合体字与复合词中联结编码和项目编码的关系*
2023-04-10赵春宇郭春彦
赵春宇 郭春彦
合体字与复合词中联结编码和项目编码的关系*
赵春宇 郭春彦
(首都师范大学心理学院, 北京市“学习与认知”重点实验室, 北京 100048)
本研究通过考察合体字和复合词加工过程中联结记忆和项目记忆的变化, 探究了在将不同项目绑定为整体的过程中联结编码和项目编码间的关系, 并结合脑电技术比较了合体字和复合词的加工过程在神经机制上的差异。行为结果显示: 与不能组成字或词的编码条件相比, 合体字和复合词编码条件下的联结记忆成绩有显著提升, 且项目记忆成绩没有下降; 与复合词编码相比, 合体字编码条件下的联结记忆和项目记忆成绩都显著更好。脑电结果显示: 复合词编码时晚期负成分(LNC)主要位于额区且发生较早, 而合体字编码时的LNC主要位于枕区且发生更晚; 合体字编码比复合词编码在α/β频段的神经振荡去同步化更强。这些结果表明, 将不同项目绑定为整体的操作可以强化大脑对联结信息的加工, 同时不会损害对项目的加工, 支持了“只有收益”的观点。本研究也从实证的角度为汉语学习材料的编排提供了参考。
项目编码, 联结编码, 合体字, 复合词, 项目记忆, 联结记忆
1 引言
情景记忆(episodic memory)是长时记忆中一个非常重要的组成成分(Tulving, 1972)。根据存储内容的不同, 情景记忆可以分成项目记忆(item memory)和联结记忆(associative memory)。项目记忆是一种可以再认出某个项目或事件是否经历过的能力。联结记忆中不仅存储着该项目或事件是否经历过, 还存储着项目与项目之间的关系(Buchler et al., 2008; Giovanello et al., 2003; Hockley & Cristi, 1996)。针对项目记忆的学习被称为项目编码, 针对联结记忆的学习则被称为联结编码。有研究发现, 在联结编码的过程中, 如果两个项目可以被组合形成一个新的整体(Ceraso, 1985), 无论是健康成年人(Haskins et al., 2008; Lu et al., 2020; Rhodes & Donaldson, 2008)、儿童(Robey & Riggins, 2017)、老年人(Memel & Ryan, 2017; Memel & Ryan, 2018; Zheng et al., 2015; Zheng et al., 2016)还是失忆症患者或某些脑损伤人群(Diana et al., 2010; Giovanello et al., 2006; Quamme et al., 2007), 其联结记忆成绩都可以得到提升(郑志伟等, 2015)。
与联结记忆不同, 将两个项目联合成一个整体的编码方式对项目记忆的影响还存在争议(Hockley & Cristi, 1996; 刘泽军等, 2019; Liu et al., 2020; Pilgrim et al., 2012)。一些研究发现, 将不同项目绑定为整体后, 联结记忆成绩得到提升的同时项目记忆成绩会受损, 即“收支平衡” (benefits and costs)的观点(Ahmad & Hockley, 2014; Murray & Kensinger, 2012; Pilgrim et al., 2012; Shao & Weng, 2011)。另外一些研究则发现, 将项目绑定为整体后, 联结记忆成绩提升的同时, 项目记忆成绩没有降低(Liu et al., 2020; 刘泽军, 郭春彦, 2022; Parks & Yonelinas, 2015)甚至有所提升(Liu & Guo, 2019), 即“只有收益” (benefits-only)的观点。这两种观点看似是在争论将两个项目绑定为整体后项目记忆受到的影响, 实则是在探讨绑定过程中联结编码与项目编码之间的关系(Ahmad & Hockley, 2014; Parks & Yonelinas, 2015)。“收支平衡”的观点认为, 在项目被绑定的过程中, 整体得到了更多的加工, 组成整体的部分会被忽略, 即单个项目所包含的信息会被整体所掩盖, 导致大脑减少对项目的编码, 进而使项目记忆成绩受损; 而“只有收益”的观点则认为, 只有项目被充分地加工后, 不同的项目才能被绑定为一个整体, 因此项目所包含的信息不会被掩盖, 只要绑定成功进行, 项目记忆成绩就不会受损。
以上两种观点都得到了一些研究的支持。Pilgrim等人(2012)通过事件相关电位(Event-Related Potential, ERP)技术探究了项目再认时与熟悉性相关的神经指标(FN400效应)。他们的逻辑是: 在项目被绑定为整体的过程中, 如果项目的信息被掩盖, 提取阶段与该项目有关的熟悉性就会减少。实验结果表明, 将不同的项目绑定为整体后, 项目再认时的FN400效应显著减少, 支持了“收支平衡”的观点。然而, 也有研究者对这项研究提出了质疑: 虽然提取阶段与项目有关的熟悉性减少, 但项目再认的行为成绩没有下降。因此, 还不能说项目编码一定受到了影响。基于此, Liu等人(2020)的研究则发现, 在记忆的提取阶段, 绑定后的项目无论是再认时的熟悉性还是行为成绩, 与没有绑定的项目相比都没有差异, 这说明项目编码没有受到影响。然而, 这项研究也可能还存在争议: 虽然行为成绩和熟悉性都没有降低, 但绑定后的项目在提取时的回想过程有所减少。因此, 也存在项目编码受到了影响的可能。在他们最近的一项研究中, 这一争议似乎得到了解决(刘泽军, 郭春彦, 2022): 学习阶段被试将不同词语组合成一个整体(复合词)后, 项目再认时的行为成绩和回想过程都没有减少, 甚至熟悉性还有所提升。综上所述, 这些研究都从提取的角度证实了将项目绑定为整体的过程可以加强联结编码, 同时项目编码不会受到损害, 支持了“只有收益”的观点。
本研究拟使用汉字来检验“只有收益”和“收支平衡”这两种观点。在汉字中, 有两种可以将不同项目绑定为一个整体的方式: 一种是基于构字法将两个部件组成一个合体字(如“亲”和“斤”组成“新”), 另一种是基于构词法将两个语素组成一个复合词(如“国”和“家”组成“国家”)。合体字的加工需要在亚词汇水平上对字的不同成分单元(即部件)进行编码, 然后将这些单元加工到一起, 组成一个符合正字法规则的汉字。因此, 这个过程通常也被称为正字法加工(Anderson et al., 2013; Su et al., 2015)。与合体字不同, 将两个汉字组成一个复合词的过程也被称为语素加工(Chung et al., 2010; Ip et al., 2019)。它需要对一个词语内部的语素和语素之间的结构进行加工, 整个过程始终与语义分析交织在一起(Chung et al., 2010; Gao et al., 2022)。总之, 虽然构字法和构词法都可以将两个汉字组合成一个新的整体, 但两者仍然存在差异。我们拟采用这两种不同的编码方式来绑定项目, 考察项目记忆成绩是否随联结记忆成绩的变化而变化。如果在联结记忆成绩更好的条件下, 项目记忆成绩没有受到降低, 则支持“只有收益”的观点; 反之, 则支持“收支平衡”的观点。
我们使用左右结构的合体字(如“口”和“十”组成“叶”)和双字复合词(如“开”和“心”组成“开心”)作为实验材料, 并结合了联结再认和项目再认范式来检验以上假设。实验1主要考察, 相比于不能组成合体字或复合词的条件, 构词法和构字法的编码方式对联结记忆的影响, 以及这两种编码方式间联结记忆成绩的差异。我们预测: (1)相比于不能组成合体字或复合词的条件, 构字法和构词法的编码方式都能显著地提升联结记忆成绩; (2)虽然两种条件下的联结记忆成绩都有所提升, 但两种条件间的联结记忆成绩仍然存在差异。实验2主要考察, 构字法和构词法两种编码方式对项目记忆的影响, 以检验在联结再认成绩更好的条件下, 项目再认成绩是否降低。由于先前的多数研究都支持了“只有收益”的观点, 因此我们预测: (3)相比于不能组成合体字或复合词的条件, 构字法和构词法的编码方式不会降低, 甚至会提升项目记忆成绩; (4)两种编码条件间, 无论实验1中哪种条件下的联结记忆成绩更好, 该条件下的项目记忆成绩都不会降低甚至会提升。
关于记忆编码的认知神经机制, 有ERP研究发现, 将两个项目进行联结会诱发一个晚期负成分(Late Negative Component, LNC), 它代表着将多个项目在工作记忆中进行维持和操作(Kamp et al., 2017), 且它的振幅与提取阶段的记忆成绩有关(Khader et al., 2005; Kim et al., 2009)。一项研究还发现, 两个单词进行联结编码后, 后续记得的项目在编码时诱发的LNC与后续不记得的项目诱发的LNC振幅不同, 但这一差异在非联结编码条件下不存在(Kounios et al., 2001)。此外, 还有研究者认为, 编码时的LNC反映了大脑对材料进行精细化加工, 这有利于后续的记忆成绩(Kamp & Zimmer, 2015)。由此可见, 若要在记忆任务中考察联结编码和项目编码的关系, LNC可以作为一个合适的考察指标。此外, 除锁时锁相的ERP信号外, 还有研究者从脑信号的时频表征(Time-Frequency Representation, TFR)的角度考察了记忆编码的神经机制。Hanslmayr等人(2012)发现, α/β频段上的神经振荡去同步化与大脑中信息的丰富程度有关, 且该指标可以支持长时记忆的编码和提取。为了从编码的角度更直接地考察项目编码是否受损, 以及构词法和构字法两种编码方式在神经机制上的差异, 我们也在实验2中使用了EEG (Electroencephalogram)技术。我们预测: (5)构字法和构词法两种编码条件间, 无论哪种条件下的联结记忆成绩更好, 该条件下的LNC和α/β频段神经振荡去同步化都不会减少甚至会增加。
2 实验1: 合体字与复合词编码对联结记忆的影响
2.1 方法
2.1.1 被试
根据前人的研究(Liu et al., 2020), 能否组成整体这一因素在联结记忆成绩上的效应量为0.76, 使用G*power 3.1计算得到检验这一效应所需的样本量为21 (置信水平为0.05, 统计检验力为0.9, 检验方式为配对样本检验)。实验1招募到30名母语为汉语、利手为右利手的健康本科生或研究生被试(21~28岁, 女性19名)。所有被试对实验流程均知情且同意。本实验已通过首都师范大学心理学院伦理委员会批准。
2.1.2 研究范式和实验设计
实验1采用了前人文献中广泛使用的联结再认范式考察联结记忆(Kamp et al., 2016; Lu et al., 2020; Memel & Ryan, 2018; Zheng et al., 2015)。联结再认范式分为学习和测验两个阶段。其考察联结记忆的逻辑如下: 在学习阶段, 被试需要对呈现的配对进行学习。在测验阶段, 刺激由两种材料组成, 一种是与学习阶段完全相同的“相同配对”, 另一种是将学习阶段的配对经过重新组合的“重组配对” (见图1)。被试需要判断屏幕上呈现的配对是“相同配对” 还是“重组配对”。由于组成“相同配对”和“重组配对”的项目都是学习阶段学过的, 两者的唯一区别是配对内部的联结关系, 因此, 联结再认范式主要涉及对联结记忆的考察。实验1采用2 (是否形成整体: 是、否) × 2 (编码条件: 构字法、构词法)两因素被试内设计, 因变量为学习阶段的反应时(RT)和测验阶段的联结再认表现(Performance of recognition, Pr = 击中率–虚报率)。
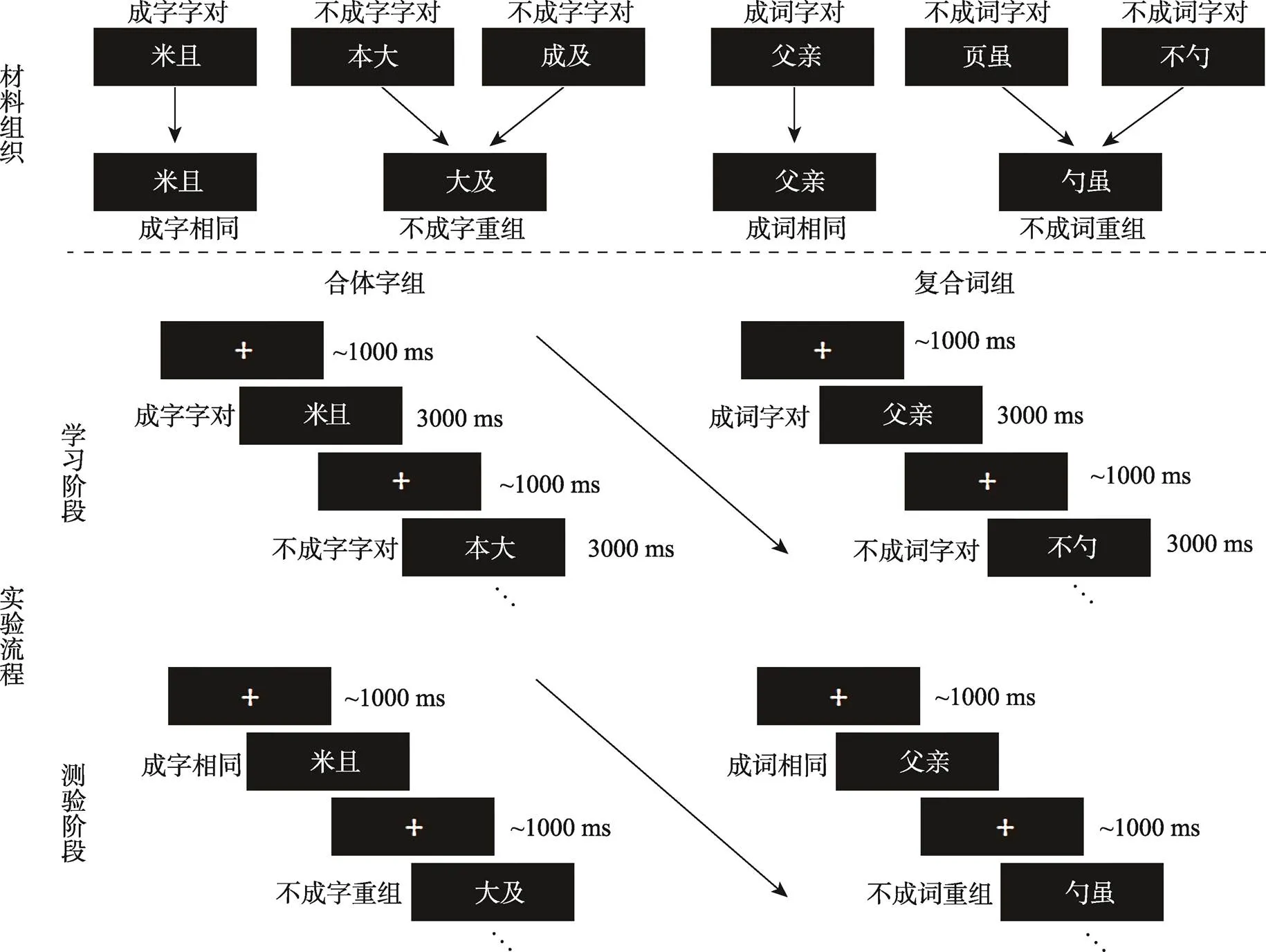
图1 实验1部分材料及实验流程示意图
2.1.3 材料
除练习和填充刺激, 正式实验共使用480个汉字。其中, 合体字组(包含成字条件和不成字条件)与复合词组(包含成词条件与不成词条件)各使用240个。
在合体字组学习阶段, 240个汉字两两配对形成60对成字字对(如“米且”)和60对不成字字对(如“本大”)。联结再认测验阶段包含4种刺激: (1) 60对成字字对中的30对以完全不变的方式在测验阶段呈现, 为30对成字相同字对; (2)剩下的30对成字字对, 每两对字对中各选一个字组成30对成字重组字对; (3) 60对不成字字对中选出30对, 同样以不变的方式在测验阶段呈现, 为30对不成字相同字对; (4)剩下的30对不成字字对, 每两对字对中各选一个字组成30对不成字重组字对。
在复合词组学习阶段, 240个汉字两两配对形成60对成词字对(如“开心”)和60对不成词字对(如“页虽”)。联结再认测验阶段也包含4种刺激: (1) 60对成词字对中的30对以完全不变的方式在测验阶段呈现, 为30对成词相同字对, (2)剩下的30对成词字对, 每两对字对中各选一个字组成30对成词重组字对, (3) 60对不成词字对中选出30对, 同样以不变的方式在测验阶段呈现, 为30对不成词相同字对, (4)剩下的30对不成词字对, 每两对字对中各选一个字组成30对不成词重组字对。
所有汉字材料均以黑底白字的形式呈现(见图1), 且每个汉字的垂直和水平视角均为1.43°。所有材料的熟悉性和笔画数都在条件间进行了平衡。具体而言, 学习阶段, 合体字组中, 60对成字字对中的120个字与60对不成字字对中的120个字之间的熟悉性(= 0.93)和笔画数(= 0.47)没有显著差异; 在复合词组中, 60对成词字对中的120个字与60对不成词字对中的120个字之间的熟悉性(= 0.80)和笔画数(= 0.11)没有显著差异; 最后, 60对成字字对中的120个字与60对成词字对中的120个字之间的熟悉性(= 0.35)和笔画数(= 0.87)也没有显著差异。
测验阶段, 在合体字组中, 30对成字相同字对中的60个字与30对成字重组字对中的60个字之间的熟悉性(= 0.76)和笔画数(= 0.99)没有显著差异; 30对不成字相同字对中的60个字与30对不成字重组字对中的60个字之间的熟悉性(= 0.91)和笔画数(= 0.96)没有显著差异。在复合词组中, 30对成词相同字对中的60个字与30对成词重组字对中的60个字之间的熟悉性(= 0.97)和笔画数(= 0.99)没有显著差异; 30对不成词相同字对中的60个字与30对不成词重组字对中的60个字之间的熟悉性(= 0.82)和笔画数(= 0.87)没有显著差异。最后, 30对成字相同字对中的60个字与30对成词相同字对中的60个字之间的熟悉性(= 0.38)和笔画数(= 0.23)没有显著差异; 30对成字重组字对中的60个字与30对成词重组字对中的60个字之间的熟悉性(= 0.28)和笔画数(= 0.29)也没有显著差异。
2.1.4 程序
被试在了解实验流程并对实验进行充分练习后, 再开始正式实验。正式实验分为4组, 包含2组合体字组和2组复合词组。每一组都包含学习、干扰和联结再认测验阶段。每组结束后至少间隔1分钟再开始下一组。被试完成合体字组与复合词组的先后顺序, 以及两种条件内各组的顺序都在被试间进行了平衡。
在学习阶段, 对于合体字组, 每个试次开始前会呈现一个900~1100 ms的注视点, 然后呈现3000 ms的字对。被试需要辨别当前字对是否可以组成一个左右结构的汉字, 并记住这两个字及其配对关系, 然后在保证正确的前提下, 尽可能快地做出当前字对是否可以组成一个字的按键反应(见图1)。对于复合词组, 除了要求被试辨别当前字对从左到右是否可以组成一个词语外, 其余程序与合体字组相同。
学习阶段结束后, 被试进入持续1分钟的干扰阶段。此时被试需要将屏幕上出现的一个随机三位数字进行连续倒减三, 并出声报告答案。测验阶段, 相同字对和重组字对以伪随机的顺序呈现。每个试次开始前也会有一个900~1100 ms的注视点, 然后是测验阶段的字对(见图1)。此时被试需要在保证正确的前提下, 尽可能快地判断当前字对是相同字对还是重组字对, 并做出相应的按键反应。被试做出反应后, 当前字对立即消失并开始呈现下一个注视点。所有按键反应都在被试间进行了平衡。
完成所有任务后, 被试需要进行一项评分任务。评分对象为学习阶段学过的所有成字字对和成词字对, 评分内容为将该字对组成一个整体(合体字或者复合词)的难度, 评分方式为5点评分, 分数越高代表在加工的过程中形成一个新的整体越困难。
2.1.5 数据收集与分析
刺激的呈现和行为数据的记录均使用PsychoPy软件进行。对成字、不成字、成词与不成词条件下学习阶段的RT和测验阶段的联结再认Pr值进行两因素(编码条件×是否形成整体)重复测量方差分析, 交互作用显著后进行简单效应分析。由于难度评分这一因变量在不能形成整体的条件下不存在, 因此成字与成词条件间的加工难度用检验进行差异性检验。结果部分我们将报告方差分析中显著的值、值和效应量(partial-η²), 以及检验中显著的值、值、效应量(Cohen’s)和条件间差异的95%置信区间(Confidence Interval, CI)。当涉及到多重比较时采用校正。所有统计检验都在SPSS 25中进行。
2.2 结果
不同条件下学习阶段的RT、测验阶段的Pr值和评分的描述性统计结果见表1和图2。学习阶段RT的两因素(编码条件×是否形成整体)方差分析结果表明, 是否形成整体的主效应((1, 29) = 16.13,< 0.001, partial-η²= 0.36)、编码条件的主效应((1, 29) = 154.53,< 0.001, partial-η²= 0.84)和二者的交互作用((1, 29) = 24.01,< 0.001, partial-η²= 0.45)均显著。简单效应分析表明, 成词条件下的RT显著低于不成词((1, 29) = 7.75,< 0.001, Cohen’s= 1.42, 95% CI = [0.13, 0.23])和成字((1, 29) = 16.05,< 0.001, Cohen’s= 2.93, 95% CI = [0.34, 0.44])条件下的RT; 且不成词条件下的RT显著低于不成字条件下的RT,(1, 29) = 6.33,< 0.001, Cohen’s= 1.16, 95% CI = [0.15, 0.29]。难度评分的结果表明, 成字条件下所有材料的平均难度得分显著高于成词条件下的平均难度得分,(1, 29) = 7.46,< 0.001, Cohen’s= 2.59, 95% CI = [1.24, 1.66]。
测验阶段Pr值的两因素(编码条件×是否形成整体)方差分析结果表明, 是否形成整体的主效应((1, 29)= 249.29,< 0.001, partial-η²= 0.90)和两因素的交互作用((1, 29) = 25.59,< 0.001, partial-η²= 0.47)显著, 而编码条件的主效应不显著,(1, 29) = 2.08,> 0.05。简单效应分析表明, 成字条件下的Pr值显著高于不成字((1, 29) = 14.50,< 0.001, Cohen’s= 2.65, 95% CI = [0.42, 0.56])和成词((1, 29) = 2.94,= 0.006, Cohen’s= 0.54, 95% CI = [0.03, 0.14])条件下的Pr值; 成词条件下的Pr值显著高于不成词条件下的Pr值,(1, 29) = 8.51,< 0.001, Cohen’s= 1.55, 95% CI = [0.20, 0.33]。
2.3 讨论
学习阶段的结果表明, 合体字条件下的编码反应时长于复合词条件下的编码反应时, 且被试普遍认为合体字编码比复合词编码更难。测验阶段的结果表明, 相比于不成字或不成词条件, 合体字与复合词编码都显著地提升了被试的联结记忆成绩。这些结果表明无论合体字和复合词这两种编码方式内部操作过程有何差异, 它们都与前人研究中所使用的操纵一样, 可以将不同项目绑定为一个整体, 进而提升联结记忆成绩。因此, 这些结果也说明实验1中使用的合体字和复合词的编码方式是有效的。在接下来的实验2中, 我们将进一步检验: 相比于不成字条件, 合体字编码条件下的项目记忆成绩是否降低; 相比于不成词条件, 复合词编码条件下的项目记忆成绩是否降低。由于实验1的结果还发现合体字条件下的联结记忆成绩好于复合词条件下的联结记忆成绩, 我们还将检验合体字条件下的项目记忆成绩是否比复合词条件下的项目记忆成绩低。如果以上三个问题的答案都是否, 则可以说明联结记忆成绩提升的同时项目记忆没有受损, 即项目编码没有受损, 支持“只有收益”的观点。
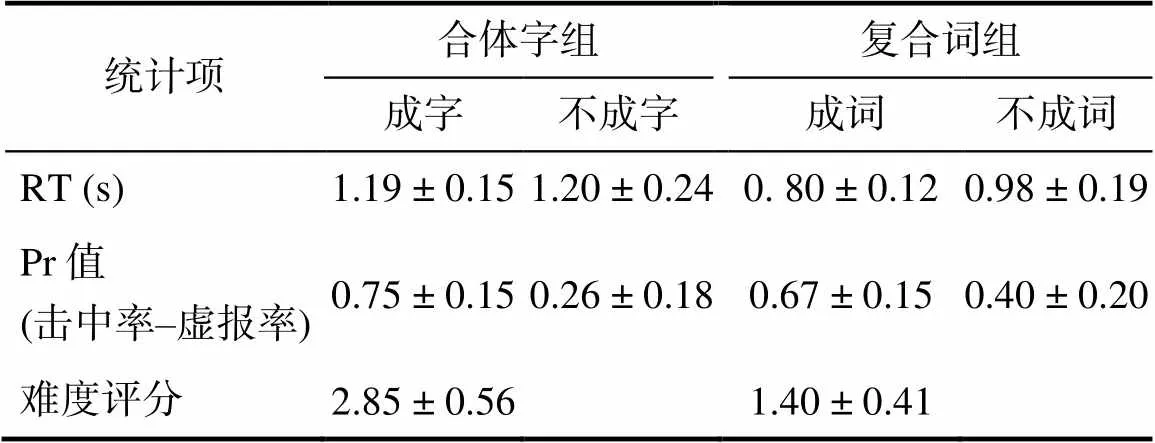
表1 学习阶段、测验阶段以及评分任务中, 被试在不同条件下的反应时、联结再认表现和难度评分的结果(M ± SD)
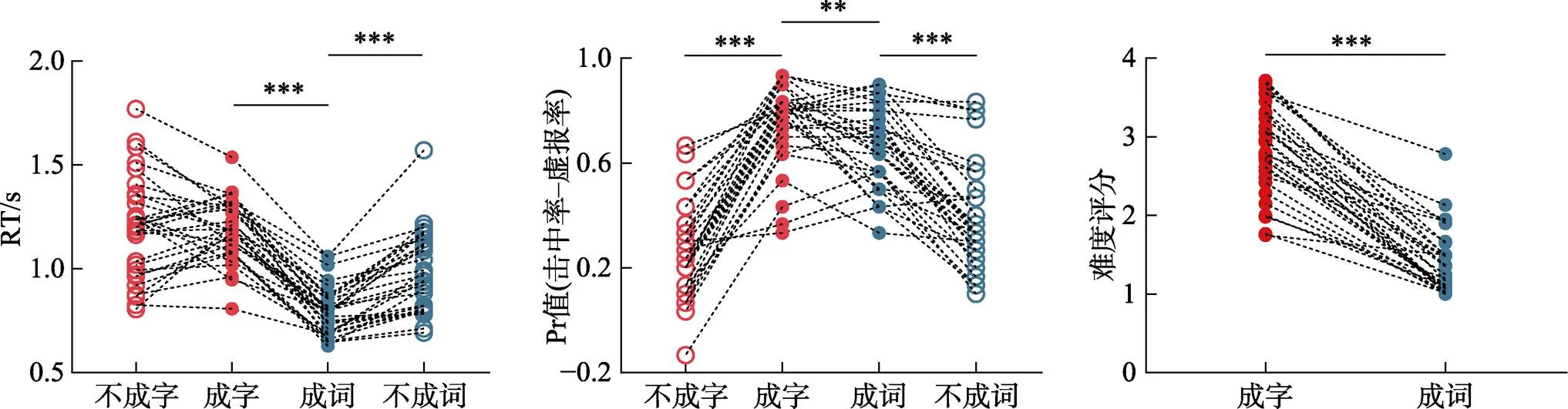
图2 左: 所有被试的编码反应时在不同条件间的变化;中: 所有被试的联结再认表现在不同条件间的变化;右: 所有被试的难度评分在两种编码条件间的变化;**代表p < 0.01,***代表p < 0.001。
3 实验2: 合体字与复合词编码对项目记忆的影响
3.1 方法
3.1.1 被试
由于还没有研究探讨过合体字与复合词这两种编码方式对项目记忆的影响, 因此我们将效应量设为中等大小0.5, 使用G*power 3.1计算得到检验交互作用所需的样本量为24 (置信水平为0.05, 统计检验力为0.9, 检验方式为2×2重复测量方差分析)。实验2招募到不同于实验1的30名母语为汉语、利手为右利手的健康本科生或研究生被试。所有被试对实验流程均知情且同意。本实验已通过首都师范大学心理学院伦理委员会批准。3名被试由于在实验过程中数据记录出现问题(2名)或脑电伪迹过多(1名)被排除, 数据分析只使用了剩下的27名被试(19~26岁, 女性16名)。
3.1.2 研究范式和实验设计
实验2采用了前人文献中广泛使用的项目再认范式来考察项目记忆(Ahmad & Hockley, 2014; Liu et al., 2020; 刘泽军, 郭春彦, 2022; Parks & Yonelinas, 2015; Pilgrim et al., 2012)。该范式也分为学习和测验两个阶段, 它与联结再认范式的区别在测验阶段。测验阶段有两种刺激, 一种是学习阶段学过的“相同项目”, 另一种是学习阶段没学过的“新项目”。被试需要判断屏幕上呈现的是“相同项目”还是“新项目”。其考察项目记忆的逻辑如下: 由于“相同项目”在学习阶段学过而“新项目”没有, 两种材料间的区别是被试是否拥有关于该项目的记忆。被试只需根据学习阶段是否见过这个项目的经验即可做出正确判断, 因此项目再认范式主要涉及对项目记忆的考察。实验2采用两因素2 (是否形成整体: 是、否) × 2 (编码条件: 构字法、构词法)被试内设计, 因变量为测验阶段的项目再认Pr值。
3.1.3 材料
除练习和填充刺激, 正式实验共使用720个汉字。其中, 合体字组(包含成字条件与不成字条件)和复合词组(包含成词条件与不成词条件)各使用360个。对于合体字组, 学习阶段同实验1; 测验阶段, 项目再认包括3种刺激: (1)每一对成字字对中选一个字组成60个成字相同项目, (2)每一对不成字字对中选一个字组成60个不成字相同项目, (3)以及120个学习阶段完全没见过的字组成新项目。对于复合词组, 学习阶段, 同实验1; 测验阶段, 项目再认也包含3种刺激: (1)每一对成词字对中选一个字组成60个成词相同项目, (2)每一对不成词字对中选一个字组成60个不成词相同项目, (3)以及120个在学习阶段完全没见过的字组成新项目。
所有汉字材料的视角大小及呈现方式同实验1。所有材料的熟悉性和笔画数都在条件间进行了平衡。具体而言, 学习阶段, 同实验1。测验阶段, 在合体字组中, 60个成字相同项目与60个不成字相同项目之间的熟悉性(= 0.69)和笔画数(= 0.98)没有显著差异; 在复合词组中, 60个成词相同项目与60个不成词相同项目之间的熟悉性(= 0.87)和笔画数(= 0.97)没有显著差异; 最后, 60个成字相同项目与60个成词相同项目之间的熟悉性(= 0.15)和笔画数(= 0.12)也没有显著差异。
3.1.4 程序
被试在了解实验流程并对实验进行充分练习后, 再开始正式实验。正式实验分为6组, 包含3组合体字组和3组复合词组。其余程序与实验1相同。
在学习阶段, 对于合体字组, 每个试次开始前会呈现一个900~1100 ms的注视点, 然后呈现3000 ms的字对。在字对呈现的前2000 ms, 被试只需辨别当前字对是否可以组成一个左右结构的汉字, 并记住这两个字。在字对出现2000 ms后, 字对上方会出现“请按键”三个字直到刺激结束。被试需要在“请按键”呈现期间做出按键反应, 判断当前字对是否可以组成一个汉字(见图3)。对于复合词组, 除了指导语要求被试辨别当前字对从左到右是否可以组合成一个词语外, 其余程序与合体字组相同。
与实验1相同, 学习阶段结束后, 被试将进入干扰阶段。测验阶段, 相同项目和新项目以伪随机的顺序呈现。每个试次开始前也会有一个900~1100 ms的注视点, 然后是2000 ms的刺激(见图3)。被试需要在保证正确的前提下尽可能快地判断当前刺激在学习阶段是否见过, 并做出相应的按键反应。所有反应的按键都在被试间进行了平衡。
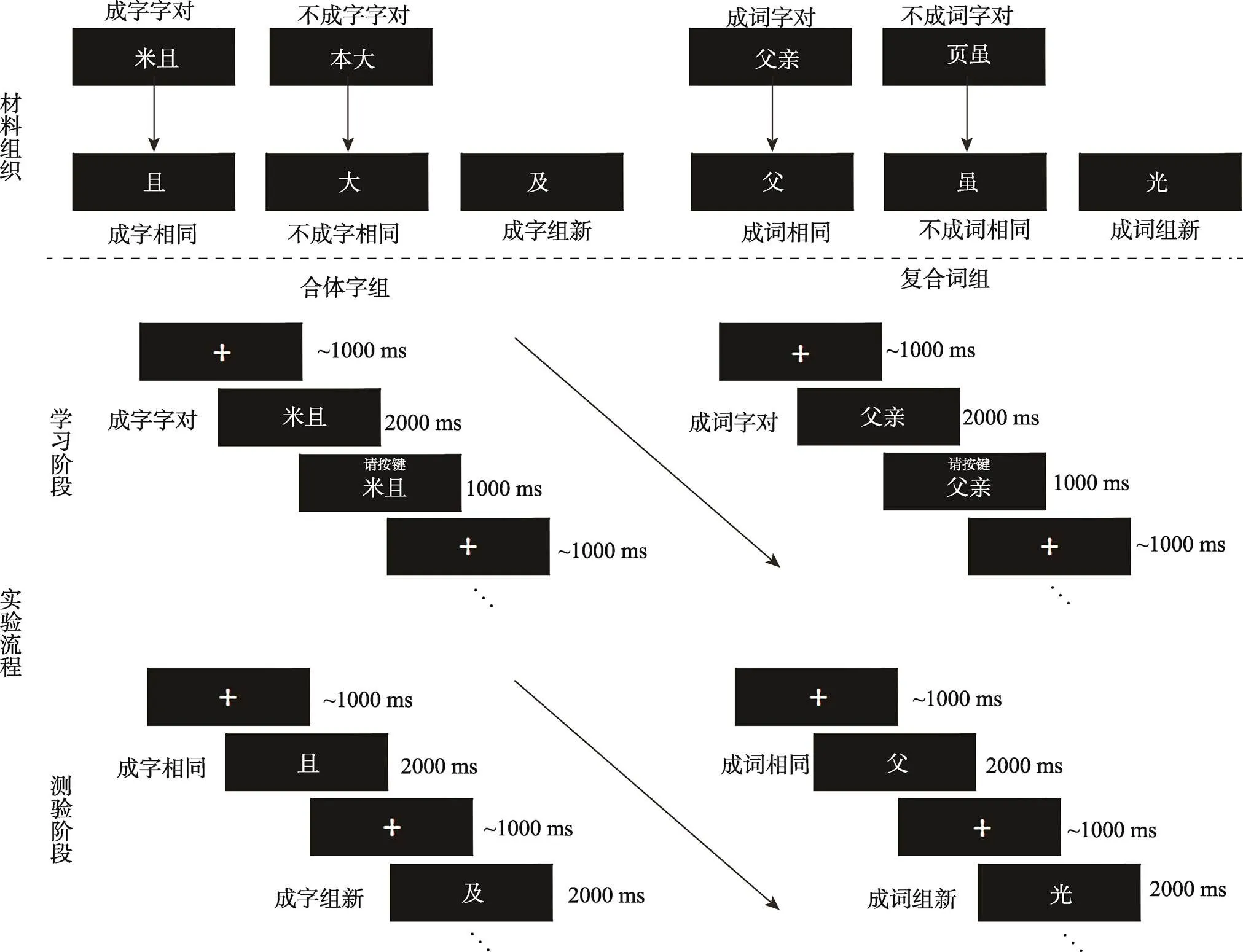
图3 实验2部分材料及实验流程示意图
3.1.5 数据收集与预处理
刺激的呈现和行为数据的记录均使用PsychoPy软件进行。EEG数据的收集采用NeuroScan SynAmps系统的62 Ag/AgCl电极, 数据采集时电阻小于7 kΩ, 采样率为500 Hz, 在线参考为左侧乳突。采集到的EEG信号由EEGLAB (Delorme & Makeig, 2004)工具包进行预处理: 首先重参考至左、右两侧乳突的平均, 然后进行0.1~100 Hz的带通滤波和49~51 Hz的陷波滤波, 眨眼和/或眼动伪迹通过独立成分分析(Independent Component Analysis, ICA)进行人工识别并去除。对于ERP分析, 连续的EEG信号被分成1800 ms的段(刺激前300 ms到刺激后1500 ms), 并将刺激前300 ms用于基线校正。对于TFR分析, 连续的EEG信号被分成2450 ms的段(刺激前600 ms到刺激后1850 ms), 且刺激前500~100 ms被用于基线校正。最后, 除头皮外周一圈电极外, 其余电极的幅值超过±75 μV, 以及被试反应错误的分段将被排除在后续分析之外。学习阶段各条件下剩余的平均试次数分别为44 (成字)、47 (不成字)、47 (成词)和46 (不成词)。
3.1.6 数据分析
对成字、不成字、成词与不成词条件下的项目再认Pr值进行两因素(编码条件×是否形成整体)重复测量方差分析, 交互作用显著后进行简单效应分析。结果部分我们报告了方差分析显著的值、值和partial-η²。为避免显著的交互作用是由不成字和不成词条件间的差异导致的, 我们合并了不成字与不成词条件下的Pr值, 补充进行了一项单因素方差分析(成字、成词、不成字/词)。当数据不满足球形假设时, 采用校正, 涉及到多重比较时采用校正。所有统计检验均在SPSS 25中进行。
为了检验合体字和复合词两种编码在神经机制上的差异, 我们首先使用多变量模式分析(Multi-Variate Pattern Analysis, MVPA)对学习阶段的EEG数据进行了探索性分析, 步骤如下: (1)将一名被试在两种编码条件下预处理后剩余的试次数下采样至相同; (2)提取两种条件下、每个试次中、所有电极(60个)上、刺激呈现后第1到10个时间点的数据, 组成600维的向量; (3)用支持向量机(Support Vector Machines, SVM)根据每个向量所属的标签(成字字对VS.成词字对)进行分类和预测(5折交叉验证), 得到分类准确率; (4)对每名被试重复上述所有步骤, 得到每名被试的分类准确率; (5)将所有被试的分类准确率与机率水平0.5进行比较(单尾), 得到在此时间窗中的值; (6)在所有时间点上重复上述所有步骤, 得到随时间变化的一系列值并进行校正。最后, 如果没有通过校正的时窗, 我们则认为两种编码的神经机制没有区别; 如果有通过校正的时窗, 我们则认为在该时窗内, 基于构字法和基于构词法这两种编码过程拥有不同的神经机制。
对于预处理后剩余的学习阶段的试次, 使用ERPLAB工具箱(Lopez-Calderon & Luck, 2014)在各条件内进行叠加平均以获得ERP。由MVPA的结果可知, 成字字对与成词字对在学习阶段的差异主要在刺激出现后1000 ms左右。检查每个电极上的ERP波形后得知, 此时间段主要为负波。因此, 在ERP分析中我们主要关注LNC。由于LNC持续时间较长, 我们进一步将LNC分成早期LNC (700~ 1000 ms)和晚期LNC (1000~1500 ms)。对于早期LNC, 首先, 平均全脑每个电极在700~1000 ms内的振幅获得两种条件下每个电极上的早期LNC; 其次, 每个电极上的LNC在两种条件间进行配对样本检验; 最后, 包含4个及以上在头皮上相邻的电极都达到显著(< 0.05)的区域将被视为存在差异的脑区。检验晚期LNC在条件间是否存在显著差异的方法与早期LNC相同。
为了进一步检验合体字编码与复合词编码在神经振荡上的差异, 我们使用Letswave7工具箱(Huang, 2019), 在0.1~100 Hz的范围内, 通过小波分析对预处理后剩余的学习阶段的试次进行了时频转换。首先, 每个电极中的离散数据用Morlet复小波(cmor1-1.5)进行卷积, 并将小波变换后得到的振幅平方以获得频谱能量; 然后, 将每名被试所有试次的频谱能量平均, 并计算刺激呈现后的能量相比于基线(–500 ~ –100 ms)的百分比变化(即事件相关频谱扰动, Event-Related Spectral Perturbation, ERSP)。刺激呈现后ERSP增强被称为事件相关同步化, ERSP减弱被称为事件相关去同步化。为了检验时频分析中显著的时窗和头皮区域, 首先, 在每个电极的每个时间点上, 分别对θ频段(4~8 Hz)、α频段(8 ~13 Hz)、β频段(13 ~ 30 Hz)和γ频段(30~ 80 Hz)内的ERSP进行平均; 然后, 在每个电极上进行基于聚类的置换检验(该方法不仅可以避免多重比较的问题, 还允许在测试统计量时加入生物物理学上的约束, 提高统计测试的灵敏度; Maris & Oostenveld, 2007), 找出显著的时间窗(双尾, 10000次, 阈值< 0.05)。最后, 差异显著且在头皮上位置相邻的电极被聚类成簇, 包含4个及以上电极的簇将被视为存在差异的脑区。
由于时频分析的结果显示两种编码方式在α/β频段的ERSP存在显著差异, 我们将进一步考察学习阶段的α/β神经振荡是否与测验阶段的记忆成绩有关。首先, 将每个电极在α/β频段(8~30 Hz)上的ERSP进行条件间比较, 得到每个电极上差异显著的时窗; 然后, 将每个差异显著电极上显著时窗内α/β频段的ERSP在两种条件间的差值, 与测验阶段击中率(Hit)在两种条件间的差值做皮尔逊相关; 最后, 若某个脑区存在4个及以上相邻且相关系数都达到显著(< 0.05)的电极, 则认为该脑区学习阶段的α/β神经振荡与测验阶段的项目再认成绩有关。
3.2 结果
3.2.1 行为结果
成字条件下Pr值的描述性统计结果为0.50 ± 0.14 (), 不成字条件下的Pr值为0.42 ± 0.16, 成词条件下的Pr值为0.41 ± 0.13, 不成词条件下的Pr值为0.37 ± 0.16。项目再认Pr值的两因素(编码条件×是否形成整体)方差分析结果显示, 编码条件的主效应((1, 26) = 21.75,< 0.001, partial-η²= 0.46)、是否形成整体的主效应((1, 26) = 17.67,< 0.001, partial-η² = 0.41)和二者的交互作用((1, 26) = 6.46,= 0.017, partial-η² = 0.20)均显著。简单效应分析表明, 如图4所示, 成字与不成字条件间的项目再认Pr值差异显著((1, 26) = 6.09,< 0.001, Cohen’s= 1.17, 95% CI = [0.06, 0.11]); 而成词与不成词条件间的项目再认Pr值差异不显著(= 0.07)。另外, 补充进行的单因素方差分析(成字、成词、不成字/词)结果也显著((2, 25) = 22.58,< 0.001, partial-η²= 0.64)。事后检验表明, 成字与成词条件间的Pr值差异显著((1, 26) = 5.23,< 0.001, Cohen’s= 1.01, 95% CI = [0.06, 0.13]), 成字与不成字/词条件间的Pr值差异显著((1, 26) = 6.66,< 0.001, Cohen’s= 1.28, 95% CI = [0.07, 0.14]), 而成词与不成字/词条件间的Pr值差异不显著(= 0.36)。
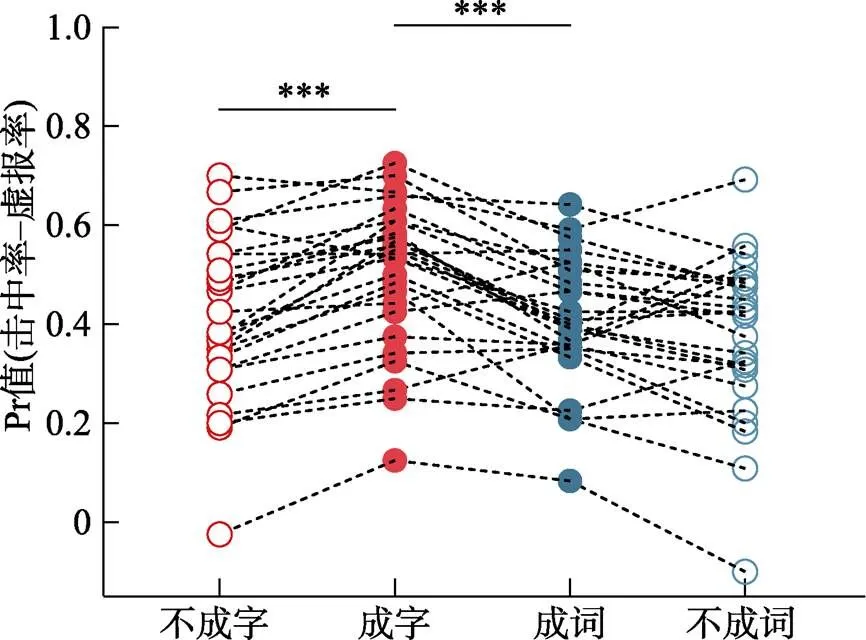
图4 所有被试的项目再认表现在不同条件间的变化,***代表p < 0.001。
3.2.2 学习阶段MVPA的结果
如图5所示, MVPA的结果显示在刺激呈现后782~1260 ms内, SVM在成字与成词两种字对间的分类准确率显著高于机率水平并通过了校正。对于不成字和不成词两种字对间的分类, 虽然在少部分时间点上SVM的准确率高于机率水平, 但没有时间段能通过校正。
3.2.3 学习阶段ERP结果
成字字对与成词字对学习阶段组平均后的ERP波形图和地形图如图6所示。对于早期LNC, 在全脑所有电极上进行的配对样本检验显示, 相比于成字字对, 在额叶−中央区域(F2, F4, F6, F8, FC7, FC5, FC3, FC1, FC4, FC6, FC8, C7, C5, C3, C4, C6, C8, CP5, CP3, CP1, CP2, CP4), 成词字对有着更负的LNC; 相比于成词字对, 在顶叶−枕叶区域(P7, PO7, PO5, PO3, PO8, O1, Oz, O2), 成字字对有着更负的LNC。晚期LNC的全脑分布模式与早期LNC基本相同。不同的是, 成词字对比成字字对有着更负LNC的额叶−中央区域更小(F4、F6、F8、FC6); 而成字字对比成词字对有着更负LNC的顶叶−枕叶区域更大(P7、P5、P3、P1、P4、P6、P8、PO7、PO5、PO3、POz、PO4、PO6、PO8、O1、Oz、O2)。
3.2.4 学习阶段TFR结果
如图7所示, 相比于成词字对, 在编码成字字对时, 全脑大部分电极在α频段和β频段上的去同步化都增强, 只有少部分电极在θ频段上显示出去同步化增强, 而γ频段上则不存在差异显著的脑区(s > 0.05)。具体而言, 如图7所示, θ频段上存在显著差异的电极主要集中在顶叶−枕叶区域(AF3、FP1、P5、P3、TP8、P4、P6、P8、PO7、PO5、PO3、POz、PO4、PO6、PO8、O1、Oz、O2), 且差异显著的时窗大都在刺激呈现后约900~1700 ms内; 而α频段除了在FC5、C5、PO3和O1电极上差异不显著, 其余电极上全都差异显著, 且额叶附近的电极显著的时窗持续时间较短(约刺激呈现后500~1200 ms), 枕叶附近的电极显著的时窗持续时间较长(约刺激呈现后500~1750 ms); 与α频段类似, β频段除了在少数电极(T7、FP1、C6、T8)上差异不显著, 其余电极全都差异显著, 且也是额叶附近的电极显著的时窗持续时间较短(约刺激呈现后600~1200 ms), 枕叶附近的电极显著的时窗持续时间较长(约刺激呈现后600~1500 ms)。
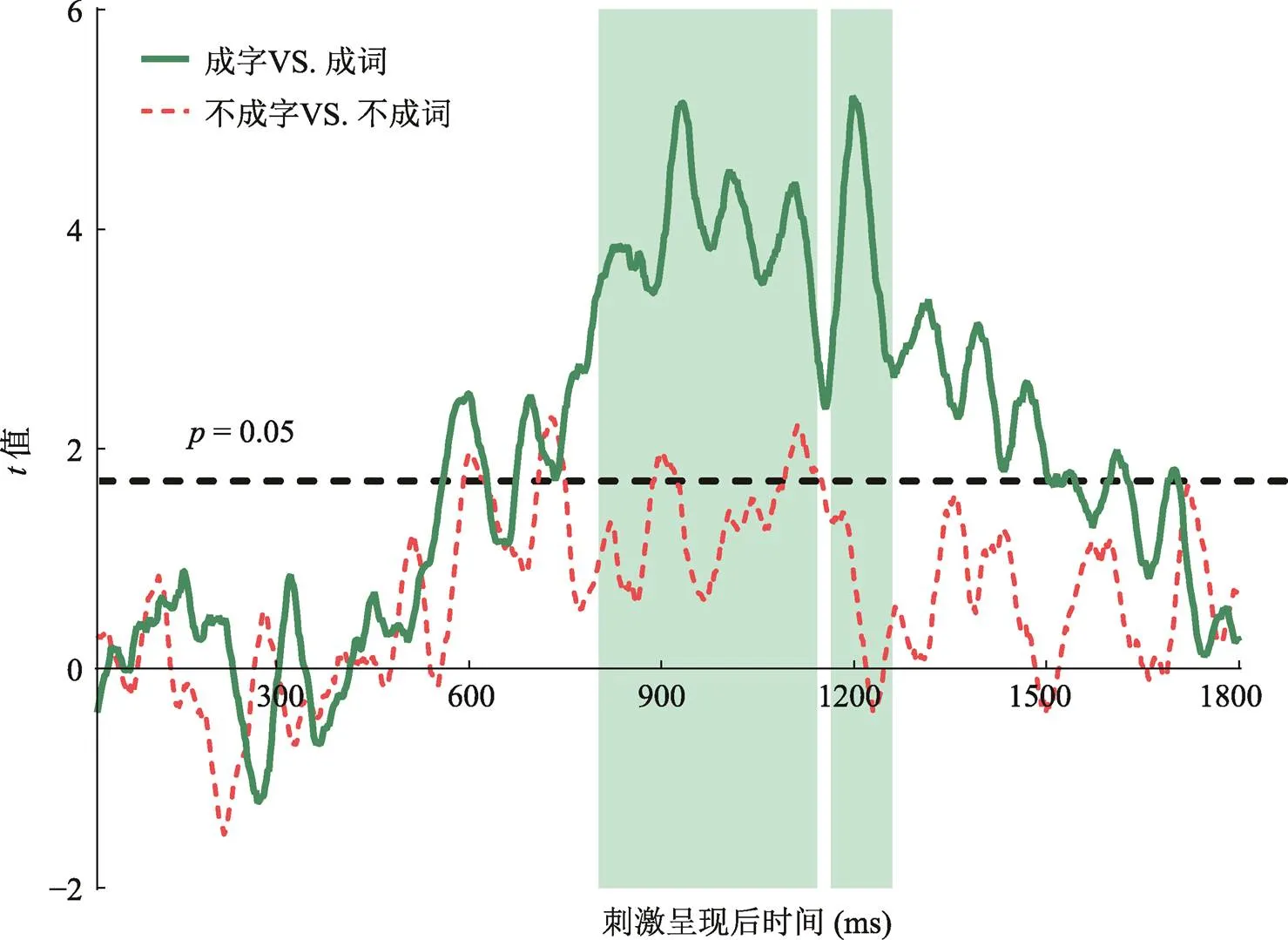
图5 SVM在不同条件间的分类结果。虚线代表显著水平p < 0.05,绿色阴影表示成字与成词条件间的分类准确率显著且通过了FDR校正的时窗。
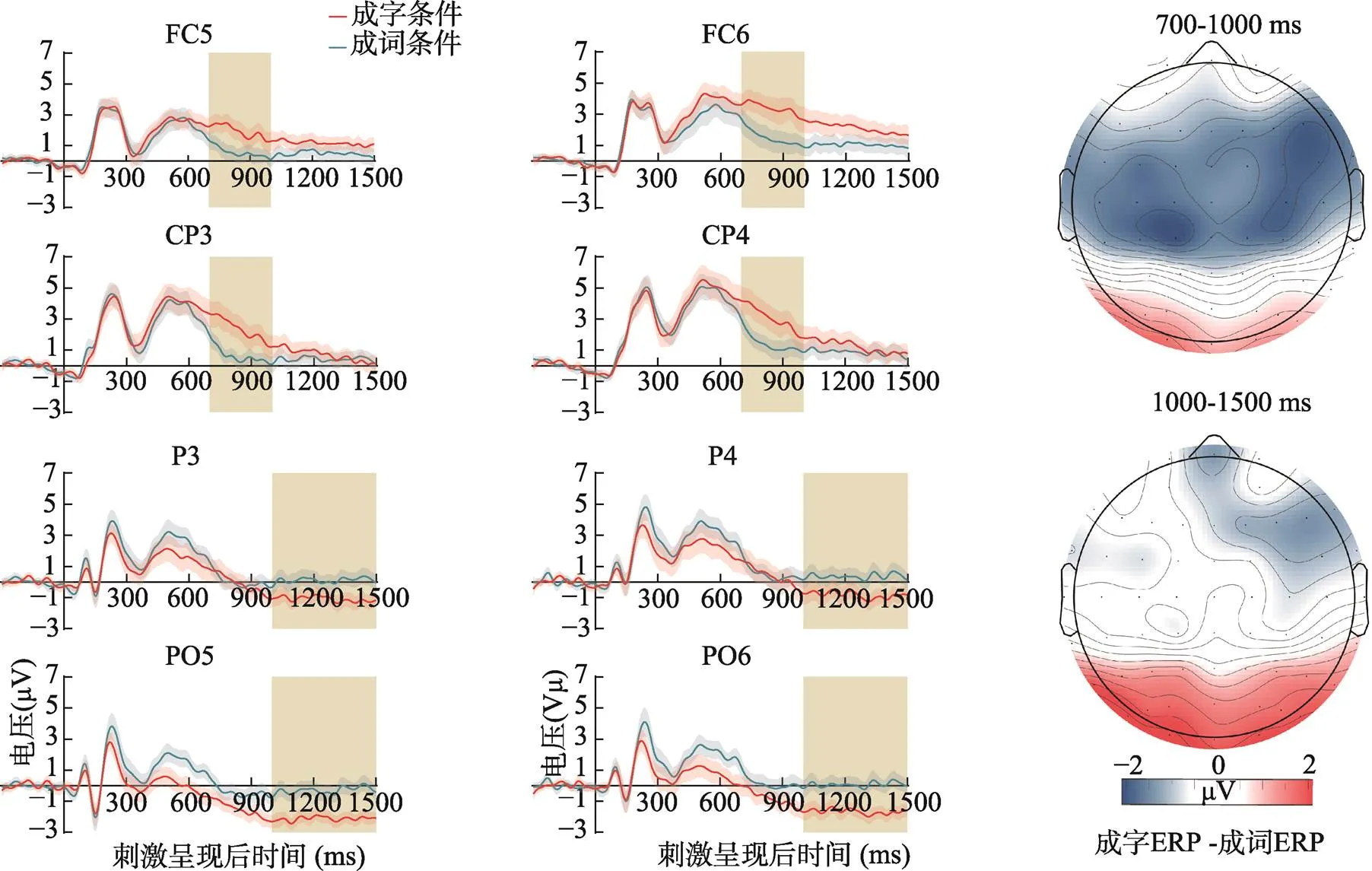
图6 两种条件下编码时的组平均ERP波形图(左、中)和地形图(右)。地形图为成字条件减成词条件得到的差异波。
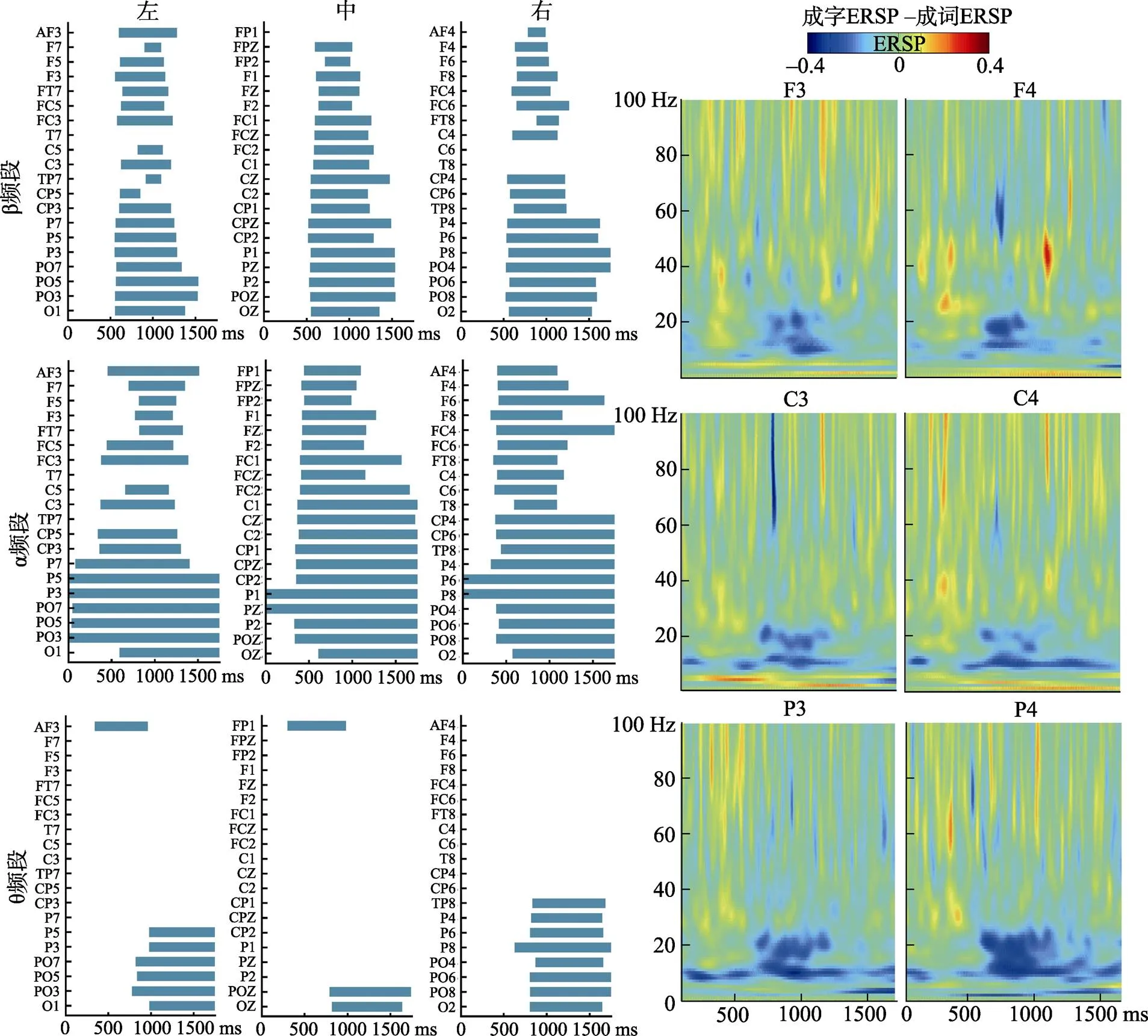
图7 左: 两种条件间θ、α和β频段上存在显著差异的电极和时窗,条形柱为对应电极上条件间差异显著的时间段;右: 部分电极条件间差异的时频结果图。
3.2.5 相关分析结果
如图8所示, 全脑相关分析的结果表明, 在额区和左侧中央区的部分电极上, 学习阶段α/β频段的ERSP与测验阶段的击中率之间呈负相关。学习阶段的ERSP去同步化越强, 测验阶段的击中率越高。排除位置不相邻的电极后, 显著相关的脑区为左侧中央区, C5 (606~1194 ms,= –0.40)、C3 (534~1220 ms,= –0.41)、CP5 (524~1206 ms,= –0.42)、CP3 (468~1230 ms,= –0.42)。
3.3 讨论
本实验考察了合体字和复合词编码在神经机制上的差异, 及其对项目记忆的影响。行为结果表明: 与不能组成字或词的条件相比, 合体字编码条件下的项目记忆成绩显著提升, 而复合词编码条件下的项目记忆成绩没有显著变化; 合体字编码条件下的项目记忆成绩比复合词编码条件下的项目记忆成绩更好。脑电结果表明: 复合词编码时的LNC效应主要集中于额区, 且发生时间较早, 而合体字编码时的LNC效应主要位于枕区, 且发生时间更晚; 此外, 合体字编码伴随着更强的α/β神经振荡去同步化, 且编码时左侧中央区域的α/β神经振荡去同步化与提取时的项目再认成绩有关。从记忆提取的角度来看, 将不同项目绑定为整体没有损害甚至能提升项目记忆成绩, 这说明项目所包含的信息在编码时没有被掩盖。从神经机制的角度来看, 与项目记忆编码有关的α/β神经振荡去同步化在合体字条件下更强, 也说明该条件下的项目加工没有减少, 甚至得到了加强。
4 综合讨论
4.1 实验1中合体字和复合词编码在促进联结记忆上的异同
将两个不同的项目绑定为一个整体可以提升联结记忆成绩, 这在前人的研究中已经达成了共识(刘泽军等, 2019; 郑志伟等, 2015)。这是因为被试在提取阶段不仅能通过项目间的关系进行联结再认, 还能够通过提取编码时形成的整体来“辅助”联结再认的完成。实验1的结果与先前的研究一致(Diana et al., 2010; Haskins et al., 2008; Quamme et al., 2007; Rhodes & Donaldson, 2008; Zheng et al., 2015): 无论是在合体字还是复合词编码条件下, 联结再认成绩都得到了显著提升。因此, 实验1的结果也表明本研究中的实验操纵是有效的, 即无论是汉语中的构字法还是构词法, 都可以将两个汉字绑定为一个整体。
除了这两种编码的相同点, 我们也需要关注它们之间的不同点。复合词编码要求被试将两个字组成一个词, 新形成的整体在本质上还是两个项目(如“开”和“心”组成“开心”)。这与前人使用的复合词(如“希腊”和“神话”组成“希腊神话”; Ahmad & Hockley, 2014; Giovanello et al., 2006; Liu et al., 2020; Rhodes & Donaldson, 2008)或指导语(想象“坐在草地上看天上的云飘过”这样一幅景象来绑定“草地”和“云”这两个词; Parks & Yonelinas, 2015; Pilgrim et al., 2012; Quamme et al., 2007)的操纵方法类似。而合体字编码则要求被试将两个字整合成一个新的汉字, 新形成的整体已不再是原来的两个项目, 而是变成了另一个全新的项目(如“口”和“十”组成“叶”)。另外, 把两个项目绑定为复合词的加工过程属于语素加工(Chung et al., 2010; Ip et al., 2019), 被试需要加工两个项目的语义并将二者在语义上进行绑定(Chung et al., 2010; Gao et al., 2022), 然后在心理词典中对这两个字组成的词语进行检索; 而在亚词汇水平上对汉字的不同部件进行绑定则属于正字法加工, 需要判断的是组成的整体是否符合正字法规则(Anderson et al., 2013; Su et al., 2015)。
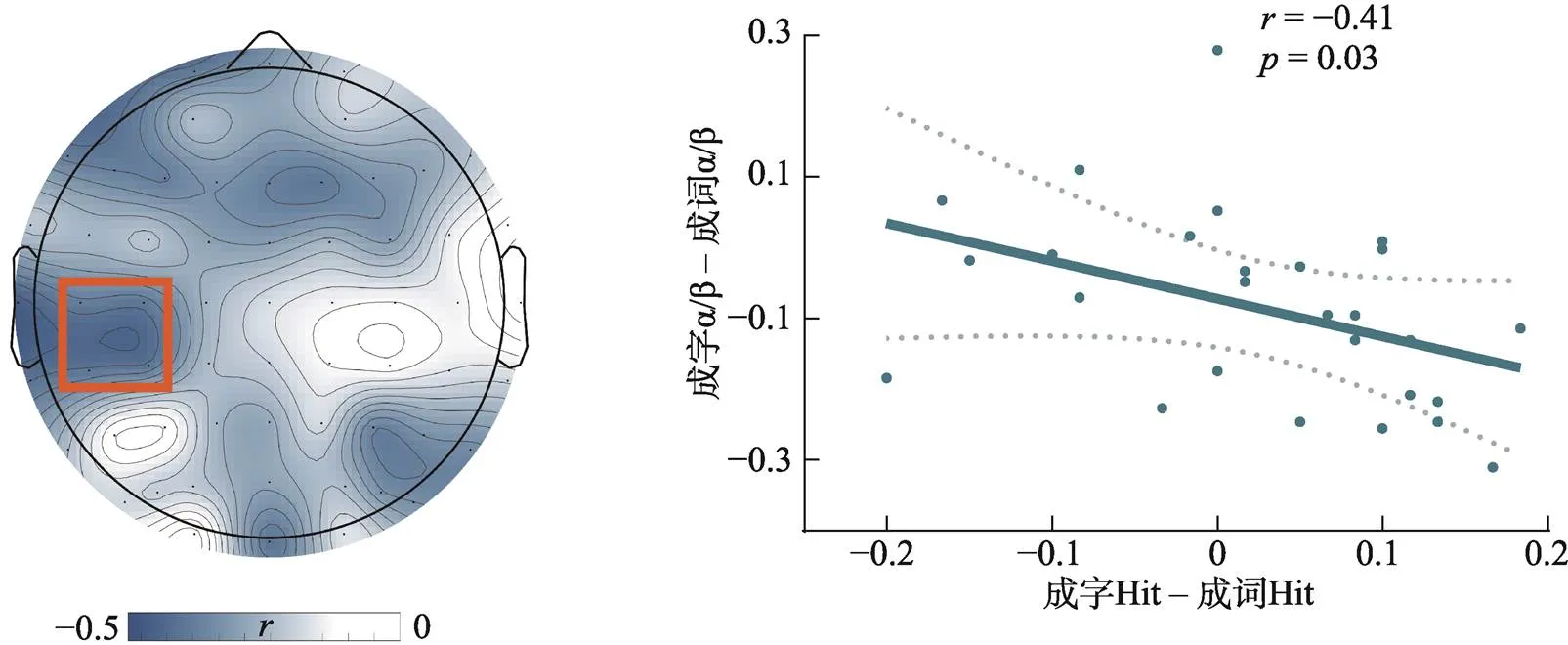
图8 左: α/β频段的ERSP之差与测验阶段Hit之差的相关系数地形图。右: 两种编码条件间相关系数显著的四个电极在α/β频段内的ERSP之差与击中率之差的散点图。
两种编码方式间存在差别, 这一点在MVPA和ERP的结果中也可以得到证实。MVPA的结果表明在刺激呈现后1000 ms左右, 两种编码方式的EEG表征不同。这说明即使同样要求被试将两个项目绑定为一个整体, 但联结成的整体不同, 其诱发的大脑活动也是不同的。在ERP的分析中, 虽然合体字编码与复合词编码都诱发了LNC, 但不同之处在于, 复合词编码时的LNC在时间上出现较早且主要分布于额叶区域, 而合体字编码时的LNC出现得更晚且主要分布于枕叶区域。先前的研究表明, 经典的额区−中央区LNC与信息在工作记忆中进行维持和操纵有关(Baddeley, 1992; Gui et al., 2017; Han et al., 2016; Li et al., 2014)。至于晚期LNC, 其脑区分布与另一个晚期负成分LPN (Late Posterior Negativity)相同。有研究发现LPN反映了大脑对刺激进行复杂且高阶的操纵和评估过程, 受到任务难度的调节(Sommer et al., 2018)。
相比于合体字条件, 复合词条件下的编码反应时和LNC都发生得更快, 其原因可能是合体字编码的难度更大。在复合词编码条件下, 被试只需要从左到右看完就能确定这两个字能否组成一个词语, 因此加工过程相对容易(难度评分的结果也证实了这一点)。比如编码“天下”这个复合词时, 被试在工作记忆中保持“天”和“下”之后, 只需在心理词典中去搜索“天下”这个词即可, 并不需要对“天”或“下”进行其他认知操作。而在合体字编码条件下, 被试在将两个成分联结成一个整体之前, 还需要对这两个部分进行变形。例如, 在编码“禾且”时, 被试需要先在工作记忆中保持“禾”和“且”这两个字, 然后在工作记忆中将“禾”加工为禾字旁, 最后将禾字旁和“且”组合到一起。而这在基于构词法的编码过程中则不需要。
实验1出现了两种不同水平的联结记忆(合体字条件下的联结记忆成绩比复合词条件下的更好), 究其原因, 除了前面提到的组成整体的不同以及加工难度上的差异, 我们推测可能还与整合水平有关(Parks & Yonelinas, 2015)。整合水平(The Levels of Unitization)的观点认为, 将项目绑定为整体是一个连续的过程, 程度有高低之分。例如, 当对“云”和“草坪”这两个词进行绑定时, 可以要求被试想象“‘云草坪’是一个用来观天的院子”, 也可以要求被试想象“他坐在草坪上看云飘过”来记住“云”和“草坪”这个词对。显然, 后一种编码方式的整合水平更低, 因为这两个项目在很大程度上仍然是独立加工的。合体字编码可以说是一种项目内的整合, 因为两个汉字最终组成的是一个汉字(如“口”和“十”构成了“叶”)。复合词编码则可以被看作是一种项目间的整合, 两个词最终组成的是一个复合词(例如“父”和“亲”组成“父亲”), 本质上还是两个字。因为合体字比复合词的整合水平更高, 所以编码时形成的整体更加紧密, 提取阶段则可以产生更强的关于整体的熟悉性。因此, 更高水平的整合可以通过更强的熟悉性来提升联结记忆成绩(Parks & Yonelinas, 2015)。
4.2 从提取的角度看项目编码没有减弱
实验2的行为结果表明, 合体字条件下的项目记忆成绩更好, 这与实验1中联结再认的行为结果一致, 说明联结编码提升的同时项目编码非但没有受损, 还得到了提升, 进一步否定了“收支平衡”的假设, 支持了“只有收益”的观点。因为如果按照“收支平衡”的观点, 绑定过程更多地加工了联结而忽略了项目, 项目得到的加工将会减少进而导致项目记忆成绩降低, 这显然不能很好地解释实验2中的行为结果。但上述结果却可以被“只有收益”的观点解释: 正是因为绑定的过程需要在项目被充分加工的基础之上才能完成, 所以只要绑定成功进行, 项目编码就不会受损, 提取阶段的项目记忆就不会降低。比如在复合词中, 只有加工了“天”的含义, 被试才能知道“天下”的意思, 因为还有很多字可以和“下”组成词语; 同样, 也只有加工了“下”被试才能完整地理解“天下”这个词。在合体字中, 虽然不一定需要加工偏旁或者部首的语义, 但这并不意味着偏旁部首会被忽略。比如“秋”字, 尽管被试不需要加工“禾”和“火”的含义, 但也需要将它们在头脑中转变成对应的偏旁部首, 再将二者进行绑定。总而言之, 将不同项目绑定为整体的过程需要对项目进行充分加工, 因此项目的编码不会被掩盖或损害。
关于合体字比复合词编码条件下的项目记忆成绩更好的原因, 我们推测可能与项目编码时的变异性有关。根据编码变异性假说, 如果学习阶段项目与更多额外的信息建立起了联系, 提取阶段就更有可能提取到与该项目有关的信息, 从而更容易记起该项目(Martin, 1968)。在合体字编码时, 与某个项目同时进行编码的不仅有另一个与之配对的字, 还有新形成的合体字, 这三个项目之间的语义相关性是比较低的(如前面的例子, “口”、“十”和“叶”), 因此编码时的变异性较大。而在复合词编码时, 虽然也有另一个与之配对的字和新组成的复合词与项目同时进行编码, 但相比之下, 复合词和其组成部分之间的语义相关性更高(如“父”和“亲”组成“父亲”), 因此该编码过程中变异性较小, 导致提取阶段项目记忆成绩更低。
4.3 从编码的角度看项目编码没有减弱
更好的项目记忆成绩往往意味着学习阶段更深入的加工和编码, 这一点可以从时频分析的结果中得到验证。根据Griffiths等人(2019)的观点, 在大脑加工信息的过程中, 与任务无关的神经元网络的激活会掩盖与任务相关的关键神经元所产生的信号, 因此神经元大量同步放电对信息加工是有害的。在宏观层面上, 这种同步活动的表现就是α/β振荡。因此, α/β频段的神经振荡去同步化越强, 表明大脑对信息的加工越充分、越有效。实验2的脑电结果表明, 相比于复合词编码, 合体字编码在刺激呈现后500~1000 ms期间, 全脑大部分区域在α/β频段上的神经振荡都表现出更强的去同步化。但这还不能确定这些去同步化代表了项目记忆特异的编码过程, 因为去同步化有可能伴随的是联结记忆的编码、来源记忆的编码或是语义记忆的编码, 甚至可能只是学习过程中伴随产生的注意或感知觉等其他心理过程。实验2中相关性分析的结果可以很好地回答这一质疑。相关分析的结果表明, 左侧中央区域的α/β频段去同步化越强则提取阶段项目记忆成绩越好, 这说明该脑区α/β频段的去同步化与项目记忆的编码有关。再结合合体字编码时全脑(包括左侧中央区)α/β频段上的神经振荡都有着更强去同步化的结果, 我们可以推测在编码合体字时, 与任务无关的神经网络被抑制了。因此, 在合体字编码过程中, 大脑非但没有减少对项目的编码, 反而对其进行了更深入且更有效的加工。
4.4 联结编码和项目编码的关系: 此消彼长或是相辅相成?
关于不同联结方式对项目编码的影响, Tibon等人(2017)认为, 联结编码与项目编码之间存在着某种权衡(trade-off)。自下而上地将两个项目联结成一个整体(通过两个项目间固有的关系将两个项目进行绑定, 如复合词或者语义相关的词对或图片对)可以使联结编码过程更加简化, 节省出来的认知资源可以投入到对项目的编码中去, 因此项目记忆会得到提升; 反之, 如果被试采用自上而下的方式(通过一个定义性的句子把两个不相关的词对绑定为一个新的概念)将两个项目联结成整体, 其绑定的过程会更困难, 大脑对项目的加工就会受到影响, 因此会削弱项目记忆。这一观点看似合理, 但难以解释自下而上的联结方式损害项目记忆(Ahmad & Hockley, 2014; Shao & Weng, 2011), 自上而下的联结又不损害项目记忆(Parks & Yonelinas, 2015; Pilgrim et al., 2012), 以及本研究中被试普遍认为合体字编码更难, 但该条件下的项目记忆成绩反而更好的情况。
本研究发现, 基于构字法的合体字编码方式同时促进了联结记忆和项目记忆。联结编码与项目编码之间的权衡似乎被打破了。我们认为, 在将项目绑定为整体的过程中, 如果该过程比较困难, 会消耗一定的认知资源。但反过来, 这也会促进对项目的加工, 进而弥补联结编码所带来的对项目记忆的损伤, 甚至会提升项目记忆。反之, 如果将项目联结为整体的过程比较简单, 一方面, 联结编码依旧会消耗认知资源, 导致项目得到的加工变少; 另一方面, 由于联结为整体的过程简单且流畅, 项目没有得到进一步的加工, 因此项目记忆受损。与Tibon等人(2017)的观点(编码过程越简单越可以增加对项目的加工, 从而提升项目记忆)不同, 我们认为将项目加工为整体的过程越困难, 反而越能促进联结和项目信息得到更深入的加工, 进而使联结记忆和项目记忆成绩都得到提升。由此可见, 联结编码与项目编码之间的关系可能不是此消彼长的权衡, 更有可能是相辅相成、互相促进的。
4.5 不足与展望
本研究尚存在一些不足。首先, 在实验1中, 测验阶段重组字对中一些项目的位置与学习阶段不同。有研究发现, 相比于学习阶段, 测验阶段项目位置的改变可能会降低被试的联结再认成绩(Bader et al., 2014; de Brigard et al., 2020; Giovanello et al., 2009; Wiegand et al., 2010)。为避免实验1中的实验效应是由重组字对中项目位置的改变导致的, 我们排除所有涉及位置改变的重组字对后, 重新计算了各条件下的Pr值。结果表明, 无论是在成字还是成词条件下, 其联结再认Pr值都显著大于不成字或不成词条件下的Pr值。尽管测验阶段重组字对中项目位置的改变并没有影响实验1的主要结论, 但这仍然是一个值得考虑且需要在将来的实验中加以控制的因素。其次, 由于独体字材料的限制以及成字条件下被试的击中率较高, 导致没有足够的错误试次用于叠加平均以消除噪声的影响, 进而难以从相继记忆效应的角度分析编码阶段与记忆相关的神经指标。未来的研究也可以试着克服实验材料不足这一缺憾, 采用相继记忆效应的方式, 更直接地探讨与记忆编码相关的神经机制。
5 结论
通过考察合体字和复合词加工过程中联结记忆和项目记忆的变化, 以及这两种加工过程在神经机制上的差异, 本研究发现在将项目绑定为整体的过程中, 联结编码得到促进的同时项目编码不会受到损害, 甚至联结编码和项目编码同时得到了促进, 支持了“只有收益”的观点。本研究为理解大脑对合体字或复合词的加工提供了新的角度, 也从实证的角度为汉语学习材料的编排提供了参考。
Ahmad, F. N., & Hockley, W. E. (2014). The role of familiarity in associative recognition of unitized compound word pairs.(12), 2301−2324.
Anderson, R. C., Ku, Y. M., Li, W., Chen, X., Wu, X., & Shu, H. (2013). Learning to see the patterns in Chinese characters.,(1), 41−56.
Bader, R., Opitz, B., Reith, W., & Mecklinger, A. (2014). Is a novel conceptual unit more than the sum of its parts?: FMRI evidence from an associative recognition memory study.,, 123−134.
Baddeley, A. 1992. Working memory.(5044)556–559.
Buchler, N. G., Light, L. L., & Reder, L. M. (2008). Memory for items and associations: Distinct representations and processes in associative recognition.(2), 183−199.
Ceraso, J. (1985). Unit formation in perception and memory.(4), 179−210.
Chung, K. K., Tong, X., Liu, P. D., McBride-Chang, C., & Meng, X. (2010). The processing of morphological structure information in Chinese coordinative compounds: An event- related potential study., 157−166.
de Brigard, F., Langella, S., Stanley, M. L., Castel, A. D., & Giovanello, K. S. (2020). Age-related differences in recognition in associative memory.,(2), 289−301.
Delorme, A., & Makeig, S. (2004). EEGLAB: An open-source toolbox for analysis of single-trial EEG dynamics including independent component analysis.(1), 9−21.
Diana, R. A., Yonelinas, A. P., & Ranganath, C. (2010). Medial temporal lobe activity during source retrieval reflects information type, not memory strength.(8), 1808−1818.
Gao, F., Wang, R., Armada-da-Silva, P., Wang, M. Y., Lu, H., Leong, C., & Yuan, Z. (2022). How the brain encodes morphological constraints during Chinese word reading: An EEG-fNIRS study.,, 184−196.
Giovanello, K. S., Keane, M. M., & Verfaellie, M. (2006). The contribution of familiarity to associative memory in amnesia.(10), 1859−1865.
Giovanello, K. S., Schnyer, D., & Verfaellie, M. (2009). Distincthippocampal regions make unique contributions to relational memory.,(2), 111−117.
Giovanello, K. S., Verfaellie, M., & Keane, M. M. (2003). Disproportionate deficit in associative recognition relative to item recognition in global amnesia.(3), 186–194.
Griffiths, B. J., Mayhew, S. D., Mullinger, K. J., Jorge, J., Charest, I., Wimber, M., & Hanslmayr, S. (2019). Alpha/beta power decreases track the fidelity of stimulus-specific information.,, e49562.
Gui, P., Ku, Y., Li, L., Li, X., Bodner, M., Lenz, F. A., ... Zhou, Y. D. (2017). Neural correlates of visuo-tactile crossmodal paired-associate learning and memory in humans.,, 181−195.
Han, J., Cao, B., Cao, Y., Gao, H., & Li, F. (2016). The role of right frontal brain regions in integration of spatial relation.,, 29−37.
Hanslmayr, S., Staudigl, T., & Fellner, M. C. (2012). Oscillatory power decreases and long-term memory: The information via desynchronization hypothesis.74.
Haskins, A. L., Yonelinas, A. P., Quamme, J. R., & Ranganath, C. (2008). Perirhinal cortex supports encoding and familiarity- based recognition of novel associations.(4), 554−560.
Hockley, W. E., & Cristi, C. (1996). Tests of encoding tradeoffs between item and associative information.(2), 202–216.
Huang, G. (2019). EEG/ERP data analysis toolboxes. In L. Hu & Z. Zhang (Eds.),(pp. 407−434). Singapore, Springer.
Ip, K. I., Marks, R. A., Hsu, L. S. J., Desai, N., Kuan, J. L., & Tardif, T. (2019). Morphological processing in Chinese engages left temporal regions.,, 104696.
Kamp, S. M., Bader, R., & Mecklinger, A. (2016). The effect of unitizing word pairs on recollection versus familiarity- based retrieval-Further evidence from ERPs.,(4), 169−178.
Kamp, S. M., Bader, R., & Mecklinger, A. (2017). ERP subsequent memory effects differ between inter-item and unitization encoding tasks.,, 30.
Kamp, S. M., & Zimmer, H. D. (2015). Contributions of attention and elaboration to associative encoding in young and older adults.,, 252−264.
Khader, P., Heil, M., & Rösler, F. (2005). Material-specific long-term memory representations of faces and spatial positions: Evidence from slow event-related brain potentials.(14), 2109−2124.
Kim, A. S., Vallesi, A., Picton, T. W., & Tulving, E. (2009). Cognitive association formation in episodic memory: Evidence from event-related potentials.,(14), 3162−3173.
Kounios, J., Smith, R. W., Yang, W., Bachman, P., & D'Esposito, M. (2001). Cognitive association formation in human memory revealed by spatiotemporal brain imaging.,(1), 297−306.
Li, B., Zhang, M., Luo, J., Qiu, J., & Liu, Y. (2014). The difference in spatiotemporal dynamics between modus ponens and modus tollens in the Wason selection task: An event-related potential study.,, 177−182.
Liu, Z., & Guo, C. (2019). Unitization improves item recognition through less overall neural processing.(13), 882−886.
Liu, Z., & Guo, C. (2022). Effects of unitization on associative and item recognition: The “benefits-only” account.(12), 1443−1454.
[刘泽军, 郭春彦. (2022). 整合对联结再认和项目再认的促进作用: “只有收益”观点.(12), 1443−1454.]
Liu, Z. J., Wang, Y. J., & Guo, C. Y. (2019). Investigating the item recognition in associative memory: A unitization perspective.(3), 490−498.
[刘泽军, 王余娟, 郭春彦. (2019). 从整合的角度看联结记忆中的项目再认.(3), 490−498.]
Liu, Z., Wu, J., Wang, Y., & Guo, C. (2020). Unitization does not impede overall item recognition performance: Behavioral and event-related potential study., 107−130.
Lopez-Calderon, J., & Luck, S. J. (2014). ERPLAB: An open-source toolbox for the analysis of event-related potentials., 213.
Lu, B., Liu, Z., Wang, Y., & Guo, C. (2020). The different effects of concept definition and interactive imagery encoding on associative recognition for word and picture stimuli., 178−189.
Maris, E., & Oostenveld, R. (2007). Nonparametric statistical testing of EEG-and MEG-data.(1), 177−190.
Martin, E. (1968). Stimulus meaningfulness and paired- associate transfer: An encoding variability hypothesis.(5), 421–441.
Memel, M., & Ryan, L. (2017). Visual integration enhances associative memory equally for young and older adults withoutreducing hippocampal encoding activation.195−206.
Memel, M., & Ryan, T. L. (2018). Visual integration of objects and scenes increases recollection-based responding despite differential MTL recruitment in young and older adults.(12), 886−899.
Murray, B. D., & Kensinger, E. A. (2012). The effects of emotion and encoding strategy on associative memory.(7), 1056–1069.
Parks, C. M., & Yonelinas, A. P. (2015). The importance of unitization for familiarity-based learning.(3), 881−903.
Pilgrim, L. K., Murray, J. G., & Donaldson, D. I. (2012). Characterizing episodic memory retrieval: Electrophysiological evidence for diminished familiarity following unitization.(8), 1671−1681.
Quamme, J. R., Yonelinas, A. P., & Norman, K. A. (2007). Effect of unitization on associative recognition in amnesia.(3), 192−200.
Rhodes, S. M., & Donaldson, D. I. (2008). Electrophysiological evidence for the effect of interactive imagery on episodic memory: Encouraging familiarity for non-unitized stimuli during associative recognition.(2), 873−884.
Robey, A., & Riggins, T. (2017). Increasing relational memory in childhood with unitization strategies.(1), 100−111.
Shao, H., & Weng, X. (2011, November). Unitization benefits associative recognition whereas impairs item recognition. In(pp. 314−317). IEEE.
Sommer, K., Vita, S., & de Pascalis, V. (2018). The late posterior negativity in episodic memory: A correlate of stimulus retrieval?,, 44−53.
Su, M., Wang, J., Maurer, U., Zhang, Y., Li, J., McBride, C., ... Shu, H. (2015). Gene-environment interaction on neural mechanisms of orthographic processing in Chinese children.,, 172−186.
Tibon, R., Gronau, N., & Levy, D. A. (2017). Associative unitization via semantic relatedness benefits episodic recognition of component elements.https://osf.io/preprints/ psyarxiv/cjxse/
Tulving, E. (1972). Episodic and semantic memory. In E. Tulving & W. Donaldson (Eds.),(pp. 381−403). New York, Academic Press.
Wiegand, I., Bader, R., & Mecklinger, A. (2010). Multiple ways to the prior occurrence of an event: An electrophysiological dissociation of experimental and conceptually driven familiarity in recognition memory.,, 106−118.
Zheng, Z. W., Li, J., & Xiao, F. Q. (2015). Familiarity contributes to associative memory: The role of unitization.(2), 202−212.
[郑志伟, 李娟, 肖凤秋. (2015). 熟悉性能够支持联结记忆: 一体化编码的作用.(2), 202–212.]
Zheng, Z., Li, J., Xiao, F., Broster, L. S., Jiang, Y., & Xi, M. (2015). The effects of unitization on the contribution of familiarity and recollection processes to associative recognition memory: Evidence from event-related potentials.(3), 355–362.
Zheng, Z., Li, J., Xiao, F., Ren, W., & He, R. (2016). Unitization improves source memory in older adults: An event-related potential study., 232−244.
The relationship between associative encoding and item encoding in the multiple-component character unitization and compound word unitization
ZHAO Chunyu, GUO Chunyan
(Beijing Key Lab of Learning and Cognition, College of Psychology, Capital Normal University, Beijing 100048, China)
Unitization refers to the manipulation that can integrate two or more items into a single entirety. Previous studies found that unitization facilitated associative memory, however, the effect of unitization on item memory was controversial. Some researchers argued that unitization promoted associative recognition at the cost of item recognition (the view of “benefits and cost”), others held that unitization could promote associative recognition without impairing item recognition (the view of “benefits-only”). These two views seemed to be arguing the impact of unitization on item memory, but in fact, they were discussing the relationship between associative encoding and item encoding during unitization.
The present study intended to explore the relationship between associative encoding and item encoding in the process of unitization through two experiments, by examining the effects of words unitization and characters unitization on associative memory and item memory as well as the differences of neural mechanisms between the two unitization strategies. In experiment 1, we used associative recognition paradigm to explore the unitization effects on associative memory. In the study phase, participants were asked to judge whether the character pairs could form to a multiple-component character (characters unitization) or a compound word (words unitization) or couldn’t (non-unitization). In the test phase, participants were asked to judge whether the character pairs were old or rearranged. In experiment 2, the item recognition paradigm was used. The procedure of the study phase was the same as in Experiment 1. In the test phase, participants were asked to judge whether the characters were old or new. In addition, the EEG signals were recorded during the task to explore the neural mechanism during memory encoding.
The behavioral results showed that: i) the encoding process of characters unitization was more difficult and had longer response time compared to words unitization; ii) the performances of associative recognition was significantly higher for the words and characters unitization conditions than the non-unitization condition, and their performances of item recognition was not decreased; iii) the performances of associative recognition and item recognition was significantly higher for the characters unitization condition than words unitization condition. The EEG results showed that: iv) the LNC during words unitization encoding was mainly distributed in the frontal area and occurred earlier than characters unitization encoding, while the LNC during characters unitization encoding was mainly located in the occipital area and occurs later than words unitization encoding; v) the desynchronization of neural oscillation within α/β band was stronger for characters unitization condition compared to words unitization condition, and the desynchronization of neural oscillation within α/β band during encoding was significantly correlated with the hit of item recognition during retrieval.
These results indicate from the perspectives of memory encoding and retrieval that the manipulation of unitization does not damage the processing of items while strengthening the processing of associative information, supporting the view of “benefits-only”. This research has deepened our understanding that the brain processes multiple-component Chinese characters and compound words, and also provided a reference for the arrangement of Chinese learning materials from the perspective of empirical evidence.
item encoding, associative encoding, multiple-component characters, compound words, item memory, associative memory
2022-07-04
* 国家自然科学基金资助项目(31671127)。
郭春彦, E-mail: guocy@cnu.edu.cn
B842
