基于深度学习的公路裂缝病害自动识别技术研究
2023-02-15隆星
隆星
(1.中国铁建投资集团有限公司,广东 珠海 519031;2.西安交通大学人居环境与建筑工程学院,西安 710049)
1 引言
截至2021年年末,我国路网总里程已达到528.07万km,高速公路达到16.91万km[1],居于世界前列。密集的公路网极大地便利了区域间的信息交流和资源分配,从而促进了经济社会的快速发展[2-3]。然而,在车辆和周围环境等因素的综合作用下,高速公路在使用过程中会不可避免地出现裂缝、车辙、坑槽等病害,这些病害会对路面寿命、公路运营产生严重影响,甚至会造成交通事故,因此,对公路路面病害的检测和养护成为管理部门的任务和日常工作。采用传统的人工视觉检测路面病害流程复杂、效率低,并且伴随着大量的人工成本。在计算机视觉和图像处理技术发展初期,研究者多通过直方图估计、局部二值模式、Gabor滤波、形态学特征、支持向量机(Support Vector Machine,SVM)等方法检测路面病害,取得了不错的精度。但这些方法存在一些共性的弊端,就是对图像的质量要求较高,对外界的抗干扰能力较差,模型的结果受光照、背景和裂缝的对比度、非裂缝等其他类别像素等的影响较大,极大地限制了路面病害的检测准确度和效率。
近年来,深度学习方法因其在非线性、模糊系统中的突出表现成为解决复杂预测、分类问题的一项重要工具。在目标检测、语义分割、图像分类、逐帧视频分类、文本处理、时间序列分析等领域都得到了广泛的应用。卷积神经网络被定义为前馈神经网络的一个子类,具有池运算和卷积层的特殊性,在捕获局部和全局特征以进行项目抽象和表示方面具备良好的性能,可以较好地抑制噪声的影响,从而被广泛应用于公路裂缝的识别中。封筠等[4]提出了一种多级卷积神经网络的路面裂缝检测模型,通过网络级联的方法在保证裂缝图像全部召回的前提下,取得了更优的检测结果,为路面裂缝图像漏筛的问题提供了解决思路。晏班夫等[5]引入了一种目标检测中的快速区域卷积神经网络算法来快速识别病害种类、位置和面积,该方法使路面表观病害检测的效率和精度都得到了极大的提高。侯越等[6]提出了卷积自编码预训练深度聚类算法,利用传统图片几何变换和CAE网络重构增强图片两种方法对小样本路面图片数据集进行扩充,提高了DCEC深度聚类方法的准确率。曹锦纲等将注意力机制引入编码器-解码器(Encoder-Decoder)框架中,提高了裂缝检测模型的效率和裂缝识别定位的准确性[7]。
以上研究虽然对裂缝识别有着较高的识别精度和较快的速度,但模型的抗干扰能力以及对裂缝边缘分割的准确率有待提高。本文基于VGG网络和SegNet网络提出一种裂缝分割算法模型(DeepCrack),在保证裂缝识别和定位准确度的同时具备较好的鲁棒性。可为新疆及干旱地区高速公路的建设和路面养护提供有价值的建议和理论性的指导。
2 研究区概况和数据预处理
2.1 研究区概况
新疆深处内陆,气候干旱,地形封闭,属于典型的大陆性干旱气候,冷暖季和昼夜温差极大,呈现出极端性大温差特征,该区域长、短时温变极易引起路基路面病害。极端的自然条件对新疆地域的公路建设与维养提出了更高的要求和标准。
本文通过道路综合检测车对G30连霍高速与G7连接的S303线K40~K77段以及G312线哈密段[见图1(a)]进行路面病害样本的采集,共采集3 000余个样本数据,主要包括裂缝、坑槽、车辙、龟裂等病害。对采集到的样本进行统计,其中大多为裂缝病害。裂缝根据其延伸方向与道路行车方向是否垂直可以分为横向裂缝和纵向裂缝,随着使用年限的增加和车辆的碾压,会逐渐形成网状裂缝[见图1(b)~(d)]。裂缝的统计学特征经常被作为评估路面健康状况的指标,实现公路裂缝的高效、智能检测对道路养护具有重要意义。
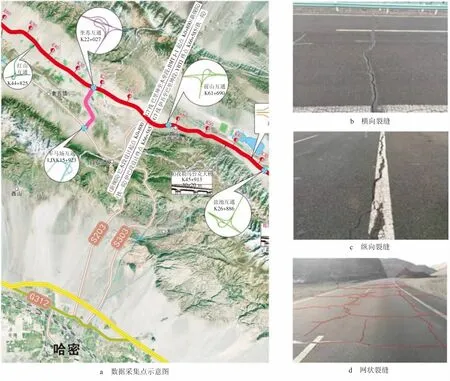
图1 裂缝数据采集位置及裂缝分类
2.2 数据预处理
采集到的裂缝数据通过预处理步骤转换为符合模型输入要求的图片。首先将样本分辨率统一为31 361 933像素。通过光照变换和多角度变换对样本数据进行扩充,尽量减弱光照、拍摄角度等因素对样本质量的影响。然后通过分割和重采样的方法(见图2)将样本统一为512 512像素大小的图片,分割时尽量确保裂缝在整张图像中占更多的比例,避免裂缝像素和非裂缝像素比过于不均衡。最后使用OpenCV将图像转换为单通道灰度图(0~255)。这里将样本划分为1 799个训练数据,100个验证数据和100个测试数据。

图2 所采集裂缝原始图像预处理分割
3 基于深度学习的路面裂缝识别
本论文提出的裂缝识别深度学习模型基于VGG网络中块的设计思路和SegNet网络中编译码器(Encoder-Decoder)思想进行设计,最后通过多尺度误差函数对模型识别精度进行量化评价。
VGG网络中块的设计思路将图像信息的识别和提取逐级抽象化,将特定卷基层和池化层组成可重复的单元块。图像在该单元块时,信息抽象化程度逐级提高,形成一系列不同尺度的中间处理结果。这些中间处理结果保留了裂缝等缺陷图像对噪声敏感但边界清晰的低尺度信息和对噪声鲁棒性强但边界模糊的高尺度信息。
这些中间处理结果根据通过Encoder-Decoder还原成与输入图像同大小的数据以进行该尺度下的误差分析,由此可以得到裂缝图像不同尺度下的误差。通过将这些多尺度下的误差图进行巧妙融合,组成新的误差函数,网络每次训练以减少该多尺度误差为目标。由于模型同时考虑了裂缝的具象信息(边界信息)和抽象信息(是否为裂缝),对于裂缝的识别准确率和定位准确率有明显提升。
3.1 模型结构
如图3所示,经过图像预处理后的输入数据会首先经过5个由3个卷基层和1个池化层组成的编码器(Encoder)网络块,从而得到裂缝图像在5个不同尺度下的信息。每经过一层编码操作,裂缝信息的抽象化程度会更高,其抗干扰能力逐级增强,但是裂缝位置、宽度等信息会逐级丢失。该过程可以看作是对图像进行多层Encoder的过程,目的是增强裂缝识别的准确率。
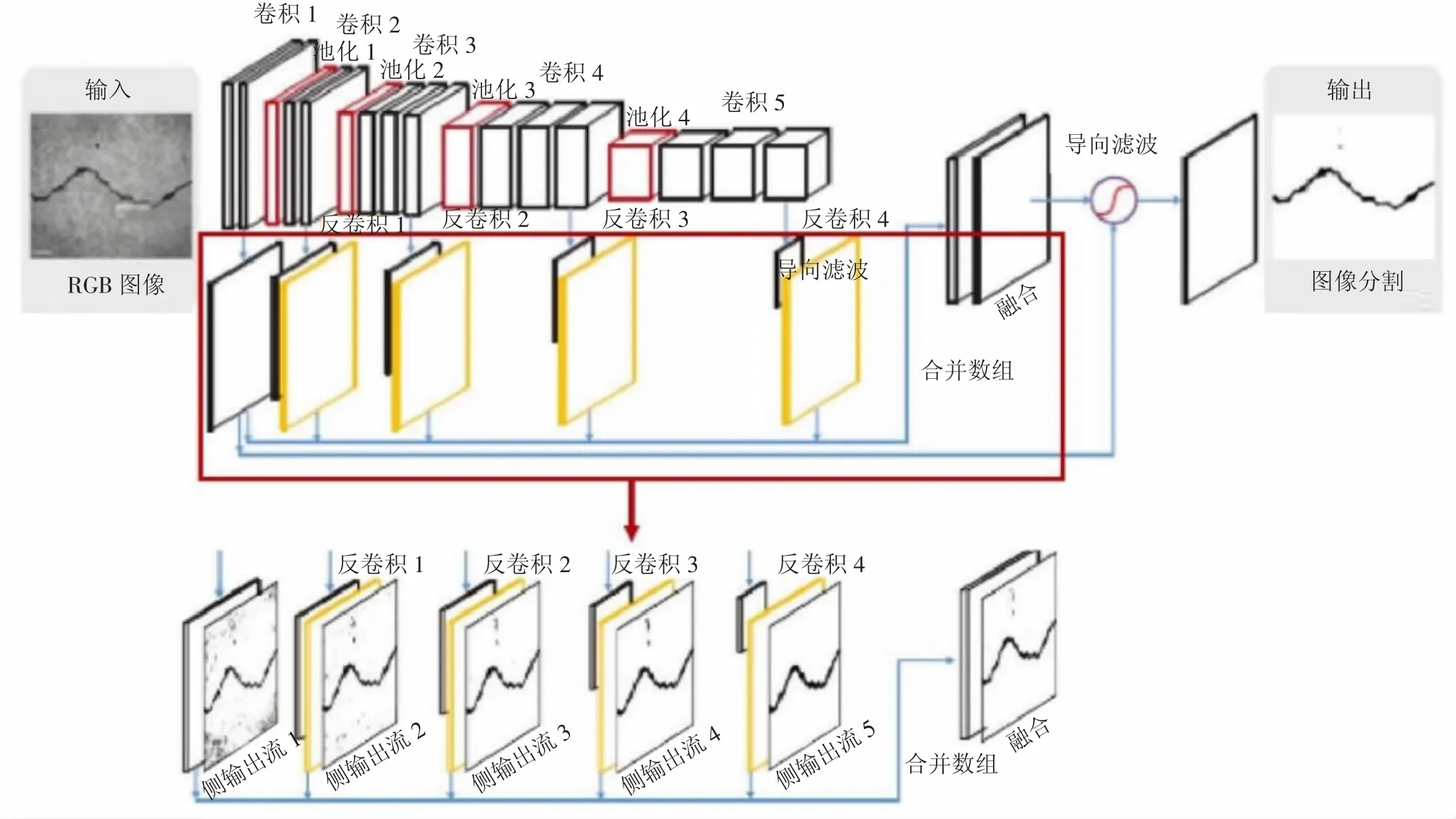
图3 裂缝图像处理过程
随后,经过编码后的图像信息会通过与Encoder对称的解码器(Decoder)网络。图像信息的中间输出结果由通过Decoder网络恢复成与输入数据同尺寸大小的图像。可以逐级增强裂缝的位置、宽度等具体信息,提高识别分割结果的边界准确度。由于经过Decoder网络得到的裂缝图像中输出结果尺寸与原始图一致,从而可以得到该尺度下的裂缝识别误差图。
在每次卷积操作后,会对特征图进行小批量标准化操作,从而得到5张特征图,分别为裂缝图像在5个尺度下的误差信息。通过将这5张误差特征图进行融合,可以有效提升线状目标的检测准确率。为了将不同尺度下的误差特征图融合,采用的卷积层调整特征图的尺寸和通道数。经过上述操作可以得到同一尺寸的不同尺度的下的裂缝预测特征图。将每个尺度下得到的误差图进行融合和导向滤波,最终得到模型的整体预测误差函数,通过最小化误差函数对网络模型进行训练,得到最终的预测模型。生成结果是表示裂缝位置的二值图,裂缝与非裂缝像素值分别为1和0。
3.2 损失函数
给定包含N张图像的训练数据集S={(Xn,Yn),n=1,…,N},其 中代 表 原 始 输 入 图 像表示与Xn相对应的真实裂缝标签图,I表示每张图像中的像素数目。目标是训练网络从而产生能达到真实结果的预测图。在编译码器(Encoder-Decoder)结构中,K表示卷积级数,故在阶段生成的特征图可以表示为F(k)=其中k=1,…,K。由多尺度融合得到的特征图可以被表示成
裂缝检测是一个二分类问题,因此,采用交叉熵损失函数来定量预测误差。由于裂缝与非裂缝像素数量分布不平衡,在网络结构中给裂缝像素增加更多的权重。从而定义像素级别的预测误差为:
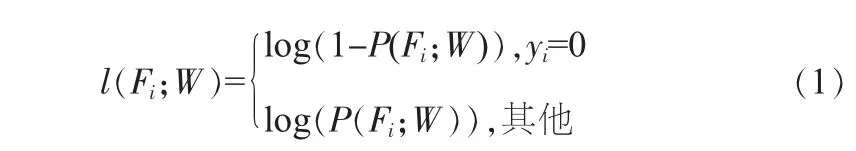
式中,Fi为网络特征图中像素点i的输出;W为网络层中标准参数的集合;P(F)为标准sigmoid函数,用于将特征图转换成概率密度图。综上,总误差可以表示成:

4 结果分析
本论文的实验环境为CPU:Intel(R)Core(TM)i9-10900KF CPU@3.70 GHz,RAM:32G。每次预测过程中,一次循环需要大约2.4 s,可通过多线程并行。
4.1 评价指标
根据样本真实类别和模型预测结果,将样本分为TP(True Positives)、FP (False Positives)、TN (True Negatives)和FN(False Negatives)。TP和FP表示对裂缝像素的预测是否正确,TN和FN表示对非裂缝像素的预测是否正确。并基于此计算精确度(Precision)、召回率(Recall)作为评估模型准确性的指标,公式为:

精确度-召回率(P-R)曲线是分别以精确度和召回率作为纵坐标和横坐标绘制的曲线。平均准确率(Average Precision,AP)是对P-R曲线的积分。
4.2 对比实验
对比实验选取两个数据集CRKWH100和CrackL315作为测试集,分别包括100张和315张路面图片。将本文提出的方法与HED,RCF等6种深度学习网络在两个数据集上进行实验,结果见图4。结果表明:经典边缘检测网络HED和RCF利用VGG16作为特征提取网络,并在不同尺度下完成特征融合。两个模型在CRKWH100数据集上的AP值为0.909 6和0.907 9,性能上相差不大,而在CrackLS315数据集上HED为所有网络中性能指标最低。U-Net与SegNet网络通过特征压缩与复原实现像素级别的类别标注。在CRKWH100数据集上,U-Net比SegNet的AP值高出5.25%。裂缝分割算法模型(DeepCrack)通过实现SegNet编解码端的特征融合与多重损失的监督训练达到了更好的效果,但融合特征并没有进行有效筛取。本文提出的单尺度多层次特征融合模块和三重注意力模块的改进策略,使新的DeepCrack在CRKWH100数据集上AP平均准确率达到0.9408,优于当前最佳的结果。此外,在CrackLS315数据集上较原先的DeepCrack在AP值提升了0.71%,获得了最佳效果,进而证明本文提出的模型具有更好的泛化性。

图4 CRKWH100数据集和Cr ackLS315数据集上测试结果的P-R曲线
将该网络模型对采集到的隧道裂缝图像进行识别,识别结果如图5所示。

图5 裂缝识别效果图
5 结论
本论文使用在京新高速(G7)沿线的高速公路上采集的公路裂缝影像制作了公路裂缝的标准数据集,并提出了一个深度学习模型用于裂缝的识别。该神经学习网络模型基于VGG块设计思想和编译码器提取多尺度抽象信息为基础,可以实现裂缝的像素级识别定位。在CRKWH100和CrackL315两个标准测试数据集中的准确率、召回率,F-measure结果均要优于目前其他几个主流模型。说明该方法可以满足工程实际检测的需求,同样的,该方法在桥梁裂缝检测、建筑物表面裂缝检测等方向也具有很好的应用前景。
