融合注意力机制的煤层气产量动态预测
2023-02-27李媛郭大立康芸玮
李媛, 郭大立, 康芸玮
(西南石油大学理学院, 成都 610500)
煤层气的产量预测研究可对后续的煤层气开发提供建议,并有利于煤层气经济效益的预测,在煤层气开发过程中发挥重要的作用[1-2]。传统的煤层气产量预测采用数值模拟方法,但该方法使用复杂,需要大量的储层数据与生产数据并且计算结果对不同生产井的数据难以匹配[3],因此一些学者将人工智能算法引入了煤层气产量预测研究中。吕玉民等[1]利用反向传播(back propagation,BP)神经网络拟合煤层井的生产历史;孔鹏等[4]利用主成分分析法得到了影响煤层气产量的主控因素,并利用朴素贝叶斯方法预测煤层气产量;朱庆钟等[3]综合考虑排采参数和产气量的动态变化,根据随机森林回归模型进行煤层气产量预测;Zeng等[5]改进了传统的灰色预测模型用于中国煤层气预测,在样本量较小时预测效果良好。
煤层气生产数据是随时间不断变化的时间序列数据,但是上述几种模型的训练方式为点对点映射,忽视了数据的时序性。因此,提出了可进行时序预测的长短期记忆神经网络(long short term memory,LSTM)预测煤层气产量。Guo等[6]利用近邻传播算法聚类邻井数据,并利用LSTM网络进行预测,该方法的精度高于传统的浅层神经网络与数值模拟;Xu等[7-8]利用多变量的LSTM网络,对煤层气产量预测取得了良好的效果,还将迁移学习引入神经网络,给生产数据量不足时的产量预测提供依据;董维强等[2]也将LSTM网络应用于煤层气产量预测。但是传统的LSTM网络煤层气产量预测结果的准确度还有能进一步提升的空间。
为了解决传统煤层气产量预测忽略的时序性问题,更好地提取煤层气产量影响因素的有效信息,且进一步提高预测的准确度,现提出一种新的煤层气产量动态预测模型,即融合注意力机制的CNN-LSTM的煤层气产量动态预测模型。利用X区块的煤层气井数据,优选影响煤层气产量的主控因素,建立煤层气井产量动态预测模型,与传统的LSTM网络比较,结合了卷积神经网络(convolutional neural networks,CNN)高效的特征提取能力和LSTM网络处理长序列数据的能力,并融合注意力机制分配LSTM隐含层的概率权重,对于煤层气井的日产气量预测提供一种新方法。
1 基本原理
1.1 基于CNN网络的特征提取
煤层气的生产数据是非线性的,具有信息量大,信息种类多,各种参数与煤层气产量之间关系复杂等特点[9]。卷积神经网络(convolutional neural networks,CNN)可提取数据的深层次特征,对于处理非线性数据的能力更强,同时也避免了手工提取特征带来的诸多不利[10]。其中一维卷积神经网络学习非线性序列的数据准确性较高,可用于时间序列的特征识别和提取[11],一般包括卷积层、池化层和全连接层。卷积层可自动提取数据中的特征向量;池化层可进行特征降维,避免过拟合;全连接层的作用为对输出数据进行维数转化。将LSTM网络处理长时间序列的优势与CNN网络提取特征的能力优势结合,避免因输入序列过长导致精度降低的情况。
1.2 基于LSTM网络的时序预测
长短期记忆神经网络(LSTM)是一种可进行时序预测的时间循环神经网络,包括输入门it、遗忘门ft和输出门ot,t为当前时刻。利用“门”可控制传入信息的更新和替换,并有效解决信息的长期依赖问题[3],t时刻LSTM网络单元结构如图1所示。输入门控制信息的传入,遗忘门控制信息的保留和丢弃,输出门根据当前细胞状态,控制有多少信息可作为当前时刻的输出。LSTM网络在t时刻的更新公式为
ft=σ(wf[ht-1,xt]+bf)
(1)
it=σ(wi[ht-1,xt]+bi)
(2)
C′t=tanh(wC[ht-1,xt]+bC)
(3)
Ct=ftCt-1+itC′t
(4)
ot=σ(wo[ht-1,xt]+bo)
(5)
ht=ottanhCt
(6)
式中:xt为t时刻的输入信息;σ为sigmoid激活函数;ht-1与ht分别为t-1时刻与t时刻的隐含层状态;wf、wi、wo和bf、bi、bo分别为遗忘门、输入门与输出门的权重与偏置;C′t为信息经过tanh函数变换后得到的候选状态;C′t中的信息可能被更新到当前时刻的记忆单元中;wC、bC为候选状态的权重、偏置;Ct-1与Ct分别为t-1时刻与t时刻的记忆细胞状态。
LSTM的细胞状态是根据加法门电路实现更新的,反向传播时采用沿时反向传播算法(back propagation through time,BPTT)学习模型中的权重与偏置参数[12]。在反向传播时,根据链式法则,不再进行连乘操作而是进行累加操作,从而避免了随着时间跨度的增加多个趋近于0的数进行连乘或多个大于1的数进行连乘的问题,从而解决了传统循环神经网络中梯度消失或爆炸的问题。

图1 t时刻LSTM网络单元结构Fig.1 t time LSTM network unit structure
长短期记忆神经网络增加门的设置使得网络得以保留关键信息,但是在输入的序列过长时仍旧可能丢失重要信息,因此结合一维卷积神经网络提取特征抓住重要信息,提高预测精度。
1.3 融合注意力机制的权重提取
注意力(Attention)机制[13-15]模仿人类大脑的注意力分配功能,将注意力放在需要关注的重点部分,使得重点区域获得更多的有用信息,是高效的信息选择和关注机制。
标准的长短期记忆神经网络采用的是传统的编码-解码结构,编码器将网络的原序列信息编码成固定长度。虽然长短记忆神经网络的记忆功能能够保存长期状态,但是对于信息量大,信息种类多的非线性煤层气数据,在神经网络的训练时仍旧可能忽略一些重要的时间序列信息,导致模型的预测效果下降。引入注意力机制分配LSTM网络隐含层的概率权重,可使得模型更容易处理长时间序列的依赖关系,克服网络中计算效率低下的问题,提高神经网络的解释性与模型性能。对于煤层气数据,输入序列在不同时间预测点的贡献不同,利用注意力机制分配隐含层概率权重,可突出重要信息对于煤层气产量的影响,增强煤层气产量预测模型的准确性。
2 融合注意力机制的CNN-LSTM煤层气产量动态预测模型
煤层气产量预测是多时序列问题,目标是学习t个时刻的输入值(x1,x2,…,xT)和t时刻的输出值yt之间的非线性关系。本文构建了一种融合注意力机制CNN-LSTM煤层气产量动态预测模型,模型结构如图2所示,主要包括输入层、CNN层、LSTM层、Attention层和输出层,图2中c是将注意力系数αij分配给不同的中间状态hj后的输出。模型由输入层对煤层气生产数据进行输入,利用1DCNN提取煤层气数据的深层特征向量,并将提取的特征作为LSTM网络的输入,提取时间特征并预测,最后融入注意力对LSTM的不同时刻的隐含层向量求权重,再利用全连接层输出。
模型中具体每层的叙述如下。
(1)输入层。对煤层气排采数据进行预处理,删除缺失值,去除噪声并标准化,处理后的数据作为模型的输入。X={Xt-n,…,Xt-2,Xt-1,Xt}为待预测时刻之前的n个多维特征向量。
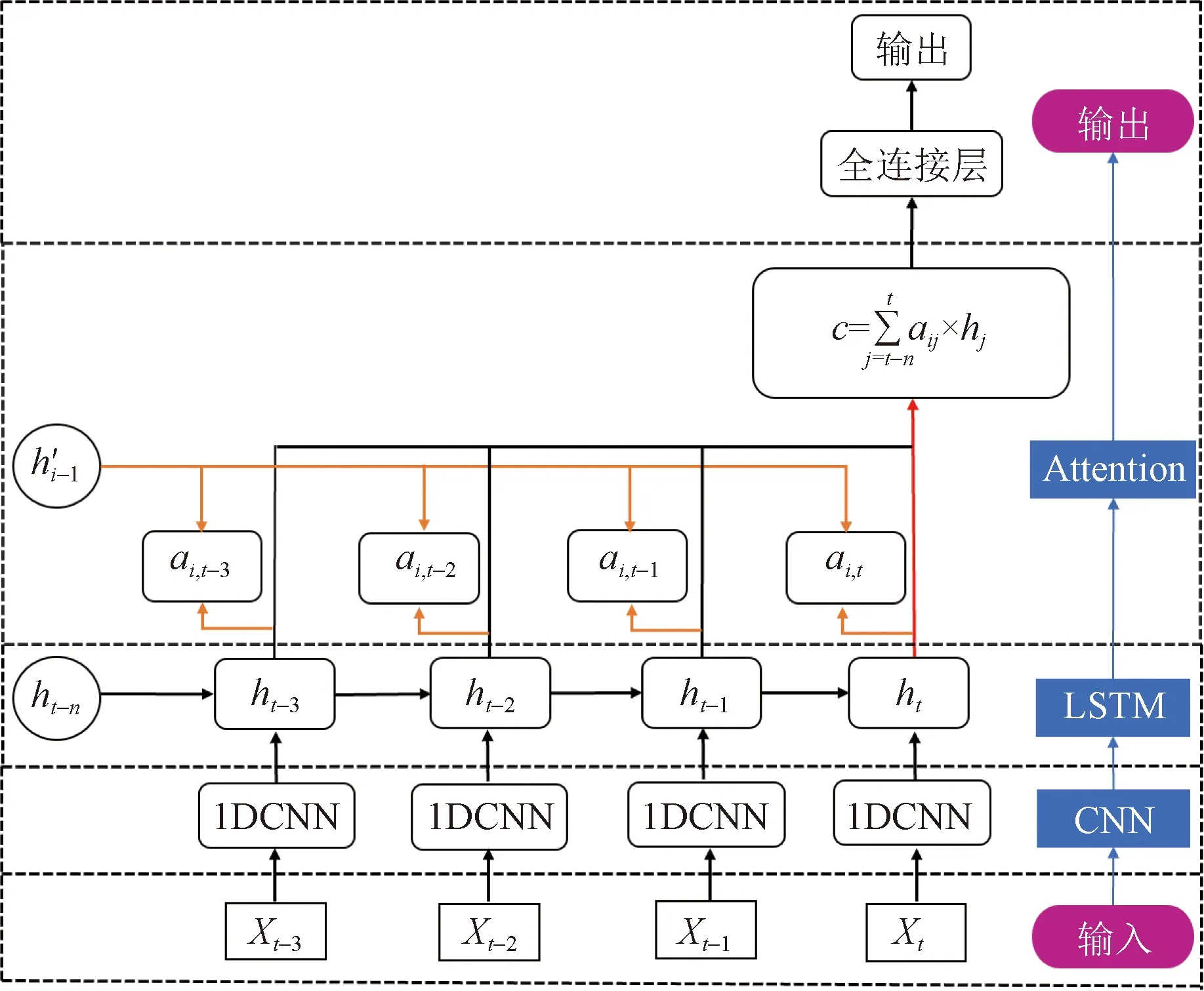
图2 融合注意力机制的CNN-LSTM煤层气 动态预测模型结构图Fig.2 Structural diagram of CNN-LSTM coalbed methane dynamic prediction model integrating attention mechanism
(2)CNN层提取序列特征。将煤层气排采数据输入卷积层中,并通过池化层降维。
N=ReLu(wN⊗X+bN)
(7)
P=max(N)+bP
(8)
式中:N、P为卷积层、池化层的输出;⊗为卷积运算;wN为权重;bN、bP为偏置;ReLu为激活函数。
(3)LSTM层做时序预测,将CNN层输出的向量输入LSTM网络,这里采用双层LSTM网络:
ht=LSTM(Pt-1,Pt)
(9)
式(9)中:ht为LSTM网络的隐含层状态。
(4)Attention层,将ht作为Attention层的输入。计算公式为
eij=utanh(wehj+Ueh′i-1+be)
(10)
(11)
(12)
式中:aij为注意力系数;eij为计算求得的前一时刻隐含层h′i-1和该时刻隐含层hj间的关系分数;eik为t-n时刻到t时刻的关系分数;u、we、Ue为权重矩阵;be为偏置;c为将注意力系数分配给不同的中间状态后的输出。
(5)输出层。将输出的向量转换为1维并输出。即
yt=ReLu(wc+b)
(13)
式(13)中:yt为t时刻煤层气产量的输出;w、b分别为权重、偏置。
3 实例与分析
利用Python3.8编写程序,基于Tensorflow2.6.0框架实现模型,采用Origin进行可视化处理,将处理后的排采数据输入模型,实现煤层气产量预测。
3.1 研究区概况
研究区块位于鄂尔多斯盆地东缘的X区块,开采层位为山西组5号和太原组8号煤层。以5号煤层为例,煤层埋深为700~1 400 m,煤层含气量平均为15.25 m3/t,属于中等偏高含气量煤层[16]。煤层孔隙度在1.90%~4.45%,为低孔隙度。煤层单层厚度2.8~8.5 m,煤层压力6.75~11.5 MPa;煤的密度1.07~1.85 t/m3,平均为1.38 t/m3;煤岩类型主要包括光亮煤、半亮煤和黯淡煤,呈块状、碎块状和粉状,割理、裂隙发育[17]。
3.2 评价指标与标准化
(1)评价指标。采用平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE)展示不同煤层气预测模型的误差。三项指标的计算公式为
(14)
(15)
(16)
式中:f(xi)为煤层气产量的预测值;xi为真实值。若3种误差越小,则产气量预测模型的精度越高。
(2)标准化处理。在煤层气数据采集过程中由于记录数据错误或缺失,设备故障等随机因素的影响,可能存在噪音及异常值。这里选用Z-score标准化方法避免异常值和极端值影响。将每个参数的数据进行以列为单位进行标准化,公式为
(17)

3.3 煤层气产量主控因素筛选
煤层气产量的影响因素复杂,参数众多,主要包括地质参数,工程措施参数和排采工艺参数。地质参数由煤层本质属性决定,工程措施参数是在钻井和压裂工艺产生的参数,两者对于单井而言是固定的,对单井的生产动态数值预测无法产生显著影响。排采工艺参数主要是排采控制中产生的参数。在钻井,压裂过程完成后,排采过程中所产生的井底压力、动液面、套压、冲程、冲次等排采参数成为影响煤层气井产量的主要因素。排采工艺参数大多是具有相同时间间隔且随时间推移不断采样的时间序列数据,可呈现出随时间动态变化的变化趋势,挖掘其中的规律是对时间序列开展的主要研究工作。
不同参数的选取会对模型预测效果产生影响,随机森林可计算每个排采参数在随机森林中的每棵决策树的贡献度平均值,从而进行参数优选[4]。贡献度平均值的选取方法包括基尼指数以及袋外分数,这里选用基尼指数评判贡献度。将排采数据输入随机森林模型中,得出不同参数之间的重要性排序如图3所示。由图3可知,煤层气排采参数的重要性排序为:井底压力 > 动液面高度 > 套压 > 冲次 > 冲程。
(1)井底压力的重要性最高,是整个排水降压过程的核心参数,反映了煤储层压降情况。在合理的排采制度下,井底压力逐渐降低,产气量不断上升,若上升或者下降得过快,容易导致煤粉涌出堵塞渗流通道,影响产气效果[18]。
(2)动液面高度对煤层气产量影响的重要性仅次于井底压力,液柱高度的变化可体现排采强度。
(3)套压可以反映出套管气体的压强情况,在整个煤层气排采过程中,套压在井筒储级效应[18]的影响下,在短时间内会对产气量造成改变。
(4)增大或降低冲次频率可影响排水速率。当冲次频率增大,排水速率加快,但连续增大冲次频率会损害煤储层。
(5)冲程是在保证排量的条件下,尽可能地选择抽油机的最大能力,同一口井的冲程一般维持不变。
由于冲程对产气量的重要性远低于其他参数,因此选择井底压力、动液面高度、套压、冲次作为影响煤层气产量的主控因素。

图3 排采参数的随机森林重要性排序Fig.3 Random forest importance of extortion parameters
3.4 模型训练与验证
根据X区块生产数据统计资料,随机选取JU01井进行模型训练,该统计数据每天记录一次,采样间隔24 h。先对数据进行预处理,剔除空值与异常值。需要注意的是,在排采初期需要将煤储层压力降至临界解吸压力,在此期间产气量的记录数据为0,而其余数据参数波动幅度较大,该阶段数据不具有预测价值,不采用;在排采过程中,由于油管或固定阀漏失,更换举升和抽油设备等问题导致排采数据在一段时间内未被记录或者数据急剧波动的阶段不在本文讨论范围内,作删除处理。最终以2013年2月—2019年2月共2 060 d的数据作为数据集。其中0~1 800 d的数据作为训练集进行模型学习训练,1 800~2 000 d的排采数据作为验证集。在应用于不同生产井时,训练样本的时间序列个数(煤层气井生产天数)对煤层气井特征参数的个数和预测参数的个数无影响。
在处理时间序列问题上,需要划分时间片段构造样本数据集,网络模型可以学习一个时间窗口内的输入与时间窗口大小时刻的输出之间的非线性关系。在模型训练时优化器采用的自适应优化算法(Adam),多次搜索调试后,将初始学习率设为0.001 55。通过在适当范围内调整参数并不断试算最终确定模型参数,其中输入尺寸(input_size)为5,批次大小(batch_size)设为40,时间步长(time_step)设为15,喂入数据的形状为(40,15,4)。CNN层的采用一层卷积层、一层池化层,卷积核设置为4个,池化窗口大小(pool_size)设为2,池化操作的移动步幅(strides)设为1,字符串(padding)为‘same’。LSTM层中,采用双层LSTM,隐含层节点个数设为7。
经超参数调试后,计算JU01煤层气井的日产气量,训练集损失函数下降曲线如图4所示,损失函数利用均方误差(mean-square error, MSE)表示。
通过迭代后,模型在训练集上的1 800个样本拟合值的平均相对误差为6.10%,在验证集上预测200个样本的平均相对误差为5.11%。JU01井训练集与验证集日产气量实际值与计算值对比如图5所示,通过模型训练后的日产气量计算值与实际日产气量与对比,二者趋势一致,说明模型具有良好的拟合效果。

图4 JU01井训练集损失函数下降曲线Fig.4 JU01 well training set loss function falling curve

图5 JU01井日产气量实际值与计算值对比Fig.5 The actual value and calculation value of JU01 well daily methane volume
3.5 模型预测对比分析
为了验证模型的有效性,结合标准的LSTM模型、无注意力机制的CNN-LSTM模型、随机森林回归模型(random forest regression,RFR)、高斯过程回归模型(gaussian processes regression,GPR)与本文模型做对比,预测JU01井未来60 d和200 d的产气量。不同模型产气量预测对比如图6所示,图6(a)和图6(b)分别为预测60 d和预测200 d对比图,不同模型预测日产气量效果对比结果如表1所示。
由图6可知,随机森林回归模型与高斯过程回归模型的预测曲线较实际生产曲线偏差较大,标准LSTM模型在实际生产曲线附近波动较为明显,无注意力机制CNN-LSTM模型较标准LSTM模型预测曲线波动有所改善,而融合注意力机制的CNN-LSTM煤层气产量动态预测模型的预测趋势与实际生产曲线最为贴近,更符合实际生产情况。
由表1可知,在相同预测天数下,随机森林回归模型的预测误差低于高斯过程回归模型,但两者的误差都高于标准的LSTM模型。融合注意力机制的CNN-LSTM煤层气产量预测模型,MAE误差、RMSE误差和MAPE误差均最低,比标准的LSTM模型的预测精度提高了3%~4%,并且增加了CNN提取特征后的无注意力CNN-LSTM模型比传统LSTM模型预测精度也有所提高。可见在长短期神经网络中引入一维卷积神经网络提取特征并融合注意力机制,加强了神经网络的预测效果,提高了预测精度。随着煤层气产量预测天数的增加,3种模型的MAE误差、RMSE误差和MAPE误差均逐渐增大,即3种模型的预测精度都有所下降,但经过对比可知融合注意力机制CNN-LSTM模型预测误差仍然最低。
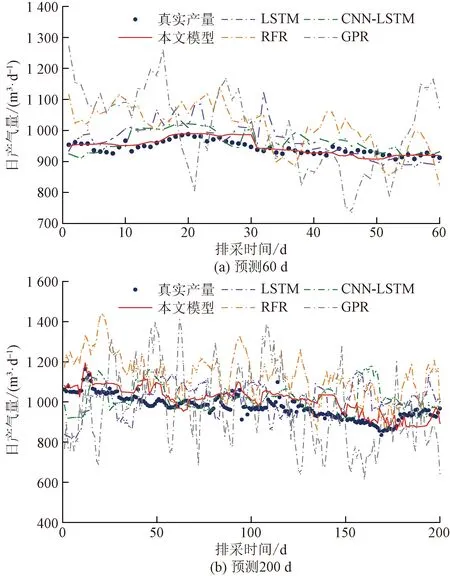
图6 不同模型的日产气量实际值与预测值对比Fig.6 Actual value and predictive value of nissan quality of different models

表1 不同模型预测日产气量效果对比Table 1 Different models predict a comparison of daily methane content
3.6 模型的复杂度分析
模型的复杂度包括模型的时间复杂度和空间复杂度,时间复杂度可用模型的训练时间和浮点运算次数(floating point of operations,FLOPs)[19-20]表示,空间复杂度可用参数量表示,关于模型的算法复杂度对比实验结果如表2所示,实验数据集采用JU01井的数据。
由表2可知,融合注意力的CNN-LSTM模型在训练时间、浮点运算次数与参数量上与无注意力的CNN-LSTM模型与差别不大,但两者对比传统的LSTM均有所提升,但提升较小,在可接受范围内。而融合注意力的CNN-LSTM模型比无注意力的CNN-LSTM模型精度提升了2.05%,比传统的预测精度提升了4.67%,由此可说明融合注意力机制的CNN-LSTM模型的复杂度问题可不考虑。

表2 模型复杂度对比实验结果Table 2 Model complexity comparison experimental results
3.7 模型的适用性分析
除了JU01井以外,对同一区块其他6口生产天数与产能不同的煤层气井也做了日产气量预测以验证模型的适用性。进行适用性分析时,模型基本参数不变,若对不同区块,不同生产井的相关参数进行自适应调整,可使模型预测误差降低。随机选取了该区块生产天数介于700~3 100 d的6口的煤层气井预测未来60 d与200 d的煤层气产量,预测结果如表3所示。由表3可知,6口井预测60 d产气量的平均相对误差均小于5%,综合6口井的误差平均为2.71%;预测200 d产气量的平均相对误差均小于8%,综合6口井的误差平均为5.86%。可见,融合注意力机制的CNN-LSTM煤层气产量动态预测模型具有良好的适用性。
在实际生产中,也需要注意煤层气的月产量,因此以JU01井为研究对象,将煤层气排采数据以月为单位放缩,得到68个月的煤层气生产数据,预测15个月的煤层气平均产量,结果如表4所示,平均相对误差为4.94%,在可接受范围内。

表3 X区块不同井的煤层气产量预测结果对比Table 3 Comparison of coalbed methane production prediction results of different wells in X block
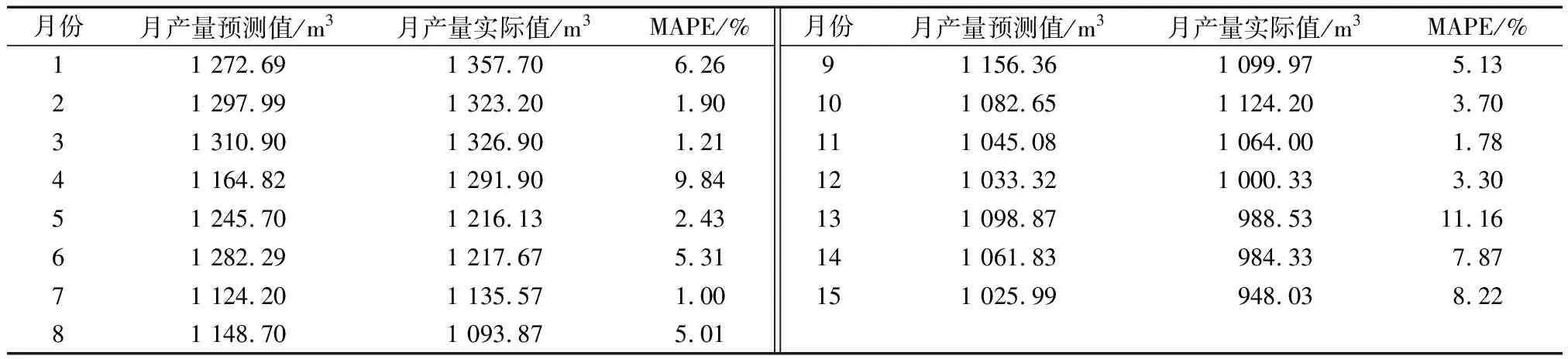
表4 煤层气月平均产量预测结果表Table 4 Prediction results of monthly average production of coalbed methane
4 结论
(1)利用随机森林变量筛选模型优选出影响X区块煤层气产量的主控因素,变量的重要性排序为:井底压力 > 动液面高度 > 套压 > 冲次 > 冲程,最终确定主控因素为:井底压力、动液面高度、套压、冲次。在煤层气排采过程中应合理控制井底压力、动液面高度、套压,选择适合的冲次频率。
(2)建立融合注意力机制的CNN-LSTM煤层气产量动态预测模型,用1DCNN高效的特征提取优势,挖掘更多有用信息,将提取的时序向量作为LSTM网络的输入,有效解决信息长期依赖性和信息丢失,对LSTM的隐含层融合注意力机制,突出重要信息。实验表明:融合注意力机制的CNN-LSTM煤层气产量预测模型具有良好的拟合和预测效果,比标准的长短期记忆神经网络的预测精度提高了3%~4%,并且复杂度区别较小,更符合实际生产情况。
(3)对产气量模型做适用性分析,计算同一区块6口生产天数与产能不同的煤层气井日产量,6口井预测60 d产气量的平均相对误差均小于5%,200 d产气量的平均相对误差均小于8%。进行月平均产量预测时,平均相对误差为4.94%。分析表明,融合注意力机制的CNN-LSTM模型各方面均表现较优。
