基于单词领域特征敏感的多领域神经机器翻译
2023-02-10黄增城满志博张玉洁徐金安陈钰枫
黄增城 满志博 张玉洁 徐金安 陈钰枫
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
10.13209/j.0479-8023.2022.063
国家自然科学基金(61876198, 61976016和61976015)资助
2022-05-13;
2022-07-29
基于单词领域特征敏感的多领域神经机器翻译
黄增城 满志博 张玉洁†徐金安 陈钰枫
北京交通大学计算机与信息技术学院, 北京 100044; † 通信作者, E-mail: yjzhang@bjtu.edu.cn
鉴于现有基于单词的领域特征学习方法在领域识别上的精度较低, 为提高领域判别和提供准确的翻译, 提出一种单词级别的领域特征敏感学习机制, 包括两方面: 1)编码器端的上下文特征编码, 为了扩展单词级别的领域特征学习范围, 引入卷积神经网络, 并行提取不同大小窗口的词串作为单词的上下文特征; 2)强化的领域特征学习, 设计基于多层感知机的领域判别器模块, 增强从单词上下文特征中获取更准确领域比例的学习能力, 提升单词的领域判别准确率。在多领域 UM-Corpus 英–汉和 OPUS 英–法翻译任务中的实验结果显示, 所提方法平均 BLEU 值分别超过强基线模型 0.82 和 1.06, 单词的领域判别准确率比基线模型分别提升 10.07%和 18.06%。对实验结果的进一步分析表明, 所提翻译模型性能的提升得益于所提出的单词领域特征敏感的学习机制。
多领域神经机器翻译; 领域特征敏感; 上下文特征; 领域判别
得益于深度学习的飞速发展, 神经机器翻译(Neural Machine Translation, NMT)模型在各种翻译任务中展现出卓越的性能(state-of-the-art)[1–4]。随之而来的是专业领域对高质量机器翻译的需求日益增加, 因此, 多领域神经机器翻译(multi-domain NMT)成为新的研究热点[5]。
多领域神经机器翻译旨在设计和构建一个统一的跨领域 NMT 模型, 能够自动判别输入句子的所属领域并进行相应的翻译。最基本的方法是合并多个领域的双语平行数据, 训练一个统一的翻译模型。虽然数据来自不同领域, 但模型可以通过学习具有语言共性的特征而得到加强。然而, 不同领域的数据会因文本风格与句子结构上的差异, 导致其中某一领域的翻译知识无法得到有效的学习, 影响模型在该领域的翻译性能。Haddow 等[6]已证实, 如果某个领域拥有足够的高质量训练数据, 可以在该领域训练出性能较好的模型, 但对于统一模型的性能, 可能由于多领域数据存在异质性, 其性能比仅在该领域数据上训练的模型差。因此, 构建高质量多领域神经机器翻译, 仍然是一项具有挑战性的任务。
人们在阅读句子时, 通常会根据上下文判断所属领域, 所以研究人员将上下文作为领域特征, 进行领域判别的建模。同时, 基于翻译对领域有较强依赖性的特点, 多领域 NMT 常采用领域判别与翻译联合学习的框架[7–9]。基于单词领域特征编码的多领域 NMT 考虑了从每个单词学习领域特征, 相比基于句子领域特征编码的多领域 NMT, 性能有较大的改进。但是, 当句子中不存在有明显领域倾向性的单词时, 这些模型难以给出正确译文。
表 1 给出法律和教育两个领域的例句, 两个句子都包含单词“executive”, 但在汉语译文中分别对应不同译语“执行”和“行政”, 反映了翻译对领域依赖的现象, 即“executive”在法律领域应翻译成“行政”, 在教育领域应翻译成“执行”, 但常规的多领域NMT 模型会翻译为“执行”。通过观察法律领域的例句, 我们发现“executive authority”这种颗粒度较大的词串具有更确定的语义, 从而指示法律领域的倾向性更强。因此本文考虑在基于单词领域特征编码的多领域 NMT 框架中, 将这种词串也作为一种领域特征, 辅助模型进行正确翻译, 如表 1 中本文模型输出所示。
基于上述观察, 本文提出单词领域特征敏感的多领域神经机器翻译模型, 旨在进一步解决单词翻译歧义问题以及专有名词误译问题。该模型在现有单词级别领域特征学习的多领域 NMT 框架[9]的基础上新增以下两个模块: 在编码器端设计领域上下文敏感机制(domain context sensitive mechanism, DCSM)扩展单词级别领域特征学习层面, 加强单词上下文领域特征的提取; 在编码器和解码器中, 设计强化的领域判别机制(reinforced domain discri-minative mechanism, RDDM), 替换原有领域判别器, 进一步提升单词的领域判别准确率, 强化单词的领域特征学习。
1 相关工作
多领域 NMT 模型, 按照学习领域特征的方式, 分为基于句子级别和基于单词级别两类。
基于句子级别的多领域 NMT 方法是在句子层面进行领域特征建模。Kobus 等[10]提出领域控制方法, 为每个源句附上领域标签, 达到为模型融入领域信息的目的。Britz等[7]在编码器外部添加一个领域判别器, 对编码器输出的嵌入表示判别其源句领域, 采用翻译模型与领域判别器联合学习的方式, 将领域知识融入模型表示。基于句子级别融合领域特征的方法简单直观, 但是无法学习单词的领域特征表示, 导致模型无法提供更精确的单词翻译。
基于单词级别的多领域 NMT 方法更看重单词携带的领域特征。Pham 等[11]将词嵌入表示划分成通用领域部分和特定领域部分, 训练时不同领域的数据只激活其对应的特定领域部分, 与通用领域部分一起学习, 达到在单词的词嵌入表示中融入领域特征的目的。Zeng 等[8]在编码器中通过两个不同的注意力机制为源句的表示生成两种门控向量, 构建特定领域的表示和通用领域的表示。此外, 他们利用目标端领域判别器的注意力权重, 调整目标函数, 以便细化模型训练。Jiang 等[9]提出了领域比例(do-main proportion)的概念, 为每个单词设置一个领域比例向量, 通过训练获得不同领域的权重; 然后重新设计 Transformer 模型[4], 在 Transformer 每一层中设置不同的多头注意力机制, 对不同领域进行关注, 并通过领域比例, 对模型参数逐层进行加权平均, 实现领域混合。通过该方法, 可以实现有效的领域知识共享, 并捕获细粒度的特定领域知识, 解决先前方法强制使用一个编码器学习跨所有领域的共享嵌入表示带来的缺乏对每个领域适应性的问题。但是, 在目标领域增多时, 该模型会出现翻译质量退化的情况。Zhang 等[12]提出一种基于领域感知自注意力机制, 每个单词在拥有语义向量的基础上还有领域向量, 学习到的领域向量表示与语义向量表示一起融入 NMT 的编码器与解码器中, 强制NMT 模型同时编码和解码语义信息与领域信息。

表1 多领域NMT模型在英–汉教育和法律领域上的翻译例子
本文基于 Jiang 等[9]的工作, 围绕提取单词上下文特征与单词级领域比例编码方式开展研究。本文模型与该工作的不同之处在于, 我们首先提出一种单词级别的领域特征学习机制, 通过扩展单词级别的领域特征学习范围, 在编码器引入多个卷积神经网络[13], 并行提取不同大小窗口的上下文作为单词的额外特征, 同时设计基于多层感知机的领域判别器改进领域编码方法, 学习单词级别强化的领域比例(reinforced domain proportion), 替换原有领域比例, 进一步提升单词的领域判别准确率, 强化单词的领域特征学习。
2 基于单词领域特征敏感的多领域神经机器翻译模型
为使模型有效地学习到单词的领域特征, 我们设计基于单词领域特征敏感的多领域翻译模型。一方面, 为扩展单词级别的领域特征学习范围, 引入领域上下文敏感机制(DCSM), 学习不同大小窗口的词串, 作为单词上下文特征; 另一方面, 为强化单词领域特征的学习, 设计强化的领域判别机制(RDDM), 通过联合学习的方式提升单词的领域判别准确率, 强化单词的领域特征学习。如图 1 所示, 模型整体框架以 Transformer 为基础进行设计, 编码器粉色部分为 DCSM 模块, 编码器与解码器绿色部分为 RDDM 模块。
2.1 领域上下文敏感机制
我们发现, 如果一些单词本身不具突出的领域特性, 但其周围的单词拥有较强的领域特性, 将它们进行组合学习之后, 可以对当前单词起到消除领域歧义的作用; 如果当前单词本身没有显著的领域特性, 并且其周围的单词领域特性也不强, 但将它们组合成词串后, 可以提供较清晰的领域归属性。为此, 我们将扩大当前单词的领域特征学习范围引入 DCSM, 具体结构如图 2 所示。相比已有模型只关注单个孤立的单词领域特征, 本文模型进一步学习单词上下文表示, 因此能够更好地学习到单词的领域特征。
根据颗粒度较大的词串具有更确定的语义, 借鉴 Gao 等[14]在翻译模型中加入卷积神经网络提取不同粒度的字符特征的思想, 我们引入 3 种卷积网络, 从单词的上下文中并行提取单词的领域特征, 给予单词更确定的领域特征, 则 DCSM 的形式化表示 如下:
DCSM() = MaxPool([Conv(,1)||Conv(,2||
Conv(,3)])+, (1)
其中,= (1,2, …,s)∈R×d为源句的嵌入表示,为句子长度,为 Transformer 模型嵌入表示大小, MaxPool 为最大池化函数, Conv(,w),∈{1, 2, 3}表示对源句在卷积核大小为w时的卷积操作, [||]表示拼接操作。具体地, 对于每个卷积网络, 我们使用与模型嵌入表示一样大小的卷积核数量, 并且使用 same padding 的方式, 在提取多通道的单词上下文领域特征的基础上, 维持卷积的输出形状不变。在进行 3 个卷积网络并行提取单词上下文领域特征后, 我们对这些特征在嵌入维度进行拼接, 最后进行最大池化。通过在嵌入维度的拼接与最大池化的组合方式, 可以学习到单词上下文领域特征中最突出的部分。在提取到单词的上下文领域特征后, 为保留单个单词的语义特征, 我们最后使用残差连接, 对 DCSM 的输入与输出进行相加。
2.2 强化的领域判别机制
领域比例是 Jiang 等[9]提出的概念, 作为一种可学习的单词在每个领域的权重向量, 可以为Trans-former 内的模块融入单词级别的领域特征。对于一个词嵌入向量, 如果训练数据拥有个领域, 那么该单词的领域比例可由式(2)进行学习。
D()=(1−)Softmax()+/, (2)
其中∈R,∈R×为可训练参数,Î(0,1)为平滑参数。单词的领域比例不仅作为领域特征为模型共享知识, 同时也是领域判别器的预测概率分布, 用于预测领域标签。通过判别器与翻译模型联合学习方式, 对领域知识与翻译知识进行融合。

图1 基于单词领域特征敏感的神经机器翻译模型

图2 领域上下文敏感机制具体结构
我们在 Jiang 等[9]模型的基础上加入 DCSM 进行初步实验, 发现模型的领域判别准确率有一定的提升, 但受限于该领域比例学习机制结构简单, 导致模型出现学习瓶颈。单词的领域判别准确率虽有提升, 但只能维持在较低的水平。另外, 同样受领域比例学习机制结构简单的影响, 模型未能充分利用这些额外的领域特征, 导致模型的翻译性能未能有效地提升。因此, 为提高单词的领域识别精度, 并充分利用 DCSM 学习到的上下文特征, 我们提出强化的领域判别机制(RDDM), 学习每个单词强化的领域比例, 代替 Jiang 等[9]模型中的领域比例。相比之下, RDDM 可以为模型提供更准确的领域特征表示与提高单词领域识别精度。对于任意的词嵌入向量, RDDM 计算每个单词强化的领域比例用式(3)表示:
RDDM()=(1−)Softmax(2(max(0,1+1)+
min(0,1+1))+2)+/, (3)
其中,1∈R×,1∈R,2∈R×和2∈R为可训练参数,为控制变换矩阵投影倍数的超参数,为平滑参数,为可训练的激活函数参数。为避免输入特征为负数时特征被直接置零, 我们在 ReLU函数基础上加入动态学习的权重来学习负值的特征, 保证 RDDM 中某些单元可以继续训练。
通过 RDDM 学得每个单词强化的领域比例, 可以作为领域特征与模型表示一起融入模型每个模块中。例如, 在 Transformer 的 FFN 模块中, 对任意的输入序列以及 RDDM 输出对应的强化领域比例, 输入序列首先经过 FFN 的第一层全连接网络, 将输入表示投影到与领域个数倍数大小的表示, 然后使用作为权重, 通过对嵌入表示进行加权计算, 经过第二个全连接网络再进行类似运算, 得到最后融入领域特征的模型表示, 整个 FFN 进行两次加权平均, 计算过程如式(4)所示:


类似地, 如果将强化的领域比例融入 Transfor-mer 的多头注意力机制中, 则在进行放缩点乘运算的自注意力函数计算前, 先将其中多头注意力机制的查询序列和键序列以及值序列分别投影到原表示空间大小的领域个数倍数的空间中, 结合作为权重的强化领域比例, 分别对,和进行加权求和再投影, 最后进行注意力计算, 如式(5)~(8)所示:




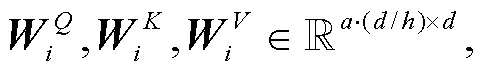
通过在编码器与解码每个模块前引入 RDDM, 可以让模型增强从单词上下文特征中获取更准确领域比例的学习能力, 最终可以学得单词强化的领域比例, 从而提升模型对单词的领域判别准确率以及增强单词的领域特征学习, 同时可以防止深层编码器–解码器结构因多次计算传递而导致单词的领域特征衰减。
2.3 模型训练
本文模型采用多任务联合学习的训练方式, 分为翻译任务与领域判别任务。假设参数表示本文模型中的可学习参数, 本文通过最小化以下目标函数完成模型的训练:

其中,MT()为神经机器翻译模型的交叉熵损失;CLS()为领域判别器的交叉熵损失, 即 RDDM 作为领域判别器学得单词的强化领域比例后充当预测单词领域的概率分布, 用于计算与单词所属领域标签之间的交叉熵损失;为领域判别损失的权重参数, 本文模型设置为 1.0。
3 评测实验与结果分析
3.1 实验数据
我们在两个多领域翻译任务中验证本文方法的有效性。
1)英语–汉语: 本文使用 UM-Corpus 数据集[15]的 5 个领域进行实验, 包括 Education, Law, News, Science 和 Spoken。
2)英语–法语: 本文使用 OPUS 数据集[16]中的3 个领域进行实验, 包括由欧洲中央银行文件制成的数据 ECB、由欧洲药品管理局文件制成的数据EMEA 以及由欧盟立法文件制成数据 JRC。
实验数据的训练集、验证集和测试集的统计如表 2 所示。我们对数据集进行预处理, 首先对数据进行去重和移除非打印字符; 然后使用开源工具包 MOSES[17]对句子进行标点符号规范化, 并对英语和法语句子进行标记化; 同时使用 Jieba①https://github.com/fxsjy/jieba工具对汉语句子进行分词; 最后使用 BPE[18]对预处理好的平行数据进行子词切分。
关于本文实验中使用的评测指标, 我们使用SacreBLEU 工具[19]计算模型生成译文的 BLEU 值, 另外, 为了评测本文模型与 Jiang 等[9]模型对单词领域比例学习效果, 我们使用领域分类准确率曲线评估模型。在模型推理生成译文阶段, 我们对模型使用波束搜索, 波束大小设为 5。
3.2 对比模型与实验设置
在多领域神经机器翻译中, 联合所有领域数据训练翻译模型是主流的框架。另外, 利用单一领域数据, 通过训练也可以得到该领域的翻译模型。我们根据模型对数据领域特征的学习方式, 将多领域翻译模型分为基于句子级别和基于单词级别两种方式。基于以上考虑, 本文设计并复现相应的对比模型如下。
1)Single: 基于 Transformer 使用单一领域的数据进行训练, 实现在单一领域上的翻译模型。
2)Mixed: 基于 Transformer 使用所有领域的混合数据进行训练, 实现统一的多领域神经机器机器翻译模型。
3)Discriminator(Disc): 由 Britz 等[7]提出在句子级别编码领域特征, 在编码器外部添加领域判别器进行领域特征表示学习。

表2 数据集统计信息
4)Adversarial Discriminator (AdvL): 在 Disc 的基础上, 对从判别器到编码器反向传播过程的梯度取相反数, 从而减弱模型的领域区分度, 增强共享知识的学习。
5)Partial Adversarial Discriminator (PAdvL): 在句子级别上, 基于 Disc 和 AdvL 联合两种方法进行领域特征表示学习。
6)Word-level Adaptive Layer-wise Domain Mi xing (WALDM): 由 Jiang 等[9]提出基于单词级别的领域编码模型, 在编码–解码器内部添加领域判别器, 从而学习单词的领域比例, 作为领域特征融入翻译模型。
本文所有模型均基于 Fairseqv0.10.2 工具[20]实现。实验中模型的超参数根据表 3 设定。基于这些超参数, 我们对所有模型使用 Adam 优化器[21], 并利用逆平方根算法来动态地调整学习率。
3.3 实验结果
表 4 为本文模型与对比模型在 UM-Corpus英-汉翻译任务上的实验结果。其中, Single 在 Law 和News 上 BLEU 值达到 71.83 和 33.39, 相较于其他模型, 达到最高水平, 这是因为单独训练一个领域数据不会引入额外的噪声。但是, 由于 Science 和Spoken 两个领域数据量较少, 且内容较为复杂, 只使用单一领域数据训练性能并不理想。虽然 Law与这两个领域的数据量相当, 但 Law 中的数据属于法律条文, 数据形式较为规范, 单独训练翻译模型的性能会更好[6]。Mixed 是多领域翻译模型的基本框架, 在 Education, Science 和 Spoken 领域, 相比Single 有所提升, 说明对于这些领域, 可以通过混合数据训练的方式来提高模型性能。

表3 实验超参数统计信息

表4 不同模型在英–汉翻译任务中的BLEU值对比结果
说明: 粗体数字表示在该领域上翻译性能最佳值, 加下划线数字为次高值, 下同。
在基于句子级别的多领域方法中, Disc, AdvL和 PAdvL 模型比 Mixed 模型在 Law, Science 和Spoken 领域均有提升。并且, Disc 和 AdvL 模型在Spoken 领域 BLEU 达到 28.70, 与其他模型相比, 达到最高水平。在基于单词级别的领域编码方法中, WALDM 在所有领域都比 Mixed 模型性能好, BLEU值比 Mixed 平均提高 1.2, 效果显著。除 Spoken 领域外, 本文模型 4 个领域均超过 WALDM, 并且所有领域的平均 BLEU 值提高 0.82, 达到所有模型中平均性能的最高水平。此外, 本文模型在 Law 领域与最高水平的 Single 模型性能接近, BLEU 值比WALDM高 4.1, 效果提升明显。
与表 4 中的最高值相比, 本文模型在 News 和Spoken 领域的性能还有待提升。原因在于, 相比其他 3 个领域, 这两个领域数据的领域特征较弱。对专业性强的领域, 本文模型拥有提取更多领域特征给予模型学习的能力, 并生成准确的译文; 在 News或 Spoken 这种数据“混杂”的领域, 本文模型难以挖掘出领域特性强的信息, 导致性能表现不佳。
为进一步验证本文模型在其他语言对上的有效性, 我们还在 OPUS 英–法数据集上进行实验, 实验结果如表 5 所示。OPUS 的 3 个领域数据专业特性较强, Single 模型在所有领域均超过 Mixed 模型, 而 Disc, AdvL 和 PadvL 模型相比 Mixed 并无明显的改善。基于单词级领域编码的 WALDM 相比 Mixed在 3 个领域上 BLEU 值均有提升, 平均提升 1.35 个BLEU 值, 其中, 在 JRC 领域, WALDM 比 Single 模型提升 0.52 个 BLEU 值。本文模型在 3 个领域上均达到最高水平, 平均性能比 Single 提高 0.91 个BLEU 值, 比 WALDM 提高 1.06 个 BLEU 值, 表明本文模型在专业性强的领域能够学习到更多的上下文领域知识, 提升模型在每一个领域的翻译性能。

表5 不同模型在英–法翻译任务中的BLEU值对比结果
除使用 BLEU 值评估模型的翻译性能外, 我们还对本文模型与对比模型 WALDM 在不同翻译任务上的领域判别准确率进行对比。图 3 展示两个模型在训练过程中, 对英–汉和英–法翻译任务在验证集中单词领域的判别准确率曲线。随着迭代次数的增加, 两个翻译任务中 WALDM 的准确率曲线在上升过程中幅度波动较大, 本文模型可以有效地学习更多的领域特征, 让曲线的波动幅度较小, 具有一定的稳定性。并且, 本文模型在两个翻译任务的领域判别准确率均优于 WALDM, 在英–汉任务中, WALDM 的准确率最高为 53.22%, 而本文模型达到63.29%; 在英–法任务中, WALDM 的最高准确率为 64.96%, 本文模型达 83.02%, 提升幅度比在英–汉任务中更大, 可以更有效地证明本文方法在英–法任务中, 通过提高单词领域判别的准确率来强化单词的领域特征学习, 能够提高模型的翻译性能。
3.4 消融实验
与英–法任务相比, 英–汉任务的领域个数更多, 更具有挑战性, 能够体现本文所提方法的有效性。因此, 我们在英–汉翻译任务上进行消融实验。
3.4.1 不同模型参数量对实验结果的影响
考虑到本文模型会在一定程度上引入额外的模型参数, 我们设计消融实验来验证不同模型参数量对实验结果的影响(表 6), 其中, Mixed(big)表示对Mixed 中嵌入层大小以及FFN模块的隐藏层大小超参数进行增大后的模型。
如表 6 所示, Mixed (big)在 Mixed 基础上增加模型的参数量, 虽然能够在一定程度上提高性能, 但与基于词级别的翻译模型 WALDM 和本文模型相比, BLEU 值低 0.58 和 1.40, 仍有一定的差距。这是因为, 在一定程度上增加 Transformer 模型参数量没有针对多领域数据特性设计的模型更有效。另外, 与从 Mixed 到 Mixed (big)引入的参数量相比, 本文模型在 WALDM 基础上只引入少量参数, BLEU 值提升 0.82, 进一步说明本文模型可以在引入较少的参数量时获得优越的性能。
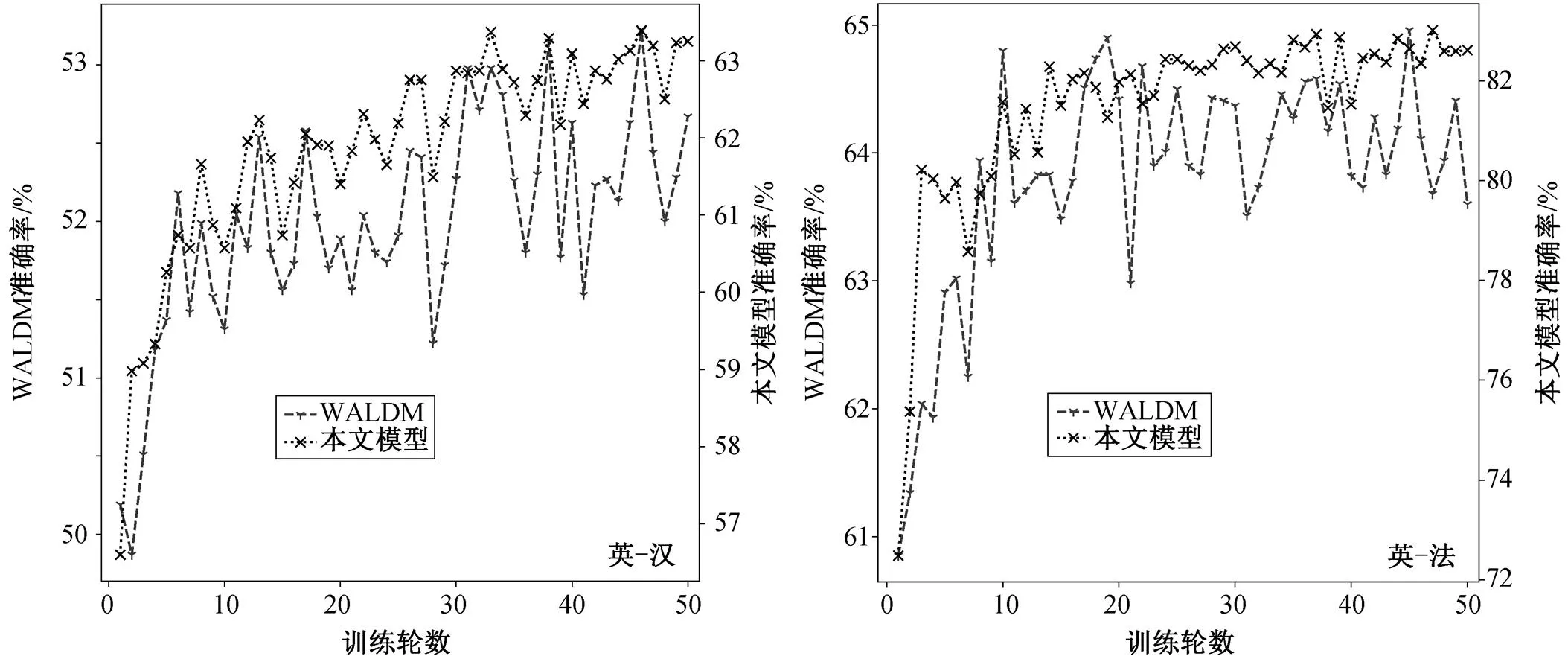
图3 本文模型与WALDM在不同翻译任务中领域判别准确率对比

表6 不同模型参数量实验结果的对比
3.4.2 DCSM 与 RDDM 对模型性能的影响
为了进一步探究 DCSM 和 RDDM 在整体机制中所起的作用, 我们对 DCSM 和 RDDM 进行消融实验, 结果如表 7 所示。与 2.2 节所提问题一致, 当本文模型去除 RDDM 后, 模型的领域判别准确率比本文模型下降 8.76%, 但相比 WALDM 的 53.22%,有 1.31%的提升, 并且 BLEU 值比本文模型下降1.07, 说明该模型虽然有 DCSM 学习不同的上下文作为领域特征, 但受限于没有使用本文模型的领域判别器模块, 未能充分地将这些额外的特征融入模型中, 引入许多不相关的噪声。当本文模型去除DCSM 后, 该模型判别准确率仅下降 1.82%, 说明RDDM 可以更有效地学习领域比例, 提升单词的领域判别准确率。该模型的 BLEU 值下降严重, 是因为缺少 DCSM 额外提取的单词上下文特征, 导致强化的领域判别器出现过拟合现象, 即模型在训练过程中单词领域的判别准确率高, 却没有 DCSM 学习到更多的单词对特定领域的特征进行补充, 最后在测试集的翻译性能较差。

表7 消融实验结果
说明: w/o表示去除。
相比单独使用 DCSM, 本文模型在使用 DCSM学习额外的领域特征之后, 可以被 RDDM 有效地利用, 而不会作为噪声影响模型性能。相比单独使用RDDM, 本文模型可以提供 DCSM 额外提取单词的上下文特征, 保证 RDDM 在学习过程不会出现过拟合的现象。通过在模型中有选择地去掉 DCSM 或RDDM, 可以发现本文模型中的 DCSM 与 RDDM互为补充, 因此在构建模型时, 二者应当作为整体同时使用。
3.5 实例分析
为了更公平和更直观地分析本文提出方法的有效性, 我们对不同模型生成的译文进行实例分析。表 8 给出从法律领域测试集中随机选取的例句, 同时列出 Mixed, WALDM 和本文模型生成的译文。可以看出, 本文模型能够更准确地翻译出领域特性强的短语, 例如, Mixed 和 WALDM 模型将“the Joint Declaration on the Question of Macao”翻译为“《澳门问题联合宣言》”, 而本文模型可以正确地翻译为“关于澳门问题的联合声明”。此外, 表 8 中其他加下划线部分显示, 领域特性强的词串均可以被本文模型正确地翻译, 使生成的译文与参考译文基本上一致。这证明我们基于单词领域特征敏感的多领域翻译模型可以通过拓展领单词的域特征学习范围以及强化领域特征学习, 进一步地提升模型的翻译能力。

表8 英–汉法律领域翻译实例对比
4 结语
本文针对翻译模型对句子中没有明显领域倾向性时孤立考虑单词领域特征以及领域判别准确率低的问题, 提出基于单词领域特征敏感的多领域神经机器翻译方法, 在关注词级别领域特征的基础上, 从单词的上下文学习多种粒度的领域特征, 扩展单词级别的领域特征学习范围, 增强模型编码词汇领域特征的能力, 随后进一步强化单词的领域特征学习, 最终提升单词的领域判别准确率。
与其他方法相比, 本文模型能够在学习单词的领域特征基础上额外提取不同粒度的上下文特征, 并为每个单词计算强化的领域比例, 指导生成正确的译文。实验结果表明, 在英–汉翻译中, 本文模型平均 BLEU 值比强基线模型提高 0.82, 领域判别准确率提升 10.07%; 在英–法翻译中, 平均 BLEU 值提升 1.06, 领域判别准确率提升 18.06%。上述结果表明, 翻译模型性能的提升得益于本文提出的单词领域特征敏感的学习机制。
在今后的工作中, 我们将围绕如何对领域上下文敏感机制的解释性进行研究, 进一步分析其具体意义和必要性。另外, 在领域特征学习方面, 我们将研究如何提高模型的领域判别准确率以及如何共享各个领域之间通用表示, 提高模型在领域特性不强的数据的翻译性能。
[1]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks // NIPS. Montreal, 2014: 3104–3112
[2]Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate // ICLR. San Diego, 2015: 1–15
[3]Luong M T, Pham H, Manning C D. Effective app-roaches to attention-based neural machine translation // EMNLP. Lisbon, 2015: 1412–1421
[4]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // NIPS. Los Angeles, 2017: 5998–6008
[5]Sajjad H, Durrani N, Dalvi F, et al. Neural machine translation training in a multi-domain scenario // Proceedings of the 14th International Conference on Spoken Language Translation. Tokyo, 2017: 66–73
[6]Haddow B, Koehn P. Analysing the effect of out-of-domain data on SMT systems // Proceedings of the Seventh Workshop on Statistical Machine Translation. Montréal, 2012: 422–432
[7]Britz D, Le Q, Pryzant R. Effective domain mixing for neural machine translation // Proceedings of the Second Conference on Machine Translation. Copen-hagen, 2017: 118–126
[8]Zeng Jiali, Su Jinsong, Wen Huating, et al. Multi-domain neural machine translation with word-level domain context discrimination // EMNLP. Brussels, 2018: 447–457
[9]Jiang Haoming, Liang Chen, Wang Chong, et al. Multi-domain neural machine translation with word-level adaptive layer-wise domain mixing [C/OL] // Proceedings of the ACL. (2020–07) [2021–02–25]. https://aclanthology.org/2020.acl-main.165/
[10]Kobus C, Crego J, Senellart J. Domain control for neural machine translation // Proceedings of the In-ternational Conference Recent Advances in Natural Language Processing. Varna, 2017: 372–378
[11]Pham M Q, Crego J, Yvon F, et al. Generic and specialized word embeddings for multi-domain ma-chine translation // Proceedings of the 16th Internatio-nal Conference on Spoken Language Translation. Hong Kong, 2019: 26
[12]Zhang Shiqi, Liu Yan, Xiong Deyi, et al. Domain-aware self-attention for multi-domain neural machine translation // Proceedings of the Interspeech 2021. Brno, 2021: 2047–2051
[13]LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4): 541–551
[14]Gao Yingqiang, Nikolov N I, Hu Yuhuang, et al. Character-level translation with self-attention [C/OL] // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. (2020–07) [2021–05–07]. https://aclanthology.org/2020.acl-main. 145/
[15]Tian Liang, Wong D F, Chao L S, et al. UM-corpus: a large English-Chinese parallel corpus for statistical machine translation // Proceedings of International Conference on Language Resources and Evaluation. Reykjavik, 2014: 1837–1842
[16]Tiedemann J. Parallel data, tools and interfaces in OPUS // Proceedings of International Conference on Language Resources and Evaluation. Istanbul, 2012: 2214–2218
[17]Koehn P, Hoang H, Birch A, et al. Moses: open source toolkit for statistical machine translation // Procee-dings of the ACL. Prague, 2007: 177–180
[18]Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units // Pro-ceedings of the ACL. Berlin, 2016: 1715–1725
[19]Post M. A call for clarity in reporting BLEU scores // Proceedings of the Third Conference on Machine Translation: Research Papers. Belgium, 2018: 168–191
[20]Ott M, Edunov S, Baevski A, et al. Fairseq: a fast, extensible toolkit for sequence modeling // NAACL. Minneapolis, 2019: 48–53
[21]Kingma D P, Ba J. Adam: a method for stochastic optimization // ICLR. San Diego, 2015: arXiv: 1412. 6980
Word-Based Domain Feature-Sensitive Multi-domain Neural Machine Translation
HUANG Zengcheng, MAN Zhibo, ZHANG Yujie†, XU Jin’an, CHEN Yufeng
School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044; †Corresponding author, E-mail: yjzhang@bjtu.edu.cn
The accuracy of the existing word-based domain feature learning methods on domain discrimination is still low and the further research for domain feature learning is required. In order to improve domain discrimination and provide accurate translation, this paper proposes a word-based domain feature-sensitive learning mechanism, including 1) the context feature encoding at encoder side, to widen the study range of word-based domain features, introducing convolutional neural networks (CNN) in encoder for extracting features from word strings with different lengths in parallel as word context features; and 2) enhanced domain feature learning. A domain discriminator module based on multi-layer perceptions (MLP) is designed to enhance the learning ability of obtaining more accurate domain proportion from word context features and improve the accuracy of word domain discrimination. Experiments on English-Chinese task of UM-Corpus and English-French task of OPUS show that the average BLEU scores of the proposed method exceed the strong baseline by 0.82 and 1.06 respectively. The accuracy of domain discrimination is improved by 10.07% and 18.06% compared with the baseline. More studies illustrate that the improvements of average BLEU scores and accuracy of domain discrimation are contributed by the proposed word-based domain feature-sensitive learning mechanism.
multi-domain NMT; domain feature-sensitive; context features; domain discrimination
