融合语境语义差异特征的短文本匹配模型
2023-02-10张文慧汪美玲侯志荣
张文慧 汪美玲 侯志荣
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
10.13209/j.0479-8023.2022.071
2022-05-13;
2022-08-04
融合语境语义差异特征的短文本匹配模型
张文慧 汪美玲 侯志荣†
工商银行金融科技研究院, 北京 100029; †通信作者, E-mail: houzr@tech.icbc.com.cn
在字面相同语义不同和字面不同语义相同的情况下, 短文本匹配往往不能准确地得到语句间语义的相似程度。针对这一问题, 提出一种融合语境语义差异特征的短文本匹配模型。该模型以 BERT 系列的语言模型作为基础匹配模型, 采用一种新的 Diff Transformer 结构作为差异特征提取器, 并以门控方式融合基础语义表示和差异特征表示来提升匹配效果。在中文测试数据集上的实验结果表明, 所提出的模型可以达到先进模型的效果。
短文本匹配; 差异特征; 语境语义; Diff Transformer
短文本匹配(short text matching)是自然语言理解的一个基本问题, 其研究目标是判定两条文本语句是否语义相同, 常应用于信息检索以及智能问答等场景, 核心任务是语句的表征及其相似程度的度量。自然语言的歧义性和多样性导致短文本匹配研究面临字面不同而语义相同以及字面相同而语义不同两大难点[1]。字面相同而语义不同指两个语句中某些词语字面一致, 但置于不同的语境, 导致词义随之变化以及语句的语义不同。例如在语句“买一斤苹果”和“买一部苹果”中, “苹果”的词义不同, 进而两个语句的语义不相似。字面不同而语义相同指两个语句中某些词语字面不一致, 但互为同义词, 对应语句的语义相似。例如在语句“您多大年纪了”和“您今年贵庚?”中, “年纪”和“贵庚”互为同义词, 两个语句的语义相似。
目前的研究主要从增强模型对短文本的语义表征能力入手, 从设计模型结构、借助外部知识以及增加差异特征 3 个角度探索解决方案。
在模型结构设计方面, 基于表示的结构和基于交互的结构是目前文本匹配模型的主流结构。基于表示的模型结构分别对文本语句进行表征, 然后进行语义相似度量。Huang 等[2]首次提出 DSSM 模型结构, 此后的研究大都以该结构为主, 比如 CDSSM模型[3]。基于交互的模型结构先对两个文本语句进行交互匹配, 然后再获取文本表征, 进行语义相似判断。Hu 等[4]首次提出 ARC-II 模型结构。交互匹配的结构设计极大地提升了文本语义表征能力, 是目前研究的主流模型结构。注意力机制与交互匹配结构相结合, 使得文本匹配效果再次得到提升, 比较经典的模型有 ESIM[5]以及各类基于语言模型进行编码的文本匹配模型。
在借助外部知识方面, 通过构建外部知识以丰富语义的方式来增强文本语义表征能力。外部知识通常为结构化知识库[6–7], 其构建需要大量人工参与, 来增加匹配模型训练的成本。
在增加差异特征方面, 将字面、语法以及语义等层面的差异信息作为特征添加到匹配模型中, 达到增强匹配效果的目的。在基于语法的差异特征提取工作中, 针对句法关系和依存关系等语法类型提取差异特征并增强文本的表征。在句法关系方面, Qiu 等[8]和 Yadav 等[9]将未匹配的谓词三元组作为句子匹配的差异特征, 通过标记差异特征的重要程度来判断语句是否相似。在依存关系方面, Lintean等[10]通过计算共同依赖项和非共同依赖项在分值上的比值进行相似度判断。Chi 等[11]将共同依赖项和非共同依赖项进行编码后输入神经网络, 进行语义判断。在基于语义的差异特征提取工作中, 提取语句中词语的语义差异, 并增强文本的语义表征。Wang 等[12]通过静态编码方式提取词义表示差异, 然后通过卷积网络学习新的语义表征。Liu 等[13]提出将语句间的非公共词汇输入编码器来获得差异特征表示。
在以上三类方法中, 增加差异特征的方法可适配到匹配模型的任何结构上, 也不需要借助外部知识。并且, 以特征增强的方式提升匹配效果, 对应的模型复杂度和训练成本也会更小。然而, 在目前研究中, 基于语法的差异特征提取只能捕获浅层差异信息, 且受限于语法分析器的分类上限。基于语义的差异特征提取只能捕获到字面不同语义相同这一种情况下的差异信息, 并且大多使用静态编码, 未考虑词汇在具体语境下的词义[12–13]。
针对上述问题, 本文从语境语义角度提取差异特征, 捕获深层差异信息, 构建一种融合语境语义差异特征的短文本匹配模型。该模型在不借助于外部知识的前提下, 可以提取字面不同而语义相同和字面相同语义不同而两种情况下短文本间语境语义的差异特征, 通过网络学习进行差异特征表示, 与文本匹配的语义表示融合后进行语义判断。
1 研究方法
1.1 模型框架
如图 1 所示, 本文提出的模型框架, 由以下 4部分组成: 句对语境编码器、差异特征提取器、差异特征编码器以及门控融合。句对语境编码器选择BERT[14]系列语言模型作为基础短文本匹配模型, 输出语义匹配的向量表示, 同时也输出文本的动态编码。差异特征提取器基于 Transformer[15]改造得到, 被称为 Diff Transformer。Diff Transformer 包含差异分值计算、差异类型判别和差异特征提取 3 部分, 以判别的方式, 提取不同类型下的差异特征。差异特征编码器利用卷积神经网络, 从提取到的差异特征中学习到关键差异特征并输出特征表示。最后用门控方式, 将文本匹配的语义表示和差异特征表示融合后, 输出相似度判断结果。
1.2 句对语境编码器


其中,–1表示BERT中第–1层Transformer的隐层输出。
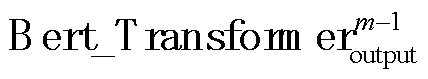
1.3 差异特征提取器
差异特征提取器从BERT的第层Transformer开始, 并行构建层Diff Transformer。Diff Trans-former在Transformer结构上进行两点改造: 1)将注意力分值计算改造为差异分值计算; 2)将 MASK 矩阵的掩码功能改造为差异类型判别功能。最后, 基于差异类型的判别结果, 选择对应的差异分值, 提取得到差异特征, Diff Transformer的详细结构如图2所示。

图1 模型框架图
1.3.1 差异分值计算
在 Transformer 的网络结构中, 自注意力机制分值矩阵(self_attention_score)的计算过程以及点积相似度(dot_similarity_score)的计算过程都通过内积实现:


在自注意力分值的计算过程中, 矩阵与的转置相乘, 得到中每个 token 向量以及中每个token 向量的点积相似度, 因此得到的自注意力分值同时也是相似度量的分值。通过式(3)得到语句S1 的 token 序列和 S2 的 token 序列之间的相似分值矩阵, 分值范围为 0~1。本文定义 Sim_score∈RÍ(=+)表示相似分值矩阵, Dissim_score∈RÍ表示不相似分值矩阵:
Sim_score = self_attention_score, (4)
Dissim_score = (1 – Sim_score)。 (5)
Diff Transformer 结构的示例如图 3 所示,Sim_ score 矩阵中的分值表示语句 S1 与语句 S2 的 token序列之间的相似分值, Dissim_score 矩阵中的分值表示语句 S1 与语句 S2 的 token 序列之间的不相似分值。
1.3.2 差异类型判别
在差异分值计算模块中, 我们得到语句 S1 的token 序列和语句 S2 的 token 序列之间的相似分值矩阵和不相似分值矩阵, 但是对于同一个 token, 最终只保留一个分值, 因此设计差异类型判别矩阵来判断这些 token 对应的差异类型, 根据判别结果, 选择保留相似分值或不相似分值。判别规则如下。
1)判别的两个 token 来自不同的语句。
2)当两个 token 所在的词语字面一致时, 需考虑语义差异的程度, 用不相似度量分值表示。
3)当两个 token 所在的词语字面不一致时, 需考虑语义相似的程度, 用相似度量分值表示。

图2 Diff Transformer结构图
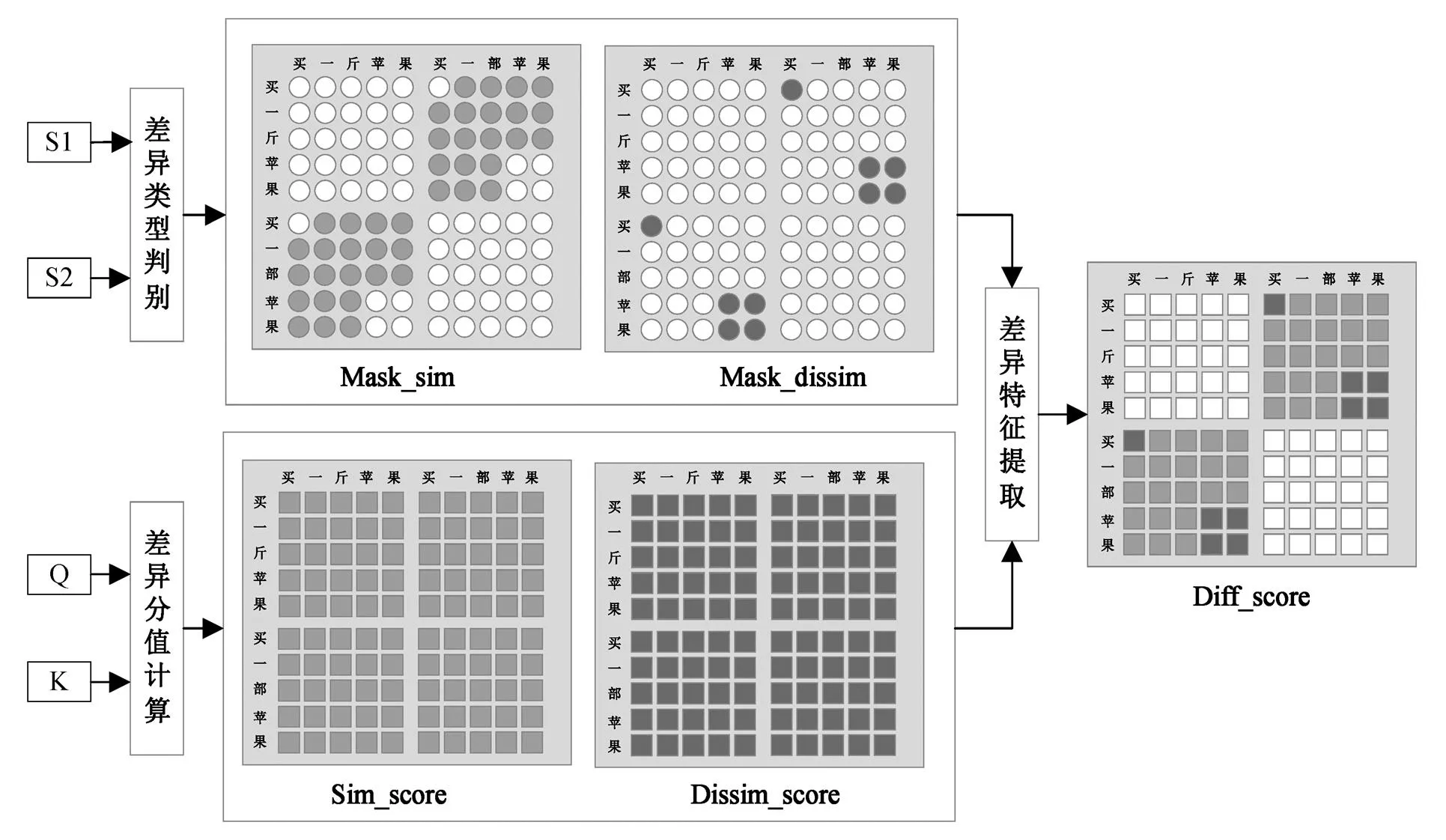
图3 Diff Transformer示例图
基于设定的判别规则, 输入语句 S1 和 S2 的token 序列、词序列和词长序列分别表示如下: token序列 S1token=(11,12,13, …,1p), S2token=(21,22,23, …,2p); 词序列 S1word=(11,12, …,1x), S2word=(21,22, …,2y); 词长序列 S1word_length=(11,12, …,1x), S2word_length= (21,22, …,2y)。其中,1i表示 S1 中的词,2j表示S2 中的词。
例如, 语句 S1 为“买一斤苹果”, 语句 S2 为“买一部苹果”, 对应的 token 序列、词序列和词长序列分别表示如下: S1token= (买, 一, 斤, 苹, 果), S2token= (买, 一, 部, 苹, 果); S1word= (买, 一斤, 苹果), S2word= (买, 一部, 苹果); S1word_length= (1, 2, 2), S2word_length= (1, 2, 2)。依次取出语句 S1 中的词, 然后与 S2 中的所有词进行差异类型判别。根据判别规则 2, 语句 S1 的第 3 个词“苹果”与语句 S2 的第 3 个词“苹果”字面一致, 所以判别为字面相同而语义不同, 则提取两个词语中 token 间的不相似分值。
差异判别矩阵的实现需要构建一个交互可见的标识矩阵 Mask_interaction。在该矩阵中, 语句 S1和 S2 只对对方可见(赋值为 1), 对自身不可见(赋值为 0)。然后构建两个判别矩阵, 分别为针对字面相同语义不同的判别矩阵 Mask_dissim 和针对字面不同语义相同的判别矩阵 Mask_sim。将标识矩阵和两个判别矩阵分别对位相乘后, 对判别矩阵中的值进行更新。具体步骤如下(⊕代表矩阵对位相加, ⊗代表矩阵对位相乘, •代表矩阵相乘)。
1)在判别矩阵 Mask_dissim 中, 当两个词语字面一致时, 矩阵中对应位置的值为 1, 表示要保留不相似分值。在判别矩阵 Mask_sim 中, 当两个词语字面不一致时, 对应位置的值为 1, 表示要保留相似分值。

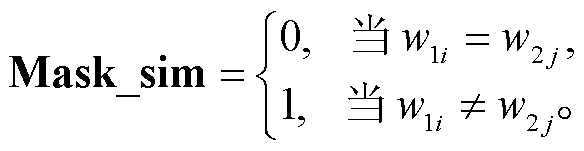
2)我们将 S1 和 S2 交互可见的判别矩阵 Mask_ interaction 分别与两个判别矩阵相乘, 得到最终的差异判别矩阵 Mask_dissim 和 Mask_sim。
Mask_dissim=Mask_dissim⊗Mask_interaction, (8)
Mask_sim=Mask_sim⊗Mask_interaction。 (9)
因为 Mask_dissim 和 Mask_sim 是从词粒度的判别得到, 而模型是以 token 粒度进行拆分和编码, 所以需要将词粒度的判别矩阵和 token 级的编码进行统一: 借助于词长序列, 将词级判别矩阵中的值按照词长复制后, 转换为 token 级别的判别矩阵。
如图 3 所示, 在 Mask_sim 判别矩阵中, 浅灰色圆点表示判别两个 token 之间为字面不同而语义相同, 保留相似分值。在 Mask_dissim 判阵矩阵中, 深灰色圆点表示判别两个 token 之间为字面相同而语义不同, 保留不相似分值。浅灰色和深灰色圆点在判别矩阵中的值设为 1, 白色圆点在判别矩阵中的值设为 0。
1.3.3 差异特征提取
通过差异分值计算, 可以得到用来衡量不同token 的相似分值和不相似分值; 通过差异类型判别, 可以得到用来判别不同 token 保留分值类型的判别矩阵。基于判别矩阵和分值矩阵, 得到差异分值矩阵 Diff_score。
1)分别将相似判别矩阵与相似分值对位相乘, 再与不相似判别矩阵和不相似分值对位相乘的结果相加, 得到差异分值矩阵 Diff_score, 图 3 中, 灰色部分代表差异分值矩阵 Diff_score 计算的结果。
Diff_score=(Mask_dissim⊗Dissim_score)⊕
(Mask_sim⊗Sim_score)。 (10)
2)差异分值矩阵与 Value 相乘, 得到所有 token差异特征的隐层表示diff:
_diff = Diff_score·Value。 (11)
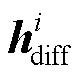


1.4 差异特征编码器
差异特征提取器中输出的是 Diff Transformer中提取到的所有 token 的差异特征, 此时的差异特征是分散到各个 token 中, 并且不是所有差异特征都有用。将这些 token 的差异特征表示向量输入卷积网络中, 进行关键差异特征的学习, 最终输出蕴含所有关键差异特征的表示向量。
定义一个卷积核的列表{W},代表卷积核的个数。每一个卷积核的大小为××,是输入 token向量的维度,是输入的通道数(1≤≤,是 Diff Transformer 训练的最大层数)。代表卷积的窗口, 通过 n-gram (=3, 4, 5)设置 3 种类型的卷积窗口。将第~层到第层 Diff Transformer 的差异特征向量拼接为卷积网络的多通道输入。

将多个卷积核经过一层卷积后拼接到一起, 然后做最大值池化处理, 得到最终的差异特征表示Diffemb:


1.4 门控融合
借鉴 GSD 模型[13]的融合方法, 用门控方式, 将句对语境编码器输出的语义表示 CLSemb与差异特征编码器输出的差异特征表示 Diffemb融合后, 再进行语义相似判断。
1)分别对初始的 CLSemb和 Diffemb进行共享权重的非线性转换, 转换后得到cls和diff:

2)同时对 CLSemb和 Diffemb以非共享权重的方式进行门转换, 得到

3)通过加权变换的方式来控制语义表示和差异特征表示输入的信息量:

从式(19)可以看出,可以对语义表示和差异表示进行有选择的融合。融合后的信息经过一个全连接层后, 最终输出语义是否相似的判别结果。
2 实验分析
2.1 实验数据
本文实验分别在公开域数据集和垂直域数据集上进行。公开域数据集选择中文问题匹配语料库(LCQMC)[16], 是基于海量百度问题构建的问题匹配数据集。LCQMC 数据集包含 28.3 万条训练语料、1.25 万条测试数据和 0.8 万条验证数据。垂直域数据集选择 BQ 数据集[17], 是金融领域下智能客服问句匹配数据集。BQ 数据集包含 10 万条训练语料、1 万条测试数据和 1 万条验证数据。
2.2 实验设置与参数选择

2.3 实验结果与分析
2.3.1 对比实验
1)与基线模型的对比实验: 在借助外部知识方面, 以 LET[6]和 KBERT[7]作为基线模型; 在增加差异特征方面以 GSD[13]作为基线模型。LET 和 KBERT均是借助外部 HowNet 知识[18]的文本匹配模型, 区别在于 KBERT 将外部知识直接嵌入文本中, 通过预训练任务学习语义表征; LET 用词格图的方式, 将外部知识输入到图注意力网络中, 通过短文本匹配任务学习语义表征。GSD 是基于门控语义差异的文本匹配模型, 与本文提出的 Diff 模型在整体设计上类似, 不同之处在于 Diff 模型不是单独对词汇编码, 而是保留词语在具体语境下的语义, 同时还兼顾字面相同而语义不同以及字面不同而语义相同这两种情况。
实验结果如表 1 所示, 可以看出, Diff 比 GSD在准确率上更具优势, 说明提取词语在具体语境下的语义差异特征, 比单独提取词语的差异特征效果好。Diff 的准确率比 KBERT 高, 说明增加差异特征比直接嵌入外部知识更具有优势。Diff 比 LET的准确率有所下降, 说明当对嵌入的外部知识按照词粒度进行充分的学习时, 效果要优于特征的加入。

表1 Diff模型和相关研究中基线模型的对比实验(%)
说明: 粗体数字表示最佳结果。
2)与不同语言模型融合后的对比实验: 语言模型选择 BERT[14], BERT-wwm[19]和Chinese-BERT[20]。BERT-wwm 在预训练任务中使用全词 MASK 预测, 与 Diff 模型的粒度一致。Chinese-BERT 是目前最先进的语言模型。表 2 中, 从 Diff (BERT-base)和Diff (BERT-wwm)的实验对比来看, 词粒度的差异特征提取模型效果更具优势, 说明编码粒度上的统一可以使模型达到更好的匹配效果。从 Diff (BERT- base)和 Chinese-BERT 的实验结果对比来看, 相比于 Chinese-BERT (base)版, Diff 模型的效果更具有优势; 相比 Chinese-BERT (large), Diff 模型可以达到同样的匹配效果。但是, 在 BQ 数据集上, Diff 模型的效果低于 Chinese-BERT (large), 主要是由于预训练模型对文本编码的限制, Chinese-BERT 从汉字本身特性出发, 将汉字字形和拼音信息融入预训练过程中, 使模型更加综合地建立汉字、字形、读音与上下文间的联系, 在语义的深度和丰富性方面实现进一步提升, 因此在垂直域数据集上的正则化效果更加明显。

表2 Diff模型和BERT系列语言模型的对比实验(%)
此外, 通过设计参数矩阵对 Diff Transformer训练的层数和输入卷积网络的层数进行动态调参可以发现, 当为3,为 1 时, 在 LCQMC 数据集上达到最好的模型效果。当为 4,为 2 时, 在 BQ数据集上达到最好的效果。这是因为与LCQMC 数据集相比, BQ 数据集语料量级更小且内容更专业,模型训练难度也相对更大, 因此在提取差异特征的训练过程中, 对训练深度的要求也更高。这也体现 Diff 模型可以根据训练语料的难易程度灵活地调整训练的层数。
2.3.2 消融实验
我们在 LCQMC 数据集上, 设计以下 3 组消融实验。
1)是否有差异分值矩阵: 取消差异分值之后, Diff Transformer 的结构只保留语句间相互可见的相似度量分值。该实验用于评估以相似度量分值来代表字面不同的语义相同以及以不相似度量分值来代表字面相同而语义不同的差异特征时对匹配效果的影响。
2)是否为词级差异判别: 取消词语级差异判别后, Diff Transformer 的结构变为 token 级别的差异判别。该实验用于评估基于词粒度的差异特征对匹配效果的影响。
3)是否为门控融合: 取消门控融合后, 在融合部分以最简单的拼接方式进行融合。该实验用于评估当语义表示和差异特征表示以不同占比进行融合时对匹配效果的影响。
从表 3 的消融实验结果来看, 差异分值、词语级差异判别以及门控融合对模型效果均产生积极影响, 其中差异分值对模型效果的影响最大。这说明融合语义差异特征的短文本匹配模型中的改造点对匹配效果均有正向提升, 可以验证在编码粒度和提取粒度均统一的前提下, 用相似度量值和不相似度量值来衡量差异特征, 并有选择地控制差异特征和语义表示的输入占比, 可以让匹配模型得到性能最优化。

表3 Diff模型的消融实验(%)
说明: 粗体字表示消融对比实验的变量。

表4 实验样例
3 结语
本文从语境语义角度提取差异特征, 捕获深层差异信息, 构建一种融合语境语义差异特征的短文本匹配模型。该模型可以提取字面不同而语义相同以及字面相同而语义不同两种情况下, 短文本间语境语义的差异特征, 通过网络学习进行差异特征表示, 与文本匹配的语义表示用门控方式融合后进行语义判断, 达到增强匹配效果的目的。实验结果表明, 本文提出的短文本匹配模型在不增加外部数据的前提下, 在基准中文匹配数据集上均达到与已有先进模型相同的效果。
未来工作中, 我们将围绕字面与语义一致情况下的特征表示与融合展开相关工作, 进一步提升短文本匹配模型的效果。
[1]Sujatha B, Raju S V. Ontology based natural language interface for relational databases. Procedia Computer Science, 2016, 100(92): 487–492
[2]Huang P S, He X, Gao J, et al. Learning deep struc-tured semantic models for web search using click-through data // Proceedings of the 22nd ACM inter-national conference on Information & Knowledge Management. San Francisco, 2013: 2333–2338
[3]Shen Y, He X, Gao J, et al. A latent semantic model with convolutional-pooling structure for information retrieval // Proceedings of the 23rd ACM international conference on conference on information and know-ledge management. Shanghai, 2014: 101–110
[4]Hu B, Lu Z, Li H, et al. Convolutional neural network architectures for matching natural language sentences // Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2. Kuching, 2014: 2042–2050
[5]Chen Q, Zhu X, Ling Z H, et al. Enhanced LSTM for Natural Language Inference // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Canada, 2017: 1657–1668
[6]Lyu B, Chen L, Zhu S, et al. LET: linguistic know-ledge enhanced graph transformer for Chinese short text matching [C/OL]. (2021–02–05) [2022–08–03]. https://doi.org/10.48550/arXiv.2102.12671
[7]Liu W, Zhou P, Zhao Z, et al. K-BERT: enabling language representation with knowledge graph // Pro-ceedings of the AAAI Conference on Artificial Intelli-gence. New York, 2020: 2901–2908
[8]Qiu L, Kan M Y, Chua T S. Paraphrase recognition via dissimilarity significance classification // Procee-dings of the 2006 Conference on Empirical Methods in Natural Language Processing. Sydney, 2006: 18–26
[9]Yadav R, Kumar A, Kumar A V, et al.Conceptuali-zation of sentence paraphrase recognition with se-mantic role labels // Proceedings of the International Conference on Data Science (ICDATA).The Steering Committee of The World Congress in Computer Sci-ence, Computer Engineering and Applied Computing (WorldComp), Las Vegas, 2012: 1
[10]Lintean M C, Rus V. Paraphrase identification using weighted dependencies and word semantics. Informa-tica, 2010, 34(1): 19–29
[11]Chi X, Xiang Y, Shen R. Paraphrase detection with dependency embedding // 2020 4th International Con-ference on Computer Science and Artificial Intelli-gence. Stockholm, 2020: 213–218
[12]Wang Z, Mi H, Ittycheriah A. Sentence similarity learning by lexical decomposition and composition // Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. Osaka, 2016: 1340–1349
[13]Liu X, Chen Q, Wu X, et al. Gated semantic diffe-rence based sentence semantic equivalence identifi-cation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 2770–2780
[14]Devlin J, Chang M W, Lee K, et al. BERT: pre-trai-ning of deep bidirectional transformers for language understanding // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech-nologies. Minneapolis, 2019: 4171–4186
[15]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Advances in Neural Information Pro-cessing Systems. California, 2017: 5998–6008
[16]Liu X, Chen Q, Deng C, et al. LCQMC: a large-scale chinese question matching corpus // Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, 2018: 1952–1962
[17]Chen J, Chen Q, Liu X, et al. The BQ corpus: a large-scale domain-specific chinese corpus for sentence semantic equivalence identification // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 4946–4951
[18]Dong Z, Dong Q. HowNet — a hybrid language and knowledge resource // International Conference on Natural Language Processing and Knowledge Engi-neering, Beijing, 2003: 820–824
[19]Cui Y, Che W, Liu T, et al. Pre-training with whole word masking for chinese BERT. IEEE/ACM Tran-sactions on Audio, Speech, and Language Processing, 2021, 29: 3504–3514
[20]Sun Z, Li X, Sun X, et al. ChineseBERT: Chinese pre-training enhanced by Glyph and Pinyin information // Proceedings of the 59th Annual Meeting of the Asso-ciation for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Bangkok, 2021: 2065–2075
A Short Text Matching Model Incorporating Contextual Semantic Differences
ZHANG Wenhui, WANG Meiling, HOU Zhirong†
ICBC Technology Co Ltd, Beijing 100029;†Corresponding author, E-mail: houzr@tech.icbc.com.cn
Short text matching is often unable to accurately obtain the degree of semantic similarity between sentences when the semantic difference of the same wording and the semantic equivalence of the different wording. To solve this problem, the paper proposes a short text matching model which integrates contextual semantic differences. In this model, language models from the BERT series are utilized as a basic matching model, a novel Diff Transformer structure is implemented for extracting difference feature, and a gate mechanism is applied to integrate basic semantic representations and difference feature for a better matching effect. The model achieves the effect of advanced models on Chinese test datasets.
short text matching; difference feature; context semantic; Diff Transformer
