面向不平衡数据集的SMOTENC-XGBoost驾驶人交通安全评估模型
2023-02-25王博文王景升吴恩重
王博文, 王景升*, 吴恩重
(1.中国人民公安大学交通管理学院, 北京 100038; 2.中国人民公安大学治安学院, 北京 100038)
中国的道路交通事故发生率及伤亡率一直处于很高的水平。据中华人民共和国交通事故统计年报显示[1],中国在2019年共发生道路交通事故1 247.3万起,造成62 763人死亡、256 101人受伤,直接财产损失达13.5亿元。挖掘交通事故致因因素,并采取针对性的整治是降低道路交通事故发生率的重要手段。
当前,中外许多学者针对交通事故致因因素进行了研究[2-4]。王旭磊等[5]从系统安全出发,探索了公路运输交通事故的致因因素,实验证明,驾驶人的安全意识不足、操作不当是主要致因因素。贾晓惠等[6]利用贝叶斯网络研究了环境因素对于公交车事故的影响,结果证明,天气、时间等因素均可能导致交通事故。林庆丰等[7]使用Logistic回归分析了机非交通事故中驾驶人、车辆、道路因素对驾驶人过错及事故严重程度的影响。张圆等[8]依据广东省9 886条小轿车交通事故数据,定量分析了不同性别小轿车驾驶人的交通事故影响因素,其中包含了驾驶人固有属性因素,如年龄。Bucsuházy等[9]通过对捷克事故数据进行研究,分析了交通环境、车辆和人为因素对交通事故的影响。
此类研究仅从驾驶人固有性质,如年龄、驾龄,或道路环境因素对事故的致因进行研究。但是,交通事故的发生往往与驾驶人历史交通行为的优劣,如驾驶人是否有酒驾、疲劳驾驶等存在安全隐患的重点驾驶行为经历存在联系,因此在研究交通事故致因因素时,应将驾驶人的历史交通行为维度同时纳入研究范围[10-17]。
除此之外,在模型建立及分析过程中还存在以下问题。
(1)大多数研究忽视了交通事故的发生与否是天然的不平衡现象,获取的数据集往往存在严重的数据不平衡问题。此类研究在进行数据预处理时,并未对存在的数据不平衡问题进行解释和解决,在进行模型的评价时,也仅使用准确率作为模型效果优劣的评价指标,忽视了模型能够将少数类个体正确识别的重要性,导致模型无效且泛化能力较低。
(2)此类研究在进行建模时多使用Logistic回归模型对数据进行拟合,而Logistic回归属于天然的欠拟合模型,在对数据的分类处理能力上不及随机森林(random forest, RF)、支持向量机(support vector machine, SVM)、极端梯度提升(extreme gradient boosting, XGBoost)等模型。
基于上述分析,从输入维度和算法两方面进行改进,现构建一种面向不平衡数据集的驾驶人交通安全评估模型,为相关部门进行识别交通隐患个体提供了数据支撑。对于输入维度的改进:本文研究将从驾驶人固有性质因素、驾驶人交通行为因素两个维度对相关的14个特征进行分析。在算法改进方面,充分考虑该任务中存在的严重的数据不平衡现象,使用SMOTENC算对该问题进行解决,并且构建基于不平衡数据构建XGBOOST模型,与回归树(decision tree, DT)、RF、SVM一同作为消融实验的对照组,用以检验模型效果。
1 相关技术
1.1 XGBOOST算法
XGBOOST是一种由多个CART分类树组成的BOOSTing类型的集成算法。相比于传统的GBDT算法,XGBOOST算法对损失函数进行二阶泰勒展
开,使用一阶导数信息及二阶导数信息共同决定损失函数,提高了模型的收敛速度;在损失函数中加入了正则项,用来控制模型的复杂度,防止过拟合情况出现;实行多线程并行计算,极大提升了模型的训练速度和分类精确度。
定义XGBOOST算法的目标函数为
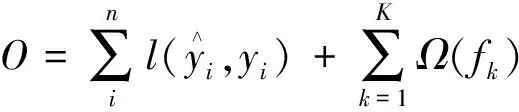
(1)
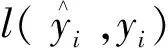
模型复杂度的惩罚项为
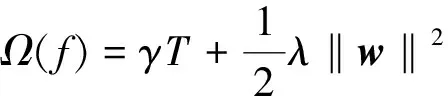
(2)
式(2)中:γ为节点切分的难度;λ为L2正则化系数;||w||为叶节点权重向量的模。
为避免过拟合现象,新生成的树需要对上一次预测的残差进行拟合,并通过迭代进行更新,第t轮学习输出的预测结果表示为

(3)

(4)
式中:当F={t(x)=wq(x)}、w∈RT时,为模型的预测结果;为前一轮模型的预测值;k(xi)为第k棵回归树的预测值;t(xi)为参数函数;xi为第i个样本的特征;wq(x)为叶子节点q的预测值;T为回归树叶节点的个数;RT为第T个叶子结点权重w的空间。结合式(1)和式(2)将目标函数使用二阶泰勒展开,并将常数项移出,得出目标函数的近似公式为

(5)

定义Ij={i|q(xi)=j}为叶子节点j的实例集,由式(6)将目标函数转化为

(6)
式(6)中:wj为叶子节点j的权重。
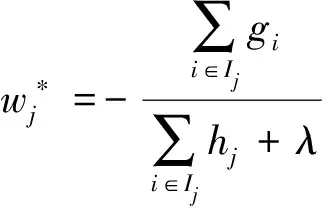
(7)
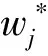

(8)
使用贪心算法迭代地对现有叶子结点添加分支,假设IL和IR分别为划分后左、右子树叶子结点的集合,I=IL∪IR,划分后的损失函数为

(9)
1.2 SMOTENC算法
用于处理数据不平衡问题的SMOTENC算法是过采样算法SMOTE的改进算法,可以分别处理连续数据及离散数据,处理流程可表示为如下过程。
(1)对于标签中占比较少一类的每一个样本(x1,x2),计算该样本在多维空间中与其他标签中占比较少的一类样本点之间的距离,获取该样本最近的k个邻近点(即对标签中占比较少一类的样本点做KNN算法)。
(2)由样本标签各类的比例拟定采样倍率,对于所有标签中占比较少的一类样本点,从其k个邻近点里随机选取一些样本,记为(x′1,x′2)。
(3)对于连续数据,对每一个上述步骤中选出的邻近样本,根据式(9)合成新样本:
(X1,X2)=(x1,x2)+rand(0,1)×Δ
(10)
式(10)中:rand(0,1)为0~1的随机数;Δ={(x′1-x1),(x′2-x2)}。
(4)对于离散数据,选取近邻样本中出现频率最高的离散数据作为新的样本值。
2 SMOTENC-XGBOOST模型
基于SMOTENC-XGBoost的驾驶人交通安全评估模型的建立流程为:①根据相关文献研究和专家访谈结果对变量进行选取;②通过问卷调查对数据进行获取;③对数据集中存在的缺失值进行填补;④选定因变量与自变量;⑤对基于平衡数据集建立的模型采用SMOTENC算法,对数据进行上采样并在采样过程中加入随机扰动(在基于不平衡数据集建立的对照组模型的数据预处理阶段则不进行此步骤);⑥使用Embedded算法结合L1正则化,通过模型评估完成对特征子集的选择,使模型自动筛选出能够使模型准确率较高的特征;⑦建立Logistic回归模型,通过获取的权重得到自变量对因变量的影响关系、自变量之间的效用关系、自变量各个取值之间的效用关系;⑧使用Python语言,基于平衡数据集建立XGBoost模型,并将基于平衡数据集建立的Logistic回归、DT、RF、SVM及基于不平衡数据集建立的XGBoost作为对照组;⑨对比XGBoost、Logistic回归、DT、RF及SVM模型,验证XGBoost模型在驾驶人交通安全评估任务上的有效性;⑩对比基于不平衡数据集建立的XGBoost,验证采用SMOTENC算法对样本进行平衡的有效性。
其中,第①~②步用于确定研究变量,获取数据;第③~⑤步为数据预处理阶段,用于对缺失值,不平衡现象进行处理,将数据整理为模型能够接受的数据格式;第⑥步为特征选择阶段,用于筛除无关变量及冗余变量;第⑦步用于通过获取的权重描述自变量对因变量的影响关系、自变量之间的效用关系、自变量各个取值之间的效用关系;第⑧步建立模型;第⑨步用于验证XGBoost模型在驾驶人交通安全评估任务上的有效性;第⑩步用于验证采用SMOTENC算法对样本进行平衡的有效性。
3 实验
3.1 数据来源
根据相关文献研究和专家访谈结果[14-16],本文研究中变量选择为驾驶人固有性质维度,包括年龄、性别、驾驶经验、个人年收入、车辆已使用几年共5个变量,及驾驶人交通行为维度,包括是否有酒驾经历、是否有疲劳驾驶经历、是否有驾驶时抽烟经历、行驶过程中使用手机的频率、行驶过程中不系安全带的频率、当车辆损坏时是会继续上路行驶、过去一年是否曾出现过交通事故、过去一年内曾出现交通违法的次数、过去一年内曾参与文明交通志愿者活动次数共9个变量。
变量:年龄、性别、驾驶经验、个人年收入,从一定程度上反映着驾驶人的反应能力、驾驶能力、社会地位等固有特征。其中个人年收入影响着驾驶人面对较少数额罚款时是否积极规避处罚的态度。变量:车辆已使用几年,一定程度上反映着车辆的性能。
变量:是否有酒驾经历、是否有疲劳驾驶经历、是否有驾驶时抽烟经历、行驶过程中使用手机的频率、行驶过程中不系安全带的频率、当车辆损坏时是会继续上路行驶、过去一年是否曾出现过交通事故、过去一年内曾出现交通违法的次数,从一定程度上反映了驾驶人以往驾驶习惯的优劣。
文明交通志愿者从事交通引导工作,协助交警指挥疏导行人、非机动车,并能够劝阻行人、非机动车闯红灯、随意穿行马路等交通违法行为,在发挥着示范引领作用。变量:过去一年内曾参与文明交通志愿者活动次数,从一定程度上反映着驾驶人的交通意识,将该变量纳入考察范围有利于深化文明交通行动,提高交通参与者参与交通志愿活动的意愿,在实际行动中提高交通意识。
通过问卷星平台发放问卷,最终收集1 020份问卷。其中不含缺失值的样本1 009份,占98.92%。本文将特征:过去一年是否发生过交通事故作为标签。将坏个体定义为:过去一年发生过交通事故的个体,并编码为1;好个体定义为:过去一年未发生过交通事故的个体,编码为0。
3.2 数据预处理
缺失值。因含有缺失值的样本占比较少,所以将含有缺失值的样本删除。
变量的所属维度、名称、类型等情况如表1所示。
将变量“过去一年是否曾出现过交通事故”作为标签,取值类型为“是”编码为1,取值类型为“否”编码为0,其余变量作为特征。
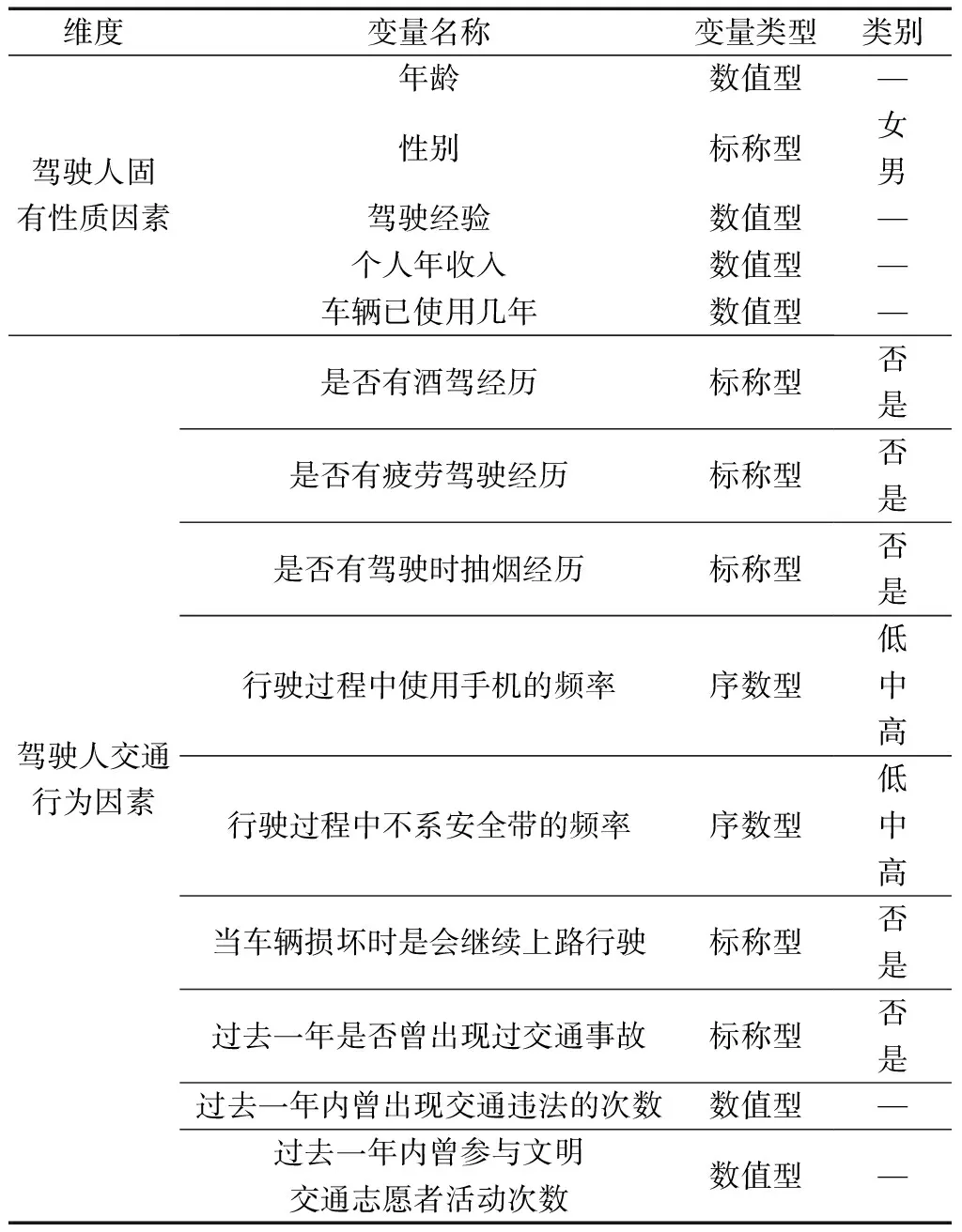
表1 变量基本情况Table 1 Basic information of variables
标签“过去一年是否曾出现过交通事故”的两个取值类别存在严重的不平衡现象。对于基于平衡数据集建立的模型,在数据预处理阶段采用SMOTENC算法,对数据进行上采样并在采样过程中加入随机扰动。平衡样本之前,样本个数为1 009个。其中标签为1的个体占样本总量的1.68%。标签为0的个体占样本总量的98.32%。使用SMOTENC算法对数据进行平衡后,样本个数为2 017个,标签为1的个体与标签为0的个体之间的比例约为1∶1。在基于不平衡数据集建立的对照组模型的数据预处理阶段则不进行此步骤。
3.3 特征选择
使用Embedded算法结合L1正则化,通过模型评估完成对特征子集的选择,使模型自动筛选出能够使模型准确率较高的特征。模型准确率与超参数C的学习曲线如图1所示。
由图1可知,当C=0.51时特征选择后的准确率稳定大于特征选择前。此时共有6个特征被保留,分别为性别、驾驶经验、是否有酒驾经历、是否有疲劳驾驶经历、行驶过程中违规使用手机频率、过去一年内曾出现交通违法的次数。

图1 模型准确率与超参数C的学习曲线Fig.1 Model accuracy and learning curve of hyperparameter C
3.4 变量解释
为对变量之间的关系进行解释,使用Logistic回归以过去一年是否曾出现过交通事故为标签,以性别、驾驶经验、是否有酒驾经历、是否有疲劳驾驶经历、行驶过程中违规使用手机频率、过去一年内曾出现交通违法的次数为特征建立模型。
二元Logistic回归的一般形式为

(11)
g(x)=θ0+θ1x1+…+θnxn
(12)
式中:n为样本个数;θn为每个特征的权重;xn为每个样本的特征矩阵。
在拟合训练集求解参数时,使用损失函数作为信息损失的指标,模型拟合训练数据越好,损失函数就越小,得到的参数组合越好。损失函数定义为
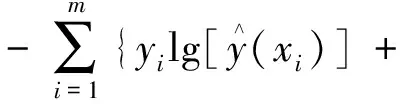
(13)

模型求解过程使用梯度下降法,设置最大迭代次数为100控制迭代进程。模型的参数检验情况如表2所示。
通过对过去一年是否曾出现过交通事故的二元然比卡方值为130.537,自由度为10,通过查卡方检验临界值表得,当显著性水平为0.05时,卡方临界值为18.307。因模型的卡方值为130.537,大于卡方临界值,且显著性小于0.05,因此模型通过了模型系数的综合检验。
通过对模型进行Hosmer和Lemeshow检验,得到卡方值为0.069,自由度为6,通过查卡方检验临界值表得,当显著性水平为0.05时,卡方临界值为12.592。因模型的卡方值为0.069小于卡方临界值,且显著性小于0.05,因此模型拟合度较好。
该模型通过了参数检验、模型系数综合检验和拟合优度检验,模型有意义,可以解释变量之间的相关关系,模型最终分类准确率为98.47%,分类效果好。由表3得出以下结论。
(1)驾驶人固有性质因素维度。男性驾驶员发生交通事故的概率是女性驾驶员的1.667倍;随着驾驶经验的增长,驾驶人发生交通事故的风险呈下降趋势。
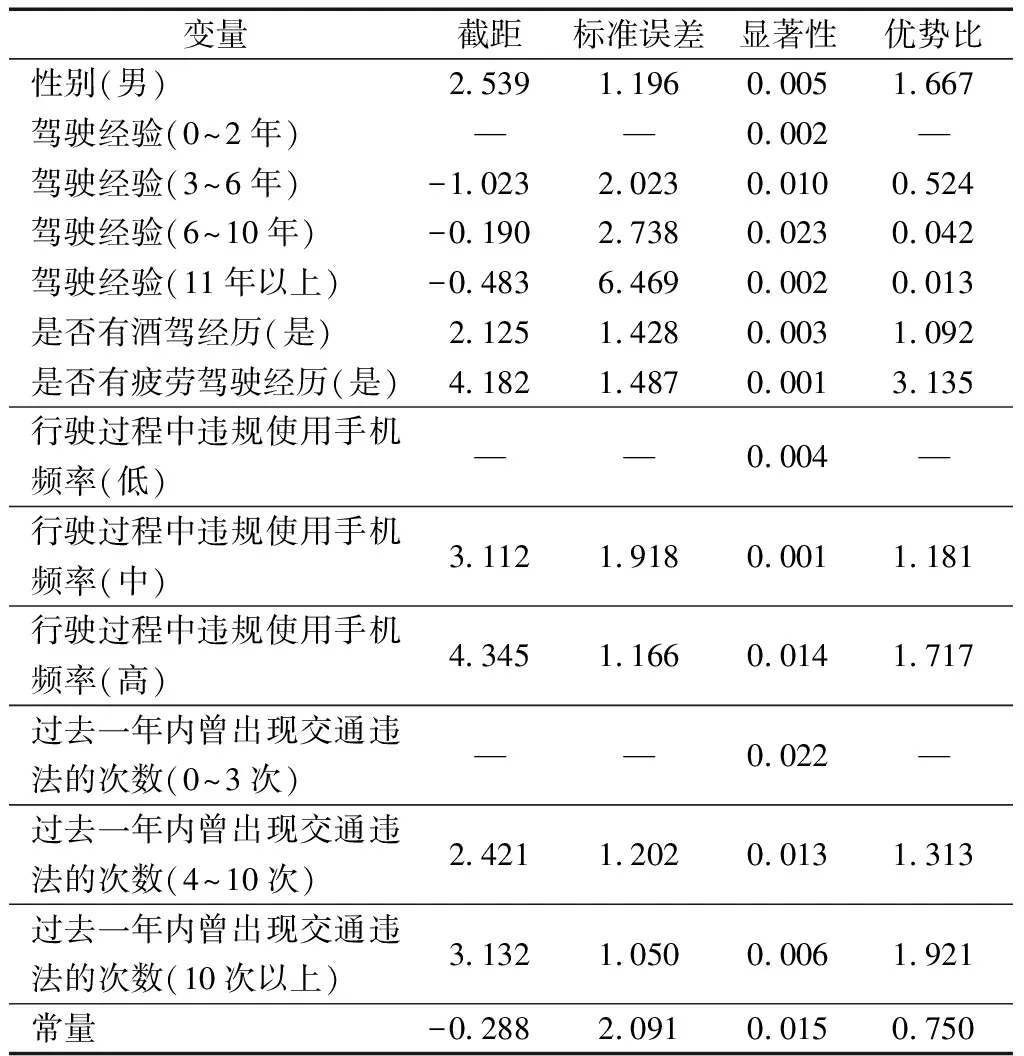
表2 参数检验表Table 2 Parameter check list
(2)驾驶人交通行为因素维度。有酒驾或疲劳驾驶经历的驾驶人,发生交通事故的概率分别为无酒驾或疲劳驾驶经历驾驶人的1.092、3.135倍。在行驶过程中违规使用手机频率及过去一年内曾出现交通违法的次数上,驾驶人发生交通事故的概率均为随着频率的升高或次数的增加而增大。且相比于驾驶时较少违规使用手机的驾驶人,经常违规使用手机的驾驶人发生交通事故的概率为其1.717倍。
3.5 模型对比
将基于平衡数据集建立的Logistic回归、DT、RF、SVM及基于不平衡数据集建立的XGBOOST作为对照组。
本文用于实现模型的计算机语言均为Python。XGBOOST模型的建立基于XGBOOST库的XGBClassifier接口,模型的参数为默认值;Logistic回归、DT、RF、SVM的建立均基于sklearn库,模型的参数为默认值。
按照7∶3的比例划分训练集和测试集,在训练过程中采用10折交叉验证。模型的准确率对比如表3所示。
由表3得,相较于Logistic回归、DT、RF及SVM,XGBOOST模型的准确率更高,准确率提升了0.37%~1.38%。除此之外,相较于基于不平衡数据集建立的XGBOOST模型,基于平衡数据集建立的XGBOOST模型准确率提升了0.75%。
分别绘制基于不平衡数据集和平衡数据集建立的XGBOOST模型的混淆矩阵如图2所示。
图2中左上角为真负类,表示样本的真实类别是0,并且模型将其识别为0;右上角为假负类,表示样本的真实类别是1,但是模型将其识别为0;左下角为假正类,表示样本的真实类别是0,但是模型将其识别为1;右下角为真正类,表示样本的真实类别是1,并且模型识别的结果也是1。
由图2得,对于不平衡数据集的测试集中的5个坏个体,XGBOOST模型将其中的3个坏个体分类错误,而对于平衡数据集的测试集中的318个坏个体,XGBOOST模型将所有坏个体正确分类。因此,在驾驶人交通安全评估任务上,采用SMOTENC算法对样本进行平衡,并使用XGBOOST算法对数据进行拟合得到的效果更好,更适用于评判驾驶人是否有交通事故发生的倾向性。

表3 模型的准确率对比Table 3 The accuracy comparison of the model
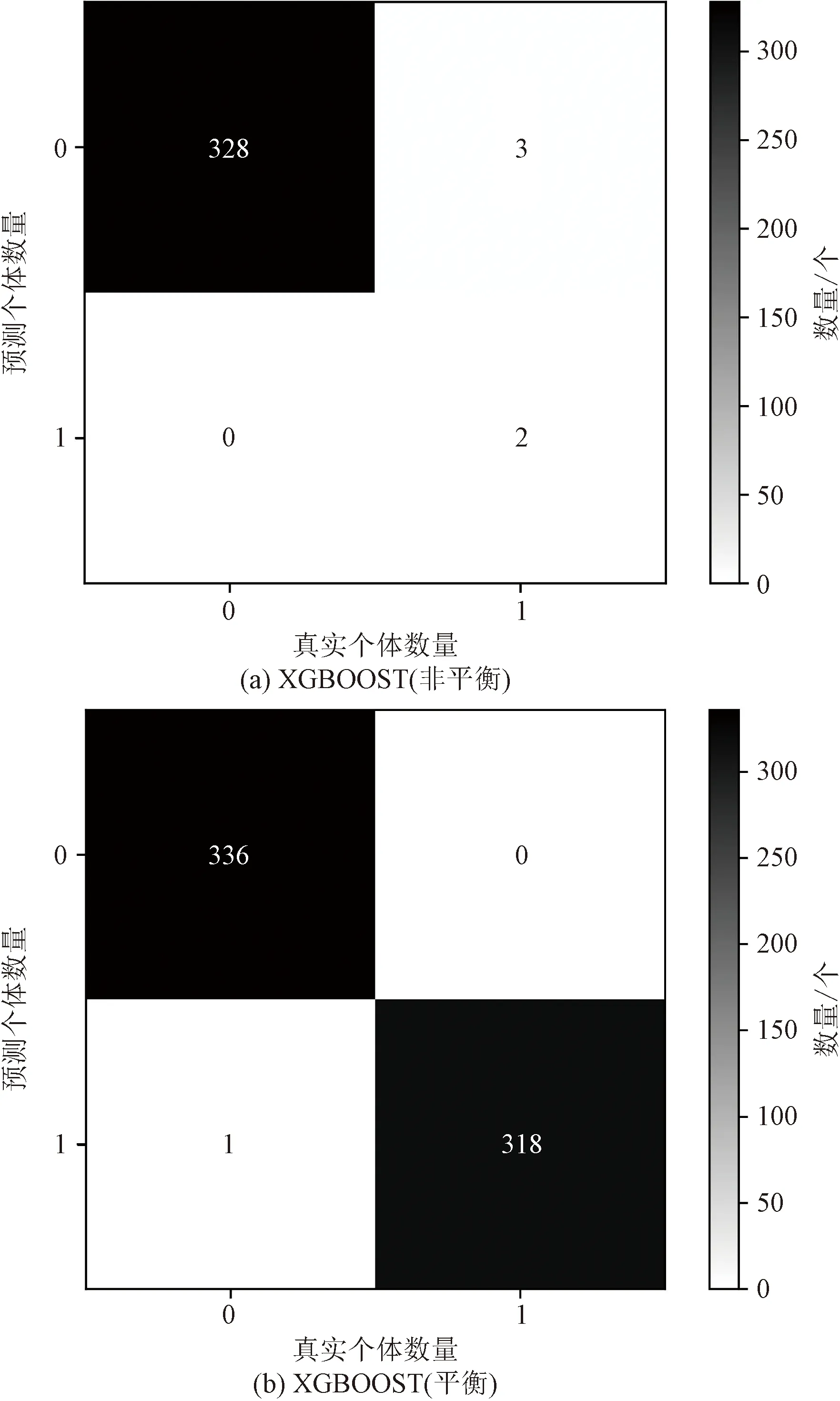
图2 混淆矩阵Fig.2 confusion matrix
4 结论
本文研究的创新点具体体现在3个方面。
(1)将研究驾驶人的历史交通行为,如驾驶人是否有酒驾经历、是否有疲劳驾驶经历等因素,结合驾驶人固有特征及车辆状态,同时纳入交通致因因素的研究范围,对管理部门开展针对性整治活动提供理论支撑。
(2)充分考虑该任务中存在的严重的数据不平衡现象,使用SMOTENC算对该问题进行解决,并且构建基于不平衡数据构建XGBoost模型作为消融实验的对照组,以准确率、混淆矩阵共同作为模型的评价指标,通过实验证明数据不平衡在模型拟合时所造成的问题。
(3)使用机器学习的方法构建模型,以Logistic回归、DT、RF、SVM作为 对照组,以准确率作为模型的评价指标,通过实验证明XGBoost模型在解决该问题上的优越性。
(4)由实验得,随着驾驶经验的增长,驾驶人发生交通事故的概率先升后降,说明老年驾驶人可能因视力状况、反应速度、认知能力等方面存在不适合继续驾驶的情况,所以之后的研究可以围绕老年驾驶人是否能够继续驾驶进行展开。
