面向机器学习的医学检验大数据构建与实践
2023-04-27王莹周玉利顾大勇
王莹 周玉利 顾大勇


关键词:检验医学;大数据;机器学习;数据集成;数据治理;数据开发
0 引言
检验医学作为医学科学的重要支撑性技术学科,在疾病的早期诊断、病情监测、预后判断与风险评估等方面发挥着重要作用。随着医学检验实验室自动化、现代化技术水平的提升,医学检验数据飞速增长,日积月累产生了海量数据资源,其中蕴藏着大量已知和未知的临床相关规律。科研人员通过回顾性或前瞻性研究,重新解读医学检验数据将发挥其重要价值,不仅有助于进一步了解疾病的本质,确定疾病精准诊疗的方法,而且有利于发现新型诊断标志物和持续优化医学检验项目的参考区间[1]。据不完全统计,临床决策所需信息的70%来自医学检验,为临床诊断提供强有力的数据支持[2-4] 。医学检验数据不仅体量巨大、类型繁多,还有特征高维和冗余等特点,传统的数据存储和统计分析方法已难以处理愈加庞大的医学检验数据[5-7]。
目前,医学检验数据主要作为一次性的临床诊断参考以及小样本量的研究分析,导致这种状况的客观原因,一方面是医学检验数据量大、医学检验项目参考区间相对固定的显性信息明确,另一方面是医学检验数据散落在实验室信息管理系统(Laboratory Infor⁃ mation System,LIS) 中,传统的数理统计工具和小样本量难以全面、系统地发掘海量医学检验数据中蕴藏的信息。主观原因,一方面是传统科研的问题导向流程,采用“发现问题、形成假说、收集数据、分析数据”的模式,数据的作用是支持假说而不是用于发现问题或规律;另一方面是把大数据平台或工具充当计算能力更强、存储空间更大的数据平台[8-13]。这些原因导致医学检验数据应用方式不同程度存在四个方面的缺憾:①人为把“大数据”裁剪为“小数据”,方便使用传统的统计分析工具,可能会错失被裁剪掉数据所蕴含的有价值信息;②对大数据重点关注数据量的维度,却忽略了大数据的另一重要特征——数据种类多;③数据收集仅用于一次性特定的研究目的,没有考虑复用于其他研究,导致产生大量重复的数据收集、数据清洗等工作;④倾向选择理想的数据集作为标准的机器学习数据源,这与真实世界的数据分布情况差异较大,生成的机器学习模型普适性存疑。
传统的数据收集、处理方式无法满足机器学习和大数据对数据的需求,机器学习涵盖了广泛的方法,旨在为计算机提供学习任务的能力。这些方法依赖于从几乎没有人工输入的数据中获取模式的算法。这与严格依赖人类知识来验证模型假设和变量选择的统计技术形成鲜明对比。大数据方法通常不受经验知识的影响,无偏见地收集和分析数据,并发现重要的模式,支持循证医学,通过构建相关的预测模型,从而更准确地评估疾病风险以及改善预后[14-15]。现有各种医院信息化系统的设计初衷主要是为了满足医疗业务流程需要,因此,在后续数据分析与应用的需求满足上尚存在较大差距,数据的收集和管理方面缺乏结合人工智能等高价值的数据二次利用的设计考虑[16]。传统科研模式中存在的“科研构思难、数据获取难、想法验证难、数据处理难”等弊端,已严重阻碍临床研究水平的进一步提升,亟待使用新的技术手段加以解决[17]。
本研究针对医学检验数据的大数据化进行创新,面向机器学习对数据质量的要求,综合考虑实验成本和实验目标需要,选择近5年的全量医学检验数据,使用大数据技术把选定时间段的全量医学检验数据系统化治理、开发,形成时段性医学检验大数据,实现对医学检验数据的高效率复用和可持续积累模式的探索与验证。
1 医学检验大数据关键技术
1.1 转置数据结构
医学检验数据采集、处理、存储均依托LIS,LIS作为业务系统通常采用关系型数据库,关系型数据库具有强大的事务处理能力,尽可能降低数据冗余度,节约存储空间,关系型数据库的结构特点决定了其只能做简单的统计分析,不能做复杂的逻辑运算。基于关系型数据库的数据结构不能满足复杂的数据分析需求。随着计算、存储技术的发展,计算和存储资源的成本飞速下降,在数据结构方面以空间换时间的数据宽表结构应运而生,数据宽表是一张把业务主题相关的指标、维度、属性关联在一起的数据库表,数据宽表具有降低数据复杂度、结构简单、数据完备度高、减少数据交互、数据访问效率高和易于业务人员自主使用数据等优点,广泛应用于数据挖掘模型训练前的数据准备[18-20]。
传统的医学检验数据结构是以患者为中心,以提供患者个体的检验报告为目的,构成医学检验数据的医学检验项目及结果以多行的形式存在,方便直观展示患者个体各个医学检验项目结果,不利于对不同患者同一个医学检验项目结果做复杂逻辑运算。转为数据宽表可以实现患者ID主关键字的所有医学检验项目位于同一行,不同患者的同一医学检验项目结果位于同一列。可以在一张数据表中直接对不同患者的同一医学检验项目数据治理、数据开发后进行统计分析和复杂逻辑运算。
1.2 建立数据治理标准
数据质量是数据发挥价值的关键,数据治理是提升数据质量、降低数据管理成本、保障数据安全和控制数据风险的方法。医学检验数据通常来自不同厂家的不同类型的设备,以实现医学检验功能为目的,缺乏全局性的数据标准,数据类型和质量参差不齐,主要存在非结构化数据、数据格式混乱、无效数据、重复数据、错误数据、数据缺失等问题。大部分的医学检验数据为结构化数据,天然符合复杂逻辑运算需求,但数据的使用维度是面向检验报告,导致大量的非结构化数据混杂其中,如定性的阴性、弱阳性和阳性等非结构化文本。数据格式混乱包括定量的格式化数据中混杂“<”“>”“+”“.”“*”“中英文注解”和“NULL”等,错误数据包括人工录入错误(如:1.00录入1.0.0) 、年龄为负值、数据类型转换错误(数值区间1~2转为1月2日)等,无效数据包括定标数据、测试数据、系统无法出具检验项目结果的默认数据等。
医学检验数据治理需要全面统计分析医学检验数据,在符合实际业务需求的前提下,建立数据清洗和数据转换的标准。对于多值有序非結构化数据按照业务要求的顺序直接转化为有序数值,对于多值无序非结构化数据,则留待后续实际使用时采用独热编码(One-Hot Encoding)方式处理;对于格式化数据中混杂的非格式化符号一般采用针对性删除的方式;对于错误数据根据实际业务情况核验后的结果,采用正确的数据做替换;对于定标数据、测试数据和系统无结果默认数据等采用针对性删除的方式。对于诊断结果通过统计分析基于不同语言、缩略方式、命名习惯等方式带来的同一疾病的重复情况,根据业务需求对其做标准化统一。
2 医学检验大数据实验方案设计
大数据的基础是数据与应用分离,把数据作为资源实现数据资产化,避免重复数据集成、数据治理和数据开发,该理念贯穿数据的全生命周期。在方案设计时采用分层策略实现清晰数据结构、减少重复开发、统一数据口径和复杂问题简单化。
2.1 整体方案
整体方案分为三层,分别为数据应用层、数据操作层和数据来源层,如图1所示。其中数据应用层包括数据统计分析、机器学习和数据展示等应用。数据操作层对数据来源首先进行数据集成,数据集成后的一个副本做行列转置,实现数据结构从关系型向数据宽表转换。通过数据洞察全面分析数据质量,根据分析结果制定数据标准。按照数据标准采用计算机程序做数据清洗和数字化转换。根据需要做数据归一化,通过数据服务的方式向数据应用层提供数据调用查询服务。数据来源层主要为LIS和医院信息系统(Hospital Information System,HIS)的关系型数据库。
2.2 方法设计
在数据操作层采用整体分级模式和分段清洗模式的数据治理方法,实现关系型数据平滑向数据宽表转化。
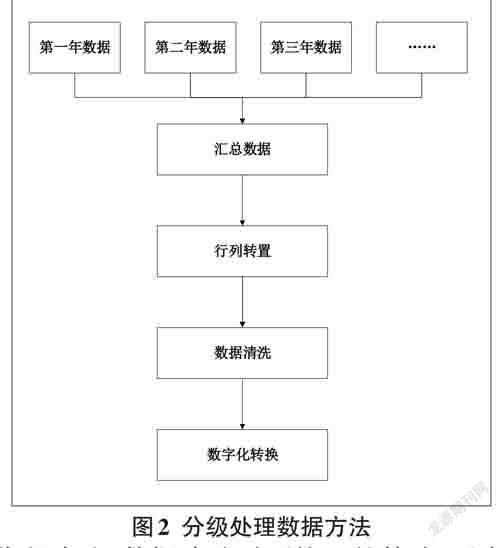
整体分级模式:数据集成、数据治理和数据开发涉及多个环节,产生错误则牵一发而动全身。采用分级处理的方法来实现功能分工、隔离稳定和方便实现的原则。主要分为数据集成、行列转置、数据清洗和数字化转换,如图2所示。每一级的输入和输出均有对应的数据表,每一级产生的系统或人工操作错误不会波及上一级,从而实现错误的有效隔离。
分段清洗:数据清洗需要统一的策略,避免数据被多次清洗[21]。数据清洗通常采用结构化查询语言(Structured Query Language,SQL) ,SQL功能丰富、应用灵活,但在实际应用中运行环境出于系统安全考虑会做相应的资源限制,如果一次清洗的字段过多,会导致清洗语句的长度或者清洗程序占用空间超出资源限制,从而产生系统错误。如果将源数据表拆分为多个数据表再进行数据清洗,虽然可以避免该错误,但在数据量较大时,拆分过程的操作复杂,效率较低。采用分段清洗模式在保持整体一致性的基础上,通过对字段的分段实施,灵活适应运行环境可提供的资源。如图3所示,S1、S2、……Sn为源数据表中的字段名称,T1-1、T1-2、……T1-n为目标数据表T1中的字段名称,“as”代表字段对应数值的简单的复制赋值,“->”代表字段对应数值经过SQL语句(例如Case when条件语句)处理后的结果赋值。整体清洗程序在运行环境资源许可的情况下一次性完成,如果超出运行环境资源限制,可以针对一部分字段进行清洗处理,另外一部分保持简单赋值模式。例如第一段清洗程序只对源数据表S 中的S1、S2和S3三个字段的数值进行清洗,清洗后的结果分别赋值到目标数据表T1 中对应的T1-1、T1-2、T1-3三个字段,源数据表S 中其余字段(S4至Sn)不做处理,直接赋值到目标数据表T1中对应的(T1-4至T1-n)。在第二段清洗中数据表T1为目标数据表,已经完成清洗的字段T1-1、T1-2、T1-3直接赋值新的目标数据表T2对应T2-1、T2-2、T2-3字段。T1-4、T1-5、T1-6三个字段的数值经过清洗后赋值到目标数据表T2的T2-4、T2-5、T2-6三个字段。源数据表T1的剩余字段(T1-7至T1-n) 不做处理直接赋值到目标数据表T2中对应的(T2-7至T2-n),后续分段依此类推,直至完成所有字段的清洗工作。
3 实验实施与分析
3.1 实验环境与实验数据
研究采用的实验环境为商用公有云服务提供的大数据计算服务平台Maxcomputer和大数据开发治理平台Dataworks。数据清洗采用SQL脚本。数据为某医院2016年10月1日至2021年09月30日的LIS和HIS中全量医学检验数据及诊断结果。原始数据包括患者的ID、年龄、性别、部门(门诊或住院)、检验日期、医学检验项目编码、检验结果、诊断结果共8个字段。医学检验项目总计1 297项(包括部分来自不同仪器设备对相同检验项目的重复),医学检验数据合计141 477 953条。在实验中,把医学检验数据转化为医学检验大数据。
3.2 实验实施过程
数据集成:以年为单位,从LIS和HIS中抽取患者的全量医学检验数据和诊断结果生成数据文件,删除861 252条无效医学检验数据后剩余140 616 701条医学检验数据的数据文件依次导入大数据计算服务平台Maxcomputer。并逐年核对数据总量,保证数据导入过程不存在遗漏或丢失。
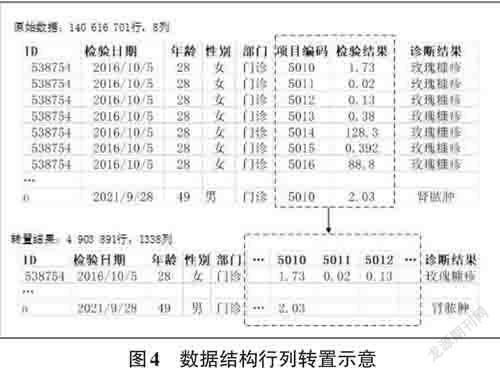
数据结构转置:以患者ID为主关键字、检验日期为次关键字,把对应的医学检验项目和结果从多行模式转为多列模式,每位患者在确定的检验日期的所有医学检验数据成为数据宽表的一条记录,如图4所示,140 616 701 行、8 列关系型数据表转置为4 903 891 行、1 338列的数据宽表。
数据清洗:对转置后的数据宽表的每一列分别做不重复数据查询,并统计相应的数据类型、数值型数据数值区间、数据量、错误数据类型等。根据统计分析结果和对应字段的医学意义制定数据治理标准。按照数据治理标准针对每一列在SQL脚本中实现相应的措施。例如对于简单的“>”“<”和“*”等无效字符的清除,直接采用空字符替换方式,对于结构混乱数据,采用正则表达式去除非法字符,对于少量的人工录入错误,采用正确数值替换的方式。
数字化转换:对于多值有序非结构化数据第一项为0、公差为1,构建数值列对多值有序非结构化数据做相应的字符替换。
3.3 实验结果
经过上述处理环节,4 903 891行、1 338列的数据宽表中绝大数列已转为结构化数据,极少数因为源数据标准不一且数据量较少的医学检验项目结果未做处理,数据宽表每一条记录对应的诊断结果未做处理,主要是为了保障按照疾病种类查询的便利和灵活性。在研究思路产生階段快速查询所关心疾病所对应的数据量或若干项医学检验项目的数据量来决定是否有必要进行研究。在数据应用阶段,可以根据研究需要,随时检索抽取其所包含的所有疾病类别对应的全项医学检验数据,在数据挖掘分析阶段,不但可以继续使用传统数理统计工具处理进行分析,而且可以直接被各种机器学习算法读取,而无须重复为不同的机器学习算法或不同的疾病做烦琐的数据处理工作。通过实验不但可以全面掌握医学检验项目实际覆盖率,而且可以分钟级快速验证科研构思的可行性,分钟级完成机器学习数据源准备。
对4 903 891条记录中每个医学检验项目的检验数量做了统计,检验数量超过百万的41项,其中最高项平均红细胞体积为2 128 955,占记录总数的43.41%,即43.41%的患者均做了平均红细胞体积这个医学检验项目。检验数量为50万至100万26项,检验数量为10万至50万142项,检验数量为1万~10 万439项,检验数量为1万以内651项。通过时段性全量检验数据统计,第一次全景展示选定时段的所有医学检验项目的实际覆盖率。
大数据可以有效地节省临床操作和研发两个方面的投入,本研究成果带来了直观的科研高效率,通过几分钟的检索验证了B淋巴母细胞瘤白血病、慢性中性粒细胞白血病、毛細胞白血病等只有数十到数百不等病例的科研构思的不可行性。只需要通过诊断结果的简单筛选,用时几分钟即可具备一种疾病类型的机器学习业务流程所需的数据源。已经生成了急性髓系白血病、慢性粒细胞白血病、甲状腺疾病、乳腺恶性肿瘤等疾病的机器学习模型,机器学习模型不但具有较高的预测水平,预测评估结果的主要指标受试者工作特征曲线下面积(Area Under Curve,AUC)、F1- Score大部分在0.9以上;而且发现了一些医学检验项目和某些疾病存在常规研究无法察觉的相关性,例如淀粉酶与慢性粒细胞白血病密切相关。
4 结束语
在传统的临床研究模式下,数据采集和数据处理分析均是耗费大量人力、物力的工作,严重制约临床科研成果的产出效率。据统计,在医院采用传统人工模式仅在数据处理阶段就需要1~2个月、数据抽取耗时5个月、科学研究约需1个月,医护科研人员的时间大量花费在数据的准备阶段[22]。有研究认为,临床数据获取困难且需要大量的手工处理,导致科研周期长、效率低下。合理的方式是科研人员将精力放在科研本身,节约科研人员的时间,提高科研产出[23]。大数据时代需要大数据思维,大数据思维强调整体性,要求用整体的眼光看待数据,与个体化时代强调研究部分有代表性的数据大不相同[24]。
本研究采用了离线方式抽取2016—2021年近5 年的某综合性三甲医院全量临床检验数据,沿用了现存业务部门与信息技术部门的合作模式和流程。使用了基于公有云服务的大数据平台和机器学习平台,大幅降低了试错成本,提高了研究效率。对全项医学检验数据不做p特定需求的处理并采用SQL脚本固化了数据治理、开发的方法和经验,可以平滑迁移到将来的自建医疗大数据平台,既可对历年医学检验数据统一处理,又可以实时处理新增医学检验数据,弥补本研究仅离线处理时段性历史数据的不足。
