入了对神经网络稀疏性开发的硬件支持。Amper架构能够根据神经网络稀疏性来压缩权重,并提供了专用的稀疏矩阵乘累加运算单元。该运算单元能够动态检测并跳过网络中零值的计算,因此进一步提高了张量核心的计算吞吐[19]。2022年,NVIDIA最新的GPGPU Hopper架构进一步为张量核心引入了转换引擎(Transformer Engine)控制逻辑。首先,转换引擎会在神经网络执行时动态分析张量核心的输出,并确定下一神经网络层的类型与数据精度需求。其次,转换引擎会根据分析结果动态转换后续网络层计算的数据精度,进而充分开发张量核心在不同精度下的强大计算性能[20]。通过历代GPGPU架构回顾可以发现,NVIDIA在面向深度神经网络优化时采取了以下3种思路:根据场景特征设计专用加速单元、增加对多种数据精度的支持以及不断增加计算核心数量。然而,各代GPGPU架构在其访存流水线方面除了增加片上存储资源容量与带宽外,并未针对卷积因子的访存特征进行相应的优化。
基于上述研究,笔者从二维、三维卷积在GPGPU上执行时的访存特征出发,提出一种GPGPU L1Dcache动态旁路系统设计。本设计能够动态识别出二维、三维卷积中具有低局域性的访存请求数据并控制其对L1Dcache旁路,进而降低访存阻塞周期。与此同时,高局域性的数据能够更有效地利用旁路操作所节省下来的L1Dcache资源,访存效率也因此而提升。为此,首先通过一组访存特征功能域来记录访存请求在L1Dcache中分配数据的局域性开发状态,然后优化了多线程调度策略以加速访存状态的采集,最后基于访存状态特征动态决定后续访存请求数据对L1Dcache的旁路。采用GPGPU-sim(3.2.2版本)架构模拟器实现了L1Dcache旁路优化设计,并运行标准二维、三维卷积进行功性能验证。实验结果表明,提出的设计相比基础架构分别降低了约7.63%与21.40%的访存阻塞周期,性能提升分别达到约2.16%与19.79%,证明了设计的有效性。
2 背景知识
2.1 GPGPU体系结构与存储系统
图1为GPGPU基础架构。GPGPU采用单指令多数据(Single Instruction Multiple Data,SIMD)计算架构,通过少量控制资源控制大量执行核心,并行执行不相关的多线程任务,以带来极高的算力与能效比。所有的执行核心被均匀地划分为多个执行组统一管理,这些执行组在GPGPU中被称为流处理器(Streaming Processor, SM)。一个SM的所有执行核心共享一组片上资源,这些片上资源包括指令cache,取指-译码单元、L1Dcache、共享存储、warp 调度器等。在不发生阻塞的条件下,SM中的每个执行核心在每一周期都能独立地执行一条线程指令。

图1 GPGPU架构示意图
当不同应用领域场景程序在使用GPGPU加速时,编程者需要解析程序中的可并行部分,并将这部分任务定义成核(kernel)函数的形式以供程序主函数调用。当程序运行时,CPU通过互联总线将需要处理的数据搬运到GPGPU存储中,接着完成kernel函数的启动。GPGPU线程分发单元首先根据kernel函数参数生成海量多线程,接着将这些线程以线程块(Thread Block,TB)为单位下发到各个SM中。进入到SM中的线程以线程束(warp)为单位进行调度与执行,一个线程块通常包含多个warp。每一周期warp调度单元按预定义的调度排序策略对SM中的所有warp进行优先级排序,并根据排序结果来依次判定各warp是否可以发射执行。在不同的周期中各warp通过交替调度执行来隐藏指令的执行延时,确保GPGPU计算核心得到有效利用。
为支持海量多线程的高效访存,GPGPU设计了复杂多层级存储系统,如图1所示的GPGPU存储系统一共分为4级。第1级为寄存器文件,其内部集成了大量高速寄存器,并为SM中每个线程都分配了独立的寄存器空间。寄存器文件访问效率最高,但工艺开销也最大。第2级存储包括共享存储与L1Dcache,与寄存器文件不同,二级存储由SM内部的所有线程共享。共享存储面向编程者开放,用于静态保存程序中最需要频繁读取的数据,该存储中保存的数据需要编程者在主程序中手动指定。而L1Dcache作为影响访存流水线性能的核心组件,动态保存访存指令请求的数据。当warp执行一条访存指令时,其内部的所有线程会首先对比各自请求数据的地址以进行访存合并,由此产生多个访存请求。接着各访存请求会依次访问L1Dcache以进行数据查找,如果数据已存在于L1Dcache中,则L1Dcache将此数据直接返回到寄存器中;如果数据不存在,则L1Dcache会寻找其内部能够被替换的数据空间,并将访存请求传输给更下一级存储。当请求数据从下级存储中返回时,L1Dcache会将其写入到可被替换的数据空间中以完成保存。第3级存储为L2Dcache,其与L1Dcache的功能一致,但由各个SM所共享,由于工艺限制,片上cache的资源十分宝贵,其容量无法像片内计算核心数量一样在不同代的GPGPU架构中快速增加。最后一级存储为全局DRAM,该存储的容量最大,但访问的效率也最低,一般用于保存GPGPU与CPU交互的输入输出数据。
2.2 存在问题
为了解当前二维、三维卷积在GPGPU上执行时的访存特征,笔者在3种不同的L1Dcache配置下运行了二维、三维卷积并收集其访存请求访问L1Dcache的缺失率。L1Dcache容量越大,表示数据能够保留的周期越长,也即L1Dcache提供的数据局域性开发能力越强。实验结果如图2所示。

图2 不同容量下二维、三维卷积L1Dcache缺失率
可以看到,随着容量的增加,二维、三维卷积的L1Dcache缺失率不断下降;特别是三维卷积,其缺失率由16 KB L1Dcache对应的77.12%下降为512 KB对应的37.99%。这说明受L1Dcache容量的限制,二维、三维卷积中部分数据局域性未得到充分开发。
为得到更细致的访存特征信息,逐一分析了二维、三维卷积中每条访存指令在不同L1Dcache容量下的请求缺失率。为了确保实验可靠,对每一条访存指令都随机采集其50次执行时的状态,并通过求平均的方式得到其L1Dcache缺失率。三维卷积的实验结果如图3所示。
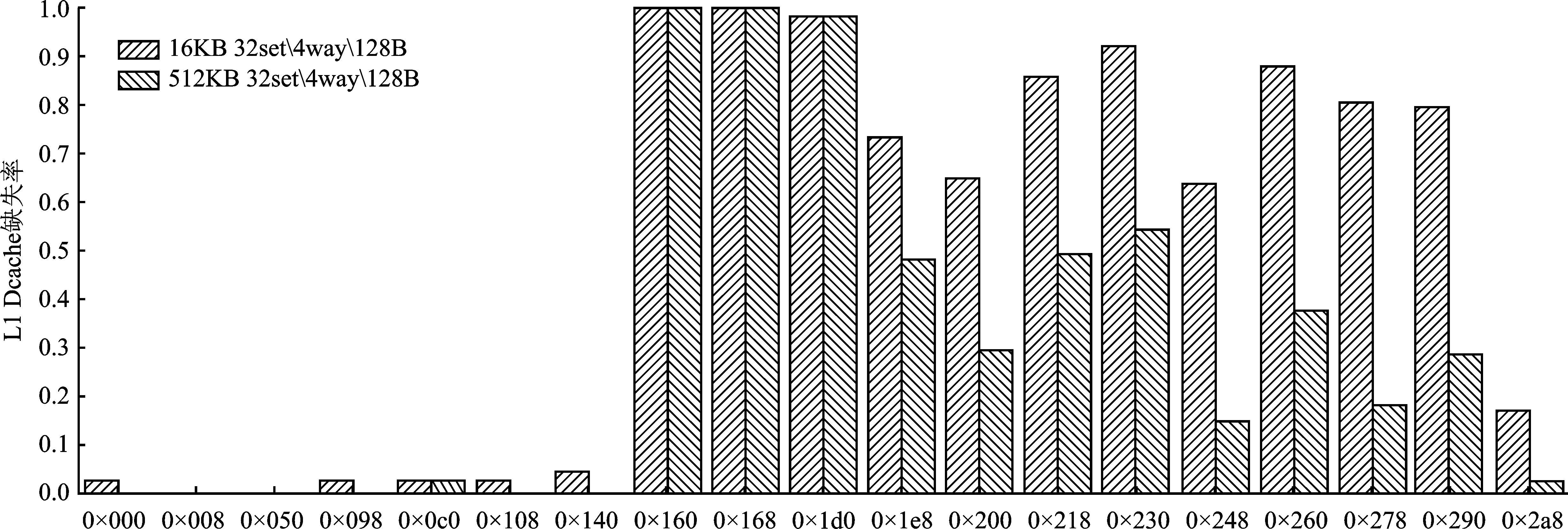
图3 不同L1Dcache容量下三维卷积各访存指令L1Dcache缺失率
可以看到,随着容量的增大,三维卷积中访存指令0×1e8、0×200、0×218等指令的L1Dcache缺失率显著降低,这说明这些指令请求的数据本具有更高的局域性,但由于L1Dcache容量限制,这些数据的局域性未能得到充分开发。由此,提出一种能够动态识别出访存数据局域性的L1Dcache旁路设计。通过旁路低局域性数据在L1Dcache中的保存来将空间留给高局域性的请求数据,由此降低L1Dcache缺失率与访存阻塞延时,进而提高二维、三维卷积执行时的访存效率与性能。
3 面向二维、三维卷积的GPGPU L1Dcache动态旁路系统
文中提出的基于访存特征的L1Dcache动态旁路系统包含两部分,分别是在图1的warp调度与L1Dcache部分进行了架构优化创新。首先,提出了一种线程块优先的warp调度策略,该策略预定义一个优先执行的线程块,即在warp调度排序时始终将来自此线程块的warp置于序列的首位。由此来自该线程块的warp总是能够被优先执行,从而加速访存状态采样。其次,提出了一种L1Dcache动态旁路系统,该系统在原先的L1Dcache设计中增加访存状态记录表以动态记录不同访存指令请求L1Dcache时的状态。当访存状态采样结束时,根据表中记录的状态信息动态决定后续访存请求的数据是否需要保存在L1Dcache中。下面对关键模块的设计与工作原理进行详细阐述。
3.1 线程块优先的warp调度策略
为保证访存状态采样的准确性与完备性,将自kernel函数发射至第一个线程块完成所有任务执行的周期定义为访存状态采样周期。传统warp调度采用罗宾环策略,其特点是静态赋予来自不同线程块的所有warp以相同的执行优先级。在这种策略的约束下所有warp会以相同的进度交替发射执行指令,导致访存状态采样无法尽早完成。而文中提出的线程块优先warp调度策略赋予了单一线程块中的warp以最高的调度优先级。该策略通过预定义一个线程块并始终优先其内部warp的执行来加速访存状态采样过程,确保完成采样的状态记录表能够被充分有效地利用。模块设计如图4所示。

图4 线程块优先的warp调度策略工作原理
可以看到,模块的输入除了需要排序的warp序列外,还包括最近执行warpID与优先线程块ID,其中最近执行warpID是指上一周期被调度执行warp的下一个warp的ID,其与预定义的优先线程块ID共同确定本周期内应排在整个序列首位的warp。由于本调度策略规定排在调度序列首位的warp一定来自于优先线程块,因此首先判定最近执行warpID是否来自于优先线程块,若判定通过,则就将此warp排在序列首位;若不通过,则将优先线程块中的第一个warp排在序列首位。接着,按顺序将优先线程块中的剩余warp排在当前序列的尾部,由此优先线程块内的所有warp首先完成了排序,并被放置在整个warp序列的最前端。这些warp有最高的优先级被调度、发射与执行。接下来需要对输入warp序列中的剩余warp排序。这里根据第一步的判定结果分为两种情况:如果最近执行warpID属于优先线程块,则以优先线程块后第一个warp为首warp,将剩余的warp按顺序排列在序列的末尾;如果不属于,那么还是要以最近执行warpID为首,将剩余warp按顺序排在序列末尾。这种方式保证除去优先线程块外,剩余的所有warp具有一致的优先级。最后将完成排序的warp序列输出到warp调度单元,以进一步完成后续warp发射与执行的判定。
3.2 基于访存状态的L1Dcache动态旁路
文中L1Dcache旁路设计的思想就是动态决定保存在L1Dcache中的访存请求数据,通过将L1Dcache存储空间保留给具有较高局域性的数据,达到降低L1Dcache缺失率与存储阻塞周期,提高性能的目的。为此,首先构建能够反映访存请求状态的数据结构,接着以此数据结构作为项(entry)来构建访存特征记录表并添加到当前的L1Dcache设计中,用以记录所有访存指令的L1Dcache请求状态。数据结构如图5所示。

图5 访存请求状态数据结构
各功能域的含义如下:
(1) m_pc:记录了各访存请求的PC值,访存指令通过此功能域寻找表中对应的项。
(2) m_count:记录了采样周期内本表项对应的cache数据块在被替换出cache时被命中的次数的累加。这里本表项对应的cache数据块是指分配这些cache数据块的访存请求的PC值均为本项的m_pc。
(3) m_times:记录本PC值下已被替换出cache的数据块数量。
(4) m_use:标记本表项的PC值对应的访存请求数据是否可以保存在cache中。
(5) m_finish:标记当前表项是否已经完成访存状态采样。
(6) m_valid:标记当前表项是否有效。
整个系统包括cache旁路判定及访存状态记录表更新两部分,其中cache旁路判定通过查询状态记录表的方式完成。系统设计如图6所示。
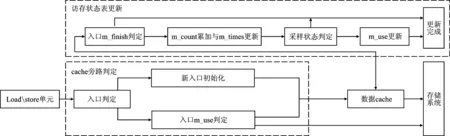
图6 LIDcache旁路判定与访存状态表更新原理
3.2.1 LIDcache旁路判定
LIDcache旁路判定部分以从Load/store单元发出的访存指令为输入,判定此指令的请求数据是否能够保存在LIDcache中。首先根据指令PC值在访存状态记录表中判定对应的项是否存在。若判定失败,则使用本指令的PC值初始化一个新表项并将其m_use功能域初始化为true,表示当前此PC值下所有访存请求的数据需要在LIDcache中保存,后续当LIDcache数据块被替换时才能使用其被命中的次数更新访存状态记录表。若判定成功,则进一步判定表项的m_use功能域;如果m_use功能域的状态为false,则表示此PC值下的请求数据不应保存在LIDcache中。由此当数据从低一级存储中返回时不会再写入到LIDcache中保存;如果状态为true,则数据返回时会保存在先前分配好的LIDcache空间中。
3.2.2 访存状态记录表更新
访存状态记录表在任何数据块被替换出LIDcache时进行更新,用以保存各PC值对应的LIDcache数据块被命中的总次数,从而为低局域性数据的旁路提供依据。状态记录表的更新过程分为以下4部分:
(1) 根据被替换数据块的PC值在表中找到对应的表项并判定表项的m_finish域状态。如果状态为false,则表示本表项的状态采样未完成,由此进入步骤(2);如果状态为true,则表示本表项已经完成了访存状态采样,不执行任何更新操作。
(2) 使用当前数据块自分配入LIDcache至替换出被请求命中的总次数来累加表项的m_count功能域,数值被用来反映数据块所具有的数据局域性程度,数值越高,则说明此数据块被命中的次数越多,也即其保存的数据具有更高的局域性。与此同时,将表项的m_times功能域增加1,表示此PC值下完成了一次访存状态更新。
(3) 判定本PC值对应的状态采样是否完成,通过优先线程块的执行状态来决定。如果优先线程块已完成执行,则表明采样周期已结束,并需要判定后续此PC值对应的访存请求是否能够将数据保存到LIDcache中,由此设置本表项的m_finish域为true并进入步骤(4);如果优先线程块还未完成执行,则不再更新剩余的功能域。
(4) 通过表项的m_count功能域与m_times功能域数值共同决定PC值对应的访存请求数据是否需要旁路LIDcache。由于在当前的存储系统设计下,L1Dcache命中与缺失时的访存性能有一个数量级的差异,因此定义旁路判定阈值的数值为10,并将m_times/m_count的数值与阈值比较。若数值小于旁路判定阈值,则认为此PC值对应的访存请求数据局域性值得被开发,本表项的m_use功能域保持为true状态,表示后续此PC对应的数据需要写回到L1Dcache中。否则,本表项的m_use功能域被设置为false,表示返回数据需要旁路L1Dcache。
由此一次对访存状态记录表的更新执行完成。当任何访存请求访问LIDcache的状态为缺失时,其都会在访存状态记录表中查找对应的表项。并根据表项的状态信息决定是否需要在LIDcache中预留保存数据的空间。
4 实验方法与结果
4.1 实验环境与参数说明
选用GPGPU-sim模拟器(3.2.2版本),这是当前学术界公认的周期精确的GPGPU架构模拟平台,其支持NVIDIA CUDA编程框架。文中以模拟器提供的GTX480架构为基础进行实验,模型内部包含15个SM,每个SM最大包含1 536个线程,每32个线程被定义为一个warp,基础warp调度算法为罗宾环调度算法,L1Dcache为16 KB。
文中在基础架构上实现了L1Dcache旁路优化设计,并采用来自PolyBench测试集的标准二维、三维卷积作为测试激励。
4.2 实验结果
4.2.1 cache缺失率、阻塞周期以及IPC
采用L1Dcache缺失率(Cache Miss Rate)与L1Dcache阻塞周期(Reservation Fail)作为指标因子来评估优化设计对L1Dcache性能产生的影响,并使用每周期指令数(Instruction Per Cycle,IPC)作为总体性能的评估指标,测试性能面向基础架构下二维、三维卷积的执行性能进行了归一化处理。由于文中设计旁路了部分低局域性数据在L1Dcache中的保存,因此这些访存请求在出现L1Dcache缺失时不需要等待数据空间的分配,这可以有效降低L1Dcache阻塞周期。图7显示了二维、三维卷积在基础架构与文中设计上执行时的L1Dcache阻塞周期、L1Dcache缺失率与IPC对比情况。

(a) L1Dcache阻塞周期对比
从图7(a)可以看到,文中设计在二维、三维卷积运算中分别降低了约7.63%与21.40%的阻塞周期,这转化为部分IPC提升的来源。从图7(b)中可以看到,在三维卷积中L1Dcache缺失率下降了约8.92%,说明本设计在三维卷积中有效提高了数据局域性的开发,部分原本需要访问全局存储的访存请求成功地在L1Dcache中命中;而二维卷积的L1Dcache缺失率小幅度上升了约0.67%;通过深入分析发现在二维卷积中基础的GPGPU L1Dcache设计能相对较好地开发数据局域性,其L1Dcache缺失率仅为约35.89%,而通过旁路引入局域性开发的提升未能超过被旁路L1Dcache数据块造成的局域性损失。然而,这种局域性的小幅度损失可以被L1Dcache阻塞周期降低所引入的性能优势掩盖。图7(c)显示的IPC的比对结果证明了文中设计在二维、三维卷积中均取得了良好的效果,分别带来了约2.16%与19.79%的性能提升,由于三维卷积中存在的L1Dcache竞争问题更严重,因此文中设计带来的性能提升更明显。
4.2.2 各访存指令执行状态
为了更进一步地详细分析文中设计对L1Dcache性能产生的影响,逐一分析了二维、三维卷积中每条访存指令的L1Dcache缺失率。从图8中可以看到在三维卷积中,文中设计识别0×160、0×200、0×278、0×290指令的访存请求为低数据局域性,由此当发生L1Dcache缺失时,这些请求访问低级存储取回的数据不会保存在L1Dcache中。而0×1d0、0×248指令的访存请求L1Dcache缺失率均有一定程度的下降,说明节省下来的空间被成功用于数据局域性的开发。从图9中可以看到在二维卷积执行时,文中设计识别0×1b0指令为低数据局域性并旁路,虽然0×108指令的L1Dcache缺失率有所下降,但0×138、0×168等指令的L1Dcache缺失率均有小幅度上升,正是这部分指令访问L1Dcache缺失率的上升造成了二维卷积中整体L1Dcache缺失率的小幅增加。不过正如节3.2.1中所述,旁路0×1b0指令的同时会降低L1Dcache阻塞周期,这可以有效隐藏L1Dcache缺失率小幅上升所带来的性能损失。

图8 三维卷积各访存指令L1Dcache缺失率比对

图9 二维卷积各访存指令L1Dcache缺失率比对
5 结束语
笔者提出了一种面向二维、三维卷积的cache旁路优化设计。该设计首先定义了能够动态反映指令访问L1Dcache特征的数据结构,然后采用优先线程块warp调度策略来加速访存状态采样,最后根据访存状态得出各PC值下访存请求对L1Dcache的旁路判定并动态完成部分低局域性数据对L1Dcache旁路。由此将L1Dcache空间保留给高局域性的数据并降低L1Dcache阻塞周期,进而提高执行性能。文中使用二维、三维卷积进行了设计验证,结果表明相比基础架构,文中设计在面向二维、三维卷积时分别带来约2.16%与19.79%的性能提升。通过实验结果发现,旁路判定策略可以进一步细化与完善,比如采取动态阈值作为判定L1Dcache旁路的准则等,这是未来需要进一步改进优化的方向。
