基于KPCA-K-means-GRU的短期风电功率预测研究*
2023-02-18周建勋王仕通易灵芝
徐 艳, 周建勋, 金 鑫, 王仕通, 易灵芝
(1.湖南电科院检测集团有限公司,湖南 长沙 410000;2.湖南电器科学研究院有限公司,湖南 长沙 410000;3.中国长江三峡集团有限公司湖南分公司,湖南 长沙 410000;4.湘潭大学 自动化与电子信息学院,湖南 湘潭 411100)
0 引 言
在“碳达峰,碳中和”的背景下,以风能、光能为代表的可再生能源开发前景广阔[1-2]。但风能间歇性和波动性的特点给电网的平稳运行造成了很大的挑战,这导致电网企业限制风电并网,造成弃风行为[3]。提高风电出力的稳定性和预测的精准性成为了亟待解决的问题,同时对风力发电做出实时有效的预测对风电开发和电网的平稳运行均至关重要。
本文主要以短期风电功率预测为研究对象,通过对0~72 h时间段的风电功率进行预测,提高电能质量。目前已有文献通过小波分解(WD)将原始时间序列分解为一系列的子数据,并用人工神经网络(ANN)进行预测[4],该研究提出的新模型能够在单一网络模型的基础上提高预测的准确度和稳定性。文献[5-7]通过引入粒子群优化算法(PSO)和遗传算法(GA)对神经网络的参数进行无监督寻优,通过群智能算法强大的搜索能力为神经网络匹配了合适的模型参数,达到了提高风电预测精度的目的。但是在学习网络参数时,群智能算法可能陷入局部最优。
上述文献虽然提出多种了针对短期风电功率预测模型的改进策略,但大多数仅考虑了历史发电数据单一变量,忽视了影响发电量的多种环境因素。风速、气压等多种天气因素结合历史功率数据可以更好地还原真实物理情景。通过K均值聚类(K-means)对数据进行无监督聚类并根据日期将风电出力情况划分为不同的类别,最后再根据深度神经网络对数据进行拟合。试验数据均选择湖南省某风电场2021年的实测数据,通过试验和对比证明了本文提出的方法具有较好的精度和鲁棒性。
1 数学模型
1.1 主成分分析(PCA)与非线性核主成分分析(KPCA)
随着科技的发展,风电功率预测的技术不断进步。传统的风电信息获取只能依靠人工对环境信息进行测量,但随着数值天气预报(NWP)系统的发展,可以轻松获得更加精准、及时且全面的天气信息。目前的NWP系统包括温度、气压、10 m风速、50 m风速、100 m风速等多种信息。虽然更多的信息能够更真实地反映实际情况,但如果不将这些信息加以处理而全部输入模型中,则会导致模型的鲁棒性降低及运行速度变慢,从而使预测系统不能应用于实际。若仅采用单一的维度进行分析,则可能遗漏关键信息,导致预测精度下降。目前,一般采用降维的思想对多维数据进行处理。降维技术是将所有的信息统一到一个框架中,通过该框架提取数据的关键特征,消除众多数据的冗余部分,在保留关键信息的同时合理降低数据的维度,避免发生维数灾难。
PCA是一种基于特征向量搜索的无监督学习方法,目前已成功应用于多种领域的监测,其能够通过映射,在保留关键信息的同时降低数据的维度[8-9]。总体来讲,PCA具有以下几个特点:
(1) 经过PCA后的变量个数比原有变量个数少,通过对原有变量主成分的提取,在保持原有数据特征的同时减少了数据的维度,避免了维数灾难,提高了计算效率;
(2) PCA不改变原有数据蕴含的信息,其虽然能够降低数据的维度以增加计算的效率,但并不是单纯地对数据进行删除,而是对原有变量进行线性投影后,将高维度的数据投射到低维的空间中达到降维的目的;
(3) PCA各个主成分之间具有互不相关性,其得到的每个主成分都是对原有数据投影后得到的结果。
1.2 皮尔逊相关系数(PCC)分析
PCC是一种衡量变量间相关性的指标[10]。对本文使用的NWP数据(包含风向、湿度、气压、平均风速、功率)进行PCC分析,试验结果如图1所示。皮尔逊公式的表达式为
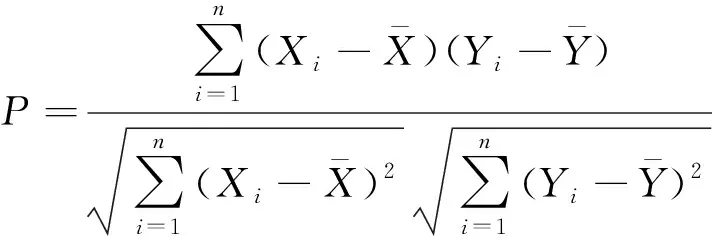
(1)

图1表明多维数据中仅风速和功率之间有较强的相关性,其余数据的线性相关程度较低,因此不宜采用线性降维。

图1 NWP变量线性相关性分析混淆矩阵图
PCA通过对原始数据进行线性化的变化达到数据降维的目的,相较于PCA,KPCA解决了特征向量线性不可分的问题,在适应线性化问题的同时提供了更多的特征数目,并通过映射函数非线性化的方式对主成分进行提取。假如原始维度空间中存有数据点Lx,则可以借助映射函数将其映射到高维度空间F。映射函数为Lx→φ(x)∈F,核函数的定义为原始空间中的点在映射空间的距离:
k(Lxi,Lxj)=φ(Lxi)φ(Lxj)
(2)
在F特征空间上的协方差矩阵M为

(3)
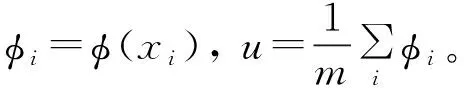
对于M矩阵中的某一特征向量v及其对应的特征值λ,有Mv=λv,v是{φi-u}生成的特征空间中的特征向量:

(4)
因为公式两边都在{φi-u}生成的F空间中,故用下式替代:
(φi-u)TCv=λ(φi-u)Tv
(5)
核矩阵H的元素Hi,j=φiφj,i,j= 1,2,…,m。通过给定的核函数可以得到对应的F空间点积,即φiφj=k(xi,xj)。做因子分析时需要中心化之后的核矩阵HC表达式:
HC=PdKPd
(6)

最后对数据点的非线性主成分进行如下的求解:
[φ(xk)-u]·v=λαk
(7)
因为采集变量不同,NWP数据集存在量纲不同的问题,同时风电数据较大的波动性会对预测的精度和速度产生不良的影响,甚至造成无法收敛的问题。
为了降低上述负面影响,本文将对数据集的各数据变量使用min-mix标准归一化方案,同时选择在分子上+1防止归一化后的数据出现零值:
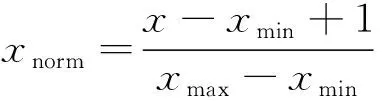
(8)
式中:xnorm为归一化的结果;xmin与xmax分别为数据集变量的最大、最小值。
KPCA方法可以通过各主成分的贡献率判断算法的目标维数[11]。使用KPCA对归一化后的数据集进行分析,结果如表1和图2所示。在表1中,9个主要组成部分的贡献率和累计贡献率主要集中在前3类,且前3类的累计贡献率已经达到了99.84%。从图2可以看出,在第3个主成分后累计贡献率上升非常缓慢。

表1 各主成分贡献率

图2 主成分累计贡献率
2 基于K-means的预测类别划分
负荷预测主要特征包括天气、季节和当天是否属于节假日等因素[12],在负荷预测中,学者们将具有相似特征的日期聚合在一起。本文将具有相似天气和功率曲线的数据集进行聚类得到不同的类别,分别对不同的类别进行训练以获得最佳的网络参数。本文采用K-means方法对数据进行无监督的聚类,K-means在进行聚类时需要随机选取K个点并将其指定为聚类中心点,根据其余样本与这些聚类中心点的欧式距离,将其归为不同的类别。欧式距离如下所示:

(9)
式中:xi、yi分别为样本X、Y的第i个变量。
K值的确定方法分为手肘法和轮廓系数法。手肘法的自动化程度低,面对海量数据时效率亟待提升。轮廓系数法根据聚类的凝聚度和分离度进行K值的判断,不同K值对应的轮廓系数如表2所示。通常轮廓系数的值在-1~1之间,轮廓系数值越大则表明聚类效果越好,不同的聚类效果如图3~图5所示。

表2 不同K值对应的轮廓系数
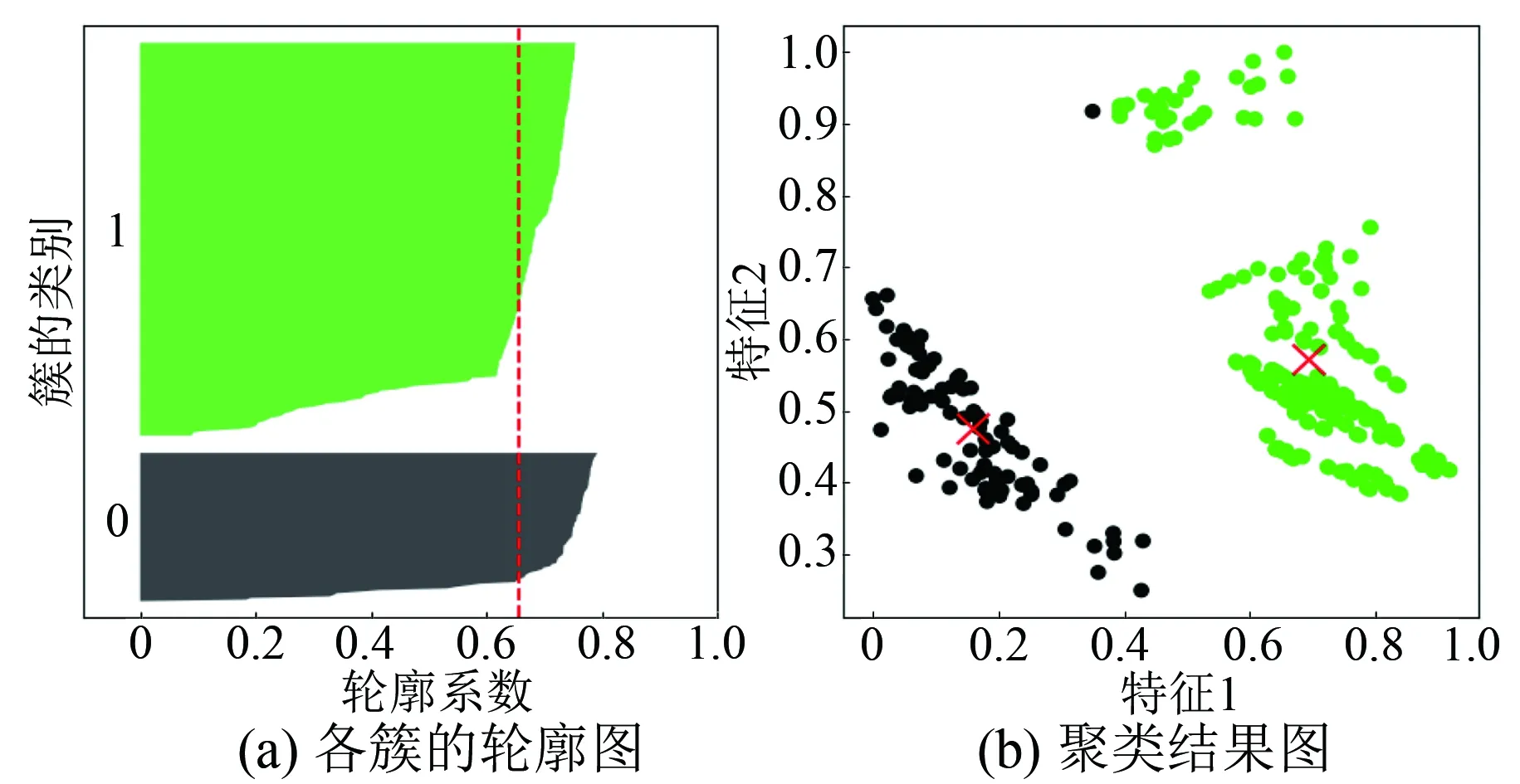
图3 K为2时对应的聚类效果

图4 K为3时对应的聚类效果

图5 K为4时对应的聚类效果
本文采用15 min为间隔的实测风电数据进行试验,每月的最后3天作为预测数据,其余作为历史数据,通过轮廓系数的比较来确定K值。当K=3时,轮廓系数为0.695 5。通过比较,本文将K取值为3,即根据聚类中心数,本文数据集可细分为3种类型。
首先,选择降维后的数据,根据向量间的欧式距离确定具体类别,具体如下:

(10)
式中:xm(k)为预测目标降维后的向量;xi(k)为历史数据样本降维后的向量。
以5月1日~20日为例,由式(10)计算出欧式距离并判断出样本所属的类。有13天样本数据属于第1类数据,有4天样本数据属于第2类数据,有3天样本数据属于第3类数据,具体分布如表3所示。降维前后数据类型对比如表4所示。

表3 历史数据样本日所在聚类的情况(K=3)

表4 降维前后数据维度对比
3 门控循环单元(GRU)网络模型
循环神经网络(RNN)的特点是每一层的神经元都可以进行反馈,进而实现信息的传递。与其他的神经网络不同的是,RNN构建的网络会对历史时刻的信息进行记忆,并将记忆留下的信息应用到当前神经元的输入计算中。这使得RNN对时间序列预测的效果较好。但RNN长期依赖问题会导致梯度消失或梯度爆炸等,进而导致模型无法训练[13]。GRU神经网络结构由更新门和重置门组成,保留RNN对时间序列优秀的处理能力,解决了梯度消失和爆炸的问题,实现了信息在网络上的长期流动,通过对网络模型结构优化减少了模型参数,同时减少了时间序列处理的步骤。在本文中,输入量为经过降维聚类后的数据,利用3类数据训练3种GRU模型。并将GRU网络模型的隐藏层hidden设置为3,循环次数epoch设置为100,loss采用mse。GRU神经网络的整体结构图如图6所示[14],在图6中,当前时刻的输入以xt来表示;经过Ct的隐藏层处理后,输出以yt来表示。
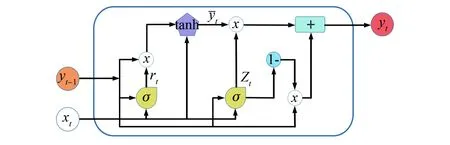
图6 GRU神经网络结构示意图
GRU神经网络的计算方式如下所示:
rt=σ(Wr·[yt-1,xt])
(11)

(12)
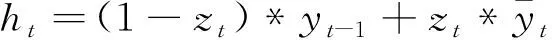
(13)

4 基于KPCA-K-means-GRU的功率预测模型性能分析
对数据降维后的训练集进行聚类,划分不同的类别,并训练不同的GRU模型参数。将预测集按照同样的方法划分类别并进行匹配。并将匹配结果输入神经网络进行预测,具体流程如图7所示。同时为了验证本文所提KPCA-K-means-GRU组合模型在超短期风电功率预测中的优越性,试验中分别与支持向量机(SVM)、极限学习机(ELM)以及GRU神经网络进行对比。通过对多维的数据进行聚合降维,本文模型将具有相同特征的风电数据划分为不同的类别,提高了模型的拟合能力,降低了功率预测的难度,在预测结果的精确度和鲁棒性上均具有优势。

图7 KPCA-K-means-GRU预测模型框架
本文选择采用均方误差(RMSE)和平均绝对百分比误差(MAPE)两个指标来进行预测模型性能指标的对比。
RMSE的表达式为

(14)
MAPE表达式为

(15)
式中:n为预测样本数;Y′(t)为预测结果;Y(t)为实际值。
该预测模型将t时刻的多个变量数据输入,将t-1时刻除功率外的其余变量作为训练样本的特征,t+1时刻的发电功率作为训练样本的目标。在K取3时,其他参数保持不变,将本文提出的KPCA-K-means-GRU模型与其他模型进行性能对比,每个模型运行10次后得到的误差取平均值。
表5展示了本文提出的模型与其他模型在预测相同数据时的误差效果对比。与其他模型相比,本文所提组合模型的误差的平均值、最大值、最小值均比其他方法小。说明本文提出的方法具有较高的预测精度。

表5 不同月份、不同方法下RMSE与MAPE对比
通过图8可以看出,本文提出的模型在数据拟合方面表现出更优的效果,在数据极值点附近的预测误差进一步降低。本文将5月份预测得到的RMSE和MAPE值通过箱型图展示,如图9与图10所示,箱型图能够直观地展示模型的精度以及鲁棒性,箱型图越低,证明预测精度越好,箱型图的长度越短,表示该模型的稳定性越好,给出的预测结果越稳定。可以看出本文提出的方法在10次试验中均表现出较低的预测误差,本文方法的预测效果比其他方法具有明显的优势,说明提出的方法在具有较高精度的同时具有较好的稳定性。

图8 5月份不同模型预测结果

图9 5月份不同模型预测误差RMSE

图10 5月份不同模型预测误差MAPE
5 结 语
本文针对风电短期功率预测建立分类再预测模型,数据采用湖南省某风电场提供的2021年实际数据,得出如下结论。
(1) 高维度的数据集能够更真实地反映实际情况。但原始数据集的维度较高,在进行数据处理时会增加处理时间,降低模型的实用性。KPCA能够在保留数据信息的同时降低数据集维度。
(2) K-means算法能够将降维后的数据分类,通过分别训练不同类别的数据可以得到更合适的网络参数。
(3) 通过与其他模型对比,证明了本文提出的模型具有较高的预测精度以及鲁棒性,说明了该模型是切实可行的。
