基于关联系数网络的电表异构信息提取方法
2023-02-27廖家威周勇方夏王玫罗彬豪朱高义
廖家威, 周勇, 方夏, 王玫, 罗彬豪, 朱高义
(四川大学机械工程学院, 成都 610065)
随着社会经济快速发展,用电信息采集普及,电网规模不断发展,电网公司管理的智能电表数量飞速增长,四川省目前在运行的智能电表数量超过3 200万。自2019年起,每年有大约300万只各种厂家和型号电表因故障、功能性升级和更换、政策变化等情况而需要拆除回收和进行数据提取及建档管理。拆回电表的射频识别(radio frequency identification, RFID)可能失效,因此不能直接检测RFID录入电表信息,而人工分拣电表面临人力物力不足,准确性和效率不足,安全管控难等问题。
在电力领域,机器视觉和人工智能已得到广泛应用,如输电线路巡检[1-2]、设备维护[3]、电力仪器仪表读数[4]等,而实现拆回电表自动分拣的关键是自动提取电表的厂家和型号信息。文献[5-6]通过传统图像处理、文本分割获取单个文本再使用分类器识别的方法提取电表信息,然而其研究的电表类别少,不能涵盖多种布局的电表,且关键参数需要手动设置,难以广泛应用。近年来深度学习飞速发展,在文本检测和识别方面取得很多成果。连接文本提议网络[7](connectionist text proposal network,CTPN)能学习大量数据获得高鲁棒性,准确定位文本。密集连接卷积网络[8](dense convolutional network, DenseNet)和连接时序分类(connectionist temporal classification,CTC)算法能识别整行文本,避免文本分割带来的误差累计,文献[9]融合以上算法成功检测作业现场设备的铭牌信息。
识别厂家文本或检测厂家商标都能提取厂家信息,而商标具有类内差异小,类间差异大,和信息密度大的优势,因此应通过检测商标提取厂家信息。常用目标检测网络有Faster-RCNN[10](faster-region convolutional neural network)、SSD[11](single shot multibox detector)和YOLO[12-14](you only look once)系列,但以上网络模型复杂,参数量大,存在算力过剩的问题,而YOLOv4-Tiny[15]作为YOLOv4的简化版,参数量更小,已被广泛应用[16-19]。
上述型号文本识别和商标检测方法相互独立,忽略了电表型号的设计代号与厂家唯一对应这一信息关联。而文献[20]基于视觉语义关联,将中文语言的语义关系融合至卷烟零售终端店招牌文字和许可证文字识别的模型中,取得了良好识别效果。
综上所述,为准确提取拆回电表厂家和型号信息,基于关联系数网络的电表异构信息提取方法,现利用型号与厂家之间的语义关联进行关联识别,与主流方法相比具有更高的准确率,能够应用于拆回电表的自动化流水线分拣,促进电表管理的智能化发展。
1 识别对象
拆回电表的型号文本、商标、厂家文本位置如图1所示。电表型号由类别代号、组别代号、设计序号、派生号构成,以“DDZY71C”和“DDZY71C-Z”为例,第一个D为类别代号,代表电表;DZY为组别代号,3个字母分别代表单相、智能型、预付费;71为设计代号,与某厂家对应;C-Z和C为派生号,C表示CPU卡费控,-Z表示载波通信。同一厂家的电表的派生号可能不同,但设计代号相同。
由图1可知,拆回电表存在3种布局,型号文本可能在上、中、下3个区域,且缺少明显的参照物,导致型号文本定位困难。而厂家和型号众多,使电表字体差异大,部分字体间距不一,导致投影法、联通域法等传统图像处理方法不能准确分割文本。如图2所示,部分拆回电表存在模糊、签字笔笔划、遮掩等干扰因素,导致难以直接识别型号文本。

图1 拆回电表图像Fig.1 Images of dismantled electric meter

图2 存在干扰因素的电表型号图像Fig.2 Images of electric meters’ model with interference factors
2 识别方法
如图3所示,文中方法主要包括型号初步识别、厂家商标初步识别、关联识别3部分,其中关联识别部分的关联系数利用验证集进行测试的方式自适应获取。
2.1 CTPN-DenseNet-CTC型号初步识别
2.1.1 CTPN文本定位
CTPN之前的文本检测和定位方法通常自上而下,首先检测低级字符(如单个字母)或笔画,随后进行非文本过滤、文本行构造及验证等后处理,这些方法复杂且鲁棒性差、可靠性低。CTPN借鉴了Faster-RCNN的锚框,使用了宽度为16像素而高度可变的垂直锚框。
CTPN模型的计算步骤如下。
步骤1使用VGG16主干网络对输入图像进行特征提取,将大小为C×H×W的conv5_3卷积层作为特征图输出,其中C、H、W分别为特征图通道数、高和宽。
步骤2在特征图上用3×3的窗口做滑窗,将3×3的窗口区域拼接为1×9的向量,得到9C×W×H的特征图。
步骤3对特征图调整维度至H×W×9C,输入双向长短期记忆网络(bi-directional long short-term memory, BiLSTM),得到长度为H×W×256的特征向量,并调整维度至256×H×W,然后连接长度为512的全连接层。
步骤4经过类似于Faster-RCNN的区域提议网络生成k个文本提议锚框,每个锚框的信息包括

图3 总体流程Fig.3 Overall flow chart
中心y坐标值、高度、有和无文本的概率分数、水平偏置量。
步骤5使用非极大值抑制过滤多余锚框。
步骤6将得到的多个锚框合并为文本行。
CTPN的损失函数为

(1)

2.1.2 DenseNet-CTC文本识别
DenseNet模型借鉴了ResNet[21]“连接跳跃”的思路,ResNet和DenseNet的公式分别为
Xl=Hl(Xl-1)+Xl-1
(2)
Xl=Hl([X0,X1,…,Xl-1])
(3)
式中:Xl为第l层的输入;Hl(·)为非线性转换结构,包括卷积、批标准化、激活及池化等操作。
由式(2)和式(3)可知,ResNet将上一层和再上一层输出通过非线性变换结构后一起输入到下一层,而DenseNet将每层都与后面所有层连接。图4为DenseNet的基本组成部分Dense_block的结构示意图,可知,L个特征层之间有L(L+1)/2个连接通道,网络结构稠密,减轻了梯度消失,增强了特征传播和特征重用性。
DenseNet-CTC模型结构如图5所示,激活函数为ReLU激活函数,使用3个Dense_block模块提取特征,每个Dense_block模块有8层特征层,特征层之间共有36个连接通道,Dense_block模块之间为过渡层,通过1×1卷积、2×2平均池化改变特征层维度以满足Dense_block模块的输入维度要求。将经过Dense_block模块得到的特征图经过一次卷积后重新排列维度并展平,再经过全连接层和Softmax分类器后得到维度为60×31的概率向量,60表示将图像沿水平方向60等分,31为字典大小,表示每1/60对应图像是字典中所有文本的分类概率。
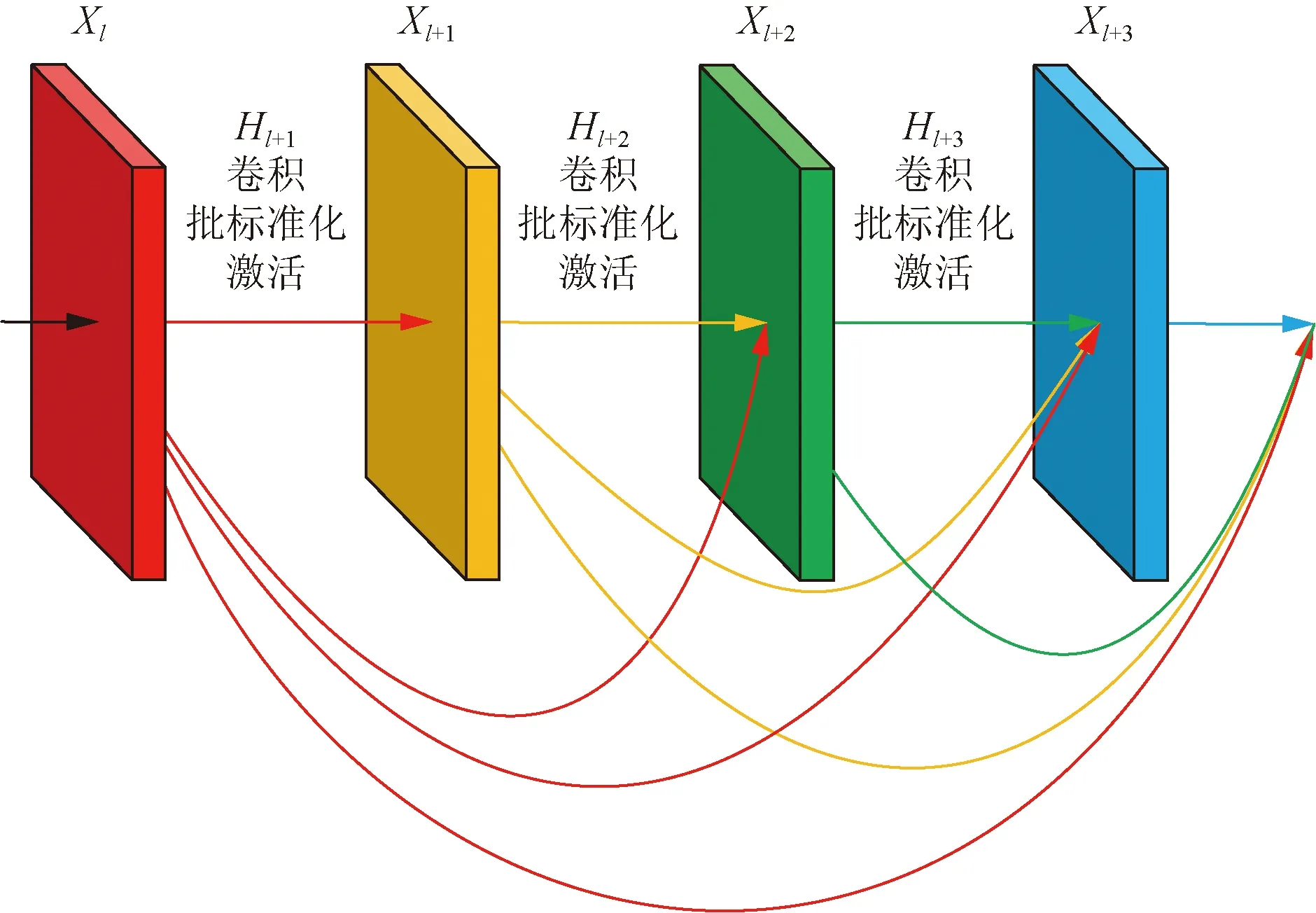
图4 Dense_block结构示意图Fig.4 Schematic of dense block

图5 DenseNet结构Fig.5 Structure of DenseNet
概率向量需要转录为文本,CTC损失函数可解决不定长时序数据分类问题。转录前概率向量的长度大于输出文本的长度,因此转录后的文本序列存在重复现象,如all对应概率向量可能转录为a-a-l-l-l-l,直接删除重复文本会误识别为al,为解决此问题,CTC引入占位符,该占位符在去重后删除,all对应概率向量转录结果可能为a-a-l-l--l-l-l-,去重后删除占位符就能得到正确结果all。
CTC损失函数将DenseNet生成的概率向量转录为文本序列,输出长度为T的文本结果。
2.2 YOLOv4-Tiny厂家商标初步识别
利用YOLOv4-Tiny检测电表商标从而提取厂家信息。YOLOv4-Tiny的结构如图6所示,与YOLOv4相比,YOLOv4-Tiny在特征提取、特征融合、特征输出等方面均做了简化。
YOLOv4-Tiny的主干网络为CSPDarknet53-Tiny,由YOLOv4主干网络CSPDarknet53轻量化而来,包含21个卷积层、3个最大池化层,激活函数为LeakyReLU。CSPDarknet53-Tiny中有3个Resblock模块,结构如图7所示,包括跨阶段部分(cross stage partial, CSP)结构和最大池化层,经过1次卷积后,分离特征图的通道,取第二部分(通道数已减半)进行卷积和残差计算,最后使用最大池化压缩尺寸。Resblock模块中有2个残差计算以加强特征提取能力并重复利用特征。第3个Resblock模块的第4个卷积层输出大小分为26×26的特征图,最大池化层的输出再经过一次卷积输出大小为13×13的特征图,用特征金字塔(feature pyramid networks, FPN)对2个特征图进行特征融合,然后输入到2个检测头(YOLO Head)进行目标框的预测和目标的分类,输出目标类别、位置和置信度。

图6 YOLOv4-Tiny结构Fig.6 Structure of YOLOv4-Tiny

图7 Resblock_body结构Fig.7 Structure of Resblock_body
2.3 关联识别
电表型号的设计代号和厂家唯一对应,利用此信息关联可以对型号文本和厂家商标两种不同结构的信息进行关联识别,具体步骤如图3关联识别部分所示。
对于型号文本识别结果、商标检测结果(商标类别和置信度)以及关联系数,分如下4种情况。
(1)商标检测结果和型号文本识别结果匹配(商标对应厂家和型号中设计代号对应厂家一致),则直接输出商标对应厂家和型号初步识别结果。
(2)商标检测结果和型号文本识别结果不匹配,商标识别置信度高于关联系数,则假设商标识别正确,校正型号的设计代号,输出商标对应厂家和校正后的型号。
(3)商标检测结果和型号文本识别结果不匹配,商标识别置信度低于关联系数,而存在设计代号对应厂家,则假设型号识别正确,输出型号初步识别结果和设计代号对应厂家。
(4)商标检测结果和型号文本识别结果不匹配,商标识别置信度低于关联系数,且不存在设计代号对应厂家,则型号识别结果和商标检测结果矛盾且都不正确,输出“无法识别”。
上述4种情况下正确提取电表信息或判断为“无法识别”的概率为式(4),关联识别前后正确提取电表信息的概率分别为
(4)
PPI=P1
(5)
PCI=P1+P2+P3
(6)

关联系数应合理选取,若选择过低,则商标置信度很容易高于关联系数,不能区分出错误识别的商标并错误地修改原本识别正确的型号文本信息;选择过高,则商标置信度难以高于关联系数,会将置信度稍低商标标识别正确的电表信息错误提取,或者导致输出“无法识别”。
关联系数在验证集进行测试获得。设定关联系数初始值c0为0.9,初始步长Δc=0.1。训练100个回合,前70回合不进行关联识别验证,之后每回合训练后根据在验证集上测试结果进行调整以自适应地获取到合适的关联系数。测试方法如下:在第i回合,比较ci-Δc、ci和ci+Δc作为关联系数在验证集的测试结果,取准确率最高的关联系数(若相等,则取较大的关联系数)作为ci+1下回合进行测试,每过5回合Δc减半,通过此方法自适应获取合理的关联系数,不需要手动设置。
3 实验与结果分析
数据集为电网公司电表回收机构的拆回电表图像,图像宽高为1 929×2 654像素,选择45个电表数量大于600的厂家,每个厂家随机选600张拆回电表照片,标注其厂家商标和型号,按4∶1∶1比例划分,得到数量分别为18 000、4 500、4 500的训练集、验证集、测试集。
模型训练和测试环境配置如下:操作系统为Windows10 64位系统,Intel CPU i5 7500,主频3.4 GHz,内存16 G,GPU为RTX2080Ti,Pycharm集成开发平台,Python版本3.6,框架为TensowFlow,版本为tensorflow-gpu1.12.0,OpenCV版本为4.1.2.30。
3.1 CTPN-DenseNet-CTC型号初步识别
3.1.1 CTPN型号文本定位
图8所示为CTPN网络的文本框检测结果,可知,CTPN能准确定位电表上的文本。
得到一系列文本框的位置后,设置长宽阈值过滤无关的符号、图案,再对文本框中心高度排序,得到型号文本框。调整图像角度保证文本框水平后剪裁获得型号文本图像。将型号文本图像按原比例缩放至长宽分别为480、32像素(不足480或32的方向用灰色填充)以满足DenseNet-CTC的输入要求,然后使用DenseNet-CTC识别。

图8 CTPN文本定位Fig.8 CTPN text localization
3.1.2 DenseNet-CTC型号文本识别
目前另一种主流的基于深度学习的文本识别模型是卷积循环神经网络(convolutional recurrent neural network, CRNN)[22]。CRNN在使用CNN提取特征后,使用BiLSTM循环网络进行时序训练得到概率向量,最后输入CTC损失函数进行不定长序列识别。将CRNN-CTC和DenseNet-CTC应用于测试集的结果作对比,如表1所示,可得DenseNet-CTC精度更高。
CRNN-CTC的误识别集中在序列,如DDZY88C误识别为DDZY566C、DDZY699C(存在设计代号566、3699的电表)。原因以下3点:①CRNN中,CNN特征提取能力不足,且加入BiLSTM,使模型更加关注文本的上下文关系,依靠推断进行识别;②文中识别对象为型号文本,识别关键是设计代号和派生号,与型号文本其他部分无上下文关联,而设计代号自身最多4个文本,文本之间关联性不强,不适合通过推断进行识别;③这种整行文本识别的方式在每个位置识别的对象可能是半个字符,且与其他字符片段相似,使该位置识别为那相似字符的概率增大,下一个位置同理,如果这段可能错误的文本序列恰好属于某设计代号,则可能误识别(如代号8识别为代号56或69)。而DenseNet不依靠上下文关系,且通过特征层之间稠密连接的方式增强了特征提取能力,更专注于识别某位置本身的文本,因此DenseNet识别精度更高。

表1 文本识别模型性能对比Table 1 Performance comparison of text recognition models
3.2 YOLOv4-Tiny厂家商标初步识别
将YOLOv4-Tiny和其他主流目标检测算法,包括Faster-RCNN、SSD、YOLOv3、YOLOv4、YOLOX,应用于测试集,以准确数、推理速度(frame per second, fps)、模型参数量为评价指标比较检测结果,如表2所示。从表2可知,6种模型准确率接近且超过99%,原因在于与一般目标检测任务相比,商标检测难度更低,体现在以下4点:①每张电表图片只有一个商标;②商标无遮掩,且即使商标出现部分污损,图像特征仍比较明显;③同种商标无形态、尺度变化,且位置变化小;④不同类别的商标差异大。这种情况下,除了评价模型的准确率,还应关注模型的获得高准确率的成本,包括每秒钟检测的帧数(fps)和计算资源成本(模型参数量),而YOLOv4-Tiny的推理速度比其他模型更快,参数量比其他模型更少,因此选择YOLOv4-Tiny模型检测拆回电表的商标。

表2 不同目标检测模型对比Table 2 Comparison of different target detection models
3.3 关联识别
虽然YOLOv4-Tiny检测厂家商标准确率达99.60%,但型号识别的准确率仅为97.16%,而只有型号和厂家同时识别正确才能正确提取电表信息,关联识别前信息提取准确数为4 354,准确率为96.75%,对于每年数量达到300万的拆回电表,仍会有大约10万只电表的信息提取错误,因而仍然需要提高提取准确率,减少误提取。本文研究基于电表型号和厂家之间的信息关联进行关联识别以提高提取准确率,降低误提取率。
利用型号文本和厂家信息初步识别结果和利用测试集自适应学习得到的关联系数进行关联识别,将得到结果与对3.1节和3.2节中的识别方法的结果作对比,如表3所示。由表3可知,文中方法提取准确率最高,且关联识别将电表信息提取准确率从96.75%提升至98.71%,使误提取率降低60.31%,可将信息被误提取的电表数量从10万降低至4万左右。
同时,挑选出测试集中的852张污损照片进行测试,结果如表4所示,可知针对污损电表,所提方法提取准确率达93.31%,相比其他方法,能更有效提取电表信息。
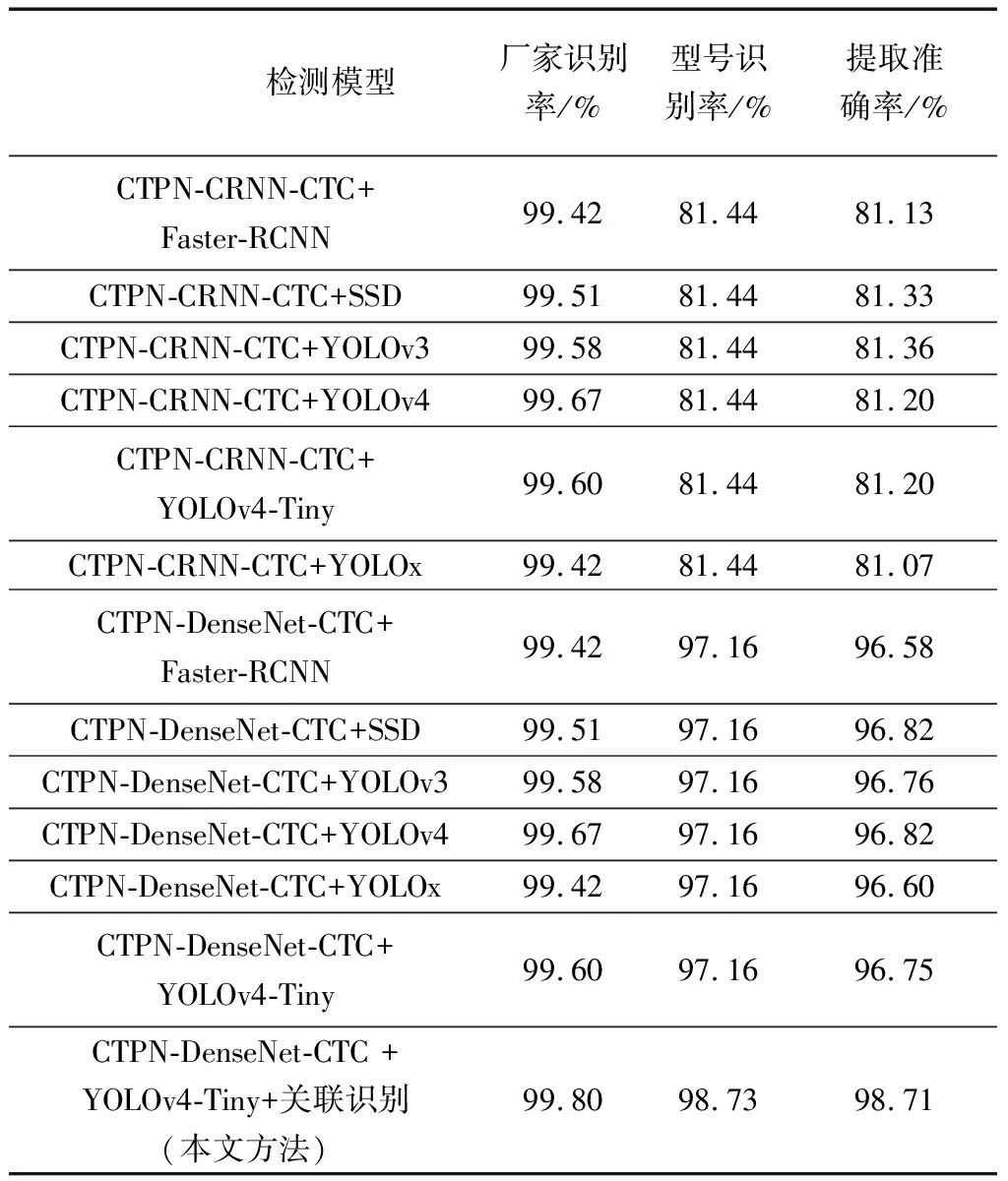
表3 测试集上识别结果Table 3 Identification results on the test set
3.4 识别速度
表5所示为识别一张拆回电表图像的型号和厂家信息的平均用时,可知,识别平均耗时0.406 s,其中大部分时间花费在CTPN型号文本定位阶段,DenseNet-CTC和YOLOv4-Tiny耗时较少。
4 结论
针对拆回电表信息识别所面临的布局不一、字体不一、存在污损的问题,提出了一种基于改进关联系数神经网络,提取电表的厂家和型号信息。与主流文本识别和目标检测算法应用于拆回电表数据集作对比后得到如下结论。
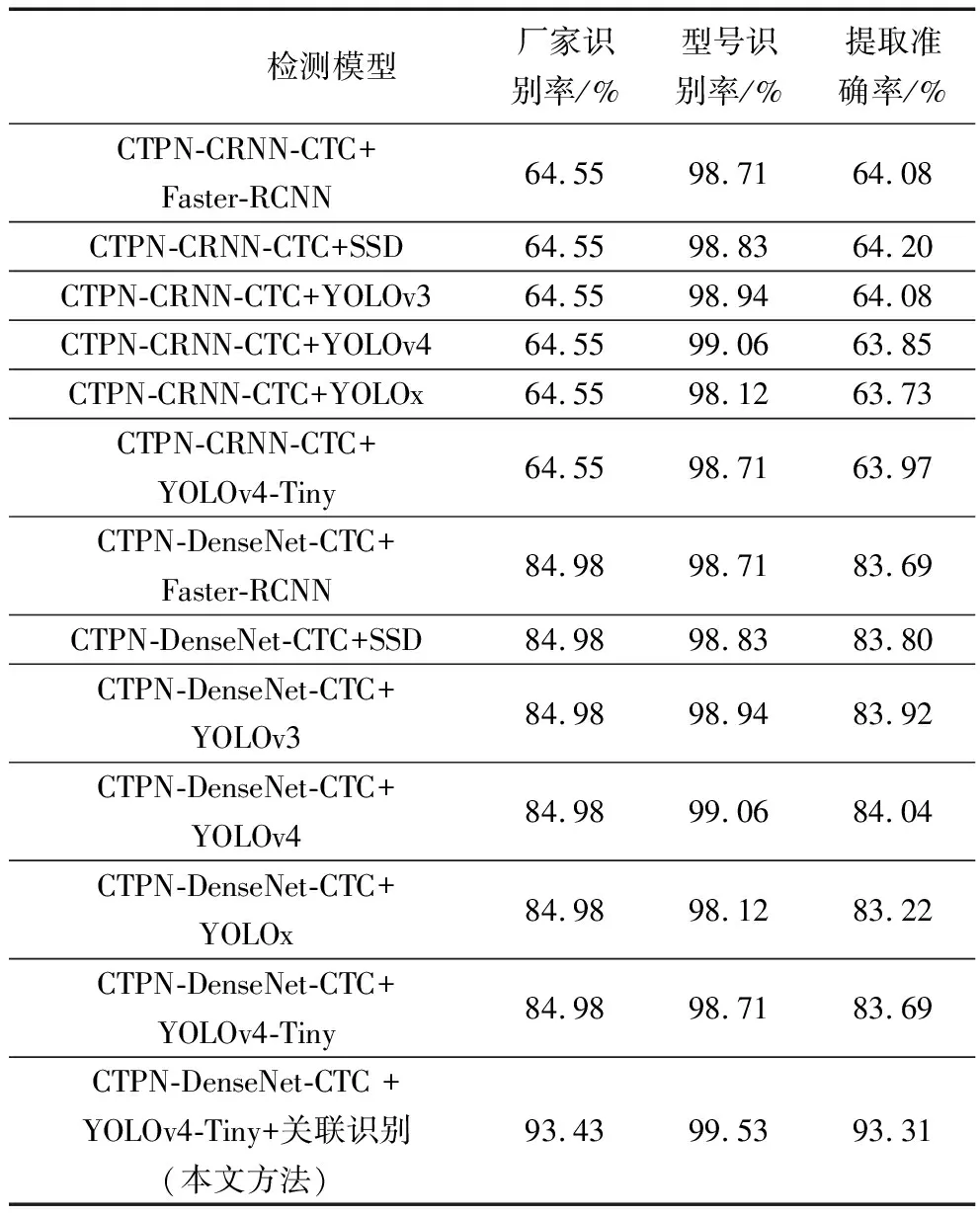
表4 污损样本识别结果Table 4 Identification results of stained samples

表5 单张图片识别用时Table 5 Time-consuming to identify a single image
(1)CTPN能克服电表布局不一的问题,准确定位型号文本。比较CRNN-CTC和DenseNet-CTC的识别结果和错误识别样本可知,对于此类长度小、自身关联性弱的文本识别任务,DenseNet精度更高。
(2)检测商标是可行且简单的获取厂家信息的方法,且使用轻量化的目标检测网络就能准确识别,从而节约算力资源。
(3)选择合理的关联系数进行关联识别能有效提高电表信息提取的准确率,降低误提取率,针对拆回电表,能将误提取率降低60.31%,对于每年300万只拆回电表,误提取数能从10万降至4万。
