基于非期望SBM-SVM改进模型的投资有效性预测
——以重庆市工业行业为例
2023-02-21陈义安
徐 杰,陈义安
重庆工商大学 数学与统计学院,重庆 400067
1 引 言
在国民经济中,工业行业是最重要的经济和生产技术综合体,工业行业分为采矿业,制造业,电力、热力、燃气及水生产和供应业3个门类,总共划分为41个行业大类,工业内部各行业间的投资结构对工业发展有一定的影响,行业间的有效投资有利于工业的健康发展。同时,工业也是能源消耗、环境污染的主要源头,近年来,工业对能源的消耗和产生的环境污染情况也引起了重视,提出的新发展理念包括绿色发展,即在经济发展过程中,要做到对保护环境、节约资源的落实,要做到对节能减排目标的完成,以此来促进经济转型的发展。因此,在研究工业行业的投资有效性时,加入环境污染这一非期望产出指标,将工业行业细分为39个行业,分析研究工业行业间的经济投资相对有效性情况,并构建出分类模型。
近年来将DEA方法与机器算法结合构建新的预测方法引起了众多学者的研究,Song[1]、冉茂盛[2]、李宁等[3]学者将DEA方法中的输入、输出数据以及结果作为训练集训练SVM模型,剩余的决策单元作为测试集进行测试,分别对企业绩效、上市公司的经营效率以及企业的平行部门绩效进行评价与分类预测,最终依据预测分类准确率验证了该方法具有可用性、有效性和实用性。Zhang[4]则是通过构建IG-SVM模型对DEA模型输入和输出数据的最小值、平均值、最大值进行预测,并利用DEA模型计算出决策单元的未来效率值,通过实例表明方法的可行性和适用性。同样,李玉龙[5]和Zhu等[6]学者建立了DEA与神经网络集成模型及机器学习(ML)算法之间的联系,分别对基础设施的投资有效性和中国制造业上市公司的绩效进行预测,证明了方法的适用性。通过上述众多学者的研究及实证证明:将DEA与机器学习算法以及SVM模型相结合构建的新模型对投资有效性研究具有可行性。但是在学者们的研究中,并没有考虑在投入产出过程中,会存在非期望产出的情况,因此本文引入非期望产出指标,利用非期望产出SBM方法与SVM方法相结合生成一个新的模型,以此研究非期望产出时的投资有效性。同样,对SVM模型参数优化,也是众多学者研究讨论的话题,通过对SVM模型的惩罚因子(C)和核函数参数(g)寻优,找到SVM模型的最优参数,提高预测准确率和模型的可用性。徐晓明[7]、颜薇等[8]分别利用智能优化算法、AGA模型对支持向量机的参数C和g进行优化,通过数值实验结果得出优化后的效果,使得预测效果更好。对于SVM模型,可以对其参数寻优,使得预测效果更佳,因此本文同样考虑运用智能优化算法对支持向量机的惩罚参数C和核函数g进行寻优,找到非期望产出SBM-SVM模型的最优C和g。本文将非期望产出SBM与SVM结合建立一个新的有效性分类方法,并对此进行改进优化,得到更佳的分类效果,此方法可以加入非期望产出指标,有利于对绿色发展、绿色投资的有效性等方向的研究。因此,本文探讨非期望SBM模型和SVM模型结合构建新的有效性分类方法及其对其优化是否具有可行性,并利用实证进行研究。
重庆市的经济正处于增长阶段,2020年重庆市全年GDP为25 002.79亿元,其中工业生产总值占国内比重28%,且近10 a来,一直维持在27.8%~37%的占比,为全行业最高。全年工业增加值为6 990.77亿元,比上年增长5.3%,规模以上工业增加值比上年增长5.8%,工业固定资产投资也呈现逐年上升的趋势,2020年比上年增长5.8%、研究重庆市工业各行业的投资有效性可以更好地分析优化产业结构,并促进工业长期稳定发展。本文选择非期望产出SBM模型对重庆市工业各行业投资效率的研究,并基于SVM模型构建出非期望SBM-SVM模型对投资有效性进行分类,运用优化模型对SVM方法参数寻优,根据结果情况得出结论。
2 非期望SBM-SVM有效性方法
Tone[9]在2001年提出了非径向非角度的SBM模型,此方法作为DEA的衍生模型,很好地解决了DEA方法由于径向距离函数以及角度模型所出现的在效率评估中的缺陷。
在投入产出过程中会产生负面效应,可以分为期望和非期望产出。于本文而言,节能减排是近年来备受关注的话题,我们期望在投入的过程中能排放出更少的环境污染物,因此加入非期望产出指标,能够更加科学、绿色健康地评价。

其中,s-为投入指标松弛变量,s+为期望产出松弛变量,su-为非期望产出松弛变量,投入要素权重为λ,最终求解的ρ*为决策单元的效率值,其取值在[0,1]。如果ρ*=1,则称决策单元为DEA相对有效;若ρ*<1,则称决策单元为非DEA相对有效。

当训练集D线性可分时,将分类问题转化成了带约束条件的二次规划问题:
s.t.yk(ωTxk+b)≥1,k=1,2,…,p
将二次规划问题转化为对偶函数,引入每个样本对应的拉格朗日乘子αk,αk≥0,k=1,2,…,p,可以得到:
(1)
对ω和b求导数,并令其为零,可以求得ω和b的最小值:
(2)
(3)
求解式(2)(3),得:
将结果代入式(1)有:
(4)
设定核函数K(xk,xj)代入式(4)中:
通过求解,可得到二次规划:
根据求解二次规划问题原理,该二次规划具有唯一解,最优分类函数为
根据KKT条件,分类面为最优分类超平面的充要条件是
(5)
训练集D为线性不可分时,引入了松弛变量ζi≥0,惩罚系数为C,构建出最大化分类间隔,使得原始带约束的二次规划问题变成以下表述:
s.t.yk(ωΤxk+b)≥1-ζk,ζ≥0,k=1,2,…,p
同样将二次规划问题转化为对偶问题,引入αk为每个样本的拉格朗日乘子,并引入新的拉格朗日乘子μk,得到式(6):
(6)
对ω,b,ζk求导数,并令其为零,可以求得ω和b的最小值:
设可以将线性不可分的两类点变成线性可分的核函数K(xk,xj),则对偶函数为
求解上述函数,分下列情况讨论:
0<αk
αk=C时,有α[yk(ωΤxk+b)-1+ζk]=0。因为C=αk+μk且αk=C,所以μk=0,ζk≥0,则yk(ωΤxk+b)≤1。
αk=0时,有α[yk(ωΤxk+b)-1+ζk]=0。因为αk=0且αk+μk=C,所以μk=C,同时因为μk·ζk=0,则ζk=0,yk(ωΤxk+b)≥1。
综上所述,所有样本必须满足:


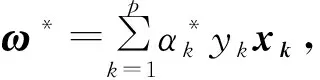

3 参数优化及模型评估方法
3.1 优化模型
支持向量机的性能和预测精确度受到惩罚因子C和核函数参数g取值大小的影响,本文选用智能优化算法调整SVM模型中的惩罚因子和核函数参数值,运用“试错法”、粒子群算法(PSO)、遗传算法(GA)对非期望SBM-SVM模型进行优化改进。粒子群算法(PSO)源于模拟鸟群捕食行为,通过群体中个体间的协作和信息共享来寻找最优解,粒子通过跟踪个体极值(pbest)和全局极值(gbest)两个极值来更新自己,找到两个最优值后,通过下列公式来更新自己的速度和位置[7]:
速度更新公式:
Vi=ω×Vi+c1×rand()×(pbesti-Xi)+
c2×rand()×(gbest-Xi)
其中,ω为惯性因子,Vi为第i个粒子的速度,Xi为第i个粒子的位置,c1和c2为学习因子,pbesti为第i个粒子的历史最优位置,gbest为粒子群的历史最优位置。
位置更新公式:Xi=Xi+Vi。
其更新步骤如下:首先对粒子群进行初始化处理;计算每个粒子的适应度值;比较每个粒子的适应度值和个体极值,若适应度值大于个体极值,则用适应度值替换;再对每个粒子的适应度值和全局极值进行比较,若适应度值大于全局极值,则用适应度值替代;根据速度更新公式和位置更新公式更新粒子的速度和位置;经过上述操作,直到到达设定的迭代次数T,终止运算,最终输出最优解C和g。
粒子群算法与非期望SBM方法和SVM模型结合的流程图如图1所示。

图1 PSO优化非期望SBM-SVM模型的流程图Fig.1 Flow chart of PSO optimizing undesirable SBM-SVM model
3.2 模型评估方法
在做分类时,需要对模型效果好坏进行评估,本文选择预测准确率、ROC曲线图、准确率和召回率来反映SVM模型分类结果的情况,首先需要构建混淆矩阵,如表1。

表1 混淆矩阵Table 1 Confusion matrix
(1) 预测准确率。预测准确率指准确判定出决策单元属于预期某一类结果的概率,其值越高,则表示准确预测的概率就越好,分类效果就越好。在表1的混淆矩阵中,其正确预测和错误预测的决策单元个数为矩阵交叉项,正确预测个数为TN+TP,预测准确率值为
(2) ROC曲线图及AUC值。对于分类器的优劣评价,通常会采用ROC曲线及AUC值,其中AUC值是ROC曲线下的面积,表示分类器对判断预期结果的预测能力,ROC曲线下的面积越大,则值越大,说明预期结果的判断能力越好,分类器的效果也就越好。
(3) 精确率和召回率。在评估分类模型时,仅使用预测准确率不能完全判定模型的优劣。依据分类数据集的结构情况,判断分类的精确率和召回率,分别对投资有效性和投资无效性预测进行验证。
4 实证研究
4.1 指标的建立与决策单元的选取
首先构建非期望SBM模型,建立SBM模型的输入、输出指标和决策单元的输入、输出指标。从对工业的投入和产出两个方面出发,选取2011—2020年重庆市相关指标,投入包括资本投入、劳动投入和能源投入,由固定资产代表资本的投入,应付职工薪酬代表劳动资金的投入,综合能源消费量作为能源的投入。由工业各行业的总产值、利润总额反映期望产出的情况。在进行劳务活动和产品产出的过程中,会产生对环境污染的排放。其中包括废水、废气、废弃物的排放,选择用重庆市工业各行业产生的废水排放量表示废水排放情况,二氧化硫和粉尘排放量表示废气排放情况,工业固体废物产生量表示废弃物排放情况,并用熵值法将以上指标综合为一个环境污染综合指数来代表工业环境污染排放物产出情况,此环境污染综合指数为非期望产出指标。
依据《国民经济行业分类标准》,将工业行业分为41个大类,其中采矿业中的开采辅助活动和其他采矿业近十年来未有相关数据发布,剔除这两个行业,本文将工业分为39个行业作为决策单元。要求决策单元的数量大于或等于投入和产出指标的数量之和的两倍,此决策单元的选取符合模型的要求。
由于工业小企业缺乏清晰完整的财务报表,开展相关的统计工作较为困难,一年的主营业务收入为2 000万元及其以上的工业单位称为规模以上工业企业,此类企业的投资、成本、收入、耗能、排放量等相关数据具有准确性和完整性,并且统计局发布的工业行业数据都为规模以上工业企业的数据,因此,以上输入输出指标都选取为重庆市规模以上工业企业的相关数据。
投入指标:按行业分固定资产X1(万元)、按行业分应付职工薪酬X2(万元)、按行业分综合能源消费量X3(吨标准煤)。
产出指标(期望):按行业分总产值Y1(万元)、按行业分利润总额Y2(万元)。
产出指标(非期望):按行业分工业环境污染综合指数Y3。
决策单元:重庆市工业各行业分类依据《国民经济行业分类》分为39类。
为了剔除价格变动的影响,将以上价格相关指标以2011年为基期进行平减处理,对固定资产指标进行平减的指数为固定资产价格指数;对应付职工薪酬进行平减处理的指数采用居民消费价格指数;采用工业生产者出厂价格指数分别对总产值和利润总额进行平减处理。
4.2 非期望SBM模型
本文选择非期望产出的非径向非角度SBM模型来评价工业各行业的DEA有效性,基于上文的SBM模型介绍,运用Stata16.0软件,测算出2011—2020年重庆市工业各行业的投资效率,表2列出2020年重庆市工业各行业的投资效率情况。

表2 重庆市2020年工业行业投资效率评价结果Table 2 Evaluation results of industrial investment efficiency in Chongqing in 2020
表2所列是对决策单元的资源配置能力、资源使用效率等多方面能力的综合衡量与评价。将工业划分为39个行业,有11个行业投资效率达到1,其中包括采矿业中2个行业,制造业中9个行业。电力、燃气及水的生产和供应业中没有达到1的行业。Wu[10]和郑建锋[11]等将DEA得出的效率分为4类,效率在0.98~1之间的决策单元为强相对有效,即此类决策单元稍作修改,便可以达到最佳组合配置;效率在0.8~0.98之间的决策单元为相对有效,此类决策单元比上一类决策单元需要多做修改,才能达到最佳组合配置;效率在0.5~0.8之间的决策单元为相对低效,这类决策单元需要重新调整资源配置或者投入产出结构,并需要一定时间来适应新配置;效率在0~0.5之间的决策单元为低效率单元,这一类决策单元需要花费大量的精力和时间来重新修改和调整投入产出。重庆市2020年的工业内部各行业投资效率,强相对有效决策单元有11个,相对低效决策单元有6个,低效率决策单元有22个,煤炭开采和洗选业为整个工业行业中效率最低的决策单元,效率值仅为0.058 665。说明重庆市2020年工业各行业间的差距较大,需要对低效率、相对低效率行业资源投入规模和配置进行调整修改。
从表2可以看出:投资效率最终呈现的评价结果取值范围在0~1之间。软件运算结果显示:有几项决策单元的效率值为0.999 99,近似等于1,因此本文将效率评价结果在0.98~1之间的决策单元设定为投资有效,运用名义数值1代表;将效率评价结果在0~0.98之间的决策单元设定为投资无效,运用名义数值0代表。
4.3 SVM模型
根据上文非期望产出SBM模型的指标选取及效率评价结果,此处选取SBM模型的输入与输出指标为SVM的特征变量指标,即重庆市2011—2020年规模以上工业按行业分的固定资产、应付职工薪酬、总产值、利润总额、工业环境污染综合指数,以上文得出的含有非期望产出的投资效率结果为SVM模型的结果变量,其中将投资效率大于0.98的决策单元标为DEA相对有效,投资效率小于0.98的决策单元标为非DEA相对有效。采用归一化对上列6个因变量指标进行标准化预处理以消除变量间的影响[12],公式如下:
本文运用R语言软件工具,利用重庆市2011—2020年工业各行业指标构建SVM模型,对重庆市工业各行业投资有效性进行分类,采用分层随机抽样进行数据划分,从结果变量的各层面随机抽取75%的数据,从而组合成训练集,则剩余25%的数据为测试集。高斯核函数在SVM模型中应用最为广泛,因此本文选用高斯核函数,将惩罚参数C设定为1,核函数参数g设定为默认值,为特征变量维数的倒数,预测结果如表3和图2所示。

表3 重庆市投资有效性分类预测结果表Table 3 Classification prediction results of investment effectiveness in Chongqing

图2 ROC曲线图Fig.2 ROC curve
最终,基于非期望SBM-SVM模型的重庆市工业投资有效性分类预测准确率结果为71.88%,ROC曲线中AUC值为0.76,投资有效性精确率为66.7%,召回率为20%,其调和平均数为30.77%;投资无效性的精确率为72.4%,召回率为91.3%,其调和平均数为80.75%。其中分类准确率和AUC值还有增大的空间,投资有效性的精确率和召回率都过低,特别是投资有效性的召回率仅为20%,因此需要对模型进行优化。
投资有效性的召回率仅为20%,发现样本数据经过有效和无效分类后,存在不平衡情况,因此对样本数据进行人工数据合成处理,将样本分类达到平衡状态。随后加入优化模型对SVM模型的惩罚因子C和核函数参数g进行寻优。本文选用“试错法”、粒子群算法(PSO)、遗传算法(GA)分别对C和g优化选取最优值,根据众多学者的研究及经验,在“试错法”对支持向量机参数寻优时,惩罚参数C和高斯核函数参数g取值范围为2-10≤C≤210,2-10≤g≤210,构建出不同的参数组合,采用交叉验证的方法来获得每次组合的错误偏差,最终选取误差最优的参数组合;粒子群算法优化时,参数取值范围为 0.1≤C≤10,0.1≤g≤10 ;遗传算法优化时,取值范围为0.1≤C≤100,0.01≤g≤10,染色体数目为200,交配概率为0.4,突变概率为0.01,繁殖次数即循环次数为100。表4和图3分别为3种方法寻找的参数C和g的最优值和准确率以及优化后的ROC图。

表4 不同优化模型的预测效果Table 4 Prediction effects of different optimization models

图3 优化后ROC曲线图Fig.3 ROC curve after optimization
从表4和图3的ROC图及3种优化方法的结果对比可以看出:3种优化方法寻找SVM模型的惩罚参数C和核函数g对于预测效果具有有效性,3种方法都提高了预测准确率。试错法寻优后,寻优到的最佳惩罚因子C=1 024,核函数参数g=0.5,优化后准确率为86.6%, ROC曲线图中的AUC值为0.92;投资有效性的精确率为100%,召回率为71.1%,其调和平均数为83.1%;投资无效性的精确率为80%,召回率为100%,其调和平均数为88.9%。PSO方法优化后,寻优到的最佳C=3.575 255 8,g=0.832 143 1,优化后准确率为88.66%,ROC曲线图中的AUC值为0.935;投资有效性的精确率为90.5%,召回率为84.4%,其调和平均数为87.3%;投资无效性的精确率为87.3%,召回率为92.3%,其调和平均数为89.7%。GA方法优化后, 寻优到的最佳惩罚因子C=14.488 004,核函数参数g=1.144 978,准确率为86.6%,ROC曲线图中的AUC值为0.92;投资有效性的精确率为88.1%,召回率为82.2%,其调和平均数为85%;投资无效性的精确率为85.5%,召回率为90.4%,其调和平均数为87.9%。其中,PSO方法寻优效果最佳,分类准确率提高了16.78%,AUC值提高了17.5%,投资有效性精确率与召回率的调和平均数提高了56.53%,投资无效性精确率与召回率的调和平均数提高了8.95%,且最优效果准确率为88.66%,得到了比较理想的效果。说明新构建的非期望SBM-SVM模型通过智能优化算法改进后对与重庆市工业投资有效性的分类研究是具有有效性和实用性的。
5 结 论
本文通过智能优化算法对非期望SBM-SVM模型改进,对惩罚因子C和核函数参数g进行寻优处理,从而提高了模型的分类准确率,提升了模型的性能;随后基于非期望SBM-SVM模型及对其的改进,建立对工业行业投资有效性分类研究的新模型,选取重庆市2011—2020年规模以上工业企业的投资相关指标和工业产出以及环境污染物排放相关指标作为样本数据,将重庆市工业行业划分为39个行业作为决策单元,通过非期望SBM模型得到工业内部各行业的评价效率,将投资效率在0.98到1之间为名义数值1,作为投资有效代表,0到0.98之间为名义数值0,作为投资无效代表,把效率分为DEA相对有效和非DEA相对有效两类,由非期望SBM模型的投入和产出指标作为特征变量,两类评价效率作为结果变量,构建SVM模型,对重庆市工业投资有效性进行分类研究,SVM模型高斯核函数的预测结果为71.88%;本文选择“试错法”、粒子群算法(PSO)、遗传算法(GA)优化模型选取SVM模型的惩罚因子C和核函数参数g的最优值,最终结果表示PSO算法寻优的效果最佳,预测准确度优化到了88.66%。对非期望SBM-SVM模型改进后,模型的准确率、AUC值、精确率和召回率及调和平均值都得到了提升,并达到了平衡,说明通过智能优化算法对模型的改进提升了模型的性能。投资有效性预测结果表明:采用构建的新的非期望SBM-SVM模型对其改进优化后,进行工业行业间投资有效性分类,具有一定的可行性和适用性。
