基于旋转框精细定位的遥感目标检测方法研究
2023-03-06方观寿郑兵兵
朱 煜 方观寿 郑兵兵 韩 飞
近年来,随着遥感技术的发展,高质量的遥感图像日益增多,这为遥感领域的应用奠定了基础.遥感图像广泛应用于灾害监测、资源调查、土地利用评价、农业产值测算、城市建设规划等领域[1],对于社会和经济发展具有重要的意义.而目标检测作为遥感图像处理的应用之一,获得图中特定目标类别和位置.通常关注飞机、机场、船舶、桥梁和汽车等目标,因此对于民用和军用领域有着十分重要的用途[2].在民用领域中,船舶的定位有利于海上救援行动,车辆的定位有利于车辆计数和分析道路的拥堵情况等.在军事领域中,这些类别信息的检测获取,有利于快速且精准地锁定攻击目标位置、分析战争形势以及制定军事行动等.因此对于遥感图像中的目标进行精准检测至关重要.
目标检测是计算机视觉领域中一个重要且具有挑战性的研究热点.随着深度学习的快速发展,目标检测器的性能取得了显著进步,已经广泛应用于各个行业.目前常用的目标检测器大致可以分为两级检测器和单级检测器两类[3].两级检测器是基于区域卷积神经网络(Regions with convolutional neural network,R-CNN)框架,检测过程分为两个阶段.第1 阶段从图像中生成一系列候选框区域,第2 阶段从候选框区域中提取特征,然后使用分类器和回归器进行预测.Faster R-CNN[4]作为两级检测器的经典方法,提出候选区域生成网络(Region proposal networks,RPN)用于候选框的产生,从而快速、准确地实现端到端检测.之后区域全卷积网络(Region-based fully convolutional network,RFCN)[5]、Cascade R-CNN[6]等两级检测器的出现进一步提高目标检测的精度.单级检测器将检测问题简化为回归问题,仅仅由一系列卷积层进行分类回归,而不需要产生候选框及特征提取阶段.因此这类方法通常检测速度较快.例如,Redmon 等[7]提出YOLO 检测器,将图像划分为一系列网格区域,每个网格区域直接回归得到边界框.Liu 等[8]提出SSD检测器,在多个不同尺度大小的特征图上直接分类回归.Lin 等[9]提出Focal Loss 分类损失函数,解决单级检测器的类别不平衡问题,进一步提高检测精度.这些先进的目标检测技术往往用于水平边界框的生成,然而在遥感图像中,大多数检测目标呈现出任意方向排列,对于横纵比大或者密集排列的目标,仅仅采用水平框检测将包含过多的冗余信息,影响检测效果.因此旋转方向成为不可忽视的因素.
早期应用于遥感领域的旋转框检测算法主要来源于文本检测,例如R2CNN[10]和RPN[11]等.然而由于遥感图像背景复杂且空间分辨率变化较大,相比于二分类的文本检测具有更大困难,因此这些优秀的文本检测算法直接应用于遥感领域中并不能取得较好的检测效果.近年来,随着目标检测算法的发展以及针对遥感图像的深入研究,涌现出许多性能良好的旋转框检测算法.例如Ding 等[12]提出旋转感兴趣区域学习器(Region of interest transformer,RoI),将水平框转换为旋转框,并在学习器中执行边界框的回归;Zhang 等[13]提出通过捕获全局场景和局部特征的相关性增强特征;Azimi 等[14]提出基于多尺度卷积核的图像级联方法;Yang 等[15]提出像素注意力机制抑制图像噪声,突出目标的特征,并且在SmoothL1损失[4]中引入IoU 常数因子解决旋转框的边界问题,使旋转框预测更加精确.Yang 等[16]设计精细调整模块,采用特征调整模块,通过插值操作实现特征对齐.Xu 等[17]提出回归4种长度比来表示对应边的相对偏移距离,并且引入了一个真实框与其水平边界框面积比作为倾斜因子,用于对每个目标水平或旋转检测的选择.Wei等[18]提出利用预测内部中线实现旋转目标检测的方法.Li 等[19]提出利用预测的掩模获取旋转框的方法.Wang 等[20]提出了一种基于初始横向连接的特征金字塔网络(Feature pyramid networks,FPN)增强算法,同时利用语义注意力机制网络提供语义特征,从复杂的背景中提取目标.
因此,目前在遥感图像中用于旋转框检测的方法大致可以分为两种.其中一种算法整体结构仍然为水平框检测,仅仅在回归预测分支中增加一些变量的获取,例如角度因子等.这种算法使得在网络预测的像素中包含较多背景信息,容易出现图1 所示的角度偏移以及漏检较多等问题.另一种算法预设含有角度的锚点框,然后采用旋转候选框内的像素进行预测.由于目标的旋转角度较多,因此这种算法需要预设大量的锚点框以保证召回率,这样会极大地增加计算量.

图1 遥感图像目标检测问题可视化Fig.1 Visualization of remote sensing images object detection problem
针对上述不足,本文结合这两种处理方法的优势,以Faster R-CNN[21]为基础,提出一种用于旋转框检测的网络R2-FRCNN (Refined rotated faster R-CNN).该网络依次采用上述两种旋转框处理方法,将前一种方法得到旋转框的过程视为粗调,这个阶段产生的旋转框作为后一种方法的预设框,然后对于旋转框再次进行调整,这个过程称为细调.两阶段调整使得网络输出更加精确的预测框.此外,针对遥感图像存在较多小目标的特点,本文提出像素重组特征金字塔结构(Pixel-recombination feature pyramid network,PFPN),相比于传统的金字塔网络,本文的金字塔结构使得特征局部信息与全局信息相结合,从而突出复杂背景下小目标的特征响应.同时为了更好地提取表征目标信息的特征,用于后续预测阶段,本文在粗调阶段设计积分感兴趣区域池化方法(Integrate region of interest pool,IRoIPool),以及在精调阶段设计旋转感兴趣区域池化方法(Rotated region of interest pool,RRoIPool),提升复杂背景下小目标的检测精度.最后,本文在粗调和细调阶段均采用全连接层与卷积层结合的预测分支以及SmoothLn回归损失函数,进一步提升算法性能.
本文结构安排如下: 第1 节详细阐述本文提出的旋转框检测网络R2-FRCNN;第2 节通过与官方基准方法和现有方法的实验结果进行对比,以及本文方法各模块的分离实验,评估本文方法的性能;第3 节总结.
1 旋转框目标检测方法
本节对提出的网络R2-FRCNN 结构以及各模块进行阐述.首先介绍R2-FRCNN 网络的整体结构,然后详细介绍各个模块(像素重组金字塔结构、感兴趣区域特征提取和网络预测分支结构),最后介绍本文使用的损失函数.
1.1 网络结构设计
图2 展示了R2-FRCNN 网络的整体结构,可以分为基础网络、像素重组金字塔、候选区域生成网络RPN、粗略调整阶段和精细调整阶段5 个部分.
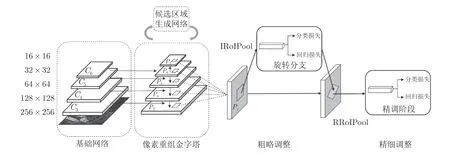
图2 R2-FRCNN 网络结构图Fig.2 The structure of R2-FRCNN
本文采用ResNet[22]作为算法的基础网络,将C3、C4、C5和C6特征层用于构建特征金字塔结构,增强网络对于小目标的检测能力.由金字塔产生的P3、P4、P5、P6和P75 个特征层上,每个像素点预设3 个锚点框,锚点框的长宽比为{1:1,1:2,2:1},尺寸大小为8,经由RPN[4]调整锚点框的位置生成一系列候选框.然后选择置信度较高的2 000 个候选框用于粗略调整阶段,该模块的回归过程将水平框调整为旋转框.最后这些候选框进入精细调整阶段,再次调整旋转框的位置,得到更好的检测效果.经过两阶段调整后的框,选择后一阶段中最大分类数值作为置信度,同时采用旋转非极大抑制算法处理,选取邻域内置信度较高的框,并且抑制低置信度的框,这些高置信度的候选框即为网络输出预测框.
1.2 像素重组金字塔结构
特征金字塔结构[23]被广泛应用于许多先进的目标检测算法中,这个结构的设计在于浅层的定位信息准确,深层的语义信息丰富,通过融合深浅层特征图,提升对于小目标的检测性能.如表1 所示,RoI-Transformer (RT)[12]、CADNet[13]、SCRDet[15]、R3Det[16]和GV R-CNN (GV)[17]均采用了深浅层融合特征,表现出优异的检测性能,而R2CNN[10]未使用特征融合,取得的检测结果远低于其他方法.图3为本文设计的像素重组金字塔结构.该结构分为2个阶段: 第1 阶段为Ci→Mi,采用尺度转化的方式,利用局部特征信息的同时,融合上下层构建金字塔结构;第2 阶段为Mi→Pi,采用非局部注意力[24]模块,利用全局信息,突出目标区域的特征.
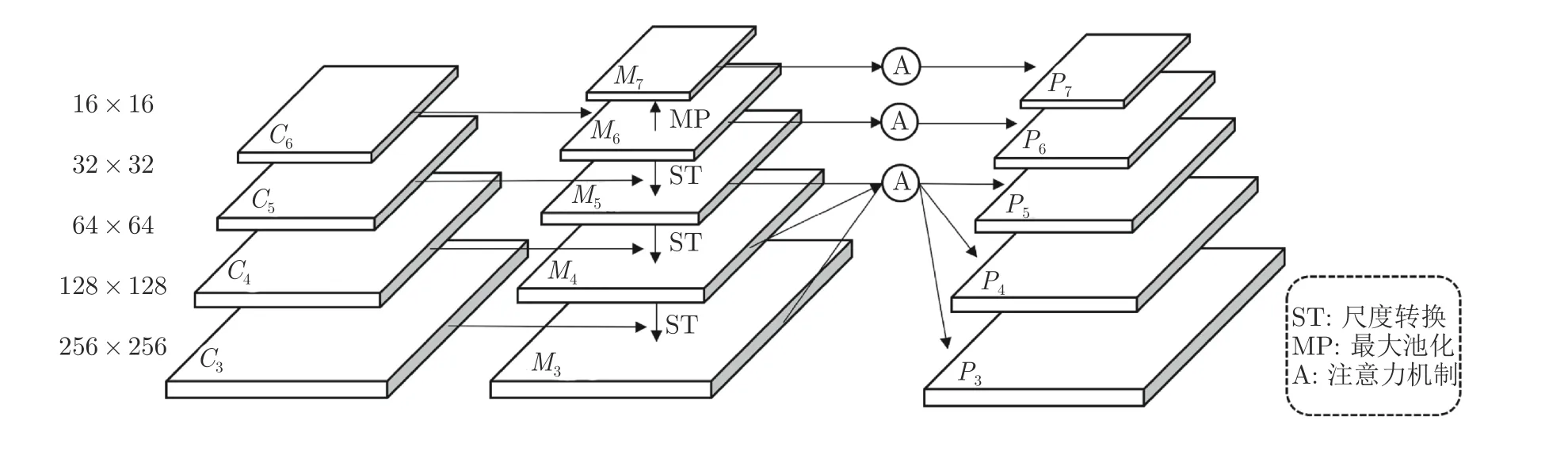
图3 像素重组金字塔结构Fig.3 The structure of pixel-recombination pyramid
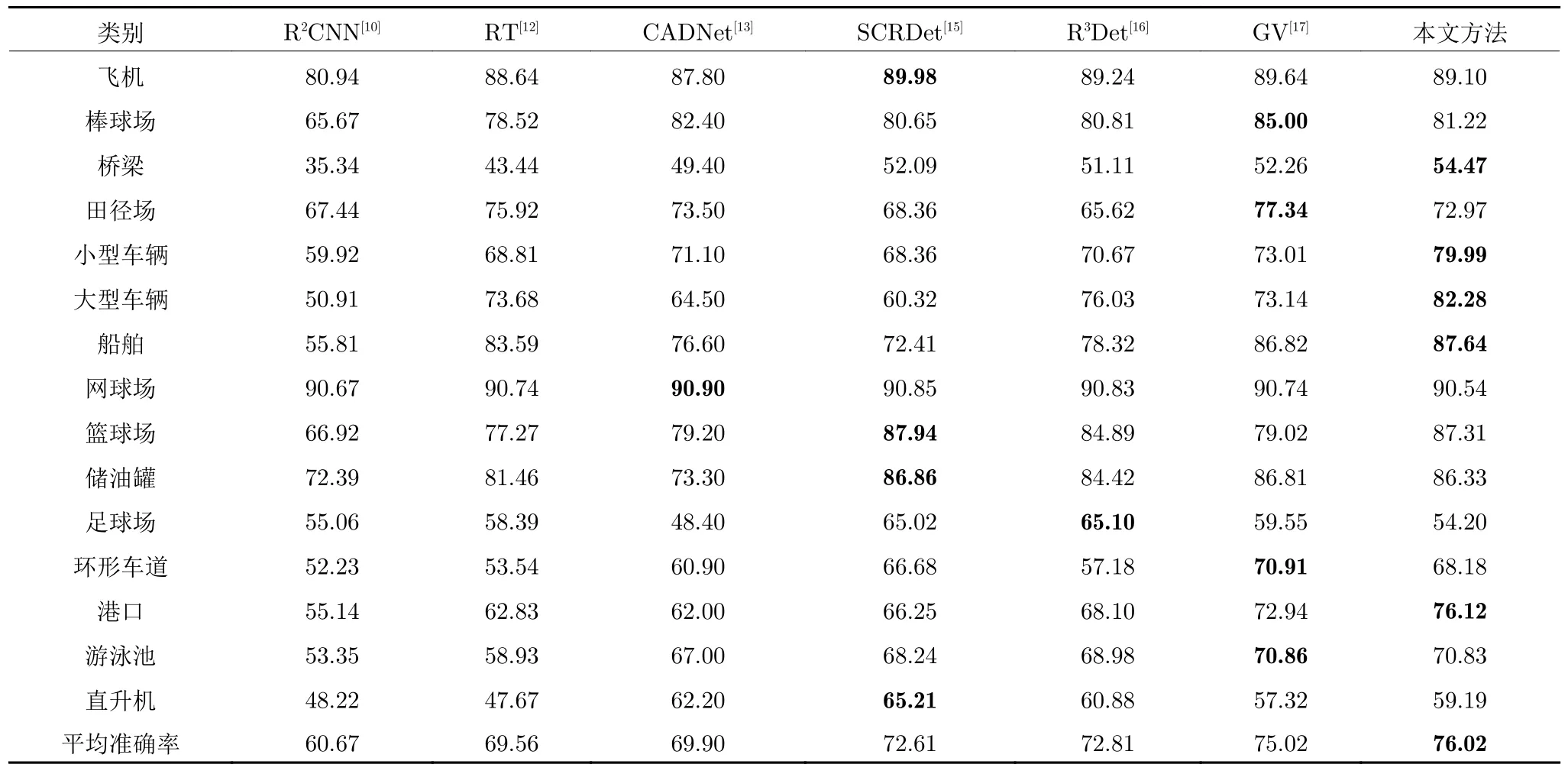
表1 不同方法在DOTA 数据集的检测精度对比(%)Table 1 Comparison of detection accuracy of different methods in DOTA (%)
在第1 阶段中,特征上采样对于金字塔结构是一个关键的操作.最常用的特征上采样方式为插值和转置卷积[25].插值法仅考虑相邻像素,无法获取密集预测任务所需的丰富语义信息.转置卷积作为卷积的逆运算,将其作为上采样方式存在2 点不足[26]:1)对于整个特征图都采用同样的卷积核,而不考虑特征图中的目标信息,限制了上采样过程对于局部变化的响应;2)若采用较大的卷积核将会增加大量参数.本文引入尺度转换作为特征上采样方法.深浅层特征融合的操作过程如图4 所示.该方法首先利用 “通道转化”方法[27]压缩通道数(本文压缩系数r=0.5),增大特征图尺寸,即:
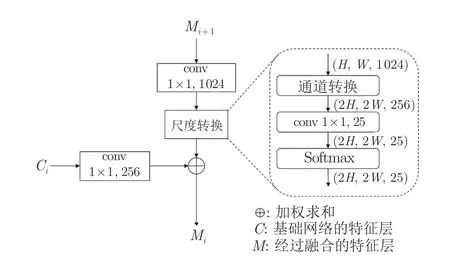
图4 特征融合结构Fig.4 The structure of feature fusion
然后,采用 1×1 的卷积层用于调整通道数,再由Softmax 函数[28]作用于每一通道的特征层.最后采用式(2)进行加权求和,使得特征融合过程更好地利用局部信息.
式中,m、n分别表示像素的横、纵位置,c表示C特征层当前通道,k表示M特征层当前通道.
第2 阶段采用非局部注意力模块,利用特征图中目标与全局特征的关系,突出目标区域的响应.
根据非局部注意力模块的定义,假设C为通道数,s为尺度大小,G为特征图尺度的乘积即s×s,x为输入特征图,q(x) 、k(x) 和v(x) 定义为采用不同线性转换的结果:
q(xs)与k(xs) 矩 阵相乘,得二维矩阵os ∈RG×G;再运用Softmax 将矩阵的每一行转换为概率值,最后与v(xs) 矩阵相乘后再与输入相加,得输出量xs′:
在本文的特征金字塔结构中,第1 阶段输出的M3和M4由于尺度较大,直接用于非局部注意力模块计算量较大.因此为了保留这两层的语义信息,同时再次融合不同层的特征,该结构将M3和M4池化为M5的尺寸大小,然后计算这3 层的均值输入非局部注意力模块,再由插值操作输出对应相等尺寸的特征图.M6和M7的特征图直接应用非局部注意力模块得到P6和P7层.
1.3 感兴趣区域特征提取模块
感兴趣区域特征提取模块主要用于固定输出尺寸大小,提取表征框内区域的特征,便于后续的网络预测.本文的RoI 特征提取模块主要分为粗调阶段的水平框和细调阶段的旋转框RoI 特征提取两部分.
自然场景图像中的目标通常是固定方向呈现,因此两阶段式目标检测算法采用水平框的RoI 特征提取.目前,应用较为广泛的RoI 特征提取是RoIPooling[4]和RoI Align[29].图5(a)为RoI 池化原理图,选择量化后块中最大像素值作为池化后的结果.然而量化的结果会导致提取的小目标像素存在偏差,影响检测效果.图5(b)为RoI 对齐原理图,取消量化操作,采用双线性插值在块中计算出N个浮点坐标的像素值,均值作为块的结果.然而这个操作存在两点不足: 采样点数量需要预先设置,不同大小候选框设置了相同数量的采样点.
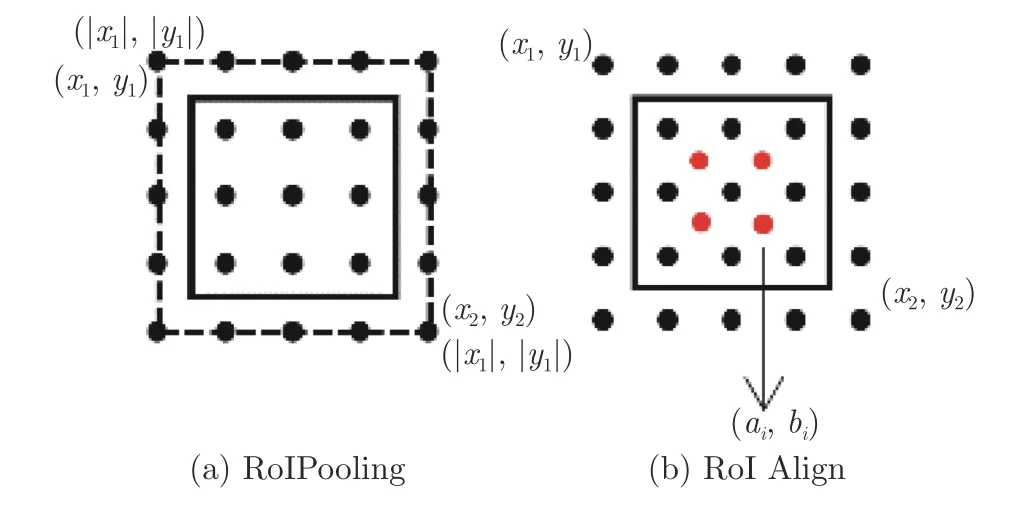
图5 常用RoI 特征提取示意图Fig.5 The schematic diagram of common RoI feature extraction
因此,本文采用精确RoI (Precise RoI,Pr-RoI)池化方法[30]的特征提取操作,如图6 所示,由插值操作将块内特征视为一个连续的过程,采用积分方
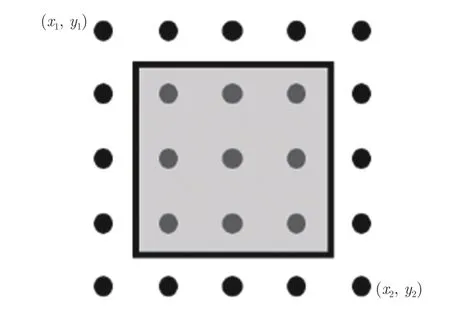
图6 IRoIPool 特征提取示意图Fig.6 The diagram of IRoIPool feature extraction
法获得整个块的像素和,其均值作为块的结果,即:
式中,f(x,y) 为采用面积插值法[15]所得的像素值.
旋转框RoI 特征提取直接采用积分操作较为复杂,因此本文将积分操作视为块内一定数量的像素之和,从而得到块的均值,即:
式中,(x1,y1) 和 (x2,y2) 分别为旋转框在水平位置处的左上角和右下角点,lx和ly分别为水平方向和垂直方向的采样距离,如图7 所示.
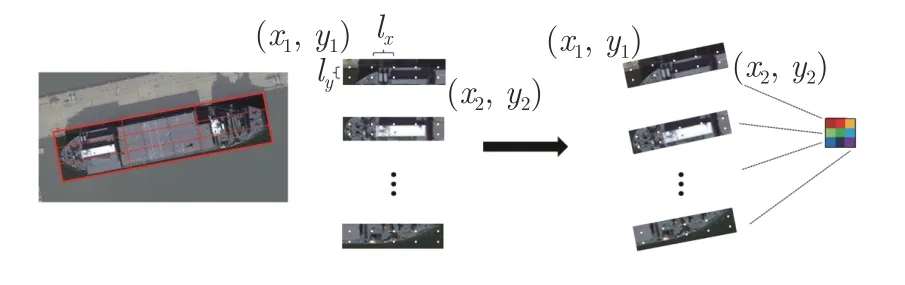
图7 旋转RoI 特征提取示意图Fig.7 The diagram of rotated RoI feature extraction
根据候选框的大小决定采样点的数量.然而采样距离太小会导致计算量大幅增加,因此为平衡检测效率与精度,本文将采样距离lx和ly设置为0.4.
旋转框在水平位置处采样点的坐标为 (xh,yh),旋转框w所对应的边与横轴正方向的夹角为θ,旋转框的中心点为 (cx,cy),由式(10)转化为旋转框中的坐标 (x,y),再由面积插值法得到该位置的像素值.
本文方法与R3Det 类似,都使用了精细调整旋转框的定位.然而R3Det 每一次调整的预测分支直接采用卷积层操作,但是卷积操作为水平滑动,用于旋转框回归将会包含一些背景像素干扰预测结果,而本文方法采用旋转框感兴趣区域提取框内的特征信息用于预测,更加有利于检测性能的提升.
1.4 预测分支结构
目标检测算法分为定位和分类两个任务.一般而言,两级检测器的预测分支采用全连接层,而单级检测器的预测分支采用卷积层.Wu 等[31]发现这两个任务适合于不同的预测分支结构,全连接层更适合用于分类任务,卷积层更适合用于回归任务.因此,本文采用图8 所示的预测分支结构.
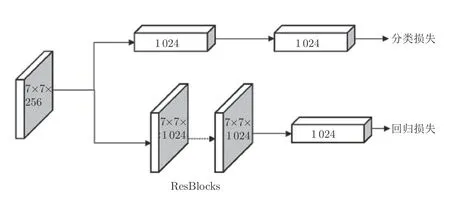
图8 预测分支结构图Fig.8 The diagram of prediction branch
在本文采用的预测分支中,分类结构保持不变,仍然采用全连接层.而回归分支采用一系列Res-Net 网络中的ResBlock 结构(本文使用2 个).
1.5 网络训练损失函数
本文提出网络的损失函数包含RPN 阶段LRPN、粗略调整阶段Lro和精细调整阶段Lre,即:
每一阶段的损失函数都包含分类损失和回归损失.分类损失采用交叉熵损失函数[4].回归损失采用SmoothLn损失函数[32],如式(12)所示,相比于SmoothL1损失函数[4],该损失函数的一阶导数是连续存在的,具有良好的光滑性.
此外,式(11) 中RPN 阶段为水平框的回归,因此使用x、y、w、h4 个值代表水平框.粗调阶段和细调阶段为旋转框的回归,使用x、y、w、h、θ5 个值代表旋转框,因此旋转框的回归转换值定义为:
式中,x、y、w、h、θ分别为旋转框中心点的横、纵坐标,框的宽度、高度和旋转角度.xt、xa分别表示真实框和候选框的值.
2 实验结果与分析
本文实验设备使用英特尔E5-2 683 CPU,英伟达GTX 1080Ti 显卡,64 GB 内存的服务器,实验环境为Ubuntu 16.04.4 操作系统、Cuda9.0、Cudnn7.4.2、Pytorch1.1.0、Python3.7.
本文实验中采用3 个GPU 进行训练,批处理大小为3 (GPU 显存限制),输入图像统一为1 024×1 024 分辨率.训练的迭代次数为15 轮,同时使用衰减系数为0.0001、动量为0.9 的随机梯度下降作为优化器,初始的学习率设置为0.01,分别在第8、第11 轮和第14 轮将学习率降低10 倍.图9 是在DOTA 数据集上训练过程的损失下降曲线图(一轮训练有4 500 次迭代),在第8 轮(36 000 次迭代)出现明显的损失下降.
图9 在DOTA 上训练过程损失曲线图Fig.9 Train loss on DOTA
2.1 实验数据集
本文使用DOTA[21]用于算法的评估.DOTA是由旋转框标注的大型公开数据集,主要用于遥感图像目标检测任务.该数据集包含由各个不同传感器和平台采集的2 806 张图像,图像的大小范围从800 × 800 像素到4 000 × 4 000 像素,含有各种尺度、方向和形状.专家选择15 种常见类别对这些图像进行标注,总共标注188 282 个目标对象,包括飞机、棒球场、桥梁、田径场、小型车辆、大型车辆、船舶、网球场、篮球场、储油罐、足球场、环形车道、港口、游泳池和直升机.另外该数据集选取一半的图像作为训练集,1/6 作为验证集,1/3 作为测试集,其中测试集的标注不公开.为降低高分辨率图像由于压缩对于小目标的影响,本文将所有图像统一裁剪为1 024 × 1 024 的子图像,重叠为200 像素.
2.2 检测结果对比
本文方法采用ResNet50 与可变形卷积[33]相结合作为基础网络进行本节实验.为了评估本文方法的性能,实验数据均采用官方提供的训练集和测试集.实验结果通过提交到DOTA 评估服务器上获得,本文方法的评估结果平均准确率为0.7602,超过目前官方提供的基准方法[21].
除了与官方基准方法进行对比,本节实验还与R2CNN[10]、RoI-Transformer[12]、CADNet[13]、SCRDet[15]、R3Det[16]和GV R-CNN[17]进行对比分析,各方法的检测结果如表1 所示.
由表1 中的检测结果可以看出,本文方法的检测结果优于其他方法,达到76.02%的平均准确率.其中桥梁、小型车辆、大型车辆、船舶和港口这些类别取得最高检测精度.由图10 可以看出,这些类别的目标在遥感数据集中尺寸较小,并且往往呈现出密集排列,因此说明本文方法对于在这类场景的检测更具有优势.此外,飞机、网球场、篮球场、储水池、游泳池等类别在遥感数据集中尺寸较大,对于这些目标本文方法仍取得与其他方法中最高检测精度相差不大的结果.这些检测结果说明本文方法能够有效地用于检测遥感图像中的目标.

图10 各类别检测结果展示Fig.10 Visualization of each category detection
2.3 分离实验
1)各模块对于检测精度的影响
为验证本文方法各模块的有效性,本节进行了一系列对比实验.表2 展示了网络在DOTA 数据集上不同模块设置的检测结果.其中 “√”表示采用该项设置,ConvFc 表示采用第1.4 节设计的预测分支结构.对比实验分析如下:
a)基准设置.本节实验将扩展后的Faster RCNN OBB[21]用于旋转框检测任务.其中,基础网络采用ResNet50[22],并且采用特征金字塔[23],RoI特征提取采用RoI Align[29],回归分支采用SmoothL1损失函数[4].为了保证实验的公平性和准确性,后续实验参数设置都是严格一致.
b)精细调整.在实验的精细调整阶段,初始候选区域特征提取选择Rotated RoI Align (RRoI Align)方法,该方法为RoI Align[29]在旋转框中的应用.由表2 的结果显示,精细调整阶段的添加,使得检测效果得到大幅提升,评估指标平均准确率增加4.10%.说明提取旋转候选框内像素进一步调整是有必要的,这个阶段避免了水平框特征提取包含过多背景像素的问题,从而提升对较大横纵比目标的检测效果.然而在实验中发现,在精细调整结构中多次调整提升效果并不明显,从一次调整增加为两次调整,平均准确率为73.68%,仅仅增加0.06%,因此为了减少参数量,本文后续实验的精细调整阶段采用一次调整过程.
c) RoI 特征提取.实验中,将第1.3 节提出的IRoIPool 和RRoIPool 用于替换初始两阶段调整模块的RoI Align 和RRoI Align.由表2 的实验结果显示,相比于初始RoI 特征提取方法,IRoIPool 方法使得检测精度平均准确率提升0.37%,RRoIPool 方法使得检测精度平均准确率进一步提升0.32%,说明本文设计的RoI 特征提取更为有效.本文后续将对这两个特征提取方法的结构做进一步研究.
d) PFPN 结构.为了更好地验证PFPN 的作用,本文对此设计了两组实验.第1 组,金字塔结构的深浅层不进行尺寸转化和非局部注意力模块,仅仅采用 1×1 的卷积将特征层的通道数转化为256,网络的其他结构和训练超参数保持一致,平均准确率仅为64.55%,由于DOTA 数据集中小目标较多,因此说明PFPN 金字塔结构对于小目标的检测效果显著.第2 组实验的结果见表2,相比于FPN,PFPN 使得平均准确率提升0.66%,说明本文提出的PFPN 结构对于遥感目标的检测更为有效.
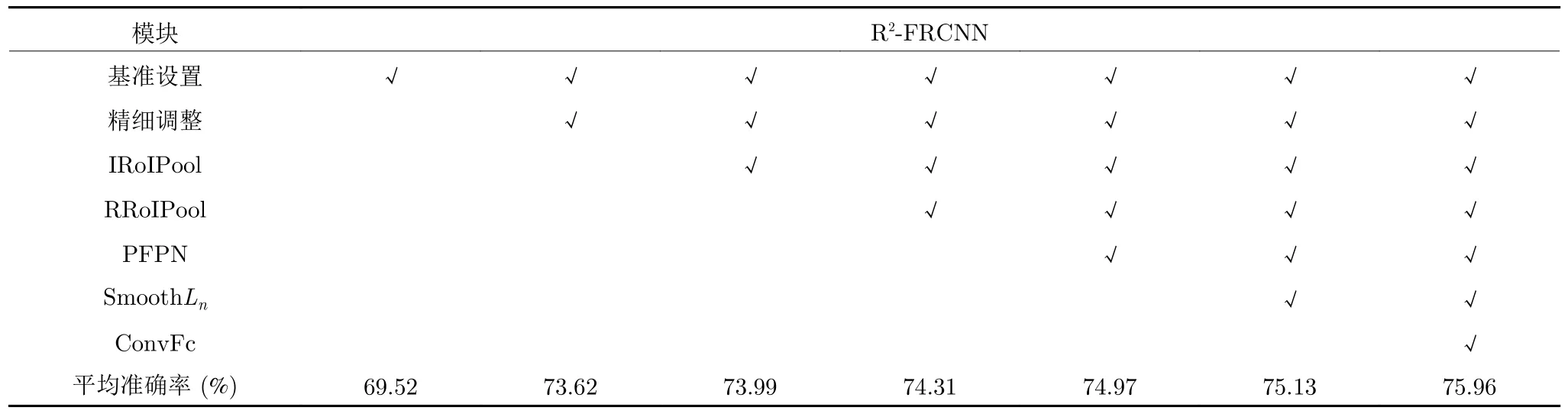
表2 R2-FRCNN 模块分离检测结果Table 2 R2-FRCNN module separates detection results
e)网络预测分支.本节针对预测分支进行两部分的实验,即回归损失函数和预测分支结构.由表2可以看出,相比于SmoothL1,回归损失函数采用SmoothLn, 使得检测精度平均准确率提升0.16%.此外,采用第1.4 节所设计的预测分支结构,分类过程采用全连接层,回归过程采用卷积层,仅增加2个ResBlock 模块,使得平均准确率提升0.83%.由此说明回归过程采用SmoothLn函数和卷积层更加适合旋转框目标检测.
2)感兴趣区域特征提取模块研究
本节研究不同RoI 特征提取结构对于检测精度的影响,实验分为水平候选框特征提取方法和旋转候选框特征提取方法两部分.实验结果分别见表3和表4 所示.

表4 不同旋转框特征提取方法的实验结果Table 4 Experimental results of different feature extraction methods of rotated boxes
表3 的实验结果显示,采用RoIPooling 方式的检测精度相对较低,其量化操作降低了对于小目标的检测效果. 而RoI Align 方式取消量化操作, 采用插值方式使得平均准确率提升2.41%, 说明提取连续的特征有利于目标检测. 本文方法在面积插值法的基础上引入积分操作, 平均准确率提升0.37%.相比于前一种方式选取固定数量的像素点, 本文采用的积分操作类似于选取较多点, 可以提取更多特征, 有利于检测效果的提升.

表3 不同水平框特征提取方法的实验结果Table 3 Experimental results of feature extraction methods of different horizontal boxes
表4 为采用不同旋转框特征提取方法的检测结果. 第1 种方法旋转感兴趣区域平均池化方法(Rotated region of interest average pooling, RRoI APooling)选取旋转框内的像素点, 像素均值作为提取的特征. 第2 种方法采用类似RoI Align 的方式在旋转框内选择浮点数坐标, 运用双线性插值获得对应的像素值, 平均准确率提升0.61%. 本文采用方法RRoIPool 可以根据旋转框大小选择不同数量的像素点表示特征. 相比于第2 种方式提升0.32%,说明本文采用的旋转框特征提取方式更适合于精细调整模块.
3 结束语
基于深度学习的目标检测算法在自然场景图像中取得了很大进展. 然而遥感图像存在背景复杂、小目标较多、排列方向任意等难点, 常见的目标检测算法并不满足这类场景的应用需求. 因此本文提出一种粗调与细调两阶段结合的旋转框检测网络R2-FRCNN 用于遥感图像检测任务. 并且设计像素重组金字塔结构, 提高复杂背景下小目标的检测性能. 同时在粗调阶段设计一种水平框特征提取方法IRoIPool, 细调阶段设计旋转框特征提取方法RRoIPool. 此外, 本文还采用SmoothLn回归损失函数, 以及全连接层和卷积层结合的预测分支, 进一步提升检测精度. 实验结果表明本文方法在大型公共数据集DOTA 上获得了较好的检测效果. 然而本文方法存在检测速度较慢、GPU 资源消耗较大等缺点, 因此在后续的工作中也将针对网络的轻量化展开进一步研究.
